10.14 GPT-2与GPT-3模型#
在「第10.13节 GPT-1原理:生成式预训练模型入门」内容中我们详细介绍了GPT-1模型的相关原理。尽管它是基于Transformer中解码器来进行构建的,但是从整个模型的构建流程来看GPT-1似乎仍旧将它当做是“编码器”在使用,并没有用到解码独有的序列生成能力。在本节内容中,我们将从另外一个视角来介绍GPT-1的迭代版本GPT-2模型。
10.14.1 GPT-2动机#
传统的自然语言模型在面对不同的任务场景时总是需要重新设计网络结构,例如问题回答、机器翻译等。尽管在GPT-1中基于预训练模型的微调方法已经极大限度上减少了对网络结构的修改,但是在不同的下游任务中依旧需要在原有网络的基础上再加入一个线性层。因此,在引入了新的模型参数后还要通过少量标注数据来训练这部分模型参数。
基于这样的动机,2019年2月OpenAI团队在GPT-1模型的基础之上提出了GPT-2模型[1] [2]。GPT-2模型最大的一个改进点就是没有再针对每个下游任务进行有监督微调,而是使用同一个预训练语言模型依靠它自身学习到的生成能力来完成不同的下游任务。从一定程度上看,这也标志着自然语言处理领域中一个新流派的出现。尽管最后GPP-2在各项下游任务中的表现还远不如现有的有监督模型,但是OpenAI研究发现随着模型规模的扩大其表现结果有还有明显的增长趋势,而这也为后续的GPT-3埋下了伏笔。
10.14.2 GPT-2结构#
从整体上看GPT-2模型依旧延续了GPT-1中的网络结构,仅仅只是对各个模块间的归一化形式和残差连接层里的权重参数缩放进行了修改,同时上下文窗口也从512增加到了1024的长度。GPT-2的训练方法也同GPT-1一样,都是通过以给定前$k$个词来预测第$k+1$个词的形式来进行建模求解得到权重参数。尽管这一目标函数看似简单,但由于训练数据集的多样性——它天然地包含有不同领域、不同场景下的语义环境——使得训练得到的模型在生成能力上同样具有这样的多样性。
在GPT-2中,模型的改进主要体现在模型规模和训练数据质与量的扩大上。一方面,为了提高模型的生成能力以适应不同的下游任务,GPT-2设计了4种规格的模型结构,其中具有48个解码层的模型更是拥有超过15亿参数,是GPT-1的10倍。
![表10-1 GPT-2模型参数规模(原始论文中作者参数量计算有误,已在[2]中进行了修正)](https://mlwithme.oss-cn-shanghai.aliyuncs.com/images/dl/231107205722.jpg)
注:M表示百万
如表10-1所示是GPT-2中4种不同规格模型的配置情况,其中最小的12层用于从模型规模上同GPT-1进行对比,而最大的48层则是用来探索模型的生成能力。
另一方面,为了能够训练得到更大规模的GPT-2模型,其对应的数据集也相应扩大了近10倍。在训练GPT-1中所使用到的数据集是包含有超过7000本未出版的电子书籍BookCorpus数据集,总大小接近5G。在GPT-2的训练过程中为了使得生成内容更加准确和多样,模型使用了来自Reddit中的4500万个经过人工筛选过的网页文本,经去重和清理后构建得到了一个近800万篇文档总共近40G的高质量数据集WebText。
在GPT-2的工作中之所以如此重视训练数据的质量是因为作者认为,高质量数据集内部本身就可能存在各个任务场景下的自然语言描述,因此如果将这些数据用于训练最终得到的模型便同样能够生成类似的文本内容。
In a now-deleted post from Aug. 16, Soheil Eid, Tory candidate in the riding of Joliette, wrote in French: ”Mentez mentez, il en restera toujours quelque chose,” which translates as,”Lie lie and something will always remain.”
If listened carefully at 29:55, a conversation can be heard between two guys in French: “-Comment on fait pour aller de l’autre cote ́? -Quel autre cote ́?”, which means “- How do you get to the other side? - What side?”.
