9.4 GloVe词向量#
在「第9.2节 Word2Vec原理:词向量训练与语义表示方法」内容中,我们详细介绍了Word2Vec中两训练词向量的模型CBOW和Skip-gram背后的思想与原理,即在固定窗口中通过中心词来预测上下文或上下文来预测中心词的思想来捕捉词与词之间的语义关系,从而学习得到词的向量表示。在接下来的这节内容中,我们将会介绍另外一种同时考虑全局信息的词向量模型。
9.4.1 GloVe动机#
由CBOW和Skip-gram这两种模型的原理可知,本质上它们都是通过固定窗口中的局部上下文信息来学词的全局向量表示,即没有考虑到词在整个语料中的全局信息对最终词向量的影响。对于一个庞大的语料来说,如果两个词频繁地出现在同一个上下文环境中,那么则说明这两个词具有更强的关联程度,因此模型在训练词向量的过程中就应该需要将这部分信息考虑进去。
基于这样的动机,斯坦福大学彭宁顿(Pennington)[1]等人于2014年提出了一种基于全局角度考虑词与词之间共现信息的词向量训练方法—— 全局向量的词嵌入( Global Vectors for Word Representation, GloVe)。GloVe模型的核心思想是首先通过全局共现矩阵(Co-occurrence Matrix)来统计词与词之间在不同上下文环境中的共现频次,然后再将其作用于原有的条件概率中来调整词向量的关联程度,从而辅以全局的角度来捕捉词与词之间的语义关系。
9.4.2 共现矩阵#
在建模GloVe模型时整个过程大致可以分为两步:首先根据训练语料计算得到共现矩阵$X$;然后再将模型的预测值同贡献矩阵进行损失计算进而训练得到包含全局统计信息的词向量。下面开始先对共现矩阵进行介绍。
共现矩阵是一个对称方阵,其大小为词表中所有词的总数,矩阵中的每个元素表示两个词在上下文中共同出现的次数。具体地,设$X$表示共现矩阵,则$X_{ij}$表示在所有文档中词$w_j$出现在词$w_i$的上下文环境中的次数,$X_i=\sum_{k}X_{ik}$表示所有词出现在词$w_i$上下文环境中的总次数。最后,在词$w_i$的上下文环境中词$w_j$出现的概率可以定义为
$$ P_{ij}=P(w_j|w_i)=\frac{X_{ij}}{X_i}\tag{9-15} $$进一步,为了构建共现矩阵首先需要定义一个窗口来考虑词$w_i$的上下文范围;然后再遍历语料库中的每个句子,并针对每个词$w_j$将词$w_i$上下文窗口内的其它词与$w_j$进行比较,如果与$w_j$相同则$X_{ij}$的值加一。
假定现在有如下3条语料:
1 I like deep learning.
2 I like NLP.
3 I enjoy flying.根据上述语料可以构造得到词表
1 vocab = ['I','like', 'enjoy', 'deep', 'learning', 'NLP', 'flying', '.']此时假定窗口长度$m=1$,则最后便可以得到如下共现矩阵$X_{8\times8}$
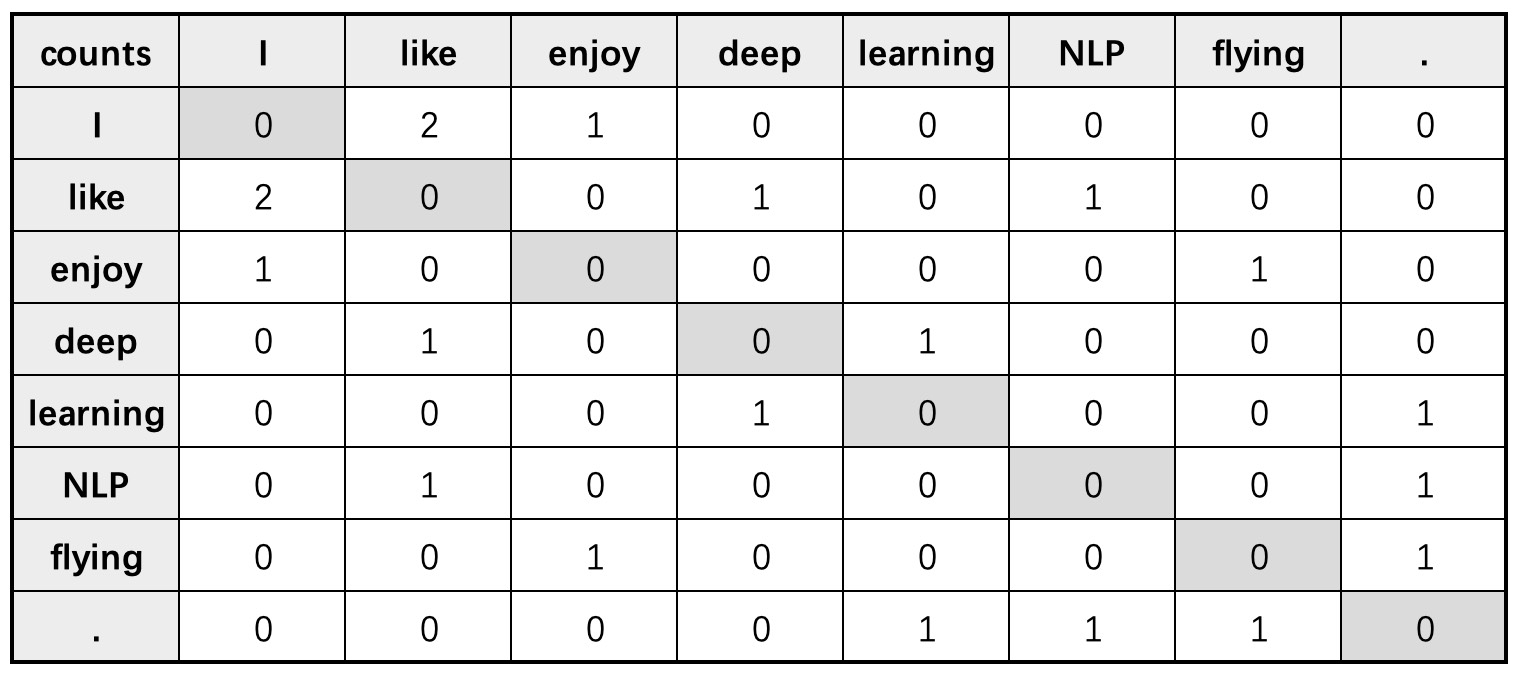
