9.9 NMT网络#
在「第9.7节 Seq2Seq教程:编码器解码器结构与序列生成」内容中,我们大致介绍了Seq2Seq架构的思想和基本原理,它通过编码器将源输入编码成一个固定维度的中间向量,然后再依靠解码器将这一中间向量解码成任务需要的目标序列。同时,这种序列到序列的网络架构也使得我们可以采用不同的网络模型来作为编码器和解码器使用,例如除了到目前为止我们已经介绍过的DNN、CNN和RNN之外,也可以是在第10章中将要介绍的自注意力模块等。在接下来的这节内容中,我们将会探索以LSTM模型为编码器和解码器的神经机器翻译模型(Neural Machine Translation, NMT)背后的原理及其实现过程。本节内容的完整示例代码可参见Code/Chapter09/C07_NMT文件夹。
9.9.1 谷歌翻译简介#
为了让每一个人都能访问世界上的所有信息,谷歌公司在2006年4月推出了一项基于统计机器方法的语言翻译模型(Statistical Machine Translation, SMT)。在SMT模型中,输入文本必须要先翻译成英语作为中转,然后再将其翻译成对应的目标语言,因此这也导致在不同语言中翻译结果的准确性差异很大[1]。
随着深度学习技术的迅猛发展,谷歌公司于2014年提出了一种基于Seq2Seq架构的序列学习模型,并且尝试将其应用于NMT这一任务中[2]。但是由于该模型在翻译质量、推理速度和处理低频词等方面的效果并没有得到显著提升,因此并没有将其运用于实际的翻译服务中[3]。不过由于Seq2Seq模型在网络结构上的独特优势——编码器直接将源输入编码成一个向量,然后解码器再将其解码为对应的目标序列,从而避免了事先将源输入分割成不同粒度的短语而导致的翻译结果不流畅的问题——研究人员一直在尝试通过各种方法提高NMT模型的效果。直到2016年,谷歌公司又基于Seq2Seq的NMT模型提出了GNMT模型来解决上述问题,并将其运用在了谷歌翻译服务中[4]。
值得一提的是随着自注意力机制(Self-Attention)的出现以及其强大的编码能力,谷歌公司也于2020年将其翻译服务中Seq2Seq的编码器部替换成了Transform中的Encoder模块(相关内容将在第10章中进行详细介绍),而解码器部分则依旧使用的是RNN模块,其主要原因在于使用RNN作为解码器在推理时的速度要远快于Transform中的Decoder模块[5]。
谷歌神经机器翻译作为一种先进的机器翻译技术,对于改进跨语言交流和信息传播有着重要的作用。它使得机器翻译在很多情况下能够产生更流畅、准确的翻译结果,同时也是深度学习在自然语言处理领域成功应用的一个典型案例。截至2023 年8 月,谷歌翻译已经提供了超过133种语言的翻译服务,每天服务用户超5亿人[1]。
9.9.2 统计翻译模型弊端#
尽管传统基于短语的统计翻译模型在翻译任务中有着不错的表现,但是却一直存在着一些难以克服的弊端。由于这类模型需要将输入划分成不同粒度的短语进行翻译,所以会导致最后翻译的结果在语义上并不连贯,同时也会使得在长文本翻译过程中无法解决上下文的长依赖问题容易出现局部翻译化的现象[6]。同时,这类模型需要人工设计和提取大量的特征,例如词频、短语对齐等,这些过程比较繁琐且依赖于专业知识因此并不具有良好的可扩展性,每换一种翻译场景都需要重新开始构建统计模型。
鉴于上述原因,基于神经网络的机器翻译模型开始引起了研究人员的注意,而谷歌公司苏茨克维尔(Sutskever)等人于2014年也提出了一种基于LSTM的神经网络机器翻译模型[2]。在第9.7节内容中我们已经大致介绍了这一模型的思想和基本原理,接下来我们再以一个真实的翻译任务为例来详细介绍NMT模型的具体工作原理。
9.9.3 NMT数据集构建#
在这里我们使用到的是一组英德翻译平行语料,一共包含有 6 个文件train.de、train.en、val.de、 val.en、test_2016_flickr.de 和test_2016_flickr.en,其分别为德语训练语料、英语训练语料、德语验证语料、英语验证语料、德语测试语料和英语测试语料。同时, 这三部分的样本量分别为 29000、1014 和 1000 条。
