5.4 kd树构建与搜索#
在前面几节内容中,我们分别介绍了K近邻分类器的基本原理及其如何通过开源的sklearn框架实现K近邻的建模。不过到目前为止,还有一个问题没有解决,也就是如何快速地找到当前样本点周围最近的K个样本点。通常来讲,这一问题可以通过kd树来解决,下面开始介绍其具体原理。
5.4.1 构造kd树#
kd树(k-Dimensional Tree)是一种基于特征维度划分的数据结构,用于组织k维空间中的样本点,其本质上等同于二叉搜索树。不同的是,在kd树中每个节点存储的并不是一个值,而是一个k维的样本点[3]。在二叉搜索树中,任意节点中的值都大于其左子树中的所有值,小于或等于其右子树中的所有值,如图5-4所示。这里需要注意的一点是,K近邻中的K指的是样本个数,kd树中的k指的是样本特征维度,各位读者注意不要混淆。
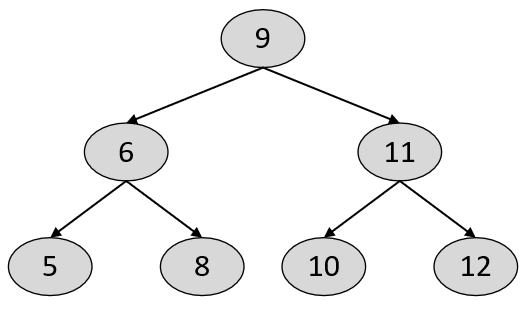
在kd树中,所有节点也都满足类似二叉搜索树的特性,即左子树中所有的样本点均“小于”其父节点中的样本点,而右子树中所有的样本点均“大于”或“等于”其父节点中的样本点,因此可以看出,构造kd树的关键就在于如何定义任意两个k维样本点之间的大小关系。
具体地,在构造kd树时,每一层的节点在划分左右子树时只会循环地选择k个维度中的一个维度进行比较。例如样本点中一共有$x$和$y$两个维度,那么在对根节点进行划分时可以以维度$x$对左右子树进行划分,接着以维度$y$对根节点的孩子进行左右子树划分,进一步,根节点的孩子的孩子则再以维度$x$进行左右子树划分,以此循环[4]。同时,为了使最后得到的是一棵平衡的kd树,所以在kd的构建过程中每次都会选择当前子树中对应维度的中位数作为切分点。
例如现在有样本点[5,7]、[3,8]、[6,3]、[8,5]、[15,6]、[10,4]、[12,13]、[9,10]、[11,14],那么根据上述规则便可以构造得到如图5-4所示的kd树。
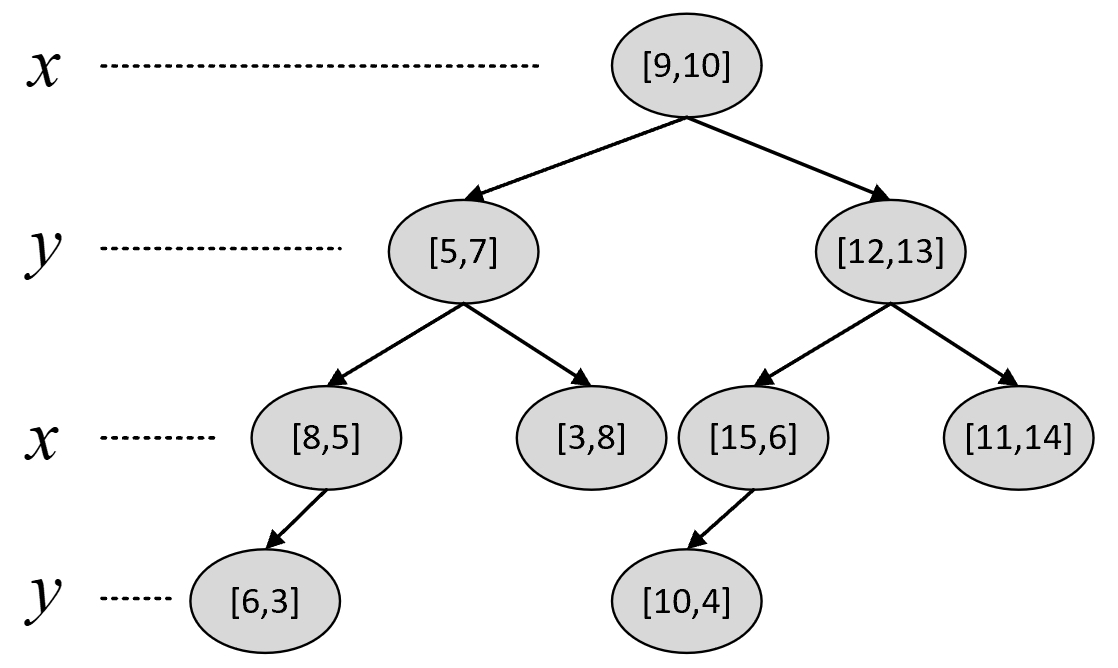
从图5-5可以看出,对于根节点来讲其左子树中所有样本点的$x$维度均小于9,其右子树的$x$维度均大于或等于9。对于根节点的左孩子来讲其左子树中所有样本点的$y$维度均小于7,其右子树中所有样本点的$y$维度均大于或等于7。当然,对于其他节点也满足类似的特性。同时,根据kd树交替选择特征维度对样本空间进行划分的特性,以图5-5中的划分方式还可以得到如图5-6所示的特征空间。
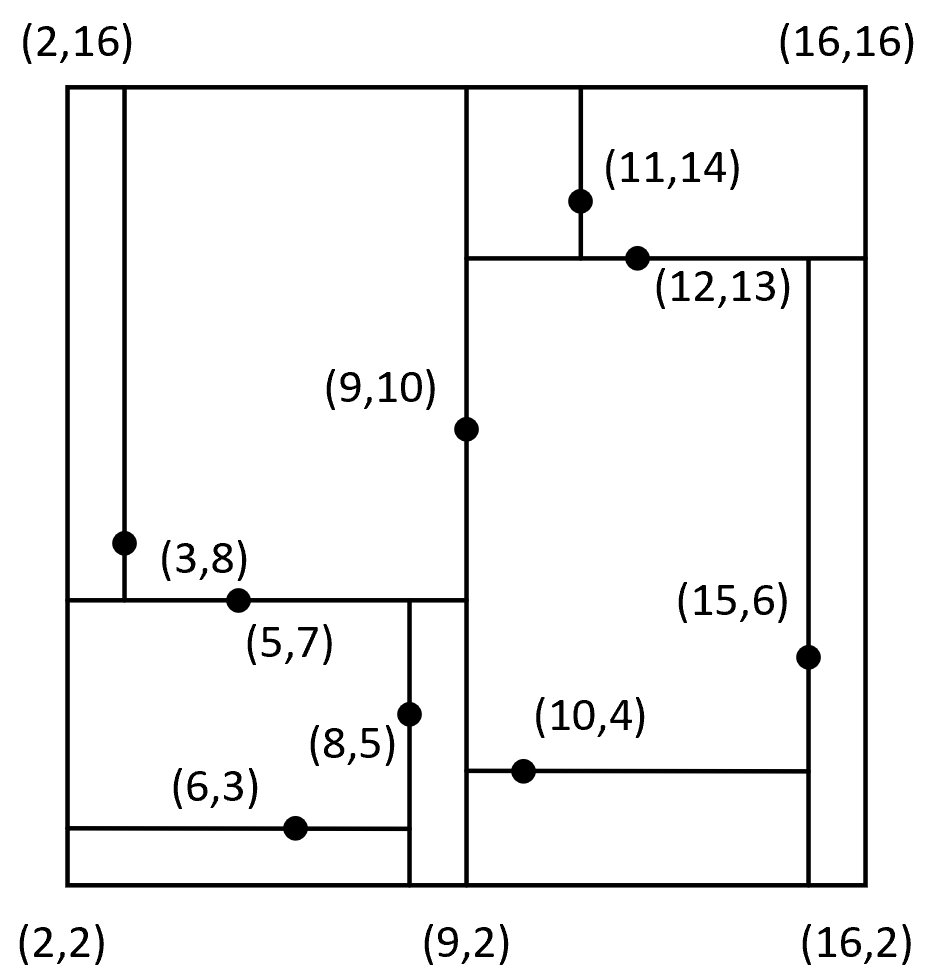
