4.8 GoogLeNet网络#
在前面两节内容中我们分别介绍了VGG和NIN模型中基于自定义块来构建网络的思想,其核心观点均是认为传统的单一卷积操作很难提取到高级的抽象特征,因此需要重新构造新的基模块,例如VGG块和多层感知机卷积块。在接下来的这节内容中,我们将再次介绍另外一种同样也是基于“块”思想的网络模型——GoogLeNet模型[1]。
4.8.1 GoogLeNet动机#
从「第4.4节 LeNet5网络:经典卷积神经网络结构入门」开始介绍的第1个卷积神经网络LeNet5模型到「第4.7节 NIN网络原理:Network in Network 结构解析」中的NIN网络模型,这4个模型除了在深度上有着明显的区别,另一个明显的差异之处就在于卷积核大小的变化以及与池化层的组合方式。
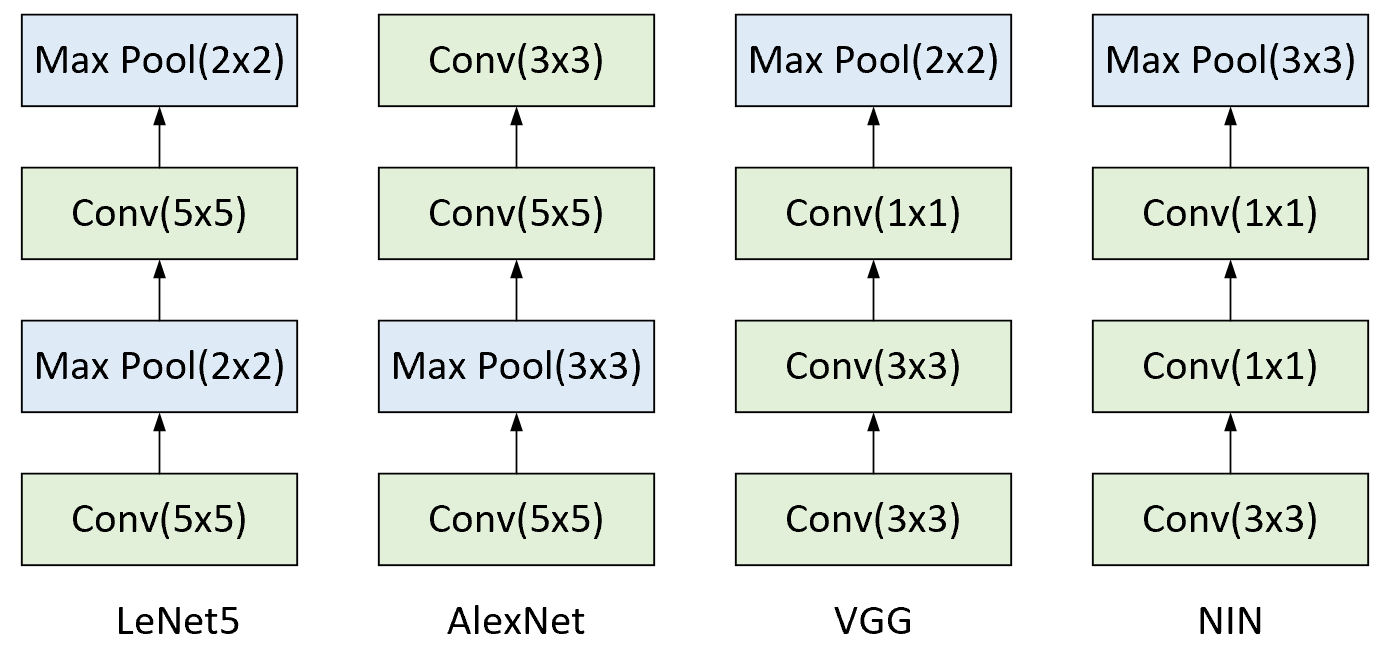
如图4-41所示,在LeNet5模型中作者仅仅只是采用了窗口大小为$5\times5$的卷积核进行特征提,而到了AlexNet中则引入了窗口大小为$3\times3$卷积操作,进一步在VGG和NIN模型中还出现了$1\times1$大小的卷积操作并同时摒弃了$5\times5$的卷积核。同时,不同的网络模型对于池化层的位置也有不同的处理方式。因此,对于某个网络层来说到底是应该使用卷积层还是池化层呢?如果使用卷积层该选择什么样的窗口大小呢?
