12.2 基于核函数的主成分分析#
在12.1节内容中我们详细介绍了PCA算法的思想原理,在本节内容中将会介绍另外一种基于PCA算法改进的核主成分分析算法(Kernel Principal Component Analysis, KPCA)[1]。如图12-12便是基于核函数的主成分分析算法的学习路线图,首先仍旧是先介绍KPCA背后的思想和在sklearn中的用法,然后介绍KPCA的原理与求解过程,最后介绍如何从零实现KPCA算法。
12.2.1 KPCA算法思想#
从名字来看,KPCA算法是在原有的PCA降维算法中引入了核技巧(Kernel Trick),而所谓核技巧则是指能够快速计算得到两个低维向量映射到高维(甚至是无穷维)空间后内积的方法,详细内容可以阅读本书10.8节内容。之所以需要在原始PCA算法中引入特征映射,是因为PCA算法只能够处理线性分布的数据样本,而对于非线性的场景来说PCA算法将会显得无能为力。
如图12-13所示,在二维空间中有一个非线性可分的数据集,其一共包含有两个类别。假设现在通过PCA算法来对其进行降维处理将会产生什么样的结果呢?
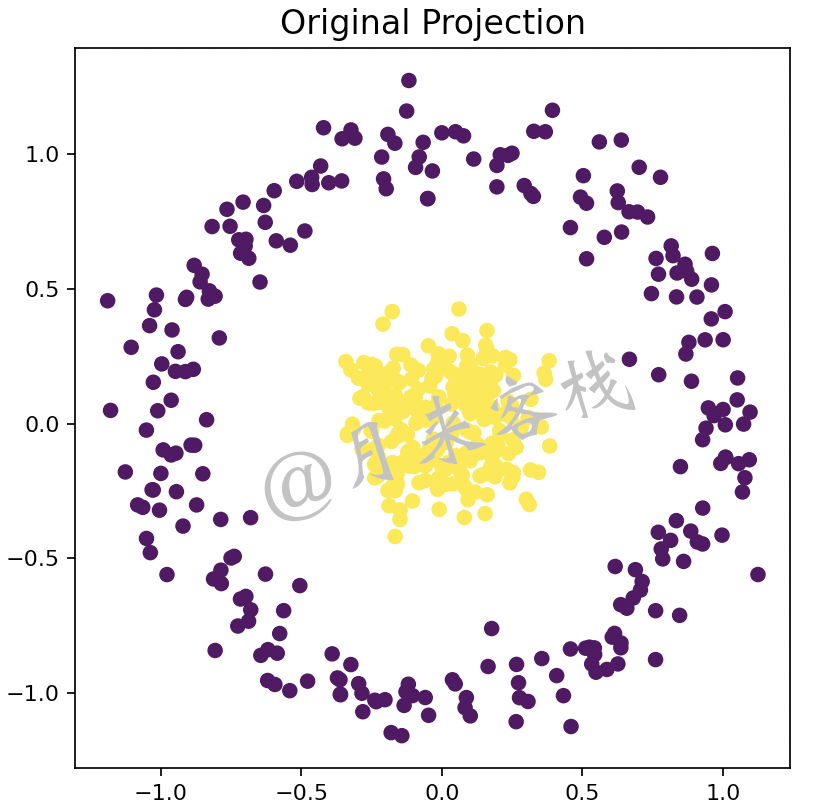
根据PCA算法原理可知,图12-13中的数据样本无论是朝着哪个方向进行投影降维,在子空间中都会将两个类别的样本点完全混合在一起,而这样的降维操作显然是无效的。因为降维算法的目的是在尽可能多的保留原有数据结构信息的前提条件下降低特征维度,而不仅仅只是为了单方面的降低维度而过多(或全部)丢失了数据原有的结构信息。如图12-14所示便是图12-13中的样本通过PCA算法降维后的结果。