从图5-6中可以看出,整个二维平面首先被样本点[9,10]划分成左右两部分(对应图5-5中的左右子树),接着左右两部分又各自分别被[5,7]和[12,13]划分成上下两部分,直到划分结束。至此,对于kd树的构造就介绍完了,接下来讲解如何通过kd树来完成搜索任务。
5.4.2 最近邻kd树搜索#
在正式介绍K近邻(最近的K个样本点)搜索前,我们先来介绍如何利用kd树进行最近邻搜索,即找到距离当前样本点最近的样本点。总体来讲,在已知kd树中搜索离给定样本点$q$最近的样本点时,首先设定一个当前全局最佳点和一个当前全局最短距离,分别用来保存当前离$q$最近的样本点及对应的距离,然后从根节点开始以类似生成kd树的规则来递归地遍历kd树中的节点。如果当前节点离$q$的距离小于全局最短距离,则更新全局最佳点和全局最短距离; 如果被搜索点到当前节点划分维度的距离小于全局最短距离,则再递归遍历当前节点另外一个子树,直至整个递归过程结束。具体步骤可以总结为[4] :
(1) 设定一个当前全局最佳点和全局最短距离,分别用来保存当前离搜索点$q$最近的样本点和最短距离,初始值分别为空和无穷大。
(2) 从根节点开始,并设其为当前节点。
(3) 如果当前节点为空,则结束。
(4) 如果当前节点到被搜索点$q$的距离小于当前全局最短距离,则更新全局最佳点和最短距离。
(5) 如果被搜索点$q$的划分维度小于当前节点的划分维度,则设当前节点的左孩子为新的当前节点并执行步骤(3)(4)(5)(6)。反之设当前节点的右孩子为新的当前节点并执行步骤(3)(4)(5)(6)。
(6) 如果被搜索点$q$的划分维度到当前节点划分维度的距离小于全局最短距离,则说明全局最佳点可能存在于当前节点的另外一个子树中,所以设当前节点的另外一个孩子为当前节点并执行步骤(3)(4)(5)(6)。
递归完成后,此时的全局最佳点就是在kd树中离被搜索点$q$最近的样本点。
这里需要明白的一点是,利用步骤(6)中的规则来判断另外一个子树中是否可能存在全局最佳点的原理如图5-7所示。
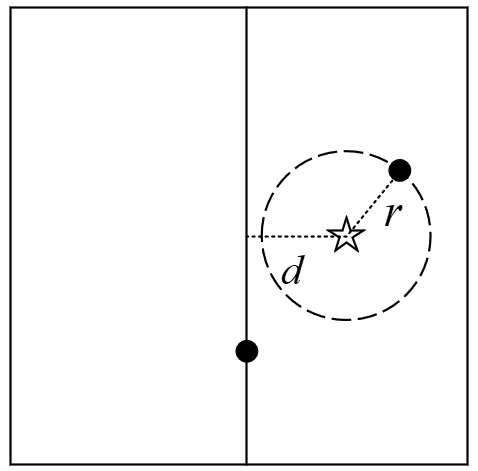
在图5-7中,右上角为当前全局最佳点,五角星为被搜索点。可以看到,此时的整个空间被下方的样本点划分成了左右两部分(子树),并且五角星离左子树中样本点的最短距离为五角星到当前划分维度的距离$d$。显然,如果被搜索点到当前全局最佳点的距离$r$小于距离$d$,则此时左子树中就不可能存在更优的全局最佳点。在下面的搜索示例中我们将会详细进行介绍。
当然,上述步骤还可以通过一个更清晰的伪代码进行表达,代码如下:
1 bestNode, bestDist = None, inf
2 def NearestNodeSearch(curr_node):
