11.5 Kmeans++聚类算法#
在前面几节内容中,我们介绍了什么是聚类算法,并且还介绍了聚类算法中应用最为广泛的Kmeans聚类算法。从Kmeans聚类算法的原理可知,Kmeans在正式聚类之前首先需要完成的就是初始化K个簇中心。同时,也正是因为这个原因使Kmeans聚类算法存在着一个巨大的缺陷——收敛情况严重依赖于簇中心的初始化状况。试想一下,如果在初始化过程中很不巧地将K个(或大多数)簇中心都初始化到同一个簇中,则在这种情况下Kmeans聚类算法很大程度上都不会收敛到全局最优解。也就是说,当簇中心初始化的位置不合适时,聚类结果将会出现严重错误。在本节内容中我们将介绍一种基于Kmeans聚类算法改进而来的Kmeans++聚类算法,其学习路线如图11-6所示。
11.5.1 Kmeans++算法思想#
如图11-7所示的聚类过程仍旧是通过Kmeans聚类算法在11.2节中所用到的人造数据集上得到的聚类结果。只不过不同的是在进行聚类时人为地将3个簇中心初始化到同一个簇中了。在图11-7中,iter=0表示未开始聚类前根据每个样本的真实簇标签所展示的结果,其中蓝色、绿色和橙色分别表示3个簇的分布情况,而3个黑色圆点为初始化的簇中心。从图11-7中可以发现,Kmeans在进行完第10次迭代后,将最上面的1个簇划分为了2个簇,将下面的2个簇划分成了1个簇。同时,当进行完第30次迭代后,可以发现算法已经开始收敛,但后续簇中心却没有发生任何变化,因此最终的结果仍旧是将上面1个簇分为2个簇,将下面的2个簇划分为1个簇。
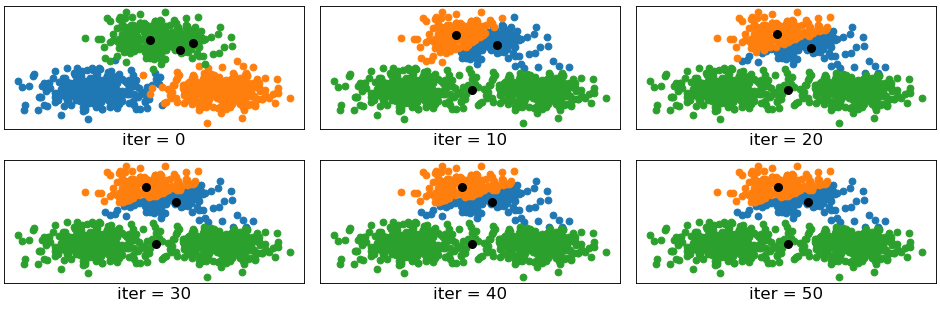
通过上面这个例子可以知道,初始簇中心的位置会严重影响Kmeans聚类算法的最终结果。对于这种情况,该怎样在最大程度上避免呢?此时就要轮到Kmeans++算法出场了。
从整体上看Kmeans++聚类算法同Kmeans聚类算法一致,唯一的区别在于初始簇中心的选择上。在Kmeans++聚类算法中,对于初始簇中心的选择是逐一进行的,并且每次在选择当前簇中心时都会选择离已有簇中心尽可能远的样本的作为簇中心,以此来避免所有簇中心出现在同一个簇中的情况。同时,在sklearn中只需要在实例化时指定对应的初始化方法,即KMeans(n_clusters=K,init='k-means++'),便可使用Kmeans++聚类算法,使用示例这里就不再赘述。
11.5.2 Kmeans++算法原理#
Kmeans++[1]仅从名字也可以看出它是Kmeans聚类算法的改进版。一言以蔽之,Kmeans++算法仅仅在初始化簇中心的方式上做了改进,其他地方同Kmeans聚类算法一样。将Kmeans++在初始化簇中心时的方法总结成一句话就是: 逐个选取K个簇中心,并且离其他簇中心越远的样本点越有可能被选为下一个簇中心。其具体做法如下:
(1) 从数据集$X$中随机(均匀分布)选取一个样本点作为第1个初始聚类中心$c_1$。
