9.6 Gradient Boost 原理与实现#
在前面两节内容中,我们分别详细介绍了AdaBoost算法和基于AdaBoost改进的SAMME算法的基本原理和实现过程。在接下来的这节内容中将会介绍另外一种基于Boost策略的算法模型——梯度提升(Gradient Boosting, GB)算法。从名字可以看出梯度提升算法有两个关键的地方:梯度和提升。提升表明整个集成模型依旧是串行进行,且后一个模型是用来对前一个模型的输出结果进行修正;梯度则表明后一个模型在对前一个模型的结果进行修正时是以梯度下降为策略进行优化的。
9.6.1 Gradient Boost 算法思想#
梯度提升是Friedman等人[12]于2001年所提出的一种基于梯度下降策略来对模型进行优化的算法,其核心思想是先通过设定一个目标函数,然后再通过梯度下降算法来对预测结果进行优化。梯度提升算法的整体结构类似于之前介绍的线性回归和逻辑回归的求解流程只是在具体细节部分有着不同的处理方式。
在AdaBoost算法中,通过赋予每个样本一个权重值,并且在上一个模型中误差越大的样本(分类问题中即被错分的样本)在下一个模型中将会被给予更高的权重,然后对于每个基模型来说其都有不同的策略来降低高权重样本的误差,以此来提高整个集成模型的预测精度,即在AdaBoost算法中它是通过赋予样本权重来提升模型的精度。对于梯度提升算法来说,它则是通过梯度来提升整个模型的预测精度。
如式(9-57)所示,便是梯度下降算法的核心公式
$$ w=w-\alpha\cdot\frac{\partial J}{\partial w}\tag{9-57} $$其中$w$表示待更新的参数对象,$J$表示关于参数$w$的目标函数,$\alpha$表示学习率。更多关于梯度下降算法的详细介绍可以参见2.5节内容。
通过式(9-57)可知,对于参数$w$来说可以根据其梯度的方向来一步一步迭代计算得到(接近)其最优解。现在假定某个模型的预测输出为$\hat{y}=f(x)$,预测值与真实值之间的损失误差为$J(y,\hat{y})$,那么为了提高模型$f(x)$的预测结果,同样可以采用梯度下降算法来对预测结果进行迭代更新,即
$$ f(x)=f(x)-\alpha\cdot\frac{\partial J}{\partial f(x)}\tag{9-58} $$而式(9-58)便是梯度提升算法的核心思想。
从式(9-58)可以看出,在梯度提升算法中最重要的便是求得目标函数$J$关于模型$f(x)$的梯度,而这通常会通过训练一系列额外的模型来对梯度进行预测,具体可见后续代码实现部分。
9.6.2 Gradient Boost 示例代码#
在明白梯度提升算法的基本思想后我们再来看如何在sklearn中使用它。首先,需要知道的是梯度提升算法本质上也只是一种模型的训练策略,因此对于基学习器的选择是任意的。但是,通常默认情况下都是以决策树作为基学习器,所以基于梯度提升方法最常见的一个模型便是梯度提升决策树(Gradient Boosting Decision Tree, GBDT)也简称梯度提升树,而sklearn中的GradientBoostingClassifier模块便是以决策树为基学习器进行实现的且不可更改。
在sklearn中,可以通过如下方式来使用梯度提升树,示例代码如下:
1 from sklearn.ensemble import GradientBoostingClassifier
2 from sklearn.datasets import load_iris
3 from sklearn.model_selection import train_test_split
4
5 if __name__ == '__main__':
6 x, y = load_iris(return_X_y=True)
7 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
8 model = GradientBoostingClassifier(learning_rate=0.2, n_estimators=50)
9 model.fit(x_train, y_train)
10 print(model.score(x_test, y_test)) # 0.956在上述代码中,第6~7行用来返回数据集并划分为训练集和测试集。第8行是实例化一个GradientBoostingClassifier类对象,其中learning_rate指式(9-58)中的学习率$\alpha$,n_estimators表示基学习器的数量,即9.6.3节算法原理第三步中的$M$。第9~10行是拟合模型并输出模型在测试集上的准确率。
由于GradientBoostingClassifier是以决策树为基学习器,因此在第8行中实例化时还可以指定决策树对应的相关参数,例如max_depth,min_samples_leaf等。最后,sklearn中对应的梯度提升回归模块为GradientBoostingRegressor。上述完整示例代码可参见 AllBooKCode/Chapter09/C14_gbdt_train.py 文件。
