9.4 AdaBoost原理与实现#
通过9.1.4节内容的介绍,我们对于Boosting集成学习的基本思想已经有了一定的了解。在本节内容中,将会介绍Boosing算法中第1种常见的提升学习算法——AdaBoost (Adaptive Boosting) [5]。
9.4.1 AdaBoost算法思想#
AdaBoost算法是由Freund 和 Schapire等人于1997年所提出[6],它是一种自适应的提升算法,其核心思想在于AdaBoost会为每个样本赋予一个权重值,在上一个模型中被错分的样本在下一个模型中将具有更高的权重,以此来尽可能保证每个样本都能够被正确划分,最后再将每个模型的预测结果集成起来作为最终的预测输出。下面通过一个实际的示例来介绍AdaBoost算法的思想。
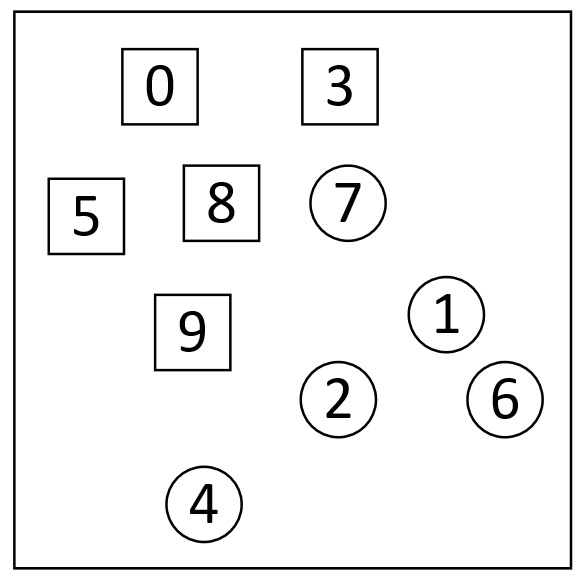
如图9-5所示,图中一共有10个样本点,包含方块和圆形两个类别。假定现在通过某种算法构建了模型1(每个样本点具有相等的权重值)并对图9-5中的样本进行分类,得到的分类结果如图9-6所示。
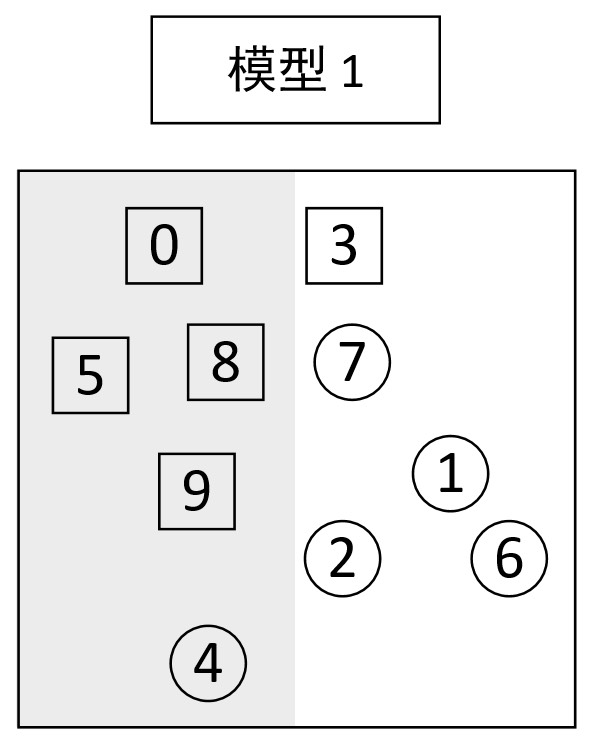
从图9-6的分类结果可知,样本③和④被划分到了错误的类别中,因此可以再次构建模型2并同时赋予样本③和④更高的权重,并对所有样本点进行分类,最终可以得到图9-7中的分类结果。
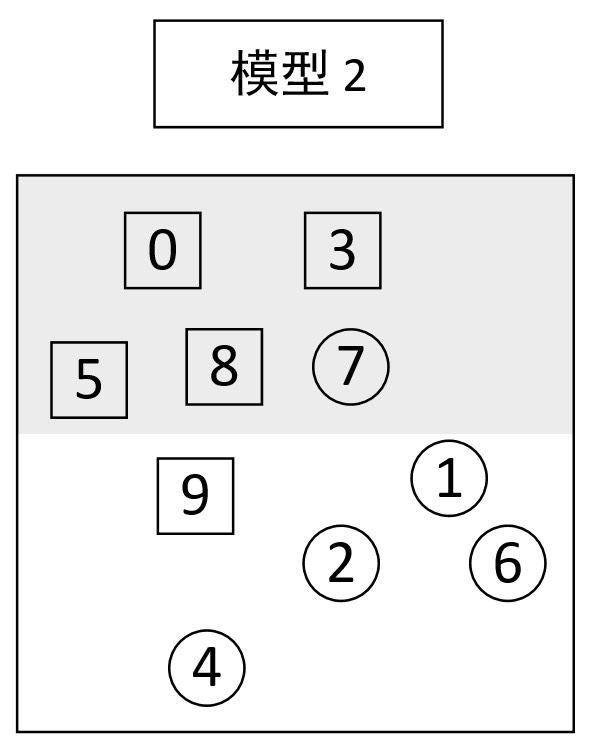
从图9-7的分类结果可知,此时样本③和④已经被正确划分了,但是样本⑦和样本⑨却又出现了错误,于是可以再次构建模型3并同时赋予样本⑦和⑨更高的权重,并对所有样本点进行分类,最终可以得到图9-8中的分类结果。
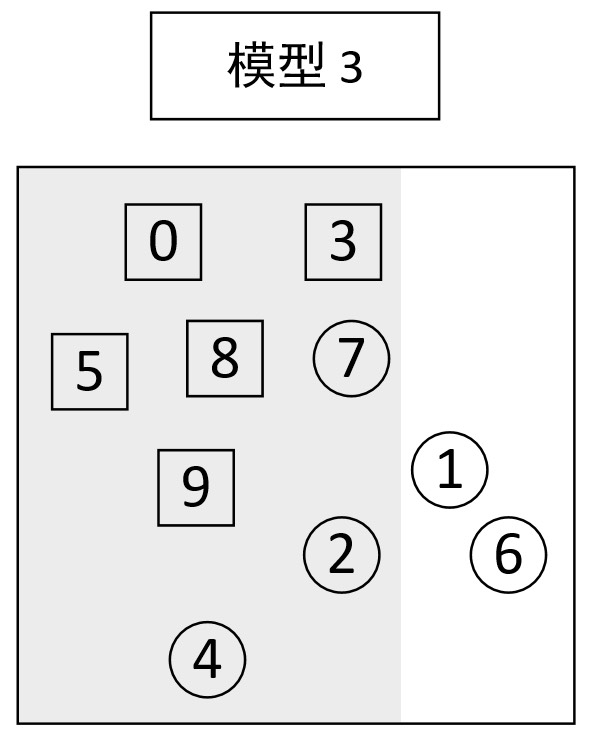
从图9-8的分类结果可知,此时模型3并没有同时将样本⑦和样本⑨都分类正确,并且样本②和④也被误分了。此时,可以再次构建模型4并同时赋予样本②④⑦更高的权重,并对所有样本点进行分类,最终可以得到图9-9中的分类结果。
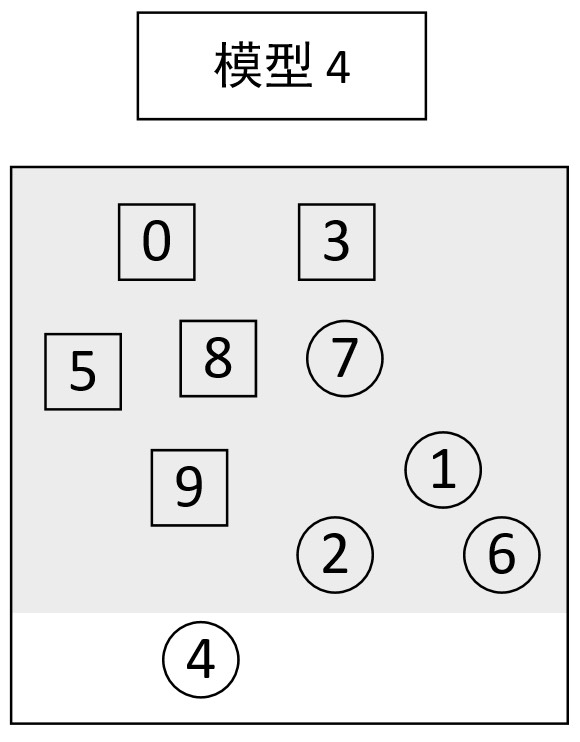
从图9-9所示的结果可以看出,模型4为了同时将所有方形和样本④分类正确,导致样本①②⑥⑦均分类错误。此时可以发现,虽然上述4个模型均没有将所有样本都正确的分类,但是最后可以将4个模型的结果集成起来看做一个模型的输出结果,如图9-10所示。
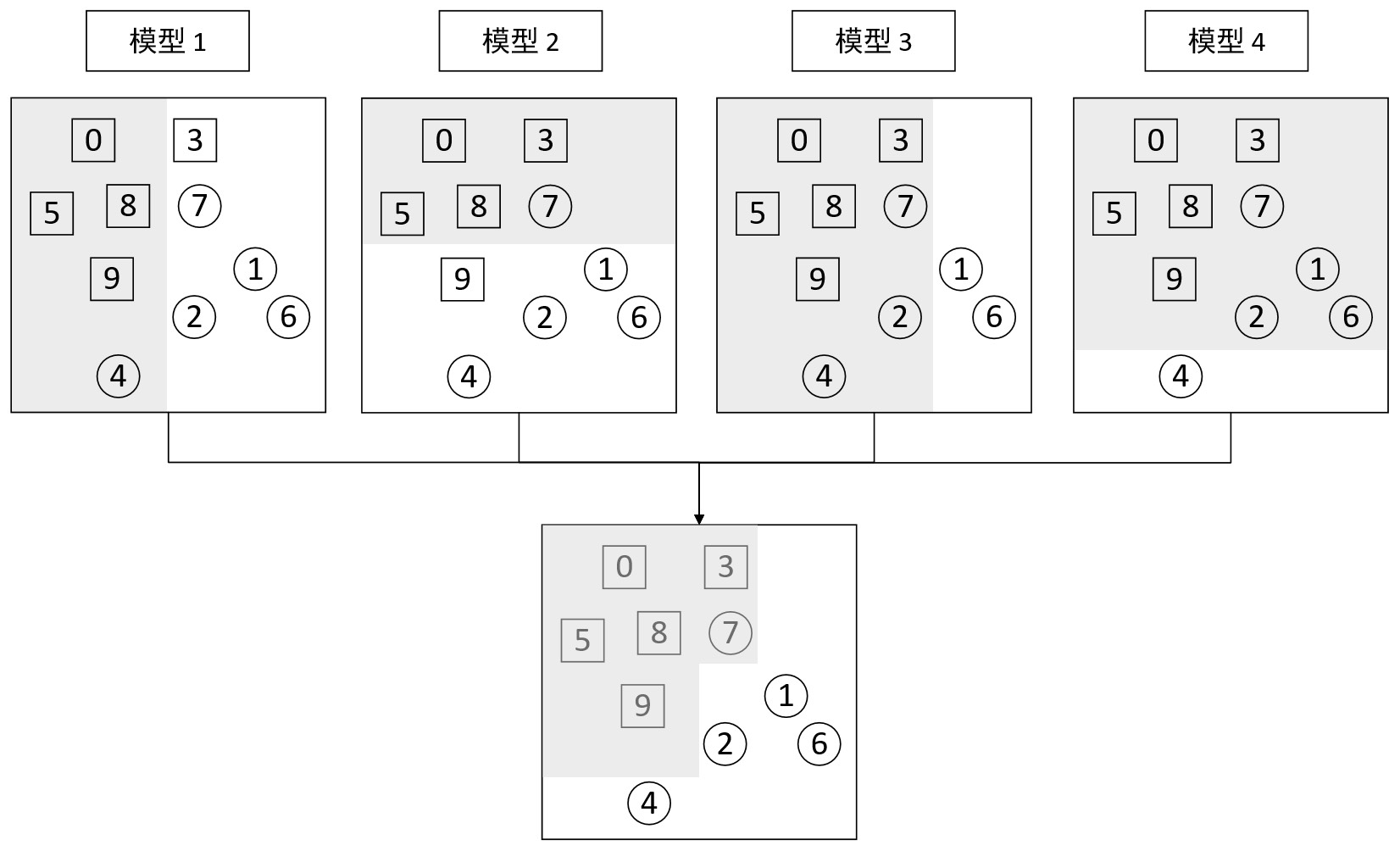
根据图9-10可知,以先前的4个模型为基础,然后以某种策略将各个模型的输出结果集成起来作为最终的预测输出,这样便可以得到一个相较于单个模型更好的预测结果(模型1到模型4的分类准确率分别为0.8、0.8、0.7和0.6,而最终集成模型的准确率为0.9)。当然,事实上如果再构建一个模型5便可以实现百分之百的准确率。
以上就是AdaBoost算法的核心思想,从这里也可以看出AdaBoost算法本质上也可以看做是一种模型的训练策略(这也类似于在13.1节中将要介绍的Self-Training算法),因此不管是任何模型都可以采用AdaBoost策略来进行建模,只是对于不同的算法在如何融入样本权重来进行建模有不同的做法。
在清楚AdaBoost算法的基本思想以后,再来看如何利用sklearn框架快速完成整建模过程。
9.4.2 AdaBoost算法示例代码#
在sklearn中,可以通过sklearn.ensemble中的AdaBoostClassifier来导入AdaBoosting集成学习方法中的分类模型。下面先来介绍一下AdaBoostClassifier类中常见的几个重要参数及含义。