如下所示便是一条平行预料数据,其中第 1 行为德语,第 2 行为英语,后续我们需要完成的是搭建一个翻译模型将德语翻译为英语。
1 Zwei junge weiße Männer sind im, Freien in der Nähe vieler Büsche.
2 Two young, White males are outside near many bushes.1. 数据集预览
在正式介绍如何构建数据集之前,我们先通过一张图来简单了解一下整个构建流程,以便更加清楚后续的构建流程及代码实现。
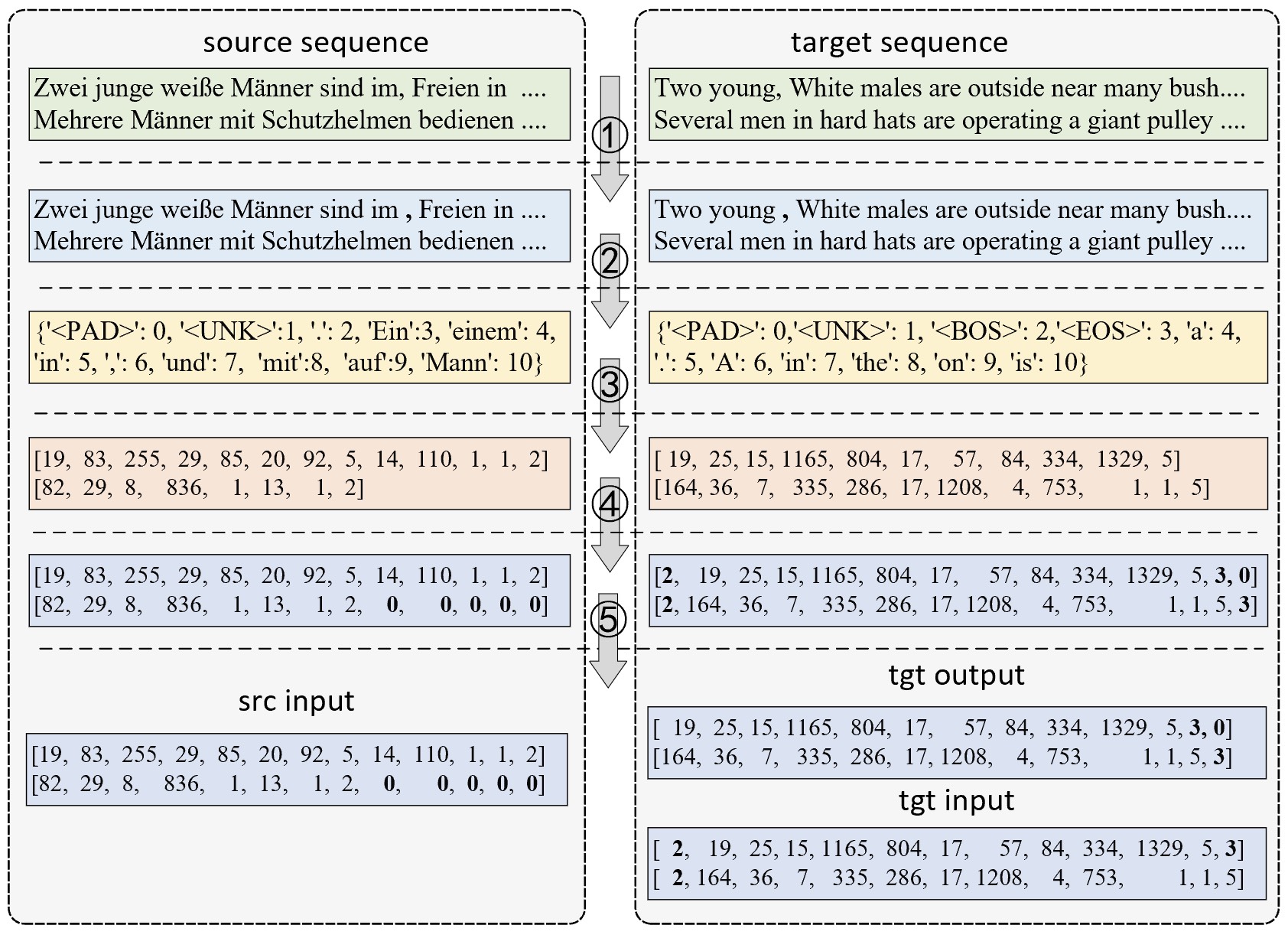
如图9-20所示,左边部分为源序列,右边部分为目标序列。从图9-20可以看出,第①步需要对原始语料进行切分(Tokenize)处理,如果是对类似英文这样的语料进行处理,最简单的就是直接按空格切分即可,但注意的一点是要把其中的标点符号也切分出来。第②步则是根据源语料和目标语料切分后的字符分别构建一个词表。第③步是将切分后的字符根据词表中的索引将其转换成对应的索引序列。第④步是对同一个小批量中的样本进行填充(Padding)处理,通常情况下以最长样本的长度进行填充,如果是对目标序列进行处理则还需要在首尾分别加上<BOS>和<EOS>特殊符。第⑤步则是分别得到编码器的源输入、解码器的目标输入和目标输出,其中目标输入和目标输出是分别取前$n-1$个字符和后$n-1$个字符($n$表示目标序列长度)。
2. 定义Tokenizer
首先我们需要对原始文本序列进行切分处理,即对应图9-20中的第①步。通常来说即使是对于同一种语料来说也有着不同的切分方式,例如「第9.6节 fastText原理:高效文本分类与词向量建模」中的子词也算是一种切分方式,因此这也会导致最后训练得到的翻译模型彼此之间会存有差异。这里我以torchtext库中的get_tokenizer方法来进行切分并构建数据集,示例代码如如下所示:
1 from torchtext.data.utils import get_tokenizer
2 def my_tokenizer():
3 tokenizer = {}
4 tokenizer['src'] = get_tokenizer('spacy', language='de_core_news_sm')
5 tokenizer['tgt'] = get_tokenizer('spacy', language='en_core_web_sm')
6 return tokenizer在上述代码中,第4~5行分别得到了源序列和目标序列对应的切分器并存放在一个字典中。需要注意的是,使用get_tokenizer()函数来获取切分器需要安装spacy、de_core_news_sm和en_core_web_sm这3个Python包,可在代码工程中获取。当然,如果需要使用其它切分器则只需要将4~5行代码替换并同样将其存放在字典中即可。
3. 建立词表
在介绍完词切分的实现方法后接下来就需要实现一个Vocab类来根据语料构建词表,即对应图9-20中的第②步,示例代码如下所示:
1 class Vocab(object):
2 def __init__(self, tokenizer, file_path, min_freq=5, top_k=None, specials=None):
3 if specials is None:
4 specials = ['<PAD>', '<UNK>', '<BOS>', '<EOS>']
5 self.specials = specials
6 self.tokenizer = tokenizer
7 self.file_path = file_path
8 self.min_freq = min_freq
9 self.top_k = top_k
10 self.stoi = {token: idx for idx, token in enumerate(specials)}
11 self.itos = specials[::]
12 self.build_vocab()在上述代码中,第2行中 tokenizer表示传入的切分器,file_path表示语料的路径,min_freq表示考虑的最小词频,top_k表示只取前top_k个字符来构建词表,specials表示指定特殊字符。这里需要注意的是,当top_k不为None时则min_freq参数无效,会直接取前top_k个词构建词表;当top_k为None时,则以min_freq进行过滤并构建词表。第10行表示字符到索引的映射,为一个字典。第11行表示索引到字符的映射,为一个列表。第12行则是开始构建词表,实现代码如下所示:
1 def build_vocab(self):
2 vocab = self._build_vocab(file_path=self.file_path)
3 if self is not vocab:
4 for k, v in self.__dict__.items():
5 self.__dict__[k] = deepcopy(vocab.__dict__[k])