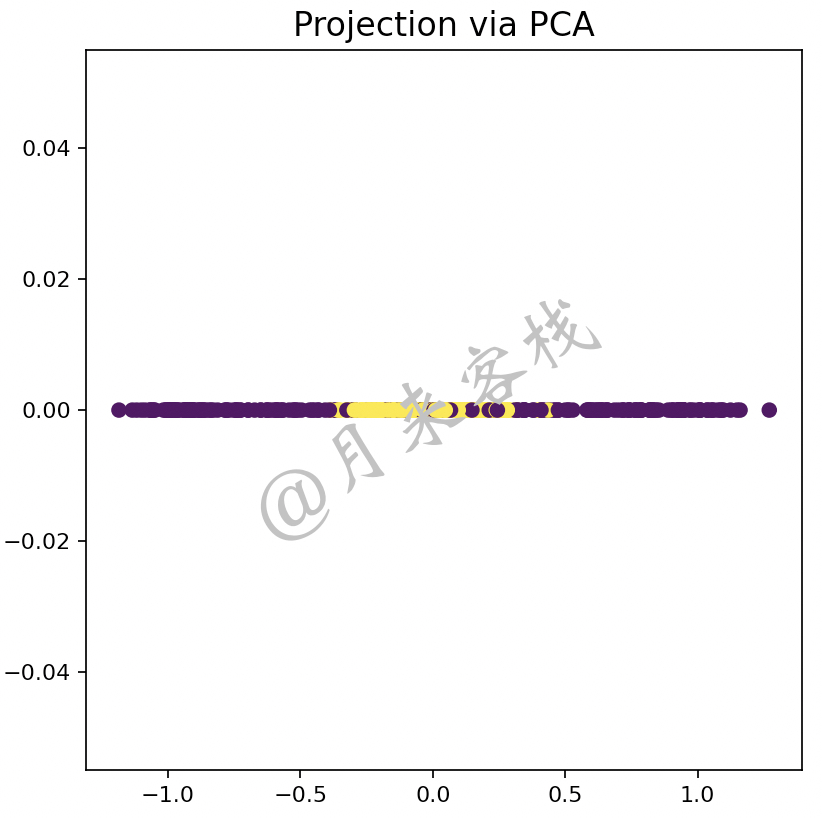
如图12-14所示,可以看到经过PCA算法降维后的结果已经完全不能够体现原有的样本结构信息(这里特指类别)。因此,这就需要借助特征映射的思想先将原始样本点映射到一个高维的线性可分的特征空间中,然后再通过PCA算法对齐进行降维处理。如图12-15所示便是经过KPCA算法降维后的结果。
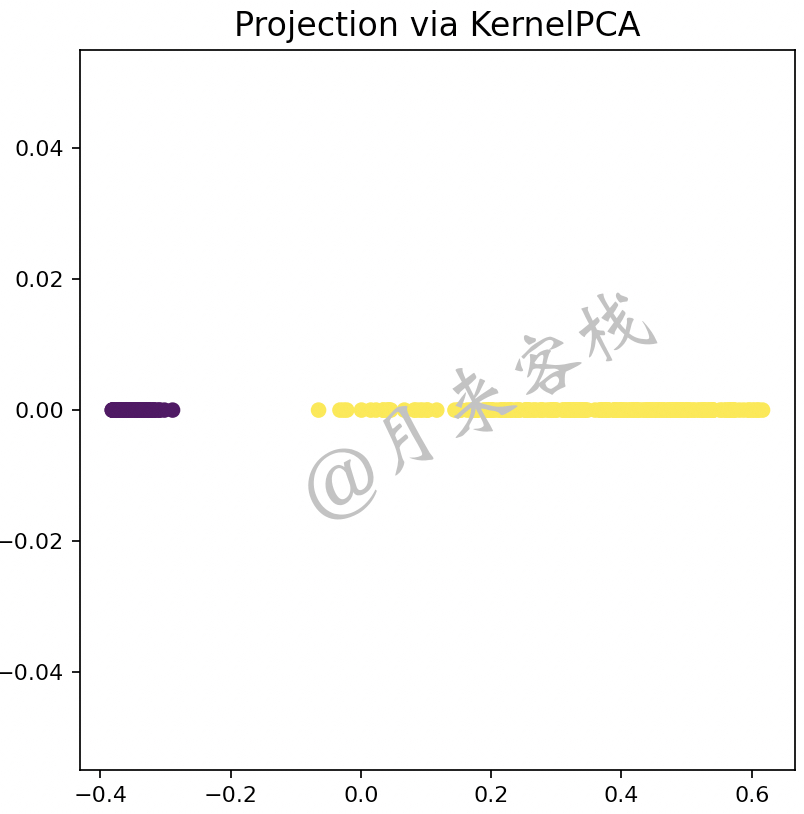
如图12-15所示,可以看到经过KPCA算法降维后的结果依旧能够体现出两个完全不同的样本类别。
根据上面的介绍可知,KPCA算法的核心思想主要可以分为两步:第1步,先将原始非线性可分的样本点映射到线性可分的高维或无穷维(高斯核)的特征空间中;第2步,在线性可分的高维空间中通过PCA算法进行降维处理。
如图12-6所示,可以选择某个合适的核函数将原始非线性可分的样本点映射到线性可分的高维空间中。
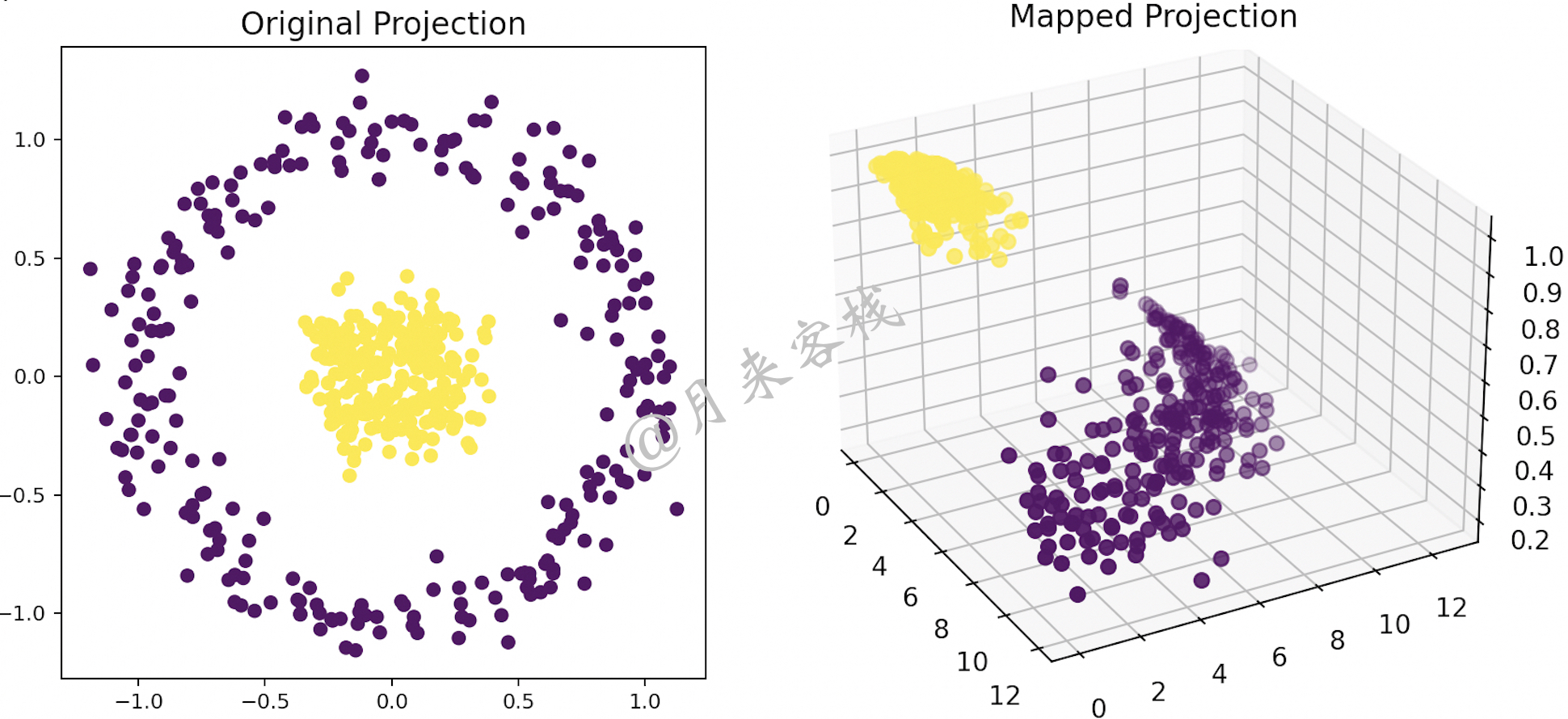
然后再通过PCA算法对其进行降维处理便可以得到类似图12-15中的结果,如图12-17所示。
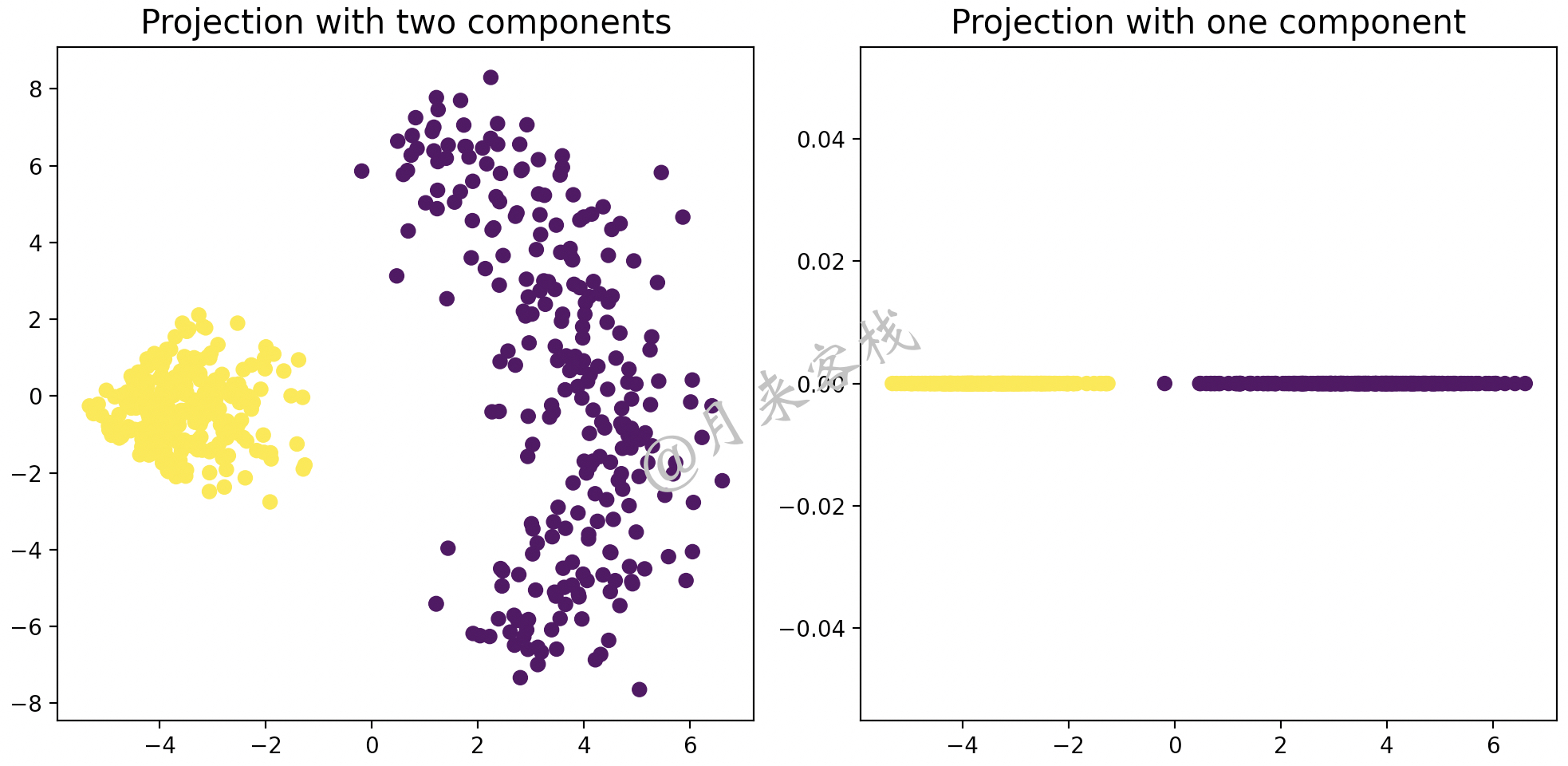
如图12-17所示,左边为PCA降维后使用2个主成分表示的可视化结果,右边为使用1个主成分表示的结果。上述可视化代码可参见 AllBooKCode/Chapter12/C05_KPCA_idea.py 文件。
12.2.2 KPCA示例代码#
在清楚了KPCA算法的基本思想后,我们便可以通过sklearn中的KernelPCA模块来进行使用,示例代码如下:
1 import numpy as np
2 from sklearn.decomposition import KernelPCA
3 from sklearn.datasets import make_circles
4 import matplotlib.pyplot as plt
5
6 def make_nonlinear_cla_data(num_points = 500):
7 x, y = make_circles(n_samples=num_points, factor=0.2, noise=0.1,
8 random_state=np.random.seed(10))
9 x = x.reshape(-1, 2)
10 return x, y.reshape(-1, 1)在上述代码中,第1~4行是导入相关模块。第6~10行是构造一个线性不可分的二分类数据集。
进一步,可以通过KernelPCA模块来对其进行降维处理并可视化,示例代码如下:
1 def visualization():
2 x, y = make_nonlinear_cla_data()
3 pca = KernelPCA(n_components=2, kernel='rbf', gamma=2.)
