7.5 高斯朴素贝叶斯原理与实现#
在前面两节内容中,我们分别介绍了基于类别特征的Categorical朴素贝叶斯算法和基于特征权重的Multinomial朴素贝叶斯算法,而两者之间的唯一区别就体现在对条件概率的处理上。在接下来的这节内容中,我们将会介绍第3种基于朴素贝叶斯思想的极大化后验概率模型——高斯朴素贝叶斯(Gaussian Naive Bayes, GNB)。
7.5.1 算法思想#
根据Categorical贝叶斯和Multinomial贝叶斯算法的原理可知,前者只能用于处理类别型取值的特征变量,而后者的初衷也是为了处理包含词频的文本向量表示(尽管从结果上看也适用于类似TFIDF这样的连续型特征)。所谓高斯贝叶斯是指假定样本每个特征维度的条件概率均服从高斯分布,进而再根据贝叶斯公式来计算得到新样本在某个特征分布下其属于各个类别的后验概率,最后通过极大化后验概率来确定样本的所属类别。
7.5.2 算法原理#
高斯贝叶斯算法假定数据样本在各个类别下,每个特征变量$X^{(i)}$的条件概率均服从高斯分布,即
$$ P(X^{(i)}|Y=c_k)=\frac{1}{\sqrt{2\pi \sigma^2_{c_ki}}}\exp\left(-\frac{(X^{(i)}-\mu_{c_ki})^2}{2\sigma^2_{c_ki}}\right)\tag{7-36} $$其中$X^{(i)}$表示第$i$个特征维度,$\sigma_{c_ki}$和$\mu_{c_ki}$分别表示在类别$Y=c_k$下特征$X^{(i)}$对应的标准差和期望。
在计算得到每个特征维度的条件概率后,再进行极大化后验概率计算
$$ \begin{aligned} \hat{y} &= \arg\max_{c_k} \log{\left(P(Y=c_k) \prod_{i=0}^{n}P(X^{(i)} \mid P(Y=c_k)\right)}\\[2ex] &=\arg\max_{c_k} \log{\left[P(Y=c_k) \prod_{i=0}^{n}\frac{1}{\sqrt{2\pi \sigma^2_{c_ki}}}\exp\left(-\frac{(X^{(i)}-\mu_{c_ki})^2}{2\sigma^2_{c_ki}}\right)\right]}\\[2ex] &\Longrightarrow \arg\max_{c_k} \left[\log P(Y=c_k)+\sum_{i=0}^n\log{\left(\frac{1}{\sqrt{2\pi \sigma^2_{c_ki}}}\exp\left(-\frac{(X^{(i)}-\mu_{c_ki})^2}{2\sigma^2_{c_ki}}\right)\right)}\right]\\[2ex] &=\arg\max_{c_k}\left(\log P(Y=c_k)-\frac{1}{2}\sum_{i=0}^n\log{2\pi\sigma^2_{c_ki}-\frac{1}{2}\sum_{i=0}^n\frac{(X^{(i)}-\mu_{c_ki})^2}{\sigma^2_{c_ki}}}\right) \end{aligned}\tag{7-37} $$这里需要注意的是,同上一节介绍的多项式朴素贝叶斯一样,在后验概率计算过程中同样进行取对数操作。
7.5.3 计算示例#
假设现在有一个基于TFIDF方法表示文本数据,其一共包含有$X^{(1)},X^{(2)},X^{(3)}$ 这3个特征维度,每个维度表示词表中相应词的TFIDF权重,$Y$表示样本对应的所属类别,如表7-3所示。现需要预测$x=[0.5,0.12,0.218]$这个样本的所属类别。
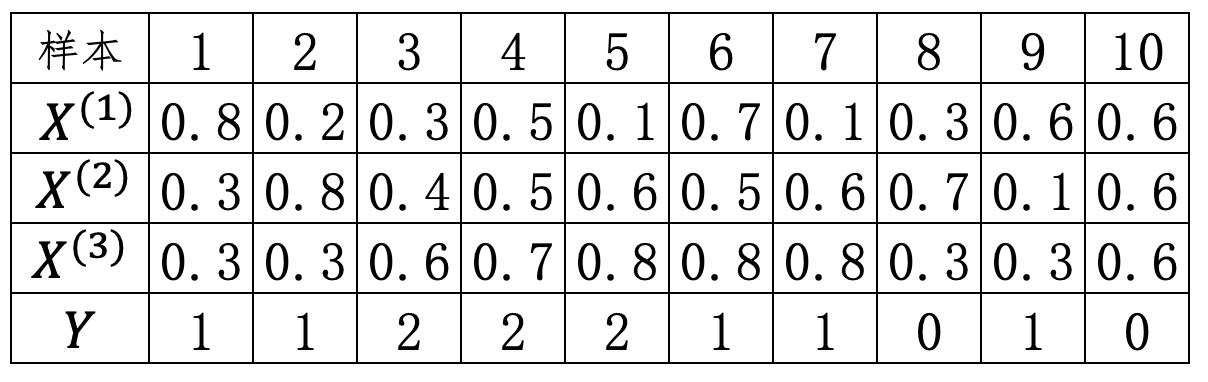
由表7-3易知,各个类别的先验概率为
$$ \begin{aligned} \log P(Y=0)&=\log(\frac{2}{10})\approx-1.609\\[1ex] \log P(Y=1)&=\log(\frac{5}{10})\approx -0.693\\[1ex] \log P(Y=2)&=\log(\frac{3}{10})\approx-1.204 \end{aligned}\tag{7-38} $$根据表7-3可知,当$Y=0$时特征$X^{(1)}$对应的参数期望和方差为
