第 6 章 模型优化方法#
在第5章内容中,我们详细介绍了深度学习模型训练过程中会用到的一些辅助技能和工具,以提高模型在训练过程的效率。在本章内容中我们将从模型优化的角度来介绍如何更快以及更好地训练一个深度学习模型。在本章内容中,我们将会详细介绍深度学习中常见的模型优化策略和方法,包括学习率调度器、梯度裁剪策略以及各种不同的归一化技术。同时,我们也将介绍基于梯度下降算法的各种改进版本,包括动量法、AdaGrad、AdaDelta和Adam等。这些算法为构建和优化深度学习模型提供了全面的指导和实践方法,并且能够帮助模型在训练过程中更快地进行收敛。
6.1 学习率调度器#
在深度学习模型训练过程中,当模型结果不太理想时最常用的做法之一就是动态调整学习率,即在模型的训练过程中采用某种策略让学习率动态变化。如最简单的方法可以是每迭代一轮学习率降为之前的一半。当然, 还可以通过其它一些更为复杂的策略来进行控制,例如在2017年谷歌发布的Transformer模型中,论文作者就采用了如下公式来动态调整学习率:
$$ \text{learning\_rate}=d\_{\text{model}}^{-0.5}\cdot \text{min}(\text{Steps}^{-0.5},\text{Steps}\cdot \text{ Warmup\_Steps}^{-1.5}) \tag{6-1} $$其中$d_{\text{model}}$表示模型的维度,$\text{Steps}$表示小批量迭代的次数,$\text{Warmup\_Steps}$表示前期线性增长的迭代次数。
根据式(6-1)中的计算方式,模型在训练过程中学习率的变化情况将如图6-1所示。
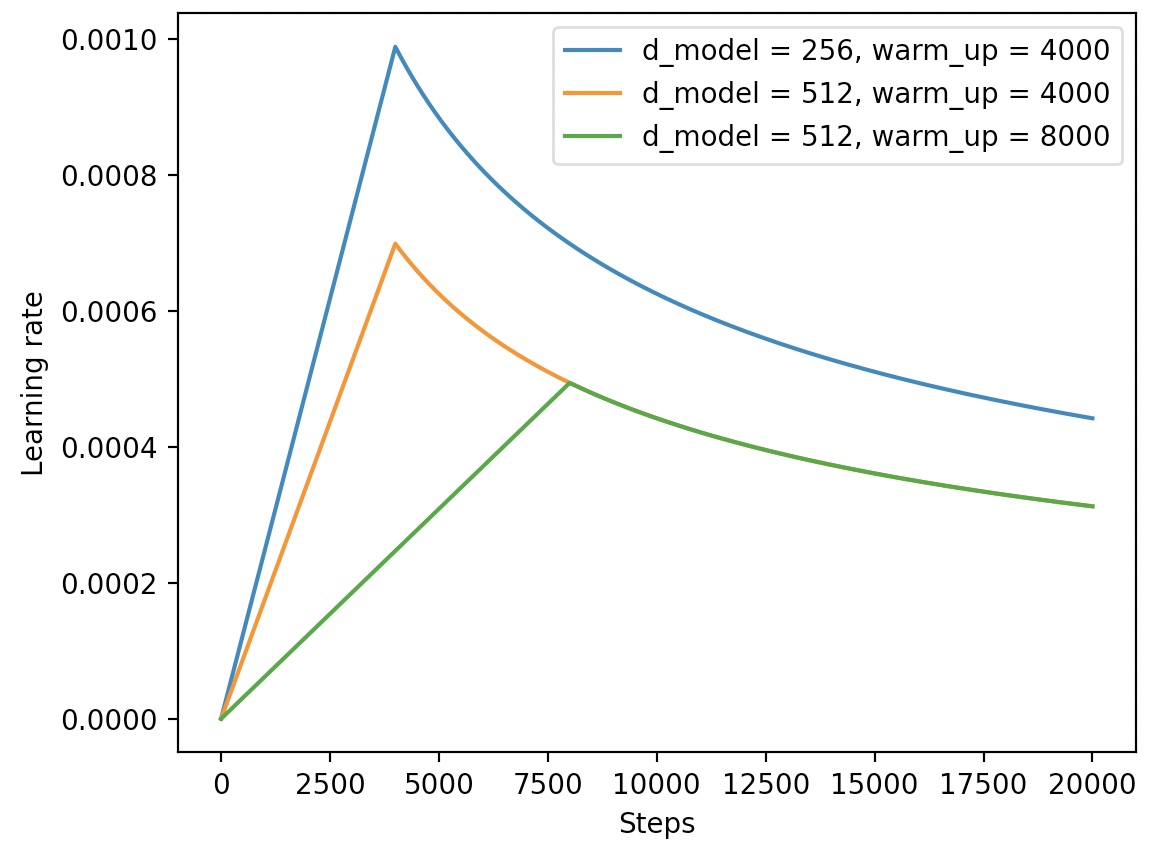
如图6-1所示,3条曲线分别表示3组参数下学习率随着迭代次的变化情况,其中到达顶点之前的线性增长阶段便是“热身”(Warmup)阶段。
当然,除了上述提到的两种学习率动态调整方式,常见的还有常数、线性、余弦变换等变换策略,并且还可以直接借助Transformers框架中的optimization模块来实现。在本节接下来的内容中,我们将会先介绍如何直接使用Transformers框架中的optimization模块来快速实现学习率动态调整的目的,然后再简单介绍一下各个方法背后的实现逻辑以及如何模仿来实现自定义的调整方法。
6.1.1 使用示例#
Transformers 框架是一个基于 PyTorch 和 TensorFlow 的开源自然语言处理框架,准确来说它应该是一个基于现有深度学习框架封装而来的高阶API库,由 HuggingFace 公司于2019年所发布 [2] [3]。Transformers 旨在提供便捷的训练、评估和部署最先进的NLP模型,特别是基于注意力机制的 Transformer 模型。该框架是目前最受欢迎和广泛使用的NLP框架之一,主要用于构建和训练自然语言处理模型,包括文本分类、序列标注、机器翻译、问答等任务。在后续的章节内容中我们也将陆续使用到该库。

Transformers 框架包含了各种最先进的NLP模型,如BERT、GPT、RoBERTa、T5等,并且还提供了大量预训练的模型和权重,用户可以直接使用这些预训练模型进行各种NLP任务的微调和迁移学习,无需从头开始训练模型,这大大节省了训练时间和资源。同时,Transformers 框架支持多种语言接口,包括Python、Java、JavaScript等,使得用户可以在不同的平台和环境中使用 Transformers 框架进行NLP任务的开发和部署。此外,Transformers 框架还支持分布式训练和模型并行化,使得用户能够高效地训练大规模的NLP模型。
在使用之前首先需要通过如下命令完成在Transformers框架的安装:
1 pip install transformers接着通过如下方式导入其中的optimization模块:
1 from transformers import optimization在optimization模块中,一共包含了6种常见的学习率动态调整方式,包括constant、constant_with_warmup、linear、polynomial、cosine 和cosine_with_restarts,其分别通过一个函数来返回对应的实例化对象,下面我们开始分别对其使用方法进行介绍。以下完整示例代码可以参见Code/Chapter06/C01_LearningRate/mian.py文件。
1. constant策略
在optimization模块中可以通过get_constant_schedule函数来返回对应的常数动态学习率调整方法。顾名思义,常数学习率动态调整就是学习率是一个恒定不变的常数,也就是说相当于没用。为了方便后续对学习率的变化过程可视化,这里先随意定义一个网络模型,示例代码如下所示:
1 class Model(nn.Module):
2 def __init__(self):
3 super(Model, self).__init__()
4 self.fc = nn.Linear(2,5)
5
6 def forward(self, x):
7 out = self.fc(x).sum()