3 if curr_node == None:
4 return
5 if distance(curr_node, q) < bestDist:
6 bestDist = distance(curr_node, q)
7 bestNode = curr_node
8 if q_i < curr_node_i:
9 NearestNodeSearch(curr_node.left)
10 else:
11 NearestNodeSearch(curr_node.right)
12 if |curr_node_i - q_i| < bestDist:
13 NearestNodeSearch(curr_node.other)在上述代码中,q_i和curr_node_i分别表示被搜索点和当前节点的划分维度,curr_node.other表示curr_node.left和curr_node.right中先前未被访问过的子树。
5.4.3 最近邻搜索示例#
在介绍完最近邻算法的搜索原理后再来看几个实际的搜索示例,以便对整个搜索过程有更加清晰的理解。如图5-8所示,左右两边分别是5.4.1节中所得到的kd树和特征划分空间,同时右图中的五角星为给定的被搜索点$q=[8.9,4]$,接下来开始在左边的kd树中搜索离$q$点最近的样本点。
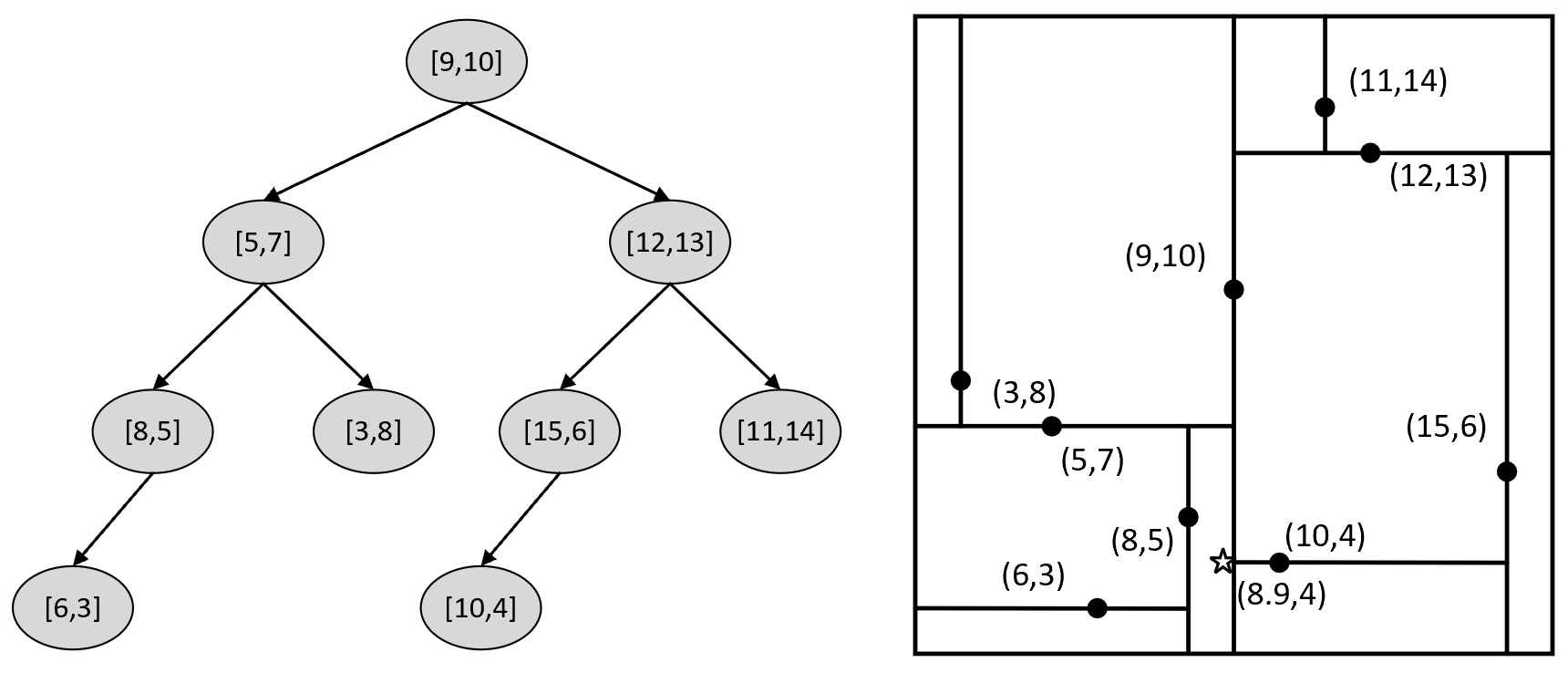
在搜索之前我们先来直观从图5-8(b)观察一下。从图中可以看出,距离$q$点最近的样本点其实是[10,4],但是由于$q$点的第1个划分维度8.9小于9,所以整个搜索过程将会先在图5-8(a)中的左子树中进行,但是由于一直满足上面步骤(6)中的条件,所以最终整个搜索过程又会回到右子树中进行,知道搜索到[10,4]这个样本点。下面我们开始跟踪整个搜索过程。
在搜索伊始,全局最佳点和全局最短距离分别为空和无穷大。第1次递归: 此时设根节点[9,10]为当前节点,因满足步骤(4),即当前节点到被搜索点的距离小于当前全局最短距离,所以将当前最佳点更新为[9,10],将全局最短距离更新为6.001。接着,由于被搜索点的划分维度8.9小于当前节点的划分维度9,因此将当前节点的左孩子[5,7]设为新的当前节点。第2次递归: 继续执行步骤(4),由于此时当前节点到被搜索点的距离为4.92,小于全局最短距离6.001,所以此时将当前最佳点更新为[5,7],将全局最短距离更新为4.92。进一步,由于被搜索点的划分维度4小于当前节点的划分维度7,因此将当前节点的左孩子[8,5]设为新的当前节点。