$$ \begin{aligned} \mu_{00} & = \frac{0.3+0.6}{2}=0.45\\[2ex] \sigma^2_{00}&=\frac{(0.3-0.45)^2+(0.6-0.45)^2}{2}=0.0225 \end{aligned}\tag{7-39} $$同理可得
$$ \mu= \begin{bmatrix} 0.45 & 0.65 & 0.45\\ 0.48 & 0.46 & 0.5 \\ 0.3&0.5&0.7\\ \end{bmatrix}\;\;\;\; \sigma^2= \begin{bmatrix} 0.0225 & 0.0025 & 0.0225\\ 0.0776 & 0.0584 & 0.06 \\ 0.0267&0.0067&0.0067\\ \end{bmatrix}\tag{7-40} $$其中$\mu_{c_ki}$表示类别$c_k$下的第$i$个特征对应的期望,$\sigma ^2_{c_ki}$表示类别$c_k$下第$i$个特征对应的方差。
进一步,根据式(7-37)可知,当$Y=0$时$x=[0.5,0.12,0.218]$对应的条件概率为
$$ \begin{aligned} \log P(x|Y=0)=&-\frac{1}{2}\sum_{i=0}^n\log{2\pi\sigma^2_{0i}-\frac{1}{2}\sum_{i=0}^n\frac{(X^{(i)}-\mu_{0i})^2}{\sigma^2_{0i}}}\\[2ex] =&-\frac{1}{2}\cdot\left[\log{(2\pi\times0.0225)}+\log{(2\pi\times0.0025)}+\log{(2\pi\times0.0225)}\right]\\[1ex] &-\frac{1}{2}\cdot\left[\frac{(0.5-0.45)^2}{0.0225}+\frac{(0.12-0.65)^2}{0.0025}+\frac{(0.218-0.45)^2}{0.0225}\right]\\[2ex] \approx&-53.398 \end{aligned}\tag{7-41} $$同理可得
$$ \begin{aligned} \log P(x|Y=1)&\approx-0.307\\[2ex] \log P(x|Y=2)&\approx-24.938 \end{aligned}\tag{7-42} $$进一步,各后验概率为
$$ \begin{aligned} P(Y=0|x)&=\log P(Y=0)+\log P(x|Y=0)=-1.609+(-53.398)\approx-55.007\\[2ex] P(Y=1|x)&=\log P(Y=1)+\log P(x|Y=1)=-0.693+(-0.307)\approx-1.0\\[2ex] P(Y=2|x)&=\log P(Y=2)+\log P(x|Y=2)=-1.204+(-24.938)\approx-26.142 \end{aligned}\tag{7-43} $$根据以上的计算结果可知,样本$x=[0.5,0.12,0.218]$属于$Y=1$这个类别的“概率”最大。同时,通常情况下在输出概率时会对上面最后的结果进行softmax操作,最终样本$x$属于3个类别的概率值分别为$0,1.0,0$。
7.5.4 高斯贝叶斯实现#
在有了前面Categorical和Multinomial贝叶斯算法的实现经验后,高斯贝叶斯的实现过程就非常容易理解了。下面,我们依旧分步进行讲解实现。需要说明的是以下实现代码均参考自sklearn 0.24.0 中的GaussianNB模块,只是对部分处理逻辑进行了修改与简化,完整代码可参见AllBooKCode/Chapter07/C03_naive_bayes_gaussian.py文件。
1. 参数初始化实现
根据7.5.2节内容可知,不管是计算先验概率还是条件概率都需要根据训练集计算得到相关参数。因此,这里需要先对各个参数进行初始化,示例代码如下:
1 class MyGaussianNB(object):
2 def __init__(self, var_smoothing=1e-9):
3 self.var_smoothing = var_smoothing
4
5 def _init_counters(self, X, y):
6 self.classes_ = np.sort(np.unique(y))
7 n_features = X.shape[1]
8 n_classes = len(self.classes_)
