10.12 BERT从零训练#
在前面几节内容中我们已经介绍了几种常见的基于BERT预训练模型的下游任务,在接下来的这节内容中我们将会介绍如何从零实现整个NSP和MLM任务并从头训练BERT模型。通常来说,我们既可以通过MLM和NSP这两个任务来从头训练一个BERT模型,当然也可以在开源预训练模型的基础上再次通过MLM和NSP任务来在特定语料中对模型进行微调,以使得整个模型参数更加符合这一场景,并且一般来说更加倾向于第2种做法。
在「第10.6节 BERT原理:双向编码器预训练模型解析」内容中我们已经就MLM和NSP这两个任务的原理做了详细介绍,所以这里就不再赘述。一言以蔽之,MLM就是随机掩盖掉部分字符让模型来预测,而NSP则是同时输入模型两句话让模型判断后一句话是否真的为前一句话的下一句话,最终通过这两个任务来训练BERT模型中的权重参数。
10.12.1 构建流程与格式化#
1. 数据集构建流程
在正式介绍数据预处理之前,我们依旧先通过一张流程图来了解一下整个数据集的构建流程。
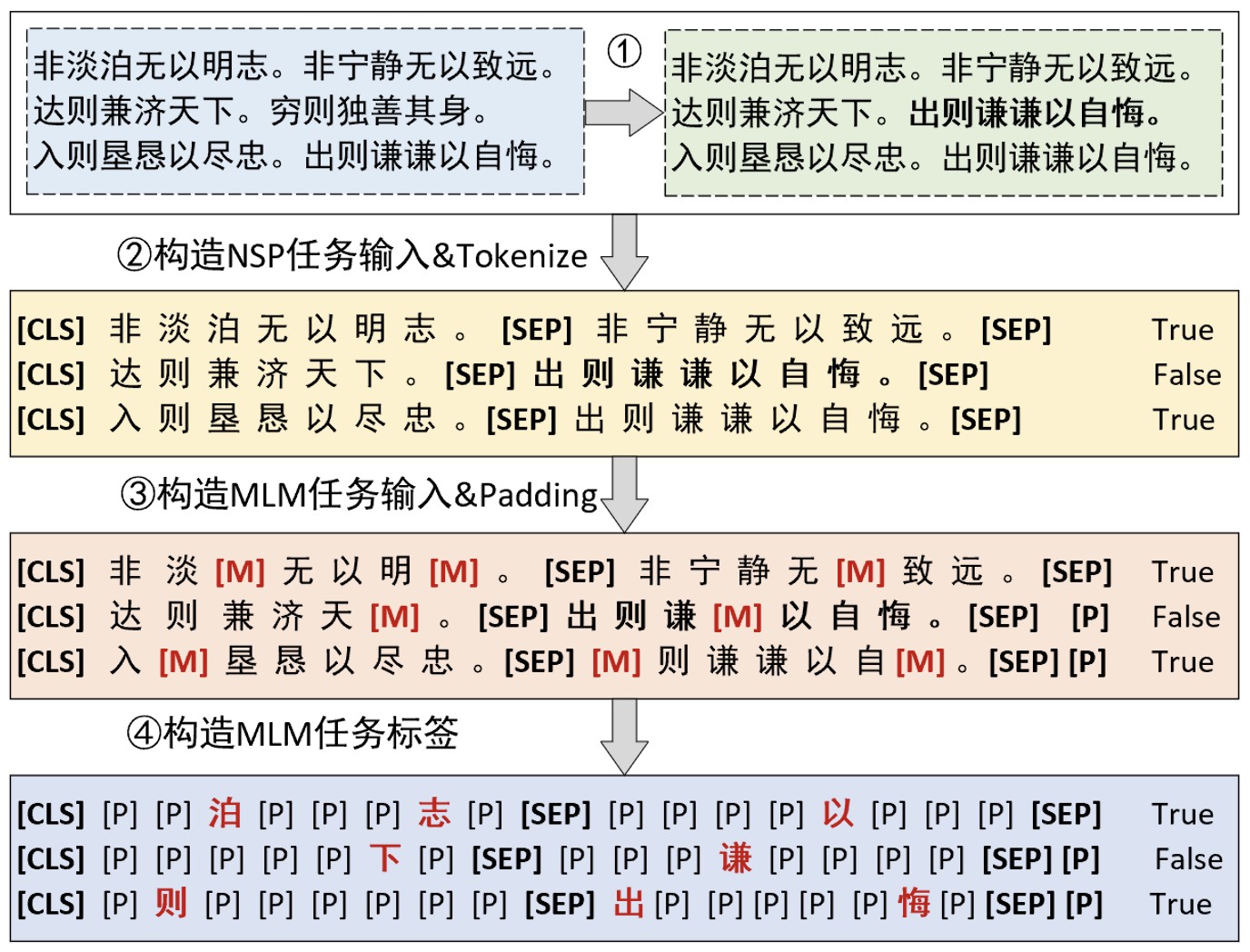
如图10-38所示便是整个NSP和MLM任务数据集的构建流程。第①②步是根据原始语料来构造NSP任务所需要的输入和标签。第③步则是随机掩盖掉部分字符来构造MLM任务的输入,并同时进行填充处理。第④步则是根据第③步处理后的结果来构造MLM任务的标签值,其中[P]表示填充的含 义,这样做的目的是为了方面在计算损失时直接忽略那些不需要进行预测的位置。在大致清楚了整个数据集的构建流程后,我们下面就可以一步一步来完成数据集的构建。
同时,为了能够使得整个数据预处理代码具有通用性,同时支持构造不同场景语料下的训练数据集,因此我们需要为每一类不同的数据源定义一个格式化函数来完成标准化的输入。这样即使是换了不同的语料只需要重写一个针对该数据集的格式化函数即可,其余部分的代码都不需要进行改动。
2. 英文数据格式化
这里首先以英文维基百科数据wiki2 [1]为例来介绍如何得到格式化后的标准数据。如下所示便是wiki2中的原始文本数据的存储形式:
1 The development of [UNK] powder , based on [UNK] or [UNK] , by the French inventor Paul [UNK] in 1884 was a further step allowing smaller charges of propellant with longer barrels . The guns of the pre @-@ [UNK] battleships of the 1890s tended to be smaller in calibre...