6 del vocab在上述代码中,第2行代码是根据语料所在路径来构建词表。第3~6行是将本地已经持久化保存的词表赋值到当前的实例化对象中。对于_build_vocab()方法,其实现代码如下所示:
1 @process_cache(unique_key=['min_freq', 'top_k'])
2 def _build_vocab(self, file_path=None):
3 counter = Counter()
4 with open(file_path, encoding='utf8') as f:
5 for string_ in f:
6 string_ = string_.strip()
7 counter.update(self.tokenizer(string_))
8 if self.top_k is not None:
9 top_k_words = counter.most_common(self.top_k - len(self.specials))
10 else:
11 top_k_words = counter.most_common()
12 for i, word in enumerate(top_k_words):
13 if word[1] < self.min_freq and self.top_k is None:
14 break
15 self.stoi[word[0]] = i + len(self.specials)
16 self.itos.append(word[0])
17 return self在上述代码中,第1行是对已经构建完成的词表进行本地持久化,详细介绍可见「第5.7节 训练数据预处理与缓存:提升深度学习训练效率」内容。第3行是初始化一个计数器用于统计每个字符出现的频率。第4~7行是遍历原始语料中的每一行,并进行切分和字符频率计数。第8~9行是当top_k不为None时则取前top_k个字符构建词表。第10~14行则是以最小词频进行过滤。第15~16行是开始构建字符与索引的映射关系。
最后,可以通过如下方式来构建词表:
1 if __name__ == '__main__':
2 path_de = os.path.join(DATA_HOME, 'GermanEnglish', 'train_.de')
3 tokenizer = my_tokenizer()
4 vocab = Vocab(tokenizer['src'], file_path=path_de, min_freq=2, top_k=None)
5 logging.info(vocab.stoi)
6 logging.info(vocab.itos)上述代码运行结束后可以得到类似如下结果:
1 {'<PAD>': 0,'<UNK>': 1,'<BOS>': 2,'<EOS>': 3,'.': 4,'Männer': 5,'in': 6,'ein': 7,'Zwei': 8,'Ein': 9,'und': 10}
2 ['<PAD>','<UNK>','<BOS>','<EOS>','.','Männer', 'in', 'ein', 'Zwei', 'Ein', 'und']4. 定义数据集构造类
进一步,我们需要定义一个类,并在类的初始化过程中根据训练语料完成词表的构建,示例代码如下所示:
1 class LoadEnglishGermanDataset():
2 DATA_DIR = os.path.join(DATA_HOME, 'GermanEnglish')
3 DATA_FILE_PATH = {'train': {'src': os.path.join(DATA_DIR, 'train.de'),
4 'tgt': os.path.join(DATA_DIR, 'train.en')},
5 'dev': {'src': os.path.join(DATA_DIR, 'val.de'),
6 'tgt': os.path.join(DATA_DIR, 'val.en')},
7 'test': {'src': os.path.join(DATA_DIR, 'test.de'),
8 'tgt': os.path.join(DATA_DIR, 'test.en')}}
9 CACHE_FILE_PATH = {'train': os.path.join(DATA_DIR, 'train'),
10 'dev': os.path.join(DATA_DIR, 'dev'),
11 'test': os.path.join(DATA_DIR, 'test')}
12 def __init__(self, batch_size=2, min_freq=2, src_top_k=None,
13 tgt_top_k=None, src_inverse=True, batch_first=True):
14 self.batch_size = batch_size
15 self.min_freq = min_freq