在图9-10中,第0行第1列(忽略表头)中2的含义为词’like’出现在词’I’的上下文环境中的次数为2,即第1条和第2条语料中的’I like’;同理,第0行第2列中1的含义为词’enjoy’出现在词’I’的上下文环境中的次数为1,即第3条语料中的’I enjoy’;第1行第0列中2的含义为词’I’出现在词’like’的上下文环境中的次数为2,即第1条语料中的’I like deep’和第2条语料中的’I like NLP’。
从共现矩阵的构建过程可以看出,共现矩阵能够有效地对词$w_j$所处词$w_i$上下文环境的情况进行量化,即$X_{ij}$越大则表示词$w_j$出现在词$w_i$的上下文中越频繁,词$w_j$与词$w_i$联系程度越紧密。同时,共现矩阵$X$的对角线全为0也表示在正常情况下同一个词不可能连续出现两次。
根据图9-10中的共现矩阵和式(9-15)可以进一步计算得到共现矩阵对应的条件概率分布
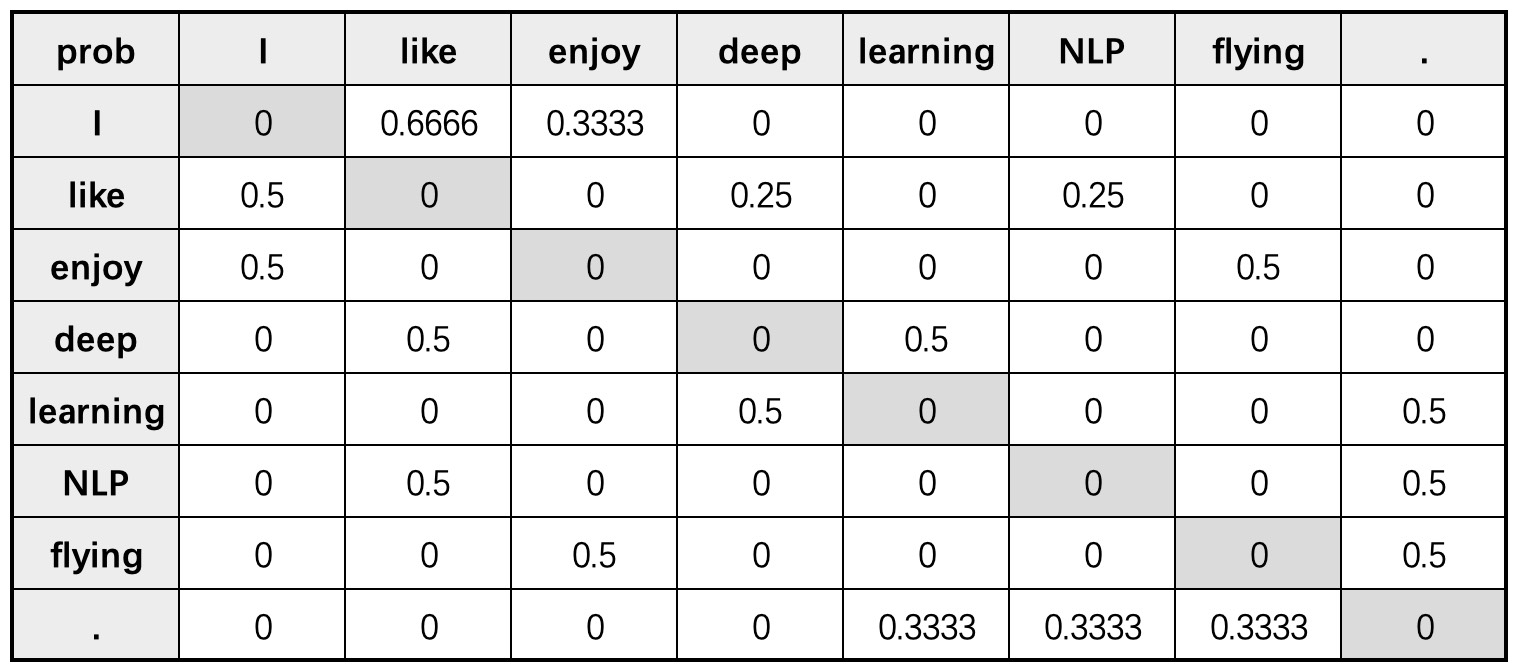
从图9-11可以得出,词’enjoy’出现在词’I’的上下文中的概率为0.3333;词’deep’出现在词’like’的上下文中的概率为0.25。
9.4.3 GloVe原理#
1. GloVe思想
根据「第9.4.2节 Word2Vec原理:词向量训练与语义表示方法」内容我们知道了共现矩阵$X$的基本原理以及如何将计算得到对应的上下文条件矩阵概率$P$。下面我们通过一个简单的示例来介绍GloVe模型背后的思想。
![图9-12 共现矩阵条件概率图[1]](https://mlwithme.oss-cn-shanghai.aliyuncs.com/images/dl/230716155517.jpg)
如图9-12所示是大语料下部分词所出现的条件概率及相应的比值结果,例如对于第1列中$1.9\times10^{-4}$来说它表示在词’ice’的上线文环境中词’solid’出现的概率,$2.2\times10^{-5}$表示在词’steam’的上线文环境中词’solid’出现的概率,而8.9则表示前者比后者的比值。在构建GloVe模型时,作者认为:
①如果词$k$与词$i$相关而与词$j$不太相关,那么$P(k|i)/P(k|j)$就应该有更大的共现比率值,例如图9-12中的第1列;
②如果词$k$与词$i$不太相关而与词$j$相关,那么$P(k|i)/P(k|j)$就应该有更小的共现比率值,例如图9-12中的第2列;
③如果词$k$与词$i$和词$j$均相关,那么$P(k|i)/P(k|j)$就应该有接近于1的共现比率值,例如图9-12中的第3、4两列。
因此作者认为共现概率之间的比值能够很好的反映语料中词与词之间的关系,利用这一关系便能够构建得到GloVe模型。根据共现比率的计算过程$P_{ik}/P_{ij}$可知此时一共涉及到$i,j,k$这3个词。假定$w_i,w_j,w_k$分别表示这3个词对应的词向量,那么共现比率可以建模为