2 The nature of the projectiles also changed during the ironclad period . Initially , the best armor @-@ piercing [UNK] was a solid cast @-@ iron shot . Later , shot of [UNK] iron , a harder iron alloy , gave better armor @-@ piercing qualities . Eventually the armor @-@ piercing shell was developed .在上述示例数据中,每一行都表示一个段落,其由一句话或多句话组成。此时我们需要在目录utils下新建create_pretraining_data.py模块,然后定义一个函数来对其进行预处理:
1 def read_wiki2(filepath=None, seps='.'):
2 with open(filepath, 'r') as f:
3 lines = f.readlines()
4 paragraphs = []
5 for line in tqdm(lines, ncols=80, desc=" ## 正在读取原始数据"):
6 if len(line.split(' . ')) < 2:
7 continue
8 line = line.strip()
9 paragraphs.append([line[0]])
10 for w in line[1:]:
11 if paragraphs[-1][-1][-1] in seps:
12 paragraphs[-1].append(w)
13 else:
14 paragraphs[-1][-1] += w
15 random.shuffle(paragraphs) # 将所有段落打乱
16 return paragraphs在上述代码中,第1行seps用于指定句子与句子之间的分隔符。第2~3行用于一次读取所有原始数据,每一行为一个段落。第5~14行用于遍历每一个段落, 并进行相应的处理。第6~7行用于过滤掉段落中只有一个句子的情况,因为后续我们要构造NSP任务所以一个段落至少要有两句话。第8行用于去掉整个段落两端的空格或换行符。第9~14行开始遍历段落中的每一句话并进行分割,同时保留了分隔符在句子中。第15行则是将所有的段落给打乱,注意不是句子。
最终,经过read_wiki2()函数处理后,我们便能得到一个标准的二维列表,格式形如:
1 [ [sentence_a1, sentence_a2, ...], [sentence_b1, sentence_b2,...],...,[] ]上述格式就是后续代码处理时所接受的标准格式,如果需要引入自己的数据那么只需要处理成这样的格式即可。
3. 中文数据格式化
在介绍完英文数据集的格式化过程后我们再来看一个中文原始数据的格式化过程。如下所示便是我们后续所需要用到的中文宋词数据集:
1 红酥手,黄縢酒,满城春色宫墙柳。东风恶,欢情薄。一怀愁绪,几年离索。错错错。 春如旧,人空瘦,泪痕红鲛绡透。桃花落。闲池阁。山盟虽 在,锦书难托。莫莫莫。
2 十年生死两茫茫。不思量。自难忘。千里孤坟,无处话凄凉。纵使相逢应不识,尘满面,鬓如霜。夜来幽梦忽还乡。小轩窗。正梳妆。相顾无言,惟有 泪千行。料得年年断 肠处,明月夜,短松冈。在上述示例中,每一行表示一首词,句与句之间通过句号进行分割。下面我们同样需要定义一个函数来对其进行预处理并返回指定的标准格式:
1 def read_songci(filepath=None, seps='。'):
2 with open(filepath, 'r', encoding='utf-8') as f:
3 lines = f.readlines()
4 paragraphs = []
5 for line in tqdm(lines, ncols=80, desc=" ## 正在读取原始数据"):
6 if "□" in line or "……" in line or len(line.split('。')) < 2:
7 continue
8 paragraphs.append([line[0]])
9 line = line.strip()
10 for w in line[1:]:
11 if paragraphs[-1][-1][-1] in seps:
12 paragraphs[-1].append(w)
13 else:
14 paragraphs[-1][-1] += w
15 random.shuffle(paragraphs)
16 return paragraphs上述代码中整体上与read_wiki2()函数一致,所以就不再赘述。
10.12.2 数据预处理#
在正式构造NSP任务数据之前,我们需要在create_pretraining_data.py模块中先定义一个类并定义相关的类成员变量以方便在其它成员方法中使用,核心示例代码如下所示:
1 class LoadBertPretrainingDataset(object):
2 def __init__(self, vocab_path='./vocab.txt', tokenizer=None,
3 batch_size=32, max_sen_len=None, max_position_embeddings=512,
4 pad_index=0, is_sample_shuffle=True, random_state=2021,
5 data_name='wiki2', masked_rate=0.15,seps="。",
6 masked_token_rate=0.8, masked_token_unchanged_rate=0.5):
7 self.vocab = build_vocab(vocab_path)
8 self.max_sen_len = max_sen_len
9 self.pad_index = pad_index
