11.7 加权Kmeans聚类算法#
在前面几节内容中,我们首先介绍了Kmeans聚类算法的原理,然后介绍了一种基于Kmeans进行改进的Kmeans++聚类算法,该算法的改进点在于依次初始化K个簇中心,最大程度上使不同的簇中心彼此之间相距较远,从而避免了各个簇中心出现在同一簇中的情况。接下来,我们将继续介绍另外一种基于Kmeans改进的聚类算法——加权Kmeans聚类算法。如图11-13所示便是加权Kmeans聚类算法的学习路线图。
11.7.1 加权Kmeans算法思想#
想象一下这样一个场景,假设现在手中有一个数据集,里面包含3个特征维度,但是,对于簇结构起决定性作用的只有其中2个维度,也就是说其中有一个维度是噪声维度。在这种情况下采用Kmeans聚类算法进行聚类会产生什么样的结果呢?
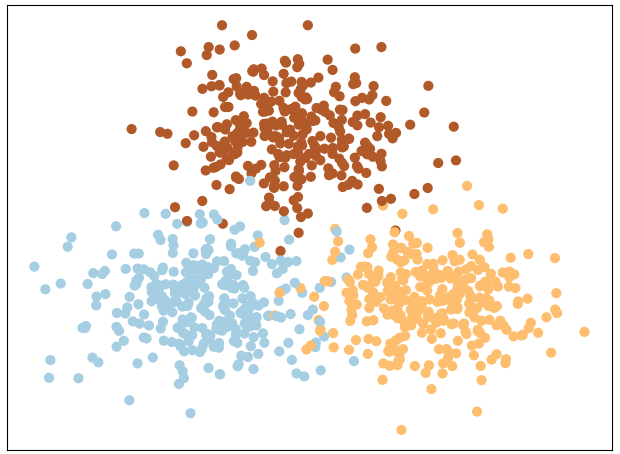
现在我们人为地来构造一个数据集,其一共包含3个明显的簇结构,可视化后的结果如图11-14所示。
进一步,在图11-14所示的数据集中再加入一个噪声维度,这样便得到了另外一个新的数据集,其可视化结果如图11-15所示,其中左右两边为不同视角下的结果。
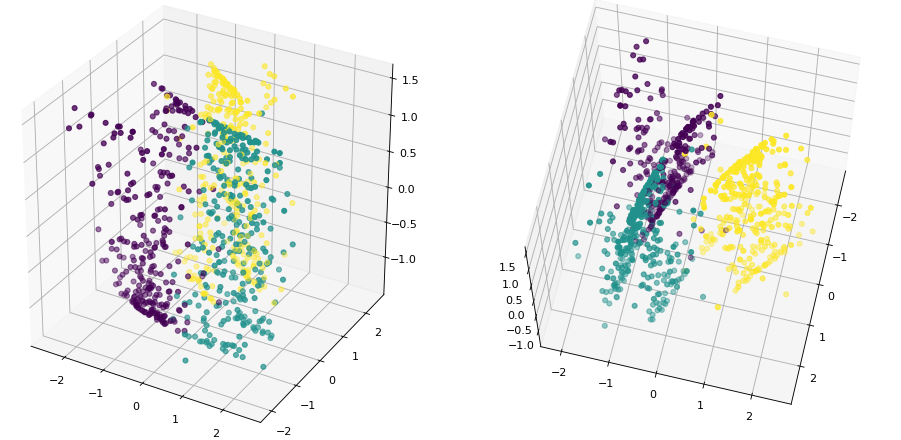
此时,对于图11-15中的结果,人眼几乎已经无法分辨其中所存在的簇结构。如果此时通过聚类对其进行聚类会出现什么样的结果呢?在通过Kmeans算法对其进行聚类后发现,此时的ARI结果已经从0.912骤然降到了0.721,完整示例代码可参见AllBooKCode/Chapter11/C09_visualization_wkmeans.py文件。为什么混入噪声维度后Kmeans聚类算法就不怎么管用了呢?
