8.8 从零实现CART算法及剪枝示例#
在8.7节内容中我们已经详细介绍了CART分类树的构建原理和剪枝过程,在本节内容中将开始介绍如何从零开始编码实现一个简易版的CART分类树。同时,由于在实际场景中数据集的特征维度大多都是连续型的特征变量,因此需要对其进行离散化处理,后续也将以连续型特征为例进行编码实现。具体离散化方法见8.6.1节内容,这里不再赘述。
下面,将直接通过表8-6中的样本数据来详细介绍在CART分类树中如何离散化连续型特征并构造相应的决策树。
8.8.1 连续型特征生成示例#
在处理连续型特征变量时,第一步便是需要将各个维度的特征进行离散化,然后再根据离散化后的区间来对特征进行判断。具体地,表8-6中对应的3个特征在离散化后各特征的取值分割点分别为: $[0.5]$ 、 $[0.5]$ 、$ [0.5,1.5]$。
由表8-6中的数据可知,根据式(8-35)可得,此时的其基尼不纯度为
$$ \text{Gini}(D)=1-\sum\limits_{k=1}^{K}{{{\left( \frac{|{{C}_{k}}|}{|D|} \right)}^{2}}}=1-{{\left( \frac{5}{15} \right)}^{2}}-{{\left( \frac{10}{15} \right)}^{2}}\approx 0.444\tag{8-51} $$并且对于特征${{A}_{1}}$来说,根据其取值是否满足条件$A_1\leq0.5$,可以将原始样本划分为$D_1$和$D_2$两个部分。由式(8-37)得
$$ \text{Gini}(D,{A}_{1}\leq0.5)=\frac{7}{15}\text{Gini}({{D}_{1}})+\frac{8}{15}\text{Gini}({{D}_{2}})=\frac{7}{15}\times \frac{24}{49}+\frac{8}{15}\times \frac{14}{64}\approx 0.345\tag{8-52} $$同理,对于特征${{A}_{2}}$来说,根据其取值是否满足条件$A_2\leq0.5$,也可以将原始样本划分为$D_1$和$D_2$两个部分。此时有
$$ \text{Gini}(D,{A}_{2}\leq0.5)=\frac{8}{15}\text{Gini}({{D}_{1}})+\frac{7}{15}\text{Gini}({{D}_{2}})=\frac{8}{15}\times \frac{1}{2}+\frac{7}{15}\times \frac{12}{49}\approx 0.381\tag{8-53} $$进一步,对于特征${{A}_{3}}$来说,根据其取值是否分别满足条件$A_3\leq0.5$和$A_3\leq1.5$,每一次也可将原始样本划分为$D_1$和$D_2$两个部分。此时有
$$ \begin{aligned} \text{Gini}(D,{A}_{3}\leq0.5)&=\frac{12}{15}\text{Gini}({{D}_{1}})+\frac{3}{15}\text{Gini}({{D}_{2}})=\frac{12}{15}\times \frac{4}{9}+\frac{3}{15}\times \frac{4}{9}\approx 0.444\\[2ex] \text{Gini}(D,{A}_{3}\leq1.5)&=\frac{7}{15}\text{Gini}({{D}_{1}})+\frac{8}{15}\text{Gini}({{D}_{2}})=\frac{7}{15}\times \frac{20}{49}+\frac{8}{15}\times \frac{30}{64}\approx 0.441 \end{aligned}\tag{8-54} $$注意:此时每次划分时都是将样本集合划分为两个部分,即$A_i \leq a$和$A_i> a$。
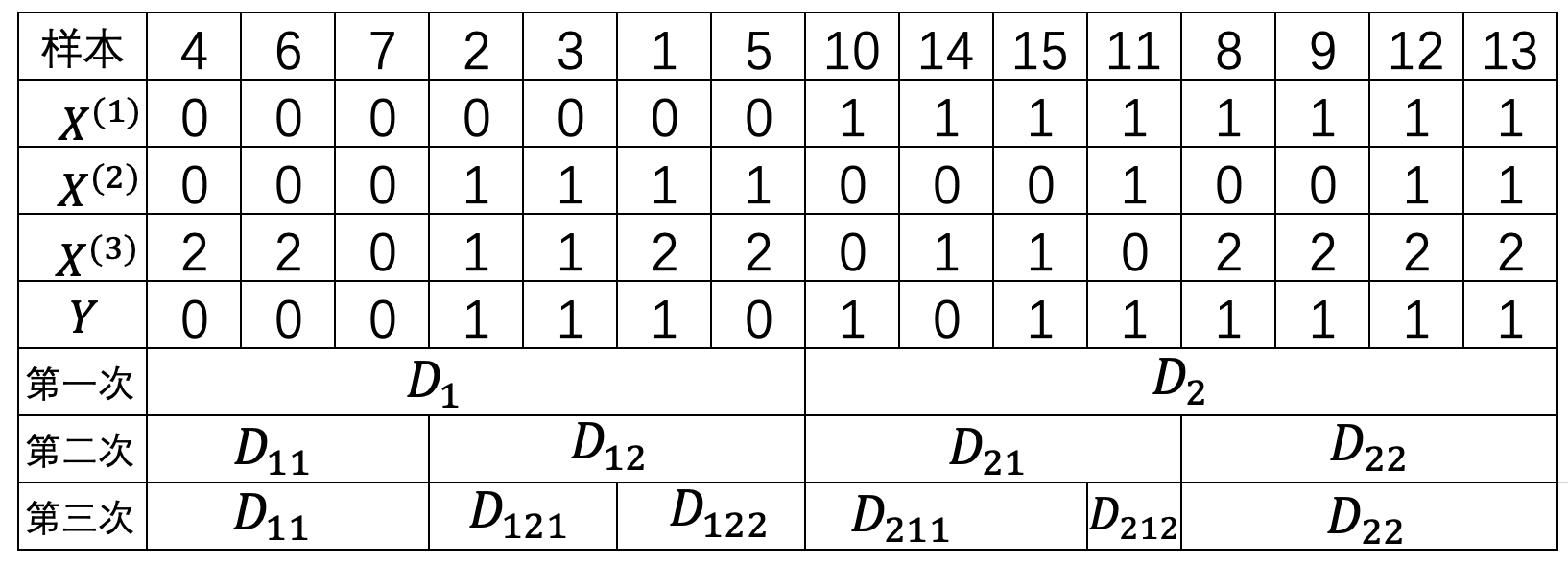
由以上计算结果可知,使用${A}_{1}\leq0.5$时对样本集合进行划分所得到的基尼不纯度最小。故,根节点应该以${A}_{1}\leq 0.5$ 是否成立来进行分割,如图8-21所示(在每个节点中,第1行表示当前节点的划分特征维度以及样本的索引,第2行分别表示判断区间和每个类别中的各个样本的数量)。
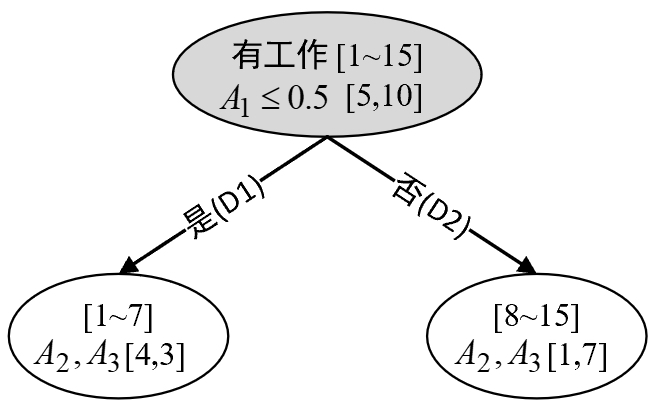
从图8-21可以看出,根据特征$A_1$是否存满足条件$A_1\leq0.5$可以将原始样本划分为$D_1$和$D_2$两个部分。经过这次划分后,原始的样本集合就被特征“有工作”分割成了左右两个部分。接下来,再对左右两个集合递归的进行上述步骤。
1. 对于左子$D_1$树来说
$$ \text{Gini}(D_1)=1-(\frac{4}{7})^2-(\frac{3}{7})^2\approx0.490\tag{8-55} $$在特征$A_2$中有