16 self.tgt_top_k = tgt_top_k
17 self.src_top_k = src_top_k
18 self.src_inverse = src_inverse
19 self.batch_first = batch_first
20 self.tokenizer = my_tokenizer()
21 self.src_vocab = Vocab(self.tokenizer['src'], self.DATA_FILE_PATH['train']['src'],
22 min_freq, src_top_k, ['<PAD>', '<UNK>'])
23 self.tgt_vocab = Vocab(self.tokenizer['tgt'], self.DATA_FILE_PATH['train']['tgt'],
24 min_freq, tgt_top_k,['<PAD>', '<UNK>', '<BOS>', '<EOS>'])
25 self.TGT_PAD_IDX = self.tgt_vocab['<PAD>']
26 self.TGT_BOS_IDX = self.tgt_vocab['<BOS>']
27 self.TGT_EOS_IDX = self.tgt_vocab['<EOS>']在上述代码中,第3~6行用于指定训练集、验证集和测试集的路径。第9~11行指定对应3部分预处理完成后的缓存路径。第14~20行则是指定相关的超参数,其中src_inverse表示是否将源输入序列逆序,因为实验表明逆序可以提升模型最后的效果[2]。第21~24行则是分别构建编码器和解码器对应的词表。第25~27行是从目标输入词表中得到特征字符对应的索引。
5. 转换为索引序列
在得到构建的词表后进一步需要实现一个方法来将原始文本序列转换为词表中对应的字符索引,即对应图9-20中的第③步。同时需要将预处理完成后的中间结果进行缓存,当使用同一组超参数加载数据集时直接返回缓存结果即可,示例代码如如下所示:
1 @process_cache(unique_key=['min_freq', 'src_top_k', 'tgt_top_k', 'batch_first'])
2 def data_process(self, file_path=None):
3 data_name = file_path.split(os.sep)[-1]
4 raw_src_iter = iter(open(self.DATA_FILE_PATH[data_name]['src'], encoding="utf8"))
5 raw_tgt_iter = iter(open(self.DATA_FILE_PATH[data_name]['tgt'], encoding="utf8"))
6 data = []
7 for (raw_src, raw_tgt) in tqdm(zip(raw_src_iter, raw_tgt_iter), ncols=80):
8 src_tokens = self.tokenizer['src'](raw_src.rstrip("\n"))
9 src_tensor_ = torch.tensor([self.src_vocab[token] for
10 token in src_tokens], dtype=torch.long)
11 tgt_tokens = self.tokenizer['tgt'](raw_tgt.rstrip("\n"))
12 tgt_tensor_ = torch.tensor([self.tgt_vocab[token] for
13 token in tgt_tokens], dtype=torch.long)
14 data.append((src_tensor_, tgt_tensor_))
15 return data在上述代码中,第1行表示将预处理后的结果进行缓存,且以列表中的超参数作为唯一索引。第3~5表示打开训练集、验证集或测试集对应的原始文件。第7行表示开始同时读取源输入和目标输入,其中tqdm显示读取过程中的进度条。第8~9行是将源序列进行切分处理并同时转换成词表中的索引。第14行则是将由源序列和目标序列构成的一个样本以元组的形式进行存放。
上述代码中在处理完成后可以得到类似如下结果:
1 [(tensor([19, 83, 255, 29, 85, 20, 92, 5, 14, 110, 1, 1, 2]),
tensor([19, 25, 15, 1165, 804, 17, 57, 84, 334, 1329, 5]))
2 (tensor([82, 29, 8, 836, 1, 13, 1, 2]),
tensor([164, 36, 7, 335, 286, 17, 1208, 4, 753, 1, 1, 5]))]对于每一行来说有两列,其中左边一列为原始序列的索引形式,右边一列就是目标序列的索引形式,每一行构成一个样本。
6. 填充处理