4 plt.figure(figsize=(12, 4))
5 plt.subplot(1, 3, 1)
6 plt.title('Original', fontsize=15)
7 plt.scatter(x[:, 0], x[:, 1], c=y)
8 x = pca.fit_transform(x)
9 plt.subplot(1, 3, 2)
10 plt.title('Projection with two components', fontsize=15)
11 plt.scatter(x[:, 0], x[:, 1], c=y)
12 plt.subplot(1, 3, 3)
13 plt.title('Projection with one component', fontsize=15)
14 plt.scatter(x[:, 0], [0] * len(x), c=y)
15 plt.tight_layout()
16 plt.show()
17
18 if __name__ == '__main__':
19 visualization()在上述代码中,第3行是实例化一个KernelPCA类对象,其中n_components用于指定主成分的数量,kernel用于指定对应的核函数,gamma为高斯核函数中的参数。第4~14行是分别对未降维、用两个主成分和一个主成分表示的结果进行可视化。
最后,上述代码运行结束后将会得到如图12-18所示的结果。
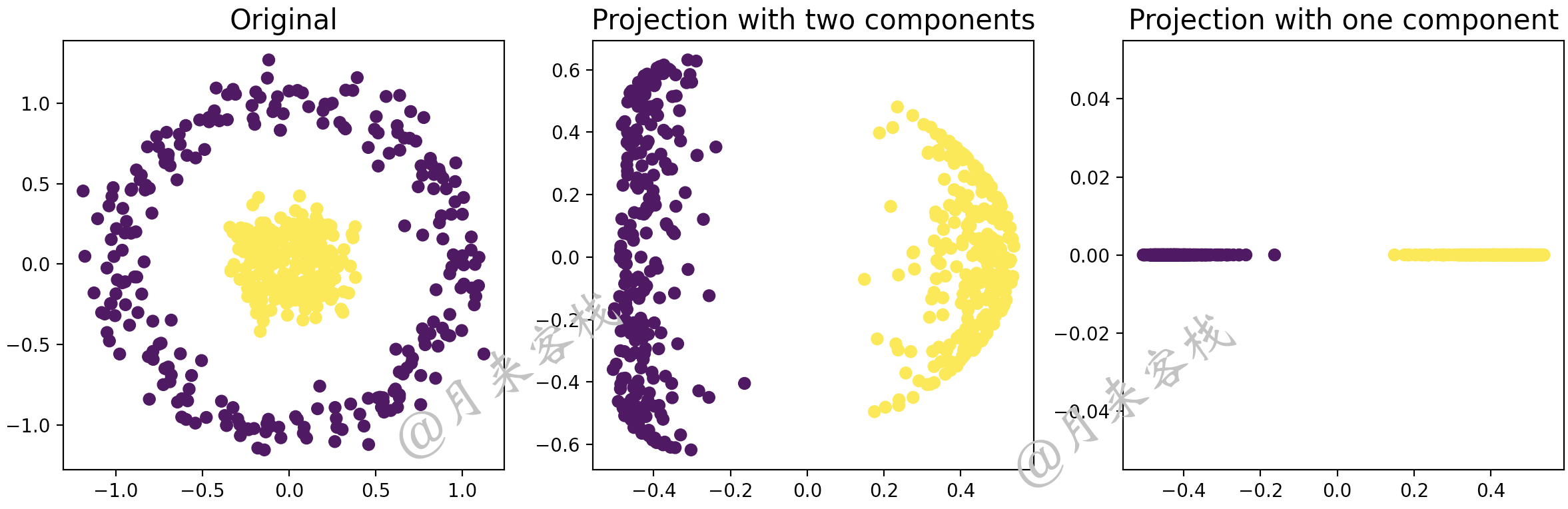
上述可视化及示例代码可参见 AllBooKCode/Chapter12/C06_KPCA_train.py 文件。
12.2.3 KPCA算法原理#
在清楚了KPCA算法的思想之后,其背后的数学原理就变得十分清晰了。根据PCA算法的原理可知,对于任意数据集$X=\{{x^{(1)},x^{(2)},...,x^{(m)}}\}$来说需要求解的方程为
$$ \Sigma u = \lambda u\tag{12-16} $$其中
$$ \Sigma=\frac{1}{m}\sum_{i=1}^mx^{(i)}x^{(i)^T}=\frac{1}{m}X^T_{m\times n}X_{m\times n}\tag{12-17} $$最后根据协方差矩阵$\Sigma$求得其对应的特征值和特征向量,并选择前$k$个最大的特征值所对应的特征向量作为主成分进行降维即可。
对于KPCA算法来说,首先需要定义一个映射函数 $\phi(x)$ 将原始的低维向量 $x^{(i)}\in R^n$ 映射为高维向量 $\phi(x^{(i)})\in R^N$ ,其中 $n\ll N$ 。
假设在映射后的高维样本空间中,所有样本点的均值为0,即
$$ \mu=\frac{1}{m}\sum_{i=1}^m\phi(x^{(i)})=0\tag{12-18} $$根据式(12-17)可知,此时新的协方差矩阵为
$$ \overline{\Sigma}=\frac{1}{m}\sum_{i=1}^m\phi(x^{(i)})\phi(x^{(i)})^T\tag{12-19} $$进一步,根据式(12-11)可得
$$ \overline{\Sigma}v=\lambda v\tag{12-20} $$最后,只需要根据协方差矩阵$\overline{\Sigma}$求得对应的特征值和特征向量,并同样选择前$k$个最大的特征值所对应的特征向量作为主成分进行降维即可。同时,这里需要注意的是,当高维空间$N$的取值非常大时,直接求解协方差矩阵$\overline{\Sigma}$的特征值与特征向量将是一件非常困难的事情,因此就需要借助核函数来完成整个计算过程,这部分内容将在12.2.5内容中节进行介绍。不过核函数只是一个计算上的技巧,它并不影响对于KPCA算法的整体把握。
12.2.4 KPCA算法求解#
在介绍完KPCA算法的基本原理和在sklearn中的使用示例后,下面再来介绍KPCA算法的求解问题。
根据式(12-19)和式(12-20)可知
$$ \overline{\Sigma}v=\frac{1}{m}\sum_{i=1}^m\phi(x^{(i)})\phi(x^{(i)})^Tv=\lambda v\tag{12-21} $$进一步由式(12-21)可得
$$ v=\frac{1}{\lambda m}\sum_{i=1}^m\phi(x^{(i)})\phi(x^{(i)})^Tv=\frac{1}{\lambda m}\sum_{i=1}^m\left(\phi(x^{(i)})^T v\right)\phi(x^{(i)})^T\tag{12-22} $$其中对于式(12-22)右侧的变形过程如下
设$x=(x_1,x_2,...,x_n)^T$,$v=(v_1,v_2,...,v_n)^T$,则此时有
$$ \begin{aligned} xx^Tv &=\begin{pmatrix}x_1\\x_2 \\ \vdots \\ x_n \end{pmatrix}_{n\times1} \begin{pmatrix} x_1&x_2&\cdots&x_n\end{pmatrix}_{1\times n} \begin{pmatrix}v_1\\v_2 \\ \vdots \\ v_n \end{pmatrix}_{n\times 1} = \begin{pmatrix}x_1x_1v_1+x_1x_2v_2+&\cdots&+x_1x_nv_n\\x_2x_1v_1+x_2x_2v_2+&\cdots&+x_2x_nv_n \\ \vdots \\x_nx_1v_1+x_nx_2v_2+&\cdots&+x_nx_nv_n\end{pmatrix}_{n\times 1} \\[3ex] &= \begin{pmatrix}(x_1v_1+x_2v_2+&\cdots&+x_nv_n)x_1\\(x_1v_1+x_2v_2+&\cdots&+x_nv_n)x_2 \\ \vdots \\(x_1v_1+x_2v_2+&\cdots&+x_nv_n)x_n\end{pmatrix}_{n\times 1}=x^Tvx^T \end{aligned}\tag{12-23} $$由于$\phi(x^{(i)})^T v$只是一个标量,因此式(12-22)中的结果可以改写为
