8.3 CNN-RNN网络#
在前面两节内容中,我们分别介绍了通过CNN和RNN来对文本数据进行特征提取的建模方法,前者是从序列局部的角度来捕捉文本序列前后之间的依赖关系,而后者则是利用了RNN固有的特性来对序列数据进行特征提取。总的来说两者各有优势,在提取特征方面有不同的侧重点,因此把CNN和RNN模型进行组合也成为了一种非常流行的做法[1] [2] [3] [4] [5] [6]。
在本节内容中我们将会详细介绍两种以CNN和RNN为基础模块的CNN-RNN模型,即:①以先CNN再RNN的顺序对时序数据进行特征提取[1] [2];②以先RNN再CNN的顺序进行[3] [4] [5]。
8.3.1 C-LSTM结构#
从名字也可以看出C-LSTM模型是以先CNN再RNN的顺序对时序数据进行特征提取。C-LSTM模型的核心思想在于先利用CNN局部特征提取的能力来抽取文本中短语粒度的特征表示,然后再利用LSTM对卷积后的特征图进行时序上的语义理解,最后得到整个文本的特征表示[1]。如图8-3所示便是C-LSTM模型对应的网络结构图。
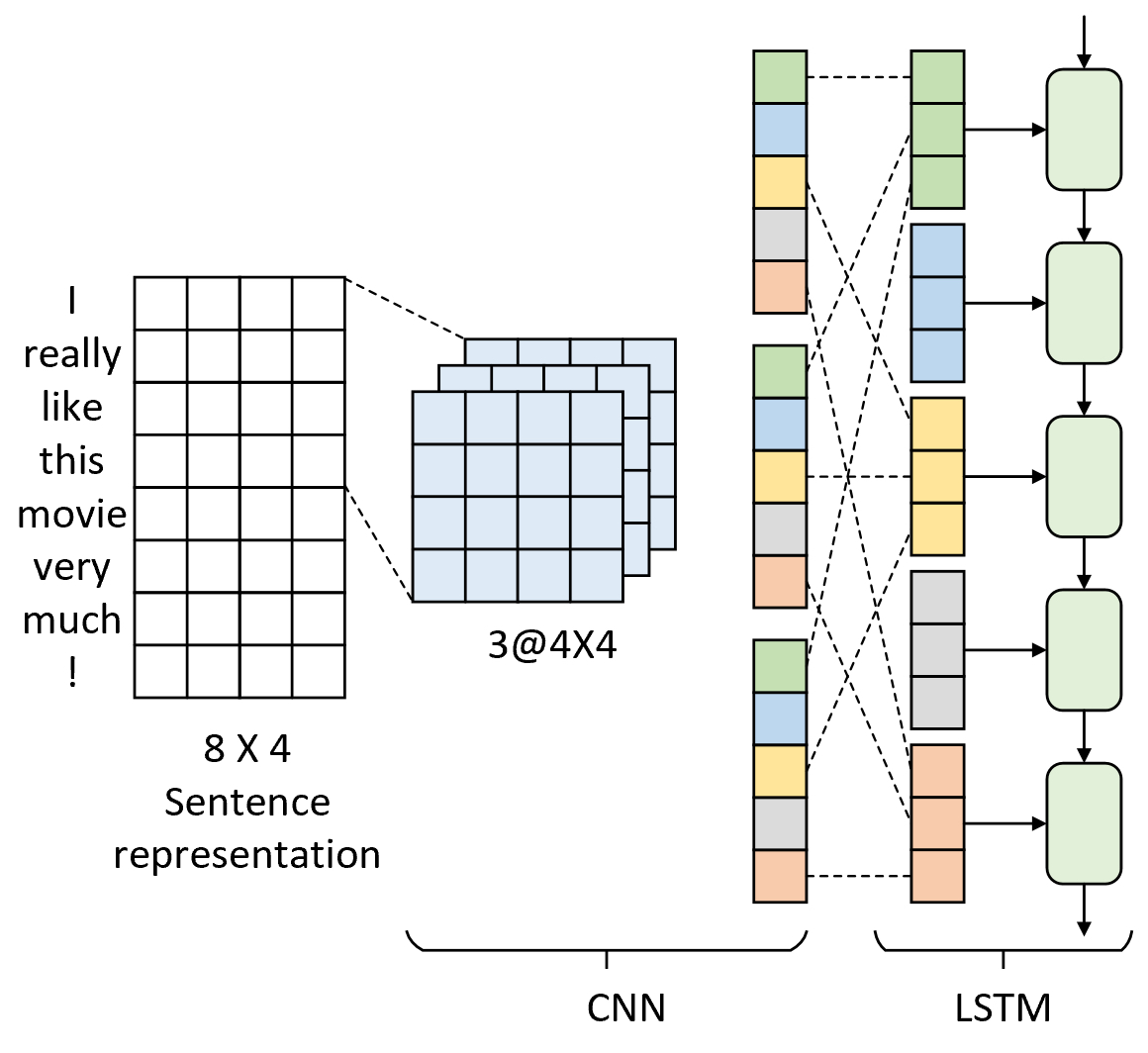
如图8-3所示,最左侧为一个$8\times4$的特征矩阵,其含义同「第8.1.1节 TextCNN文本分类:卷积神经网络做文本建模」中的一致,这里不再赘述。进一步,C-LSTM模型采用了多卷积核卷积对其进行局部特征提取,这可以看作是短语层面的语义信息。此时得到的特征图有两方面的含义:①对于特征图的每一行(即每次卷积窗口滑动后计算得到的结果)来说它表示的仍旧是具有前后时序关系的序列特征,只是获得的更大粒度的语义信息;②对于特征图的每个通道来说可以看作是同一时刻多个维度的语义信息。因此,C-LSTM模型最后会对卷积后的结果进行重构并作为LSTM的输入进行时序上的特征提取。
除此之外,类似的还有CNN-LSTM模型[2],其结构整体上与C-LSTM类似,仅仅只是在CNN处理后还加入了一个特定的池化层。
8.3.2 C-LSTM实现#
在清楚C-LSTM模型的相关原理后,我们再来看如何借助PyTorch实现该模型。 以下完整示例代码可以参见Code/Chapter08/C03_CLSTM/CLSTM.py文件。
1. 前向传播
首先实现模型的整个前向传播过程。从图8-3可知,整个模型整体分为4个大的部分,词嵌入层、卷积层和循环神经网络层以及后续的分类层,实现代码如下所示:
1 class CLSTM(nn.Module):
2 def __init__(self, config):
3 super(CLSTM, self).__init__()
4 if config.cell_type == 'RNN':
5 rnn_cell = nn.RNN
6 elif config.cell_type == 'LSTM':
7 rnn_cell = nn.LSTM
8 elif config.cell_type == 'GRU':
9 rnn_cell = nn.GRU
10 else:
11 raise ValueError("Unrecognized RNN cell type: " + config.cell_type)
12 out_hidden_size = config.hidden_size * (int(config.bidirectional) + 1)
13 self.config = config
14 self.token_embedding = nn.Embedding(config.vocab_size, config.embedding_size)
15 self.conv = nn.Conv2d(1, config.out_channels,