8 return out进一步,在模型训练的过程中,我们可以通过以下方式来进行使用:
1 if __name__ == '__main__':
2 x = torch.rand([3, 2])
3 model = Model()
4 steps = 1000
5 optimizer = torch.optim.Adam(model.parameters(), lr=1.0)
6 scheduler = optimization.get_constant_schedule(optimizer, last_epoch=-1)
7 name,lrs = "constant",[]
8 for _ in range(steps):
9 loss = model(x)
10 optimizer.zero_grad()
11 loss.backward()
12 optimizer.step()
13 scheduler.step()
14 lrs.append(scheduler.get_last_lr())在上述代码中,第6行便是用来得到常数学习率变化的实例化对象,其中last_epoch用于在恢复训练时指定上次结束时的epoch数量,因为有些方法学习率的变化会与epoch数有关,如果不考虑模型恢复的话指定为-1即可,这部分内容将在本节末尾处进行详细介绍。第13行是对学习率进行更新。第14行是保存每次变化后的学习率便于可视化。
在整个迭代过程结束之后便可以得到如图6-3所示的可视化结果。
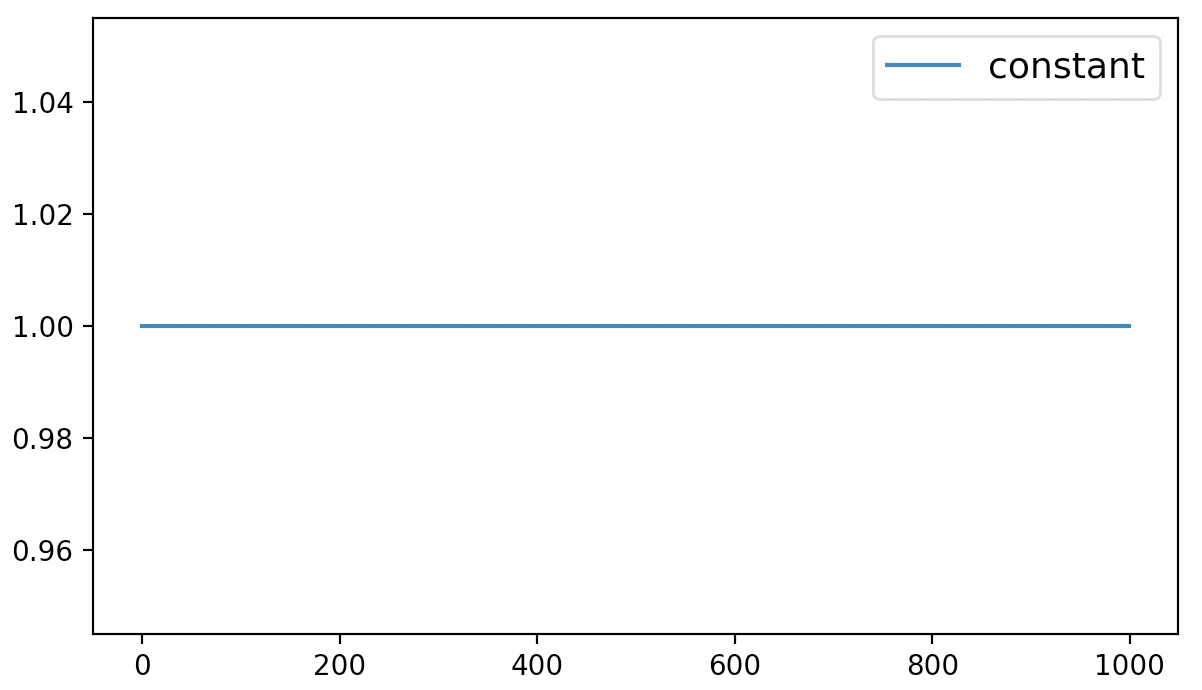
如图6-3所示,模型在整个训练过程中学习率并没有发生变化,一直保持着1.0的初始值。
2. constant_with_warmup策略
在optimization模块中可以通过get_constant_schedule_with_warmup函数来返回constant_with_warmup策略对应的动态学习率调整实例化方法。从名字可以看出,该方法最终得到的是一个带warmup的常数学习率变化。在模型训练的过程中可以通过以下方式进行使用:
1 scheduler = optimization.get_constant_schedule_with_warmup(
2 optimizer, num_warmup_steps=300)其中num_warmup_steps表示warmup的迭代次数。
最后,该方法的可视化结果如图6-4所示。
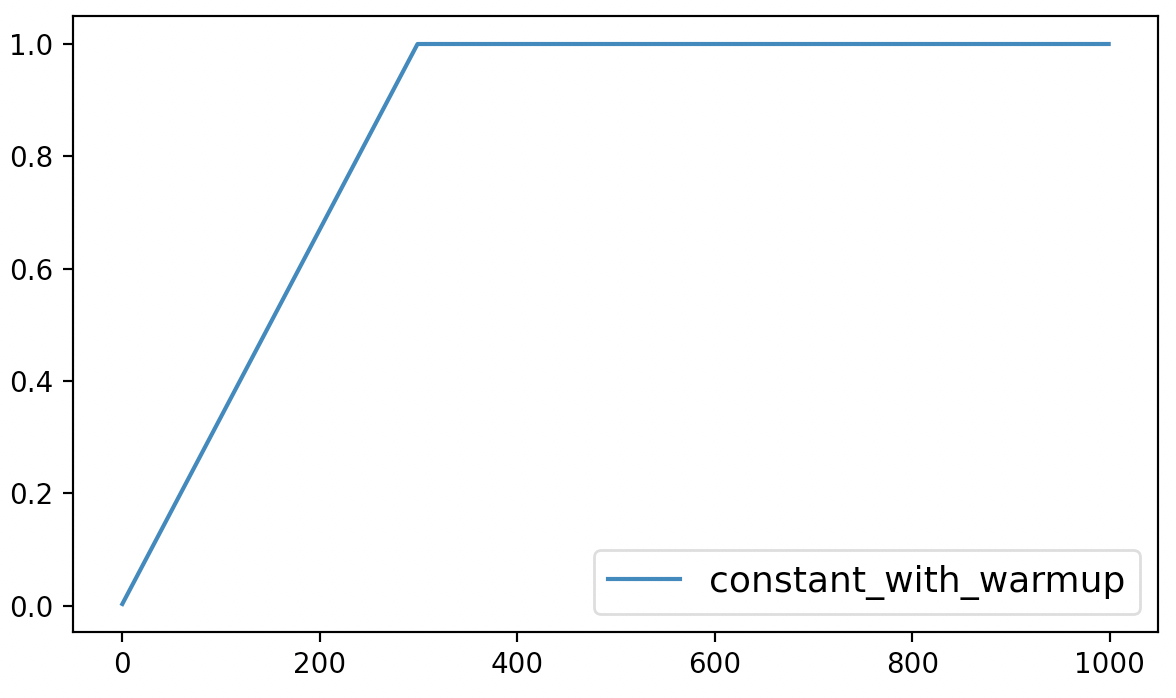
从图6-4可以看出,constant_with_warmup仅仅只是在最初的300个steps中以线性的方式进行增长,之后便是同样保持为常数。
3. linear策略
从名字可以看出,该方法最终得到的是一个带warmup的线性变换学习率调整方法。在模型训练的过程中,可以通过以下方式进行使用:
1 scheduler = optimization.get_linear_schedule_with_warmup(optimizer,
2 num_warmup_steps=300,num_training_steps=steps)其中num_training_steps表示整个模型训练的step数。
最后,该方法的可视化结果如图6-5所示。
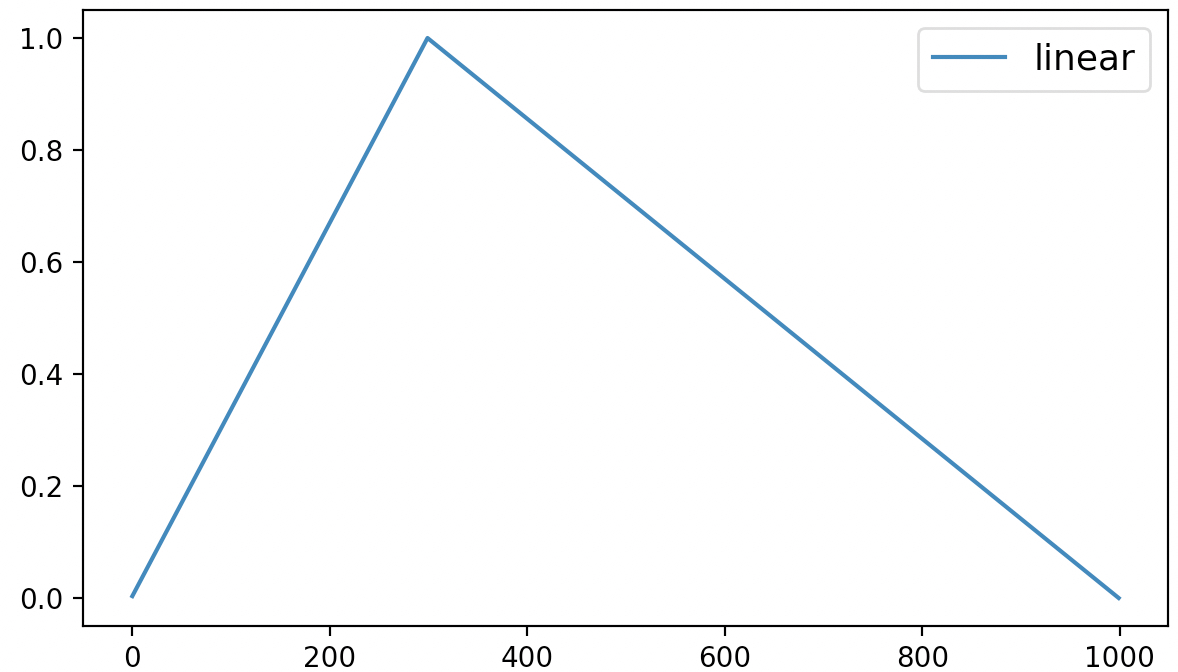
从图6-5可以看出,linear动态学习率调整策略先是在最初的300个迭代过程中以线性方式进行增长,之后便是同样以线性的方式进行递减,直到衰减到0为止。
4. polynomial策略
在optimization模块中可以通过get_polynomial_decay_schedule_with_warmup函数来返回带热身的多项式动态学习率调整实例化方法。在模型训练的过程中可以通过以下方式进行使用:
1 scheduler = optimization.get_polynomial_decay_schedule_with_warmup(optimizer,
2 num_warmup_steps=300,num_training_steps=steps, lr_end = 1e-7, power=3)其中power表示多项式的次数,当power=1时(默认)等价于get_linear_schedule_with_warmup函数。lr_end表示学习率衰减到的最小值。
最后,该方法的可视化结果如图6-6所示。
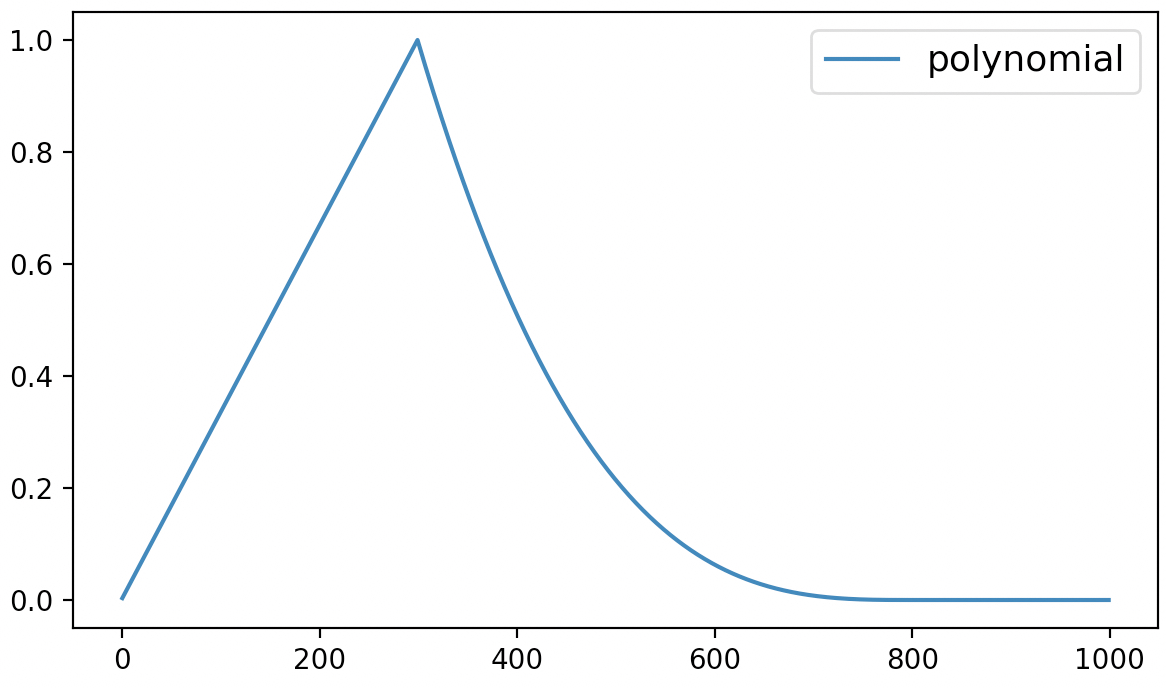
从图6-6可以看出,polynomial动态学习率调整策略先是在最初的300个迭代过程中以线性方式进行增长,之后便是多项式的方式进行递减,直到衰减到lr_end后保持不变。
5. cosine策略
在optimization模块中可以通过get_cosine_schedule_with_warmup来返回基于cosine函数变化的动态学习率调整方法。在模型训练过程中可以通过如下方式进行使用:
1 scheduler = optimization.get_cosine_schedule_with_warmup(optimizer,
