11.10 基于密度的聚类算法#
在前面几节内容中,我们陆续介绍了3种常见聚类算法的原理与实现过程,包括原始的Kmeans聚类算法、Kmeans++聚类算法以及基于特征权重的加权Kmeans聚类算法 ,并且这3种都算是基于Kmeans框架下的聚类算法,也就是说它们本质上解决的都是一类数据的聚类问题。在本节内容中,我们将开始介绍一种新的聚类算法,即基于密度的聚类算法,其学习路线如图11-23所示。
11.10.1 DBSCAN算法思想#
由于在实际场景中我们遇到的不仅仅只有图11-2所示簇结构的数据集,还可能存在一些其它簇结构形式的数据,例如图11-24所示的结构类型。
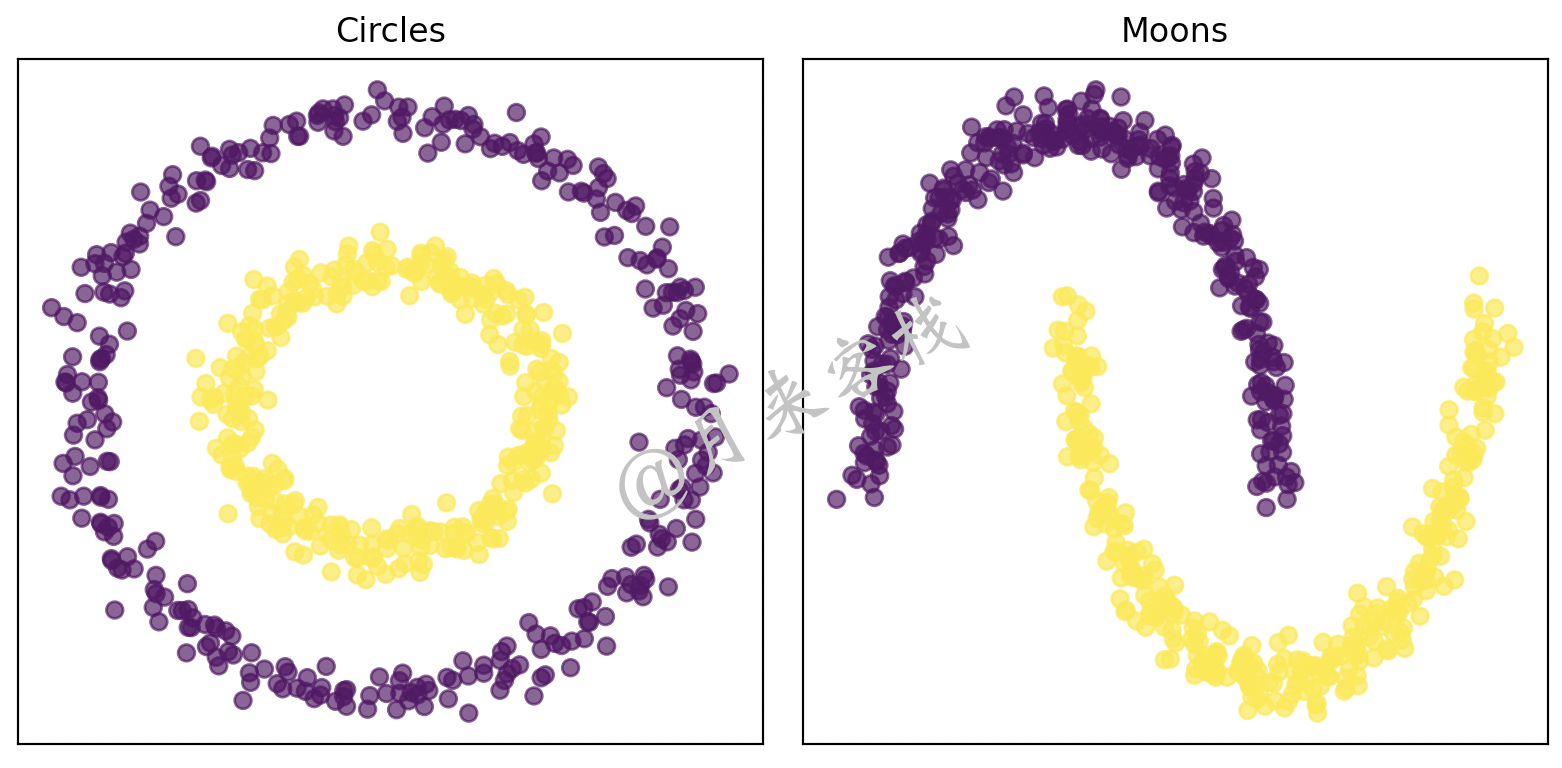
如图11-24所示,对于这两种异形的数据集来说,不管是采用前面介绍的3种聚类算法中的哪一种,最后得到的结果都会很差,因为类Kmeans聚类算法都不适合对这种数据进行聚类处理,并且如果一定要用类Kmeans聚类算法来进行聚类,那么将会得到如图11-25所示的结果。
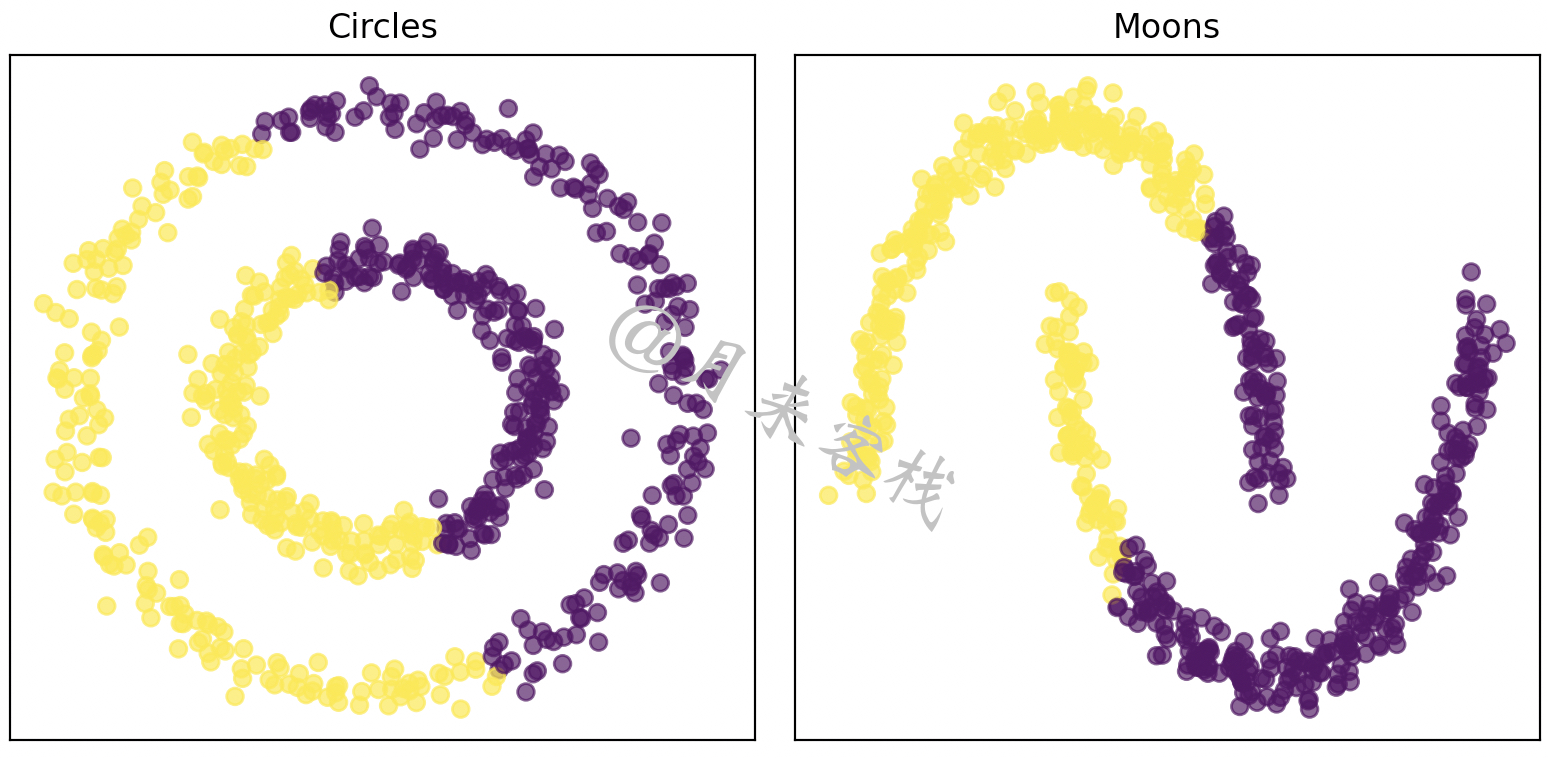
如图11-25所示,左右两边均是采用Kmeans++算法聚类后的结果,其中不同颜色表示聚类算法给出的聚类结果,可以看到由于类Kmeans聚类算法的特性,其在这类数据集上的表现并不好。对于图11-25所示这样结构的数据,一种更好的办法是基于密度来进行聚类。
基于密度的聚类算法(Density Based Spatial Clustering of Applications with Noise, DBSCAN),1996年由Martin Ester等人提出[1] [2],它的核心思想是根据样本之间的密度(紧凑程度)来对样本进行聚类处理。例如对于图11-25中所示的两种异形数据来说,两种类别之间有着明显空白之处(密度小),而对于各类别内部的样本来说样本之间分布却非常紧凑(密度大),因此只需要将所有各自相互紧邻的样本点划分为不同的簇结构即可完成整个聚类过程。可以发现,基于这样的聚类思想不管待聚类的数据集是什么样的分布形式,都可以很好的对其进行聚类处理。同时,从算法的全称可以看出,DBSCAN算法的原理除了是基于密度这一特性外,它还能有效地发掘数据中的异常样本,即那些密度低且相对孤立的样本点。
11.10.2 DBSCAN示例代码#
在介绍完DBSCAN算法的思想以后,我们再来看如何借助sklearn来完成整个建模过程,完整示例代码可参见 AllBooKCode/Chapter11/C17_dbscan_train.py 文件。具体地,先构造类似图11-25所示的数据集,然后使用sklearn中的DBSCAN模块来完成整个聚类过程,示例代码如下:
1 from sklearn.cluster import DBSCAN
2 from sklearn.datasets import make_moons
3
4 if __name__ == '__main__':
5 X, y = make_moons(n_samples=700, noise=0.05, random_state=2020)
6 X = StandardScaler().fit_transform(X)
7 db = DBSCAN(eps=0.3, min_samples=10)
8 db.fit(X)
9 print(f"调整兰德系数为: {adjusted_rand_score(y, db.labels_)}")在上述代码中,第1行是导入基于密度的聚类模块。第2行是导入一个函数,并通过第5行所示的方式来构造形如图11-25右边所示数据集。第6行是对数据样本进行标准化处理。第7行是利用DDBSCAN聚类算法对样本进行聚类处理,其中eps和min_samples表示用于构建核心样本的两个关键参数,eps越大且min_samples越小则最终得到的簇结构将会偏少,反之则得到簇结构将会偏多,详细原理见下文。第8~9行则是对于样本进行聚类处理,并通过调整兰德系数来对聚类结果进行评估。