1 from sklearn.ensemble import AdaBoostClassifier
2 def __init__(self, base_estimator=None, n_estimators=50, learning_rate=1.):在上述代码中,第1行是导入AdaBoost算法模块。第2行base_estimator表示所使用的基模型,如果设置为 None则默认使用决策树n_estimators表示基模型的数量,默认为50个;learning_rate用来控制每个基模型的贡献度,即在式(9-8)的后面再乘以这个系数(这只是sklearn在实现时所新加入的参数),默认为1,即等权重。较小的学习率会减小每个分类器的权重变化,使得模型的调整更加平滑和缓慢,这有助于避免过拟合,但可能需要更多的基模型才能达到相同的分类性能;而较大的学习率可以使得模型的收敛速度加快,但可能导致过拟合。因此,在实际应用中,需要根据具体问题进行调优,找到最佳的learning_rate和n_estimators的组合,以实现模型的最佳性能。
下面以决策树作为基模型通过sklearn中的AdaBoostClassifier类来进行Boosting集成学习建模,完整示例可参见 AllBooKCode/Chapter09/C08_AdaBoosting.py 文件。
1 if __name__ == '__main__':
2 x_train, x_test, y_train, y_test = load_data()
3 dt = DecisionTreeClassifier(criterion='gini', max_features=4, max_depth=1)
4 model = AdaBoostClassifier(estimator=dt, n_estimators=100)
5 model.fit(x_train, y_train)
6 print("模型在测试集上的准确率为:", model.score(x_test, y_test))在上述代码中,第3行是定义决策树作为基模型(基模型)。第4行是定义AdaBoost分类器,并将决策树基模型作为参数来实例化一个AdaBoostClassifier类对象。
到此,对于AdaBoost的示例用法就介绍完了。不过细心的读者可能会问,此时基分类器决策树和AdaBoost均有自己的超参数,如果要在上述训练过程中使用网格搜索GridSearchCV该如何实现呢?关于这部分内容完整示例可参见 AllBooKCode/Chapter09/C09_AdaBoosting_gridsearch.py 文件。
9.4.3 AdaBoost算法原理#
在介绍完AdaBoost算法的核心思想及使用示例后,接下来再来看AdaBoost算法的具体原理[6]。假设$g^{(m)}(x),m=1,2,...,M$为$M$个基模型,数据集$(x_1,y_1),(x_2,y_2),...,(x_n,y_n)$一共有$n$个样本,且 $y_i\in \{-1,1\}$,则AdaBoost算法可以通过如下过程来进行表示:
(1) 初始化每个样本的权重为$w_i=1/n$,即等权重;
(2) 使用训练集训练得到基模型 $g^{(m)}(x)$,其输出形式与 $y_i$ 相同 ;
(3) 根据式(9-7)~式(9-9)分别迭代计算每个基模型 $g^{(m)}$ 对应下的分类误差 $err^{(m)}$,模型权重 $\alpha^{(m)}$ 和更新样本权重$w_i$