2 num_warmup_steps=300,num_training_steps=steps,num_cycles=2)其中num_cycles表示循环的次数。
最后,该方法的可视化结果如图6-7所示。
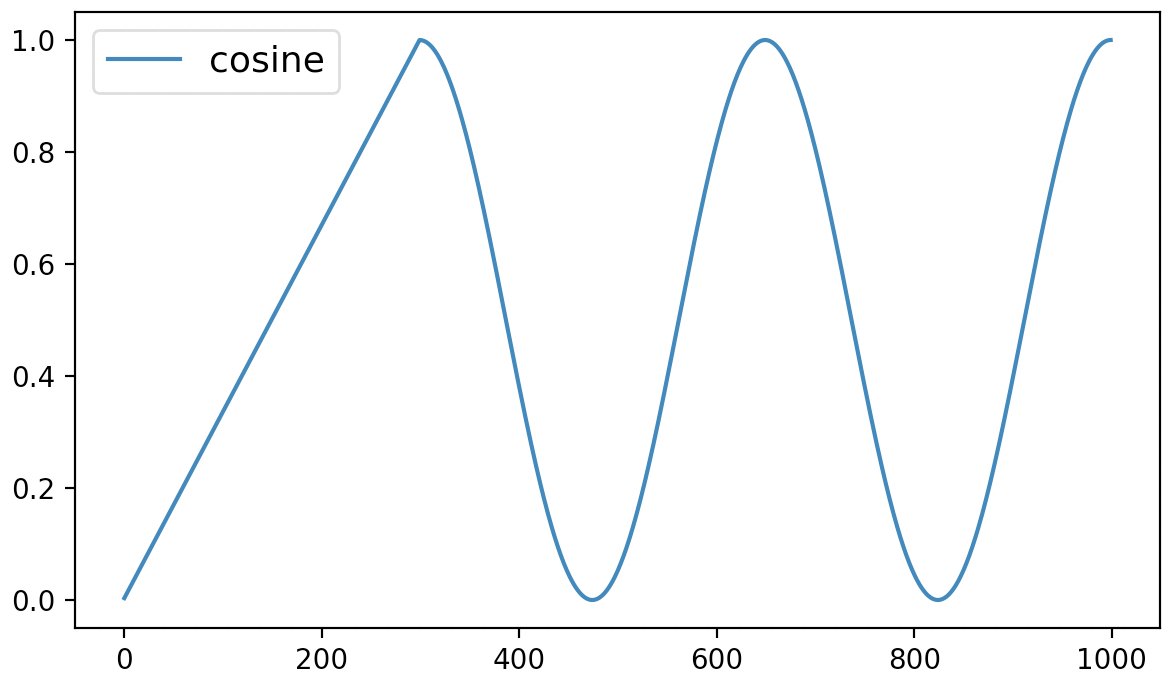
从图6-7可以看出,cosine动态学习率调整策略先是在最初的300个steps中以线性的方式进行增长,之后便是以余弦函数的方式进行周期性变换。
6. cosine_with_restarts策略
在optimization模块中可以通过get_cosine_with_hard_restarts_schedule_with_warmup来返回基于cosine函数的硬重启动态学习率调整方法。所谓硬重启是指学习率衰减到0之后直接变回到最大值再次进行衰减。在模型训练过程中可以通过如下方式进行使用:
1 scheduler = optimization.get_cosine_with_hard_restarts_schedule_with_warmup(optimizer,
2 num_warmup_steps=300,num_training_steps=steps,num_cycles=2)最后,该方法的可视化结果如图6-8所示。
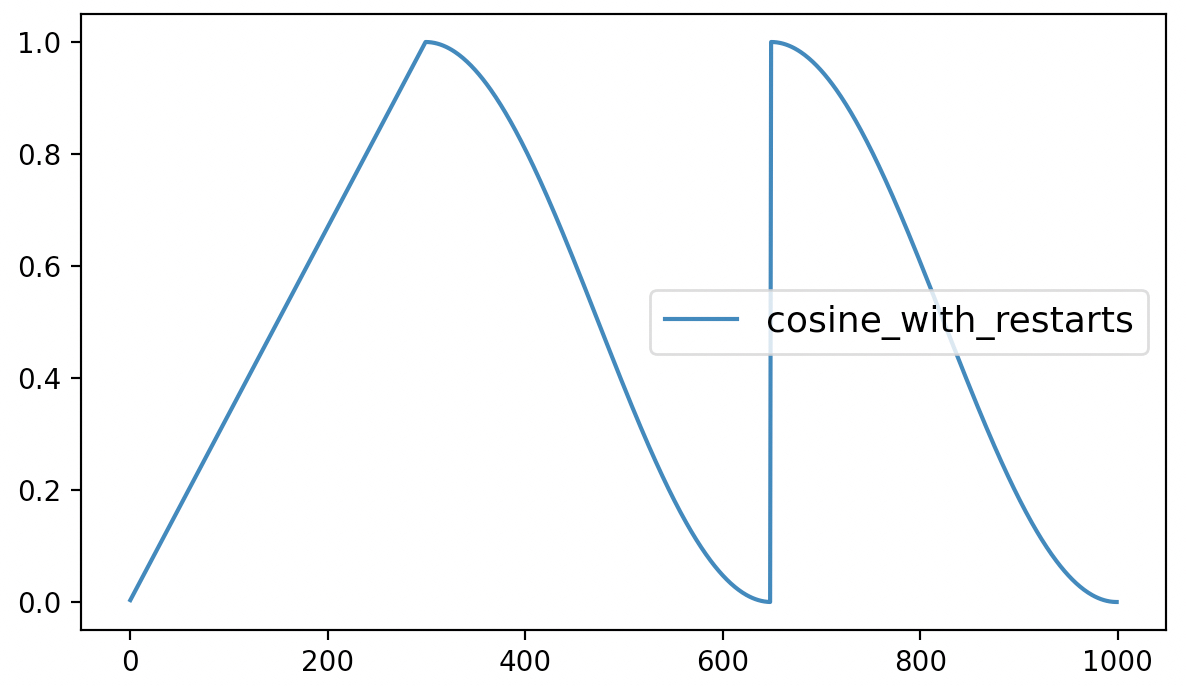
从图6-8可以看出,cosine_with_restarts动态学习率调整策略先是在最初的300个迭代过程中以线性方式进行增长,之后便是以余弦函数的方式进行周期性衰减,当达到最小值时再直接恢复到初始学习率。
7. get_scheduler方法
通过上述6个函数便能够返回得到相应的动态学习率调整方法。当然,如果你并不需要修改一些特定的参数,例如多项式中的power和余弦变换中的num_cycles等,那么还可以使用一个更加简单的统一接口来调用上述6个方法,示例代码如下所示:
1 from transformers import get_scheduler
2 def get_scheduler(
3 name: Union[str, SchedulerType],
4 optimizer: Optimizer,
5 num_warmup_steps: Optional[int] = None,
6 num_training_steps: Optional[int] = None):在上述代码中,第3行name表示指定学习率调整的方式,可选项就是上面介绍的6种,并且通过constant、constant_with_warmup、linear、polynomial、cosine 和cosine_with_restarts这6个关键字就能够返回得到对应的方法;而对于其它特定的参数则会保持每个方法对应的默认值。例如通过get_scheduler函数返回get_cosine_with_hard_restarts_schedule_with_warmup时,num_cycles则为1
例如可以以如下方式来使用cosine_with_restarts策略进行学习率动态调整:
1 scheduler = get_scheduler(name="cosine_with_restarts", optimizer=optimizer,
2 num_warmup_steps=300, num_training_steps=steps)6.1.2 实现原理#
在介绍完Transformes框架中常见的6种学习率动态调整方法及其使用示例后,我们再来简单地一下其背后的实现原理。对于Transformers框架中所实现的这6种学习率动态调整方法本质上也是基于PyTorch框架中的LambdaLR类而来,其定义
1 from torch.optim.lr_scheduler import LambdaLR
2 class LambdaLR(_LRScheduler):
3 def __init__(self, optimizer, lr_lambda, last_epoch=-1):
4 pass通过这个接口,只需要指定优化器、学习率系数的计算方式(函数)以及last_epoch参数来实例化类LambdaLR便可以返回得到相应的实例化对象。下面我们开始逐一进行介绍。
1. constant策略实现
对于constant的计算过程来说比较简单, 只需要传入一个返回值始终为1.0的匿名函数即可。因为返回的1将会作为一个系数乘以初始设定的学习率,以此来保证学习率不发生改变,实现代码如下所示:
1 def get_constant_schedule(Optimizer, last_epoch = -1):
2 return LambdaLR(optimizer, lambda _: 1, last_epoch=last_epoch)在上述代码中,lambda _:1就是对应返回值为1的匿名函数,其中_表示不需要传入参数。
2. constant_with_warmup策略实现
对于constant_with_warmup来说其计算过程也并不复杂,整体逻辑是在num_warmup_steps之前系数保持线性增长,在num_warmup_steps之后保持为1.0不变即可,故其计算公式为