9.6.3 Gradient Boost 算法原理#
在介绍完梯度提升算法的思想和使用示例后再来看它背后的具体原理。假如现在我们需要训练一个模型,数据样本对应的标签值为$y$,第$m$次提升后模型的预测输出为$\hat{y}^{(m)}=f^{(m)}(x)$,预测值与真实值之间的损失为$J(y,\hat{y}^{(m)})$,则对于梯度提升算法来说可通过如下步骤求得模型:
第一步:初始化学习率$\alpha$以及$m=0$并根据数据集训练得到模型$f^{(m)}(x)$,
第二步:计算得到损失函数$J$关于$f^{(m)}(x)$的梯度,并根据如下公式对模型$f^{(m)}(x)$进行更新
$$ f^{(m+1)}(x)=f^{(m)}(x)-\alpha\cdot\frac{\partial J}{\partial f^{(m)}(x)}\tag{9-59} $$第三步:判断$m<=M$是否成立,成立则结束迭代,否则$m=m+1$,并进入第二步。
以上便是梯度提升算法整个流程的核心步骤,下面分别来看它在回归和分类模型中的详细计算示例。
9.6.4 Gradient Boost 回归#
例如现在某数据集一共5个样本,标签分别为$y_0=2,y_1=4,y_2=2.5,y_3=1.8,y_4=2.4$,模型的预测输出为$\hat{y}^{(m)}=f^{(m)}(x)$,$M=3,\alpha=0.5$,且采用均方误差作为损失函数,即
$$ J(y,\hat{y}^{(m)})=\frac{1}{2}(y-\hat{y}^{(m)})^2\tag{9-60} $$由式(9-60)可知,损失函数$J$关于$\hat{y}^{(m)}$的梯度为
$$ \frac{\partial J}{\partial \hat{y}^{(m)}}=-(y-\hat{y}^{(m)})\tag{9-61} $$假定模型$f^{(0)}(x)$的初始预测结果为$\hat{y}^{(0)}_0=1.6,\hat{y}^{(0)}_1=2.7,\hat{y}^{(0)}_2=0.5,\hat{y}^{(0)}_3=1.1,\hat{y}^{(0)}_4=0.9$,则采用梯度提升算法进行第1次提升后的结果$f^{(1)}(x)$为
$$ \begin{aligned} f^{(1)}(x)=f^{(0)}(x)+\alpha\cdot(y-\hat{y}^{(0)}) =\begin{bmatrix}1.6\\2.7\\0.5\\1.1\\0.9\end{bmatrix}+ 0.5\cdot\begin{bmatrix}2-1.6\\4-2.7\\2.5-0.5\\1.8-1.1\\2.4-0.9\end{bmatrix}=\begin{bmatrix}1.8\\3.35\\1.5\\1.45\\1.65\end{bmatrix} \end{aligned}\tag{9-62} $$同理可得,第2、3次提升后的结果$f^{(2)}(x),f^{(3)}(x)$对应的预测结果分别为
$$ f^{(2)}(x)=\begin{bmatrix}1.9\\3.675\\2\\1.625\\2.205\end{bmatrix}, \;\; f^{(3)}(x)=\begin{bmatrix}1.95\\3.837\\2.25\\1.712\\2.213\end{bmatrix},\;\; y=\begin{bmatrix}2\\4\\2.5\\1.8\\2.4\end{bmatrix}\tag{9-63} $$从上述过程可以看出,随着迭代次数的增加,模型的预测结果也更加地接近于标签的真实值。上述计算过程示例代码可参见 AllBooKCode/Chapter09/C15_example_gradient_boost_reg.py 文件。
9.6.5 Gradient Boost 分类#
在介绍完梯度提升中的回归计算示例后相信各位读者对梯度提升算法已经有了一定的认识。不过在分类场景中,应该如何利用梯度下降来对模型的预测结果进行优化提升呢?一个可行的办法便是对每个类别下的预测概率进行梯度提升优化。
例如现在某三分类数据集一共5个样本,标签分别为$y_0=2,y_1=1,y_2=2,y_3=0,y_4=0$,模型的预测输出为$\hat{y}^{(m)}=f^{(m)}(x)$,$M=3,\alpha=0.5$,且采用多项式误差(Multinomial Deviance)作为损失函数,即对于任意一个样本$x$来说其在第$m$次提升后对应的损失为
$$ J(y,p^{(m)}(x))=-\sum_{k=0}^K\mathbb{I}(y=k)f^{(m)}_k(x)+\log\left(\sum_{k=0}^Ke^{f^{(m)}_k(x)}\right)\tag{9-64} $$其中,$K$表示分类数;$\mathbb{I}(\cdot)$表示指示函数;$y$表示样本$x$对应的真实标签,是一个标量;$p^{(m)}(x)$表示样本$x$在第$m$次提升后预测结果的概率分布;$f^{(m)}_k(x)$表示样本$x$在第$m$次提升后在类别$k$中的预测概率值,即$p^{(m)}(x)=[f^{(m)}_0(x),f^{(m)}_1(x)...,f^{(m)}_k(x)]$。
