7.6 CharRNN网络#
经过前面几节内容的介绍,我们已经清楚了RNN模型及其变体的相关原理,并且在「第7.2节 时序数据建模:RNN 适合处理什么样的序列任务」内容中我们也通过两个实例详细介绍了RNN中多对一任务的构建流程。在本节内容中,我们将会以古诗词生成为例来介绍了RNN中的多对多任务类型,即图7-3中的第3种情况。
7.6.1 任务构造原理#
对于接下来要介绍的古诗生成模型其本质上就是一个简单的RNN模型,也被称为字符级循环神经网络CharRNN[1]。CharRNN通过将序列$t_1,t_2,...,t_{n-1},t_n$作为模型输入,将$t_2,t_3,...,t_n,t_{n+1}$作为标签来训练模型,整个网络结构如图7-14所示。
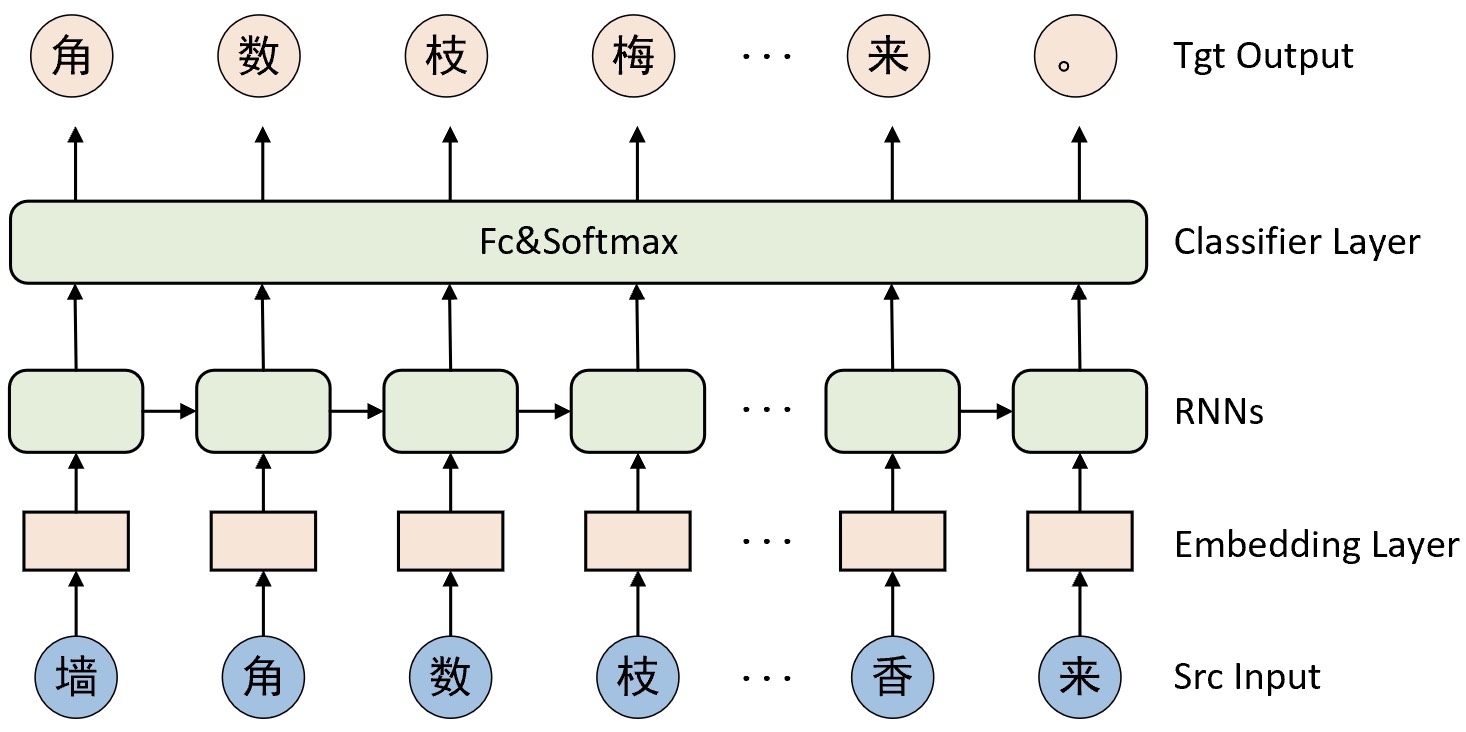
如图7-14所示,最下面为原始输入(Src Input),在转换为词表中的索引后便输入到词嵌入层(Embedding Layer)中。简单来讲,词嵌入层是一个包含有$m$行$n$列的网络层,其中$m$表示词表中词的数量,$n$表示向量的维度,即词嵌入层的作用是将词表中的每个词通过一个$n$维向量来进行表示。更多关于词嵌入层的内容将在「第9.5节 词向量微调使用:预训练词向量在下游任务中的应用」中进行介绍。
在经过词嵌入层的处理之后再将该结果输入到循环神经网络中;然后再将循环神经网络输出结果中的每个时刻进行分类处理,并且因为这里的预测结果是词表中的其中一个词,所以其分类类别数便是词表的长度;最后将模型的预测结果同正确标签进行损失计算并完成整个模型的训练。
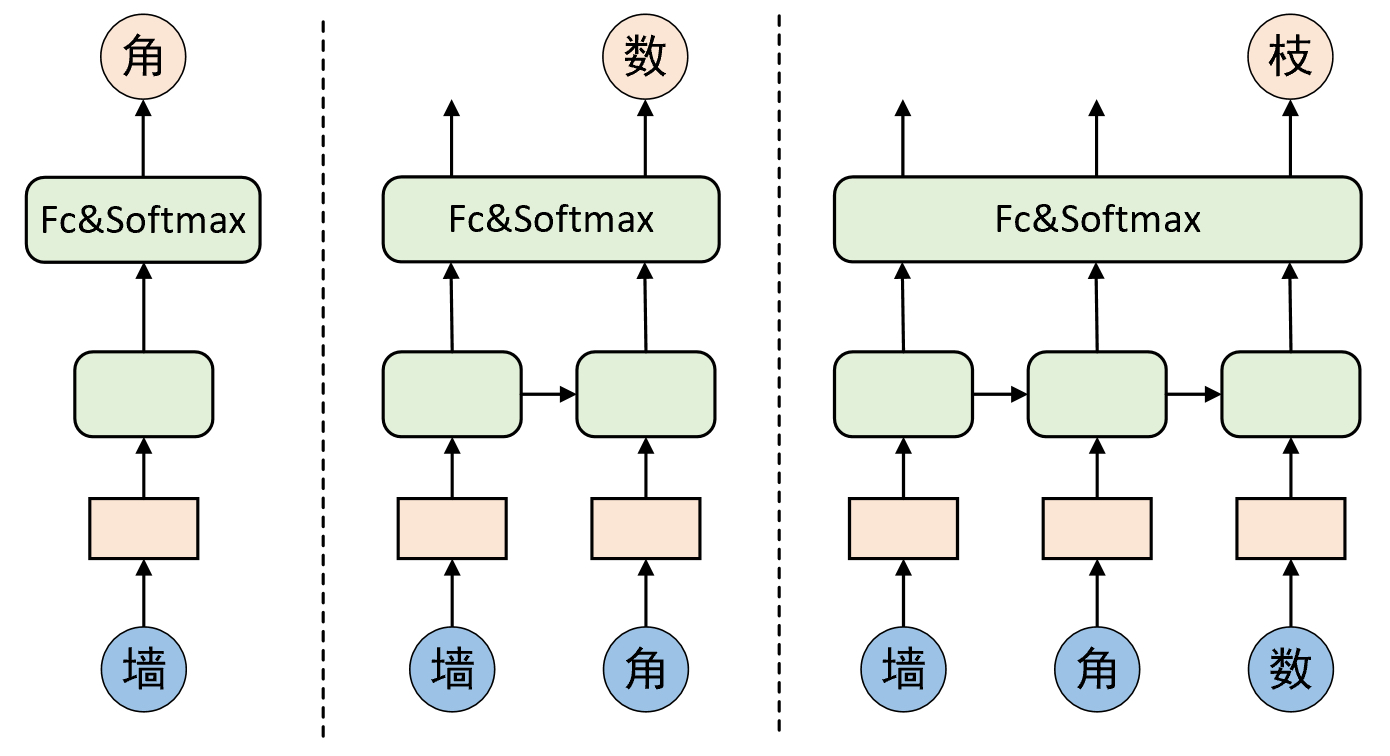
当模型训练完成之后,可以通过给模型输入一个序列片段来循环完成固定长度序列的生成任务,整个预测过程原理如图7-15所示。
7.6.2 数据预处理#
1. 数据集介绍
在清楚整个模型的训练和预测过程后,我们再来如何从零构建模型训练所需要的数据集。这里我们所使用到的是一个全唐诗[2]的数据集,一共有58个json文件共计大约5.8万余首古诗。在每个json文件中,文本内容的存储形式如下所示。
1 [{"author": "王安石",
2 "paragraphs": ["墙角数枝梅,凌寒独自开。","遥知不是雪,为有暗香来。"],
3 "title": "梅花",
4 "id": "ae7391fc-aef5-4f59-ae25-a7e7a9ee0858"},
5 {"author": "佚名",
6 "paragraphs": ["自伯东去,首如飞蓬。","岂无膏沐,谁适为容。"],
7 "title": "诗经·国风·卫风",
8 "id": "0f0b345d-c074-4ec7-bde1-e28438712b7b"}]从上述结果可以看出,整个json文件的最外层是一个列表,列表中的每个元素便是一个包含有一首古诗的字段,后续我们将只取每首古诗中的paragraphs来构建数据集。
2. 预处理流程
在正式介绍如何构建数据集之前我们先通过一张图了解一下整体的构建流程。假如现在有两个样本构成了一个小批量,那么其整个数据的处理流程如图7-16所示。
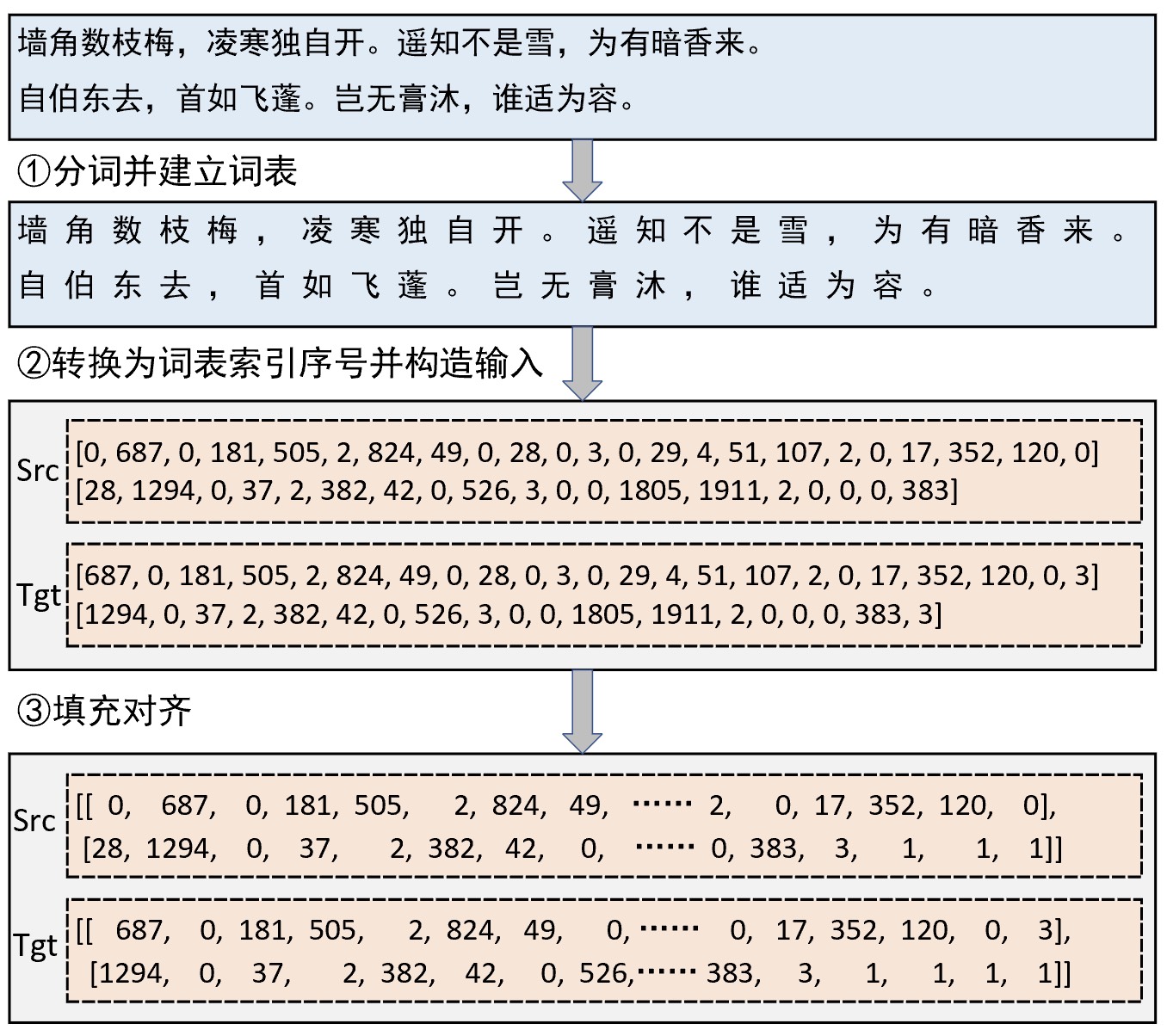
注:图7-16中的词表是以整个训练集为语料构建而成,并非只由上述两个样本构建,其中0表示['UNK'],1表示['PAD']。
如图7-16所示,首先我们需要将原始json格式的语料抽取出出来;然后再以此为基础对句子进行分词(字)并构建词表;接着再将样本句子中的每个词转换为词表中对应的索引序号得到原始输入Src,并同时将原始输入向左平移一位得到真实标签Tgt;最后在输入模型之前再对其进行填充处理以使得每个小批量中所有样本的长度一致。
3. 格式化样本和 Tokenize
首先,我们定义一个类TangShi并继承自在第7.2.4节中介绍的TouTiaoNews类以复用其中的部分方法,同时初始化原始数据的相关存储路径,示例代码如下所示:
1 class TangShi(TouTiaoNews):
2 DATA_DIR = os.path.join(DATA_HOME, 'peotry_tang')
3 FILE_PATH = [os.path.join(DATA_DIR, 'poet.tang.0-55.json'),
4 os.path.join(DATA_DIR, 'poet.tang.56-56.json'),