10 self.data_name = data_name
11 self.masked_rate = masked_rate
12 self.masked_token_rate = masked_token_rate
13 random.seed(random_state)紧接着,需要定义一个成员函数来封装格式化原始数据集的函数,实现代码如下所示:
1 def get_format_data(self, file_path):
2 if self.data_name == 'wiki2':
3 return read_wiki2(file_path, self.seps)
4 elif self.data_name == 'custom':
5 return read_custom(file_path)
6 elif self.data_name == 'songci':
7 return read_songci(file_path, self.seps)从上述代码可以看出,该函数的作用就是给出了一个标准化的格式化函数 调用方式,可以根据指定的数据集名称返回相应的格式化函数。但是需要注意 的是,格式化函数返回的格式需要同 read_wiki2()函数返回的样式保持一致。
1. 构造NSP任务数据
进一步,我们便可以来定义构造NSP任务数据的处理函数,用来根据给定的连续两句话和对应的段落返回NSP任务中的句子对和标签,示例代码如下所示:
1 def get_next_sentence_sample(sentence, next_sentence, paragraphs):
2 if random.random() < 0.5:
3 is_next = True
4 else:
5 new_next_sentence = next_sentence
6 while next_sentence == new_next_sentence:
7 new_next_sentence = random.choice(random.choice(paragraphs))
8 next_sentence = new_next_sentence
9 is_next = False
10 return sentence, next_sentence, is_next在上述代码中,第2行用于根据均匀分布产生$[0,1)$之间的一个随机数作为概率值。第5~9行是先从所有段落中随机出一个段落,再从随机出的一个段落中随机出一句话,以此来随机选择下一句话,其中第6~7行是防止随机选择的下 一个句子仍旧与之前的相同。第10行是返回构造好的一条 NSP任务样本。后续我们只需要调用get_next_sentence_sample()方法即可构造NSP样本。
2. 构造MLM任务数据
为了方便后续构造MLM任务样本,我们这里需要先定义一个辅助函数来根据给定的索引和候选掩盖位置以及需要掩盖的字符数量来返回被掩盖后的索引和标签信息,示例代码如下所示:
1 def replace_masked_tokens(self, token_ids, candidate_pred_pos, num_mlm):
2 pred_positions = []
3 mlm_input_tokens_id = [token_id for token_id in token_ids]
4 for mlm_pred_position in candidate_pred_pos:
5 if len(pred_positions) >= num_mlm:
6 break
7 masked_token_id = None
8 if random.random() < self.masked_token_rate:
9 masked_token_id = self.MASK_IDS
10 else:
11 if random.random() < self.masked_token_unchanged_rate:
12 masked_token_id = token_ids[mlm_pred_position]
13 else:
14 masked_token_id = random.randint(0, len(self.vocab.stoi) - 1)
15 mlm_input_tokens_id[mlm_pred_position] = masked_token_id
16 pred_positions.append(mlm_pred_position)
17 mlm_label = [self.PAD_IDX if idx not in pred_positions
18 else token_ids[idx] for idx in range(len(token_ids))]
19 return mlm_input_tokens_id, mlm_label在上述代码中,第1行里token_ids表示经过get_next_sentence_sample()函数处理后的上下句,且已经转换为词表索引后的结果,candidate_pred_pos表示所有可能被掩盖掉的候选位置,num_mlm表示根据$15\%$的比例计算出来需要被掩盖掉的位置数量。第4~6行为依次遍历每一个候选字符的索引,如果已满足需要被掩盖的数量则跳出循环。第8~9行表示将其中$80\%$的索引替换为[MASK],即$15\%$中的$80\%$。第10~14行是分别保持$10\%$的位置不变以及将另外$10\%$替换为随机索引。第15~16行是对索引进行替换,以及记录下哪些位置上的索引进行了替换。第17~18 行是根据已记录的索引替换信息得到对应的标签信息,其做法便是如果该位置没出现在pred_positions中则表示该位置是不需要被预测的对象,因此在进行损失计算时需要忽略掉这些位置,即为PAD_IDX;而如果其出现在掩盖的位置, 则其标签为原始正确索引值,即正确标签。
例如以下输入:
1 token_ids = [101, 1031, 4895, 2243, 1033, 10029, 2000, 2624, 1031,....]