基于这样的动机,谷歌公司在2015年的一篇论文中提出了一种并行的网络结构块Inception来解决这一问题,并以Inception块为基础构建得到了整个GoogLeNet网络模型。
4.8.2 GoogLeNet结构#
在正式介绍GoogLeNet模型的网络结构之前,我们先来介绍其中的核心部分Inception模块和$1\times1$卷积的作用。
1. 理解Inception模块
如图4-42所示便是Inception块的构成元素。从图中可以看出,对于任意Inception块的输入来说从左到右并行有a、b、c和d共4条路径选择,分别对应了不同大小卷积核的卷积操作和池化操作。
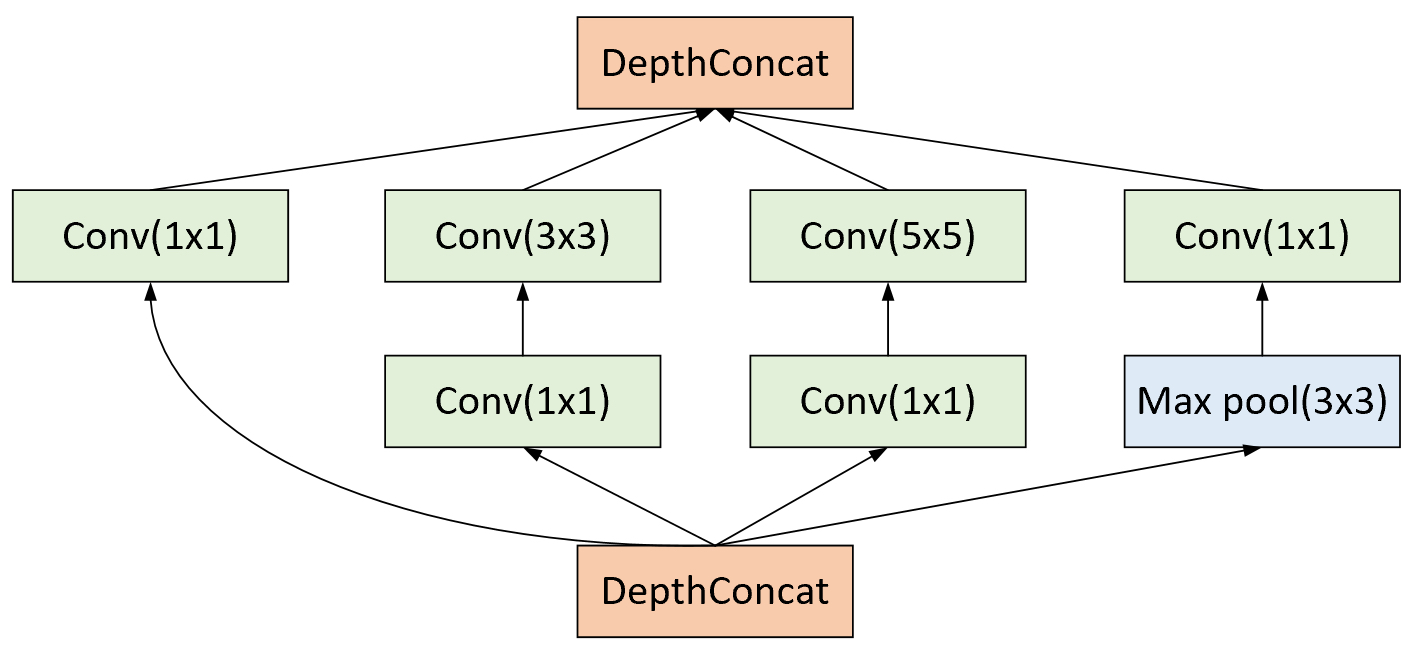
进一步,将不同路径下运算得到的结果在通道这一维度上进行堆叠便得到了Inception块的输出。最终,通过以Inception块来代替传统卷积的方式便能够在同一层获取得到不同卷积尺度的计算结果,这便是Inception块的核心思想。可以看出GoogLeNet这个名字和LetNet并没有任何关系,仅仅只是在向后者致敬。
2. $1\times1$卷积的作用
此时可能有读者会问,为什么Inception块的中间两条路径也会有$1\times1$大小的卷积操作?