9 self.mu_ = np.zeros((n_classes, n_features))
10 self.sigma2_ = np.zeros((n_classes, n_features))
11 self.class_count_ = np.zeros(n_classes, dtype=np.float64)
12 self.class_prior_ = np.zeros(len(self.classes_), dtype=np.float64)在上述代码中,第3行为方差平滑项,主要是为了避免在计算条件概率是方差(分母)为0的情况,尤其是在高维特征中这种现象很容易出现。第6行用来得到训练集中的分类情况,而排序是为了后面依次遍历每个类别。第7~8行分别用来得到特征维度和分类类别总数。第9~10行则是初始化计算条件概率中的期望和方差,其中mu_[i][j]表示第i个类别下第j个特征对应的期望,sigma_[i][j]表示第i个类别下第j个特征对应的方差。第11~12行用来统计每个类别下的样本数以及初始化先验概率。
2. 模型拟合实现
由于参数计算过程较为简单,所以这里并没有将这部分代码单独写为一个方法,整个模型拟合(参数计算)过程的示例代码如下:
1 def fit(self, X, y):
2 self._init_counters(X, y)
3 self.epsilon_ = self.var_smoothing * np.var(X, axis=0).max()
4 for i, y_i in enumerate(self.classes_): # 遍历每一个类别
5 X_i = X[y == y_i, :] # 取类别y_i对应的所有样本
6 self.mu_[i, :] = np.mean(X_i, axis=0) # 计算期望
7 self.sigma2_[i, :] = np.var(X_i, axis=0) # 计算方差
8 self.class_count_[i] += X_i.shape[0] # 类别y_i对应的样本数量
9 self.sigma2_ += self.epsilon_
10 self.class_prior_ = self.class_count_ / self.class_count_.sum()
11 return self在上述代码中,第2行用来初始化得到相关参数,也就是上面第1步介绍的内容。第5行开始逐一遍历每个类别下的样本。第6~7行是计算当前类别中所有样本每个维度所对应的期望和方差。第8行是统计得到当前类别对应的样本数量。第9行则是对计算后的方差进行平滑处理,同时第3行是为了避免加入的平滑项系数太大从而对结果产生严重影响,因此选择了以最大方差最为基础。第10行是计算每个类别对应的先验概率。
3. 后验概率实现
在完成模型的拟合过程后,对于新输入的样本来说其最终的预测结果则取决于对应的极大后验概率。根据式(7-37)可知,后验概率实现过程示例代码如下:
1 def _joint_likelihood(self, X):
2 joint_likelihood = []
3 for i in range(np.size(self.classes_)):
4 jointi = np.log(self.class_prior_[i]) # shape: [1,]
5 n_ij = - 0.5 * np.sum(np.log(2. * np.pi * self.sigma2_[i, :]))
6 n_ij -= 0.5 * np.sum(((X - self.mu_[i, :]) ** 2) /
7 (self.sigma2_[i, :]), 1) # shape: [n_samples,]
8 joint_likelihood.append(jointi + n_ij) # [[n_samples,1],..[n_samples,1]]
9 joint_likelihood = np.array(joint_likelihood).T # [n_samples,n_classes]
10 return joint_likelihood在上述代码中,第4行用来对先验概率取对数操作。第5~7行是实现式(7-37)中的条件概率计算过程。第8行是计算当前类别下对应的后验概率。第10行则是返回所有样本计算得到后验概率,形状为 [n_samples,n_classes] 。
在实现每个样本后验概率的计算结果后,最后一步需要完成的便是极大化操作,即从所有后验概率中选择最大的概率值对应的类别作为该样本的预测类别即可,示例代码如下:
1 def predict(self, X, with_prob=False):
2 from scipy.special import softmax
3 jll = self._joint_likelihood(X)
4 y_pred = self.classes_[np.argmax(jll, axis=1)]
5 if with_prob:
6 prob = softmax(jll)
7 return y_pred, prob
8 return y_pred在上述代码中,第4行便是极大化后验概率的操作。第5~8样则是根据对应的参数来返回预测后的结果。
4. 使用示例
下面,我们先以表7-3中的模拟数据来通过上述实现的代码进行示例,首先需要构造模拟数据集,示例代码如下:
1 def load_simple_data():
2 import numpy as np
3 x = np.array([[0.8, 0.2, 0.3, 0.5, 0.1, 0.7, 0.1, 0.3, 0.6, 0.6],
4 [0.3, 0.8, 0.4, 0.5, 0.6, 0.5, 0.6, 0.7, 0.1, 0.6],
5 [0.3, 0.3, 0.6, 0.7, 0.8, 0.8, 0.8, 0.3, 0.3, 0.6]]).transpose()
6 y = np.array([1, 1, 2, 2, 2, 1, 1, 0, 1, 0])
7 return x, y进一步,便可以通过MyGaussianNB来进行建模,实现代码如下所示:
1 def test_naive_bayes():
2 x, y = load_simple_data()
3 logging.info(f"========== MyGaussianNB 运行结果 ==========")
4 model = MyGaussianNB()
5 model.fit(x, y)
6 logging.info(f"预测结果: {model.predict(np.array([[0.5, 0.12, 0.218]]), with_prob=True)}")
7 logging.info(f"========== GaussianNB 运行结果 ==========")
8 model = GaussianNB()
9 model.fit(x, y)
10 logging.info(f"预测结果: {model.predict(np.array([[0.5, 0.12, 0.218]]))}")在上述代码运行结束后可以看到类似如下结果:
1 ========= MyGaussianNB 运行结果 ==========
2 期望mu = [[0.45 0.65 0.45] [0.48 0.46 0.5 ] [0.3 0.5 0.7 ]]
3 方差sigma = [[0.0225 0.0025 0.0225] [0.0776 0.0584 0.06] [0.02667 0.00667 0.00667]]
4 先验概率 = [0.2 0.5 0.3]
5 log先验概率 = [-1.60943791 -0.69314718 -1.2039728 ]
6 预测结果: [1], [3.50455541e-24, 1.00000000e+00, 1.20454334e-11]
7 ========= GaussianNB 运行结果 ==========
8 期望mu = [[0.45 0.65 0.45] [0.48 0.46 0.5 ] [0.3 0.5 0.7 ]]
9 方差sigma = [[0.0225 0.0025 0.0225] [0.0776 0.0584 0.06] [0.02667 0.00667 0.00667]]
10 先验概率 = [0.2 0.5 0.3]
11 log先验概率 = [-1.60943791 -0.69314718 -1.2039728 ]
12 预测结果: [1]在上述结果中,上面部分为本文所实现代码的输出结果,下面部分则是sklearn中GaussianNB模块的输出结果。
7.5.5 模型对比#