5 os.path.join(DATA_DIR, 'poet.tang.57-57.json')]
6 def __init__(self, *args, **kwargs):
7 super(TangShi, self).__init__(*args, **kwargs)
8 self.ends = [self.vocab.stoi["。"], self.vocab.stoi["?"]]在上述代码中,第2行用来指定原始数据存储路径。第3~5行用来指定文件名并同时划分了训练集(poet.tang.0.json~poet.tang.55000.json)、验证集(poet.tang.56000.json~poet.tang.56000.json)和测试集(poet.tang.57000.json~poet.tang.57000.json),后续将解析其中的序号来读取相应的原始文件。第8行用来指定可能的结束符,用于生成序列时的停止条件之一。
进一步,定义load_raw_data方法来完成原始所有数据的载入,示例代码如下所示:
1 def load_raw_data(self, file_path=None):
2
3 def read_json_data(file_path):
4 samples, labels = [], []
5 with open(file_path, encoding='utf-8') as f:
6 data = json.loads(f.read())
7 for item in data:
8 content = "".join(item['paragraphs'])
9 if not skip(content):
10 samples.append(content[:-1])
11 labels.append(content[1:]) # 向左平移
12 return samples, labels
13
14 file_name = file_path.split(os.path.sep)[-1]
15 start, end = file_name.split('.')[2].split('-')
16 all_samples, all_labels = [], []
17 for i in range(int(start), int(end) + 1):
18 file_path = os.path.join(self.DATA_DIR, f'poet.tang.{i * 1000}.json')
19 samples, labels = read_json_data(file_path)
20 all_samples += samples
21 all_labels += labels
22 return all_samples, all_labels在上述代码中,第3~12行是定义一个辅助函数来读取单个的原始json文件,其中第9行为根据相应条件来判断是否将部分内容过滤,第10~11行是构造对应的输入和标签。第14~16行为根据传入的参数提取文件对应序号。第17~21行为根据拼接的文件名循环读取原始json文件。第22行为返回所有格式化后的结果。
在完成上述load_raw_data方法的实现之后,在实例化类TangShi时便可同时根据训练集完成词表的构建,详见第7.2.4节中类TouTiaoNews的初始化方法。
4. 转换为索引
在完成词表构建之后,下一步则是需要将原始古诗进行分词处理,并将其转换为词表中对应的索引,示例代码如下所示:
1 def data_process(self, file_path):
2 samples, labels = self.load_raw_data(file_path)
3 data = []
4 for i in tqdm(range(len(samples)), ncols=80):
5 x_tokens = tokenize(samples[i])
6 x_token_ids = [self.vocab[token] for token in x_tokens]
7 y_tokens = tokenize(labels[i])
8 y_token_ids = [self.vocab[token] for token in y_tokens]
9 x_token_ids_tensor = torch.tensor(x_token_ids, dtype=torch.long)
10 y_token_ids_tensor = torch.tensor(y_token_ids, dtype=torch.long)