第3次递归: 继续执行步骤(4),由于此时当前节点到被搜索点的距离为1.345,小于全局最短距离4.92,所以将当前最佳点更新为[8,5],将全局最短距离更新为1.345。此时,由于被搜索点的划分维度8.9大于或等于当前节点的划分维度8,因此将当前节点的右孩子设为新的当前节点,并进入第4次递归。第4次递归: 由于此时当前节点为空,所以第4次递归结束并返回第3次递归,即此时的当前节点为[8,5],并继续执行步骤(6)。由于被搜索点的划分维度8.9到当前节点的划分维度8的距离为0.9,小于全局最短距离1.345,说明全局最佳点可能存在于当前节点的左子树中(此时可以想象假如kd树中存在点[7.9,4]),所以将当前节点的左孩子[6,3]设为新的当前节点,并进入第5次递归。
第5次递归: 继续执行步骤(4),由于此时当前节点到被搜索点的距离为3.068,大于全局最短距离,因此维持状态不变。进一步,因为被搜索点的划分维度4大于当前节点的划分维度3,所以将当前节点的右孩子设为新的当前节点,并进入第6次递归。第6次递归:由于当前节点为空,所以第6次递归结束并回到第5次递归中。在第5次递归中继续执行步骤(6),由于被搜索点的划分维度4到当前节点的划分维度3的距离为1,小于全局最短距离1.345,说明全局最佳点可能存在于当前节点的左子树中,所以将当前节点[6,3]的左孩子设为新的当前节点,并进入到第7次递归。
第7次递归:由于当前节点为空,所以第7次递归结束并回到第2次递归中。此时的当前节点为[5,7]并执行步骤(6),不满足条件返回到第1次递归中。此时的当前节点为[9,10],并执行步骤(6),满足被搜索点的划分维度8.9到当前节点的划分维度9的距离为0.1小于全局最短距离1.345的条件,说明全局最佳点可能存在于当前节点的右子树中,所以将当前节点[9,10]的右孩子设为新的当前节点,并进入到第8次递归。
第8次递归:继续执行步骤(4),由于此时当前节点[12,13]到被搜索点的距离为9.519,大于全局最短距离,因此维持状态不变。进一步,因为被搜索点的划分维度4小于当前节点的划分维度12,所以将当前节点的左孩子设为新的当前节点,并进入第9次递归。第9次递归: 继续执行步骤(4),由于此时当前节点[15,6]到被搜索点的距离为6.42,大于全局最短距离,因此维持状态不变。继续,将当前节点的左孩子[10,4]设为新的当前节点,并进入第10次递归。
第10次递归:继续执行步骤(4),由于此时当前节点[10,4]到被搜索点的距离为1.1,小于全局最短距离1.345,所以此时将当前最佳点更新为[10,4],将全局最短距离更新为1.1。进一步,由于被搜索点的划分维度4大于等于当前节点的划分维度4,因此将当前节点的右孩子设为新的当前节点,并进入第11次递归。第11次递归:由于当前节点为空,所以第11次递归结束并回到第10次递归中。此时的当前节点为[10,4]并执行步骤(6),由于被搜索点的划分维度4到当前节点的划分维度4的距离为0,小于全局最短距离1.1,说明全局最佳点可能存在于当前节点的左子树中,所以将当前节点[10,4]的左孩子设为新的当前节点,并进入到第12次递归。