16 kernel_size=(config.window_size, config.embedding_size))
17 self.rnn = rnn_cell(config.out_channels, config.hidden_size, config.num_layers,
18 batch_first=True, bidirectional=config.bidirectional)
19 self.classifier = nn.Sequential(nn.Linear(out_hidden_size, config.num_classes))在上述代码中,第4~11行是根据对应的参数返回相应的循环记忆单元。第12行是计算循环神经网络输出结的维度,即在双向结构中该维度为单向结构的2倍,具体可参见「第7.5.3节 BiRNN原理:双向循环神经网络如何建模上下文」内容。第14行是实例化得到一个词嵌入层。第15~16行是实例化得到一个卷积层。第17~18行是根据对应参数实例化得到循环记忆单元。第19行则是由一个全连接构成的分类层。
进一步,整个前向传播计算过程的示例代码如下所示:
1 def forward(self, x, labels=None):
2 x = self.token_embedding(x)
3 x = torch.unsqueeze(x, dim=1)
4 feature_maps = self.conv(x).squeeze(-1)
5 feature_maps = feature_maps.transpose(1, 2)
6 x, _ = self.rnn(feature_maps)
7 if self.config.cat_type == 'last':
8 x = x[:, -1]
9 elif self.config.cat_type == 'mean':
10 x = torch.mean(x, dim=1)
11 elif self.config.cat_type == 'sum':
12 x = torch.sum(x, dim=1)
13 else:
14 raise ValueError("Unrecognized cat_type: " + self.cat_type)
15 logits = self.classifier(x)
16 if labels is not None:
17 loss_fct = nn.CrossEntropyLoss(reduction='mean')
18 loss = loss_fct(logits, labels)
19 return loss, logits
20 else:
21 return logits在上述代码中,第2行是词嵌入层的输出结果,形状为[batch_size, src_len, embedding_size]。第3行是进行维度扩展以满足卷积层的输出格式,处理后的形状为[batch_size, 1, src_len, embedding_size]。第4行则是卷积层处理后的结果,形状为[batch_size, out_channels, src_len-window_size+1],此时最后一个维度才具有时序关系,因此需要对其进行交换。第5行便是维度交换后的结果,形状为[batch_size, src_len-window_size+1, out_channels]。第6行是RNN计算后的输出结果,形状为[batch_size, src_len, out_hidden_size]。第7~14行是根据不同的组合方式对循环神经网络的输出结果进行组合,形状为[batch_size, out_hidden_size]。第15行则是最后的分类层,输出结果形状为[batch_size, num_classes]。第16~21行则是根据条件返回对应的处理结果。