$$ v=\frac{1}{\lambda m}\sum_{i=1}^m\left(\phi(x^{(i)})^T v\right)\phi(x^{(i)})^T=\sum_{i=1}^m\alpha_i\phi(x^{(i)})\tag{12-24} $$即,特征向量实际为样本点的线性组合。
继续,将式(12-24)带入式(12-21)有
$$ \frac{1}{m}\sum_{i=1}^m\phi(x^{(i)})\phi(x^{(i)})^T\left(\sum_{l=1}^m\alpha_{jl}\phi(x^{(l)})\right)=\lambda_j \left(\sum_{l=1}^m\alpha_{jl}\phi(x^{(l)})\right)\tag{12-25} $$其中$\lambda_j$表示第$j$个特征值,$\alpha_{jl}$表示第$j$个特征向量中构成该向量的第 $l$ 个样本对应的系数,因为根据式(12-24)可知每一个特征向量都是$m$个样本的线性组合构成。
令$K_{ij}=\phi(x^{(i)})^T\phi(x^{(j)})$,此时式(12-25)可以改写为
$$ \frac{1}{m}\sum_{i=1}^m\phi(x^{(i)})\left(\sum_{l=1}^m\alpha_{jl}K_{il}\right)=\lambda_j \sum_{l=1}^m\alpha_{jl}\phi(x^{(l)})\tag{12-26} $$可以发现这里的 $K_{ij}$ 其实等价于式(12-17)中的 $\Sigma_{ij}$。进一步,在式(12-26)两边同时左乘$\phi(x^{(k)}),k=1,2,...,m$,此时有
$$ \begin{aligned} \frac{1}{m}\sum_{i=1}^m\phi(x^{(k)})^T\phi(x^{(i)})\left(\sum_{l=1}^m\alpha_{jl}K_{il}\right)&=\lambda_j \sum_{l=1}^m\alpha_{jl}\phi(x^{(k)})^T\phi(x^{(l)})\\[3ex] \sum_{i=1}^mK_{ki}\left(\sum_{l=1}^m\alpha_{jl}K_{il}\right)&=m\lambda_j \sum_{l=1}^m\alpha_{jl}K_{kl} \end{aligned}\tag{12-27} $$当$k=1$时,式(12-27)左边有
$$ \begin{aligned} \sum_{i=1}^mK_{ki}\left(\sum_{l=1}^m\alpha_{jl}K_{il}\right)=& \left(\alpha_{j1}K_{11}K_{11}+\alpha_{j2}K_{11}K_{12}+\cdots+\alpha_{jm}K_{11}K_{1m}\right)+\\ &\left(\alpha_{j1}K_{12}K_{21}+\alpha_{j2}K_{12}K_{22}+\cdots+\alpha_{jm}K_{12}K_{2m}\right)+\\ &\;\;\;\;\;\;\;\;\;\;\;\;\;\;\vdots\\ &\left(\alpha_{j1}K_{1m}K_{m1}+\alpha_{j2}K_{1m}K_{m2}+\cdots+\alpha_{jm}K_{1m}K_{mm}\right)\\[2ex] =&\begin{pmatrix} K_{11}&K_{12}&\cdots&K_{1m}\end{pmatrix} \begin{pmatrix} K_{11}&K_{12}&\cdots&K_{1m}\\ K_{21}&K_{22}&\cdots&K_{2m}\\ \vdots\\ K_{m1}&K_{m2}&\cdots&K_{mm} \end{pmatrix}\alpha_j \end{aligned}\tag{12-28} $$其中 $\alpha_j$ 是一个 $m$ 维的列向量。
式(12-27)右边有
$$ \begin{aligned} m\lambda_j \sum_{l=1}^m\alpha_{jl}K_{kl}&= m\lambda_j\left(\alpha_{j1}K_{11}+\alpha_{j2}K_{12}+\cdots\alpha_{jm}K_{1m}\right)\\ &=m\lambda_j\begin{pmatrix} K_{11}&K_{12}&\cdots&K_{1m}\end{pmatrix}\alpha_j \end{aligned}\tag{12-29} $$最后,当 $k=2,3,...,m$ 时可得
$$ \begin{aligned} \begin{pmatrix} K_{11}&K_{12}&\cdots&K_{1m}\\ K_{21}&K_{22}&\cdots&K_{2m}\\ \vdots\\ K_{m1}&K_{m2}&\cdots&K_{mm} \end{pmatrix} \begin{pmatrix} K_{11}&K_{12}&\cdots&K_{1m}\\ K_{21}&K_{22}&\cdots&K_{2m}\\ \vdots\\ K_{m1}&K_{m2}&\cdots&K_{mm} \end{pmatrix}\alpha_j=m\lambda_j\begin{pmatrix} K_{11}&K_{12}&\cdots&K_{1m}\\ K_{21}&K_{22}&\cdots&K_{2m}\\ \vdots\\ K_{m1}&K_{m2}&\cdots&K_{mm} \end{pmatrix}\alpha_j\\ \end{aligned}\tag{12-30} $$进一步,式(12-30)可以简写为
$$ K^2\alpha_j=m\lambda_jK\alpha_j\tag{12-31} $$其中 $K$ 是一个形状为 $m\times m $ 的矩阵。
当 $\lambda_j\neq0$ 时,式(12-31)可以改写为
$$ K\alpha_j=m\lambda_j\alpha_j\tag{12-32} $$根据式(12-32)便可以求解得到$\lambda_j$和$\alpha_j$。
由PCA算法的降维过程可知,任意样本点 $x^{(i)}$ 在特征向量(主成分) $v_j$ 上的投影(表示)为
$$ y_j=\phi(x^{(i)})^Tv_j=\sum_{l=1}^m\alpha_{jl}\phi(x^{(i)})^T\phi(x^{(l)})=\sum_{l=1}^m\alpha_{jl}K_{il}\tag{12-33} $$最后,只需要将 $\phi(x^{(i)})$ 在每个主成分上进行投影便可以得到降维后的表示。