11.10.3 DBSCAN算法核心概念#
在正式介绍DBSCAN算法的原理之前,先来介绍算法中几个非常重要的核心概念,核心样本、直接可达、可达和异常样本。同时,在DBSCAN算法中还有两个非常关键的超参数,半径$r$和最小样本数$\text{minPts}$,如图11-26所示。
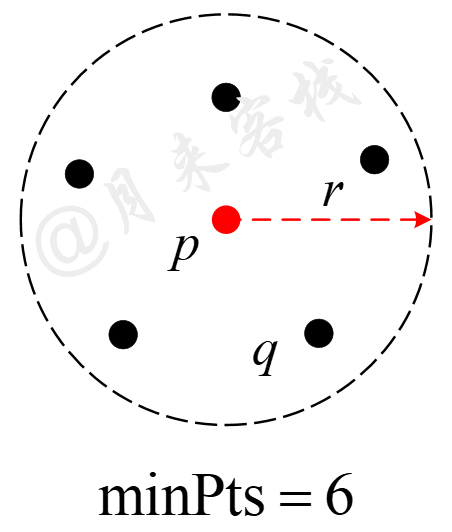
1)核心样本(Core Point):以样本点$p$为圆心$r$为半径作圆,如果圆域内至少存在$\text{minPts}$个样本(包括$p$自身),则称$p$为核心样本,否则称为非核心样本(Non-core Point)。
2)直接可达(Directly Reachable ):以核心样本$p$为圆心$r$为半径,圆域内的所有样本点对于$p$来说直接可达。
如图11-26所示,以样本点$p$为圆心$r$为半径作圆,圆域内恰好存在$\text{minPts}=6$个样本,则此时称$p$为核心样本,称$q$称为非核心样本。同时,称圆域内的所有样本对于核心样本$p$来说直接可达。值得注意的一点是,直接可达是针对核心样本而言,例如图11-26中样本$q$对于$p$来说直接可达,但不能说成样本$p$对于$q$来说直接可达。
3)可达(Reachable):如果存在样本点 $p_1,p_2,...,p_n$,且 $p=p_1,q=p_n$,$p_{i+1}$对于$p_i$来说直接可达,那么称$q$对于$p$来说可达。注意,这里暗含着$p_1,...,p_{n-1}$均为核心样本。
4)异常点(Outliers):如果样本点$O$对于其它任何样本点来说均不直接可达,则称样本点$O$为异常点。
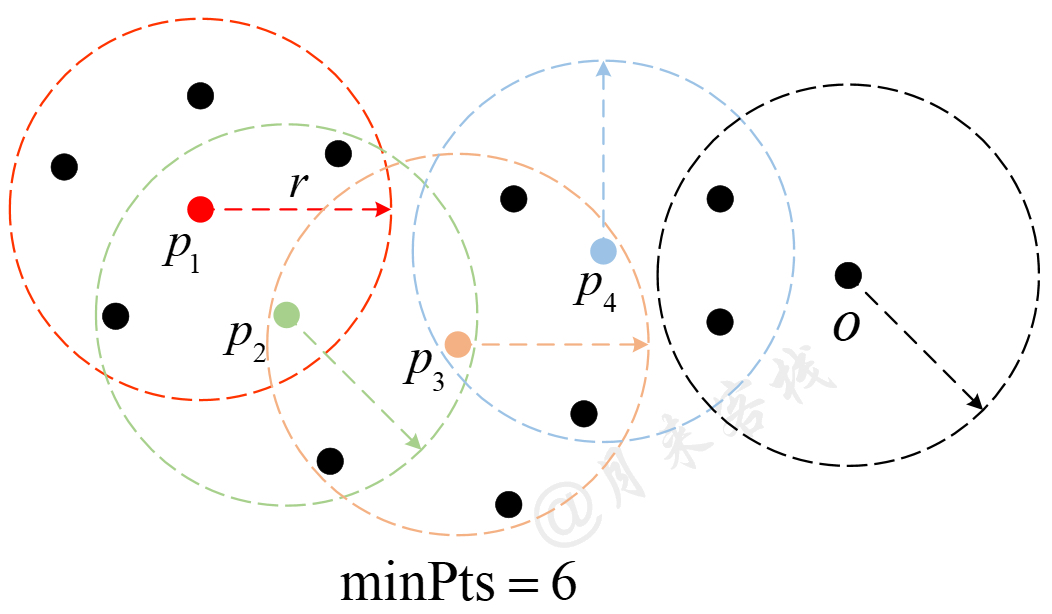
如图11-27所示,$p_1,p_2,p_3,p_4$均为核心样本,且$p_2$对于$p_1$来说直接可达,$p_3$对于$p_2$来说直接可达,$p_4$对于$p_3$来说直接可达,因此$p_4$对于$p_1$来说可达。同时,由于样本点$O$既不是核心样本,且对于其它样本来说也不直接可达,因此$O$为异常点。
11.10.4 DBSCAN算法原理#
在介绍完DBSCAN算法中的几个核心概念后我们再来学习DBSCAN算法的原理就相对简单一些了。总的来说DBSCAN算法的聚类过程大致可以分为两大步:①先计算得到每个样本点以$r$为半径圆域内的样本点,并得到相应的核心样本点;②然后再依次遍历每个样本,根据其是否为核心样本来对直接可达的样本点进行簇类别的划分。
具体地,整个聚类过程的详细步骤可以通过如下伪代码来进行表示:
1 def dbscan():
2 label_num = 0
3 labels =[-1,...,-1] # 长度为样本个数,均为-1的簇标签向量
4 for i = 0,...,n # 遍历所有样本点
5 if (样本i已经访问过) 或 (样本i不是核心样本):
6 continue
7 idx = i
8 while True:
9 if 第idx个样本没有被访问过:
10 为当前样本labels[idx]赋予一个簇类别label_num
11 if 当前样本idx为核心样本:
12 for j = 0,...,k : # 遍历第idx个核心样本周围的所有样本
13 if 第j个样本未被访问过:
14 将样本j对应的索引加入到栈s中
15 if 栈为空:
16 退出当前循环
17 idx = s.pop() # 取栈中最后一个元素并删除
18 label_num += 1最后,簇标签向量labels中保存的便是每个样本点所属的簇编号,同时如果labels[i]为-1,则表示第i个样本点为异常点。
11.10.5 DBSCAN计算示例#
在介绍完DBSCAN算法的原理后,我们下面再来通过一个实际的例子对算法的整个聚类过程进行示例,以便大家能够理解得更加透彻。
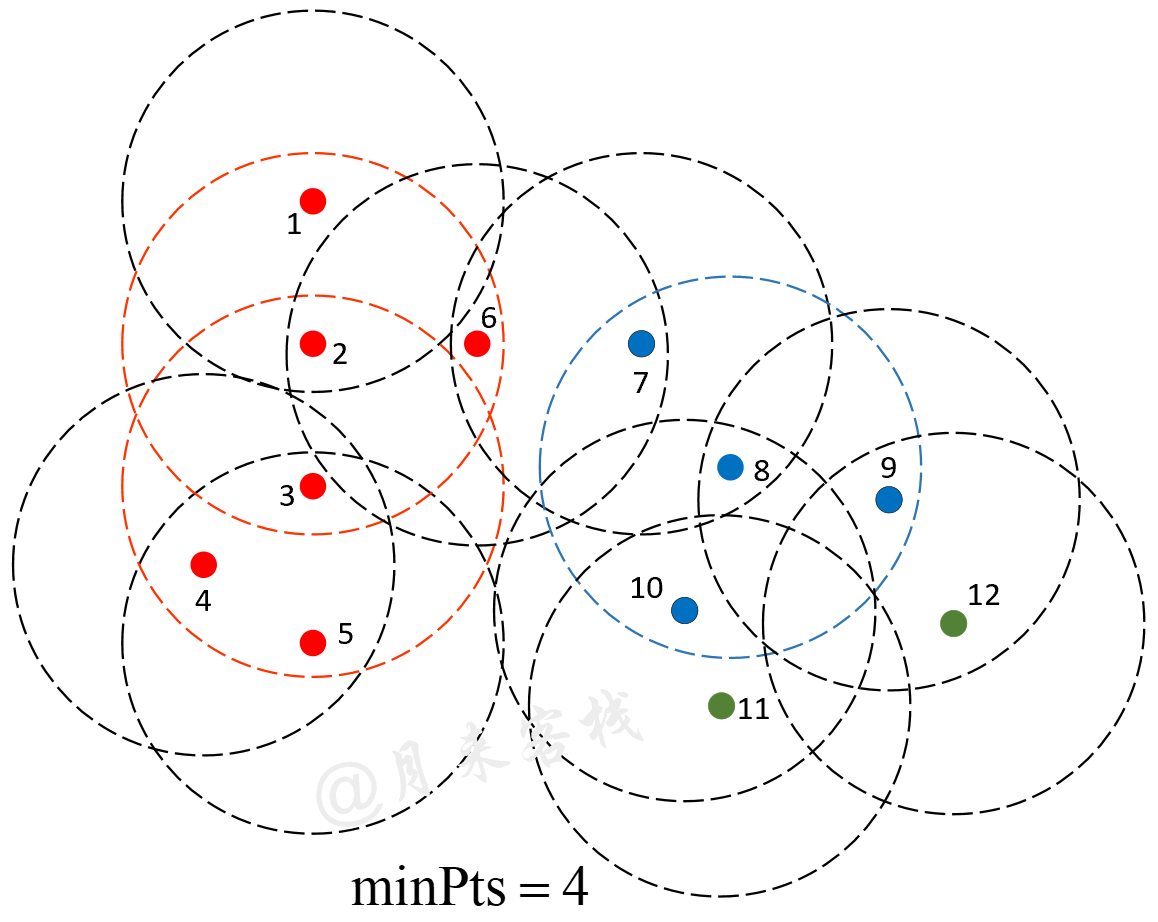