最后,可以通过如下方式来进行使用
1 class ModelConfig(object):
2 def __init__(self):
3 self.num_classes = 15
4 self.vocab_size = 8
5 self.embedding_size = 16
6 self.out_channels = 32
7 self.window_size = 3
8 self.hidden_size = 128
9 self.num_layers = 1
10 self.cell_type = 'LSTM'
11 self.bidirectional = False
12 self.cat_type = 'last'
13
14 if __name__ == '__main__':
15 config = ModelConfig()
16 model = CLSTM(config)
17 x = torch.randint(0, config.vocab_size, [2, 10], dtype=torch.long)
18 label = torch.randint(0, config.num_classes, [2], dtype=torch.long)
19 loss, logits = model(x, label)
20 print(logits.shape) # torch.Size([2, 15])在上述代码中,第1~12行参数配置定义类。第15~16行是分别实例化参数配置类和模型。第17~18在是构造输入和标签。第19~20便是模型的输出结果。
2. 模型训练
由于这部分代码在之前也已经多次介绍过,因此这里也不再赘述,各位读者直接参考源码即可。最后,在对网络模型进行训练时将会得到类似如下的输出结果:
1 Epochs[1/50]--batch[0/1047]--Acc: 0.0781--loss: 2.7171
2 Epochs[1/50]--batch[50/2093]--Acc: 0.1289--loss: 2.5839
3 Epochs[1/50]--batch[100/2093]--Acc: 0.0859--loss: 2.5997
4 Epochs[1/50]--batch[150/2093]--Acc: 0.1016--loss: 2.5939
5 Epochs[1/50]--batch[200/2093]--Acc: 0.1211--loss: 2.5879
6 Epochs[1/50]--batch[250/2093]--Acc: 0.1602--loss: 2.5488
7 Epochs[1/50]--batch[300/2093]--Acc: 0.1836--loss: 2.5344
8 Epochs[1/50]--batch[350/2093]--Acc: 0.2383--loss: 2.3362
9 Epochs[1/50]--Acc on val 0.7589
10 Epochs[8/50]--Acc on val 0.8414从上述结果可知,模型大约在迭代8轮之后在验证集上的准确率大约在$84\%$左右。
8.3.3 BiLSTM-CNN结构#
在介绍完C-LSTM模型的相关原理后我们再来看一个先使用RNN再使用CNN进行建模的BiLSTM-CNN模型[3]。BiLSTM-CNN模型的核心思想在于先利用双向LSTM来抽取文本在时序上的特征属性,然后再利用CNN来抽取局部的重要信息作为整个文本的向量表示并完成后续分类任务。如图8-4所示便是BiLSTM-CNN模型对应的网络结构图。