注:此处也可采用其它损失函数,这里为了和sklearn进行对比所以选择了和它一样的损失函数。
由式(9-64)可知,损失函数$J$关于样本$x$在第$i$个类别下的预测概率$f^{(m)}_i(x)$的梯度为
$$ \frac{\partial J}{\partial f^{(m)}_i(x)}=-\mathbb{I}(y=i)+\frac{e^{f^{(m)}_i(x)}}{\sum_{k=0}^Ke^{f^{(m)}_k(x)}}\tag{9-65} $$假定随机初始化模型$f^{(0)}(x)$的结果为
$$ f^{(0)}(x)= \begin{bmatrix} 0&0.1&0.3\\ 0.2&0.2&0.1\\ 0.3&0.2&0.1\\ 0&0&0.4\\ 0&0.1&0\\ \end{bmatrix}\tag{9-66} $$式(9-66)表示5个样本属于3个类别下各自的概率值,则此种情况下,根据式(9-64)可知整体损失值为
$$ \begin{aligned} J=&\frac{1}{5}\left(- \begin{bmatrix}0&0&1\\0&1&0\\0&0&1\\1&0&0\\1&0&0\end{bmatrix}* \begin{bmatrix}0&0.1&0.3\\0.2&0.2&0.1\\0.3&0.2&0.1\\0&0&0.4\\0&0.1&0\\\end{bmatrix} +\begin{bmatrix} \log(e^{0.0}+e^{0.1}+e^{0.3})\\ \log(e^{0.2}+e^{0.2}+e^{0.1})\\ \log(e^{0.3}+e^{0.2}+e^{0.1})\\ \log(e^{0.0}+e^{0.0}+e^{0.4})\\ \log(e^{0.0}+e^{0.1}+e^{0.0}) \end{bmatrix} \right)\\[2ex] =&\frac{1}{5}[-(0\times 0.0+0\times 0.1+1\times 0.3)+ \log(e^{0.0}+e^{0.1}+e^{0.3})\\[1ex] &-(0\times 0.2+1\times 0.2+0\times 0.1)+ \log(e^{0.2}+e^{0.2}+e^{0.1})\\[1ex] &-(0\times 0.3+0\times 0.2+1\times 0.1)+ \log(e^{0.3}+e^{0.2}+e^{0.1})\\[1ex] &-(1\times 0.0+0\times 0.0+0\times 0.4)+ \log(e^{0.0}+e^{0.0}+e^{0.4})\\[1ex] &-(1\times 0.0+0\times 0.1+0\times 0.0)+ \log(e^{0.0}+e^{0.1}+e^{0.0})]\\[1ex] \approx&1.118 \end{aligned}\tag{9-67} $$根据式(9-65)可知所有样本在第0个类别下的梯度为
$$ \frac{\partial J}{\partial f^{(0)}_0(x)}= -\begin{bmatrix}\mathbb{I}(2=0)\\[1ex]\mathbb{I}(1=0)\\[1ex]\mathbb{I}(2=0)\\[1ex]\mathbb{I}(0=0)\\[1ex]\mathbb{I}(0=0)\end{bmatrix}+ \begin{bmatrix} e^{0.0}/(e^{0.0}+e^{0.1}+e^{0.3})\\[1ex] e^{0.2}/(e^{0.2}+e^{0.2}+e^{0.1})\\[1ex] e^{0.3}/(e^{0.3}+e^{0.2}+e^{0.1})\\[1ex] e^{0.0}/(e^{0.0}+e^{0.0}+e^{0.4})\\[1ex] e^{0.0}/(e^{0.0}+e^{0.1}+e^{0.0})\\[1ex] \end{bmatrix}= \begin{bmatrix}0.289\\[1ex]0.344\\[1ex]0.367\\[1ex]-0.716\\[1ex]-0.678\end{bmatrix}\tag{9-68} $$进一步,根据式(9-59)可得,对于所有样本来说第0个类别下更新后的预测概率为
$$ \begin{aligned} f_0^{(1)}(x)=f_0^{(0)}(x)-\alpha\cdot\frac{\partial J}{\partial f^{(0)}_0(x)} =\begin{bmatrix}0\\[1ex]0.2\\[1ex]0.3\\[1ex]0\\[1ex]0\end{bmatrix}-0.5\times \begin{bmatrix}0.289\\[1ex]0.344\\[1ex]0.367\\[1ex]-0.716\\[1ex]-0.678\end{bmatrix}= \begin{bmatrix}-0.145\\[1ex]0.028\\[1ex]0.116\\[1ex]0.357\\[1ex]0.339\end{bmatrix} \end{aligned}\tag{9-69} $$同理,可以计算得到所有样本在第1次提升后的预测概率为