同时,由于通常情况下 $\phi(x^{(i)})$ 并不满足 $0$ 均值的情况,所以需要对其进行标准化处理,即
$$ \widetilde{\phi}(x^{(i)})=\phi(x^{(i)})-\frac{1}{m}\sum_{k=1}^m\phi(x^{(k)})\tag{12-34} $$进一步有
$$ \begin{aligned} \widetilde{K}_{ij}&=\widetilde{\phi}(x^{(i)})^T\widetilde{\phi}(x^{(j)})\\[2ex] &=\left(\phi(x^{(i)})-\frac{1}{m}\sum_{k=1}^m\phi(x^{(k)})\right)^T\left(\phi(x^{(j)})-\frac{1}{m}\sum_{k=1}^m\phi(x^{(k)})\right)\\[2ex] &=K_{ij}-\frac{1}{m}\sum_{k=1}^mK_{ik}-\frac{1}{m}\sum_{k=1}^mK_{kj}+\frac{1}{m^2}\sum_{k=1}^m\sum_{l=1}^mK_{kl} \end{aligned}\tag{12-35} $$将式(12-35)写成矩阵形式为
$$ \widetilde{K}=K-K1_L-1_{L}K+1_LK1_L\tag{12-36} $$其中 $1_L$ 是一个形状为 $m\times m$ 的全为$\frac{1}{m}$ 矩阵。
同时,根据式(12-36)可知,$K1_L$ 的含义是对矩阵 $K$ 在行上求平均,$1_{L}K$ 是对矩阵 $K$在列上求平均,$1_LK1_L$ 是对矩阵 $K$ 中的所有元素求平均。此处便可以看出, $\widetilde{K}$ 在实际编码实现的时候除了根据式(12-36)中的方法直接计算以外,还可以分别按定义计算每个部分,然后再计算最后的结果,而后一种计算方法更加广义。从式(12-35)可以看出,也正是因为有零均值这一步,所以才顺理成章地引入了核函数。
例如
$$ \begin{aligned} &\begin{pmatrix} 4&2\\2&1 \end{pmatrix}\times \begin{pmatrix} \frac{1}{2}&\frac{1}{2}\\\frac{1}{2}&\frac{1}{2} \end{pmatrix}=\begin{pmatrix} 3&3\\\frac{3}{2}&\frac{3}{2} \end{pmatrix}\\[2ex] &\begin{pmatrix} \frac{1}{2}&\frac{1}{2}\\ \frac{1}{2}&\frac{1}{2} \end{pmatrix}\times \begin{pmatrix} 4&2\\2&1 \end{pmatrix}\times \begin{pmatrix} \frac{1}{2}&\frac{1}{2}\\ \frac{1}{2}&\frac{1}{2} \end{pmatrix}=\begin{pmatrix} \frac{9}{4}&\frac{9}{4}\\\frac{9}{4}&\frac{9}{4} \end{pmatrix} \end{aligned}\tag{12-37} $$最后,对于 KPCA 算法的求解过程可总结为如下4步:
第1步:选择一个核函数;
第2步:根据式(12-36)构造一个去中心化后的核矩阵(Kernel Matrix) $\widetilde{K}$ ;
第3步:根据式(12-38)计算 $\widetilde{K}$ 对应的特征值和特征向量:
$$ \widetilde{K}\alpha_i=\lambda_i\alpha_i\tag{12-38} $$第4步:根据式 (12-39) 计算得到任意样本 $x^{(i)}$ 在第 $j$ 个主成分投影后的向量表示:
$$ y_j=\sum_{l=1}^m\alpha_{jl}\widetilde{K}_{il},j=1,2,...,d\tag{12-39} $$即
$$ Y_{m\times d}=\widetilde{K}_{m\times m}\alpha^T_{d\times m}\tag{12-40} $$需要注意的是式(12-39)和式(12-40)中的 $\widetilde{K}$ 在训练集和测试集上有所不同,细节之处详见后续代码实现。
12.2.5 常见核函数#
通过核函数我们便能够快速计算得到两个原始特征向量映射到高维空间后并进行内积计算后的结果。同时,在实际解决问题的时候甚至都不用关心核函数的映射规则是什么,也就是说不需要我们知道映射后的高维空间,只需要正确选用核函数实现目的即可。更多关于核函数的详细内容可以参见10.8节内容,这里就不再赘述。
12.2.6 从零实现KPCA算法#
在详细介绍完KPCA算法的具体原理之后再来看如何动从零手实现这一算法。以下完整示例代码可参见 AllBooKCode/Chapter12/C07_KPCA_imp.py 文件。
1. 矩阵 $\widetilde{K}$ 求解
根据12.2.4节内容可知,首先需要选择一个核函数并计算得到矩阵 $K$并进一步根据式(12-36)计算得到$\widetilde{K}$ 。在这里可以借助sklearn中的pairwise_kernels函数来完成矩阵 $K$ 的计算,示例代码如下:
1 class MyKernelPCA(object):
2 def __init__(self, n_components=None, kernel='linear',
3 gamma=2., degree=3, coef0=1.):
4 self.n_components = n_components
5 self.kernel = kernel
6 self.gamma = gamma
7 self.degree = degree
8 self.coef0 = coef0
9
10 def _get_center_kernel(self, X, Y=None):
11 params = {"gamma": self.gamma, "degree": self.degree, "coef0": self.coef0}
12 K = pairwise_kernels(X, Y, metric=self.kernel, filter_params=True, **params)