从上面的输出结果可以看出,无论是对于原始序列来说还是目标序列来说,在不同样本间其长度都不尽相同。但是在将数据输入到编码器或解码器时均需要保持同样的长度,因此在这里我们需要对索引序列进行填充处理。同时,需要注意的是通常情况下,在生成模型中模型训练时只需要保证同一个小批量里,所有原始序列等长,所有目标序列等长即可,也就是说不需要保证在整个数据集中所有样本都等长。
因此,在这里我们默认以每个小批量样本中,源序列和目标序列各自最长的样本为标准分别对其它样本进行填充处理,同时需要在目标序列的首尾分别加上特殊符号<BOS>和<EOS>,即对应图9-20中的第④步,示例代码如下所示:
1 def generate_batch(self, data_batch):
2 src_batch, tgt_batch = [], []
3 for (src_item, tgt_item) in data_batch:
4 if self.src_inverse:
5 src_item = torch.flip(src_item, dims=[0])
6 src_batch.append(src_item)
7 tgt_item = torch.cat([torch.tensor([self.TGT_BOS_IDX]), tgt_item,
8 torch.tensor([self.TGT_EOS_IDX])], dim=0)
9 tgt_batch.append(tgt_item)
10 src_batch = pad_sequence(src_batch, self.batch_first, None, self.TGT_PAD_IDX)
11 tgt_batch = pad_sequence(tgt_batch, self.batch_first, None, self.TGT_PAD_IDX)
12 return src_batch, tgt_batch在上述代码中,第3行是遍历函数data_process()返回结果中的每一个样本。第4~5行是对源序列进行逆序处理。第7~8行是在目标序列的首尾分别添加特殊字符。第10~11行则是对源序列和目标序列进行填充处理,其中关于pad_sequence()函数的详细介绍可以参见「第7.2.4节 时序数据建模:RNN 适合处理什么样的序列任务」内容,这里就不再赘述。第12行是返回每个小批量处理完成的样本。
7. 构造DataLoader与使用示
在经过前面6个步步骤的操作后整个数据集的构建就基本完成了,只需要再构造一个DataLoader迭代器即可,示例代码如下:
1 def load_train_val_test_data(self, is_train=False):
2 if not is_train:
3 test_data = self.data_process(self.CACHE_FILE_PATH['test'])
4 test_iter = DataLoader(test_data, batch_size=self.batch_size,
5 shuffle=False, collate_fn=self.generate_batch)
6 return test_iter
7 train_data = self.data_process(file_path=self.CACHE_FILE_PATH['train'])
8 val_data = self.data_process(file_path=self.CACHE_FILE_PATH['dev'])
9 train_iter = DataLoader(train_data, batch_size=self.batch_size,
10 shuffle=True, collate_fn=self.generate_batch)
11 valid_iter = DataLoader(val_data, batch_size=self.batch_size,
12 shuffle=False, collate_fn=self.generate_batch)
13 return train_iter, valid_iter在上述代码中,第3~4行是返回测试集对应的迭代器,其中shuffle表示是否将样本打乱,一般只需要打乱训练集中的样本即可。第7~12行则是分别返回训练集和验证集对应的迭代器。
最后,在完成类LoadEnglishGermanDataset所有的编码过程后便可以通过如下形式进行使用:
1 if __name__ == '__main__':
2 data_loader = LoadEnglishGermanDataset(batch_size=2, min_freq=2,src_inverse=False)
3 train_iter, valid_iter = data_loader.load_train_val_test_data(is_train=True)
4 for x, y in train_iter:
5 logging.info(x.shape) # torch.Size([2, 20])
6 logging.info(y.shape) # torch.Size([2, 22])在上述代码中,第2行表示以词频来过滤词表并以源输入顺序的方式来构建数据集。第3行是返回训练集和验证集对应的迭代器。