第12次递归:由于当前节点为空,所以第12次递归结束并回到第9次递归中,此时的当前节点为[15,6]并执行步骤(6),不满足条件返回到第8次递归中。此时的当前节点为[12,13],并执行步骤(6),不满足条件返回到第1次递归中。此时,所有的递归过程执行完毕,全局最佳点中保存的点[10,4]便是kd树中离被搜索点$q=[8.9,4]$最近的样本点,最短距离为1.1,并且整个搜索过程还可以通过图5-9来进行表示。
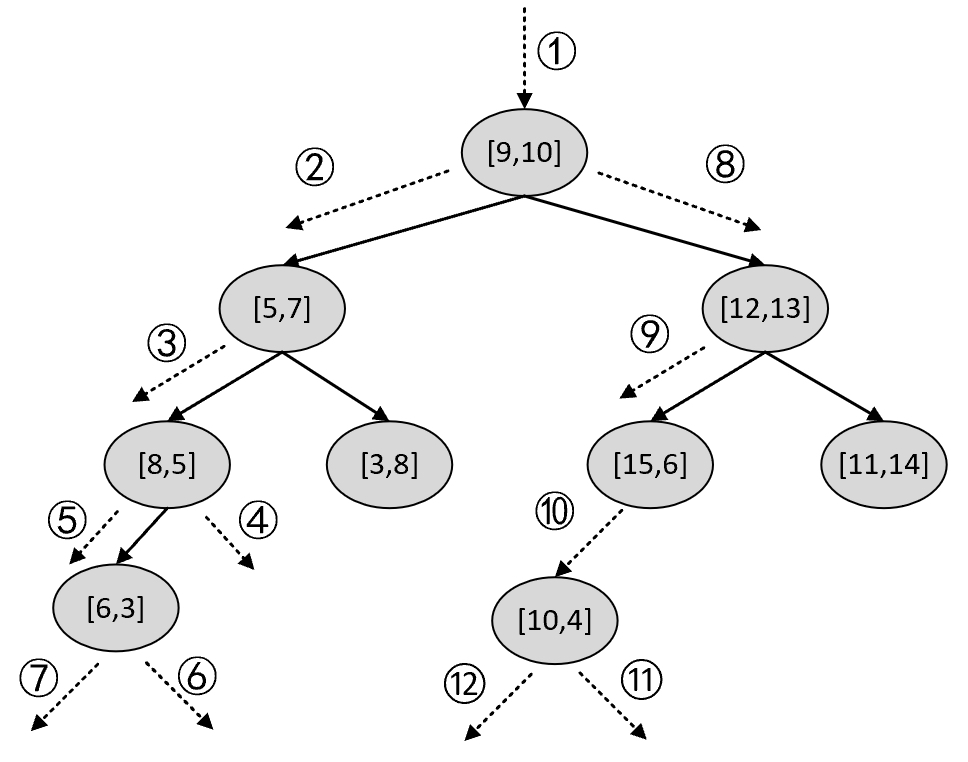
经过上述步骤后,相信读者对于kd树的搜索过程已经有了清晰的认识。同时,建议各位读者在阅读上述内容时自己动手在纸上画一画整个流程,当然还可以运行本书配套的代码来详细输出上述的搜索过程,详见AllBooKCode/Chapter05/C05_knn_imp_from_scratch.py
5.4.4 K近邻kd树搜索#
在介绍完kd树的最近邻搜索原理后,我们便可以轻松地理解kd树的K近邻搜索过程。需要再次提醒的是,这里的“K”和“k”分别表示两种不同的含义,“K”表示要搜索并得到离给定点最近的K个样本点,而“k”表示的是样本点的维度。
总地来讲,K近邻的搜索过程和最近邻的搜索过程类似,只是需要额外地维护一个大小为K的有序列表。在整个列表中,当前离被搜索点最近的样本点放在首位,而离被搜索点最远的样本点放在末尾。具体的搜索过程可以总结为
(1) 设定大小为K的有序列表用来保存当前离搜索点最近的K个样本点。
(2) 从根节点开始,并设其为当前节点。
(3) 如果当前节点为空,则结束。
(4) 如果列表不满,则直接将当前样本插入列表中; 如果列表已满,则判断当前样本到被搜索点的距离是否小于列表最后一个元素到被搜索点的距离,成立则将列表中最后一个元素删除,并插入当前样本(每次插入后仍有序)。
(5) 如果被搜索点的划分维度小于当前节点的划分维度,则设当前节点的左孩子为新的当前节点并执行步骤(3)(4)(5)(6)。反之设当前节点的右孩子为新的当前节点并执行步骤(3)(4)(5)(6)。
(6) 如果列表不满K个样本,或者如果被搜索点的划分维度到当前节点划分维度的距离小于列表中最后一个元素到被搜索点的距离,则设当前节点的另外一个孩子为当前节点并执行步骤(3)(4)(5)(6)。