11 data.append((x_token_ids_tensor, y_token_ids_tensor))
12 return data在上述代码中,第2行便是得到分词后的原始古诗句子和对应的标签。第5行是对输入部分的句子进行分词处理。第6行是将分词后的输入转换为词表中对应的索引。第9行则是将索引ID转换为张量类型。第11~12行是保存处理好的每个样本并返回最后的结果。
到此,对于前面两个样本来说,经过data_process方法处理后便会得到如下所示结果:
1 ## 原始样本为:
2 ## 输入为: 墙角数枝梅,凌寒独自开。遥知不是雪,为有暗香来
3 ## 分割后为: ['墙', '角', '数', '枝', '梅', ',', '凌', '寒', '独', '自', '开', '。',
4 ## '遥', '知', '不', '是', '雪', ',', '为', '有', '暗', '香', '来']
5 ## 向量化后为: [0, 687, 0, 181, 505, 2, 824, 49, 0, 28, 0, 3, 0, 29, 4, 2, 0, 17, 352, 120, 0]
6 ## 标签为: 角数枝梅,凌寒独自开。遥知不是雪,为有暗香来。
7 ## 分割后为: ['角', '数', '枝', '梅', ',', '凌', '寒', '独', '自', '开', '。',
8 ## '遥', '知', '不', '是', '雪', ',', '为', '有', '暗', '香', '来', '。']
9 ## 向量化后为: [687, 0, 181, 505, 2, 824, 49, 0, 28, 0, 3, 0, 29, 4, 2, 0, 17, 352, 120, 0, 3]
10 ... 5. 填充对齐
在完成上述所有步骤之后我们还需要对每个小批量中的样本进行填充或截断处理,以使得每个小批量中所有样本的长度相等。具体地,示例代码如下所示:
1 def generate_batch(self, data_batch):
2 batch_sentence, batch_label = [], []
3 for (sen, label) in data_batch:
4 batch_sentence.append(sen)
5 batch_label.append(label)
6 x_batch_sentence = pad_sequence(batch_sentence,
7 padding_value=self.vocab.stoi[self.vocab.PAD],
8 batch_first=True,max_len=self.max_sen_len)
9 y_batch_sentence = pad_sequence(batch_label,
10 padding_value=self.vocab.stoi[self.vocab.PAD],
11 batch_first=True,max_len=self.max_sen_len)
12 return x_batch_sentence, y_batch_sentence在上述代码中,第3~5行开始遍历一个小批量中的每个样本并分别放到两个列表中。第6~11行则是分别对模型输入和标签进行填充或截断处理,其中pad_sequence()函数的介绍可参见7.2.4节内容。第12行是返回当前小批量处理完成后的结果。
在完成上述所有实现之后,便可以通过如下方式进行使用:
1 if __name__ == '__main__':
2 tang_shi = TangShi(top_k=2000, max_sen_len=None,
3 batch_size=2,is_sample_shuffle=False)
4 train_iter, val_iter = tang_shi.load_train_val_test_data(is_train=True)
5 for x,y in train_iter:
6 print(x,x.shape)
7 print(y,y.shape)上述代码运行结束的输出结果如下所示:
1 tensor([[ 0, 687, 0, 181, 505, 2, 824, 49, 0, 28, 0, 3,
2 0, 29, 4, 51, 107, 2, 0, 17, 352, 120, 0],
3 [ 28, 1294, 0, 37, 2, 382, 42, 0, 526, 3, 0, 0,