如图11-28所示,图中一共包含有12个样本点,$\text{minPts}=4$,且同时我们已经以每个样本点为圆心$r$为半径进行了作圆。根据图示可知样本2、3和8均为核心样本。下面,开始一步步来模拟DBSCAN算法的整个聚类过程。在阅读下面内容时建议结合11.10.4节中的伪代码进行理解。
不失一般性,以1到12的顺序遍历每个样本点。此时,由于第1个样本点为非核心样本所以继续遍历第2个样本。
由于第2个样本为核心样本,且第2个样本未被访问过,记label[2]=0,进一步继续遍历第2个样本点周围的3个样本点1、3和6。因为这3个样本点均未被访问过,所以放入栈中s=[1,3,6]。由于此时栈不为空,所以取栈s中的最后一个样本出栈,此时s=[1,3]。因为第6个样本点未被访问过,所以记label[6]=0,进一步因为第6个样本不是核心样本所以不用遍历其周围的样本点。由于此时栈不为空,所以取栈s中的最后一个样本出栈,此时s=[1]。因为第3个样本点为核心样本,且第3个样本未被访问过,记label[3]=0,进一步继续遍历第3个样本点周围的3个样本点2、4和5。由于第2个样本点之前被访问过,所以只需要将4和5放入栈中,即s=[1,4,5]。由于此时栈不为空,所以取栈s中的最后一个样本出栈,此时s=[1,4]。因为第5个样本点未被访问过,所以记label[5]=0,进一步因为第5个样本不是核心样本所以不用遍历其周围的样本点。由于此时栈不为空,所以取栈s中的最后一个样本出栈,此时s=[1]。因为第4个样本点未被访问过,所以记label[4]=0,进一步因为第4个样本不是核心样本所以不用遍历其周围的样本点。由于此时栈不为空,所以继续取栈s中的最后一个样本出栈,此时s=[]。因为第1个样本点未被访问过,所以记label[1]=0,进一步因为第1个样本不是核心样本所以不用遍历其周围的样本点。由于此时栈为空,所以退出当前while循环。
到此,图11-28中第1个簇已经聚类完毕,即图中的红色样本点。
进一步,开始遍历第3个样本点。由于第3个样本点已近被访问过,所以开始遍历第4个样本点。同时,第4、5、6个样本点均在上面被访问过,于是开始遍历第7个样本点。由于第7个样本不是核心样本,所以继续遍历第8个样本。
由于第8个样本为核心样本,且第8个样本未被访问过,记label[8]=1,进一步继续遍历第8个样本点周围的3个样本点7、9和10。因为这3个样本点均未被访问过,所以放入栈中s=[7,9,10]。由于此时栈不为空,所以取栈s中的最后一个样本出栈,此时s=[7,9]。因为第10个样本点未被访问过,所以记label[10]=1,进一步因为第10个样本不是核心样本所以不用遍历其周围的样本点。由于此时栈不为空,所以取栈s中的最后一个样本出栈,此时s=[7]。因为第9个样本点未被访问过,所以记label[9]=1,进一步因为第9个样本不是核心样本所以不用遍历其周围的样本点。由于此时栈不为空,所以取栈s中的最后一个样本出栈,此时s=[]。因为第7个样本点未被访问过,所以记label[7]=1,进一步因为第7个样本不是核心样本所以不用遍历其周围的样本点。由于此时栈为空,所以退出当前循环。
到此,图11-28中第2个簇已经聚类完毕,即图中的蓝色样本点。
进一步,最外层for循环开始遍历第9个样本。由于第9个样本点已经被访问过,同理第10个样本点也被访问过,所以开始遍历第11个样本点。由于第11个样本点不是核心样本,所以继续遍历第12个样本点。同样,虽然第12个样本点未被访问过,但是其同样不是核心样本点,所以退出循环,整个遍历过程结束,绿色样本表示异常样本。
最终,将会得到如下所示的聚类:
1 label[1]=0, label[2]=0, label[3]=0, label[4]=0, label[5]=0, label[6]=0,
2 label[7]=1, label[8]=1, label[9]=1, label[10]=1, label[11]=-1, label[12]=-1以上示例就是DBSCAN算法的整个聚类流程,同时各位读者还可以去网站[3]来看查看DBSCAN算法的动态聚类过程。
