7.3 LSTM网络#
在前面两节内容中,我们详细介绍了RNN模型的原理以及在PyTorch框架中的使用方法。虽然理论上RNN模型在处理序列数据方面具有着很好的效果,但在处理长序列数据时RNN模型可能会出现梯度消失或爆炸的情况,进而导致模型无法学习到长期依赖的关系。在这样的背景下,基于RNN模型改进的长短期记忆网络(Long Short-Term Memory, LSTM)[1]便应运而生了。
7.3.1 LSTM动机#
根据「第7.1节 RNN原理:循环神经网络的结构与序列建模」内容可知,RNN模型出现的动机便是为了解决时序数据的特征编码问题,但在实际情况中由于时序数据的时间步长较多因而又导致了新问题的出现。例如模型在对一个时序长度为50的序列进行特征提取时,第50个时刻的隐含向量$h_{50}$便会依赖之前所有时刻的信息。在这样的情景下,一方面由第7.1.6节内容可知模型在训练过程中极易出现梯度消失或爆炸的情况;另一方面由于历史时刻和当前时刻的状态信息得不到有效筛选,使得模型难以学到真正对下游任务有用的信息,而这也被称之为长期依赖(Long-Term Dependencies)问题。
基于这样的动机, 霍赫赖特等人在1997年提出了基于门控单元的长短期记忆网络。LSTM模型的设计思想在于通过引入门控机制(Gating)和记忆状态(Memory State)来解决上述两个问题。门控机制可以控制信息的流动决定哪些信息应该被保留,哪些应该被遗忘,以及哪些信息应该输入给下一个记忆单元以便模型可以更好地捕捉序列的长期依赖关系。同时,记忆状态则是类似于残差模块中的连接,使得经过筛选后的记忆状态能够直接输入到下一个记忆单元,从而缓解了RNN中的梯度消失或爆炸问题。
7.3.2 LSTM结构#
同RNN模型类似,LSTM模型也是一个在时间维度进行展开的循环结构。在原始的RNN模型中,每个重复的记忆单元内只包含一个简单的网络层,而对于LSTM模型来说每个记忆单元包含有4个不同的网络层,并通过不同的方式进行相互作用以此得到当前时候的输出结果。如图7-6所示便是LSTM模型的网络结构示意图。
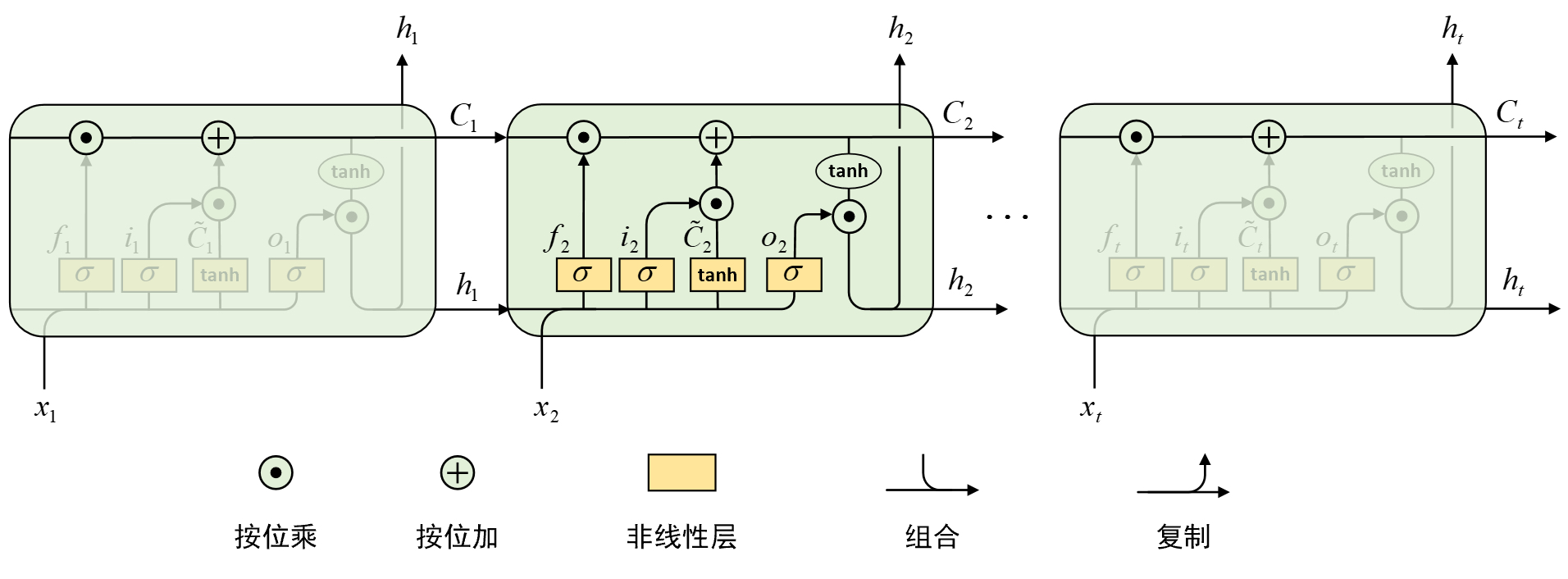
在图7-6中,上方贯穿每个记忆单元的便是LSTM中引入的记忆状态$C_t$,同时$f_t$ 、$i_t$、$o_t$和$\tilde{C_t}$ 分别表示遗忘门(Forget Gate)、输入门(Input Gate)、输出门(Output Gate)和输入层对应的输出结果,$h_t$表示当前时候的输出结果。从图7-6可以看出,LSTM中的每个记忆单元都会通过3个门控结构($f_t$、$i_t$和$o_t$)来完成对信息流动的控制与筛选。每个门控结构都是根据同样的输入经Sigmoid函数作用后得到一系列取值在区间$[0,1]$ 里的值,其中0表示将流经的所有信息进行完全抑制,而1则表示对流经的信息不做任何处理。