通过连续几节内容的介绍,我们已经详细介绍完了最原始基于类别型变量的Categorical朴素贝叶斯模型、基于词频占比的Multinomial朴素贝叶斯模型以及基于高斯分布的Gaussian朴素贝叶斯模型。对于Categorical NB来说,其只能处理类别型变量作为特征的数据集,例如不考虑词频的词袋模型;对于Multinomial NB来说,其初始动机是为了考虑词袋模型中词频占比对模型的结果的影响,但从结果来看对于类似TFIDF的特征表示模型依旧能够有着很好的效果,这是因为Multinomial NB还可以从线性模型的角度来进行解释;对于Gaussian NB来说,它假设数据集中每个特征维度的条件概率均符合高斯分布,因此理论上来讲它更适合处理连续型的特征变量,但从结果来看其对于离散型的特征表示也有着不错的效果。
下面,我们将依旧使用垃圾邮件分类数据集,但采用不同特征处理方式,来对这3个模型进行一次交叉对比。以下完整代码可参见AllBooKCode/Chapter07/C04_comparison.py文件。
1. 构建数据集
为了方便后续生成不同特征表示的数据集,这里需要先定义一个函数来根据参数生成并返回不同处理方式后的结果,示例代码如下:
1 def make_dataset(feature_type='category', top_k_words=1000):
2 x_text, y = load_cut_spam()
3 if feature_type == "category":
4 vectorizer = VectWithoutFrequency(top_k_words=top_k_words)
5 elif feature_type == "counts":
6 vectorizer = CountVectorizer(max_features=top_k_words)
7 elif feature_type == "tfidf":
8 vectorizer = TfidfVectorizer(max_features=top_k_words)
9 else:
10 raise ValueError(f"不存在特征处理类型{feature_type}")
11 x_train, x_test, y_train, y_test = train_test_split(
12 x_text, y, test_size=0.3, random_state=2022)
13 x_train = vectorizer.fit_transform(x_train)
14 x_test = vectorizer.transform(x_test)
15 if not isinstance(x_train, np.ndarray):
16 x_train = x_train.toarray()
17 x_test = x_test.toarray()
18 return x_train, x_test, y_train, y_test在上述代码中,第3~8行是根据传入的不同参数来实例化不同的特征处理类模块。第11~14行先将数据集划分为训练集和测试集,然后再分别将其转换为不同的特征表示。第15~18行是将稀疏表示转换为稠密表示,并返回最后的结果。
2. 定义辅助函数
进一步,需要定义一个辅助函数来根据传入的训练集和测试集完成模型的训练和预测,示例代码如下:
1 def comp_funcs(x_train, x_test, y_train, y_test, model_type):
2 if model_type == "MyCategoricalNB":
3 model = MyCategoricalNB()
4 elif model_type == "MyMultinomialNB":
5 model = MyMultinomialNB()
6 else:
7 model = MyGaussianNB()
8 model.fit(x_train, y_train)
9 y_pred = model.predict(x_test)
10 print(f"{model_type}模型在测试集上的准确率为:{accuracy_score(y_test, y_pred)}")在上述代码中,第2~9行代码分别是根据不同的参数来实例化不同的模型并进行拟合与预测。
接着,再定义一个辅助函数来根据传入的类型参数选择不同的数据处理方式和模型,示例代码如下:
1 def comparison(feature_type="category", top_k_words=1000, model_type="MyCategoricalNB"):
2 print(f"{feature_type}特征表示方法,", end='')
3 x_train, x_test, y_train, y_test = make_dataset(feature_type, top_k_words)