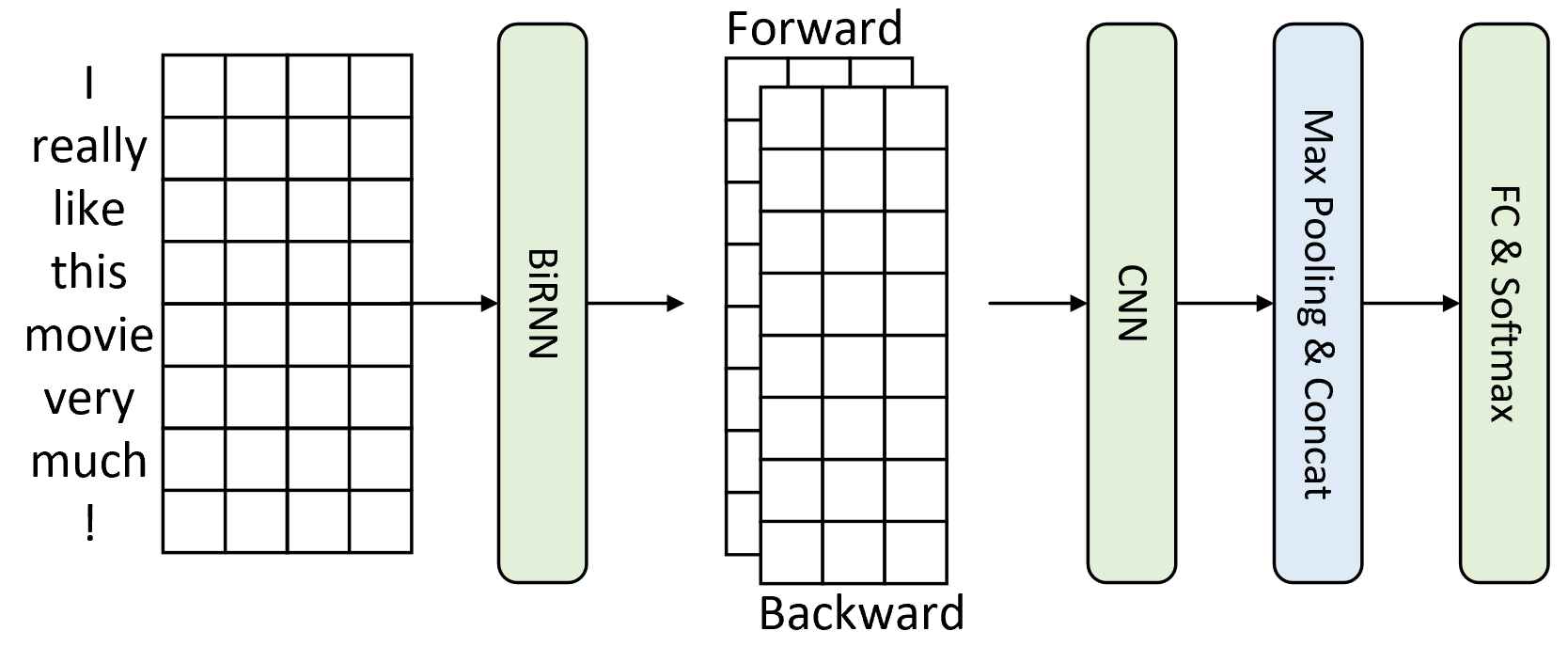
如图8-4所示,同之前介绍的一样最左侧为一个$8\times4$的文本表示矩阵,然后紧接着是一个双向的循环神经网络层,进一步将循环神经网络正向和反向的输出向量垂直堆叠形成两个特征通道。此时的两个特征通道可以看作是从不同角度来表示文本数据的时序依赖关系。下一步再将该特征图作为卷积层的输入,利用卷积操作来加强对文本序列局部重要信息的提取,例如词粒度或短语粒度等信息。最后,卷积层结束后每个特征图将只是一个向量,即卷积核宽度等于输入特征图的宽度,并通过一个池化层和全连接层来对输入文本进行分类,整个处理流程同第8.1.1节中的TextCNN类似。
8.3.4 BiLSTM-CNN实现#
在清楚BiLSTM-CNN模型的相关原理后,我们再来看如何借助PyTorch实现该模型。 以下完整示例代码可以参见Code/Chapter08/C04_BiLSTMCNN/BiLSTMCNN.py文件。
1. 前向传播
首先实现模型的整个前向传播过程。从图8-4可知,整个模型整体分为词嵌入层、双向循环神经网络层、卷积层以及最后的分类层,实现代码如下所示:
1 class BiLSTMCNN(torch.nn.Module):
2 def __init__(self, config=None):
3 super(BiLSTMCNN, self).__init__()
4 if config.cell_type == 'RNN':
5 rnn_cell = nn.RNN
6 elif config.cell_type == 'LSTM':
7 rnn_cell = nn.LSTM
8 elif config.cell_type == 'GRU':
9 rnn_cell = nn.GRU
10 else:
11 raise ValueError("Unrecognized RNN cell type: " + config.cell_type)
12 self.token_embedding = nn.Embedding(config.vocab_size, config.embedding_size)
13 self.rnn = rnn_cell(config.embedding_size, config.hidden_size, config.num_layers,
14 batch_first=True, bidirectional=True)
15 self.cnn = nn.Conv2d(2, config.out_channels, [config.kernel_size, config.hidden_size])
16 self.max_pool = nn.AdaptiveMaxPool2d((1, 1))
17 self.classifier = nn.Sequential(nn.Linear(config.out_channels, config.num_classes))在上述代码中,第4~11行是根据对应的参数返回相应的循环记忆单元。第12行是实例化得到一个词嵌入层。第13~14行是根据对应参数实例化得到双向循环记忆单元。第15~16行是分别实例化得到一个卷积层和最大池化层。第17行则是由一个全连接构成的分类层。
进一步,整个前向传播计算过程的示例代码如下所示:
1 def forward(self, x, labels=None):
2 x = self.token_embedding(x)
3 x, _ = self.rnn(x)
4 x = torch.reshape(x, (x.shape[0], x.shape[1], 2, -1))
5 x = x.transpose(1, 2)