$$ \text{Gini}(D_1, A_2\leq0.5)=\frac{3}{7}(1-1)+\frac{4}{7}(1-\frac{1}{16}-\frac{9}{16})\approx0.214\tag{8-56} $$在特征$A_3$中有
$$ \begin{aligned} \text{Gini}(D_1,A_3\leq 0.5)&=\frac{1}{7}(1-1)+\frac{6}{7}(1-\frac{1}{4}-\frac{1}{4})\approx0.4286\\[2ex] \text{Gini}(D_1, A_3\leq 1.5)&=\frac{3}{7}(1-\frac{1}{9}-\frac{4}{9})+\frac{4}{7}(1-\frac{1}{16}-\frac{9}{16})\approx0.405\\[2ex] \end{aligned}\tag{8-57} $$此时,基尼不纯度$\text{Gini}(D_1, A_2\leq 0.5)\approx0.214$最小,故选择$ A_2\leq 0.5$作为判断区间,此时划分结果如表8-7所示。
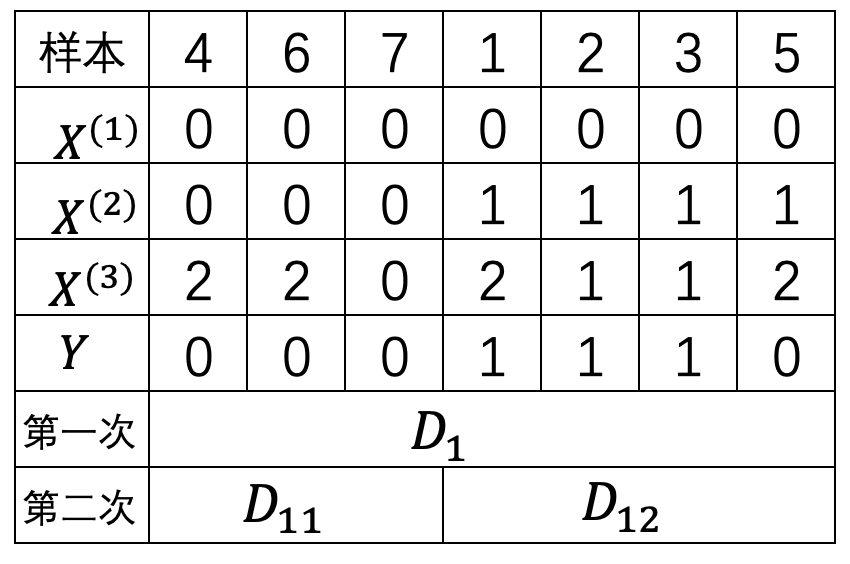
2. 对于右子$D_2$树来说
$$ \text{Gini}(D_2)=1-(\frac{1}{8})^2-(\frac{7}{8})^2\approx0.219\tag{8-58} $$在特征$A_2$中有
$$ \text{Gini}(D_2, A_2\leq0.5)=\frac{5}{8}(1-\frac{1}{25}-\frac{16}{25})+\frac{3}{8}(1-1)\approx0.2\tag{8-59} $$在特征$A_3$中有
$$ \begin{aligned} \text{Gini}(D_2,A_3\leq 0.5)&=\frac{2}{8}(1-1)+\frac{6}{8}(1-\frac{1}{36}-\frac{25}{36})\approx0.208\\[2ex] \text{Gini}(D_2,A_3\leq 1.5)&=\frac{4}{8}(1-\frac{1}{16}-\frac{9}{16})+\frac{4}{8}(1-1)\approx0.188\\[2ex] \end{aligned}\tag{8-60} $$此时,基尼不纯度$\text{Gini}(D_2, A_3\leq1.5)\approx0.188$最小,故选择 $A_3\leq1.5$作为判断区间,此时划分结果如表8-8所示。
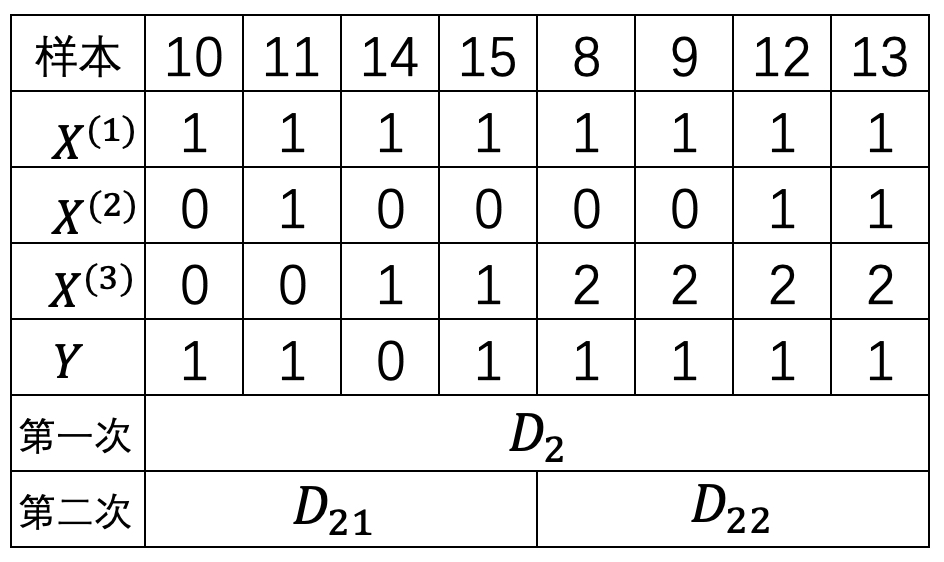
进一步,根据表8-7和表8-8的划分结果便可以得到如图8-22所示的结果。
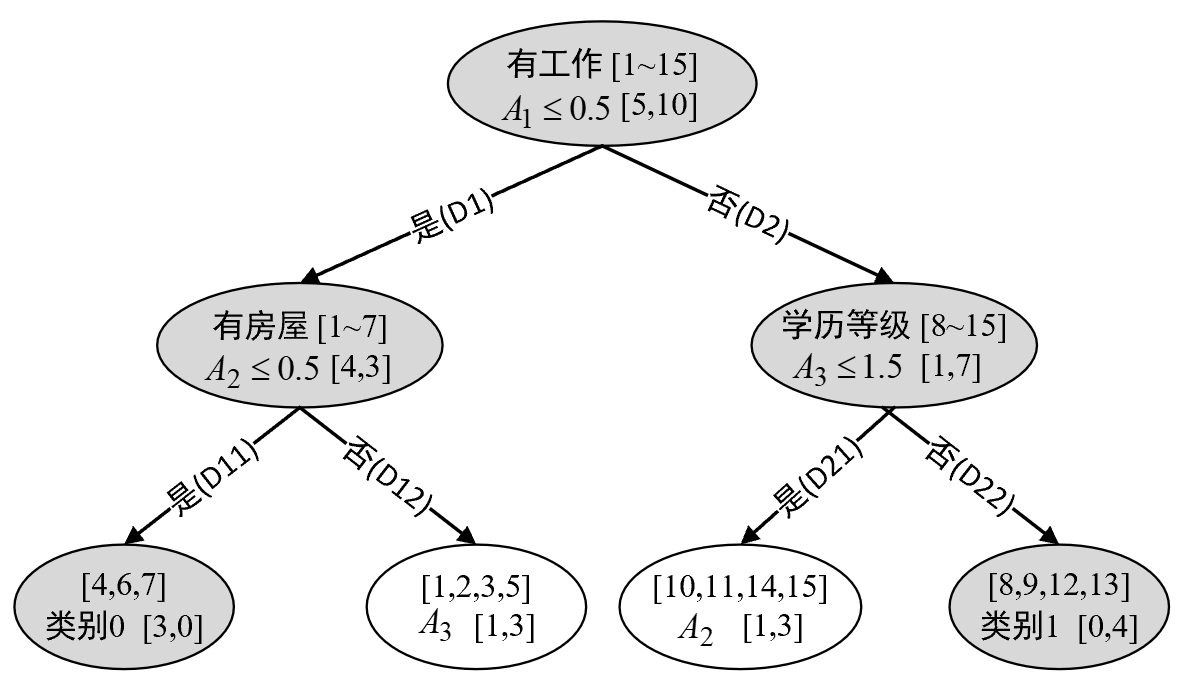
根据图8-22可知,此时对于集合$D_{11}$来说其只有一个类别,因此停止划分。
3. 对于集合$D_{12}$来说
$$ \text{Gini}(D_{12})=1-(\frac{1}{4})^2-(\frac{3}{4})^2\approx0.375\tag{8-61} $$在特征$A_3$ 中有
$$ \text{Gini}(D_{12}, A_3\leq 1.5)=\frac{2}{4}(1-1)+\frac{2}{4}(1-\frac{1}{4}-\frac{1}{4})=0.25\tag{8-62} $$此时,基尼不纯度$\text{Gini}(D_{12},A_3\leq1.5)=0.25$最小,故选择$A_3\leq1.5$作为判断区间。
4. 对于集合$D_{21}$来说
$$ \text{Gini}(D_{12})=1-(\frac{1}{4})^2-(\frac{3}{4})^2\approx0.375\tag{8-63} $$在特征$A_2$中有
$$ \begin{aligned} \text{Gini}(D_{21},A_2\leq0.5)=\frac{3}{4}(1-\frac{1}{9}-\frac{4}{9})+\frac{1}{4}(1-1)\approx0.333 \end{aligned}\tag{8-64} $$此时,基尼不纯度$\text{Gini}(D_{21},A_2\leq0.5)\approx0.333$最小,故选择$A_2\leq0.5$作为判断区间。当然,对于特征$A_2$来说其只有一个取值区间,所以也可以不用计算。
对于集合$D_{22}$ 来说其只有一个类别,所以也停止划分。这样便可以得到如表8-9所示的划分结果。
最终,根据表8-9便可得到如图8-23所示的决策树。
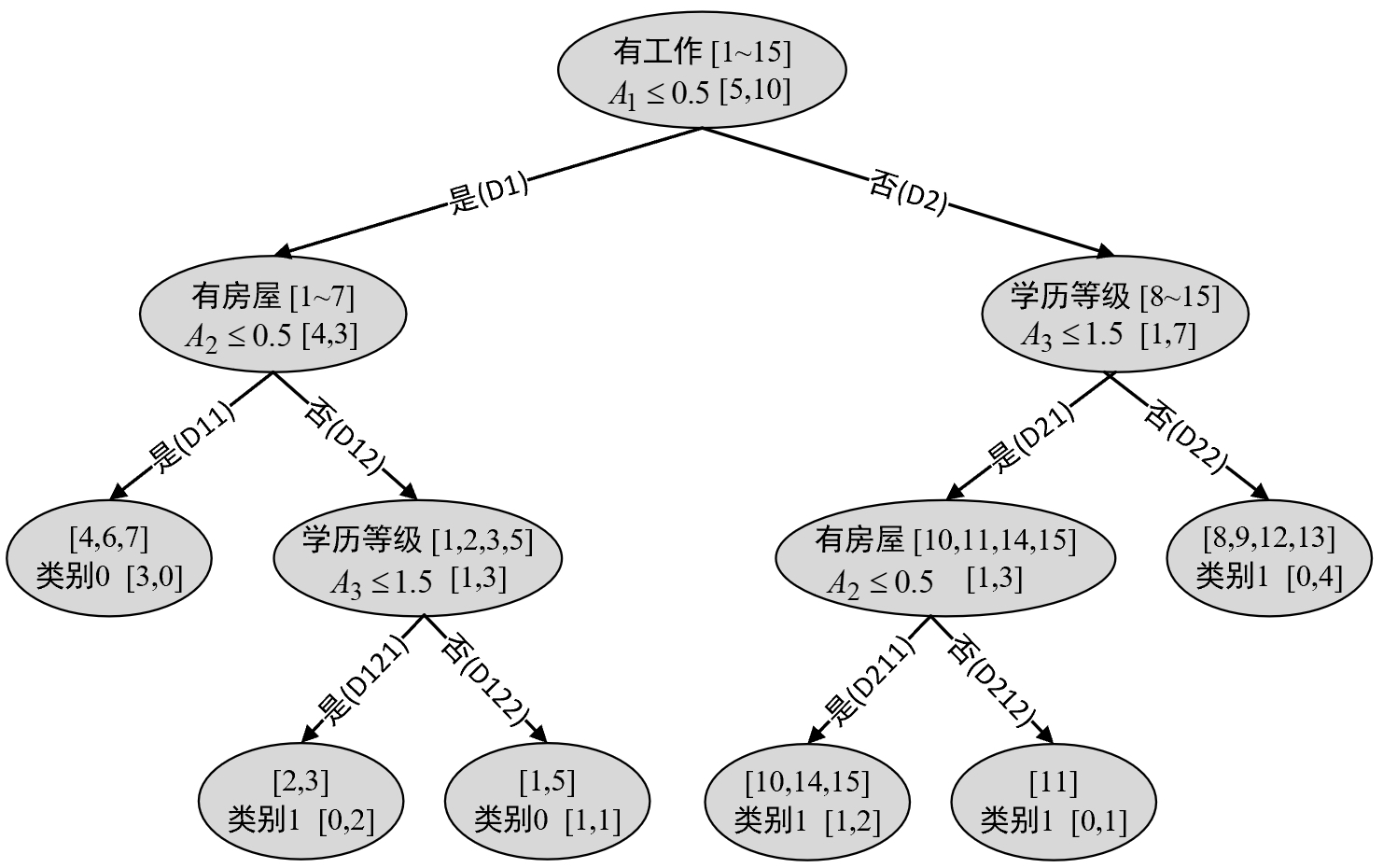
这里值得一提的是,由于划分特征的处理方式不同,所以图8-23中的结果与图8-14中的结果略有差异。
8.8.2 连续型特征剪枝示例#
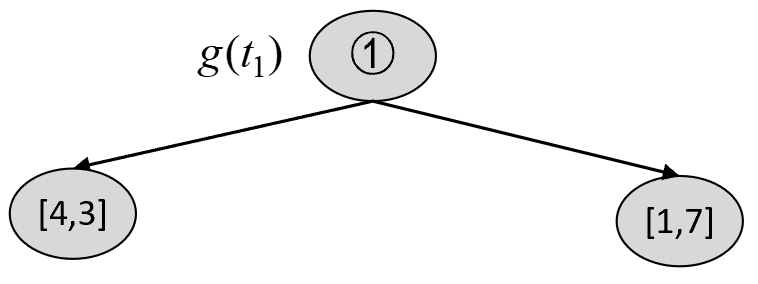
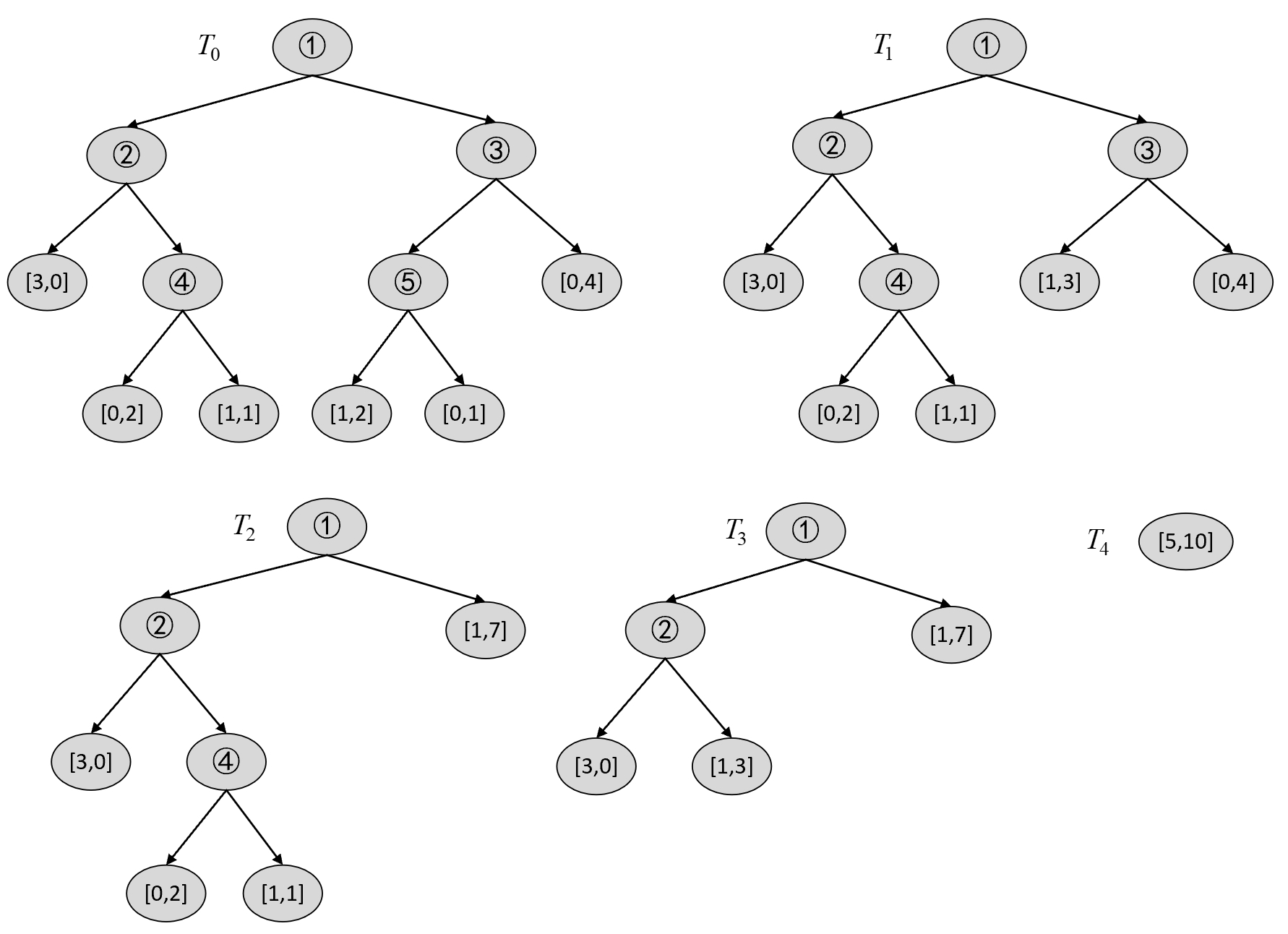
在简单介绍完连续型特征变量的CART分类树生成示例后,我们再以此生成结果为例来详细介绍整个剪枝过程。由图8-23可知,此时的决策树便是子树序列中的$T_0$ ,且可以简化为如图8-24所示的结果。