1. 遗忘门
遗忘门主要用于对历史记忆状态$C_{t-1}$进行筛选,选择性的遗忘或者保留部分历史信息,使得真正有用的信息能够贯穿LSTM 网络。
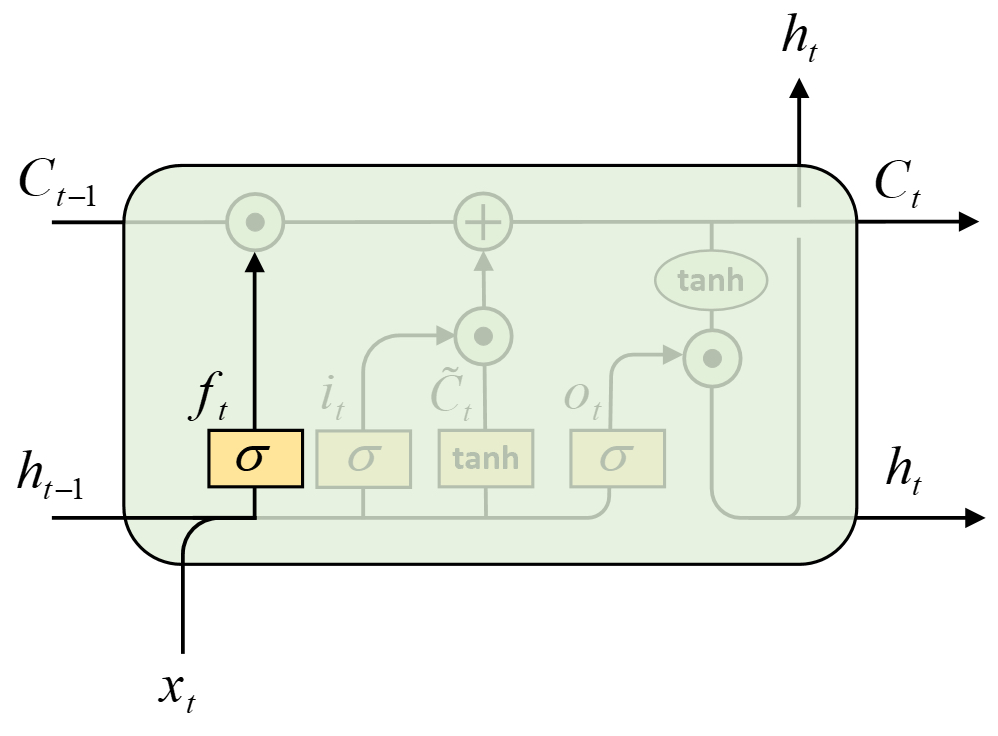
如图7-7所示,在LSTM中第1步需要做的就是确定应该丢弃哪些信息,$t-1$时刻的输出$h_{t-1}$和当前时刻的输入$x_t$经过遗忘门之后,后续再通过按位乘作用于$C_{t-1}$便完成了对历史记忆状态的筛选,其具体计算过程为
$$ f_t=\sigma([h_{t-1},x_t]W_f+b_f)\tag{7-9} $$
其中$\sigma$为Sigmoid函数,$[a,b]$ 表示将$a,b$两个向量进行堆叠组合,$x_t$的形状为[batch_size,input_size],$h_{t-1}$的形状为[batch_size,hidden_size],$[h_{t-1},x_t]$的形状为[batch_size,input_size+hidden_size],$W_f$的形状为[input_size+hidden_size,hidden_size],$b_f$的形状为[hidden_size],$f_t$的形状为[batch_size,hidden_size]。
2.输入门
输入门主要用于对输入信息$\tilde{C_t}$进行筛选,仅让其中部分信息流入到当前时刻,然后再与历史记忆状态融合形成新的记忆状态$C_t$。
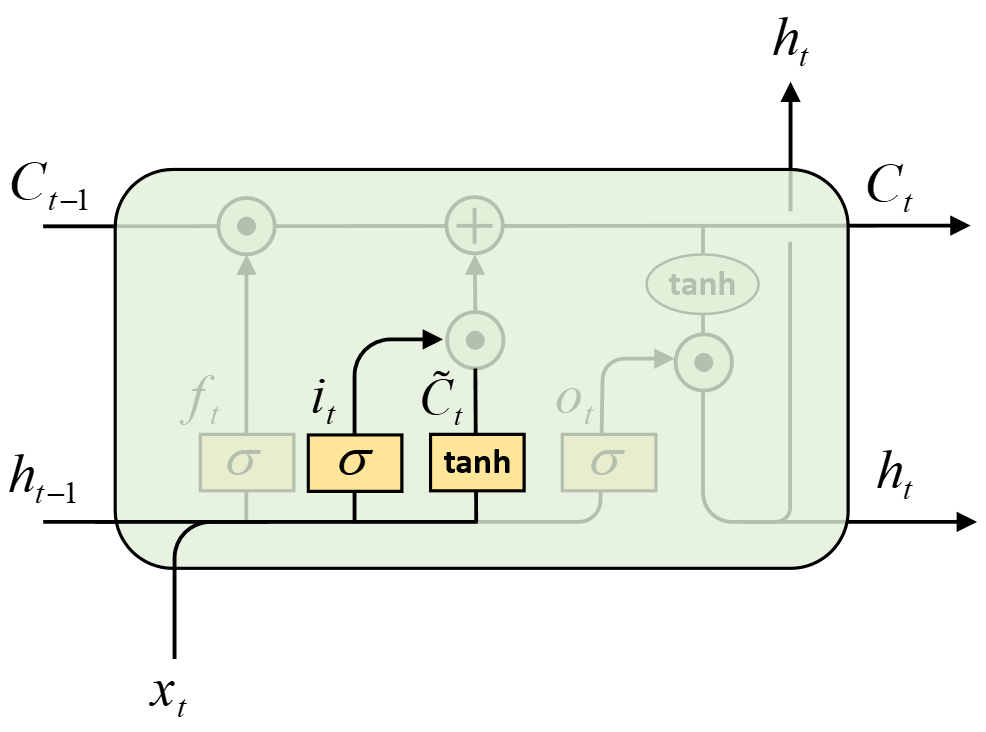
如图7-8所示,在LSTM中第2步需要做的便是通过输入门对当前时刻的输入信息进行筛选,其具体计算过程为
$$ \begin{aligned} i_t&=\sigma([h_{t-1},x_t]W_i+b_i)\\[2ex] \tilde{C_t}&=\tanh([h_{t-1},x_t]W_c+b_c)\\[2ex] \end{aligned}\tag{7-10} $$
其中$W_i$和$W_c$的形状均为[input_size+hidden_size,hidden_size],$b_i$和$b_c$的形状均为[hidden_size],$i_t$和$\tilde{C}_t$的形状均为[batch_size,hidden_size]。
进一步对历史记忆状态$C_{t-1}$进行更新,计算过程为
$$ C_t=f_t\odot C_{t-1}\oplus i_t\odot\tilde{C_t}\tag{7-11} $$
其中$\odot$表示按位乘,$\oplus$表示按位加,$C_{t-1}$的形状为[batch_size,hidden_size]。
3. 输出门
输出门主要用于对记忆状态$C_t$进行筛选,仅让其中部分需要的信息输出得到当前时刻的输出结果$h_t$。