$$ err^{(m)}=\frac{\sum_{i=1}^nw_i\cdot \mathbb{I}\left(y_i\neq g^{(m)}(x_i)\right)}{\sum_{i=1}^nw_i}\tag{9-7} $$$$ \alpha^{(m)}=\log\frac{1-err^{(m)}}{err^{(m)}}\tag{9-8} $$$$ \begin{aligned} &w_i\leftarrow w_i\cdot\exp \left(\alpha^{(m)}\cdot\mathbb{I}\left(y_i\neq g^{(m)}(x_i)\right)\right),i=1,2,...,n \\[2ex] &w_i\leftarrow \frac{w_i}{\sum_{j=1}^nw_j} \end{aligned}\tag{9-9} $$(3) 将训练得到的$M$个基模型根据式(9-10)中的方式进行集成,然后输出得到样本的预测结果:
$$ C(x)=\arg \max_{k}=\sum_{m=1}^M\alpha^{(m)}\cdot \mathbb{I}(g^{(m)}(x)=k)\tag{9-10} $$其中$\mathbb{I}(\cdot)$为指示函数,条件成立时取1,不成立时取0。
从式(9-7)可以看出,如果每个样本都是等权重的话,那么$err^{(m)}$则是计算对应分类结果的错误率。同时,从式(9-7)~式(9-10)的计算过程也可以再次看出,AdaBoost算法并不是某种特定算法的称谓,而是一种模型训练策略,只是在大多数情况下都是选择决策树作为基模型,因此不少读者很容易就将AdaBoost与树模型画上了等号。对于上述过程,大家还可以结合9.4.6节中的模拟实现过程进行理解。
9.4.4 前向分步加法模型#
在9.4.3节内容中,虽然我们已经完整介绍了AdaBoost算法的计算流程,但有一个疑问便是为什么这样做是有效的。事实上,在AdaBoost算法提出若干年之后Friedman等人才从损失函数的视角来给予它一个合理的解释,这也被称之为前向分步加法模型(Forward Stagewise Additive Modeling)[7]。在前向分步加法模型中,当使用指数损失作为模型的损失函数时,其最终优化得到结果便是AdaBoost模型。
在许多分类和回归模型中,它们都可以表示为一系列简单模型线性组合的形式,如式(9-11)所示。
$$ f(x)=\sum_{m=1}^M\beta^{(m)}g^{(m)}(x)\tag{9-11} $$其中$M$表示模型个数;$x$表示输入样本;$\beta^{(m)}$ 为模型$g^{(m)}(x)$对应的系数。
通常情况下,所有模型$g^{(m)}(x)$ 和对应的系数 $\beta^{(m)}$都是通过在训练集$(x_n,y_n)$上最小化某一损失函数$L$优化而来,如式(9-12)所示。
$$ \left(\beta^{(m)}_{\ast},g_{\ast}^{(m)}\right)^M_{m=1}=\underset{(\beta^{(m)},g^{(m)})^M_{m=1}}{\text{arg min}}\sum_{i=1}^nL\left(y_i,\sum_{m=1}^M\beta^{(m)}g^{(m)}(x_i)\right)\tag{9-12} $$其中式(9-12)的含义是,对于任意一个模型$g^{(m)}(x)$来说,总能在训练样本$(x_n,y_n)$上找到一组最优的模型参数使得整体的损失值最小。
根据式(9-12)的形式可知,如果直接同时对所有模型进行优化通常来说比较困难,而一种可行的办法则是使用贪婪地做法分步对每个模型$g^{(m)}(x)$进行优化求解,即