递归完成后,此时离被搜索点最近的K个样本点就是有序列表中的K个样本。
上述步骤同样可以通过一个更清晰的伪代码进行表达,代码如下:
1 KNearestNodes, n = [], 0
2 def NearestNodeSearch(curr_node):
3 if curr_node == None:
4 return
5 if n < K:
6 KNearestNodes.insert(curr_node) # 插入后保持有序
7 if n >= K and
8 distance(curr_node, q) < distance(curr_node, KNearestNodes[-1]):
9 KNearestNodes.pop()
10 KNearestNodes.insert(curr_node) # 插入后保持有序
11 if q_i < curr_node_i:
12 NearestNodeSearch(curr_node.left)
13 else:
14 NearestNodeSearch(curr_node.right)
15 if n < K or | curr_node_i - q_i | < distance(q, KNearestNodes[-1]):
16 NearestNodeSearch(curr_node.other)在上述代码中,KNearestNodes[-1]表示取有序列表中的最后一个元素,q_i和curr_node_i分别表示被搜索点和当前节点的划分维度,curr_node.other表示curr_node.left和curr_node.right中先前未被访问过的子树。
5.4.5 K 近邻搜索示例#
下面以图5-8中的kd树为例,来搜索离样本点$q=[8.9,4]$最近的3个样本点。
在搜索伊始,有序列表为空,K=3。第1次递归: 此时将根节点[9,10]设为当前节点,因满足步骤(4)中候选列表为空的条件,所以直接将根节点加入候选列表中,即此时KNearestNodes=([9,10])。接着,由于被搜索点的划分维度8.9小于当前节点的划分维度9,因此将当前节点的左孩子[5,7]设为新的当前节点并进入第2次递归。第2次递归: 继续执行步骤(4),由于此时候选列表未满,所以直接将当前节点插入候选列表中并排序,即此时KNearestNodes=([5,7], [9,10])。进一步,由于被搜索点的划分维度4小于当前节点的划分维度7,因此将当前节点的左孩子[8,5]设为新的当前节点并进入第3次递归。第3次递归: 继续执行步骤(4),由于此时候选列表未满,所以直接将当前节点插入候选列表中,即此时KNearestNodes=([8,5], [5,7], [9,10])。进一步,由于被搜索点的划分维度8.9大于当前节点的划分维度8,所以将当前节点的右孩子设为新的当前节点,并进入第4次递归。