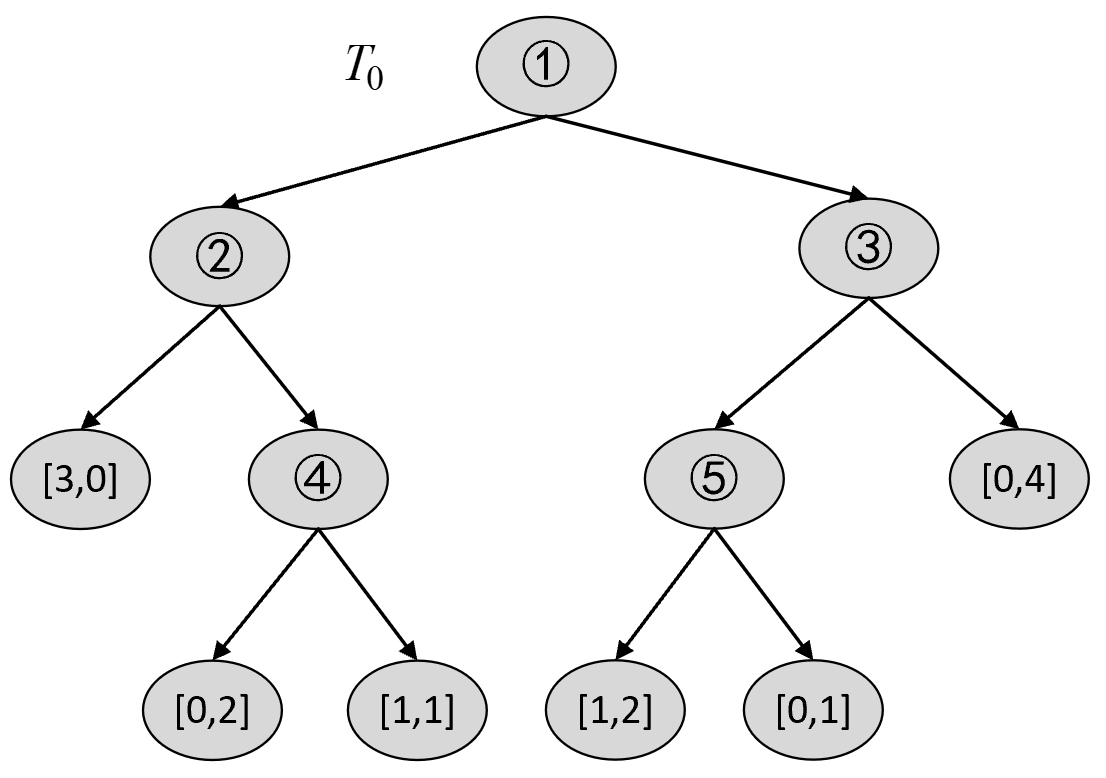
其中叶子节点中的数字表示每个类别的样本数。
此时,根据$T_0$可以构建$T_1$中 的各种剪枝情况,然后选择最优节点进行剪枝。对于$T_0$ 来说,第1种情况为减掉5号节点,如图8-25所示。
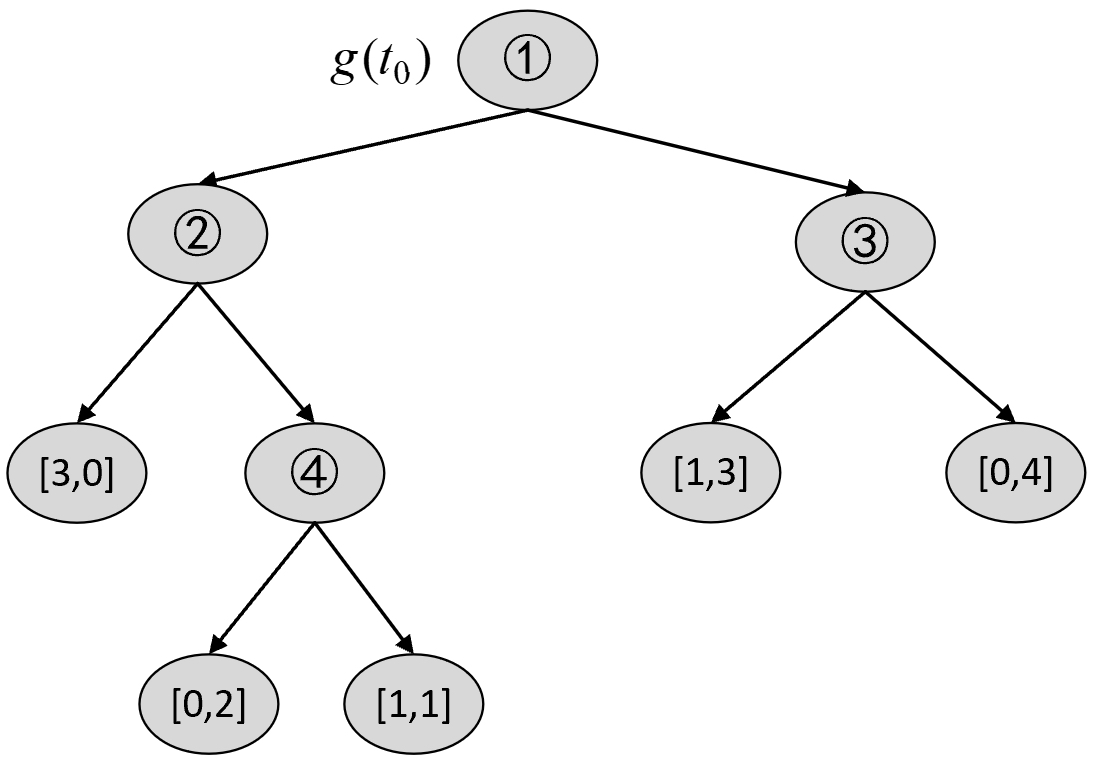
根据图8-24和图8-25可知,由式(8-45)和式(8-46)可分别计算得到剪枝前$C(T_t)$和剪枝后$C(t)$的损失分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{3}+2\cdot\log\frac{2}{3}+1\cdot\log1)\approx2.7549\\[2ex] C(t)&=-(1\cdot\log\frac{1}{4}+3\cdot\log\frac{3}{4})\approx3.2451 \end{aligned}\tag{8-65} $$此时有
$$ g(t_0)=\frac{C(t)-C(T_t)}{|T_t|-1}=\frac{3.2451-2.7549}{2-1}\approx0.4902\tag{8-66} $$对于$T_0$ 来说,第2种情况为减掉4号节点,如图8-26所示。
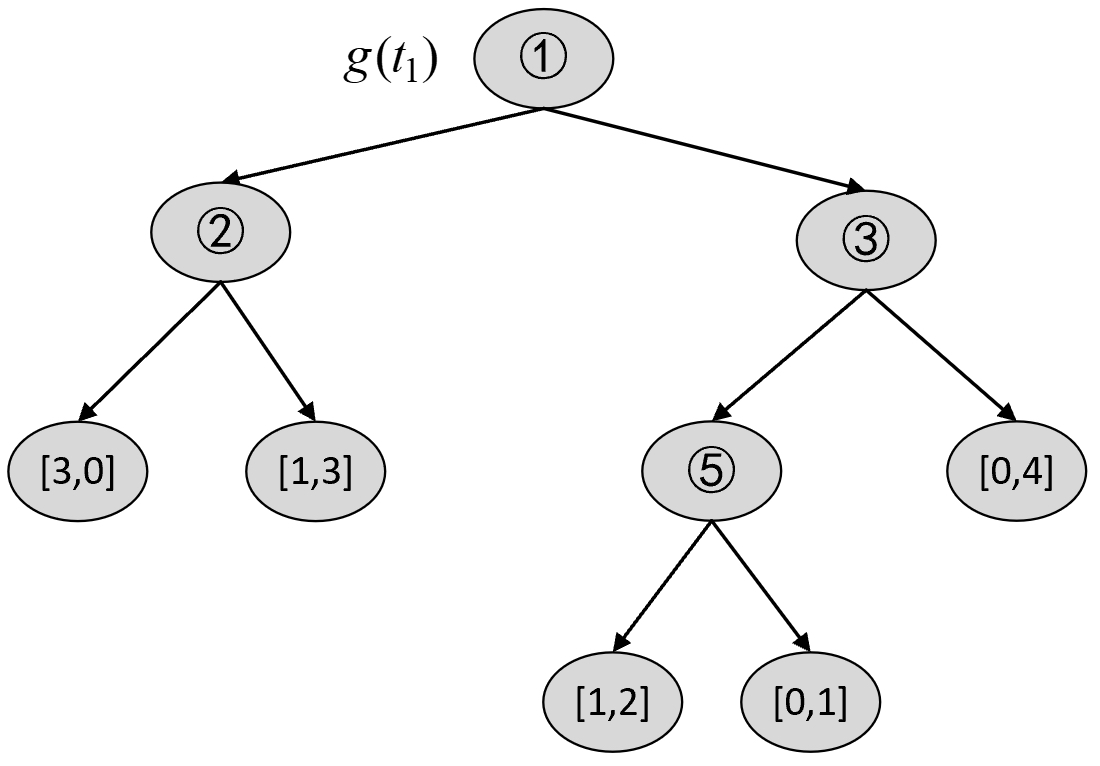
根据图8-23和图8-25可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_1)$分别为
$$ \begin{aligned} C(T_t)&=-(2\cdot\log\frac{2}{2}+1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{2})=2\\[2ex] C(t)&=-(1\cdot\log\frac{1}{4}+3\cdot\log\frac{3}{4})\approx3.2451\\[2ex] g(t_1)&=\frac{3.245-2}{2-1}=1.2451 \end{aligned}\tag{8-67} $$对于$T_0$ 来说,第3种情况为减掉3号节点,如图8-27所示。
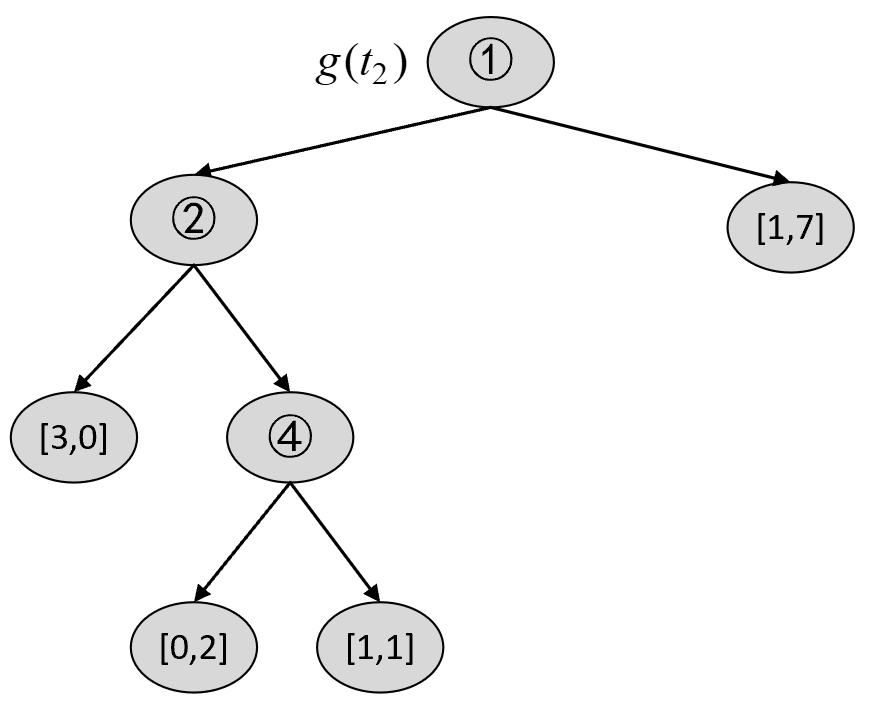
根据图8-24和图8-27可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_2)$分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{3}+2\cdot\log\frac{2}{3}+1\cdot\log\frac{1}{1}+4\cdot\log\frac{4}{4})\approx2.7549\\[2ex] C(t)&=-(1\cdot\log\frac{1}{8}+7\cdot\log\frac{7}{8})\approx4.3485\\[2ex] g(t_2)&=\frac{4.3485-2.7549}{3-1}=0.7968 \end{aligned}\tag{8-68} $$对于$T_0$ 来说,第4种情况为减掉2号节点,如图8-28所示。
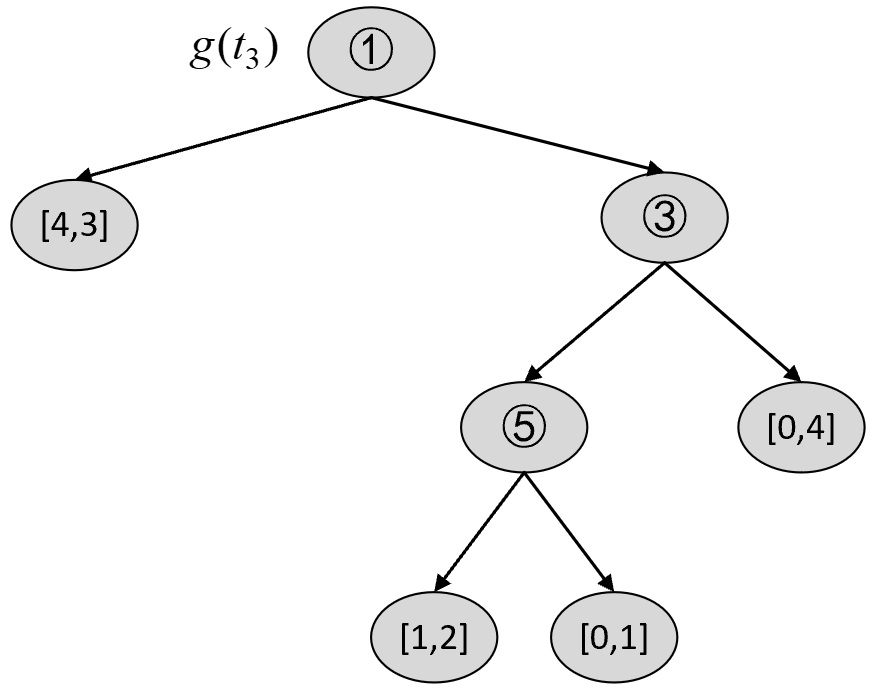
根据图8-24和图8-28可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_3)$分别为
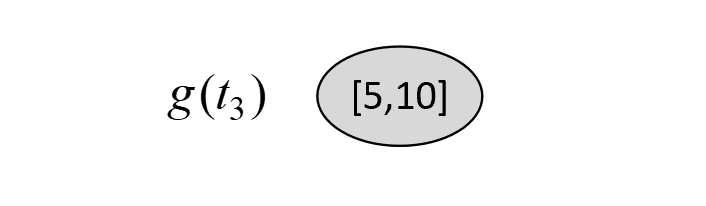
$$ \begin{aligned} C(T_t)&=-(3\cdot\log\frac{3}{3}+2\cdot\log\frac{2}{2}+1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{2})=2\\[2ex] C(t)&=-(4\cdot\log\frac{4}{7}+3\cdot\log\frac{3}{7})\approx6.8966\\[2ex] g(t_3)&=\frac{6.897-2}{3-1}\approx2.4483 \end{aligned}\tag{8-69} $$对于$T_0$来说,第5情况为剪掉1号节点,如图8-29所示。
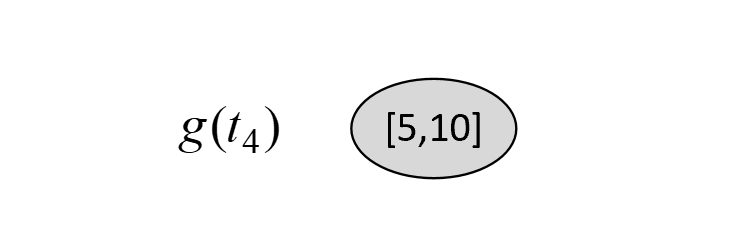
根据图8-24和图8-29可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_4)$分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{3}+2\cdot\log\frac{2}{3})\approx4.7549\\[2ex] C(t)&=-(5\cdot\log\frac{5}{15}+10\cdot\log\frac{10}{15})\approx13.7755\\[2ex] g(t_4)&=\frac{13.7744-4.7549}{6-1}\approx 1.8039 \end{aligned}\tag{8-70} $$此时,对于$T_0$来说,其所有可能的剪枝情况我们都列举完了,且同时有