$$ \left(\beta^{(m)}_{\ast},g_{\ast}^{(m)}\right)=\underset{\beta^{(m)},g^{(m)}}{\text{arg min}}\sum_{i=1}^nL\left(y_i,\beta^{(m)} g^{(m)}(x_i)\right)\tag{9-13} $$例如在第$m$步的优化过程中,待求解的模型为$g^{(m)}(x)$,则此时的损失定义为
$$ \sum_{i=1}^nL\left(y_i,f^{(m-1)}(x_i)+\beta^{(m)}g^{(m)}(x_i)\right)\tag{9-14} $$其中
$$ f^{(m)}(x)=f^{(m-1)}(x)+\beta^{(m)}g^{(m)}(x),\;f^{(0)}(x)=0\tag{9-15} $$而式(9-14)的含义是在优化模型 $g^{(m)}(x)$ 同时需要考虑到前 $m-1$ 个基模型的叠加情况 $f^{(m-1)}(x)$,这也是分步加法的体现,且此时可以看出,式(9-11)中的$f(x)$便等于式(9-15)中的$f^{(M)}(x)$。这样,在每一步优化结束后都能求解得到对应模型 $g_{\ast}^{(m)}(x)$ 及系数 $\beta^{(m)}_{\ast}$,进而求解得到所有模型对应的参数。
以上便是前向分步加法模型的整体思想,下面再来看当损失函数$L(\cdot)$为指数损失时的具体情况。
9.4.5 AdaBoost算法求解#
在上面我们介绍到,当前向分步加法模型中的损失函数为指数损失时,最终优化得到结果便是AdaBoost模型。具体地,设此时对应的损失函数为[8] [9]
$$ L(y,f(x))=\exp(-yf(x))\tag{9-16} $$同时,设模型$g^{(m)}(x)$ 为一个二分类模型,其输出 $g^{(m)}(x)\in\{-1,1\}$,则此时式(9-14)可以改写为
$$ \begin{aligned} \left(\beta^{(m)}_{\ast},g_{\ast}^{(m)}\right)&=\underset{\beta^{(m)},g^{(m)}}{\text{arg min}}\sum_{i=1}^n \exp\left(-y_i(f^{(m-1)}(x_i)+\beta^{(m)} g^{(m)}(x_i))\right)\\[2ex] &=\underset{\beta^{(m)},g^{(m)}}{\text{arg min}}\sum_{i=1}^n w^{(m)}_i \cdot\exp\left(-y_i\beta^{(m)} g^{(m)}(x_i)\right) \end{aligned}\tag{9-17} $$其中$w^{(m)}_i=\exp(-y_i(f^{(m-1)}(x_i)))$。
进一步,根据$y_i=g^{(m)}(x_i)$ 或 $y_i\neq g^{(m)}(x_i)$这两种取值情况,且注意如果 $y_i=g^{(m)}(x_i)$ 则两者的乘积为1,否则为-1,此时可以将式(9-17)改写为
$$ \begin{aligned} \left(\beta^{(m)}_{\ast},g_{\ast}^{(m)}\right)&=\underset{\beta^{(m)},g^{(m)}}{\text{arg min}}\sum_{i=1}^n w^{(m)}_i \cdot\exp\left(-y_i\beta^{(m)} g^{(m)}(x_i)\right)\\[2ex] &=\underset{\beta^{(m)},g^{(m)}}{\text{arg