11.10.6 DBSCAN优缺点#
在介绍完整个DBSCAN的算法原理后我们再来看看它的一些优缺点。对于DBSCAN算法来说,其最大的优点在于它能够对任何形状的数据集进行聚类,其次在聚类之前并不需要指定簇的数量,这一点同类Kmeans算法不同。同时,在聚类结束后DBSCAN算法还能顺便从数据集中找到异常样本,而这对于某些异常检测场景来说是非常有用的。
虽然DBSCAN算法有着上述明显的优点,但是也存在不少缺点,其中最明显的就是慢。DBSCAN聚类算法慢主要体现在两个方面,一方面是根据半径$r$来查找每个样本点周围样本的过程;另一方面则是对每个样本点进行簇划分的过程。当然最慢的还前者,如果采用暴力法则需要$O(n^2)$的时间复杂度,采用类似于kd树这样的方法则也需要$O(n\text{log}n)$的时间复杂度,这相较于类Kmeans聚类算法$O(\text{num\_iter})$的时间复杂度来说明显慢了不少。同时,在聚类过程中如果簇与簇边界上的样本对于不同簇中的核心样本来说均是直接可达的,那么其最终归属于哪个簇则取决于样本的遍历顺序。例如在图11-28中,如果6号样本点也是核心样本,那么7号样本点属于左边的簇还是右边的簇则取决于是先遍历到6号样本还是8号样本。除此之外,如果某个数据集各个簇内部的密度差异过大,那么DBSCAN算法聚类结果将会大受影响。最后,对于半径$r$和$\text{minPts}$的选择也需要一定的经验。
到此,对于DBSCAN聚类算法的整个原理部分就介绍完了,下面我们再来介绍如何一步一步进行实现。
11.10.7 从零实现DBSCAN算法#
根据上面介绍的原理可知,DBSCAN聚类算法主要分为两大步:第1步是搜索得到每个样本点周围以$r$为半径$\text{minPts}$为阈值的样本点;第2步便是依次遍历每个样本,根据其是否为核心样本来对直接可达的样本点进行簇类别的划分。下面开始分别来对这两部分的代码实现进行介绍。以下完整示例代码可参见 AllBooKCode/Chapter11/C18_dbscan_imp.py 文件。
1. 样本搜索实现
作为实现DBSCAN聚类算法的关键一步,首先需要知道每个样本以自身为圆心$r$为半径,在这个圆域内有多少样本点。当然,最容易想到也但也最低效的做法就是依次遍历每个样本点,然后再分别计算它们与自身的距离并判断是否在半径$r$以内。不过这里我们可以沿用之前在第5章介绍K近邻时所使用的kd树来完成这一过程。
对于KNN算法来说,其核心在于如何快速找到距离自身最近的K个样本点。因此,只需要对这部分代码稍加改动就能够实现如何快速找到距离自身半径为$r$圆域内的样本点。
首先,定义一个MyNearestNeighbors,并继承自之前实现的类MyKDTree,代码如下:
1 class MyNearestNeighbors(MyKDTree):
2 def __init__(self, X, p, r=0.5):
3 super(MyNearestNeighbors, self).__init__(points=X, p=p)
4 self.r = r在上述代码中,第2行X表示原始的数据集;p表示$L_p$距离中的参数$p$,当p=2时表示使用欧氏距离;r表示半径。在根据上述初始化方法实例化类对象后,便得到了一个根据X构造而成的kd树。
下面,再根据kd树中的K近邻搜索代码修改为此处所需要的根据距离来搜索的代码即可,示例代码如下:
1 def query_radius_single(self, point):
2 query_radius_nodes = []
3 visited = []
4
5 def radius_node(point, curr_node, order=0):
6 nonlocal query_radius_nodes
7 logging.debug(f" query_radius 搜索当前访问节点为:{curr_node}")
8 if curr_node is None:
9 return None
10 visited.append(curr_node)
11 if self.distance(point, curr_node.data, self.p) <= self.r:
12 query_radius_nodes = self.append(query_radius_nodes, curr_node, point)
13 cmp_dim = order % self.dim
14 if point[cmp_dim] < curr_node.data[cmp_dim]:
15 radius_node(point, curr_node.left_child, order + 1)
16 else:
17 radius_node(point, curr_node.right_child, order + 1)
18 if np.abs(curr_node.data[cmp_dim] - point[cmp_dim]) < self.r:
19 child = curr_node.left_child if curr_node.left_child \
20 not in visited else curr_node.right_child
21 radius_node(point, child, order + 1)
22
23 radius_node(point, self.root, 0)
24 return query_radius_nodes在上述代码中,第1行point表示传入的一个样本点,形状为[n_features,]。第5~23行则是递归遍历整个kd树并完成找寻距离point半径为self.r圆域内的所有样本点。具体的搜索原理大家可以参考第5.4节中的内容,在这里就不再赘述。
进一步,需要实现一个方法来循环完成对所有样本点周围样本的搜索过程,示例代码如下:
1 def radius_neighbors(self, points):
2 result_points = []
3 result_ind = []
4 for point in points:
5 radius_nodes = self.query_radius_single(point)
6 tmp_points = []
7 tmp_ind = []
8 for node in radius_nodes:
9 tmp_points.append(node.data)
10 tmp_ind.append(int(node.index))
11 result_points.append(np.array(tmp_points))
12 result_ind.append(np.array(tmp_ind, dtype=np.int64))
13 logging.debug("搜索下一个样本点……")
14 return result_points, result_ind在上述代码中,第1行points表示传入的所有样本点,形状为[n_samples,n_features]。第4~7行是遍历每个样本点,并找到每个样本点周围的样本点。第8~10行是取每个样本点周围的样本点以及对应的索引。第14行则是返回整体最后的结果。
到此,我们就完成了对于样本点周围样本的搜索,示例代码如下:
1 def test_query_radius():
2 import numpy as np
3 from sklearn.neighbors import NearestNeighbors
4 samples = np.array([[0., 0.], [4, 5], [0., 1], [1., 1],
5 [3, 6], [4, 9], [7, 2], [10, 7], [8, 8], [9, 6]])
6 query = np.array([[1., 2], [1, 1], [4, 3], [7, 5], [6, 6]])
7
8 r = 1.6