4 1805, 1911, 2, 0, 0, 0, 383, 1, 1, 1, 1]])
5 torch.Size([2, 23])
6 tensor([[ 687, 0, 181, 505, 2, 824, 49, 0, 28, 0, 3, 0,
7 29, 4, 51, 107, 2, 0, 17, 352, 120, 0, 3],
8 [1294, 0, 37, 2, 382, 42, 0, 526, 3, 0, 0, 1805,
9 1911, 2, 0, 0, 0, 383, 3, 1, 1, 1, 1]])
10 torch.Size([2, 23])在上述结果中,第1个样本的长度为24,第2个样本的长度20,所以第2个样本索引为1的位置便是对其进行的填充。
以上完整示例代码可以参见Code/utils/data_helper.py文件。
7.6.3 古诗生成任务#
1. 前向传播
在完成数据集的构建之后,接下来我们再来看如何实现整个模型。首先需定义一个类并完成相关变量的初始化工作,示例代码如下所示:
1 class CharRNN(nn.Module):
2 def __init__(self, vocab_size=2000, embedding_size=64, hidden_size=128,
3 num_layers=2, cell_type='LSTM' PAD_IDX=1):
4 super(CharRNN, self).__init__()
5 if cell_type == 'RNN':
6 rnn_cell = nn.RNN
7 elif cell_type == 'LSTM':
8 rnn_cell = nn.LSTM
9 elif cell_type == 'GRU':
10 rnn_cell = nn.GRU
11 else:
12 raise ValueError("Unrecognized RNN cell type: " + cell_type)
13 self.vocab_size = vocab_size
14 self.hidden_size = hidden_size
15 self.embedding_size = embedding_size
16 self.num_layers = num_layers
17 self.bidirectional = bidirectional
18 self.PAD_IDX = PAD_IDX
19 self.token_embedding = nn.Embedding(self.vocab_size, self.embedding_size)
20 self.rnn = rnn_cell(self.embedding_size, self.hidden_size,batch_first=True,
21 num_layers=self.num_layers)
22 self.classifier = nn.Sequential(nn.LayerNorm(self.hidden_size),
23 nn.Linear(self.hidden_size, self.hidden_size),nn.ReLU(inplace=True),
24 nn.Linear(self.hidden_size, self.vocab_size))在上述代码中,第5~12行表示根据参数cell_type来返回得到对应的循环记忆单元。第13~18行表示初始化相应的模型参数。第19行表示实例化一个词嵌入层,权重矩阵的形状为[vocab_size,embedding_size],即词表中的每一个词均通过一个维度为embedding_size的向量来进行表示,因此之后输入RNN每个时刻向量的维度便是embedding_size。第20~21行是根据相应参数实例化一个RNN模型。第22~24行则是最后的分类层,其中分类数量为词表的大小。
进一步,其前向传播的计算过程实现为
1 def forward(self, x, labels=None):
2 x = self.token_embedding(x)
3 x, _ = self.rnn(x)
4 logits = self.classifier(x)
5 if labels is not None:
6 loss_fct = nn.CrossEntropyLoss(reduction='sum',ignore_index=self.PAD_IDX)