min}}\left[e^{-\beta^{(m)}}\sum_{y_i=g^{(m)}(x_i)}w_i^{(m)}+e^{\beta^{(m)}} \sum_{y_i\neq g^{(m)}(x_i)}w_i^{(m)}\right]\\[2ex] &=\underset{\beta^{(m)},g^{(m)}}{\text{arg min}}\left[e^{-\beta^{(m)}}\sum_{i=1}^nw_i^{(m)}+\left(e^{\beta^{(m)}}-e^{-\beta^{(m)}}\right)\sum_{i=1}^nw^{(m)}_i\cdot\mathbb{I}(y_i\neq g^{(m)}(x_i))\right] \end{aligned}\tag{9-18} $$接下来分两步分别对式(9-18)中的$\beta^{(m)}$和$g^{(m)}$进行求解。
首先,固定$\beta^{(m)}$为常数,则求解$g^{(m)}$只需要等价地最小化式(9-19)即可
$$ g^{(m)}_{\ast}=\underset{g^{(m)}}{\text{arg min}}\sum_{i=1}^nw^{(m)}_i\mathbb{I}(y_i\neq g^{(m)}(x_i))\tag{9-19} $$即只需要在具体的算法中最小化其对应的目标函数即可,其中$w^{(m)}_i$ 是每个训练样本在第$m$步优化时对应的权重值。
其次,固定$g^{(m)}$为常数,在式(9-18)中对$\beta^{(m)}$求偏导并令其为0有
$$ \begin{aligned} -e^{-\beta^{(m)}}\sum_{i=1}^nw^{(m)}_i+\left(e^{\beta^{(m)}}+e^{-\beta^{(m)}}\right)\sum_{i=1}^nw^{(m)}_i\mathbb{I}(y_i\neq g^{(m)}(x_i))=0 \end{aligned}\tag{9-20} $$此时,在式(9-20)两边同时除以$e^{-\beta^{(m)}}$可得
$$ \begin{aligned} &\left(e^{2\beta^{(m)}}+1\right)\sum_{i=1}^nw^{(m)}_i\mathbb{I}(y_i\neq g^{(m)}(x_i))=\sum_{i=1}^nw^{(m)}_i\\[2ex] &e^{2\beta^{(m)}}=\frac{\sum_{i=1}^nw^{(m)}_i}{\sum_{i=1}^nw^{(m)}_i\mathbb{I}(y_i\neq g^{(m)}(x_i))}-1 \end{aligned}\tag{9-21} $$令
$$ err^{(m)}=\frac{\sum_{i=1}^nw^{(m)}_i\mathbb{I}(y_i\neq g^{(m)}(x_i))}{\sum_{i=1}^nw^{(m)}_i}\tag{9-22} $$则式(9-21)可以简写为
$$ e^{2\beta^{(m)}}=\frac{1}{err^{(m)}}-1=\frac{1-err^{(m)}}{err^{(m)}}\tag{9-23} $$进一步,根据式(9-23)可得
$$ \beta^{(m)}=\frac{1}{2}\log{\frac{1-err^{(m)}}{err^{(m)}}}\tag{9-24} $$由此便得到了式(9-8)中的模型权重$\alpha^{(m)}$的更新公式,更准确应该是$\alpha^{(m)}=2\beta^{(m)}$,不过这并不影响最终的优化结果。
最后,根据式(9-15)可得