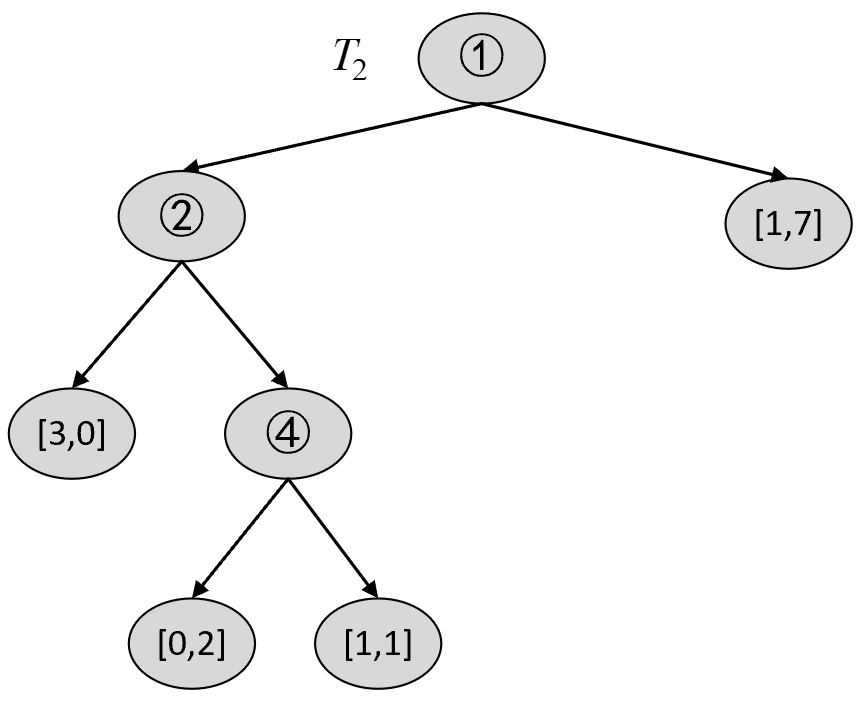
$$ \alpha_1=\min[g(t_0),g(t_1),g(t_2),g(t_3),g(t_4)]=0.4902\tag{8-71} $$由此可知,$T_1$ 如图8-30所示。
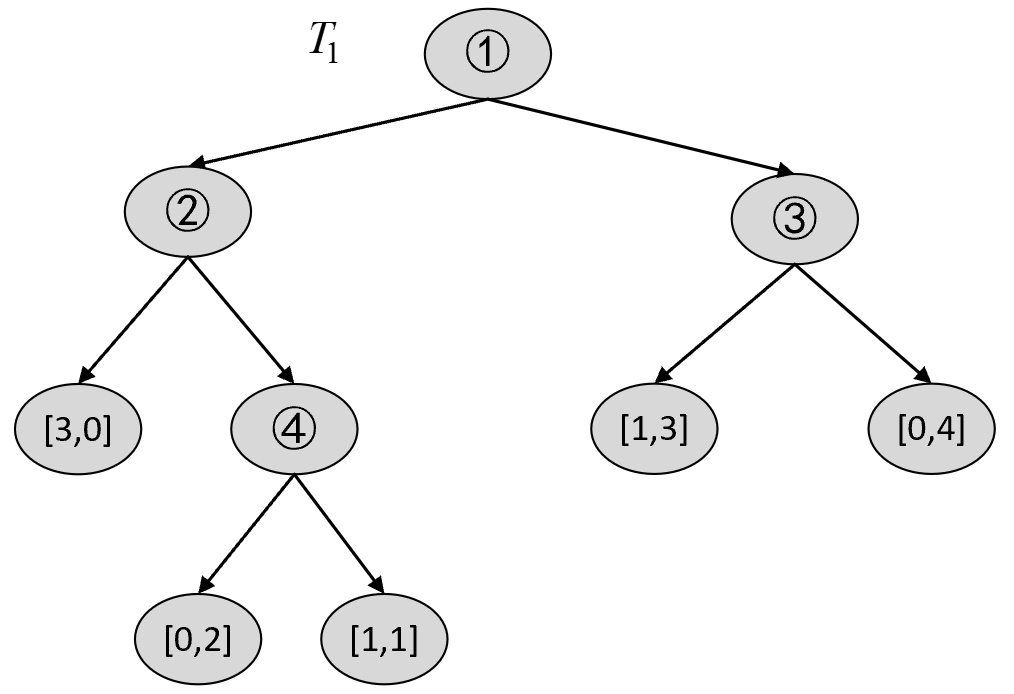
根据$T_1$可以构建$T_2$中的各种剪枝情况,然后选择最优节点进行剪枝。对于$T_1$来说,第1种情况为剪掉4号节点,结果如图8-31所示。
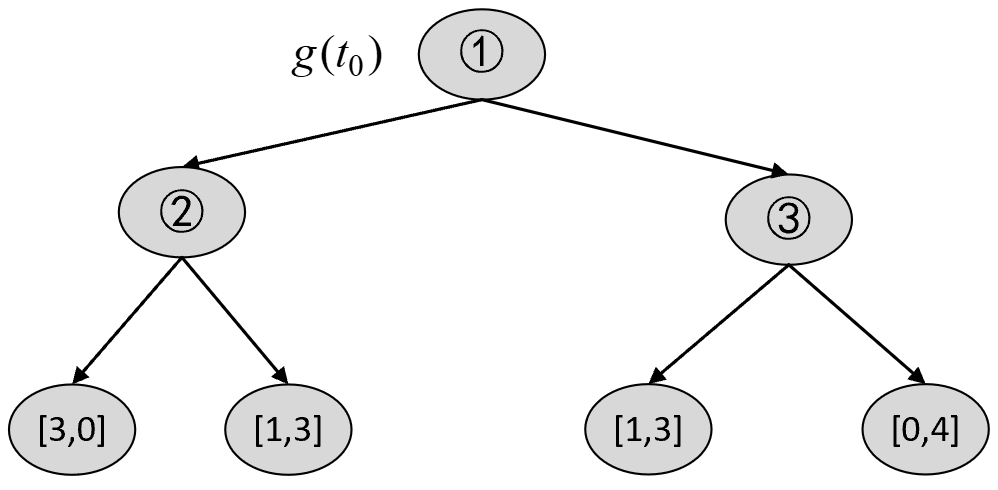
根据图8-30和图8-31可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_0)$分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{2})=2\\[2ex] C(t)&=-(1\cdot\log\frac{1}{4}+3\cdot\log\frac{3}{4})\approx3.2451\\[2ex] g(t_0)&=\frac{3.2451-2}{2-1}\approx1.2451 \end{aligned}\tag{8-72} $$对于$T_1$ 来说,第2种情况为剪掉3号节点,结果如图8-32所示。
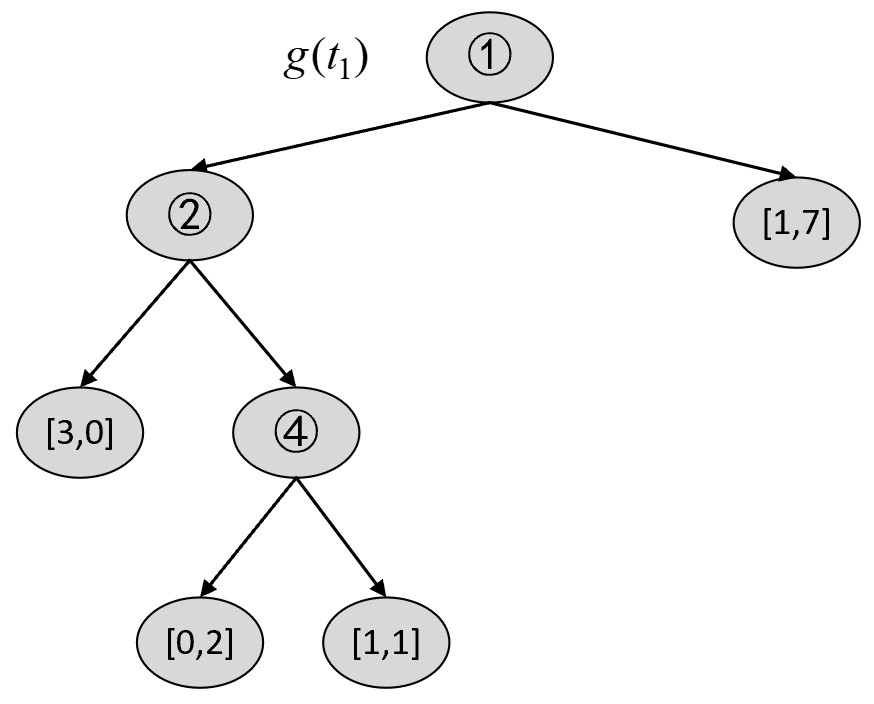
根据图8-30和图8-32可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_1)$分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{4}+3\cdot\log\frac{3}{4})\approx3.2451\\[2ex] C(t)&=-(1\cdot\log\frac{1}{8}+7\cdot\log\frac{7}{8})\approx4.3485\\[2ex] g(t_1)&=\frac{4.3485-3.2451}{2-1}\approx1.1034 \end{aligned}\tag{8-73} $$对于$T_1$ 来说,第3种情况为剪掉2号节点,结果如图8-33所示。
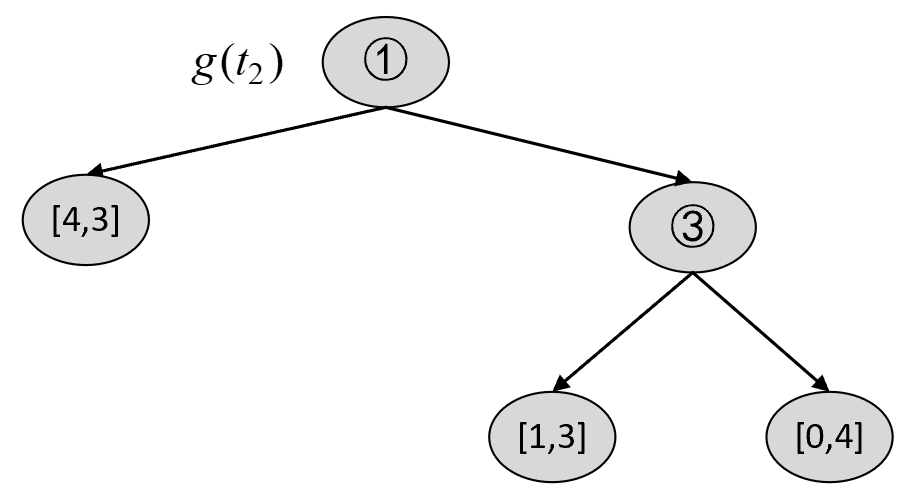
根据图8-30和图8-33可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_2)$分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{2})=2\\[2ex] C(t)&=-(4\cdot\log\frac{4}{7}+3\cdot\log\frac{3}{7})\approx6.8966\\[2ex] g(t_2)&=\frac{6.897-2}{3-1}=2.4483 \end{aligned}\tag{8-74} $$对于$T_1$来说,第4种情况为剪掉1号节点,结果如图8-34所示。
根据图8-30和图8-34可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_3)$分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{4}+3\cdot\log\frac{3}{4})\approx5.2451\\[2ex] C(t)&=-(5\cdot\log\frac{5}{15}+10\cdot\log\frac{10}{15})\approx13.7744\\[2ex] g(t_3)&=\frac{13.7744-5.2451}{5-1}\approx 2.1323 \end{aligned}\tag{8-75} $$此时,对于$T_1$来说,其所有可能的剪枝情况我们都列举完了,且同时有
$$ \alpha_2=\min[g(t_0),g(t_1),g(t_2),g(t_3)]=1.1034\tag{8-76} $$由此可知,$T_2$ 如图8-35所示。
根据$T_2$可以构建$T_3$中的各种剪枝情况,然后选择最优节点进行剪枝。对于$T_2$来说,第1种情况为剪掉4号节点,结果如图8-36所示。
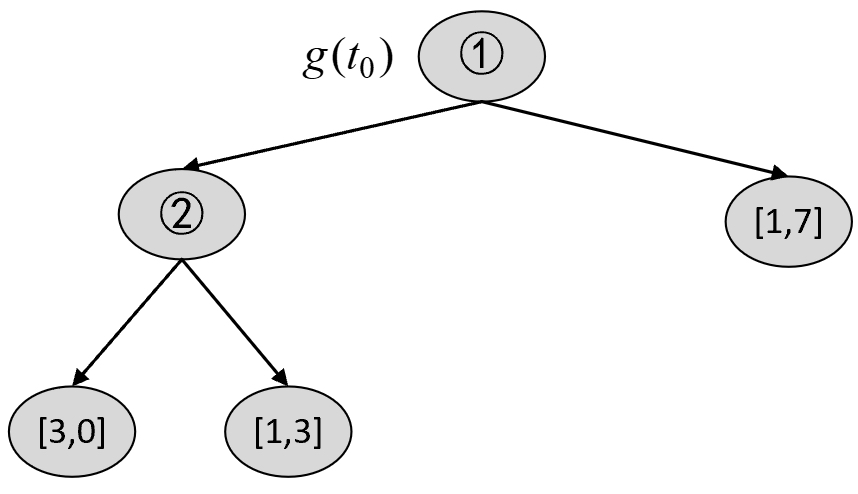
根据图8-35和图8-36可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_0)$分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{2}+0)=2\\[2ex] C(t)&=-(1\cdot\log\frac{1}{4}+3\cdot\log\frac{3}{4})\approx3.2451\\[2ex] g(t_0)&=\frac{3.2451-2}{2-1}=1.2451 \end{aligned}\tag{8-77} $$对于$T_2$ 来说,第2种情况为剪掉2号节点,结果如图8-37所示。