例如对于上述作者从数据集中所摘录出的2个示例来说,每个示例中均含有从法语到英语的翻译过程,并且整个文本的表述方式也就是我们交流时的自然表达形式。因此,GPT-2模型尝试从数据的角度来提高模型的生成能力。最后,在不同下游任务的推理场景中,我们只需要给定相应的提示词(Prompt)便可以生成对应的输出结果。例如在英语到法语的翻译任务中,我们可以通过构建类似“英语1 = 法语1 \n 英语2 = ”这样的输入来完成英语2到法语的翻译任务。不过遗憾的是我们按照论文中所描述的方法经过反复尝试后依旧没能得到预期的结果,各位读者可自行试验。
10.14.3 GPT-2使用#
出于担心大型语言模型被用来大规模生成欺骗性、偏见或辱骂性的语言,在GPT-2发布之初OpenAI只公布了最小的124M版本预训练模型。不过随着时间的推移9个月以后[5]OpenAI便公布了最大的1558M版本预训练模型,我们可以通过[2]中的方式来下载与使用。此处建议使用本书所注释的版本[6],其依旧克隆自[2]只是对部分代码进行了注释同时补充了环境安装的依赖文件。
首先进入该项目仓库并将其克隆到本地;然后创建一个Python版本为3.6的环境(该项目只支持这一版本),并依照项目中的requirements.txt安装整个运行环境;接着通过如下命令来下载模型文件:
1 python download_model.py 124M 其中最后一个参数表示指定的模型,可选的有124M、355M、774M和1558M,其中124M大小约497M,1558MB大小约为4.9GB。
上述代码执行完毕后会在当前目录生成一个models目录,里面会以模型名生成对应的模型目录。例如上面会生成一个名为124M的目录,目录里面将会有7个模型文件,其中model.ckpt.data-00000-of-00001便是对应的模型权重文件。这里需要注意的是,由于网络原因运行代码时模型可能会下载失败,因此我们可以将download_model.py文件中第18行里model.ckpt.data-00000-of-00001给去掉,然后手动在浏览器中通过如下链接[7]下载该模型文件,并放到对应的模型目录中。
上述工作准备完毕后,我们便可以通过如下方式来使用GPT-2根据我们的输入生成对应的文本:
1 python src/interactive_conditional_samples.py
# 输入
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
# 输出:
Having studied the experiment since the 2015, Sivary-Dylan looked for clues as to why those mighty unicorns are immodest.
But to her dismay, there weren't even that many.