$$ \begin{aligned} w^{(m+1)}_i=&\exp(-y_i(f^{(m)}(x_i)))\\[1ex] =&\exp(-y_i(f^{(m-1)}(x_i)+\beta^{(m)}g^{(m)}(x_i)))\\[1ex] =&w^{(m)}_i\exp(-y_i\beta^{(m)}g^{(m)}(x_i)) \end{aligned}\tag{9-25} $$因为$-y_ig^{(m)}(x_i)=2\cdot\mathbb{I}(y_i\neq g^{(m)}(x_i))-1$,所以可以将式(9-25)改写为
$$ w^{(m+1)}_i=w^{(m)}_i\exp(2\beta^{(m)}\mathbb{I}(y_i\neq g^{(m)}(x_i)))\exp(-\beta^{(m)})\tag{9-26} $$由$\alpha^{(m)}=2\beta^{(m)}$可得,式(9-26)可重写为
$$ \begin{aligned} w^{(m+1)}_i=&w^{(m)}_i\exp(\alpha^{(m)}\mathbb{I}(y_i\neq g^{(m)}(x_i)))\exp(-\beta^{(m)}) \end{aligned}\tag{9-27} $$最后,根据式(9-27)可知,样本权重$w_i$在更新过程中均乘以了$\exp(-\beta^{(m)})$,所以在实际求解过程中样本权重的更新公式可以简写为:
$$ w^{(m+1)}_i\leftarrow w^{(m)}_i\exp(\alpha^{(m)}\mathbb{I}(y_i\neq g^{(m)}(x_i)))\tag{9-28} $$到此,对于AdaBoost算法的求解过程就介绍完了,进一步可以根据9.4.3节中的迭代步骤来求得每个模型对应的参数。
下面,再以一个模拟的分类器来实现上述训练过程,以便更加了解AdaBoost算法内部的运行机制。
9.4.6 从零实现AdaBoost算法#
在这里,首先定义一个模拟的分类器,示例代码如下:
1 def estimator(n_samples,sample_weight):
2 y_pred = np.random.uniform(0, 1, n_samples) < 0.5
3 return np.array(y_pred, dtype=np.int32)在上述代码中,第2行为根据均匀分布随机为n_samples个样本点生成了一个概率分布,并以0.5作为阈值来输出分类器的预测结果。需要注意的是,在真实情况中sample_weight会参与模型的训练过程,而且对于不同的算法算模型策略不同,这在后续章节中将会进行介绍,这里是模拟所以没用到。
其次,需要根据式(9-7)~式(9-9)来实现一次提升的计算过程,示例代码如下:
1 def single_boost(n_samples, sample_weight, y, iboost):
2 y_predict = estimator(n_samples,sample_weight)
3 incorrect = y_predict != y
4 estimator_error = np.average(incorrect, weights=sample_weight, axis=0)
5 estimator_weight = np.log((1. - estimator_error) / estimator_error)
6 sample_weight *= np.exp(estimator_weight * incorrect)