2 candidate_pred_positions = [2,8,5,9,7,3...]
3 num_mlm_preds = 5经过函数replace_masked_tokens()方法处理后的结果则类似为:
1 mlm_input_tokens_id = [101,1031,103,2243,1033, 10029, 2000, 103, 1031, ...]
2 mlm_label = [ 0, 0, 4895, 0, 0, 0, 0, 2624, 0,...]在这之后,我们便可以定义一个函数来构造MLM任务所需要用到的训练数据,示例代码如下所示:
1 def get_masked_sample(self, token_ids):
2 candidate_pred_positions = []
3 for i, ids in enumerate(token_ids):
4 if ids in [self.CLS_IDX, self.SEP_IDX]:
5 continue
6 candidate_pred_positions.append(i)
7 random.shuffle(candidate_pred_positions)
8 num_mlm_preds = max(1, round(len(token_ids) * self.masked_rate))
9 mlm_input_tokens_id, mlm_label = self.replace_masked_tokens(
10 token_ids, candidate_pred_positions, num_mlm_preds)
11 return mlm_input_tokens_id, mlm_label在上述代码中,第1行token_ids便是一个样本的索引序列。第3~6行用来记录所有可能进行掩盖的字符的索引,并同时排除掉特殊字符。第7行是将所有候选位置打乱,更利于后续随机抽取。第8行是用来计算需要进行掩盖的位置的数量,例如原始论文中是$15\%$ 。第9~10行便是上面介绍到的replace_masked_tokens()方法。第11行是返回最终MLM 任务和NSP任务的输mlm_input_tokens_id和MLM任务的标签mlm_label。
3. 构造整体任务数据
在分别介绍完MLM和NSP两个任务各自样本的构造方法后,下面我们再通过一个方法将两者组合起来便得到了最终整个样本数据的构建过程,示例代码如下所示:
1 def data_process(self, file_path):
2 paragraphs = self.get_format_data(file_path)
3 data, max_len = [], 0
4 for paragraph in tqdm(paragraphs, ncols=80):
5 for i in range(len(paragraph) - 1):
6 sentence, next_sentence, is_next = self.get_next_sentence_sample(
7 paragraph[i], paragraph[i + 1], paragraphs)
8 token_a_ids = [self.vocab[token] for token in self.tokenizer(sentence)]
9 token_b_ids = [self.vocab[token] for token in self.tokenizer(next_sentence)]
10 token_ids = [self.CLS_IDX] + token_a_ids + [self.SEP_IDX] + token_b_ids
11 seg1, seg2 = [0] * (len(token_a_ids) + 2), [1] * (len(token_b_ids) + 1)
12 segs = seg1 + seg2
13 if len(token_ids) > self.max_position_embeddings - 1:
14 token_ids = token_ids[:self.max_position_embeddings - 1]
15 segs = segs[:self.max_position_embeddings]
16 token_ids += [self.SEP_IDX]
17 segs = torch.tensor(segs, dtype=torch.long)
18 nsp_lable = torch.tensor(int(is_next), dtype=torch.long)
19 mlm_input_tokens_id, mlm_label = self.get_masked_sample(token_ids)
20 token_ids = torch.tensor(mlm_input_tokens_id, dtype=torch.long)
21 mlm_label = torch.tensor(mlm_label, dtype=torch.long)
22 max_len = max(max_len, token_ids.size(0))
23 data.append([token_ids, segs, nsp_lable, mlm_label])
24 all_data = {'data': data, 'max_len': max_len}