$$ \text{lr\_coef}= \begin{cases} \frac{\text{current\_step}}{\text{num\_warmup\_steps}}, & \text{current\_step}\;<\;\text{num\_warmup\_steps} \\[2ex] 1.0, & \text{current\_step}\;\geq \;\text{num\_warmup\_steps} \end{cases}\tag{6-2} $$其中$\text{current\_step}$ 表示当前迭代的计数结果。
进一步,根据式(6-2)可知,constant_with_warmup策略的最终实现代码如下所示:
1 def get_constant_schedule_with_warmup(Optimizer, num_warmup_steps,last_epoch = -1):
2 def lr_lambda(current_step):
3 if current_step < num_warmup_steps:
4 return float(current_step) / float(max(1.0, num_warmup_steps))
5 return 1.0
6 return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)在上述代码中,第2~5行便是学习率动态调整的作用系数。这里我们需要再次提醒各位读者,lr_lambda()函数返回的是学习率的变换系数,该系数乘以初始的学习率才是最终模型用到的学习率。例如上述代码中当current_step大于等于num_warmup_steps时返回的系数就是1,这样就能保证在这之后学习率就会保持初始设定的学习率不变。
3. linear策略实现
对于linear的系数计算过程来说只需要分别在num_warmup_steps之前和之后均保持线性增加和线性减少即可,故其计算公式为
$$ \text{lr\_coef}= \begin{cases} \frac{\text{current\_step}}{\text{num\_warmup\_steps}}, & \text{current\_step}\;<\;\text{num\_warmup\_steps} \\[2ex] \frac{\text{num\_training\_steps}-\text{current\_step}}{\text{num\_training\_steps}-\text{num\_warmup\_steps}}, & \text{current\_step}\;\geq \;\text{num\_warmup\_steps} \end{cases}\tag{6-3} $$其中$\text{num\_training\_steps}$表示预先设定的总的小批量训练迭代次数。
进一步,根据式(6-3)可知,linear策略的最终实现代码如下所示:
1 def get_linear_schedule_with_warmup(optimizer, num_warmup_steps,
2 num_training_steps, last_epoch=-1):
3 def lr_lambda(current_step: int):
4 if current_step < num_warmup_steps:
5 return float(current_step) / float(max(1, num_warmup_steps))
6 return max( 0.0, float(num_training_steps - current_step) /
7 float(max(1, num_training_steps - num_warmup_steps)))
8 return LambdaLR(optimizer, lr_lambda, last_epoch)4. polynomial策略实现
对于polynomial的系数计算过程来说则稍微复杂了一点,其整体逻辑便是在num_warmup_steps之前系数保持线性增长,在num_warmup_steps之后保持为定值不变,在两者之间则以对应的多项式函数进行变换,故其计算公式为
$$ \begin{aligned} \text{lr\_coef}= &\begin{cases} \frac{\text{current\_step}}{\text{num\_warmup\_steps}}, & \text{current\_step}\;<\;\text{num\_warmup\_steps} \\[2ex] \frac{\text{lr\_end}}{\text{lr\_init}}, & \text{current\_step}\;> \;\text{num\_training\_steps} \\[2ex] \frac{\text{scale}+\text{lr\_end}}{\text{lr\_init}}, & \text{num\_warmup\_steps}\;\leq\;\text{current\_step}\;\leq\;\text{num\_training\_steps} \end{cases} \\[7ex] &\text{scale}=(\text{lr\_init}-\text{lr\_end})\cdot\left[1-\frac{\text{current\_step}-\text{num\_warmup\_steps}}{\text{num\_training\_steps}-\text{num\_warmup\_steps}}\right]^{\text{power}} \end{aligned}\tag{6-4} $$其中$\text{lr\_init}$表示初始设定的学习率。