"What's surprising is the general pattern of language," Sivary-Dylan told Gizmodo. "We've known about the deluge and around 6,000 instances of awarding money to orphan cheering wildlife groups for their Galaxy baby." ...这里需要注意的是,interactive_conditional_samples.py中默认使用的是124M这个模型,如果换成1558M则需要将其中interact_model()函数中的model_name参数指定为'1558M'。
从上述生成结果可以看出,尽管GPT-2看似根据提示生成了对应的文本序列,但是很大程度上它更像是在自说自话,整个上下文并没有太强的逻辑关系。因此尽管GPT-2模型的动机非常新颖,试图完全的去掉下游模型微调的过程,但是从模型的表现结果来看它并不十分出众。不过尽管如此,它依旧在这一方向迈出了重要的一步,并且作者通过实验发现随着模型规模的扩大模型在一些任务上的表现还有明显的增长趋势,而这一发现也为GPT-3的诞生提供了动机。
10.14.4 GPT-3结构#
虽然从模型新意度上看GPT-2相较于GPT-1有了本质的改变,但是从模型最后的表现结果来看GPT-2并没有取得显著的进步。不过尽管如此,在每个下游任务中都需要通过少量标注样本来对模型进行梯度更新依旧是一种成本高昂的做法,尤其是当模型规模大到一定程度时。同时,根据已有研究显示,随着模型规模的扩大模型在下游任务中的表都有着明显地提升[8],此时模型的最大规模已有170亿参数[9]。
基于这样的动机,布朗(Brown)等人[8]于2020年5月又提出了参数规模达1750亿的GPT-3模型。从整体上看,GPT-3在模型结构和训练方法上与GPT-2一样,仅仅只是非常直接地扩大了模型的参数量、数据集的大小和丰富度,同时上下文窗口也从GPT-2中的1024增加到了2048的长度。GPT-3模型除了在规模上更加激进,最重要的是它提出了一种不需要对模型参数进行更新的上下文情境学习(In-Context Learning)或少样本学习(Few-Shot Learning)方法。GPT-3模型不再像GPT-2那样在下游任务中完全不给模型任何样例进行学习,而是给定少量标注样本让模型知道该如何完成这一任务。因为即使是人类也做不到在不看任何示例的情况下而完成一项之前从未见过的新任务。
1. 预训练过程
对于GPT-3模型来说它使用了和GPT-2相同的网络结构,区别在于GPT-3还额外引入了Sparse Transformer[10]中的稀疏注意力模块来降低模型的时间复杂度。同时,为了研究模型性能与规模之间的关系,OpenAI一共训练了8种不同规模的模型,其中具有96个解码层的模型便是拥有1750亿参数的GPT-3模型,是GPT-2的100倍。