$$ F(w_i,w_j,w_k)=\frac{P_{ik}}{P_{jk}}\tag{9-16} $$而GloVe模型要做的便是根据式(9-16)这个等式的关系来构建目标函数并优化得到每个词对应的词向量表示,同时下一步需要完成的便是找到$F(\cdot)$背后可能的一个函数表达式。
2. 目标函数
对于GloVe目标函数的构建过程首先需要明白一点的是共现矩阵是通过语料统计得到的结果,而GloVe算法的设计思路则是将共现矩阵作为目标值进行优化,使得通过模型训练得到的词向量经过运算也能够反映式(9-16)所表达的含义。
由于词嵌入空间的向量之间都是线性关系,因此向量之间的差异也可以通过作差来进行表示,所以式(9-16)可改写为
$$ F(w_i-w_j,w_k)=\frac{P_{ik}}{P_{jk}}\tag{9-17} $$同时,式(9-17)的右侧为一个标量,而要想左侧两个向量运算得到的结果也是标量,一个自然而然的方法就是两个向量进行内积运算。进一步式(9-17)可以改写为
$$ F((w_i-w_j)^Tw_k)=F(w^T_iw_k-w_j^Tw_k)=\frac{P_{ik}}{P_{jk}}\tag{9-18} $$根据式(9-18)将可以发现,如果$F(\cdot)=e^x$那么便可以合理的将向量内积运算与共现比率联系起来,即式(9-18)可以改写为
$$ F(w^T_iw_k-w_j^Tw_k)=\frac{\exp{(w^T_iw_k)}}{\exp{(w^T_jw_k)}}=\frac{P_{ik}}{P_{jk}}\tag{9-19} $$进一步,由式(9-15)和式(9-19)可得
$$ w^T_iw_k=\log{P_{ik}}=\log{P(w_k|w_i)}=\log{\frac{X_{ik}}{X_i}}=\log{X_{ik}}-\log{X_i}\tag{9-20} $$在有了式(9-20)之后GloVe对应的目标函数就算是呼之欲出了,不过式(9-20)还有一个不足之处,那就是$\log{X_i}$破坏了整个式子的对称性,即$\log{X_{ik}}-\log{X_i}\neq\log{X_{ki}}-\log{X_k}$。因为在实际建模过程中等式(9-20)左侧$w_i$和$w_k$的内积并不受两者顺序的影响,因此也需要右侧具有同样的性质。所以,可以将式(9-20)中的$\log{X_i}$通过一个可训练的偏置$b_i$来进行代替,同时为了满足对称性需要再加一个偏置$b_k$,即此时根据式(9-20)有
$$ w^T_iw_k\approx\log{X_{ik}}-b_i-b_k\tag{9-21} $$此时,根据式(9-21)便可以初步得到GloVe模型需要求解的目标函数,即
$$ J=\sum_{i=0}^{|\mathcal{V}|-1}\sum_{k=0}^{|\mathcal{V}|-1}\left(w^T_iw_k+b_i+b_k-\log{X_{ik}}\right)^2\tag{9-22} $$其中$|\mathcal{V}|$表示词表的长度。