进一步,根据式(6-4)可知,polynomial策略的最终实现代码如下所示:
1 def get_polynomial_decay_schedule_with_warmup(optimizer,
2 num_warmup_steps, num_training_steps, lr_end=1e-7,
3 power=1.0, last_epoch=-1):
4 lr_init = optimizer.defaults["lr"]
5 assert lr_init > lr_end, f"lr_end ({lr_end}) must be be smaller than initial lr ({lr_init})"
6 def lr_lambda(current_step):
7 if current_step < num_warmup_steps:
8 return float(current_step) / float(max(1, num_warmup_steps))
9 elif current_step > num_training_steps:
10 return lr_end / lr_init # as LambdaLR multiplies by lr_init
11 else:
12 lr_range = lr_init - lr_end
13 decay_steps = num_training_steps - num_warmup_steps
14 pct_remaining = 1 - (current_step - num_warmup_steps) / decay_steps
15 decay = lr_range * pct_remaining ** power + lr_end
16 return decay / lr_init # as LambdaLR multiplies by lr_init
17 return LambdaLR(optimizer, lr_lambda, last_epoch)5. cosine策略实现
对于cosine学习率动态变换的系数计算过程来说就稍微更复杂了,其整体逻辑便是在num_warmup_steps之前系数保持线性增长,在num_warmup_steps之后则以对应的余弦函数进行变换,故其计算公式为
$$ \begin{aligned} \text{lr\_coef}= &\begin{cases} \frac{\text{current\_step}}{\text{num\_warmup\_steps}}, & \text{current\_step}\;<\;\text{num\_warmup\_steps} \\[2ex] \frac{1}{2}\cdot\left(1+\cos\left(\text{scale}\right)\right), & \text{current\_step}\;\geq \;\text{num\_warmup\_steps} \\[2ex] \end{cases} \\[7ex] &\text{scale}=2\cdot\pi\cdot\text{num\_cycles}\cdot\frac{\text{current\_step}-\text{num\_warmup\_steps}}{\text{num\_training\_steps}-\text{num\_warmup\_steps}} \end{aligned}\tag{6-5} $$进一步,根据式(6-5)可知,cosine策略的最终实现代码如下所示:
1 def get_cosine_schedule_with_warmup(optimizer, num_warmup_steps,
2 num_training_steps, num_cycles = 0.5, last_epoch = -1):
3 def lr_lambda(current_step):
4 if current_step < num_warmup_steps:
5 return float(current_step) / float(max(1, num_warmup_steps))
6 progress = float(current_step - num_warmup_steps) /
7 float(max(1, num_training_steps - num_warmup_steps))
8 return max(0.0, 0.5 * (1.0 + math.cos(math.pi *
9 float(num_cycles) * 2.0 * progress)))
10 return LambdaLR(optimizer, lr_lambda, last_epoch)6. cosine_with_restarts策略实现