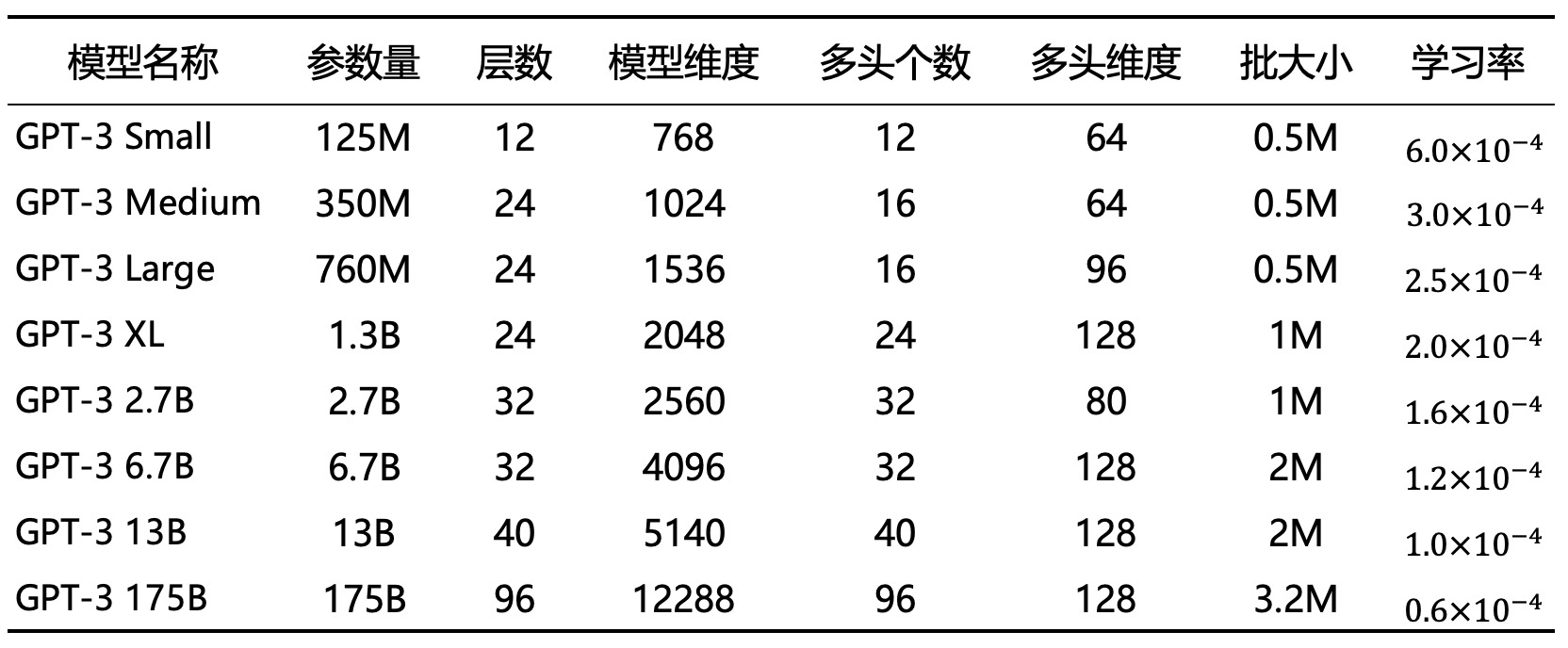
注:M表示百万,B表示十亿。
如表10-2所示便是8种规模的参数配置情况,其中GPT-3 Small相当于BERT-Base和GPT1的参数规模,GPT-3 Medium相当于BERT-Large的规模,GPT-3 XL则相当于GPT-2的规模。而为了训练得到如此大规模的模型GPT-3也使用了前所未有的数据规模,仅明确公开的就有570GB大小(总大小据估算为750GB),如表10-3所示。
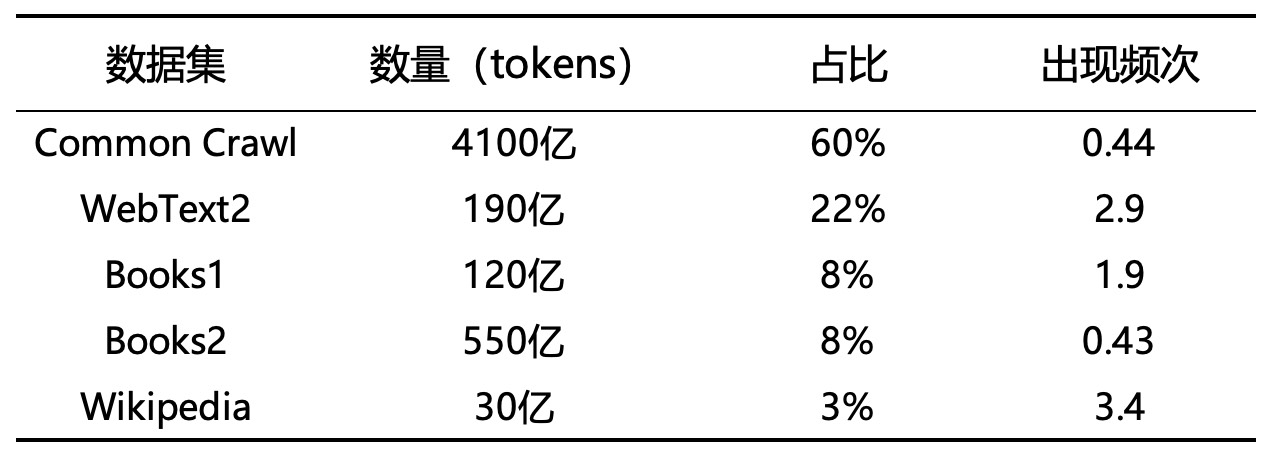
如表10-3所示便是GPT-3中所使用到的5个数据集。Common Crawl是一个大规模的开放式网络抓取项目[11],它致力于收集并提供互联网上的网页数据,总量超过了2550亿个网页。GPT-3将其中2016年至2019年的45TB数据经过清洗过滤后留下570GB数据,总共大约4100亿个词元,作为训练数据的一部分。WebText2则是基于GPT-2模型中WebText1的扩展数据集,包含有190亿个词元。Books1和Books2是两个基于互联网的电子数据,总计670亿词元,而大小及来源OpenAI并未公开。Wikipedia是英文语种的维基百科网页数据,大约30亿词元。同时,由于5个数据集的质量并不相同,所以GPT-3在训练的时候并不是直接将上述数据混合后进行打乱构造小批量样本,而是将给予高质量的数据集更高的采样比率。例如尽管Common Crawl数据集从规模上看要远远大于其它4个数据集,但是在每个小批量中它的占比只有60%,而最小规模的Wikipedia则有3%的占比。这使得模型在整个训练过程中每平均每3000亿词元数据集Wikipedia出现的频次约为3.4次,而Common Crawl仅为0.44次。
2. 情境学习
在整个模型训练完成以后GPT-3采用了上下文情境学习的方式来完成各个下游任务的推理过程,需要再次提醒的是在该过程中模型的权重参数不会进行更新。同时,为了系统性地研究情境学习对模型推理结果的影响,OpenAI提出了3种设定下的对比实验,即少样本学习(Few-Shot Learning)、单样本学习(One-Shot Learning)和零样本学习(Zero-Shot Learning)。
-
零样本学习:指在模型推理过程中仅将任务描述和提示输入到模型中,然后让模型完成该任务的输出。
-
单样本学习:指在模型推理过程中将任务描述、一个完整的任务示例和提示输入到模型中,然后让模型完成该任务的输出。
-
少样本学习:指在模型推理过程中将任务描述、多个完整的任务示例和提示输入到模型中,然后让模型完成该任务的输出。
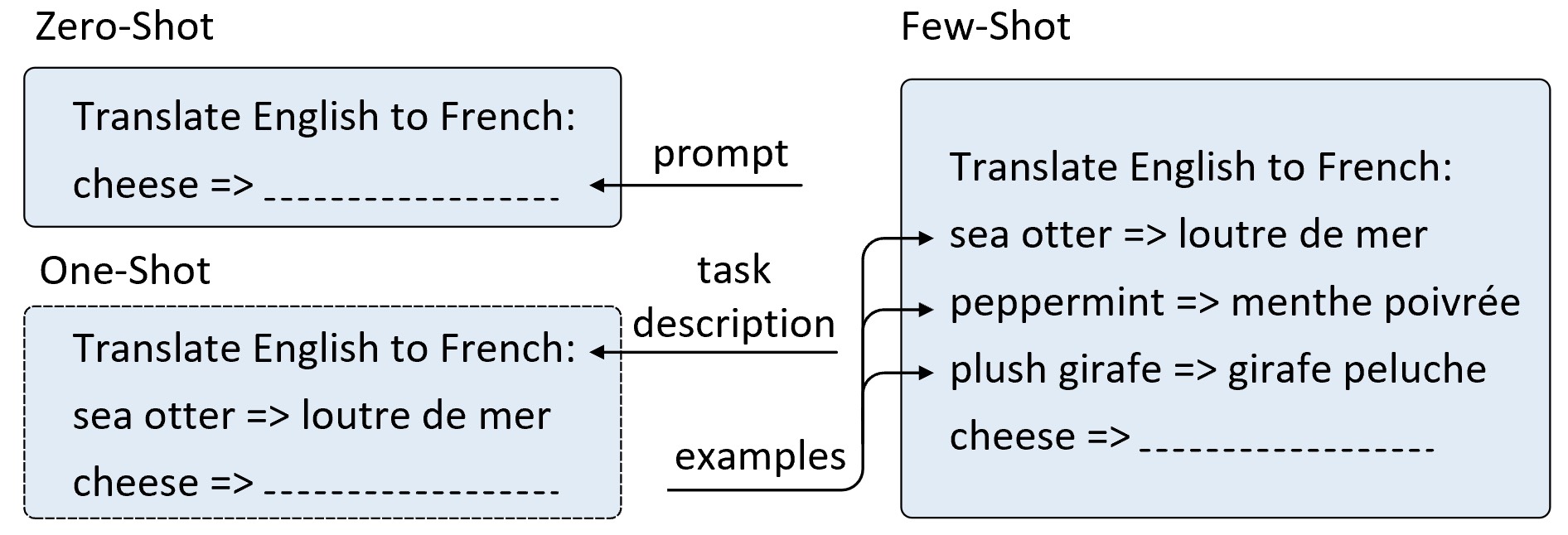