7 return sample_weight, estimator_weight, estimator_error, y_predict在上述代码中,第2行是分类器的预测输出结果。第3~4行是完成式(9-7)中的计算过程。第5行是完成式(9-8)的计算过程。第6行则是完成式(9-9)的计算过程。第7行是返回各项的计算结果。
进一步,需要完成所有提升的循环迭代过程,示例代码如下:
1 def boost(y, n_samples, n_estimators):
2 sample_weight = np.ones(n_samples, dtype=np.float64) # 初始化权重全为1
3 sample_weight /= sample_weight.sum() # 标准化权重
4 estimator_weights_ = np.zeros(n_estimators, dtype=np.float64)
5 estimator_errors_ = np.zeros(n_estimators, dtype=np.float64)
6 y_predicts_ = []
7 for iboost in range(n_estimators):
8 sample_weight, estimator_weight, estimator_error, y_predict \
9 = single_boost(n_samples, sample_weight, y, iboost)
10 estimator_weights_[iboost] = estimator_weight
11 estimator_errors_[iboost] = estimator_error
12 y_predicts_.append(y_predict)
13 if estimator_error == 0:
14 break
15 sample_weight_sum = np.sum(sample_weight)
16 if sample_weight_sum <= 0:
17 break
18 sample_weight /= sample_weight_sum
19 y_predicts_ = np.vstack(y_predicts_)
20 return estimator_weights_, y_predicts_在上述代码中,第2~3行是初始化每个样本的权重。第4~5行是初始化两个全0的向量后续分别用来记录模型误差$err^{(m)}$和模型权重$\alpha^{(m)}$。第7~18行则是AdaBoost的循环迭代过程,其中第8~12行是完成一次单独的提升操作,并记录相应的返回结果,第13~14行是判断模型误差是否为0,第15~18行是计算权重和并判断是否结束迭代以及对样本权重进行标准化。第19~20行是返回后续所需要的结果。
最后,还需要根据式(9-10)来实现模型的预测过程,示例代码如下:
1 def predict(estimator_weights, y_predicts):
2 K = 2 # 分类数
3 estimator_weights = np.reshape(estimator_weights, [1, -1])
4 result = []
5 for k in range(K):
6 correct = (y_predicts == k)
7 result.append(np.matmul(estimator_weights, correct))
8 result = np.vstack(result)
9 print("计算分类概率值: \n", result)
10 y_pred = np.argmax(result, axis=0)
11 return y_pred在上述代码中,第5行是依次遍历每一个类别,并根据式(9-10)计算得到对应的分类概率值。第10行是根据每个样本属于每个类别的概率值取最大者对应的下标作为该样本的分类类别。