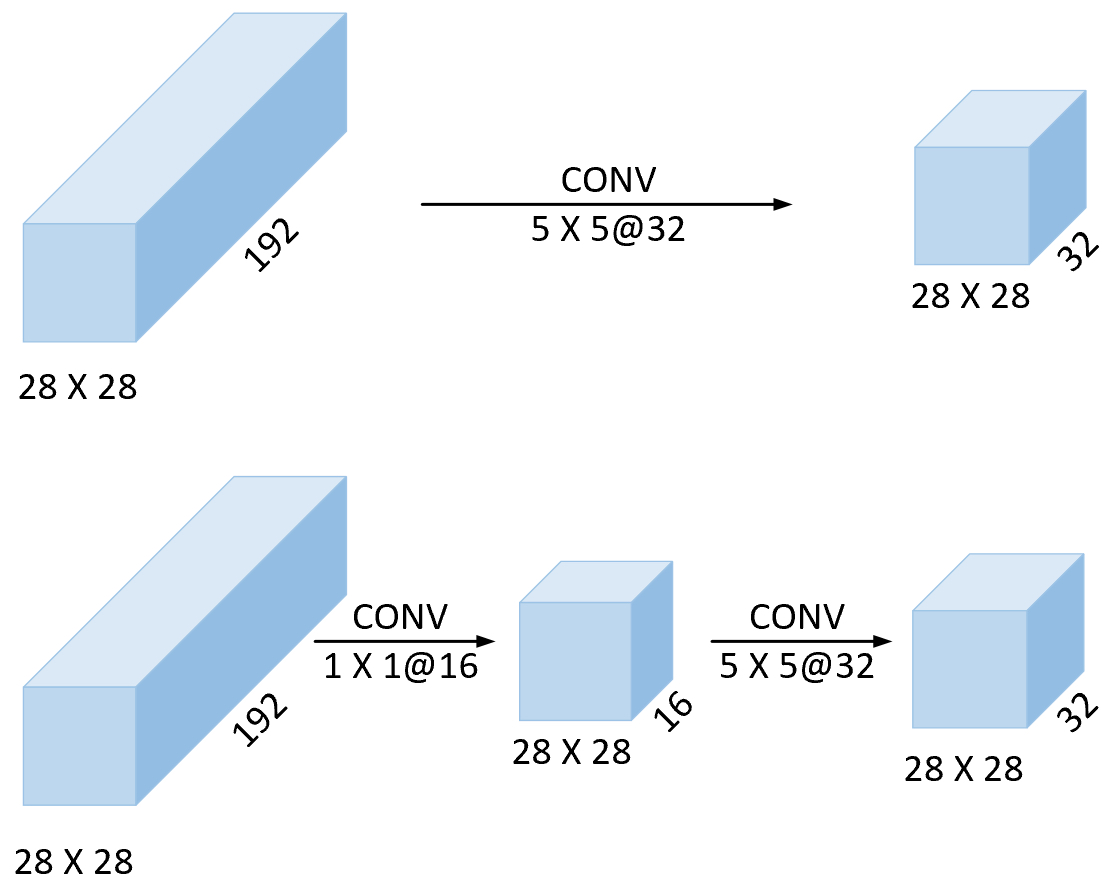
如图4-43所示,现有特征图的形状为$28\times28\times192$,如果直接使用32个窗口大小为$5\times5$的卷积核进行卷积操作,那么此时一共有153600个权重参数;而如果先用16个窗口大小为$1\times1$的卷积核对原始特征图进行降维,然后再进行窗口大小为$5\times5$的卷积操作,那么此时一共有15872个权重参数。可以看出,后者的参数量仅仅只有前者的约十分之一,同时整个计算量也变成了前者的十分之一。因此,Inception模块中间两个$1\times1$卷积操作的目的便是降低模型的参数量。
3. 整体网络结构
在介绍完Inception结构的思想原理后我们再来看GoogLeNet的整个网络结构。总的来说,除了传统的3个卷积运算之外,GoogLeNet一共由9个Inception块所构成,而这9个Inception块又可以分为三个阶段,前两个阶段结束之后特征图的大小均变成了之前的一半,最后一个阶段结束后便是一个全局池化层并通过一个全连接层来完成分类任务。
如图4-44所示便是GoogLeNet的网络结构图。以原始输入大小为3通道$224\times224$的图像为例,在经过前面两个卷积层和池化层之后特征图的形状变成了[28,28,192]。进一步,在经过模块Inception(3a)时,4个分支路径的特征图形状分别为[28,28,64]、[28,28,128]、[28,28,32]和[28,28,32],然后在通道这个维度上进行堆叠得到形状为[28,28,256]的特征图。从这里可以看出,在Inception模块的4个路径中$3\times3$大小的卷积核最多,并且后续也一直保持了这个规律,一定程度上反映出$3\times3$大小的卷积核更具有优势。紧接着便是Inception(3b)、Inception(4a)、Inception(4b)、Inception(4c)、Inception(4d)、Inception(4e)、Inception(5a)和Inception(5b)这8个Inception块,输出形状为[7,7,1024]。最后,再通过一个维度为1024的全连接层完成分类任务。具体每个Inception块计算后特征图的形状可以参见图4-44中的对应标注。
当然,GoogLeNet除了图4-44所示的网络结构外,作者认为处于网络模型中间层的特征往往具有更强的判别能力,因此GoogLeNet的另一个版本还在网络的中间部分额外的添加了两个分类器,即在分别再取Inception(4a)和Inception(4d)的输出结果进行后续的分类任务。
4.8.3 GoogLeNet实现#
在介绍完GoogLeNet模型的网络结构之后我们再来看如何一步步实现整个模型。类似于实现NIN模型一样,这里需要先定义实现Inception模块,然后再以此为基础来实现GoogLeNet模型。以下完整示例代码可以参见Code/Chapter04/C07_GoogLeNet/文件。
1. 辅助模块
首先需要实现两个辅助类来完成Inception块的计算过程,实现代码如下所示:
1 class BasicConv2d(nn.Module):
2 def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
3 super(BasicConv2d, self).__init__()
4 self.conv = nn.Conv2d(in_channels, out_channels,
5 kernel_size, stride, padding)
6 self.relu = nn.ReLU(inplace=True)
7
8 def forward(self, x):
9 x = self.conv(x)
10 return self.relu(x)在上述代码中,类BasicConv2d的作用便是同时完成一个卷积操作和一次非线性变换。因为是继承自nn.Module,所以后续可以将BasicConv2d整体作为一个网络层进行使用。
进一步,Inception块的实现代码如下所示:
1 class Inception(nn.Module):
2 def __init__(self, in_channels, ch1x1, ch3x3reduce, ch3x3, ch5x5reduce, ch5x5, pool_proj):
3 super(Inception, self).__init__()
4 self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