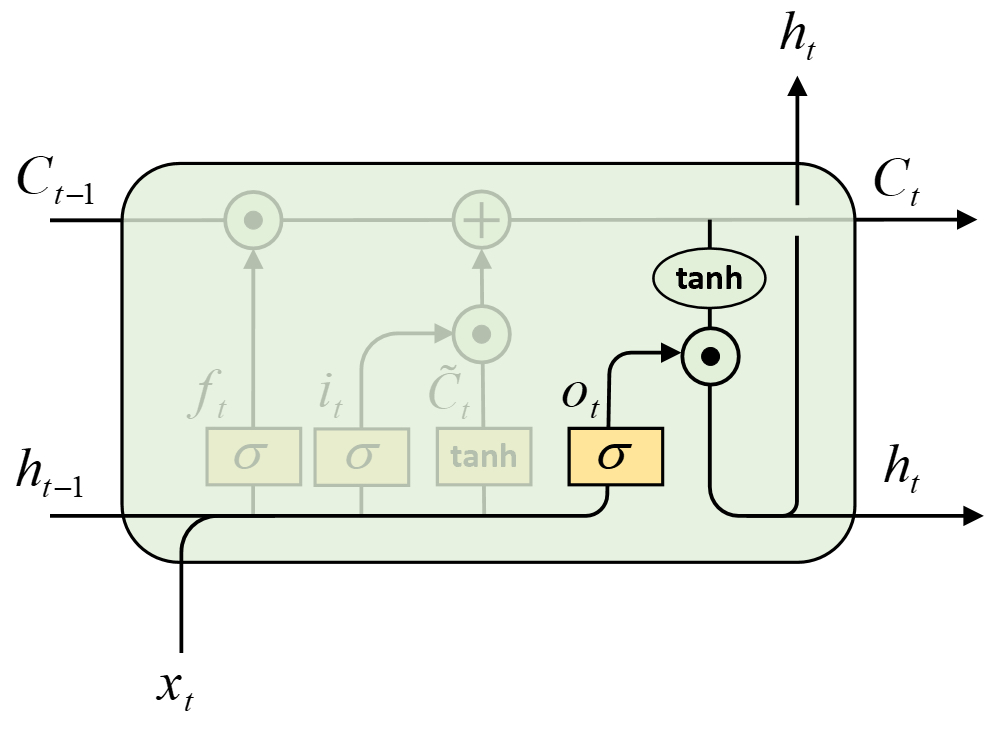
如图7-9所示,在LSTM中第3步需要做的便是通过输出门对当前时刻的输出信息进行筛选,其具体计算过程为
$$ \begin{aligned} o_t&=\sigma([h_{t-1},x_t]W_o+b_o)\\[2ex] h_t&=o_t\odot\tanh(C_t) \end{aligned}\tag{7-12} $$
其中$W_o$的形状为[input_size+hidden_size,hidden_size],$b_o$的形状为[hidden_size],$o_t$、$C_t$和$h_t$的形状均为[batch_size,hidden_size]。
7.3.3 LSTM实现#
在清楚LSTM模型的相关原理之后,我们再来看如何借助PyTorch快速实现LSTM模型,示例代码如下所示:
1 def test_LSTM():
2 batch_size, time_step = 2, 3
3 input_size, hidden_size = 4, 5
4 x = torch.rand([batch_size, time_step, input_size])
5 lstm = nn.LSTM(input_size, hidden_size, num_layers=2, batch_first=True)
6 output, (hn, cn) = lstm(x)
7 print(output)
8 print(hn)
9 print(cn)从上述代码可以看出,PyTorch中LSTM的使用方式和7.1.6节中介绍的RNN的使用方式一致,因此相同点这里我们就不再赘述。需要注意的是,由于LSTM模型的输出有$C_t$和$h_t$两个部分,因此第6行的输出结果包含有3个部分,其中output是每个时刻的输出结果,形状为[batch_size, time_step, hidden_size],hn和cn为每一层最后一个时刻$h_t$和$C_t$对应的输出结果,形状为[num_layer, batch_size, hidden_size]。
在上述代码运行结束后便可得到如下所示结果:
1 tensor([[[-0.1470, -0.1340, -0.0569, -0.0220, -0.1149],
2 [-0.1706, -0.1674, -0.0699, -0.0375, -0.1820],
3 [-0.1661, -0.1770, -0.0681, -0.0459, -0.2228]],
4 [[-0.1420, -0.1348, -0.0561, -0.0204, -0.1190],
5 [-0.1633, -0.1672, -0.0636, -0.0308, -0.1862],
6 [-0.1651, -0.1789, -0.0644, -0.0392, -0.2191]]],