根据图8-35和图8-37可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_1)$分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{2}+0)=2\\[2ex] C(t)&=-(4\cdot\log\frac{4}{7}+3\cdot\log\frac{3}{7})\approx6.8966\\[2ex] g(t_1)&=\frac{6.8966-2}{3-1}=2.4483 \end{aligned}\tag{8-78} $$对于$T_2$来说,第3种情况为剪掉1号节点,结果如图8-38所示。
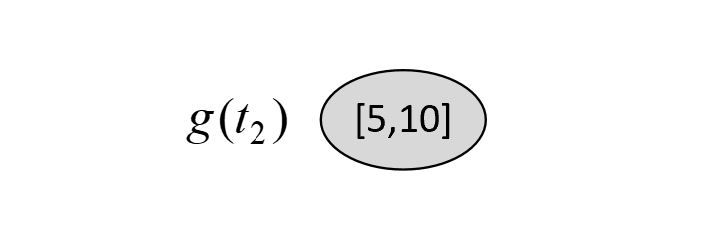
根据图8-35和图8-38可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_2)$分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{2}+1\cdot\log\frac{1}{8}+7\cdot\log\frac{7}{8})\approx6.3485\\[2ex] C(t)&=-(5\cdot\log\frac{5}{15}+10\cdot\log\frac{10}{15})\approx13.7744\\[2ex] g(t_2)&=\frac{13.7744-6.3485}{4-1}=2.4753 \end{aligned}\tag{8-79} $$此时,对于$T_2$来说,其所有可能的剪枝情况都列举完了,且同时有
$$ \alpha_3=\min[g(t_0),g(t_1),g(t_2)]=1.2451\tag{8-80} $$由此可知,$T_3$ 如图8-39所示。
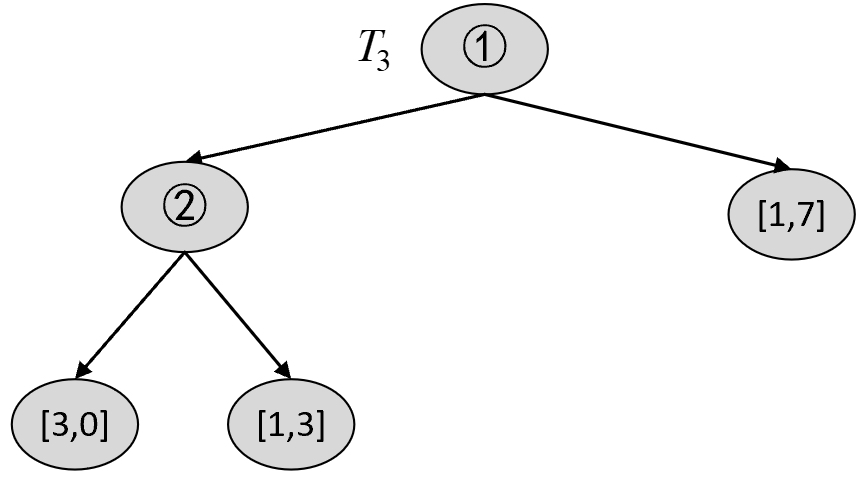
根据$T_3$可以构建$T_4$中的各种剪枝情况,然后选择最优节点进行剪枝。对于$T_3$来说,第1种情况为剪掉2号节点,结果如图8-40所示。
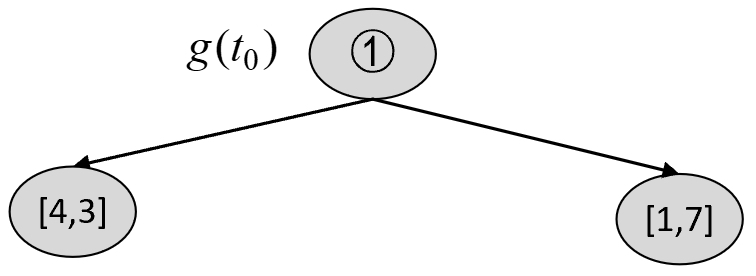
根据图8-39和图8-40可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_0)$分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{4}+3\cdot\log\frac{3}{4})\approx3.2451\\[2ex] C(t)&=-(4\cdot\log\frac{4}{7}+3\cdot\log\frac{3}{7})\approx6.8966\\[2ex] g(t_0)&=\frac{6.8966-3.2451}{2-1}\approx 3.6514 \end{aligned}\tag{8-81} $$对于$T_3$来说,第2种情况为剪掉1号节点,结果如图8-41所示。
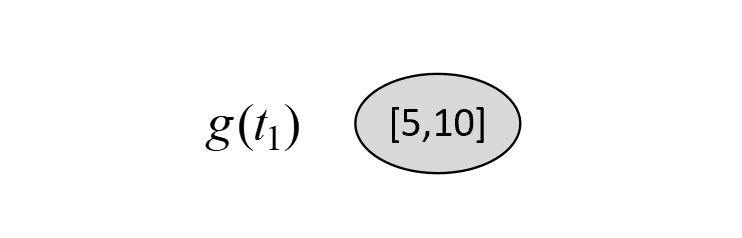
根据图8-39和图8-41可知,在剪枝前$C(T_t)$和剪枝后$C(t)$的损失以及$g(t_1)$分别为
$$ \begin{aligned} C(T_t)&=-(1\cdot\log\frac{1}{4}+3\cdot\log\frac{3}{4}+1\cdot\log\frac{1}{8}+7\cdot\log\frac{7}{8})\approx7.5936\\[2ex] C(t)&=-(5\cdot\log\frac{5}{15}+10\cdot\log\frac{10}{15})\approx13.7744\\[2ex] g(t_1)&=\frac{13.7744-7.5936}{3-1}\approx 3.0903 \end{aligned}\tag{8-82} $$此时,对于$T_3$来说,其所有可能的剪枝情况都列举完了,且同时有
$$ \alpha_4=\min[g(t_0),g(t_1)]=3.0903\tag{8-83} $$由此可知,$T_4$如图8-42所示。
由此,便可以得到整个剪枝后的子序列,如图8-43所示。
在得到所有子序列后,只需要通过交叉验证或者一个测试集来选择其中最优的子树,并作为最终构建的决策树即可。
8.8.3 节点定义实现#
经过8.3节和8.5节对ID3和C4.5算法实现的介绍,对于决策树实现的大致流程相信各位读者已经比较熟悉了。在CART分类树的实现过程中,其总体实现思路与之前ID3和C4.5并没有太大变化,只是由之前的多叉树变成现在的二叉树结构。同时,还需要修改的地方是划分标准的计算,包括节点基尼不纯度以及某一特征下基尼不纯度的计算过程。接下来,按决策树构建的依赖关系来依次介绍每一步的实现过程。以下完整实现代码可参见AllBooKCode/Chapter08/C05_cart_imp.py 文件。