(2) 接着计算每个样本点$x\in X$与当前已有聚类中心之间的最短距离,并用$D(x)$表示,然后计算每个样本点${{x}^{\prime }}\in X$被选为下一个聚类中心的概率,并选择最大概率值所对应的样本点作为下一个簇中心$c_i$。
$$ {{c}_{i}}=\underset{{{x}^{\prime }}}{\mathop{\arg \max }}\,\frac{D{{({{x}^{\prime }})}^{2}}}{\sum\limits_{x\in X}{D}{{(x)}^{2}}}\tag{11-6} $$(3) 重复第(2)步,直到选择出K个聚类中心。
从式(11-6)可以看出,整个选择过程是先计算每个样本到各个簇的最小距离,然后选择所有最小距离中的最大距离,即先求最小化再求最大化,有点类似于SVM中的思想。同时,因为分母为一个常数所以在实际计算时并不用计算这个概率,只需计算距离即可,即距离现有簇中心越远的样本点越可能被选为下一个簇中心。
11.5.3 Kmeans++计算示例#
在上面的内容中我们已经介绍了Kmeans++聚类算法在初始化簇中心时的具体步骤,不过,为了能够使读者理解得更加清楚,下面我们就通过一个例子来实际演示一下簇中心的选择过程。
如图11-8所示为一个人为制作的模拟数据集,可以很明显地看出该数据集一共包含3个簇,这就意味着在聚类之前需要初始化3个簇中心。现在假设Kmeans++算法第1步选择的是将7号样本点(1,2)作为第1个初始聚类簇中心,那么在进行第2个簇中心的查找时就需要计算所有样本点到7号样本点的距离。
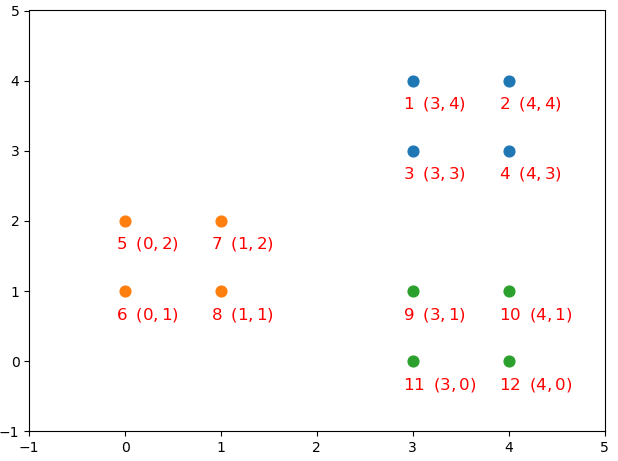
根据计算可得到7号样本点到其它所有样本点的距离,如表11-1所示。

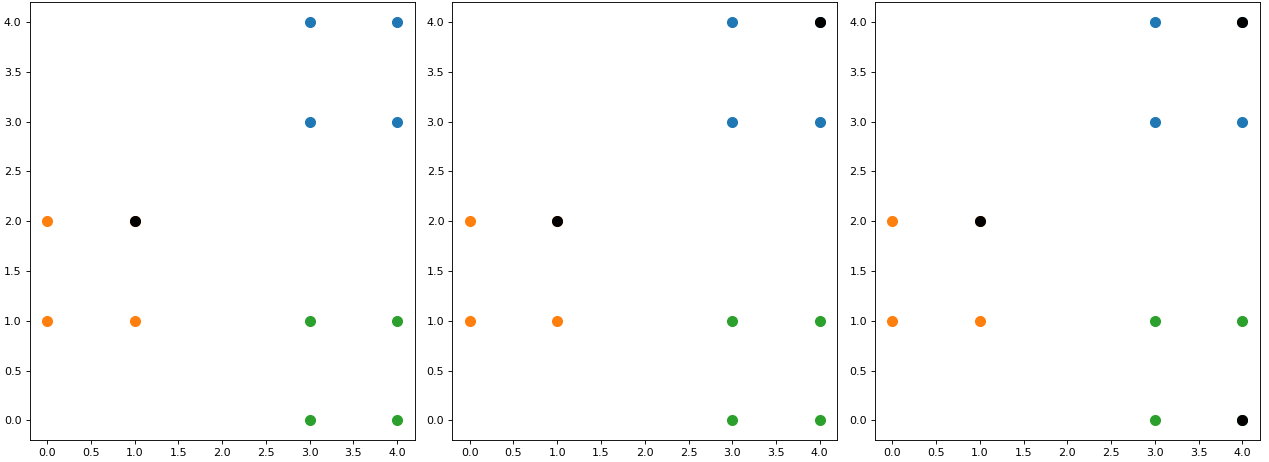
从表11-1中的结果可以看出,离7号样本点最远的是2号和12号样本点(当然从图11-8中也可以看出),因此Kmeans++就会选择2号(也可以是12号)样本点为下一个聚类中心。接着,再次重复步骤(2)又可以得到如表11-2所示的结果。

从表11-2中的结果可以看出,同时离2号和7号样本点最远的是12号样本点,所以Kmeans++算法选择的下一个簇中心为12号样本点。进一步,可以得到如图11-9所示的可视化结果。
从图11-9可以看出,Kmeans++算法在每次选择簇中心时,离当前已有簇中心越远的样本点越可能被选中,即作为下一个簇中心,从而避免所有簇中心出现在同一个簇中的情况。
至此,对于Kmeans++算法的簇中心选择原理就介绍完了。接下来再来介绍如何通过Python编码实现这一个过程。
11.5.4 从零实现Kmeans++聚类算法#
由于Kmeans++算法仅仅在簇中心初始化方法上做了改变,因此只需重写Kmeans中簇中心初始化函数即可,完整示例代码可参见 AllBooKCode/Chapter11/C07_kmeanspp.py 文件,示例代码如下:
1 def InitialCentroid(x, K):