7 grad_fn=<TransposeBackward0>)
8 tensor([[[-0.2327, 0.0633, 0.1928, 0.1506, -0.1884],
9 [-0.3359, 0.0807, 0.1338, 0.2239, -0.2434]],
10 [[-0.1661, -0.1770, -0.0681, -0.0459, -0.2228],
11 [-0.1651, -0.1789, -0.0644, -0.0392, -0.2191]]],
12 grad_fn=<StackBackward0>)
13 tensor([[[-0.5751, 0.1446, 0.3955, 0.2903, -0.4299],
14 [-0.6660, 0.1560, 0.2633, 0.5053, -0.4937]],
15 [[-0.3822, -0.3938, -0.1443, -0.1064, -0.4331],
16 [-0.3860, -0.3943, -0.1392, -0.0893, -0.4248]]],
17 grad_fn=<StackBackward0>)以上完整示例代码可以参见Code/Chapter07/C04_LSTM/main.py文件。关于LSTM模型的实战介绍可参见「第7.6节 CharRNN教程:基于字符级序列的生成模型」内容。
7.3.4 LSTM梯度分析#
在介绍完LSTM的相关原理之后我们再来大致分析一下为什么LSTM能够有效解决传统RNN中的长期依赖问题。首先需要明白的是RNN中模型无法学习到序列的长期依赖问题本质是因为梯度消失或者爆炸的缘故。对于梯度爆炸来说可以通过梯度裁剪等手段来进行克服,但是对于梯度消失来说RNN却显得无能为力。在LSTM中,通过引入记忆状态$C_t$便有效地解决了这一问题。
如图7-6所示,从直观上来看对于有效的历史信息,只要遗忘门的输出结果接近于1,那么所有的历史状态信息都能够通过$C_t$流入到LSTM的各个时间单元中,从而使得模型能够记住较长的历史信息。
进一步,从梯度计算的角度来看,假定LSTM第$t$个时刻的输出为$h_t$,由式(7-10)和式(7-11)可知$h_t$关于输入层权重参数$W_c$的梯度是由$C_{t-1}$和$\tilde{C}_t$这两部分的梯度相加而来[2]。因此在新增记忆状态之后,$h_t$关于输入层参数$W_c$新增部分的梯度可以表示为
$$ \begin{aligned} \frac{\partial h_t}{\partial W_c}&=\frac{\partial h_t}{\partial C_t}\frac{\partial C_t}{\partial W_c}+\frac{\partial h_t}{\partial C_t}\frac{\partial C_t}{\partial