7 loss = loss_fct(logits.reshape(-1, self.vocab_size), labels.reshape(-1))/x.shape[0]
8 return loss, logits
9 else:
10 return logits在上述代码中,第2行是将样本索引输入到词嵌入层中,根据索引在词嵌入层中取到对应行作为对应的向量表示,形状将从[batch_size,src_len]变为[batch_size,src_len,embedding_size]。第3行表示取RNN编码后的结果,输出x的形状为 [batch_size, src_len, hidden_size]。第4行为分类器的输出结果,输出形状为[batch_size, src_len, vocab_size],即后续对每个时刻的输出都进行分类。第6~7行是在训练集上计算损失,其中ignore_index表示指定需要忽略损失计算的类标签,例如在此处对于填充的部分信息。同时需要注意的是,第6行中参数reduction='sum'指定了计算损失和,而第7行只除以批大小则是为了消除其它超参数受序列长短的影响,因为默认情况下reduction='mean'返回的是每个时间步对应的平均损失,即损失和除以batch_size*src_len,而此时模型容易忽略短序列中所产生的误差。
如下示例展示了类CrossEntropyLoss中ignore_index参数的作用:
1 if __name__ == '__main__':
2 logits = torch.tensor([[0.5, 0.7, -0.2],
3 [0.3, 0.6, 0.8],
4 [0.2, 0.1, 0.3]])
5 label = torch.tensor([1, 0, 2])
6 loss = torch.nn.CrossEntropyLoss(ignore_index=2)
7 print(loss(logits, label)) # 1.0929
8 loss = torch.nn.CrossEntropyLoss()
9 print(loss(logits[:2], label[:2])) # 1.0929在上述代码中,第6行和第8行分别实例化了一个交叉熵计算对象,区别在于前者指定了需要忽略的类别标签。从最后的结果可以看出,尽管前者计算的是3个样本的交叉熵,但是由于指定了ignore_index,因此计算得到的损失值同后者只有2个样本计算得到的损失相等。
2. 模型训练
由于序列生成不同于之前介绍到的普通分类任务,所以在模型训练之前我们需要先定义一个评价指标来评估生成结果的好坏。这里,我们使用改进版的准确率来进行评估,即对于每个生成序列来说,计算其与正确序列标签之间的准确率,需要注意的是此时需要忽略掉填充部分的结果。
例如对于如下预测和标签来说:
$$ \begin{aligned} y=[5,6,8,8,3,4,7,8,2,7,1,1,1]\\[2ex] \hat{y}=[5,6,8,8,2,4,6,7,2,7,2,3,3] \end{aligned} \tag{7-17} $$其准确率为$7/10=0.7$,即上述结果中第0、1、2、3、5、8、9这7个位置预测正确,4、6、7这3个位置预测错误,而第10、11、12这3个位置为填充部分需要忽略。
对于整个数据集来说,则用总的正确数量除以总的有效数量即可,实现代码如下所示:
1 def accuracy(logits, y_true, PAD_IDX=1):
2 y_pred = logits.argmax(axis=2).reshape(-1)
3 y_true = y_true.reshape(-1)
4 acc = y_pred.eq(y_true)
5 mask = torch.logical_not(y_true.eq(PAD_IDX))
6 acc = acc.logical_and(mask)
7 correct = acc.sum().item()
8 total = mask.sum().item()
9 return float(correct) / total, correct, total在上述代码中,第1行logits为模型的预测概率输出形状为[batch_size,src_len,vocab_size],y_true为正确标签形状为[batch_size,tgt_len],PAD_IDX为填充标识。第2行是根据预测概率得到预测结果。第4行是计算预测值与正确值的比较情况。第5行是找到真实标签中填充位置的信息,填充位置为False非填充位置为True。第6行是去掉比较结果中填充的部分。第7~8行是分别计算预测正确的数量和总的有效数量。第9行则是返回相应的结果。