第4次递归: 由于此时当前节点为空,所以第4次递归结束并返回第3次递归中,即此时的当前节点为[8,5],并继续执行步骤(6)。此时候选列表已满,但由于被搜索点的划分维度8.9到当前划分维度8的距离为0.9,小于被搜索点到有序列表中最后一个样本点距离6.001,说明可能存在一个比有序列表中最后一个元素更近的样本点,所以将当前节点的左孩子设为新的当前节点并进入第5次递归。第5次递归:此时当前节点为[6,3],继续执行步骤(4),尽管此时列表已满但是当前节点[6,3]到被搜索点[8.9,4]的距离3.068,小于被搜索点[8.9,4]到列表中最后一个节点[9,10]的距离6.001,所以进行替换即此时KNearestNodes=([8,5], [6,3], [5,7])。进一步,由于被搜索点的划分维度4大于当前节点的划分维度3,因此将当前节点的右孩子设为新的当前节点并进入第6次递归。
第6次递归: 由于当前节点为空,所以第6次递归结束并回到第5次递归中。返回第5次递归后,此时的当前节点为[6,3],继续执行步骤(6)。此时列表已满,但由于被搜索点的划分维度4到当前划分维度3的距离为1,小于被搜索点到有序列表中最后一个样本点距离4.92,所以将当前节点的左孩子设为新的当前节点并进入第7次递归。第7次递归:由于此时当前节点为空,所以第7次递归结束并返回第2次递归中,此时的当前节点为[5,7],并继续执行步骤(6)。此时候选列表已满,但由于被搜索点的划分维度4到当前划分维度7的距离为3,小于被搜索点到有序列表中最后一个样本点距离4.92,所以将当前节点的右孩子[3,8]设为新的当前节点并进入第8次递归。
第8次递归:此时当前节点为[3,8],由于其到被搜索点的距离7.128大于列表中最后一个节点到被搜索点的距离4.92,不进行替换。进一步,由于被搜索点的划分维度8.9大于当前节点的划分维度3,因此将当前节点的右孩子设为新的当前节点并进入第9次递归。第9次递归: 由于当前节点为空,所以第9次递归结束并回到第8次递归中,此时的当前节点为[3,8],并继续执行步骤(6)。进一步,步骤(6)不成立返回第1次递归中,此时的当前节点为[9,10],并继续执行步骤(6)。此时候选列表已满,但由于被搜索点的划分维度8.9到当前划分维度9的距离为0.1,小于被搜索点到有序列表中最后一个样本点距离4.92,所以将当前节点的右孩子[12,13]设为新的当前节点并进入第10次递归。