假如现在有两个簇中心$c_1=[2,3]$和$c_2=[3,5]$,样本点$x=[4,4]$。在这种情况下$d_{x{{c}_{1}}}^{2}=5$大于$d_{x{{c}_{2}}}^{2}=2$,因此样本点$x$应该被划入簇$c_2$中,但如果此时加入一列噪声维度,变成$c_1=[2,3,2]$和$c_2=[3,5,9]$,样本点变成$x=[4,4,1]$。那么在这样的情况下$d_{x{{c}_{1}}}^{2}=6$就会小于$d_{x{{c}_{2}}}^{2}=66$,此时$x$就会被错误地划分到簇$c_1$中。
可以发现,正是由于噪声维度的出现,使得Kmeans聚类算法在计算样本间的距离时把噪声维度所在的距离也一并地考虑到了结果中,最终导致聚类精度下降。有没有什么好的办法解决这个问题,使在聚类过程中尽量忽略噪声维度的影响呢?当然有,答案就是给每个特征维度赋予一个权重。
加权Kmeans聚类算法出自于2005年的一篇论文[1] 。这篇论文的核心思想就是给每个特征维度初始化一个权重值,等到目标函数收敛时噪声维度所对应的权重就会趋于0,从而使在计算样本间的距离时能够尽可能地忽略噪声维度的影响。
在上面的例子中,如果给算法
$$W=[w_1,w_2,w_3]=[0.49,0.49,0.02]$$这样一个特征权重,并且在计算样本间距离的时候考虑的是加权距离,则有
$$ \begin{aligned} & d_{x{{c}_{1}}}^{2}=0.49\times {{(4-2)}^{2}}+0.49\times {{(4-3)}^{2}}+0.02\times {{(1-2)}^{2}}=2.47 \\[1ex] & d_{x{{c}_{2}}}^{2}=0.49\times {{(4-3)}^{2}}+0.49\times {{(4-5)}^{2}}+0.02\times {{(1-9)}^{2}}=2.26 \end{aligned}\tag{11-28} $$此时可以发现,在特征权重的作用下,加权后的距离$d^2_{xc_1}$仍旧大于$d^2_{xc_2}$,$x$依然会被划分到簇$c_2$中,因此也就避免了被划分错误的情况。
11.7.2 加权Kmeans算法原理#
讲了这么多,那么加权Kmeans聚类算法是如何实现这个想法的呢?具体地,加权Kmeans聚类算法的目标函数为
$$ \begin{aligned} &P(U,Z,W)=\sum\limits_{p=1}^{k}{\sum\limits_{i=1}^{n}{{{u}_{ip}}}}\sum\limits_{j=1}^{m}{w_{j}^{\beta }}{{({{x}_{ij}}-{{z}_{pj}})}^{2}}\\[2ex] &\text{s}.\text{t}. \ \sum\limits_{p=1}^{k}{{{u}_{ip}}}=1,\ \sum\limits_{j=1}^{m}{{{w}_{j}}}=1 \end{aligned} \tag{11-29} $$从目标函数式(11-29)可以发现,相较于原始的Kmeans聚类算法,加权Kmeans聚类算法仅仅在目标函数中增加了一个权重参数$w^{\beta}_j$。它的作用在于,在最小化整个簇内距离时计算的是每个维度的加权距离和,即通过不同的权重值来调节每个维度对聚类结果的影响,并且,当$\beta=0$时,目标函数式(11-29)也就退化到了Kmeans聚类算法中的目标函数。
11.7.3 加权Kmeans算法迭代公式#
根据目标函数式(11-29)可知,其一共包含3个需要求解的参数$U$、$Z$和$W$。在这里,我们先直接给出每个参数的迭代计算公式,具体的求解过程将在11.7.4节中进行介绍。
1. 簇分配矩阵$U$
$$ {{u}_{ip}}=\begin{cases} 1, & w_{j}^{\beta }\sum\limits_{j=1}^{m}{{{({{x}_{ij}}-{{z}_{pj}})}^{2}}}\le w_{j}^{\beta }\sum\limits_{j=1}^{m}{{{({{x}_{ij}}-{{z}_{tj}})}^{2}}},\ \text{for }1\le t\le k \\[4ex] 0, & \text{其它} \\ \end{cases} \tag{11-30} $$从式(11-30)可以看出,其与Kmeans中簇分配矩阵计算方式的差别在于每个维度在计算距离时考虑了权重。
2. 簇中心矩阵$Z$
$$ {{z}_{pj}}=\frac{\sum\limits_{i=1}^{n}{{{u}_{ip}}}{{x}_{ij}}}{\sum\limits_{i=1}^{n}{{{u}_{ip}}}}\tag{11-31} $$可以发现,加权Kmeans聚类算法中的簇中心矩阵计算方法同Kmeans相比并没有发生变化。
3. 权重矩阵$W$
$$ {{w}_{j}}=\frac{1}{\sum\limits_{t=1}^{m}{{{\left[ \frac{{{D}_{j}}}{{{D}_{t}}} \right]}^{\frac{1}{\beta -1}}}}},\;\; \beta >1\text{或}\beta \le 0\tag{11-32} $$其中
$$ {{D}_{j}}=\sum\limits_{p=1}^{k}{\sum\limits_{i=1}^{n}{{{u}_{ip}}}}{{({{x}_{ij}}-{{z}_{pj}})}^{2}}\tag{11-33} $$可以看出,$D_j$其实就是所有样本点在第$j$个维度上的距离和。
在得到每个参数的迭代公式后,便可以写出整个加权Kmeans聚类算法的工作流程:
(1) 首先随机初始化K个簇中心,并初始化一个$m$维的权重向量。
(2) 然后根据式(11-30)计算每个样本点与初始化簇中心的相似度,并将该样本点划分到与之相似度最高的簇中心所对应的簇中。
(3) 根据式(11-31)重新计算每个簇的簇中心。