在前期工作准备完毕之后便可以开始训练整个模型。总体来说训练模型的代码与之前介绍过的大同小异,所在我们这里就不再赘述,各位读者直接参考源码即可。最后,在对网络模型进行训练时将会得到类似如下的输出结果:
1 Epochs[1/50]--batch[0/365]--Acc: 0.185--loss: 6.0012
2 Epochs[1/50]--batch[50/365]--Acc: 0.187--loss: 5.6588
3 Epochs[1/50]--batch[100/365]--Acc: 0.195--loss: 5.569
4 Epochs[1/50]--batch[150/365]--Acc: 0.2094--loss: 5.1763
5 Epochs[10/50]--batch[350/365]--Acc: 0.4597--loss: 2.6894
6 Epochs[10/50]--Acc on val 0.2202
7 Epochs[37/50]--batch[0/365]--Acc: 0.8259--loss: 0.8444
8 Epochs[37/50]--batch[50/365]--Acc: 0.8363--loss: 0.7929
9 Epochs[37/50]--batch[100/365]--Acc: 0.8264--loss: 0.8362
10 Epochs[10/50]--Acc on val 0.2004从上述结果可以看出,尽管模型在训练集上已经有了不错的准确率,但是在验证集上的泛化结果却并不好,可能的原因在于古诗词这类具有创造性的数据其内部并不存在统一的概率分布,即各个作者的风格不尽相同。尽管如此,但我们可以选择保存在训练集上准确率最高的模型用于后续的生成场景。
以上完整示例代码可以参见Code/Chapter07/C07_CharRNNPoetry/CharRNN.py文件。
3. 推理样本处理
在完成模型训练之后便可以进一步来使用它根据提示生成新的文本序列。但是在这之前我们需要先定义两个辅助函数来完成推理样本和序列生成结果的处理。
首先需要在类TangShi中实现make_infer_sample方法来预处理模型推理时的输入,示例代码如下所示:
1 def make_infer_sample(self, srcs):
2 all_token_ids = []
3 for src in srcs:
4 text = self.simplified_traditional_convert(src, 's2t')
5 tokens = tokenize(text)
6 token_ids = [self.vocab[token] for token in tokens]
7 token_ids = torch.tensor(token_ids, dtype=torch.long)
8 all_token_ids.append(torch.reshape(token_ids, [1, -1]))
9 return all_token_ids在上述代码中,第1行src表示推理时输入模型的提示,形如["李白乘舟将欲行","朝辞白帝彩"]表示让模型根据两个提示生成两首诗。第4行表示将简体转换为繁体,因为整个数据集为繁体语料。第5~8行则是将原始输入处理为词表中的索引。
经过make_infer_sample方法处理后,["李白乘舟将欲行","朝辞白帝彩"]的输出结果为
1 [tensor([[767, 32, 388, 214, 113, 108, 34]]),
2 tensor([[ 69, 366, 32, 390, 720]])]进一步,还需要实现一个方法来格式化推理时模型的生成序列,将其转换成文字输出,示例代码如下所示:
1 def pretty_print(self, result):
2 result = [self.vocab.itos[item.item()] for item in result[0]]
3 result = "".join(result)
4 result = self.simplified_traditional_convert(result, 't2s')
5 seps = [self.vocab.itos[idx] for idx in self.ends]