第10次递归:此时的当前节点为[12,13],由于其到被搜索点的距离9.519,大于列表中最后一个节点到被搜索点的距离4.92,不进行替换。进一步,由于被搜索点的划分维度4小于当前节点的划分维度13,因此将当前节点的左孩子[15,6]设为新的当前节点并进入第11次递归。第11次递归:此时的当前节点为[15, 6],由于其到被搜索点的距离6.42,大于候选列表中最后一个节点到被搜索点的距离4.92,不进行替换。进一步,由于被搜索点的划分维度8.9小于当前节点的划分维度15,因此将当前节点的左孩子[10,4]设为新的当前节点并进入第12次递归。
第12次递归:此时的当前节点为[10,4],继续执行步骤(4)。尽管此时列表已满但是当前节点[10, 4]到被搜索点[8.9,4]的距离1.1,小于被搜索点[8.9,4]到列表中最后一个节点[5,7]的距离4.92,所以进行替换即此时KNearestNodes=([10,4], [8,5], [6,3])。进一步,由于被搜索点的划分维度4大于等于当前节点的划分维度4,因此将当前节点的右孩子设为新的当前节点并进入第13次递归。第13次递归:由于当前节点为空,所以第13次递归结束并回到第12次递归中,此时的当前节点为[10,4],并继续执行步骤(6)。此时候选列表已满,但由于被搜索点的划分维度4到当前划分维度4的距离为0,小于被搜索点到有序列表中最后一个样本点距离3.068,所以将当前节点的左孩子设为新的当前节点并进入第14次递归。
第14次递归: 由于当前节点为空,所以第14次递归结束并回到第11次递归中,此时的当前节点为[15,6],并继续执行步骤(6)。返回第11次递归后,不满足步骤(6)中的条件,所以再次返回10次递归,当前节点为[12, 13],并执行步骤(6)。返回第10次递归以后,此时候选列表已满,且被搜索点的划分维度4到当前划分维度13的距离为9,大于被搜索点到有序列表中最后一个样本点距离3.068,所以不满足步骤(6)中的条件,到此所有递归过程结束。此时候选列表中的元素便为kd树中离被搜索点[8.9,4]最近的3个样本点,即KNearestNodes=([10,4], [8,5], [6,3])。同时,整个递归过程的执行顺序如图5-10所示。
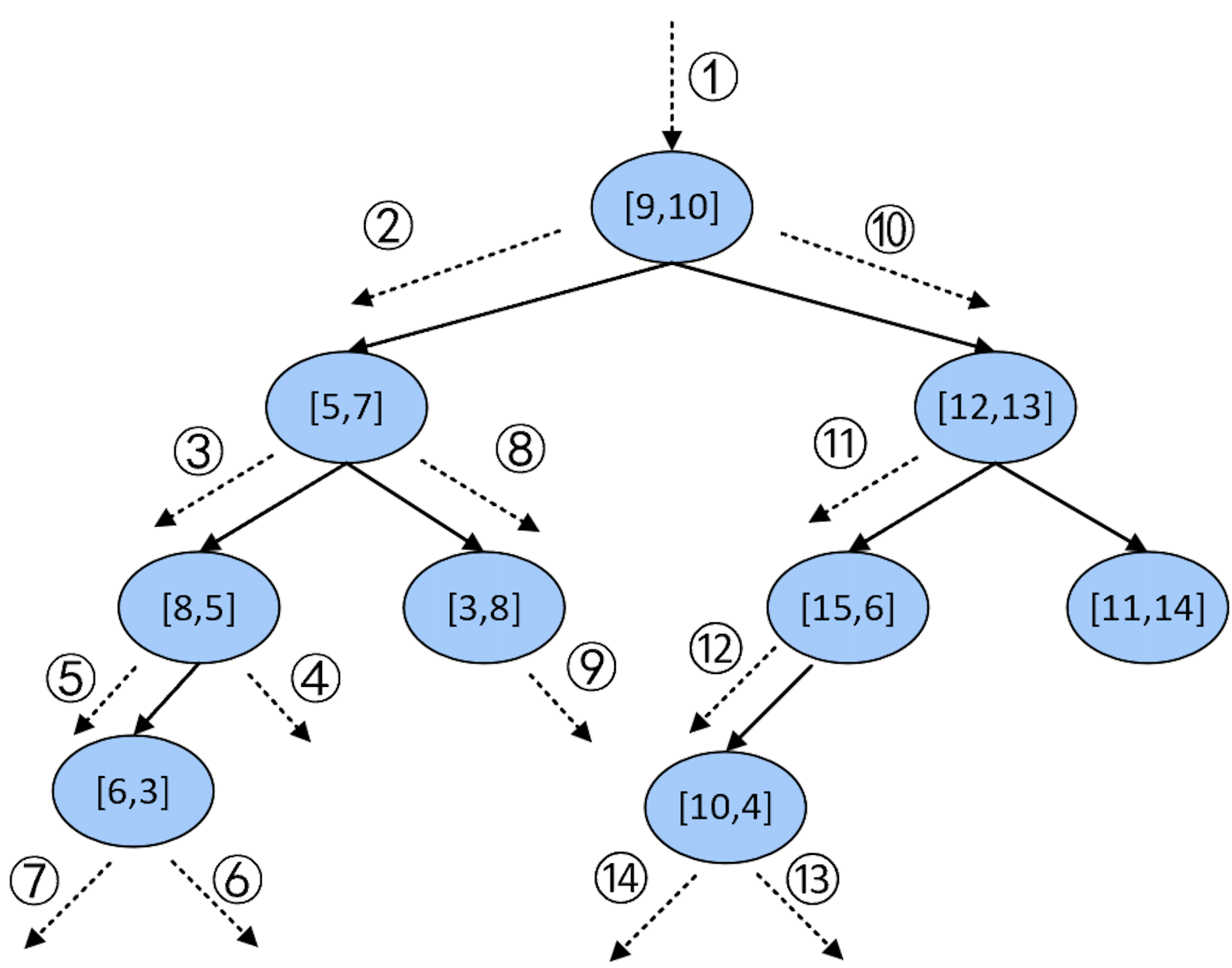
至此,对于K近邻算法的原理就介绍完了。
5.4.6 小结#
在本节中,我们首先介绍了kd树的基本原理,以及如何构造一棵kd树;接着介绍了如何通过kd树来根据给定的样本的搜索距离其最近的样本点,并通过一个实际的搜索示例进行了详细介绍;最后介绍了如何在最近邻的基础上,在kd树中搜索离给定点最近的K个样本点,即K最近邻搜索。在下一节内容中,我们将介绍如何从零实现K近邻算法。