4 comp_funcs(x_train, x_test, y_train, y_test, model_type)3. 模型比较
在完成上述步骤后,便可以通过如下方式来完成所有模型的对比结果,示例代码如下:
1 if __name__ == '__main__':
2 feature_types = ["category", "counts", "tfidf"]
3 model_types = ["MyCategoricalNB", "MyMultinomialNB", "MyGaussianNB"]
4 top_k_words = 6000
5 comparison(feature_types[0], top_k_words, model_types[0])
6 comparison(feature_types[0], top_k_words, model_types[1])
7 comparison(feature_types[0], top_k_words, model_types[2])
8 comparison(feature_types[1], top_k_words, model_types[1])
9 comparison(feature_types[1], top_k_words, model_types[2])
10 comparison(feature_types[2], top_k_words, model_types[1])
11 comparison(feature_types[2], top_k_words, model_types[2])在上述代码运行结束后,便可以得到如表7-4所示的结果对比。
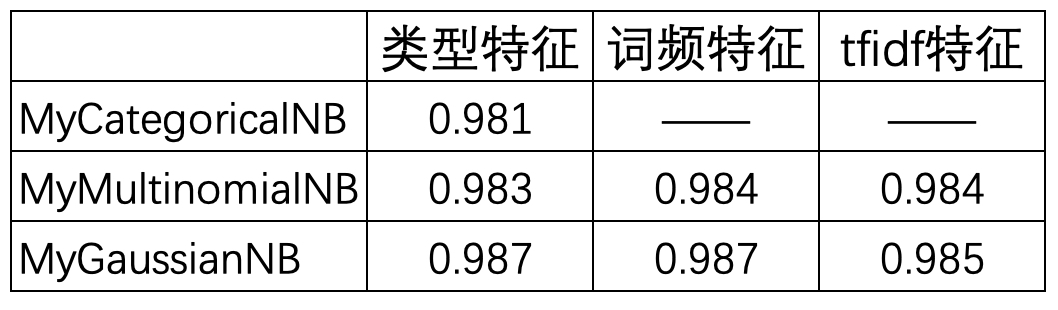
从表7-4可以看出,对于Categorical NB模型来说只能处理类型特征变量,而对于其它两个模型来说3种特征表示均适用。同时,考虑词频的Multinomial NB模型在效果上要略好于不考虑词频的Categorical NB模型。从模型效果来看,Gaussian NB模型无论是采用哪种特征表示方式,相较于其它两种模型其结果都是最好的,并且在这一数据集上不考虑词频的表示方法在Gaussian NB模型中的结果居然同考虑词频的结果里一致。因此,在实际情况中可以优先考虑使用Gaussian NB模型来进行建模。
7.5.6 小结#
在本节内容中,我们首先介绍了高斯朴素贝叶斯算法的基本原理;然后通过一个实际的示例来进一步的介绍了高斯贝叶斯算法的原理与计算过程;接着一步一步详细地介绍了高斯贝叶斯的实现方法;最后,我们还以真实的垃圾邮件分类数据集为例对比了3种不同模型在3种不同特征表示下的分类效果。
总结一下,在本章中我们首先介绍了朴素贝叶斯算法中的几个基本概念,包括先验概率、后验概率、极大后验概率和极大似然估计等,因为只有在对这些概念有了感性的认识才能更加有利于对后续算法原理的理解;接着介绍了朴素贝叶斯算法的基本原理,并且还以一个真实的示例对整个算法的计算过程进行了演示,然后介绍了以平滑处理的方式来处理贝叶斯算法中可能存在的条件概率为0的情况,即贝叶斯估计;然后陆续介绍了两种常见的基于朴素贝叶斯思想的算法模型及其原理和实现;最后还详细对比了3种不同的贝叶斯算法在同一数据集上采用不同特征处理方式下的分类效果,并且得出了在实际情况中可以优先考虑使用Gaussian NB模型来进行建模的结论。
引用#
[1]李航,统计机器学习,清华大学出版社
[2]Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
[3] https://scikit-learn.org/stable/modules/naive_bayes.html#naive-bayes
[4] Rennie J D, Shih L, Teevan J, et al. Tackling the poor assumptions of naive bayes text classifiers[C] (ICML-03). 2003: 616-623.https://www.aaai.org/Papers/ICML/2003/ICML03-081.pdf
[5] https://nlp.stanford.edu/IR-book/html/htmledition/naive-bayes-text-classification-1.html
[6] 代码仓库:https://github.com/moon-hotel/MachineLearningWithMe