25 return all_data在上述代码中,第3行max_len用来记录整个数据集中最长序列的长度,在后续可将其作为填充长度的标准。从第4~5行开始,便是依次遍历每个段落以及段落中的每个句子来构造MLM和NSP任务样本。第6~7行用于构建NSP任务数据样本。第8~16行是将得到的字符序列转换为词表索引,其中13~15行用于判断序列长度,对于超出部分进行截取。第18行是构造NSP任务的真实标签。第19~21行是是分别构造MLM任务的输入和标签。第23行是将每个构造完成的样本保存到data列表中。第24~25行是返回最终生成的结果。
例如在处理宋词语料时,上述代码便会输出如下类似结果:
1 ## 当前句文本: 风住尘香花已尽,日晚倦梳头 ## 下一句文本:锦书欲寄鸿难托 ## 下一句标签:False
2 ## Mask前词元结果:['[CLS]', '风', '住', '尘', '香', '花', '已', '尽', ',', '日', '晚', '倦',
3 '梳', '头','[SEP]', '锦', '书', '欲','寄', '鸿','难', '托','[SEP]']
4 ## Mask前token ids:[101, 7599, 857, 2212, 7676, 5709, 2347, 2226, 8024, 3189, 3241,
5 958, 3463, 1928, 102, 7239, 741, 3617, 2164, 7896, 7410, 2805, 102]
6 ## segment ids:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],序列长度为 23
7 ## Mask数量为: 3
8 ## Mask后token ids:[101, 7599, 857, 2212, 103, 5709, 2347, 103, 8024, 3189, 3241, 103,
9 3463, 1928, 102, 7239, 741, 3617, 2164, 7896, 7410, 2805, 102]
10 ## Mask后词元结果:['[CLS]','风', '住', '尘','[MASK]','花','已','[MASK]', ',', '日','晚','[MASK]',
11 '梳','头','[SEP]', '锦','书', '欲','寄','鸿','难','托', '[SEP]']
12 ## Mask后label ids:[0, 0, 0, 0, 7676, 0, 0, 2226, 0, 0, 0, 958, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]进一步,我们只需要再完成填充处理便能够完成数据集的构建过程,这部分实现各位读者直接阅读源码即可。
10.12.3 预训练任务实现#
为了能够对这两部分的代码实现有着更加清晰的认识我们将先分别来实现这两个任务,最后再将两者结合到一起来实现BERT预训练任务。
1. NSP任务实现
整体来看NSP任务实现较为简单,直接取[CLS]位置上的向量进行分类即可,示例代码如下所示:
1 class BertForNextSentencePrediction(nn.Module):
2 def __init__(self, config, bert_model_dir=None):
3 super(BertForNextSentencePrediction, self).__init__()
4 if bert_model_dir is not None:
5 self.bert = BertModel.from_pretrained(config, bert_model_dir)
6 else:
7 self.bert = BertModel(config)
8 self.classifier = nn.Linear(config.hidden_size, 2)
9
10 def forward(self, input_ids, attention_mask=None, token_type_ids=None,
11 position_ids=None, next_sentence_labels=None):
12 pooled_output, _ = self.bert( input_ids,attention_mask,
13 token_type_ids,position_ids)
14 seq_relationship_score = self.classifier(pooled_output)
15 if next_sentence_labels is not None:
16 loss_fct = nn.CrossEntropyLoss()
17 loss = loss_fct(seq_relationship_score.view(-1, 2),
18 next_sentence_labels.view(-1))
19 return loss
20 else:
21 return seq_relationship_score上述代码便是整个NSP任务的实现过程,可以看到其本质上就是一个文本分类任务,所以这里我们就不再赘述。
2. MLM任务实现
相较于NSP任务,MLM任务的实现则稍显复杂。如同命名体识别任务一样,它需要将BERT模型最后一层的整个输出进行一次变换和标准化,然后再做字符级的分类任务来预测被掩盖部分对应的值,这个网络结构如图10-39所示。
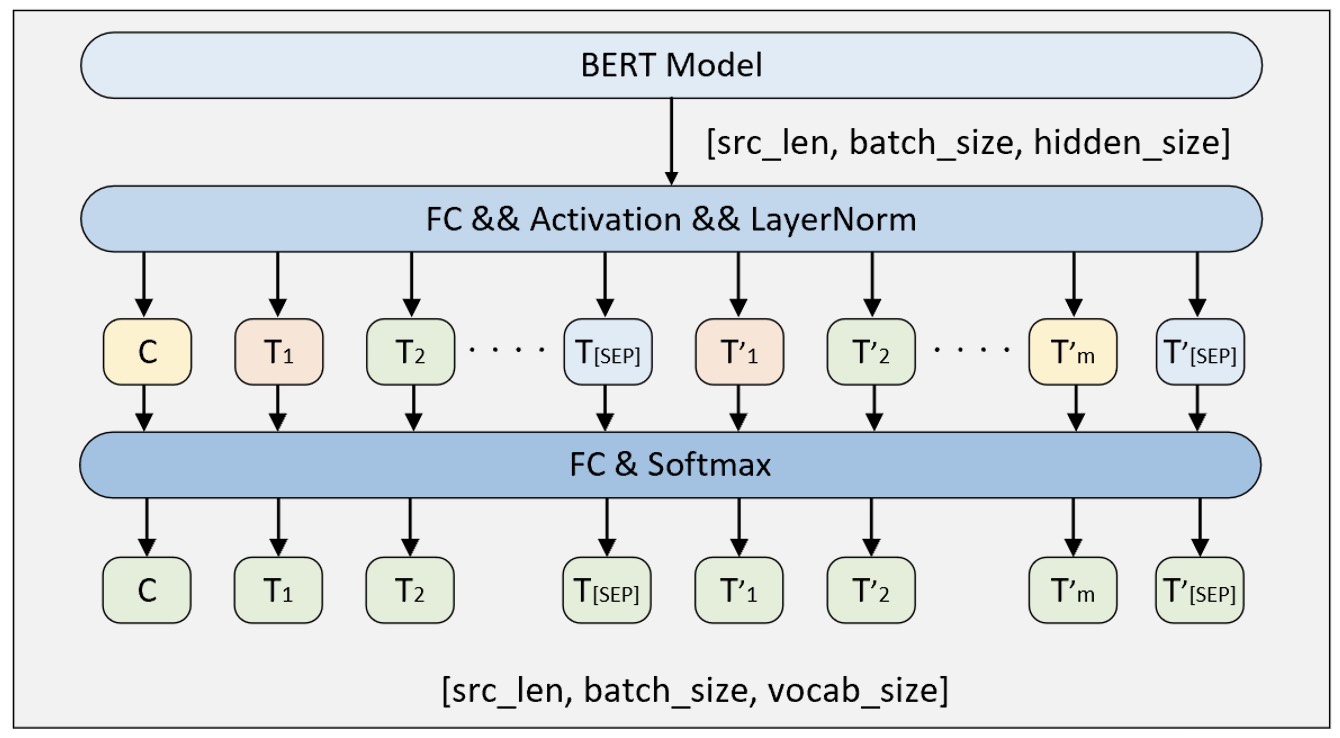