首先,需要定义决策树中每个节点的相关信息,同时由于CART是一棵二叉树,所以在定义节点的时候我们定义相应的左孩子和右孩子,而不是像之前一样通过一个字典来保存所有的孩子节点,整体节点定义示例代码如下:
1 class Node(object):
2 def __init__(self, ):
3 self.sample_index = None
4 self.values = None
5 self.feature_id = -1
6 self.features = None
7 self.n_samples = 0
8 self.left_child = None
9 self.right_child = None
10 self.criterion_value = 0.
11 self.split_value = None
12 self.n_leaf = 0
13 self.leaf_costs = 0. 在上述代码中,第3行sample_index是保存当前节点中对应样本在数据集中的索引。第4行values是保存每个类别的数量,例如[5,10]表示当前节点中第0个类别有5个样本,第1个类别有10个样本。第5行feature_id保存当前节点对应划分特征的id。第6行features是记录当前节点可用的剩余划分特征例如[0,2]表示第0,2个特征在当前节点之前还没有使用过。第7行n_samples是保存当前节点对应的样本数量。第8-9行分别保存当前节点的左右孩子。第10行criterion_value是保存当前节点对应的基尼系数。第11行split_value是选择保存左右孩子时的特征判断区间值,例如split_value=0.5表示如果当前样本的划分维度对应的特征取值小于等于0.5则进入到当前节点的左孩子中,反之则进入到当前节点的右孩子中。第12行n_leaf是保存以当前节点为根节点时其叶子节点的个数。第13行leaf_costs是保存以当前节点为根节点时其所有叶子节点的损失和,这两个节点属性在剪枝过程中才会用到。
在定义完节点信息后,还需要根据8.3.5节中的内容实现决策树的特征离散化过程,示例代码如下:
1 def _get_feature_values(self, data):
2 n_features = data.shape[1]
3 feature_values = {}
4 for i in range(n_features):
5 x_feature = sorted(set(data[:, i])) # 去重与排序
6 tmp_values = []
7 for j in range(1, len(x_feature)):
8 tmp_values.append(round((x_feature[j - 1] + x_feature[j]) / 2, 4)) # 计算均值
9 feature_values[i] = tmp_values
10 return feature_values在上述代码中,第4行是开始遍历每一个特征。第5行是对当前列特征进行去重并排序。第7-8行是对当前列的特征取两两之间的均值进行离散化。第9行是以字典的形式对离散化后的结果进行保存,其中key表示特征序号value表示特征离散化后的取值。值得注意的是在离散化特征时并没有在两端分别加上最小值和最大值,这点不同于8.6.1节中的处理方式,因为CART分类树构建时的特征划分方式不同。
例如,通过上述代码便可以得到如下所示的离散化结果:
1 x = np.array([[3, 4, 5, 6, 7],
2 [2, 2, 3, 5, 8],
3 [3, 3, 8, 8, 9.]])
4 _get_feature_values(x)
5 {0: [2.5], 1: [2.5, 3.5], 2: [4.0, 6.5], 3: [5.5, 7.0], 4: [7.5, 8.5]}8.8.4 基尼不纯度实现#
根据式(8-35)可得,对于任意集合其基尼不纯度的计算过程实现,示例代码如下:
1 class MyCART(object):
2 def __init__(self, min_samples_split=2,
3 epsilon=1e-5,
4 pruning=False,
5 random_state=2022):
6 self.root = None
7 self.min_samples_split = min_samples_split
8 self.epsilon = epsilon
9 self.pruning = pruning
10 self.random_state = random_state
11
12 def _compute_gini(self, y_class):
13 y_unique = np.unique(y_class)
14 if y_unique.shape[0] == 1: # 只有一个类别
15 return 0. # 基尼不纯度为0
16 gini = 0.