图 10-42 Zero-shot、One-Shot和Few-shot原理示意图
如图10-42所示便是3种学习设定下的模型推理过程,其中第1行表示对该任务的描述,即此处场景是将英语翻译为法语。对于零样本学习来说,给定模型任务描述以及提示并将整个内容作为模型输入,并期望模型生成英文单词对应的法语翻译。对于单样本学习来说,除了给定任务描述和提示之外还需要给定模型一个具体的任务示例,然后让模型产生相应的结果。对于少样本学习来说则需要同时给定模型10到100个左右的具体示例作为输入,最终让模型生成预期的结果。可以看出,在情境学习中GPT-3将标注样本也作为模型输入,通过自注意力机制来编码理解下游任务的意图并生成结果,从而避免了传统方式中通过更新梯度来进行学习的过程。不过从理论上讲,预训练得到的GPT-3模型同样可以通过微调的方式来更新参数,而这也是OpenAI未来将会探索的工作,例如在「第10.16节 InstructGPT与ChatGPT:指令对齐与对话模型演进」内容中我们将要介绍到的InstructGPT模型。
3. 任务推理
在利用GPT-3来完成各项下游任务时我们需要根据不同的任务类型来构造相应的提示输入。具体地,对于类似多项选择这样的任务场景,我们需要提供$K$个示例样本以及对应的问题和选项,然后模型根据示例样式从备选选项中给正确答案;对于分类问题来说我们同样可以根据类似多项选择这样的方式来构造模型输入,即在示例样本中对每个类标标注正确与否,然后再将待分类样本一同输入到模型让模型从备选分类中给出正确答案。对于自由式的文本序列生成任务,如文本翻译、摘要生成和问题回答等,GPT-3则是采用「第9.7节 Seq2Seq教程:编码器解码器结构与序列生成」中介绍的束搜索(束宽为4,长度惩罚系数为0.6)来生成最后的结果。

如图10-43所示便是使用GPT-3进行问题选择和文本分类的示例模板。值得注意的是,如果分类任务的分类数较多,则可能需要给定更多的示例数据才能分类准确。当然,GPT-3模型本质上更擅长序列生成任务,如果是一般的分类任务则使用传统的微调方式效果通常会更好。最终GPT-3模型在零样本或者少样本设定下都取得了显著的效果,并且还能够生成足以以假乱真的文本内容。以上案例各位读者可以在OpenAI官网[12]中注册账号以后选择补全模式达芬奇003模型进行实验。
10.14.5 GPT-3的局限性与安全性#
尽管GPT-3相比于GPT-2在模型效果上有了显著提升,但是GPT-3依然存在着较多的局限性。具体来说,GPT-3在生成文本时随着段落长度的增加会出现语义重复的现象,并且连贯性也会减弱,甚至出现自相矛盾的情况;其次GPT-3在常识推理方面也较为困了,例如它并不能回答类似“如果我把奶酪放进冰箱,会融化吗?”这样的问题;最后,对于GPT-3在使用少样本学习的推理过程中它到底是从示例样本中真正学习到了相关有用的信息,还是说它仅仅只是根据给定的示例样本从之前学习过的文本中找到类似结果这是不确定的,因此准确理解小样本学习的工作原理将是OpenAI未来研究的一个重要探索方向。