C_{t-1} }\frac{\partial C_{t-1}}{\partial W_c}+\frac{\partial h_t}{\partial C_t}\frac{\partial C_t}{\partial C_{t-1}}\frac{\partial C_{t-1}}{\partial C_{t-2}}\frac{\partial C_{t-2}}{\partial W_c}+...+\frac{\partial h_t}{\partial C_t}\frac{\partial C_t}{\partial C_{t-1}}\cdots\frac{\partial C_{2}}{\partial C_{1}}\frac{\partial C_{1}}{\partial W_c}\\[3ex] &=\frac{\partial h_t}{\partial C_t}\frac{\partial C_t}{\partial W_c}+\frac{\partial h_t}{\partial C_t}f_t\frac{\partial C_{t-1}}{\partial W_c}+\frac{\partial h_t}{\partial C_t}f_tf_{t-1}\frac{\partial C_{t-2}}{\partial W_c}+...+\frac{\partial h_t}{\partial C_t}f_t\cdots f_{2}\frac{\partial C_{1}}{\partial W_c}\\[3ex] &=\frac{\partial h_t}{\partial C_t}\frac{\partial C_t}{\partial W_c}+\sum_{i=1}^{t-1}\left(\frac{\partial h_t}{\partial C_t}\prod_{j=i+1}^tf_j\frac{\partial C_i}{\partial W_c}\right) \end{aligned}\tag{7-13} $$根据式(7-13)可以看出,同式(7-8)相比尽管此时依旧存在梯度连续相乘的情况,但是只要遗忘门$f_t$的输出结果接近于1,那么便能够极大程度上缓解长距离上梯度消失的问题。
7.3.5 小结#
在本节内容中,我们首先介绍了RNN模型存在的弊端以及LSTM模型出现的动机;然后详细介绍了LSTM中每个门控单元的作用以及整个LSTM的工作原理;最后介绍了在PyTorch中LSTM模型的使用示例以及分析了为什么LSTM模型能够解决梯度消失等问题。
引用#
[1] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural computation, 1997, 9(8): 1735-1780.
[2] 诸葛越, 葫芦娃. 百面机器学习[M]. 北京: 人民邮电出版社, 2018.