9.9.4 Seq2Seq实现#
根据图9-15可知,Seq2Seq模型整个包含编码器和解码器两个部分。因此下面先介绍如何分别实现这两个部分,然后再整合实现整个Seq2Seq模型。
1. 编码器实现
编码器主要由一个词嵌入层和一个RNN模型所构成,实现代码如下所示:
1 class Encoder(nn.Module):
2 def __init__(self, embedding_size, hidden_size, num_layers, vocab_size,
3 cell_type='LSTM', bidirectional=False, batch_first=True):
4 super(Encoder, self).__init__()
5 self.embedding_size = embedding_size
6 self.hidden_size = hidden_size
7 self.num_layers = num_layers
8 self.vocab_size = vocab_size
9 self.cell_type = cell_type
10 self.bidirectional = bidirectional
11 self.batch_first = batch_first
12 if cell_type == 'LSTM':
13 rnn_cell = nn.LSTM
14 elif cell_type == 'GRU':
15 rnn_cell = nn.GRU
16 self.token_embedding = nn.Embedding(self.vocab_size, self.embedding_size)
17 self.rnn = rnn_cell(self.embedding_size, self.hidden_size, self.num_layers,
18 self.batch_first)
19 def forward(self, src_input=None):
20 src_input = self.token_embedding(src_input)
21 output, final_state = self.rnn(src_input)
22 return output, final_state在上述代码中,第2~3行embedding_size表示源序列词嵌入的维度,hidden_size表示RNN隐藏向量的维度,num_layers表示RNN的层数,vocab_size表示词表的大小,cell_type表示指定LSTM或者GRU模型,bidirectional表示是否使用双向RNN,batch_first表示是否第1个维度为批大小。第16行是随机实例化一个词嵌入层,当然这里也可以根据「第9.5节 词向量微调使用:预训练词向量在下游任务中的应用」中介绍的方法来使用第三方词向量进行初始化。第17~18行是实例化一个RNN模型。第19~22行则是编码器对应的前向传播计算过程,其中输入src_input的形状为[batch_size, src_len],经过词嵌入层后为[batch_size, src_len, embedding_size],output的形状为[batch_size, src_len, hidden_size]。
2. 解码器实现
为了便于后续扩展包含有注意力机制的模块,所以这里我们将实现一个通用的解码器接口DecoderWrapper。在不含有注意力机制的情况下,整个解码器同样主要由一个词嵌入层和一个RNN模型所构成,实现代码如下所示:
1 class DecoderWrapper(nn.Module):
2 def __init__(self, embedding_size, hidden_size, num_layers, vocab_size,
3 cell_type='LSTM', decoder_type='standard', batch_first=True, dropout=0.):
4 super(DecoderWrapper, self).__init__()
5 self.embedding_size = embedding_size
6 self.vocab_size = vocab_size
7 self.cell_type = cell_type
8 self.attention_type = attention_type
9 self.hidden_size = hidden_size
10 self.num_layers = num_layers
11 self.batch_first = batch_first
12 self.dropout = dropout
13 self.token_embedding = nn.Embedding(self.vocab_size, self.embedding_size)
14 if cell_type == 'LSTM':
15 rnn_cell = nn.LSTM