对于cosine_with_restarts学习率动态变换的系数计算过程来说,总体上与cosine方式的实现过程类似,仅仅只是多增加了一个条件判断,故其计算公式为
$$ \begin{aligned} \text{lr\_coef}=& \begin{cases} \frac{\text{current\_step}}{\text{num\_warmup\_steps}}, & \text{current\_step}\;<\;\text{num\_warmup\_steps} \\[2ex] 0.0, & \text{current\_step}\;>\;\text{num\_training\_steps}\\[2ex] \frac{1}{2}\cdot\left(1+\cos\left(\text{scale}\right)\right), & \text{num\_warmup\_steps}\;\leq\;\text{current\_step}\;\leq\;\text{num\_training\_steps} \\[2ex] \end{cases} \\[7ex] &\text{scale}=\pi\cdot\left(\text{num\_cycles}\cdot\frac{\text{current\_step}-\text{num\_warmup\_steps}}{\text{num\_training\_steps}-\text{num\_warmup\_steps}}\right)\%1.0 \end{aligned}\tag{6-6} $$其中这里的$\%$符号表示取余。
进一步,根据式(6-5)可知,cosine_with_restarts策略的最终实现代码如下所示:
1 def get_cosine_with_hard_restarts_schedule_with_warmup(optimizer,
2 num_warmup_steps, num_training_steps, num_cycles = 1, last_epoch = -1):
3 def lr_lambda(current_step):
4 if current_step < num_warmup_steps:
5 return float(current_step) / float(max(1, num_warmup_steps))
6 progress = float(current_step - num_warmup_steps) /
7 float(max(1, num_training_steps - num_warmup_steps))
8 if progress >= 1.0:
9 return 0.0
10 return max(0.0, 0.5 * (1.0 + math.cos(math.pi *
11 ((float(num_cycles) * progress) % 1.0))))
12 return LambdaLR(optimizer, lr_lambda, last_epoch)7. transfromer策略实现
经过对上述几种动态学习率调整方法实现过程的介绍,对于式(6-1)也就是Transformer论文中学习率的调整策略,我们也可以模仿上述的方式来进行实现,示例代码如下所示:
1 def get_customized_schedule_with_warmup(optimizer, num_warmup_steps,
2 d_model=1.0, last_epoch=-1):
3 def lr_lambda(current_step):
4 current_step += 1
5 arg1 = current_step ** -0.5
6 arg2 = current_step * (num_warmup_steps ** -1.5)
7 return (d_model ** -0.5) * min(arg1, arg2)
8 return LambdaLR(optimizer, lr_lambda, last_epoch)由于式(6-1)中计算学习率的方法并不涉及到初始学习率设置,所以在后面初始化Adam()等优化器时参数lr需要赋值为1.0,这样get_customized_schedule_with_warmup返回后的结果就直接是我们需要的学习率了。当然,也可以直接在上述代码第6行的返回值中再加上除以初始学习率这一步,这样后续就不用有优化器中学习率必须设置为1的限制了,各位读者理解便是。
进一步,可以通过前面类似方式来使用该方法,示例代码如下所示
1 optimizer = torch.optim.Adam(model.parameters(), lr=1.0)
2 scheduler = get_customized_schedule_with_warmup(optimizer,
3 num_warmup_steps=200,d_model=728)最终,上述代码在训练过中将会得到如图6-9所示的学习率变化曲线。
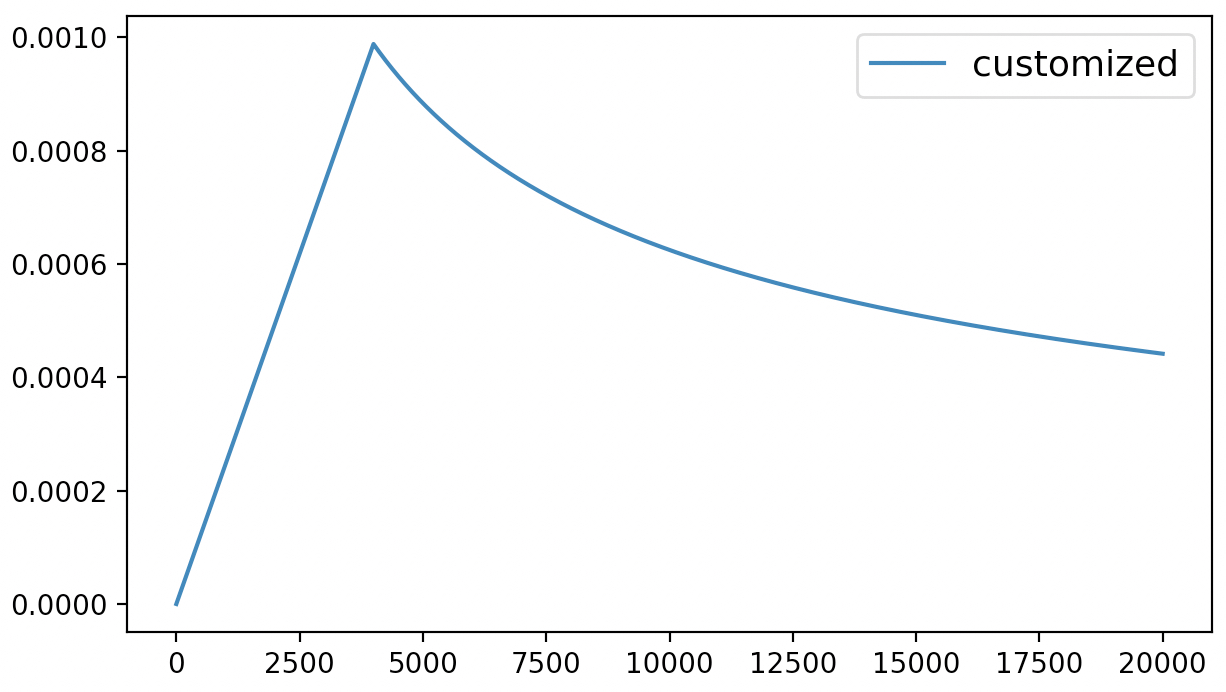
6.1.3 状态恢复#