在完成所有编码过程后便可以通过如下方式运行上述代码:
1 if __name__ == '__main__':
2 n_samples = 10
3 np.random.seed(370)
4 y = np.random.randint(0, 2, 10) # 生成正确标签
5 n_estimators = 4
6 print("正确标签: ", y)
7 estimator_weights, y_predicts = boost(y, n_samples, n_estimators)
8 print("estimator_weights:", estimator_weights)
9 print("所有没有预测结果:\n", y_predicts)
10 y_pred = predict(estimator_weights, y_predicts)
11 print("预测结果:", y_pred)
12 print("AdaBoost准确率:", np.average(y == y_pred))上述代码运行结束后,对于每个分类器的输出结果我们可以通过表9-3来进行表示。
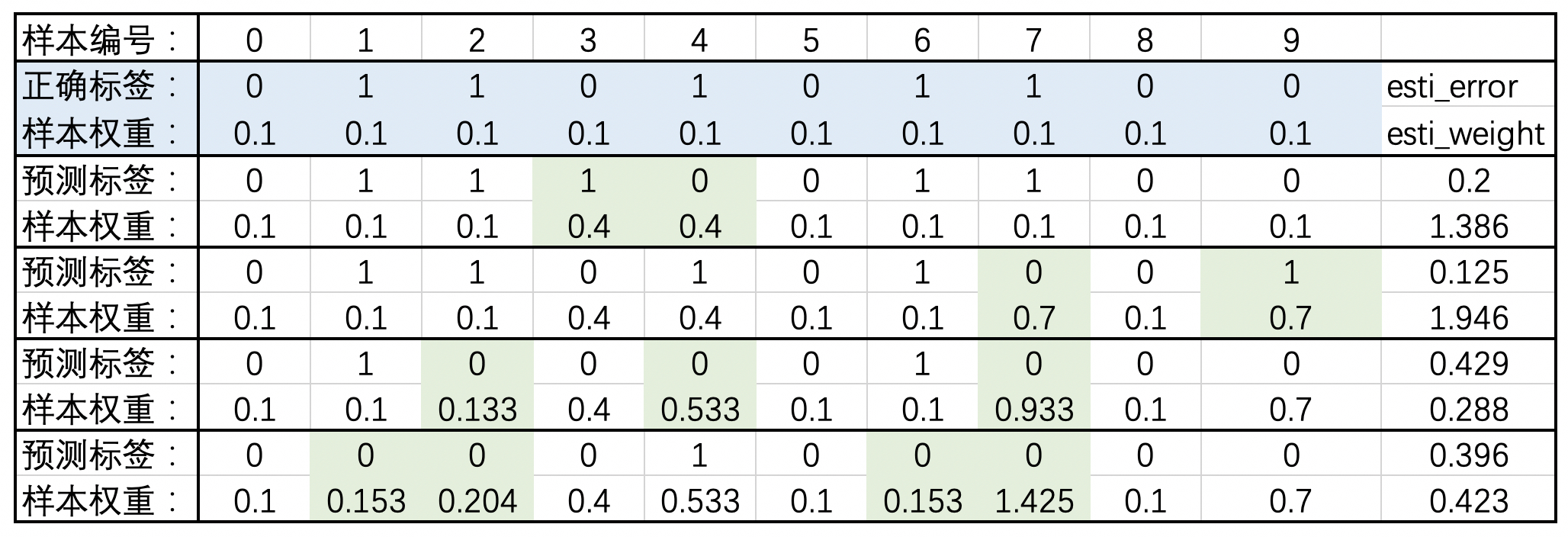
从表9-3可以看出,初始状态时每个样本点的权重值均为0.1,并且在第1个模型运行结束后,由于③④两个样本点分类错误因此其权重均从0.1变成了0.4(注意,这里为了方便理解AdaBoost的思想,所以样本权重没有进行标准化)。进一步,对于第2个分类器来说,由于⑦⑨两个样本点分类错误因此权重均从0.1增加到了0.7,而其它分类正确的样本权重保持不变。对于后续两个分类器来说同理,不再赘述。
对于整个模型后面的预测输出结果如下所示:
1 estimator_weights: [1.386 1.946 0.288 0.423]
2 每个分类器的预测结果:
3 [[0 1 1 1 0 0 1 1 0 0]
4 [0 1 1 0 1 0 1 0 0 1]
5 [0 1 0 0 0 0 1 0 0 0]
6 [0 0 0 0 1 0 0 0 0 0]]
7 计算分类概率值:
8 [[4.043 0.423 0.711 2.656 1.674 4.043 0.423 2.656 4.043 2.097]
9 [0. 3.62 3.332 1.386 2.369 0. 3.62 1.386 0. 1.946]]
10 预测结果: [0 1 1 0 1 0 1 0 0 0]
11 AdaBoost准确率: 0.9在上述结果中,第1行是每个基模型对应的权重,并且可以发现分类器的准确率越高其对应的权重值便越大。第3~6行是每个分类器的预测结果。第8~9行是根据式(9-10)计算得到的每个样本属于各个类别的置信度。第10行是每个样本对应的最终预测输出。上述完整代码可参见 AllBooKCode/Chapter09/C11_manual_adaboost.py 文件。
9.4.7 小结#
在本节内容中,我们首先介绍了AdaBoost算法的基本思想,即先串行地训练一系列前后依赖的同类模型,再通过某种策略将所有的模型组合起来并预测输出最终的结果;然后详细介绍了AdaBoost算法的基本原理以及在sklearn框架中的用法;进一步详细介绍了前向分步加法模型,并推导得出当损失函数为指数损失函数时前向分步加法模型的优化结果便等同于AdaBoost算法的求解结果;最后还通过一个模拟的分类器来从零实现了AdaBoost的整个算法求解过程。在下一节内容中,我们将会进一步介绍AdaBoost算法的改进版本以及对应的代码实现过程。