5 self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3reduce, kernel_size=1),
6 BasicConv2d(ch3x3reduce, ch3x3, kernel_size=3, padding=1))
7 self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch5x5reduce, kernel_size=1),
8 BasicConv2d(ch5x5reduce, ch5x5, kernel_size=5, padding=2))
9 self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
10 BasicConv2d(in_channels, pool_proj, kernel_size=1))
11
12 def forward(self, x):
13 branch1 = self.branch1(x)
14 branch2 = self.branch2(x)
15 branch3 = self.branch3(x)
16 branch4 = self.branch4(x)
17 return torch.cat([branch1, branch2, branch3, branch4], 1)在上述代码中,第2行中in_channels表示上一层输入的通道数,ch1x1表示 $1\times1$卷积的个数,ch3x3reduce表示$3\times3$卷积之前$1\times1$卷积的个数,ch3x3表示$3\times3$卷积的个数,ch5x5reduce表示$5\times5$卷积之前$1\times1$卷积的个数,ch5x5表示$5\times5$卷积的个数,pool_proj表示池化后$1\times1$卷积的个数。第4~9行便是Inception块中对应4个分支路径的计算部分。第13~16行是4个分支对应的前向传播过程。第17行是将4个分支的结果在通道维度上进行堆叠。
2. 前向传播
基于上面实现的辅助模块,整个GoogLeNet网络模型的前向传播过程实现代码如下所示:
1 class GoogLeNet(nn.Module):
2 def __init__(self, num_classes=1000, in_channels=3):
3 super(GoogLeNet, self).__init__()
4 s1 = nn.Sequential(BasicConv2d(in_channels, 64, kernel_size=7, stride=2, padding=3),
5 nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
6 s2 = nn.Sequential(BasicConv2d(64, 64, kernel_size=1, stride=1),
7 BasicConv2d(64, 192, kernel_size=3, stride=1, padding=1),
8 nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
9 s3 = nn.Sequential(Inception(192, 64, 96, 128, 16, 32, 32), # inception3a
10 Inception(256, 128, 128, 192, 32, 96, 64), # inception3b
11 nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
12 s4 = nn.Sequential(Inception(480, 192, 96, 208, 16, 48, 64), # inception4a
13 Inception(512, 160, 112, 224, 24, 64, 64), # inception4b
14 Inception(512, 128, 128, 256, 24, 64, 64), # inception4c
15 Inception(512, 112, 144, 288, 32, 64, 64), # inception4d
16 Inception(528, 256, 160, 320, 32, 128, 128), # inception4e
17 nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