在GPT-2模型发布之初OpenAI就曾担心该模型被用作欺骗性或有害文本的生成,因此对于一个规模更加庞大和生成能力更强的GPT-3来说,它所带来的影响是不可忽视的。例如垃圾邮件生成、假新闻生成、论文造假、歧视言论以及违法法律法规文本的生成等。在10.17.8节内容中我们将进行示例。因此OpenAI也对GPT-3在生成内容的有害性、公平性和偏见性方面进行了详细地分析,以便在未来的工作中进行改进。
10.14.6 小结#
在本节内容中,我们首先详细介绍了GPT-2模型所提出的动机和它的原理,以及相比于GPT-1模型的改变之处;然后介绍了如何使用OpenAI开源的GPT-2模型来生成文本内容;进一步,我们介绍了GPT-3模型所提出动机和原理,详细区分了情境学习与传统微调方法的不同之处以及模型的预训练过程;最后,我们介绍了如何在不同的下游任务中构造对应的提示模板来完成任务,并分析了当前GPT-3模型所存在的局限性。在下一节内容中,我们将会介绍一个基于GPT-2模型的开源项目来进一步介绍整个模型的细节之处。
引用#
[1] Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9.
[2] https://github.com/openai/gpt-2
[3] https://openai.com/research/better-language-models
[4] https://openai.com/research/gpt-2-6-month-follow-up
[5] https://openai.com/research/gpt-2-1-5b-release
[6] https://github.com/moon-hotel/gpt-2
[7] https://openaipublic.blob.core.windows.net/gpt-2/models/1558M/model.ckpt.data-00000-of-00001
[8] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[9] Rosset C, Turing-NLG: A 17-billion-parameter language model by Microsoft, Published February 13, 2022.
[10] Child R, Gray S, Radford A, et al. Generating long sequences with sparse transformers[J]. arXiv preprint, 2019, arXiv:1904.10509.
[12] https://platform.openai.com/playground