$$ \begin{aligned} f^{(1)}(x)&= \begin{bmatrix}-0.145&-0.066&0.586\\[1ex]0.028&0.518&-0.045\\[1ex]0.116&0.023&0.430\\[1ex]0.357&-0.128&0.204\\[1ex]0.339&-0.057&-0.149\end{bmatrix} \end{aligned}\tag{9-70} $$
此时,根据式(9-70)可得,在第1次提升后的预测标签为[2,1,2,0,0],且损失值为0.816。
可以发现,在第1次提升结束后就模型已经得到了正确的预测结果。不过继续迭代下去会得到更高的预测概率和更低的损失值,后两次提升结束后的损失值分别为0.6112和0.4732,各位读者可以手动计算验证一下。上述计算过程完整示例代码可参见 AllBooKCode/Chapter09/C16_example_gradient_boost_cla.py 文件。
9.6.6从零实现Gradient Boost回归#
通过上述内容,我们已经知道了梯度提升算法的基本原理。不过有一个疑问便是,在训练集上可以借助样本的真实标签来计算各个类别下的梯度值,但是在测试集上没有标签的时候又该怎么来完成梯度的计算呢?在实现基于梯度提升的各类模型时,最关键的一点便是如何在测试集上计算相应的梯度。通常,一种可行的做法便是在训练集上训练相关模型来完成梯度的预测。下面,先从稍微简单的回归模型开始介绍。
对于梯度提升回归模型来说,只需要在模型训练时的每一次提升中,训练一个对应的回归模型来预测梯度即可,下面开始分别进行介绍。
1. 损失函数实现
在实现回归模型时这里依旧以均方误差作为损失函数,示例代码如下:
1 def objective_function(y, y_hat):
2 return 0.5 * (y - y_hat) ** 2在上述代码中,y和y_hat均为一个形状为[n_samples,]的向量。同时,这里需要注意的是,由于梯度提升是对每个样本点的预测结果以梯度下降来进行更新,因此损失函数并不需要进行求和平均。
2. 梯度求解实现
根据损失函数,梯度计算的示例代码如下:
1 def negative_gradient(y, y_hat):
2 return (y - y_hat)这里需要注意的是,上述代码返回的是负梯度方向。
3. 梯度提升实现
在完成上述两个辅助函数的实现后,接下来需要定义一个类MyGradientBoostRegression来完成整个梯度提升回归模型的实现。首先需要定义这个类并完成相应的初始化方法,示例代码如下:
1 class MyGradientBoostRegression(object):
2 def __init__(self, learning_rate=0.1,
3 n_estimators=100, base_estimator=None):
4 self.learning_rate = learning_rate
5 self.n_estimators = n_estimators
6 self.base_estimator = base_estimator
7 self.estimators_ = []
8 self.loss_ = []在上述代码中,第4行表示梯度下降中的学习率。第5行表示模型提升的次数,即梯度下降迭代的次数。第6行表示用于在测试数据上预测梯度的基模型。第7行用于保存所有训练好的基模型,在模型测试过程中会用到。第8行用于保存训练过程中模型对应的损失值。
进一步,需要定义一个类方法来完成所有的梯度提升过程,示例代码如下:
1 def _fit_stages(self, X, y, raw_predictions):
2 for i in range(self.n_estimators):
3 grad = negative_gradient(y, raw_predictions)
4 model = deepcopy(self.base_estimator)
5 model.fit(X, grad)
6 grad = model.predict(X)
7 raw_predictions += self.learning_rate * grad
8 self.loss_.append(np.sum(objective_function(y, raw_predictions)))