如图10-39所示便是构造MLM任务的流程示意图。首先取BERT模型最后一层的输出,形状为[src_len,batch_size,hidden_size];然后再经过一次线性变换和标准化,形状同样为[src_len,batch_size,hidden_size];最后再经过一个分类层对每个位置上的向量进行分类处理便得到了最后的预测结果,形状为[src_len,batch_s ize,vocab_size]。
此时我们便可以定义类BertForLMTransformHead来完成上述3个步骤,示例代码如下所示:
1 class BertForLMTransformHead(nn.Module):
2 def __init__(self, config, bert_model_embedding_weights=None):
3 super(BertForLMTransformHead, self).__init__()
4 self.dense = nn.Linear(config.hidden_size, config.hidden_size)
5 if isinstance(config.hidden_act, str):
6 self.transform_act_fn = get_activation(config.hidden_act)
7 else:
8 self.transform_act_fn = config.hidden_act
9 self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=1e-12)
10 self.decoder = nn.Linear(config.hidden_size, config.vocab_size)
11 if bert_model_embedding_weights is not None:
12 self.decoder.weight = nn.Parameter(bert_model_embedding_weights)
13 self.decoder.bias = nn.Parameter(torch.zeros(config.vocab_size))
14
15 def forward(self, hidden_states):
16 hidden_states = self.dense(hidden_states)
17 hidden_states = self.transform_act_fn(hidden_states)
18 hidden_states = self.LayerNorm(hidden_states)
19 hidden_states = self.decoder(hidden_states)
20 return hidden_states在上述代码中,第4~8行用来定义相应的(非)线性变换。第9~10行用来定义对应的标准化和最后的分类层。第11~12是用来判断最后分类层中的权重参数是否复用BERT模型TokenEmbedding层中的权重参数,因为MLM任务最后的预测类别就等于TokenEmbedding中的各个词,所以最后分类层中的权重参数可以复用[2]。第15行开始是对应的前向传播过程。第16~18行处理后的结果形状均为[src_len, batch_size, hidden_size]。第19行是最后分类层的计算结果,形状为[src_len, batch_size, vocab_size]。
进一步,我们可以通过如下代码来实现MLM任务:
1 class BertForMaskedLM(nn.Module):
2 def __init__(self, config, bert_model_dir=None):
3 super(BertForMaskedLM, self).__init__()
4 if bert_model_dir is not None:
5 self.bert = BertModel.from_pretrained(config, bert_model_dir)
6 else:
7 self.bert = BertModel(config)
8 weights = None
9 if config.use_embedding_weight:
10 weights = self.bert.bert_embeddings.word_embeddings.embedding.weight
11 self.classifier = BertForLMTransformHead(config, weights)
12 self.config = config
13
14 def forward(self, input_ids, attention_mask=None, token_type_ids=None,
15 position_ids=None, masked_lm_labels=None):
16 _, all_encoder_outputs = self.bert(input_ids, attention_mask,
17 token_type_ids, position_ids)
18 sequence_output = all_encoder_outputs[-1]
19 logits = self.classifier(sequence_output)
20 if masked_lm_labels is not None:
21 loss_fct = nn.CrossEntropyLoss(ignore_index=0)