17 for i in range(len(y_unique)): # 取每个类别
18 p = np.sum(y_class == y_unique[i]) / len(y_class)
19 gini += p ** 2
20 gini = 1 - gini
21 return gini在上述代码中,第2~10行为类CART的初始化构造函数,用来初始化决策树的相关参数,其中epsilon表节点停止划分时的最小标准,pruning表示是否对生成后的决策树进行剪枝处理。第12行是开始计算任意集合的基尼不纯度。第13~15行是判断如果集合中只存在一个类别,那么其对应的基尼不纯度便是0。第17~20行是累计每个类别样本的分布情况并计算得到整体的基尼不纯度。
例如,对于表8-6中的数据集来说,便可以通过_compute_gini方法来计算数据集的基尼不纯度,示例代码如下:
1 def load_simple_data():
2 x = np.array([[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
3 [1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0],
4 [2, 1, 1, 2, 2, 2, 0, 2, 2, 0, 0, 2, 2, 1, 1]]).transpose()
5 y = np.array([1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1])
6 return x, y
7
8 def test_gini():
9 x, y = load_simple_data()
10 dt = MyCART()
11 logging.info(f"标签{y}的Gini指数为: {dt._compute_gini(y)}")
12 # - INFO: 标签[1 1 1 0 0 0 0 1 1 1 1 1 1 0 1]的Gini指数为: 0.4444根据上述结果来看,标签[1 1 1 0 0 0 0 1 1 1 1 1 1 0 1]对应的基尼不纯度0.444同式(8-51)中的计算结果相符。
进一步,需要实现在给定样本集合和特征维度的情况下,返回当前特征维度中对应的最小基尼不纯度、离散化区间的索引以及样本划分的索引。根据式(8-37)可知,对于在给定特征下样本集合的基尼不纯度计算过程示例代码如下:
1 def _compute_gini_da(self, f_id, data):
2 feature_values = self.feature_values[f_id]
3 x_feature = data[:, f_id]
4 x_ids = np.array(data[:, -1], dtype=np.int).reshape(-1)
5 labels = self._y[x_ids]
6 min_gini = 99999.
7 split_id = None
8 split_sample_idx = None
9 for i in range(len(feature_values)):
10 index = (x_feature <= feature_values[i])
11 # 判断特征的取值是否 <= 特征分裂值(即左孩子对应的索引),并以此将当前节点中的样本划分为左右两个部分
12 if np.sum(index) < 1.:
13 continue
14 d1, y1 = data[index], labels[index] # 根据当前特征维度的取值将样本划分为两个部分,左子树
15 d2, y2 = data[~index], labels[~index] # 右子树
16 gini = len(y1) / len(index) * self._compute_gini(y1) + \
17 len(y2) / len(index) * self._compute_gini(y2)
18 if gini < min_gini: # 保存当前特征维度下,能使基尼不纯度最小时的特征取值
19 min_gini = gini
20 split_id = i
21 split_sample_idx = index
22 logging.debug(f"当前特征维度下的最小基尼不纯度为 {min_gini}")
23 return min_gini, split_id, split_sample_idx在上述代码中,第2~3行是取当前f_id列特征对应的离散化取值情况以及对应的特征列。第4~5行是分别取对应的样本索引和样本标签。第6~8行是分别用来保存最小基尼不纯度、当前特征维度对应离散化判断值的索引和对当前样本划分成左右子树样本对应的索引。第9行是遍历当前特征维度中,离散化特征的每个取值。第10~15行是 判断特征的取值是否存在于某个范围中,并以此将当前节点中的样本划分为左右两个部份。第16~17行是计算样本集合划分后的基尼不纯度。第18~21行是保存当前特征维度下,能使基尼不纯度最小时的特征取值。第23行是返回某个样本集合在当前特征维度下的最优基尼不纯度、离散化特征区间以及样本划分索引。
例如,在如下示例中:
1 x = np.array([[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
2 [1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0],
3 [2, 1, 1, 2, 2, 2, 0, 2, 2, 0, 0, 2, 2, 1, 1]]).transpose()
4 y = np.array([1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1])
5 dt = MyCART()
6 dt.feature_values = dt._get_feature_values(x)
7 dt._y = y
8 print(dt.feature_values)
9 # {0: [0.5], 1: [0.5], 2: [0.5, 1.5]}
10 X = np.hstack(([x, np.arange(len(x)).reshape(-1, 1)]))
11 r = dt._compute_gini_da(0, X)
12 print(r)
13 # (0.3452, 0, array([ True, True, True, True, True, True,
14 # True, False, False, False, False, False, False, False, False]))根据计算结果来看,对于数据集x来说,在第0个特征维度中,当离散化的取值区间为小于等于0.5时,对应的基尼不纯度最小为0.3452。这一计算结果与式(8-52)中的计算结果相符。
8.8.5 决策树构建实现#
在完成前期准备工作后,接下来便可以来实现决策树的构建过程。这里首先来定义fit()方法,并完成决策树构建前的处理,示例代码如下:
1 def fit(self, X, y):
2 self._y = np.array(y).reshape(-1)
3 self.n_classes = len(np.bincount(y))
4 feature_ids = [i for i in range(X.shape[1])]
5 self.feature_values = self._get_feature_values(X)
6 self._X = np.hstack(([X, np.arange(len(X)).reshape(-1, 1)]))
7 self._build_tree(self._X, feature_ids) 在上述代码中,第1行X,y分别为训练用到的样本和标签,形状为[n_samples, n_features]和[n_samples,]。第3行是 得到当前数据集的类别数量。第4行是得到特征的序号。第5行是得到离散化特征。第6行是将训练集中每个样本的序号加入到X的最后一列。第7行是 递归构建决策树。
下面开始介绍_build_tree()方法的实现。由于这部分代码较长,下面分块进行介绍。第一部分示例代码如下:
1 def _build_tree(self, data, f_ids):
2 x_ids = np.array(data[:, -1], dtype=np.int).reshape(-1)
3 node = Node()
4 node.sample_index = x_ids
5 labels = self._y[x_ids]
6 node.n_samples = len(labels)
7 node.values = np.bincount(labels, minlength=self.n_classes)
8 node.features = f_ids
9 if self.root is None:
10 self.root = node
11 y_unique = np.unique(labels)
12 if y_unique.shape[0] == 1 or len(f_ids) < 1 \
13 or node.n_samples <= self.min_samples_split:
14 return node
15 gini = self._compute_gini(labels)
16 node.criterion_value = gini在上述代码中,第2行是取当前样本集合对应在原始训练集中的索引。第3~6行分别是定义一个新节点、保存当前节点所有样本的索引、取当前节点所有样本对应的标签以及保存当前节点的样本数量。第7行是保存当前节点每个类别的样本数。第8行是保存当前节点状态时特征集中的剩余特征。第11行是取当前节点中存在的类别情况。第12~14行是判断如果当前节点中只有一个类别或特征集为空或样本数量少于min_samples_split,则直接返回当前节点。第15~16行是计算当前节点对应的基尼不纯度并保存到当前节点中。
1 min_gini = 99999
2 split_id = None
3 split_sample_idx = None
4 best_feature_id = -1
5 for f_id in f_ids:
6 m_gini, s_id, s_s_idx = self._compute_gini_da(f_id, data)
7 if m_gini < min_gini:
8 min_gini = m_gini
9 split_id = s_id
10 split_sample_idx = s_s_idx
11 best_feature_id = f_id在上述代码中,第4行是保存所有可用划分特征中,能够使得基尼不纯度最小的特征对应的特征ID。第5行是遍历样本的每个特征。第6行是遍历当前特征下的每种取值方式的基尼不纯度,并返回最小基尼不纯度对应的结果。第7~11行是保存在所有特征中,基尼不纯度最小情况下对应的基尼不纯度、特征离散取值索引、样本划分索引和划分特征ID。
1 node.feature_id = best_feature_id
2 feature_values = self.feature_values[best_feature_id]
3 node.split_value = feature_values[split_id]
4 left_data = data[split_sample_idx]
5 right_data = data[~split_sample_idx]
6 candidate_ids = deepcopy(f_ids)
7 candidate_ids.remove(best_feature_id)
8 if len(left_data) > 0:
9 node.left_child = self._build_tree(left_data, candidate_ids)
10 if len(right_data) > 0:
11 node.right_child = self._build_tree(right_data, candidate_ids)
12 return node在上述代码中,第2~3行是得到最佳划分特征对应的离散特征取值。第4~5行是根据划分索引来得到当前节点对应左孩子和右孩子中的样本。第6行是复制当前节点对应的特征集,复制的原因是因为candidate_ids是一个列表作为参数传递实际上是传入的地址,会改变原始列表的结果。第7行是得到当前节点划分后的剩余特征集,从这里也可以看出同一个子树中同一个特征只会用到一次。第8~11行是递归构建决策树。
在完成上述代码后,便可通过如下示例来进行验证:
1 def test_cart():
2 x, y = load_simple_data()
3 dt = MyCART(min_samples_split=1)
4 dt.fit(x, y)
5 dt.level_order()
6
7 标签[1 1 1 0 0 0 0 1 1 1 1 1 1 0 1]的GINI指数为: 0.4444
8 ========>
9 当前节点所有样本的索引 [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
10 当前节点的样本数量 15 当前节点每个类别的样本数 [ 5 10]
11 当前节点状态时特征集中剩余特征 [0, 1, 2] 当前节点中的样本基尼不纯度为 0.4444
12 ----------
13 所有特征维度对应的离散化特征取值为 {0: [0.5], 1: [0.5], 2: [0.5, 1.5]}
14 当前特征维度<0>对应的离散化特征取值为 [0.5]
15 当前样本对应的标签值为[1 1 1 0 0 0 0 1 1 1 1 1 1 0 1]
16 当前特征维度在 x <= 0.5 下对应的基尼不纯度为: 0.3452 =(7/15)* 0.4898 + (8/15)* 0.2188
17 当前特征维度下的最小基尼不纯度为 0.3452
18 ----------
19 所有特征维度对应的离散化特征取值为 {0: [0.5], 1: [0.5], 2: [0.5, 1.5]}
20 当前特征维度<1>对应的离散化特征取值为 [0.5]
21 当前样本对应的标签值为[1 1 1 0 0 0 0 1 1 1 1 1 1 0 1]
22 当前特征维度在 x <= 0.5 下对应的基尼不纯度为: 0.381 =(8/15)* 0.5 + (7/15)* 0.2449
23 当前特征维度下的最小基尼不纯度为 0.3809
24 ----------
25 所有特征维度对应的离散化特征取值为 {0: [0.5], 1: [0.5], 2: [0.5, 1.5]}
26 当前特征维度<2>对应的离散化特征取值为 [0.5, 1.5]
27 当前样本对应的标签值为[1 1 1 0 0 0 0 1 1 1 1 1 1 0 1]
28 当前特征维度在 x <= 0.5 下对应的基尼不纯度为: 0.4444 =(3/15)* 0.4444 + (12/15)* 0.4444以上输出结果为决策树在构建过程中所生成的部分信息,也对应着上面式(8-52)到式(8-56)的计算过程。同时,其层次遍历的部分结果如下所示:
1 正在进行层次遍历……
2 第1层的节点为:
3 当前节点所有样本的索引([ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14])
4 当前节点的样本数量(15) 当前节点每个类别的样本数([ 5 10]) 当前节点对应的基尼不纯度为(0.444)
5 第2层的节点为:
6 当前节点所有样本的索引([0 1 2 3 4 5 6])
7 当前节点的样本数量(7) 当前节点每个类别的样本数([4 3]) 当前节点对应的基尼不纯度为(0.49)
8 当前节点所有样本的索引([ 7 8 9 10 11 12 13 14])
9 当前节点的样本数量(8) 当前节点每个类别的样本数([1 7]) 当前节点对应的基尼不纯度为(0.219)
10 ......8.8.6 决策树预测实现#
在完成决策树的拟合过程后,进一步便可实现测试样本的预测过程。对于CART决策树来说,根据图8-23的结果可知在预测新样本时首先是根据当前节点对应的划分特征ID取到对应的特征列;然后再根据当前节点保存的离散化特征取值索引得到判断区间;然后判断测试样本对应的特征取值是否存在于当前节点的判断区间内,如果存在则继续进入到当前节点的左孩子,如果不存在则进入当前节点的有孩子;最后递归地进行遍历,直到当前节点为空或不存在判断区间停止。
具体实现过程示例代码如下:
1 def _predict_one_sample(self, x):
2 current_node = self.root
3 while True:
4 if not current_node.left_child or \
5 not current_node.right_child or \
6 current_node.split_value is None \
7 or current_node.n_samples < self.min_samples_split:
8 return current_node.values
9 current_feature_id = current_node.feature_id
10 current_feature = x[current_feature_id]
11 split_value = current_node.split_value
12 if current_feature <= split_value:
13 current_node = current_node.left_child
14 else:
15 current_node = current_node.right_child在上述代码中,第4~8行用来判断如果当前节点为叶子节点则返回对应的类别信息values。第9~10行是获取当前节点对应的划分特征ID,并取测试样本中对应的维度的值。第11~15行则是根据判断区间来进入当前节点对应的孩子节点中。
在完成单个样本的预测过程后,便可以循环实现多个样本的预测过程,示例代码如下:
1 def predict(self, X):
2 results = []
3 for x in X:
4 results.append(self._predict_one_sample(x))
5 results = np.array(results)
6 logging.debug(f"原始预测结果为:\n{results}")
7 y_pred = np.argmax(results, axis=1)
8 return y_pred例如对于以下测试样本:
1 y_pred = dt.predict(np.array([[0, 0, 2],
2 [0, 1, 1],
3 [1, 1, 1],
4 [0, 1, 0],
5 [0, 1, 2]]))其预测结果为:
1 原始预测结果为:
2 [[3 0]
3 [0 2]
4 [0 1]
5 [0 2]
6 [1 1]]
7 CART 预测结果为:[0 1 1 1 0]到目前为止,对于CART分类树构建与预测部分的代码节介绍完了,接下来继续看剪枝部分的实现。
8.8.7 决策树剪枝实现#
根据8.7.4节的剪枝步骤可知,在剪枝计算$g(t)$的过程中我们需要得到以当前节点为根节点,对应的孩子节点的个数,以及对应所有孩子节点的损失和。因此,前面我们在定义树节点时便包含了记录以当前节点为根节点其孩子节点个数的n_leaf,以及所有孩子节点损失和的leaf_costs。从上面的实现过程可知这两个属性并没有更新,因此需要在剪枝的过程中同时更新这两个属性的信息。
下面,首先需要对每种剪枝情况下$g(t)$的计算过程进行实现,示例代码如下:
1 def _get_pruning_gt(self, node):
2
3 def _compute_cost_in_leaf(labels):
4 y_count = np.bincount(labels)
5 n_samples = len(labels)
6 cost = 0
7 for i in range(len(y_count)):
8 if y_count[i] == 0:
9 continue
10 cost += y_count[i] * np.log2(y_count[i] / n_samples)
11 return -cost
12
13 if not node.left_child and not node.right_child:
14 node.leaf_costs = _compute_cost_in_leaf(self._y[node.sample_index])
15 return 9999999.