9 self.estimators_.append(model) 在上述代码中,第1行里X表示样本特征形状为[n_samples,n_features],y和raw_predictions分别表示真实标签和预测结果且形状均为[n_samples,]。第2~9行表示开始进行梯度提升操作。第3行是根据真实值和预测值计算得到负梯度。第4~5行是深度拷贝一个基模型,并用训练样本和真实梯度来进行拟合,因为在预测阶段无法计算得到真实梯度,需要使用对应的模型来预测梯度。第6~7行则是根据梯度来更新预测结果(训练时第7行里的grad也可以直接使用第3行的真实值)。第8~9行则是分别保存损失和拟合后的模型。
继续,在完成所有梯度提升过程的实现后,只需要再定义一个fit方法来整合即可,示例代码如下:
1 def fit(self, X, y):
2 self.raw_predictions = np.zeros(X.shape[0])
3 self._fit_stages(X, y, self.raw_predictions)在上述代码中,第2行是定义一个全0向量作为模型预测的初始值,形状为[n_samples,]。第3行则是根据训练集和标签进行模型拟合。
4. 预测实现
在完成模型拟合部分的代码后,最后还需要定义一个方法来对新样本进行预测,示例代码如下:
1 def predict(self, X):
2 raw_predictions = np.zeros(X.shape[0]) # [n_samples,]
3 for model in self.estimators_:
4 grad = model.predict(X) # 预测每个样本在当前boost序列中对应的梯度值
5 raw_predictions += self.learning_rate * grad # 梯度下降更新预测结果
6 return raw_predictions在上述代码中,第1行X便是新输入的测试样本。第3-5行是开始遍历每个基模型,用于根据当前输入预测得到对应的梯度,并根据梯度提升算法对预测结果进行更新。第6行则是返回最终预测得到的结果。
5. 使用示例
在完成上述所有实现过程后,便可以来进行测试,示例代码如下:
1 if __name__ == '__main__':
2 x, y = make_data(200, False)
3 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
4 n_estimators = 100
5 base_estimator = LinearRegression()
6 my_boost = MyGradientBoostRegression(n_estimators=n_estimators,
7 base_estimator=base_estimator,learning_rate=0.1)
8 my_boost.fit(x_train, y_train)
9 plt.plot(range(n_estimators), my_boost.loss_)
10 plt.xlabel("boosting steps")
11 plt.ylabel("loss on training data")
12 plt.show()
13 loss = np.sum(objective_function(y_test, my_boost.predict(x_test)))
14 print(f"loss in test by MyGradientBoostRegression {loss}")在上述代码中,第2~3行用于返回得到训练集和测试集。第4~5行是设置提升次数和基模型,该基模型还可以是其它任意回归模型。第6~8行是实例化上面实现的梯度提升模型,并利用训练集进行拟合。第9~12行是将训练过程中的整个损失变换进行可视化,结果如图9-13所示。
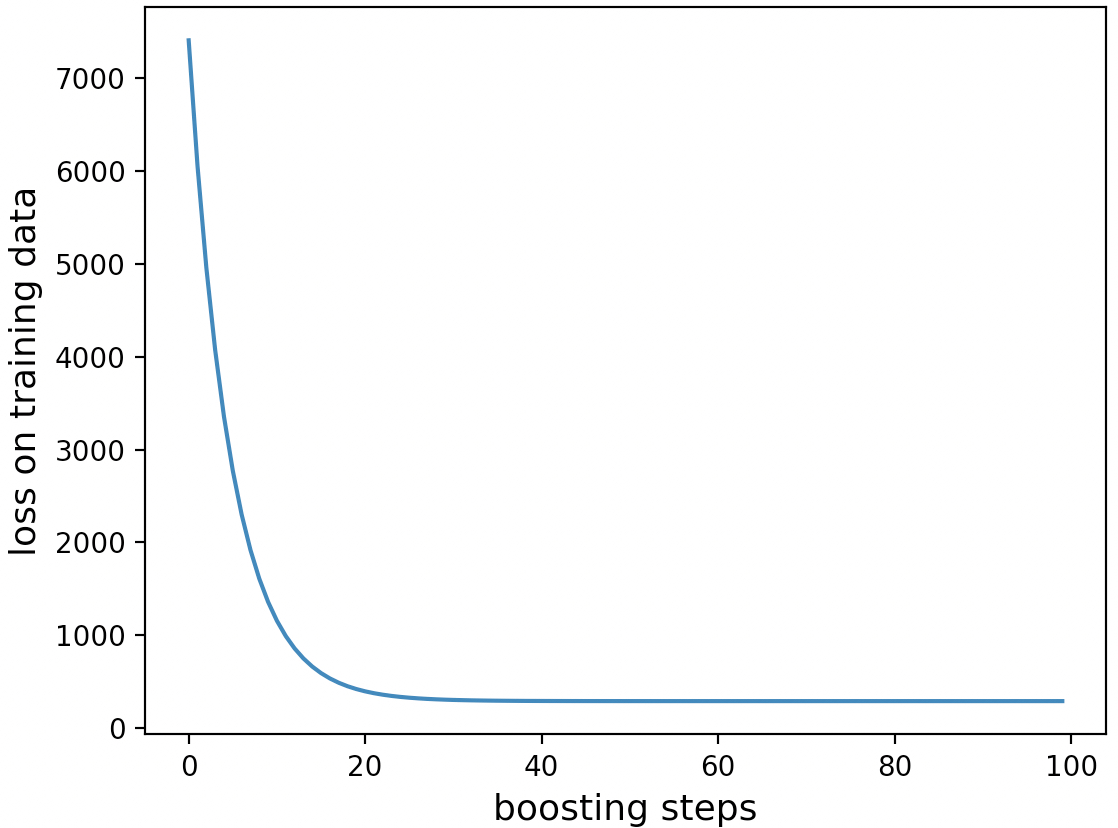
从图9-13可以看出,大约在20次提升之后模型便开始收敛了。
第14~15行则是模型训练完成后输出的损失值,结果如下:
loss in test by MyGradientBoostRegression 113.684最后,还可以同sklearn中的梯度提升回归进行对比,示例代码如下:
1 model = GradientBoostingRegressor()
2 model.fit(x_train, y_train)
3 loss = np.sum(objective_function(y_test, model.predict(x_test)))
4 print(f"loss in test by GradientBoostingRegressor {loss}")
5 # loss in test by GradientBoostingRegressor 163.6398从输出结果可以看出,MyGradientBoostRegression模型在该数据集上的表现结果还略好于sklearn中的GradientBoostingRegressor模型。以上完整示例代码可参见 AllBooKCode/Chapter09/C17_manual_gradient_boost_reg.py 文件。