22 lm_loss = loss_fct(logits.reshape(-1, self.config.vocab_size),
23 masked_lm_labels.reshape(-1))
24 return lm_loss
25 else:
26 return logits 在上述代码中,第4~7行用于返回得到原始的BERT模型。第8~10行是取TokenEmbedding层中的权重参数。第11行是返回得到MLM任务分类层实例化后的类对象。第16~18行是返回得到BERT模型的所有层输出并只取最后一层,此时的形状为[src_len, batch_size, hidden_size]。第19行是完成最后MLM中分类任务的输出,形状为[src_len, batch_size, vocab_size]。第20~16行是根据标签是否为空来返回不同的输出结果。
3. 前向传播
在分别实现NSP和MLM这两个任务以后,便可以整合得到整个BERT预训练任务的实现,示例代码如下所示:
1 class BertForPretrainingModel(nn.Module):
2 def __init__(self, config, bert_model_dir=None):
3 super(BertForPretrainingModel, self).__init__()
4 if bert_model_dir is not None:
5 self.bert = BertModel.from_pretrained(config, bert_model_dir)
6 else:
7 self.bert = BertModel(config)
8 weights = None
9 if 'use_embedding_weight' in config.__dict__
10 and config.use_embedding_weight:
11 weights = self.bert.bert_embeddings.word_embeddings.embedding.weight
12 self.mlm_prediction = BertForLMTransformHead(config, weights)
13 self.nsp_prediction = nn.Linear(config.hidden_size, 2)
14 self.config = config在上述代码中,第9~11行是判断是否使用TokenEmbedding层中的权重参数。第12~13行分别是返回得到实例化后的MLM和NSP任务模型。
进一步,整个前向传播的计算实现过程如下所示:
1 def forward(self, input_ids, attention_mask=None,
2 token_type_ids=None, position_ids=None,
3 masked_lm_labels=None, nsp_label=None):
4 output, all_outputs = self.bert(input_ids,attention_mask,
5 token_type_ids,position_ids)
6 sequence_output = all_outputs[-1]
7 mlm_logits = self.mlm_prediction(sequence_output)
8 nsp_logits = self.nsp_prediction(output)
9 if masked_lm_labels is not None and nsp_label is not None:
10 loss_mlm = nn.CrossEntropyLoss(ignore_index=0)
11 loss_nsp = nn.CrossEntropyLoss()
12 mlm_loss = loss_mlm(mlm_logits.reshape(-1, self.config.vocab_size),
13 masked_lm_labels.reshape(-1))
14 nsp_loss = loss_nsp(nsp_logits.reshape(-1, 2),
15 nsp_label.reshape(-1))
16 total_loss = mlm_loss + nsp_loss
17 return total_loss, mlm_logits, nsp_logits
18 else:
19 return mlm_logits, nsp_logits在上述代码中,第1~4行是模型所接收的所有输入,其中input_ids、token_type_ids和masked_lm_labels的形状均为[src_len, batch_size],attention_mask的形状为[batch_size, src_len],nsp_label的形状为[batch_size]。第4~8行是返回BERT模型的所有输出,并分别取不同部分来进行后续的MLM和NSP任务,此时sequence_output的形状为[src_len, batch_size, hidden_size],mlm_logits的形状为[src_len, batch_size, vocab_size],nsp_logits的形状为[batch_size, 2]。第9~19行是根据是否有标签输入来返回不同的输出结果,同时需要注意的是第16行返回的是两个任务的损失和作为整体模型的损失值。
10.12.4 模型训练与微调#