从式(9-22)可以看出,前面3项相当于模型的预测值,而第4项则相当于模型的真实值,最终通过最小二乘法来衡量模型的误差。此时可以发现,GloVe模型本质上是基于共现比率的思想来构造得到一个合理的目标函数使得求解得到的模型参数,即词向量,能够反过来通过向量运算表示共现比率,因此GloVe建模得到的词向量被称为全局向量。
虽然式(9-22)可以作为GloVe模型的目标函数,但是它还存在有一个明显的缺陷,那就是它等权的看待任意两个词的共现情况。从常识来看,两个词共现的次数越多那么它对目标函数影响就应该越大,所以可以根据两个词的共现次数再设计一个权重项来对式(9-22)进行加权,因此式(9-22)可以改写为
$$ J=\sum_{i=0}^{|\mathcal{V}|-1}\sum_{k=0}^{|\mathcal{V}|-1}f\left(X_{ik}\right)\left(w^T_iw_k+b_i+b_k-\log{X_{ik}}\right)^2\tag{9-23} $$其中权重函数$f(x)$应该满足以下3条性质
①如两个词没有共现情况,那么$f(0)=0$;
②$f(x)$为非递减函数,即$f(x)$随着共现次数的递增不会出现递减的情况(保存递增或不变);
③$f(x)$不能随着$x$的递增而一直递增,因为语料中可能会存在大量无意义的共现情况。
基于上述3条性质,$f(x)$的一种可能情况为
$$ f(x)= \begin{cases} (\frac{x}{x_{max}})^{\alpha}&\text{if }x < x_{max}\\[2ex] 1&\text{otherwise.} \end{cases}\tag{9-24} $$以上便是GloVe模型目标函数的构建过程,同时在论文中作者经过实验发现当出$x_{max}=100$和$\alpha=0.75$时能够获得较好的结果。
9.4.4 GloVe词向量使用#
在介绍完整个GloVe模型的原理之后我们再来看如何使用GloVe模型训练生成的词向量。我们可以在斯坦福自然语言处理的官方网站[4]找到GloVe开源的词向量模型,包括由维基百科、推特和Common Crawl网页数据等。这里以glove.6b.zip为例,它是以维基百科为语料训练而来,整个语料包含有近60亿单词,词表长度近40万。该文件解压后有4个词向量模型,分别是glove.6B.50d.txt、glove.6B.100d.txt、glove.6B.200d.txt和glove.6B.300d.txt,即50维度、100维、200维和300维的词向量。
进一步,可以借助Gensim中的glove2word2vec载入上述词向量模型,示例代码如下所示:
1 from gensim.scripts.glove2word2vec import glove2word2vec
2
3 def load_glove_6b50():
4 glove_path = os.path.join(DATA_HOME, 'Pretrained', 'glove6b', 'glove.6B.50d.txt')