到此,对于梯度提升中回归模型的实现就介绍完了,接下来再来看分类模型的实现过程。
9.6.7 从零实现Gradient Boost分类#
对于梯度提升分类模型来说,由于是对每个类别进行概率预测,所以需要在模型训练时的每一次提升中为每个类别训练一个对应的回归模型来预测梯度,因此一共需要训练$M\times K$个回归模型,具体各个部分实现如下。
1. 损失函数实现
在实现分类模型时,这里还是以9.6.5节中介绍的多项式误差作为损失函数。根据式(9-64)可知,损失函数实现示例代码如下:
1 def objective_function(y, raw_predictions, K):
2 Y = np.zeros((y.shape[0], K), dtype=np.float64)
3 for k in range(K):
4 Y[:, k] = y == k
5 return np.average(-1 * (Y * raw_predictions).sum(axis=1)
6 + logsumexp(raw_predictions, axis=1))在上述代码中,第2~4行是将真实标签转y换为one-hot的表示形式Y形状为[n_samples,n_classes]。第5~6行则是返回所有样本的损失平均,其中logsumexp等价于np.log(np.sum(np.exp(a)))。
2. 梯度求解实现
根据损失函数可知,其关于任意一个样本在第$i$个类别下的梯度计算方式如式(9-65)所示。根据式(9-65),梯度计算实现示例代码如下:
1 def negative_gradient(y, raw_predictions, k=0):
2 y = np.array(y == k, dtype=np.float64)
3 a = y - np.nan_to_num(np.exp(raw_predictions[:, k]
4 - logsumexp(raw_predictions, axis=1)))
5 return a在上述代码中,k表示当前对第$k$个类别计算梯度。第2行是对应式(9-65)中的$\mathbb{I}(y=i)$。第3行是计算得到所有样本在第$k$个类别下的负梯度。需要注意的是这里用到了一个变形公式是$\frac{e^{a}}{b}=\frac{e^a}{e^{\ln{b}}}=e^{a-\ln b}$。
3. 梯度提升实现
在完成上述两个辅助函数的实现后,接下来需要定义一个类MyGradientBoostClassification来完成整个梯度提分类模型的实现。首先需要定义这个类并完成相应的初始化方法,示例代码如下:
1 class MyGradientBoostClassifier(object):
2 def __init__(self, learning_rate=0.1,
3 n_estimators=100, base_estimator=None):
4 self.learning_rate = learning_rate
5 self.n_estimators = n_estimators
6 self.base_estimator = base_estimator
7 self.loss_ = []在上述代码中,第4行表示梯度下降中的学习率。第5行表示模型提升的次数。第6行表示用于在测试数据上预测梯度的基模型。第7行用于保存训练过程中模型对应的损失值。
进一步,需要定义一个类方法来完成所有的梯度提升过程,示例代码如下:
1 def _fit_stages(self, X, y, raw_predictions):
2 for i in range(self.n_estimators):
3 for k in range(self.n_classes_):
4 grad = negative_gradient(y, raw_predictions, k)
5 model = deepcopy(self.base_estimator)
6 model.fit(X, grad)
7 # grad = model.predict(X)
8 raw_predictions[:, k] += self.learning_rate * grad
9 self.estimators_[i, k] = model # 保存每一次boosting对应第k个类别的模型
10 self.loss_.append(objective_function(y, raw_predictions, self.n_classes_))在上述代码中,第1行X,y,raw_predictions分别为特征、标签和预测概率,形状分别为[n_samples, n_features]、[n_samples,]和[n_samples,n_classes] 。第2行是开始进行梯度提升。第3行开始是在每一次提升中对所有样本每个类别下的预测概率利用梯度下降进行更新。第4行是在训练集上计算每个类别对应的真实梯度,当预测时就只能使用预测值了。第5~6行是深度拷贝传入的回归模型并进行拟合用于测试阶段预测梯度。第7行是训练过程中预测的梯度值,因为训练时可以通过第4行计算得到真实梯度所以直接使用真实梯度即可,这里只是进行说明。第8行是通过梯度下降对每个类别下的预测概率进行更新。第9行是保存每次梯度提升中每个类别对应的基模型。第10行则是保存每次梯度提升后模型在训练集上的整体损失。