16 parent_cost = _compute_cost_in_leaf(self._y[node.sample_index])# 计算以当前节点为根节点剪枝后的损失
17 if node.left_child:
18 node.leaf_costs += node.left_child.leaf_costs # 以当前节点为根节点累计剪枝前所有叶子节点的损失
19 if node.right_child:
20 node.leaf_costs += node.right_child.leaf_costs
21 g_t = (parent_cost - node.leaf_costs) / (node.n_leaf - 1 + 1e-5) # 计算gt,其中1e-5为平滑项
22 return g_t在上述代码中,第3~11是计算每个节点中的损失值。第13~15行是判断如果当前节点是叶子节点,则计算该叶子节点对应的损失值(因为是叶子结点所以不需要计算$g(t)$值)。第16行是计算以当前节点为根节点剪枝后的损失。第17~20行是计算以当前节点为根节点剪枝前累计所有叶子节点的损失。第21~22行是计算$g(t)$值,并返回。
这里值得注意的是,只有在当前节点为叶子节点的时候才会计算一次损失并保存到node.leaf_costs中,而如果当前节点非叶子节点则其node.leaf_costs对应的是其孩子节点的node.leaf_costs累加值。
下一步便是实现对于每棵子树$T_i$来说,计算得到其所有可能剪枝情况下的$g(t_i)$,然后选择 $g(t_i)$最小的节点进行剪枝并同时得到$T_{i+1}$;进一步循环得到$T_{i+2},T_{i+3}$,示例代码如下:
1 def _get_subtree_sequence(self):
2 subtrees = []
3 stop = False
4 while not stop:
5 if not self.root.right_child and not self.root.left_child:
6 stop = True
7 level_order_nodes = self.level_order(return_node=True)
8 best_gt = 99999.
9 best_pruning_node = None
10 for i in range(len(level_order_nodes) - 1, -1, -1):
11 current_level_nodes = level_order_nodes[i]
12 for j in range(len(current_level_nodes)):
13 current_node = current_level_nodes[j]
14 current_node.n_leaf = 0
15 current_node.leaf_costs = 0.
16 if current_node.left_child is not None:
17 current_node.n_leaf += current_node.left_child.n_leaf
18 if current_node.right_child is not None:
19 current_node.n_leaf += current_node.right_child.n_leaf
20 elif not current_node.left_child and not current_node.right_child:
21 current_node.n_leaf = 1
22 gt = self._get_pruning_gt(current_node)
23 if gt < best_gt:
24 best_gt = gt
25 best_pruning_node = current_node
26 subtrees.append(deepcopy(self.root))
27 if not stop:
28 best_pruning_node.left_child = None
29 best_pruning_node.right_child = None # 剪枝
30 return subtrees在上述代码中,第2行是用来保存所有可能的子序列$T_0,T_1,...,T_n$。第5~6行是停止条件判断。第7行是对当前子树$T_i$进行层次遍历并返回层次遍历后的结果。第10~11行是从下向上对子树$T_i$进行遍历,并取当前层的所有节点。第12~13行是从左到右对当前层的节点进行遍历。第14~15行是对于每一棵子树$T_i$来说重置计数,因为原始值中包含有上一棵子树的计数信息。第16~19行是计算以当前节点为根节点的叶子节点总数。第20~21是判断如果当前节点为叶子节点,则其对应的叶子节点数为1。第22行是计算以当前节点为根节点的$g(t)$值。第23~25行是保留在$T_i$中所有剪枝情况下$g(t)$最小时对应的状态。第27~29行则是进行剪枝处理。
在实现完上述过程后,便可以利用上述代码来输出表8-6示例数据中的决策树子序列,示例代码如下:
1 def test_get_subtree():
2 x, y = load_simple_data()
3 dt = CART(min_samples_split=1)
4 dt.fit(x, y)
5 subtrees = dt._get_subtree_sequence()
6 logging.debug(f"生成子树个数为:{len(subtrees)}")
7 for i, tree in enumerate(subtrees):
8 logging.debug(f"-----正在层次遍历第 {i} 颗子树-----")
9 dt.root = tree
10 dt.level_order()在上述代码运行结束以后,部分输出结果如下:
1 正在获取子序列T0,T1,T2,T3...
2 正在进行层次遍历……
3 并返回层次遍历的所有结果!
4 ------------------
5 当前节点g(t)为:1.2451 当前节点(剪枝后)的损失为:3.2451
6 当前节点的孩子节点(剪枝前)损失为:2.0
7 ------------------
8 当前节点g(t)为:0.4902 当前节点(剪枝后)的损失为:3.2451
9 当前节点的孩子节点(剪枝前)损失为:2.7548
10 ------------------
11 当前节点g(t)为:2.4482 当前节点(剪枝后)的损失为:6.8965
12 当前节点的孩子节点(剪枝前)损失为:2.0
13 ------------------
14 当前节点g(t)为:0.7968 当前节点(剪枝后)的损失为:4.3485
15 当前节点的孩子节点(剪枝前)损失为:2.7548
16 ------------------
17 当前节点g(t)为:1.8039 当前节点(剪枝后)的损失为:13.7744
18 当前节点的孩子节点(剪枝前)损失为:4.7548
19 本轮T(0)计算结束,最小的g(t)为 0.4902
20 注意:上述剪枝的计算顺序为从下到上,从左到右。上述输出结果也就是对应着8.8.2节中的所有计算过程。在得到所有决策树子序列$T_0,T_1,...,T_n$后,只需要通过交叉验证或者是测试集验证即可得到最终的最优子树。这里使用相对简单的测试集验证来进行筛选,示例代码如下所示:
1 def _pruning_leaf(self):
2 subtrees = self._get_subtree_sequence()
3 best_tree = None
4 max_acc = 0.
5 for tree in subtrees:
6 self.root = tree
7 acc = accuracy_score(self.predict(self.x_test), self.y_test)
8 if acc > max_acc:
9 max_acc = acc
10 best_tree = tree
11 self.root = best_tree在上述代码中,第2行是得到所有的子序列。第5~10行则是在测试集上对所有子树进行测试,然后选择准确率最高的子树作为最终的决策树。
8.8.8 使用示例#
到此对于整个CART分类树的实现就介绍完了。下面,通过load_wine数据集来进行测试,示例代码如下:
1 def test_wine_classification():
2 x, y = load_wine(return_X_y=True)
3 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=12)
4 dt = MyCART(min_samples_split=2, pruning=True, random_state=2020)
5 dt.fit(x_train, y_train)
6 y_pred = dt.predict(x_train)
7 logging.info(f"MyCART Acc on training data:{accuracy_score(y_train, y_pred)}")
8 y_pred = dt.predict(x_test)
9 logging.info(f"MyCART Acc on testing data:{accuracy_score(y_test, y_pred)}")
10 model = DecisionTreeClassifier(criterion='gini', random_state=20)
11 model.fit(x_train, y_train)
12 y_pred = model.predict(x_test)
13 logging.info(f"DecisionTreeClassifier Acc on testing data:{accuracy_score(y_test, y_pred)}")在上述代码中,我们也特意加入了和sklearn中DecisionTreeClassifier模块中CART算法的对比,最后对比结果如下:
1 MyCART Acc on training data:0.9919
2 MyCART Acc on testing data:0.9444
3 DecisionTreeClassifier Acc on testing data:0.9444不过值得一说的是,在不同状态下(例如测试集的划分方式等)都会对最后的比较结果产生一定的差异,大家可以自行尝试。同时,本文中的实现仅供学习使用并没有考虑诸多细节之处,实际请直接使用sklearn中的相关模块。
8.8.9 小结#
在本节内容中,我们首先介绍了CART分类树的生成原理以及连续型特征离散化的方法;然后通过一个实际的示例来详细介绍了CART分类树的生成过程;接着介绍了CART算法的剪枝原理并同样进行了详细的计算示例;最后我们一步一步地介绍了CART分类树生成与剪枝的代码实现。
总结一下,在本章中我们首先介绍了决策树的基本思想,即可以看成是一系列if else的规则集合,其关键在于如何构建一颗好的决策树;进一步介绍了ID3和C4.5这两种常见决策树生成算法的原理与实现,包括如何对构建的决策树进行可视化;然后介绍了在决策树的建模过程中如何对连续型特征进行离散化处理;最后详细介绍了CART算法中分类树的构建与剪枝过程,以及如何从零进行实现。
引用#
[1] 吴军.数学之美[M].3版.北京: 人民邮电出版社,2020.
[2] 李航.统计学习方法[M].2版.北京: 清华大学出版社,2019.
[3]Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
[4] http://www.graphviz.org/download/
[5] https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeRegressor.html
[6] https://scikit-learn.org/stable/modules/tree.html