(4) 根据式(11-32)重新计算权重向量。
(5) 循环迭代步骤(2)~(4),直到目标函数收敛。
11.7.4 加权Kmeans参数求解#
通常,对于类Kmeans框架下的聚类算法,其各个参数的求解过程依赖于拉格朗日乘数法,因此,根据式(11-29)便可以得到如下拉格朗日函数
$$ \Phi (W,\alpha )=\sum\limits_{j=1}^{m}{w_{j}^{\beta }}{{D}_{j}}+\alpha \left( \sum\limits_{j=1}^{m}{{{w}_{j}}}-1 \right)\tag{11-34} $$接着分别对$W$和$\alpha$求导并令其为0,可得
$$ \frac{\partial \Phi }{\partial {{w}_{j}}}=\beta w_{j}^{\beta -1}{{D}_{j}}+\alpha =0\tag{11-35} $$$$ \frac{\partial \Phi }{\partial \alpha }=\sum\limits_{j=1}^{m}{{{w}_{j}}}-1=0\tag{11-36} $$根据式(11-35)可得
$$ {{w}_{j}}={{\left( \frac{-\alpha }{\beta {{D}_{j}}} \right)}^{\frac{1}{\beta -1}}}\tag{11-37} $$将式(11-37)代入式(11-36)得
$$ \sum\limits_{j=1}^{m}{{{\left( \frac{-\alpha }{\beta {{D}_{j}}} \right)}^{\frac{1}{\beta -1}}}}=1\tag{11-38} $$根据式(11-38)有
$$ {{(-\alpha )}^{\frac{1}{\beta -1}}}=1/\left[ \sum\limits_{t=1}^{m}{{{\left( \frac{1}{\beta {{D}_{t}}} \right)}^{\frac{1}{\beta -1}}}} \right]\tag{11-39} $$将式(11-39)代入式(11-37)即可得到式(11-32)。
由此便得到了$W$的迭代计算公式,同时对于超参数$\beta$的取值直接使用交叉验证即可,在这里就不再叙述了。
11.7.5 从零实现加权Kmeans算法#
根据前面几节内容的介绍可以发现,对于一个类Kmeans算法的实现,其实只需实现其对应的迭代更新公式,然后将其以Kmeans聚类算法类似的流程进行调用即可,因此这里只需介绍式(11-32)的实现方法,完整示例代码可参见 AllBooKCode/Chapter11/C10_wkmeans.py 文件,示例代码如下:
1 def computeWeight(X, centroid, idx, K, belta):
2 n, m = X.shape
3 weight = np.zeros(m, dtype=float)
4 D = np.zeros(m, dtype=float)
5 for k in range(K):
6 index = np.where(idx == k)[0]
7 temp = X[index, :] # 取第k个簇的所有样本
8 distance2 = np.power((temp - centroid[k, :]), 2)
9 D = D + np.sum(distance2, axis=0)#所有样本同一维度的距离和
10 e = 1 / float(belta - 1)
11 for j in range(m):
12 temp = D[j] / D
13 weight[j] = 1 / np.sum((np.power(temp, e)))
14 return weight在上述代码中,第3~4行用来初始化两个全0的向量,分别用来保存权重向量和中间变量$D$。第5~9行是取每个簇中的所有样本并计算每个维度的累加和。第11~13行分别用来计算权重向量的每个维度。
至此,就可以通过加权Kmeans聚类算法来对包含噪声维度的数据集进行聚类,示例代码如下:
1 if __name__ == '__main__':
2 x, y, x_noise = make_data()
3 y_pred = wkmeans(x, 3, belta=3)
4 ARI = adjusted_rand_score(y, y_pred)
5 print("ARI without noise: ", ARI) # 0.912
6 y_pred = wkmeans(x_noise, 3, belta=3)
7 ARI = adjusted_rand_score(y, y_pred)# 0.902
8 print("ARI with noise : ", ARI)从最后的结果来看,加权Kmeans聚类算法在不含有噪声维度及含有噪声维度的数据集上的ARI指标分别为0.912和0.902,可以发现两者在结果上几乎相差无几。同时,对比于Kmeans聚类得到的结果,加权Kmeans聚类算法在处理这类包含噪声维度的数据集中,有着明显的优势。
11.7.6 小结#
在本节中,我们首先通过一个引例介绍了什么是含有噪声维度的数据集以及为什么加入噪声维度后Kmeans聚类算法的精度就会下降,由此引入了基于权重的加权Kmeans聚类算法;然后介绍了加权Kmeans聚类算法的思想,并通过一个简单的示例进行了说明;进一步详细介绍了加权Kmeans算法的原理及求解过程;最后介绍了如何从零开始实现加权Kmeans算法,并通过含噪音和不含噪音的两个数据集进行了实验对比。在下一节内容中将开始介绍聚类算法中的第2种评价指标体系。
引用#
[1] J.Z.Huang,Automated variable weighting in kmeans type clustering,in IEEE Transactions on Pattern Analysis and Machine Intelligence.