继续,在完成所有梯度提升过程的实现后,只需要再定义一个fit方法来整合即可,示例代码如下:
1 def fit(self, X, y):
2 self.classes_, y = np.unique(y, return_inverse=True)
3 self.n_classes_ = len(self.classes_)
4 self.estimators_ = np.empty((self.n_estimators, self.n_classes_), dtype=object)
5 self.raw_predictions = np.zeros([X.shape[0], self.n_classes_])
6 self._fit_stages(X, y, self.raw_predictions)在上述代码中,第2行是得到真实的标签类别classes_和标签y,其中 return_inverse=True的作用是将标签进行标准化,例如[2,2,3,4]这个三分类标签会被标准化为[0,0,1,2]。第3行是得到分类数。第4行是初始化一个形状为[n_estimators,n_classes_]的矩阵用于保存提升过程中的基模型。第5行是初始化一个形状为[n_samples,n_classes]的概率预测结构。第6行则是开始拟合整个模型。
4. 预测实现
在完成模型拟合部分的代码后,最后还需要定义两个方法来对新样本进行预测,示例代码如下:
1 def predict_prob(self, X):
2 raw_predictions = np.zeros([X.shape[0], self.n_classes_])
3 for i in range(self.n_estimators):
4 for k in range(self.n_classes_):
5 model = self.estimators_[i, k]
6 grad = model.predict(X)
7 raw_predictions[:, k] += self.learning_rate * grad
8 return raw_predictions
9
10 def predict(self, X):
11 raw_predictions = self.predict_prob(X)
12 return np.argmax(raw_predictions, axis=1)在上述代码中,第2行是初始化预测样本每个类别对应的概率值。第3~6行是开始遍历每一次提升操作每个类别下对应的基模型,并预测当前状态下对应的梯度值。第7行根据梯度提升算法来更新每个类别对应的预测值。第8行是返回所有样本的预测概率值。第10~12行则是根据每个样本的预测概率值得到对应的真实标签。
5. 使用示例
在完成上述所有实现过程后,便可以来进行测试,示例代码如下:
1 if __name__ == '__main__':
2 x, y = load_iris(return_X_y=True)
3 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
4 base_estimator = DecisionTreeRegressor()
5 my_boost = MyGradientBoostClassifier(base_estimator=base_estimator,learning_rate=0.3)
6 my_boost.fit(x_train, y_train)
7 y_hat = my_boost.predict(x_train)
8 print(f"accuracy on training data {accuracy_score(y_train, y_hat)}")
9 y_hat = my_boost.predict(x_test)
10 print(f"accuracy on testing data {accuracy_score(y_test, y_hat)}")
11
12 plt.plot(range(my_boost.n_estimators), my_boost.loss_)
13 plt.xlabel("boosting steps", fontsize=13)
14 plt.ylabel("loss on training data", fontsize=13)
15 plt.show()在上述代码中,第2~3行用于返回得到训练集和测试集。第4行是设置用于预测梯度的基模型,同样还可以是其它任意回归模型。第5~7行是实例化上面实现的梯度提升模型,并利用训练集进行拟合和预测。第9~10行是输出模型在测试集上的表现结果。
1 accuracy on training data 1.0