6 x = self.cnn(x)
7 x = self.max_pool(x)
8 x = torch.flatten(x, start_dim=1)
9 logits = self.classifier(x)
10 if labels is not None:
11 loss_fct = nn.CrossEntropyLoss(reduction='mean')
12 loss = loss_fct(logits, labels)
13 return loss, logits
14 else:
15 return logits在上述代码中,第2行是词嵌入层的输出结果,形状为[batch_size, src_len, embedding_size]。第3行是双向RNN计算后的输出结果,形状为[batch_size, src_len, 2*hidden_size]。第4~5行是将上一步的结果处理成特征图的表示形式,结果形状为[batch_size, 2, src_len, hidden_size]。第6行则是卷积层处理后的结果,形状为[batch_size, out_channels, src_len-kernel_size+1,1]。第7行是最大池化层,输出结果形状为[batch_size, out_channels, 1, 1]。第8行表示将x第1个维度以及之后的维度拉伸成一个维度,当然使用两次squeeze(-1)也能达到同样的效果。第9行则是最后的分类层,输出结果形状为[batch_size, num_classes]。第10~15行则是根据条件返回对应的处理结果。
最后,可以通过如下方式来进行使用
1 class ModelConfig(object):
2 def __init__(self):
3 self.num_classes = 15
4 self.vocab_size = 8
5 self.embedding_size = 16
6 self.hidden_size = 512
7 self.num_layers = 2
8 self.cell_type = 'LSTM'
9 self.cat_type = 'last'
10 self.kernel_size = 3
11 self.out_channels = 64
12
13 if __name__ == '__main__':
14 config = ModelConfig()
15 model = BiLSTMCNN(config)
16 x = torch.randint(0, config.vocab_size, [2, 3], dtype=torch.long)
17 label = torch.randint(0, config.num_classes, [2], dtype=torch.long)
18 loss, logits = model(x, label)
19 print(logits.shape) # torch.Size([2, 15])在上述代码中,第1~11是行参数配置定义类。第14~15行是分别实例化参数配置类和模型。第16~17行是构造输入和标签。第18~19行便是模型的输出结果。
2. 模型训练
这部分代码依旧同先前的类似这里就不再赘述,各位读者直接参考源码即可。最后,在对网络模型进行训练时将会得到类似如下的输出结果:
1 Epochs[1/50]--batch[0/1047]--Acc: 0.082--loss: 2.6891
2 Epochs[1/50]--batch[50/2093]--Acc: 0.0703--loss: 2.5854
3 Epochs[1/50]--batch[100/2093]--Acc: 0.2695--loss: 2.3634