16 elif cell_type == 'GRU':
17 rnn_cell = nn.GRU
18 self.rnn = rnn_cell(self.embedding_size, self.hidden_size, num_layers=self.num_layers,
19 batch_first=self.batch_first, dropout=self.dropout)上述代码整体上与编码器中的一致,所以这里就不再赘述,其中attention_type参数用来指定注意力机制的类型,将在「第9.11节 含注意力的NMT网络:注意力机制在翻译中的应用」内容中进行介绍。但是对于前向传播过程来说则输入值多了编码器输出这一部分,示例代码如下所示:
1 def forward(self, tgt_input=None, decoder_state=None,
2 encoder_output=None, src_key_padding_mask=None):
3 tgt_input = self.token_embedding(tgt_input)
4 if self.attention_type == 'standard':
5 outputs, decoder_state = self.rnn(tgt_input, decoder_state)
6 return outputs, decoder_state在上述代码中,第1行tgt_input为解码器输入形状为[batch_size, tgt_len],encoder_state为编码器的输出final_state,如果是LSTM则包含$C$和$H$两个部分,GRU则只包含$H$这一个部分,具体可参见「第7.7.3节 LSTM原理:长短期记忆网络如何解决长依赖」内容。第2行是编码器的输出以及编码器输入的填充信息,用于后续计算注意力。第3~6行则是整个前向传播计算过程,其中attention_type为'standard'表示不使用注意力机制。
3. 序列到序列模型实现
在实现完编码器和解码器之后,只需要将两者整合起来即可完成Seq2Seq模型的实现,示例代码如下所示:
1 class Seq2Seq(nn.Module):
2 def __init__(self, config=None):
3 super(Seq2Seq, self).__init__()
4 self.encoder = Encoder(config.src_emb_size, config.hidden_size,
5 config.num_layers,config.src_v_size, config.cell_type,
6 config.batch_first,config.dropout)
7 self.decoder = DecoderWrapper(config.tgt_emb_size, config.hidden_size,
8 config.num_layers,config.tgt_v_size, config.cell_type,
9 config.attention_type,config.batch_first, config.dropout)
10 def forward(self, src_input, tgt_input, src_key_padding_mask=None):
11 encoder_output, encoder_state = self.encoder(src_input)
12 decoder_output, decoder_state = self.decoder(tgt_input, encoder_state,
13 encoder_output, src_key_padding_mask)
14 return decoder_output在上述代码中,第4~6行是实例化一个编码器。第7~9行是实例化一个解码器。第10~13行则是整个Seq2Seq模型的前向传播计算过程。
最后,我们可以通过如下方式来进行使用:
1 class ModelConfig():
2 def __init__(self):
3 self.src_emb_size = 32
4 self.tgt_emb_size = 64
5 self.hidden_size = 128
6 self.num_layers = 2
7 self.src_v_size = 50
8 self.tgt_v_size = 60
9 self.cell_type = 'GRU'
10 self.batch_first = True
11 self.dropout = 0.5
12 self.attention_type = 'standard'
13 def test_Seq2Seq():
14 src_input = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9],
15 [1, 2, 3, 3, 3, 4, 2, 1, 1]])
16 tgt_input = torch.LongTensor([[1, 2, 6, 7, 8, 9],[1, 2, 4, 2, 1, 1]])