2 c0_idx = int(np.random.uniform(0, len(x)))
3 centroid = x[c0_idx].reshape(1, -1)
4 k, n = 1, x.shape[0]
5 while k < K:
6 d2 = []
7 for i in range(n):
8 subs = centroid - x[i, :]
9 dimension2 = np.power(subs, 2)
10 dimension_s = np.sum(dimension2, axis=1)
11 d2.append(np.min(dimension_s))
12 # new_c_idx = np.argmax(d2) # 方法一
13 prob = np.array(d2) / np.sum(np.array(d2)) # 方法二
14 new_c_idx = np.random.choice(n, p=prob)
15 centroid = np.vstack([centroid, x[new_c_idx]])
16 k += 1
17 return centroid在上述代码中,第2~3行用来随机从数据集中取第1个簇中心。第7~11行用来遍历每个样本点到当前已有簇中心的距离,并选择其中的最短距离进行保存。第12行是选择当前样本中距离已有簇中心最远的样本点作为下一个簇中心。第13~14行则是另外一种依据概率分布进行采样选择的方法,距离越远越有可能被选中作为下一个簇中心。第12行和13~14行分别对应着两种不同的方法,可以根据需要进行选择。第15行则是将新得到的簇中心添加到已有簇中心中。在实现完这部分代码后,便可以同Kmeans算法中已有的代码组合,以此得到Kmeans++算法的实现代码。
最终,如果再次将第11.2节中的人造模拟数据以Kmeans++算法进行聚类,则可以得到如图11-10所示的可视化结果。
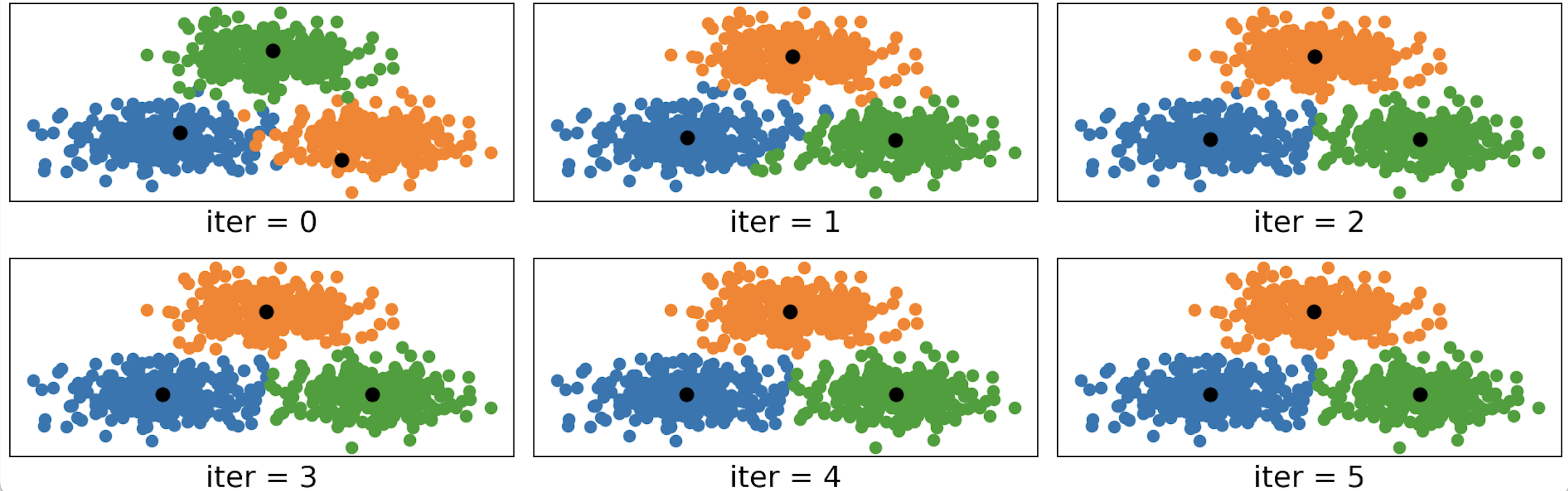
从图11-10中可以明显看到,在初始化的簇中心结果中各个簇中心彼此相距得都十分远,从而不可能再发生初始簇中心都在同一个簇中的情况,因此就更不会出现图11-7中的情况。到此,对于整个Kmeans++聚类算法的原理就介绍完了。
11.5.5 小结#
在本节中,我们首先介绍了Kmeans聚类算法在初始化簇中心时的弊端,并以图示的方式进行了说明; 接着介绍了Kmeans++聚类算法的核心思想,即逐一对簇中心进行选择,并且下一个簇中心要离当前已有簇中心尽可能远;最后详细介绍了Kmeans++聚类算法的原理和计算过程,以及如何通过Python编码实现Kmeans++算法中的簇中心初始化方法,同时还对聚类结果进行了可视化。在下一节内容中我们将开始介绍聚类算法中的第一种评价指标。
引用#
[1] Arthur D,Vassilvitskii S.kmeans++: The advantages of careful seeding[R]. Stanford,2006.