6 for sep in seps:
7 result = result.split(sep)
8 result = f"{sep}\n".join(result)
9 result = result.split('\n')
10 true_result = [result[0]]
11 i = 1
12 while i < len(result) - 1:
13 if len(result[i]) < len(result[i - 1]):
14 true_result.append(result[i] + result[i + 1])
15 i += 2
16 else:
17 true_result.append(result[i])
18 i += 1
19 true_result = "\n".join(true_result)
20 return true_result在上述代码中,第1行中result是推理生成的序列词表索引。第2行用于将索引转换为文字。第3~4行分别是格式化为字符串并转换为简体。第5行是得到句子可能的结束符标志。第6~8行是按结束符分割并得到初步格式化后的结果。第9~19行是处理当问号出现在句中时的情况。
以下示例可以看出pretty_print方法处理后的结果:
1 if __name__ == '__main__':
2 result = torch.tensor([[773, 217, 898, 122, 17, 2, 215, 23, 286, 16, 63, 3, 74, 428, 1897,
3 1112, 58, 2, 21, 15, 493, 5, 269, 3, 723, 10, 19, 6, 48, 2, 869, 863,
4 4, 153, 1605, 3, 16, 46, 556, 25, 219, 1034, 88, 89, 78, 45, 1188, 3]])
5 tang_shi = TangShi(top_k=2500)
6 result = tang_shi.pretty_print(result)
7 print(result)
8
9 借问陇头水,终年恨何事。
10 深疑呜咽声,中有征人泪。
11 昨日上山下,达曙不能寐。
12 何处接长波?东流入清渭。在上述代码中,第2~4行便是推理时模型生成的结果,第9~12行则是经过格式化后的结果。
4. 模型推理
在完成上述准备工作后便可以根据训练好的模型来生成新的序列。不过由于序列生成模型推理过程相对于普通的分类场景则稍显复杂,因为需要逐一根据上一时刻的输出来预测下一时刻的结果,其过程如图7-15所示,并根据相应条件结束。所以首先我们实现一个辅助函数来完成所有时刻的预测过程,示例代码如下所示:
1 def greedy_decode(model, src, config, ends,UNK_IDX):
2 max_len = [10 * config.num_sens, 12 * config.num_sens, 16 * config.num_sens]
3 src = src.to(config.device)
4 for i in range(max(max_len) * 2):
5 out = model(src) # [1, src_len, vocab_size]
6 if config.with_max_prob:
7 _, next_word = torch.max(out[:, -1], dim=1)
8 else:
9 prob = torch.softmax(out[:, -1], dim=-1)
10 while True:
11 next_word = torch.distributions.Categorical(prob).sample()
12 if next_word.item() != UNK_IDX:
13 break
14 next_word = next_word.item()
15 src = torch.cat([src, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
16 if next_word in ends and (src.shape[1] in max_len or src.shape[1] > max(max_len)):
17 break