在介绍完上述几种动态学习率调整及自定义方法的实现过程之后,我们再来大致看看底层LambdaLR的实现逻辑,以更有利于灵活地使用上述方法。当然,如果有读者暂时只想停留在对上述6种方式的使用层面,那么后续内容可以先行略过,等有需要再来查阅。
1. 实现逻辑
翻阅PyTorch框架总LambdaLR类的实现代码可以发现,类LambdaLR是继承自类_LRScheduler,两者之中的核心类方法和部分代码下所示:
1 class _LRScheduler(object):
2 def __init__(self, optimizer, last_epoch=-1):
3 if last_epoch == -1:
4 for group in optimizer.param_groups:
5 group.setdefault('initial_lr', group['lr'])
6 self.base_lrs = list(map(lambda group: group['initial_lr'], optimizer.param_groups))
7 self.last_epoch = last_epoch
8 self.step()
9
10 def step(self, epoch=None):
11 with _enable_get_lr_call(self):
12 if epoch is None:
13 self.last_epoch += 1
14 values = self.get_lr()
15 else:
16 self.last_epoch = epoch
17 if hasattr(self, "_get_closed_form_lr"):
18 values = self._get_closed_form_lr()
19 else:
20 values = self.get_lr()
21 for param_group, lr in zip(self.optimizer.param_groups, values):
22 param_group['lr'] = lr
23
24 class LambdaLR(_LRScheduler):
25 def __init__(self, optimizer, lr_lambda, last_epoch=-1):
26 self.optimizer = optimizer
27 self.last_epoch = last_epoch
28 self.lr_lambdas = [lr_lambda] * len(optimizer.param_groups)
29 super(LambdaLR, self).__init__(optimizer, last_epoch)
30
31 def get_lr(self):
32 return [base_lr * lmbda(self.last_epoch)
33 for lmbda, base_lr in zip(self.lr_lambdas, self.base_lrs)]要理解整个学习率的动态计算过程核心部分是是弄清楚get_lr()和step()这两个方法。从第6.1.1节中的使用示例可知,模型在训练过程中是通过step()这个方法来实现学习率的更新操作,因此这里这里就从step()方法入手来进行研究。
从上述代码第10行可以发现,step()方法在调用时还会接受一个epoch参数,但在上面的使用示例中并没有传入,那它又有什么用呢?进一步,从第12~14行可知当epoch为None时,那么self.last_epoch就会累计加1;而如果epoch不为None那么self.last_epoch就会直接取epoch的值;接着便是通过self.get_lr()函数来获取当前的学习率。在得到当前学习率的计算结果后,再通过第21-22行代码将其传入到优化器中便实现了学习率的动态调整。
接着再来看LambdaLR中get_lr()部分的实现代码。从第28行代码可知,self.lr_lambdas就是LambdaLR实例化时传入的参数lr_lambda,也就是第6.1.1节中介绍的学习率系数计算函数;而self.last_epoch则是前面对应的current_step参数。此时可以发现,LambdaLR中epoch这个概念不仅仅有我们平常训练时所说的迭代“轮”数,也可以理解成训练时参数更新的次数。
从第12~20行的逻辑可以看出,如果在使用过程中需要学习率在每个小批量迭代时也进行也进行更新,那么最简单的做法就是调用step()方法时不指定epoch;如果仅仅是需要在每个epoch(轮)后学习率才发生变化,那么在调用step()方法时指定epoch为当前的轮数即可,例如:
1 for epoch in epoches:
2 for data in data_iter:
3 optimizer.step()
4 scheduler.step(epoch=epoch)通常来说,前一种方式用到的时候更多,也就是第6.1.1节中介绍到的示例。
同时,根据上述代码第3~6行可知,当last_epoch=-1时_LRScheduler就默认当前为模型刚开始训练时的状态,并把optimizer中的lr参数作为初始学习率initial_lr,也就是后续的self.base_lrs,被用于在第33行中计算当前的学习率。当last_epoch不为-1时也就意味着此时的模型可能需要恢复到之前的某个时刻继续进行训练,那么学习率也就需要恢复到之前结束的那一刻。