1. 模型训练
在实现完整个预训练部分的代码实现后便可以开始进行模型训练,并且经过训练完成之后的权重参数又可以继续在下游任务中进行微调。对于整个模型训练部分的代码和前面几个微调任务中的类似,所以这里就不再赘述各位读者直接阅读源码即可。最终,模型的在宋词数据集上将会得到类似如图10-40中的损失值和准确率变化情况。
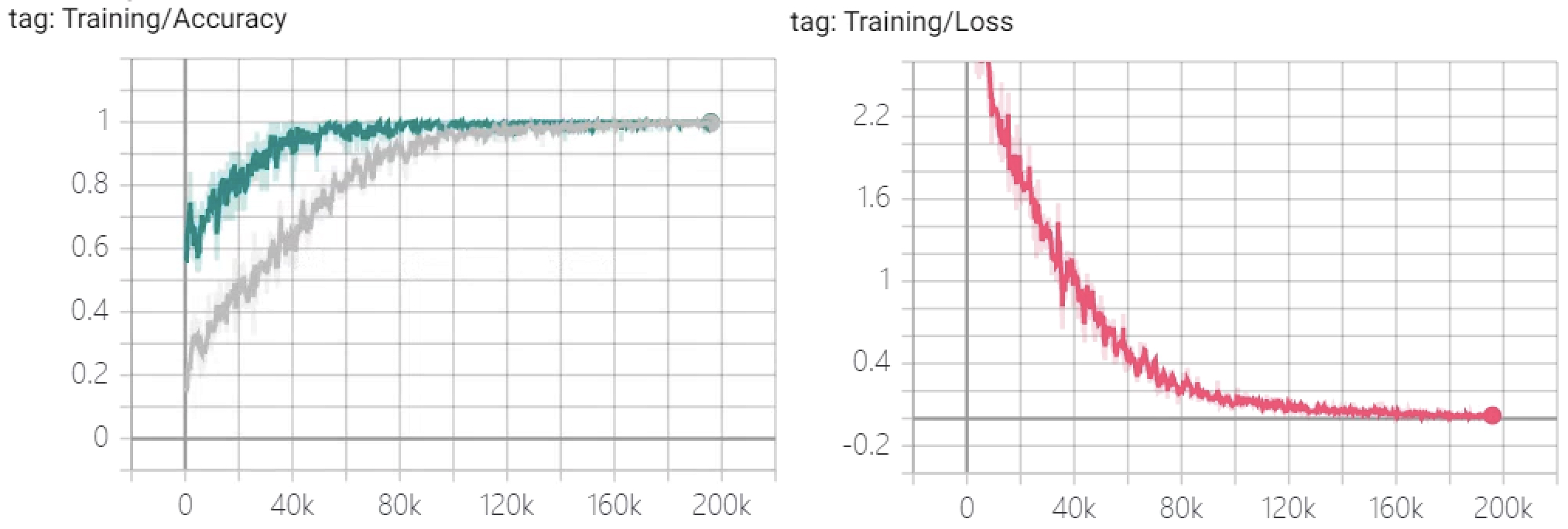
如图10-40所示,左侧上方为NSP任务在训练集上准确率的变化情况,下方为MLM任务在训练集上准确率的变化情况;右侧为NSP和MLM两个预训练任务整体损失的变化情况。
2. 模型推理
在模型训练部分的内容介绍完毕后,我们再来看模型推理部分的实现。 对于推理部分的实现总体思路为:①将测试样本构造为模型所接受的输入格式;②通过模型前向传播得到预测结果输出;③对模型输出结果进行格式化处理得到最终的预测结果。
对于模型推理部分的实现示例代码如下所示:
1 def inference(config, sentences=None, masked=False, language='en', random_state=None):
2 bert_tokenize = BertTokenizer.from_pretrained(config.model_dir).tokenize
3 data_loader = LoadBertPretrainingDataset(...)
4 token_ids, pred_idx, mask = data_loader.make_inference_samples(
5 sentences,masked,language,random_state)
6 model = BertForPretrainingModel(config,config.model_dir)
7 if os.path.exists(config.model_save_path):
8 checkpoint = torch.load(config.model_save_path)
9 loaded_paras = checkpoint['model_state_dict']
10 model.load_state_dict(loaded_paras)
11 else:
12 raise ValueError(f"模型 {config.model_save_path} 不存在!")
13 with torch.no_grad():
14 mlm_logits, _ = model(input_ids=token_ids,attention_mask=mask)
15 pretty_print(token_ids, mlm_logits, pred_idx,
16 data_loader.vocab.itos, sentences, language)在上述代码中,第3行是初始化类LoadBertPretrainingDataset,同时需要说明的是由于是推理场景所以构造样本时masked_rate可以是任意值,不用局限$15\%$。第4~5行是将传入的测试样本转换为模型所接受的形式,其中masked参数是用来指定输入的测试样本有没进行掩盖操作,如果没有则自动按masked_rate的比例进行掩盖操作;language参数是指定测试样本的语种类型。第7~10行是载入本地持久化的权重参数来初始化模型。第13~14行是得到模型前向传播的输出结果。第15~16行是根据模型的前向传播输出结果来格式化得到最后的输出形式。
最终,可以通过如下方式来完成模型的推理过程,示例代码如下所示:
1 if __name__ == '__main__':
2 config = ModelConfig()
3 sentences_2 = ["十年生死两茫茫。不思量。自难忘。千里孤坟,无处话凄凉。",
4 "红酥手。黄藤酒。满园春色宫墙柳。"]
5 inference(config, sentences, masked=False, language='zh',random_state=2022)上述代码运行结束后将会得到类似如下所示结果:
1 ### 原始: 我住长江头,君住长江尾。
2 ## 掩盖: 我住长江头,[MASK]住长[MASK]尾。
3 ## 预测: 我住长江头,君住长河尾。
4 ### 原始: 日日思君不见君,共饮长江水。
5 ## 掩盖: 日日思君不[MASK]君,共[MASK]长江水。
6 ## 预测: 日日思君不见君,共饮长江水。3. 模型微调
在介绍完整个预训练模型的实现和训练过程后,最后一步便是如何将训练得到的模型继续运用在下游任务中。实现这一目的只需要将保存好的模型重新命名为pytorch_model.bin,然后替换掉之前的文件即可。这样就可以像在前面介绍的下游任务中一样对模型进行微调了。
10.12.5 小结#
在本节内容中,我们首先介绍了NSP和MLM这两个预训练任务数据集的整体构建流程;然后详细介绍了构建整个数据集的编码过程;进一步,我们介绍了如何借助PyTorch框架来一步步实现整个预训练任务以及模型的训练过程;最后介绍了如何将训练持久化的模型运用于推理过程中,并同时进行了示例。到此,对于BERT模型的原理、使用和训练等内容就介绍完了。
引用#
[1] https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip
[2] https://github.com/google-research/bert/