18 return src在上述代码中,第1行src为已经转换为词表索引的输入,形状必须为[1,src_len],即原始输入可以是一个字或几个字,ends为可能结束标志,如句号或者问号。第2行表示限定输出序列的形式,这里仅限定为四言、五言或七言,例如五言的序列长度为$((5+1)\times2)\times \text{num\_sens}$。第4行开始表示用来循环预测每个时刻的输出结果,且限定了最大长度。第5行的输出形状为[1, src_len, vocab_size]。第6~7行表示根据最大概率来选择当前时刻的输出结果。第8~13行表示根据概率分布来采样得到当前时刻的输出值,之所以使用概率分布是为了保证生成古诗的多样性,否则同样的输入只会产生唯一的结果,同时过滤掉预测结果为UNK的情况。第15行是将当前时刻的预测结果同当前时刻之前所有时刻的输入拼接起来作为一个输入序列来预测下一个时刻的输出。第16行判断是否满足停止条件,即当前预测结果为结束标志且整个序列长度为max_len中的一个或者大于允许预测的最大长度。
进一步,需要结合greedy_decode函数来实现完整的预测过程,示例代码如下所示:
1 def inference(config, srcs=None):
2 model = CharRNN(config.top_k, config.embedding_size,config.hidden_size,
3 config.num_layers, config.cell_type)
4 if os.path.exists(config.model_save_path):
5 logging.info(f" # 载入模型进行推理……")
6 checkpoint = torch.load(config.model_save_path)
7 model.load_state_dict(checkpoint)
8 else:
9 raise ValueError(f" # 模型{config.model_save_path}不存在!")
10 tang_shi = TangShi(top_k=config.top_k)
11 srcs = tang_shi.make_infer_sample(srcs)
12 unk_idx = tang_shi.vocab.stoi[tang_shi.vocab.UNK]
13 with torch.no_grad():
14 for src in srcs:
15 result = greedy_decode(model, src, config, ends=tang_shi.ends, UNK_IDX=unk_idx)
16 result = tang_shi.pretty_print(result)
17 logging.info(f"\n{result}")在上述代码中,第2~9行用于实例化一个古诗生成模型并用本地模型对其进行初始化。第10~11行则是构造输入样本。第12行是得到['UNK']在词表中的索引。第13~16行则是对每个样本逐一进行预测输出。以上完整示例代码可以参见Code/Chapter07/C07_CharRNNPoetry/doPoetry.py文件。
最后,对于如下输入示例:
1 if __name__ == '__main__':
2 config = ModelConfig()
3 config.__dict__['num_sens'] = 2
4 config.__dict__['with_max_prob'] = False
5 srcs = ["李白乘舟将欲行", "朝辞白帝彩"]
6 inference(config, srcs)在上述代码中,第3~4行为新加入的两个参数,即指定生成的句子数量和生成的采样方式。第5行则是给定的两个提示。
进一步,模型生成的结果如下所示:
1 李白乘舟将欲行,忽闻白鸟逐双旌。
2 江边老去黄河水,夜夜无过渌水声。
3
4 朝辞白帝彩云间,万仞山阴独未还。
5 燕子入时寒食好,玉杯销尽百年心。7.6.4 小结#
在本节内容中,我们首先介绍了基于RNN模型,即CharRNN的古诗词生成原理;然后详细介绍了整个数据集迭代器的构建过程,包括预处理流程、格式化样本、构建词表和转换为词表索引等;最后介绍了整个生成模型的训练和推理实现过程,包括模型训练和推理样本处理等。
引用#
[1] Blog A K. The Unreasonable Effectiveness of Recurrent Neural Networks[J]. May, 2015.
[2] https://github.com/chinese-poetry/chinese-poetry