13 if Y is None:
14 l_mat = np.ones(K.shape) / K.shape[0]
15 KM = K - (K @ l_mat) - (l_mat @ K) + ((l_mat @ K) @ l_mat)
16 else:
17 row_mean = (np.sum(K, axis=1) / K.shape[0])[:, None]
18 col_mean = np.sum(K, axis=0) / K.shape[0]
19 all_mean = np.sum(row_mean) / K.shape[0]
20 KM = K - col_mean - row_mean + all_mean
21 return KM在上述代码中,第2~3行为初始化方法,其中第4行是指定主成分数量,默认None即保留所有主成分。第5行是指定核函数类型,有'linear'、'poly'、'rbf',和'sigmoid',即分别对应10.8.4节中的4个核函数。第6~8行分别是这4个核函数中的$\gamma$、$d$和$r$。第10行是指定计算核矩阵 $K$ 时用到的样本,其中在训练阶段 X 即为训练样本 Y=None,在预测阶段时 X 即为新样本 Y 为训练集样本。因为投影时的主成分是通过训练集样本的核矩阵计算得出,它包含了数据在高维特征空间中的方差信息,因此测试样本必须同样被映射到由训练集定义的主成分空间中,而这种映射是通过计算测试样本和训练集样本间的核矩阵得到。第11行是相关参数的取值。第12行是调用 pairwise_kernels 函数来实现核矩阵 $K$ 的计算,其中**params的含义是将params以关键字参数gamma=self.gamma这样的形式传入函数。第13~15行是在训练阶段通过式(12-36)来计算去中心化后的核矩阵 $\widetilde{K}$ 。 第17~20行是在预测阶段根据式(12-36)的原始定义来计算 $\widetilde{K}$ ,这是因为预测阶段计算得到的核矩阵 $K$ 不是方阵所以不能通过式(12-36)来直接进行计算。
2. 特征值特征向量求解
在获取得到矩阵 $\widetilde{K}$ 之后便可以来计算对应的特征值和特征向量,示例代码如下:
1 def fit(self, X):
2 self._X = X
3 self.KM = self._get_center_kernel(X)
4 w, v = np.linalg.eigh(self.KM) # 计算特征值和特征向量
5 idx = np.argsort(w)[::-1] # 获取特征值降序排序的索引
6 self.lambdas_ = w[idx] # [k,] 进行降序排列
7 self.alphas_ = v[:, idx][:, :self.n_components] # 排序
8 return self在上述代码中,第2行是得到训练集X的引用,因为在新样本进行降维时需要计算新样本与训练样本所构成的核矩阵,其形状为[n_samples,n_features]。第3行是根据训练集计算矩阵得到去中心化后的核矩阵 $\widetilde{K}$。第4~7行是计算核矩阵对应的特征值和特征向量,并按特征值大小进行排序取前n_components个特征向量,其中 v[:,i]表示特征值 w[i] 所对应的特征向量。
3. 降维处理
在计算得到主成分之后,便可以根据式(12-36)来计算得到降维后的结果,示例代码如下:
1 def fit_transform(self, X):
2 self.fit(X)
3 # [n_samples,n_samples] @ [n_samples,n_components]
4 return np.matmul(self.KM, self.alphas_)对于测试集来说,需要先计算测试样本与训练样本构造的核矩阵,再根据式(12-39)计算得到降维后的结果,示例代码如下:
1 def transform(self, X):
2 KM = self._get_center_kernel(X, self._X)
3 # KM: [n_test_samples, n_train_samples]
4 return np.matmul(KM, self.alphas_)在第2行中,因为训练和测试阶段的核矩阵需要在相同的特征空间中,所以测试样本需映射到由训练样本定义的核主成分空间,因而需要计算测试样本与训练样本之间的核矩阵。
到此,对于整个KPCA算法的实现部分就介绍完了,下面来看使用示例。
4. 使用示例
在实现完整个降维过程后, 便可以通过如下所示的代码来进行测试。首先需要构造一个类似图12-13所示的模拟数据集,示例代码如下:
1 def make_nonlinear_cla_data():
2 num_points = 1000
3 x, y = make_circles(n_samples=num_points, factor=0.2, noise=0.1,
4 random_state=np.random.seed(10))
5 x_train, x_test, y_train, y_test = \
6 train_test_split(x, y, test_size=0.3, random_state=2020)
7 return x_train, x_test, y_train, y_test进一步,定义一个函数来对比MyKernelPCA和sklearn中KernelPCA模块的降维结果,示例代码如下:
1 def comp():
2 x_train, x_test, y_train, y_test = make_nonlinear_cla_data()
3 my_kernel_pca = MyKernelPCA(n_components=2, kernel='rbf', gamma=11.)
4 my_kernel_pca.fit(x_train)
5 x_d = my_kernel_pca.transform(x_test)
6 plt.figure(figsize=(8, 4))
7 plt.subplot(1, 2, 1)
8 plt.title("MyKernelPCA on test data")
9 plt.scatter(x_d[:, 0], x_d[:, 1], c=y_test)
10
11 kernel_pca = KernelPCA(n_components=2, kernel='rbf', gamma=11.)