9 neigh = NearestNeighbors(radius=r, leaf_size=1)
10 neigh.fit(samples)
11 neighborhoods = neigh.radius_neighbors(query, return_distance=False)
12 logging.info(f" ====== 查找样本点周围r={r}内的样本,NearestNeighbors 运行结果:")
13 logging.info(neighborhoods)
14
15 model = MyNearestNeighbors(samples, p=2, r=r)
16 _, neighborhoods = model.radius_neighbors(query)
17 logging.info(f" ====== 查找样本点周围r={r}内的样本,MyNearestNeighbors 运行结果:")
18 logging.info(neighborhoods)
19 if __name__ == '__main__':
20 test_query_radius()上述代码运行结束后的结果如下:
1 ====== 查找样本点周围r=1.6内的样本,NearestNeighbors 运行结果:
2 [array([2, 3]) array([0, 2, 3]) array([], dtype=int64)
3 array([], dtype=int64) array([], dtype=int64)]
4
5 ====== 查找样本点周围r=1.6内的样本,MyNearestNeighbors 运行结果:
6 [array([3, 2]), array([3, 2, 0]), array([], dtype=int64),
7 array([], dtype=int64), array([], dtype=int64)]上述结果中,列表中的每个元素表示距离query中对应样本在半径为r=1.6以内的样本点的索引。从输出结果可以看出,所有样本中距离点[1,2]距离小于等于1.6的样本有2、3两个样本,距离点[1,1]距离小于等于1.6的样本有0、2、3这3个样本。
2. 样本划分实现
在完成每个样本点以自身为圆心$r$为半径圆域内样本的搜索过程后,便可以进一步实现样本的簇划分过程。在这之前,需要先定义一个辅助函数,即实现11.10.4节中的伪代码来完成整个划分过程,示例代码如下:
1 def my_dbscan_inner(is_core, neighborhoods, labels):
2 label_num = 0 # 用来记录簇的编号
3 stack = [] # 深度优先遍历时用的栈
4 for i in range(labels.shape[0]):
5 if labels[i] != -1 or not is_core[i]:
6 continue
7 idx = i
8 while True:
9 if labels[idx] == -1:
10 labels[idx] = label_num
11 if is_core[idx]:
12 neighb = neighborhoods[idx]
13 for j in range(neighb.shape[0]):
14 v = neighb[j]
15 if labels[v] == -1:
16 stack.append(v)
17 if len(stack) == 0: #
18 break
19 idx = stack.pop()