2 accuracy on testing data 0.9555第12~15行是对训练过程中每次提升后的损失值进行可视化,如图9-14所示。
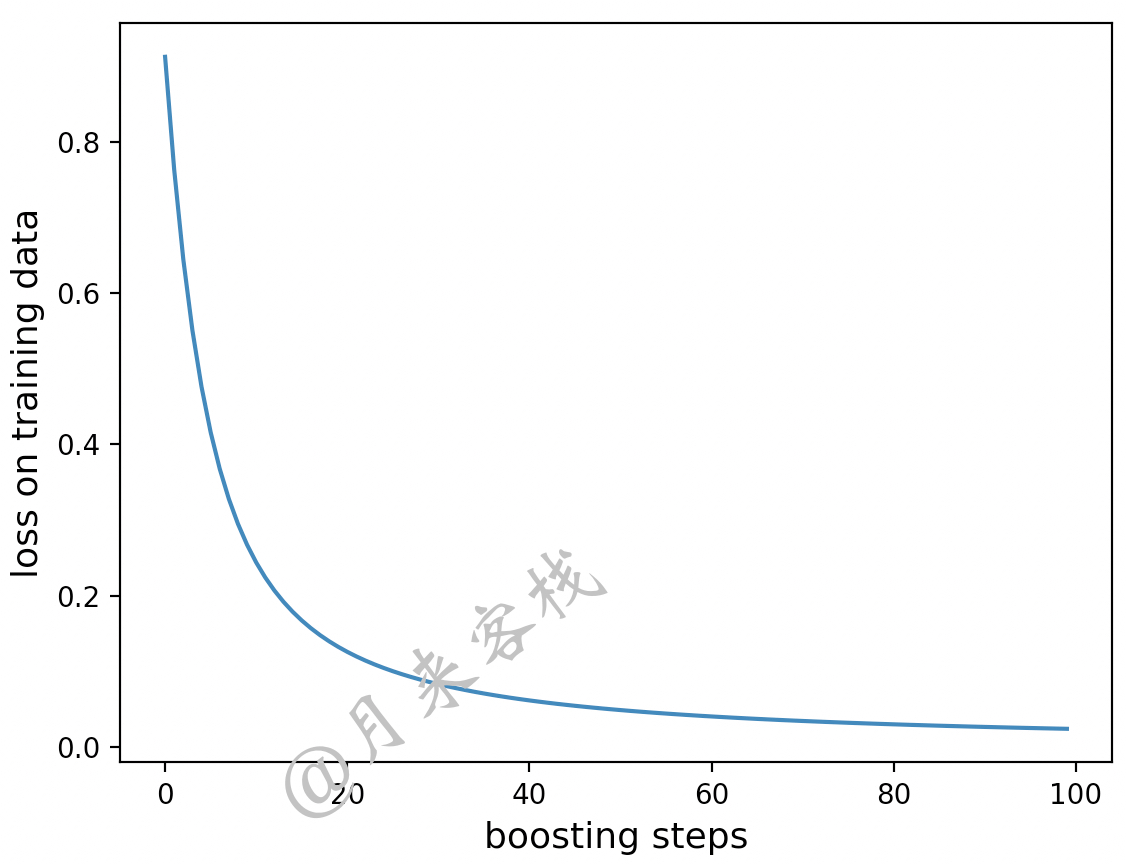
从图9-14可以看出,大约在60次提升之后模型便开始收敛了。最后,还可以同sklearn中的梯度提升回归进行对比,示例代码如下:
1 boost = GradientBoostingClassifier(init='zero')
2 boost.fit(x_train, y_train)
3 print(f"accuracy on training data: {boost.score(x_train, y_train)}")
4 print(f"accuracy on testing data: {boost.score(x_test, y_test)}")输出结果为:
1 accuracy on training data: 1.0
2 accuracy on testing data: 0.955以上完整示例代码可参见 AllBooKCode/Chapter09/C18_manual_gradient_boost_cla.py 文件。
9.6.8 小结#
在本节内容中,我们首先介绍了梯度提升算法的基本思想原理,并总结了整个算法的迭代流程;然后分别以梯度提升回归和梯度提升分类为例,详细介绍了整个算法的计算过程以及在sklearn中的使用示例;接着介绍了如何从零实现基于梯度提升的回归模型和分类模型,包括损失函数实现、梯度求解实现以及模型拟合与预测等过程;最后还将实现的回归和分类模型同sklearn中的相应模型进行了比较,发现两者在当前数据集上的预测精度并没有明显差异。
总结一下,在本章中我们首先介绍了集成学习算法的基本思想,并就3种常见的集成学习策略Bagging、Boosting和Stacking进行了简单介绍和示例,接着进一步详细介绍了随机森林、自适应提升和梯度提升3种集成算法的基本原理以及如何从零实现;最后我们还通过一个真实的比赛数据集,详细介绍了从数据预处理到模型训练与预测的全过程。经过以上内容的学习,将会使我们对于如何从零构建一个机器学习模型有更深入的理解。
引用#
[1] Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
[2] https://en.wikipedia.org/wiki/Ensemble_learning
[3] https://en.wikipedia.org/wiki/Random_forest
[4] https://www.kaggle.com/c/titanic/data
[5] https://en.wikipedia.org/wiki/AdaBoost
[6] Hastie, Trevor; Rosset, Saharon; Zhu, Ji; Zou, Hui (2009). “Multi-class AdaBoost”. Statistics and Its Interface. 2 (3): 349–360.
[7] Friedman J, Hastie T, Tibshirani R. Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors)[J]. The annals of statistics, 2000, 28(2): 337-407.
[8] https://www.cs.toronto.edu/~mbrubake/teaching/C11/Handouts/AdaBoost.pdf
[9] https://www.cs.cmu.edu/~epxing/Class/10701-08s/recitation/boosting.pdf
[10] https://scikit-learn.org/stable/modules/ensemble.html#adaboost
[11] Trevor Hastie, Robert Tibshirani, Jerome Friedman, The Elements of Statistical Learning, Second Edition, Springer Series in Statistics, Jan 13, 2017.
[12] Friedman, J.H. (2001) Greedy Function Approximation: A Gradient Boosting Machine. Annals of Statistics, 29, 1189-1232.
[13] A Gentle Introduction to Gradient Boosting https://www.ccs.neu.edu/home/vip/teach/MLcourse/4_boosting/slides/gradient_boosting.pdf
[14] https://www.clear.rice.edu/comp540/Chapter10.pdf