下面,我们再来介绍最后一个示例,即如何通过指定last_epoch来恢复到之前中断时的状态继续进行追加训练。
2. 学习率恢复
假如某位读者正在采用cosine方法作为学习率动态调整策略来训练模型,并且在训练3轮迭代后便结束了训练,同时也得到了如图6-10所示的学习率变化曲线。
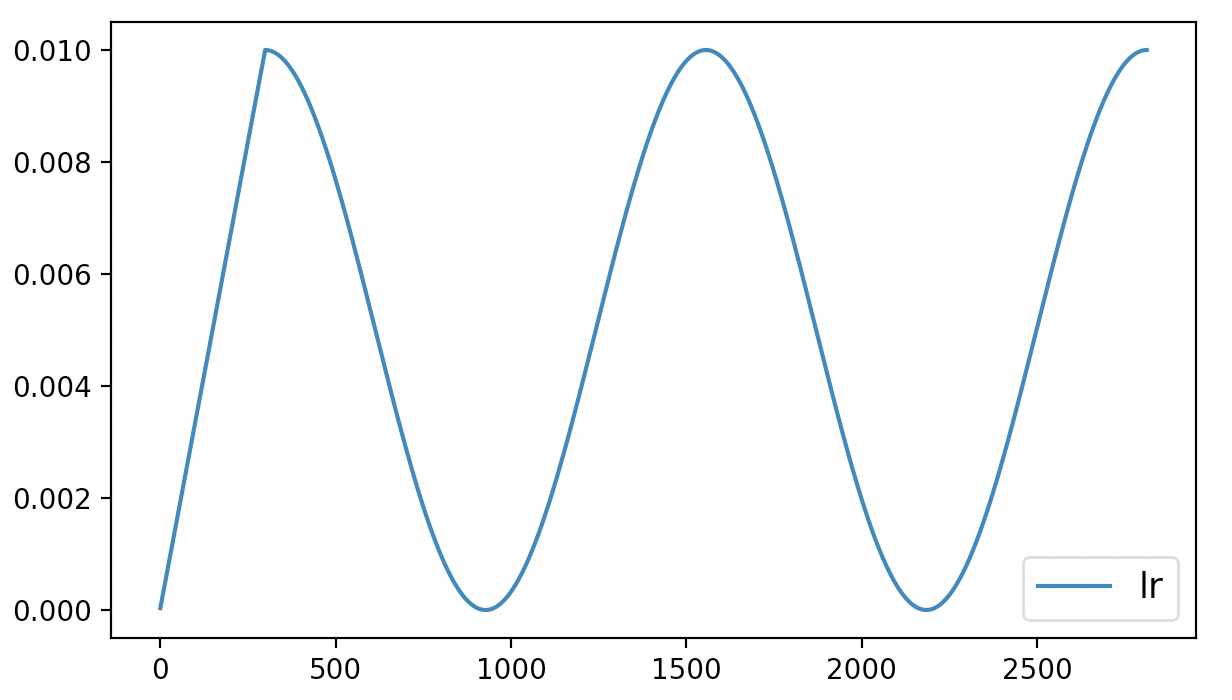
在这位读者认真分析完训练过程中所产生的相关数据后认为,模型如果继续进行训练应该还能获得更好的结果于是打算对之前保存的模型进行追加训练。但此时学习率要怎么样才能恢复到之前结束时的状态呢?也就是说模型在进行追加训练时学习率应该接着之前的状态继续进行,而不是像图10那样又从头开始。
此时可以通过如下代码来实现上述目的:
1 last_epoch = -1
2 if os.path.exists(config.model_save_path):
3 checkpoint = torch.load(config.model_save_path)
4 last_epoch = checkpoint['last_epoch']
5 model.load_state_dict(checkpoint['model_state_dict'])
6 num_training_steps = len(train_iter) * config.epochs
7 optimizer = torch.optim.Adam([{"params": model.parameters(),
8 "initial_lr": config.learning_rate}])
9 scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=300,
10 num_training_steps=num_training_steps,num_cycles=2, last_epoch=last_epoch)
11 for epoch in range(config.epochs):
12 for i, (x, y) in enumerate(train_iter):
13 loss, logits = model(x, y)
14 optimizer.zero_grad()
15 loss.backward()
16 optimizer.step() # 执行梯度下降
17 scheduler.step()
18 lrs.append(scheduler.get_last_lr())
19 torch.save({'last_epoch': scheduler.last_epoch,
20 'model_state_dict': model.state_dict()},config.model_save_path)在上述代码中,第2~5行用来判断本地是否存在模型,如果存在则获取对应的参数值。第7~10行则分别用来定义和实例化相关方法,当本地不存在模型时last_epoch将作为-1被传递到get_cosine_schedule_with_warmup中,即此时学习率从头开始变换。第19~20行则是对训练结束后的模型参数进行保存,同时也保存了last_epoch的值。
这里需要注意一点的是,只要在优化器中指定了initial_lr参数, 那么LambdaLR在动态计算学习率时的base_lr就是initial_lr对应的值,与优化器中的指定的lr参数也就没有了关系。
当后续再对模型进行追加训练时,第4行代码便获取得到了上一次训练结束后的last_epoch值,接着后续训练时学习率便可以接着上一次结束时的状态继续进行。最终也可以得到如图6-11所示的学习率变化曲线。
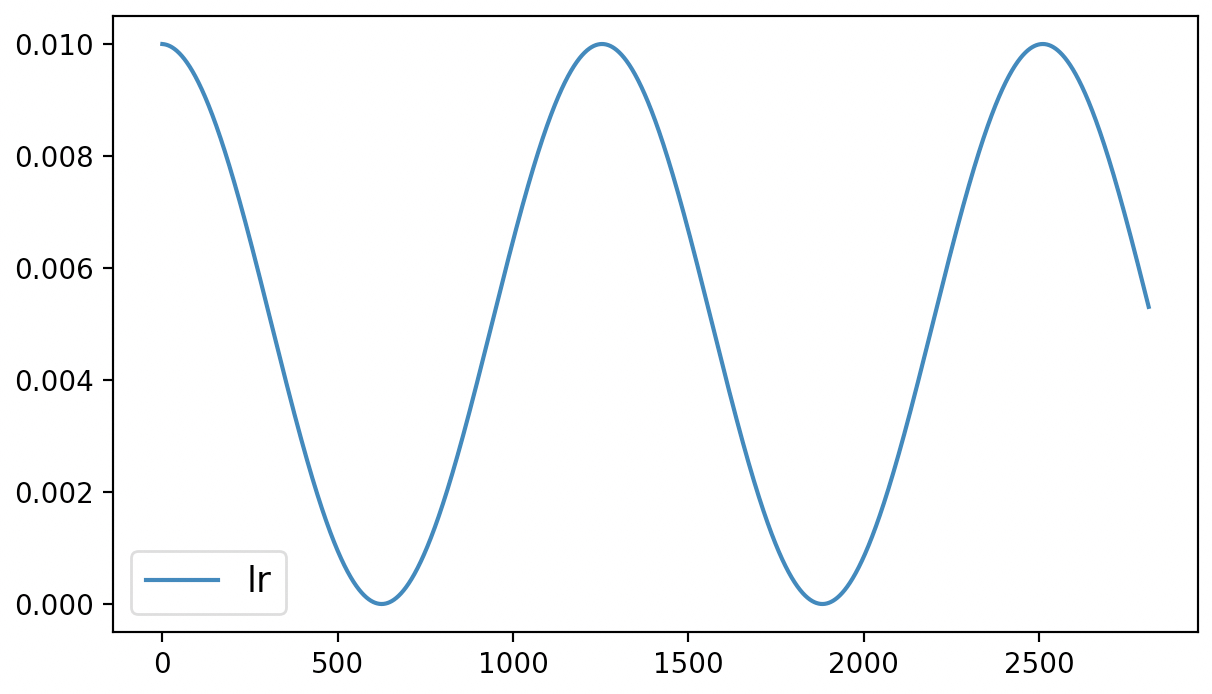
从图6-11可以看出,左侧学习率的初始值就是接着图6-10中学习率的结束值开始进行的变换。
6.1.4 小结#
在本节内容中,我们首先通过一个实例引出了什么是动态学习率调整;然后详细介绍了如何通过Transformers框架中的optimization模块来快速实现6种常见的动态学习率调整策略,并逐一进行了示例;接着介绍了PyTorch框架底层LambdaLR的实现逻辑,并对其中相关重要参数进行了介绍;最后通过一个示例介绍了如何在对模型进行追加训练时也能使得学习率恢复到之前训练时的状态。
引用#
[1] Paszke A, Gross S, Massa F, et al. Pytorch: An imperative style, high-performance deep learning library[J]. Advances in neural information processing systems, 2019, 32.
[2] https://huggingface.co/docs/transformers/index
[3] https://en.wikipedia.org/wiki/Transformer_(deep_learning_architecture)