18 s5 = nn.Sequential(Inception(832, 256, 160, 320, 32, 128, 128), # inception5a
19 Inception(832, 384, 192, 384, 48, 128, 128)) # inception5b
20 s6 = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten(),
21 nn.Dropout(0.5), nn.Linear(1024, num_classes))
22 self.google_net = nn.Sequential(s1, s2, s3, s4, s5, s6)
23
24 def forward(self, x, labels=None):
25 logits = self.google_net(x) # N x 1000 (num_classes)
26 if labels is not None:
27 loss_fct = nn.CrossEntropyLoss(reduction='mean')
28 loss = loss_fct(logits, labels)
29 return loss, logits
30 else:
31 return logits在上述代码中,第2行的两个参数分别用来指定分类数量和输入图片的通道数。第4~8行对应的是图4-44中Inception(3a)之前的卷积计算。第9~19行分别对应图4-44中的各个Inception块。第20~21行则是最后的分类器部分。第24~31是完成上述整个前向传播的计算过程,并根据条件返回相应的结果。
在上述网络定义结束后,第4~20行中每个Sequential里相应模块完成计算后结果的形状如下所示:
1 网络层: Sequential, 输出形状: torch.Size([2, 64, 56, 56])
2 网络层: Sequential, 输出形状: torch.Size([2, 192, 28, 28])
3 网络层: Sequential, 输出形状: torch.Size([2, 480, 14, 14])
4 网络层: Sequential, 输出形状: torch.Size([2, 832, 7, 7])
5 网络层: Sequential, 输出形状: torch.Size([2, 1024, 7, 7])
6 网络层: Sequential, 输出形状: torch.Size([2, 1000])3. 模型训练
在这里我们将继续使用「第4.6节 VGG网络:卷积神经网络加深的设计思路」中介绍到的CIFAR10数据集,所以不再对相关内容进行赘述。在前面各项工作都准备完毕之后便可以进一步实现模型的训练过程。由于这部分代码与第4.6节中的训练代码基本上一样,只需要将网络模型实例化的语句改为model = GoogLeNet(config.num_classes,config.in_channels),并同时加入梯度裁剪(参见「第6.2节 梯度裁剪:训练不稳定时如何控制梯度爆炸」内容)即可,因此这里也不再赘述,各位读者直接参考源码。
最后,在对网络模型进行训练时将会得到类似如下的输出结果:
1 Epochs[1/60]--batch[0/782]--Acc: 0.0625--loss: 2.3048
2 Epochs[1/60]--batch[50/782]--Acc: 0.2109--loss: 2.3025
3 Epochs[1/60]--batch[100/782]--Acc: 0.3047--loss: 2.2967
4 ...
5 Epochs[1/60]--Acc on test 0.274
6 Epochs[59/60]--Acc on test 0.8214
7 Epochs[60/60]--Acc on test 0.83034.8.4 小结#
在本节内容中,我们首先介绍了Inception模块提出的动机及其思想原理,并同时解释了其中$1\times1$卷积的作用;然后介绍了GoogLeNet模型的整体架构;最后还介绍了如何通过PyTorch来实现GoogLeNet网络,并同时在CIFAR10数据集上进行了实验。在学完本节内容后,我们最应该掌握的两个点就是Inception本身这种结构以及对于$1\times1$卷积的理解。在下一节内容中,我们将开始介绍卷积网络中的第6个经典模型ResNet。
引用#
[1] Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C] Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, 1-9.