5 glove_word2vec_path = os.path.join(DATA_HOME, 'Pretrained', 'glove6b',
6 'glove.6B.50d.word2vec.txt')
7 if not os.path.exists(glove_word2vec_path):
8 glove2word2vec(glove_path, glove_word2vec_path)
9 model = KeyedVectors.load_word2vec_format(glove_word2vec_path)
10 logging.info(f"china: {model['china']}")
11 sim_words = model.most_similar(['china'], topn=5)
12 logging.info(f"与china最相似的前5个词为:{sim_words}")在上述代码中,第1行glove2word2vec模块用于将GloVe格式的词向量模型转换为Word2Vec对应的保存格式,即后者在保存时比前者多了一行用于记录词向量个数和维度的信息。第4~5行分别用于构造glove.6B.50d模型的路径和转换后的保存路径。第7~8行用于判断是否存在转换后的模型。第9~12行则是在「第9.3节 Word2Vec训练与使用:CBOW、Skip-gram 与词向量应用」中介绍到的词向量使用方法。
上述代码运行结束后的输出结果类似如下:
1 china: [-0.22427 0.27427 0.054742 1.4692 0.061821 -0.51894 ......
2 [('taiwan', 0.936076), ('chinese', 0.895724), ('beijing', 0.892087),
('mainland', 0.864479), ('japan', 0.842884)]9.4.5 小结#
在本节内容中,我们首先介绍了GloVe模型出现的动机;然后详细介绍了共现矩阵的思想和原理,即通过两个词在整个语料中的共现频次来考虑词向量的生成过程;最后一步一步介绍了GloVe模型的原理和构建过程,并同时介绍了如何借助Gensim来使用预训练的GloVe词向量模型。
引用#
[1] Pennington J, Socher R, Manning C. GloVe: Global Vectors for Word Representation[C]. In Proceedings of the 2014 Conference on EMNLP, 2014, 1532–1543.
[2] Natural Language Processing with Deep Learning, Stanford CS224n, Winter 2022.
[3] 阿斯顿·张、李沐、扎卡里 C. 立顿等,动手学深度学习[M],2版. 北京:人民邮电出版社, 2019.
[4] https://nlp.stanford.edu/projects/glove/