20 label_num += 1在上述代码中,第1行is_core是一个只含0和1,形状为 [n_samples,]的向量, is_core[i]=1 表示第i个样本为核心样本;neighborhoods为一个列表,neighborhoods[i] 表示第i个样本以$r$为半径周围存在样本的索引;labels为一个形状为[n_samples,]的向量, labels[i]表示第i个样本所属的簇编号,初始情况全部为-1,即没有被访问过。第2行中label_num用来记录当前时刻的簇编号。第3行中stack是深度优先遍历样本时的栈。第4行构造索引开始遍历每一个样本。第5~6行判断如果该样本i已经访问过或者不是核心样本则继续遍历下一个样本,即只有没访问过且为核心样本才继续往下进行。第8行开始进行深度优先遍历。第9~10行判断如果第idx个样本没有被访问过,则为第idx样本赋予一个簇类别。第11~12行判断如果第idx个样本是核心样本,则取以第idx个核心样本为圆心,周围半径$r$内的所有样本点。第13~16行开始遍历核心样本点周围的所有样本,如果该样本没有被访问过则将其放入到栈中。第17行判断如果栈为空,则表示当前簇中所有样本都访问完毕,即此轮深度遍历结束。第19行是返回栈中最后一个元素并将其从栈中删除;第20行是累加簇编号,并进入下一个簇的划分过程中。
到此,对于DBSCAN算法中最重要的两个部分就实现完毕了,下面需要将这两部分结合起来实现最终的DBSCAN算法。
3. DBSCAN实现
在有了前面的铺垫之后,DBSCAN算法实现起来就变得非常容易了。首先仍旧需要先定义一个类并实现相应的构造函数,示例代码如下:
1 class MyDBSCAN(object):
2 def __init__(self, eps=0.5, p=2, min_samples=5):
3 self.eps = eps
4 self.p = p
5 self.min_samples = min_samples # 成为核心样本周围样本的最小数量在上述代码中,第2行中eps表示半径,p表示$L_p$距离中的参数$p$,min_samples表示构成核心样本的最小样本数。
进一步,利用第11.10.7节中实现的代码来完成整个聚类过程的实现,示例代码如下:
1 def fit(self, X):
2 neighbors_model = MyNearestNeighbors(X, p=self.p, r=self.eps)
3 time1 = time.time()
4 _, neighborhoods = neighbors_model.radius_neighbors(X)
5 time2 = time.time()
6 logging.info(f"计算每个样本点周围的样本花费时间为:{time2 - time1}s")
7 # 得到每个样本点在以self.eps为半径的区域内存在样本点的个数
8 n_neighbors = np.array([len(neighbors) for neighbors in neighborhoods])
9 labels = np.full(X.shape[0], -1, dtype=np.intp)
10 core_samples = np.asarray(n_neighbors >= self.min_samples, dtype=np.uint8)
11 my_dbscan_inner(core_samples, neighborhoods, labels)
12 time3 = time.time()
13 logging.info(f"对每个样本点进行簇划分花费的时间为{time3 - time2}s")
14 self.labels_ = labels在上述代码中,第1行中X表示数据集,形状为[n_samples,n_features]。第2行是实例化一个MyNearestNeighbors类对象并同时完成了kd树的构建。第4行是返回得到X中每个变量以自身为圆心self.eps为半径圆域内的所有样本点。第8行是得到每个样本点周围圆域内样本的个数。第9行是初始化一个全为-1的簇标记向量。第10行是得到核心样本的索引向量,core_samples[i]=1表示第i个样本为核心样本。第11行是对每个样本进行簇类别的划分,并得到最终的结果。
到此,对于整个DBSCAN算法的实现过程就介绍完了,下面来看使用示例。
11.10.8 DBSCAN使用示例#
在完成DBSCAN算法的实现过程后,可以通过如下所示的方式来进行使用,示例代码如下:
1 def test_circle_dbscan():
2 plt.figure(figsize=(8, 4))
3 X, labels_true = make_circles(n_samples=700, noise=0.05, random_state=2022,factor=0.5)
4 X = StandardScaler().fit_transform(X)
5 db = DBSCAN(eps=0.3, min_samples=10)
6 db.fit(X)
7 logging.info(f"DBSCAN: {adjusted_rand_score(labels_true, db.labels_)}")
8 my_db = MyDBSCAN(eps=0.3, min_samples=10)
9 my_db.fit(X)
10 logging.info(f"MyDBSCAN: {adjusted_rand_score(labels_true, my_db.labels_)}")
11
12 plt.subplot(1, 2, 1)
13 plt.scatter(X[:, 0], X[:, 1], c=db.labels_, alpha=0.7)
14 plt.title("Clustered by DBSCAN")
15 plt.subplot(1, 2, 2)
16 plt.scatter(X[:, 0], X[:, 1], c=my_db.labels_, alpha=0.7)
17 plt.title("Clustered by MyDBSCAN")
18 plt.tight_layout()
19 plt.show()
20
21 if __name__ == '__main__':
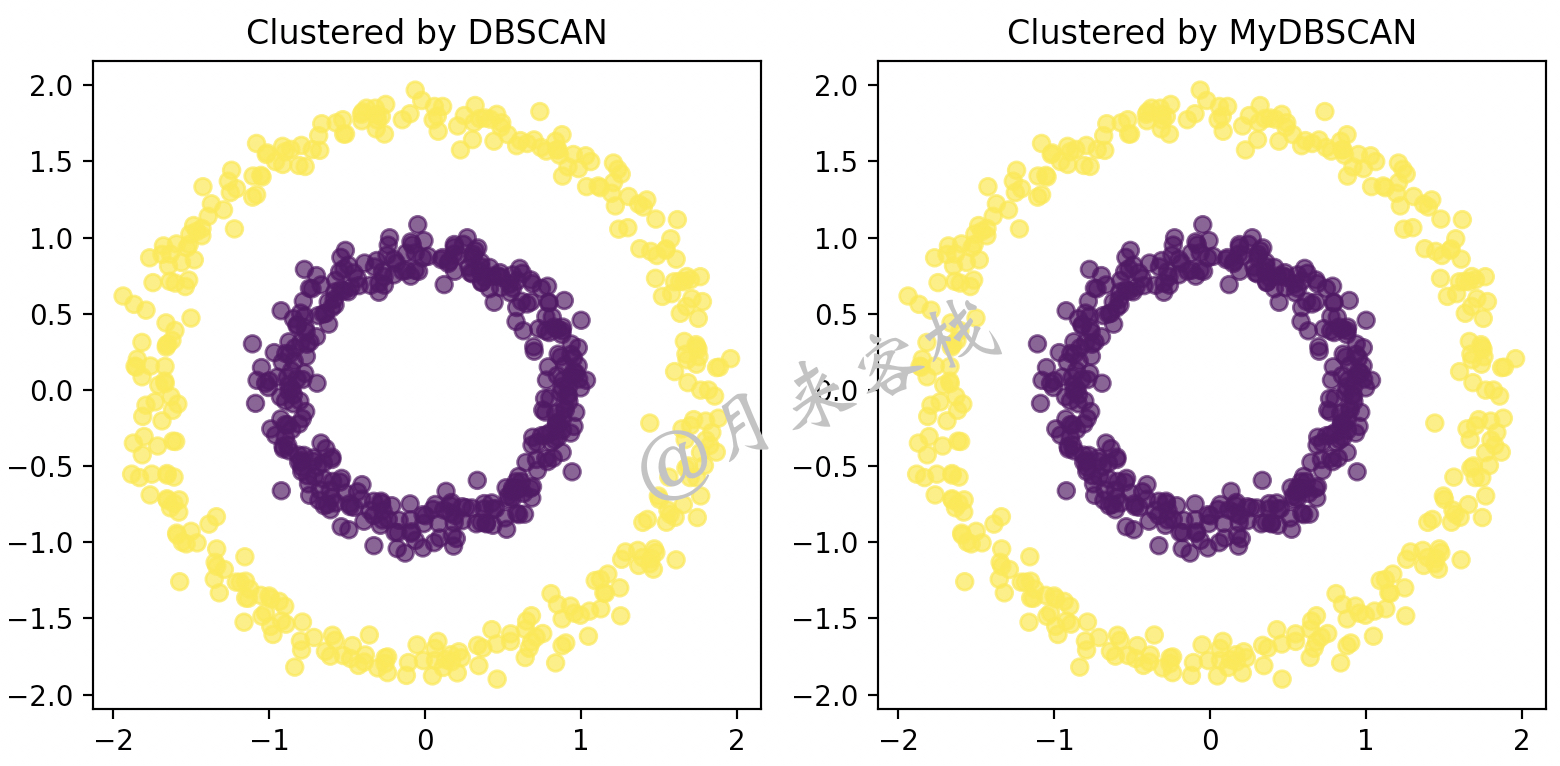
22 test_circle_dbscan() 在上述代码中,第3~4行用来构造数据集并进行标准化;第5-9行是分别用sklearn中的DBSCAN算法和上面实现的MyDBSCAN做对比;第12~19行则是对两者预测后的结果进行可视化。
在上述代码运行结束后将会得到如下所示的输出结果:
1 DBSCAN: 1.0
2 计算每个样本点周围的样本花费时间为:31.7s
3 对每个样本点进行簇划分花费的时间为0.0136s
4 MyDBSCAN: 聚类结果兰德系数为: 1.0根据上述结果可以发现,DBSCAN和MyDBSCAN在调整兰德系数这一指标上的结果没有任何区别,同时还可以发现MyDBSCAN算法在聚类过程中主要时间都花费在了第1步计算核心样本上了。进一步,根据聚类标签还可以得到如图11-29所示的可视化结果。
11.10.9 小结#
在本节内容中,我们首先通过一个引例介绍了传统基于Kmeans框架聚类算法的不足之处,并一步步引出了基于密度的聚类算法DBSCAN的思想;然后介绍了如何借助sklearn来完成DBSCAN的建模过程;进一步详细介绍了DBSCAN算法的核心概念和基本原理,还通过一个实际的计算示例来进一步介绍了DBSCAN算法的整个聚类过程;最后,我们一步步地介绍了DBSCAN算法的实现过程,并通过一个实际的示例来介绍了DBSCAN算法的使用方式。在下一节内容中我们将介绍另外一种也是本章的最后一个聚类算法——层次聚类算法。
引用#
[1] https://en.wikipedia.org/wiki/DBSCAN
[2] Ester M, Kriegel H P, Sander J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]//kdd. 1996, 96(34): 226-231.
[3] https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
[4] https://scikit-learn.org/stable/modules/clustering.html#dbscan