12 kernel_pca.fit(x_train)
13 x_d = kernel_pca.transform(x_test)
14 plt.subplot(1, 2, 2)
15 plt.title("KernelPCA on test data")
16 plt.scatter(x_d[:, 0], x_d[:, 1], c=y_test)
17 plt.tight_layout()
18 plt.show()在上述代码中,第2行是载入模拟数据。第3~4行是用训练集来拟合模型(计算核矩阵和特征向量)。第5行是对测试样本进行成分分析。第6~9行则是将降维后的结果进行可视化。第11~18行则是进行类似的处理。
最后,上述代码运行结束后将会得到如图12-19所示的结果。
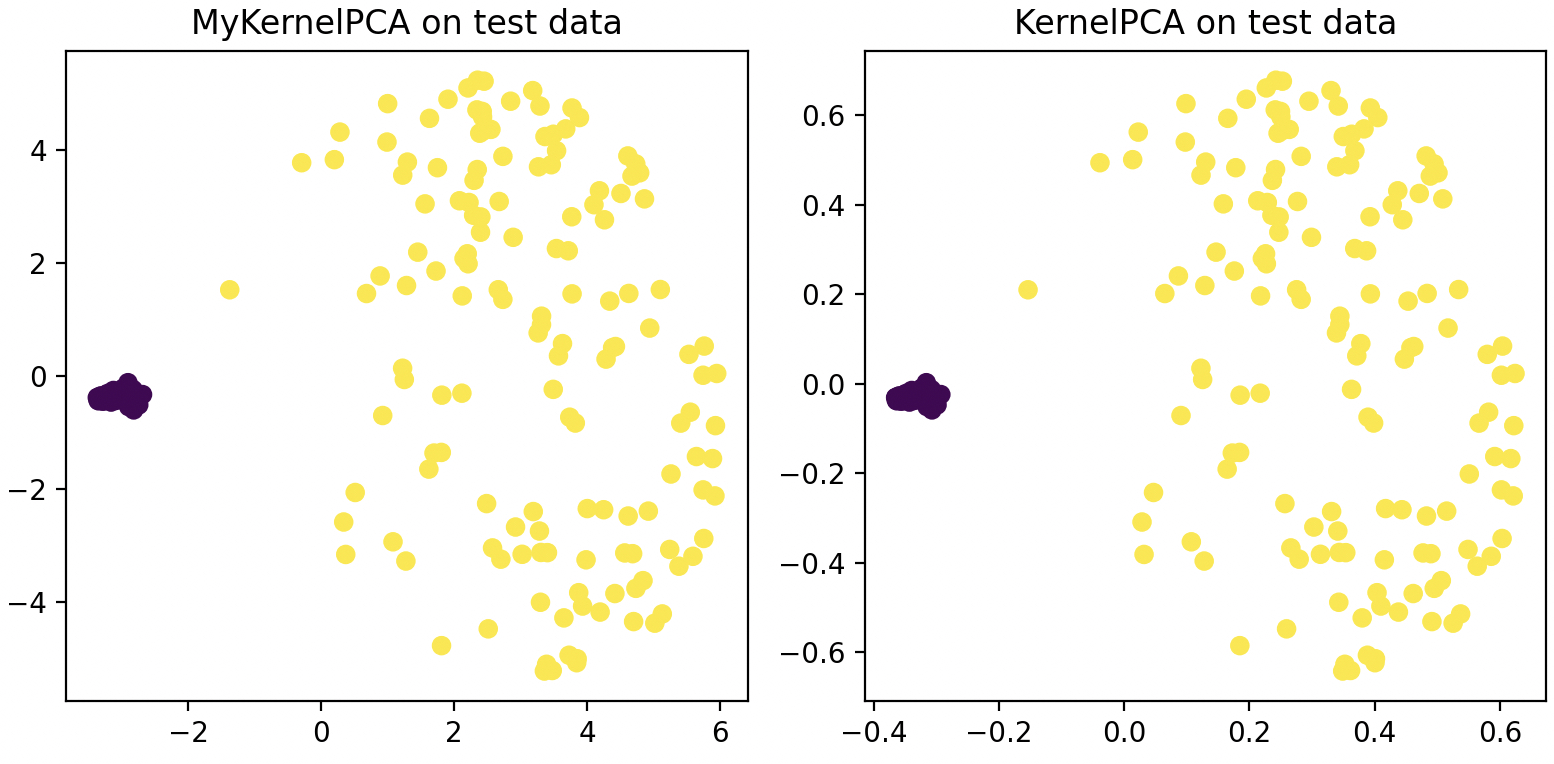
从图12-19可以看出,两者在投影后的结果上基本没有太大差别,如果选择只通过一个主成分进行表示便可以得到类似图12-18中的结果。到此,对于整个KPCA算法的原理及实现过程就介绍完了。
12.2.7 小结#
在本节内容中,我们首先介绍了引入KPCA算法的动机,并介绍了其背后的基本思想;然后介绍了KPCA算法的基本原理和在sklearn中的使用示例;最后详细介绍了KPCA算法的求解过程以及如何自己动手实现KPCA算法,并同sklearn中的KernelPCA进行了对比。到此,对于常见的两种PCA降维算法就算是介绍完了。
总结一下,在本章中,我们首先介绍了什么是降维以及为什么需要对数据进行降维处理,接着介绍了两种常见的分别用于处理线性和非线性数据的降维算法PCA和KPCA,包括其基本原理、如何通过sklearn进行建模、具体的参数求解证明过程等;最后详细介绍了如何自己动手来实现这两种算法模型,并对其进行了验证。
引用#
[1] Schölkopf B, Smola A, Müller K R. Kernel principal component analysis[C]//International conference on artificial neural networks. Springer, Berlin, Heidelberg, 1997: 583-588.
https://en.wikipedia.org/wiki/Kernel_principal_component_analysis
[2] https://sebastianraschka.com/Articles/2014_kernel_pca.html
[3] http://www.cs.haifa.ac.il/~rita/uml_course/lectures/KPCA.pdf
[4] https://nanohub.org/resources/32712/download/2020.01.31-ECE595ML-L07.2.pdf
[5] https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.KernelPCA.html