4 Epochs[1/50]--batch[150/2093]--Acc: 0.4453--loss: 1.8408
5 Epochs[1/50]--batch[200/2093]--Acc: 0.6602--loss: 1.1232
6 Epochs[1/50]--batch[250/2093]--Acc: 0.7305--loss: 0.9747
7 Epochs[1/50]--batch[300/2093]--Acc: 0.7148--loss: 1.0209
8 Epochs[1/50]--batch[350/2093]--Acc: 0.7695--loss: 0.8577
9 Epochs[1/50]--Acc on val 0.8213
10 Epochs[8/50]--Acc on val 0.8538从上述结果可以看出,BiLSTM-CNN模型的收敛速度和效果要略微地好于C-LSTM模型。
8.3.5 小结#
在本节内容中,我们首先引入了可将卷积网络和循环神经网络同时运用于时序数据特征提取的做法;然后分别详细介绍了两种基于CNN和RNN文本分类模型的原理;最后介绍了如何基于PyTorch框架从零实现这两种分类模型。同时,对于上面所介绍的两个模型都有一个共同的特性那就是CNN和RNN是串行进行的,即其中一个部分的输出将作为另外一个部分的输入,因此还有研究者以并行的方式利用CNN和RNN来对原始输入进行特征提取并将两者的结果融合作为最终的特征表示以完成后续任务[6]。
引用#
[1] Zhou C, Sun C, Liu Z, et al. A C-LSTM neural network for text classification[J]. arXiv preprint, 2015, arXiv:1511.08630.
[2] Zhang Y, Yuan H, Wang J, et al. YNU-HPCC at EmoInt-2017: Using a CNN-LSTM model for sentiment intensity prediction[C]. Proceedings of the 8th workshop on computational approaches to subjectivity, sentiment and social media analysis. 2017, 200-204.
[3] Lin S, Xie H, Yu L C, et al. SentiNLP at IJCNLP-2017 Task 4: Customer feedback analysis using a Bi-LSTM-CNN model[C]. Proceedings of the IJCNLP 2017, Shared Tasks, 2017, 149-154.
[4] Sosa P M. Twitter sentiment analysis using combined LSTM-CNN models[J]. Eprint Arxiv, 2017, 2017: 1-9.
[5] Li Y, Wang X, Xu P. Chinese Text Classification Model Based on Deep Learning. Future Internet, 2018, 113(10).
[6] Kunfu Wang, Pengyi Zhang, et al. A Text Classification Method Based on the Merge-LSTM-CNN Model[J] . Journal of Physics: Conference Series, 2020, 1646(1): 012110.