17 config, seq2seq = ModelConfig(),Seq2Seq(config)
18 output = seq2seq(src_input, tgt_input)
19 print("Seq2Seq output.shape: ", output.shape)在上述代码中,第1~12行是定义一个配置类来管理模型超参数。第14~16行用于构造源序列和目标序列。第17行是实例化一个配置类和Seq2Seq模型。第18行则是模型前向传播后的输出结果,形状为[batch_size, tgt_len, hidden_size]。
9.9.5 NMT模型实现#
在实现完Seq2Seq模型之后,下一步便可以基于此来实现最后的NMT翻译模型。由于序列模型在训练和推理时的过程不太一样,所以推理部分还需要单独实现。下面先介绍训练部分的内容。
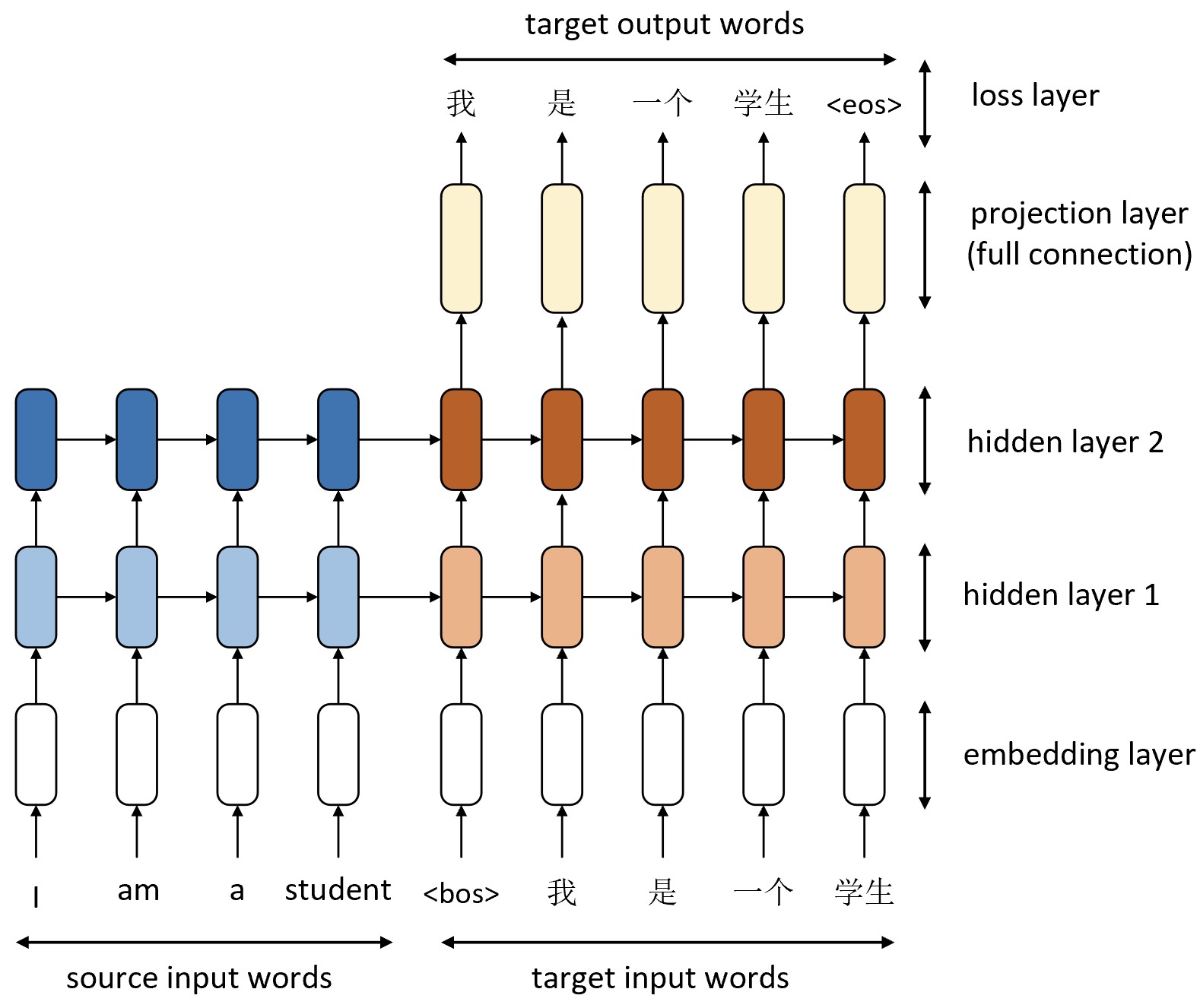
如图9-21所示便是NMT模型在训练时的示意图,左侧为源序列输入,右侧上方为目标序列输出。为了能够更加有效地指导模型训练,在训练过程中解码器每个时刻的输入(图9-21右侧下方)都是上一时刻输出结果真实的标签值而非预测值[2],即此时并没有用解码器第1个时刻的预测输出作为解码器第2个时刻的输入,而是直接以正确标签作为输入,这也被称为强制教学(Teacher Forcing)。
训练部分示例代码如下所示:
1 class TranslationModel(nn.Module):
2 def __init__(self, config = None):
3 super().__init__()
4 self.seq2seq = Seq2Seq(config)
5 self.classifier = nn.Linear(config.hidden_size, config.tgt_v_size)
6
7 def forward(self, src_input, tgt_input,src_key_padding_mask=None):
8 output = self.seq2seq(src_input, tgt_input,src_key_padding_mask)
9 logits = self.classifier(output)
10 return logits在上述代码中,第4~5行是分别实例化一个Seq2Seq模型和一个分类层,其中后者用于对解码后的每个时刻进行分类处理。第8~9行便是模型训练时的前向传播过程。
进一步,在推理过程中我们需要先对源序列进行编码,然后解码器再逐一时刻对中间向量进行解码,示例代码如下所示:
1 def encoder(self, src_input):
2 output, final_state = self.seq2seq.encoder(src_input)
3 return output, final_state
4
5 def decoder(self, tgt_input, decoder_state, encoder_output):
6 output, final_state = self.seq2seq.decoder(tgt_input, decoder_state, encoder_output)
7 return output, final_state在上述代码中,第1~3行是对源序列进行编码处理。第5~7行是对目标序列的一个时刻进行解码处理,整个解码过程的实现见第9.9.6节推理部分。
9.9.6 NMT推理实现#
对于NMT模型的推理过程来说,编码阶段的过程同训练时一致,即源序列经过编码器后得到一个中间向量。但是在解码过程中则是逐时刻依次解码,即对每个时刻进行解码器都需要依赖于上一时刻的预测结果。
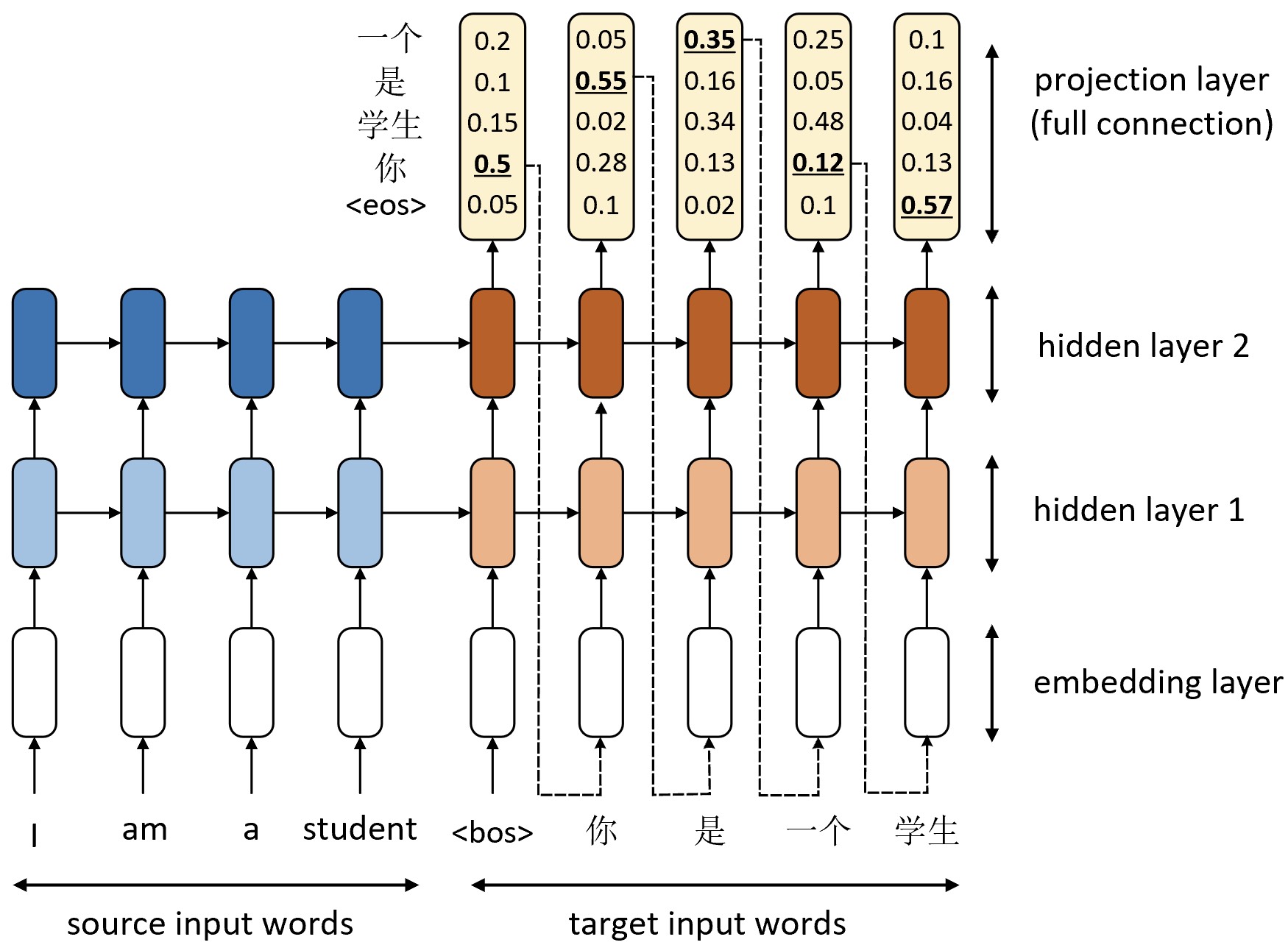
如图9-22所示便是NMT模型在基于贪婪策略时的推理过程示意图。从图9-22可以看出,解码器在对第$t$时刻进行解码时将会以第$t-1$时刻的预测结果作为输入进行预测,然后以此循环进行直到预测结果为结束符<EOS>或达到预先设定的最大长度停止。通常情况下最大长度可以设置为源输入序列长度的两倍。
由于整个推理过程所涉及到的内容较多,所以这里我们将分成3个功能函数来进行介绍,同时也便于功能扩展。首先根据第9.7.3节中贪婪搜索的原理,其具体实现过程如下所示:
1 def greedy_decode(model, src_in, start_symbol=2, end_symbol=3, device=None):
2 encoder_out, decoder_state = model.encoder(src_in)
3 max_len = src_in.shape[1] * 2
4 tgt_in = torch.LongTensor([[start_symbol]]).to(device)
5 results = []
6 for i in range(max_len):
7 decoder_out, decoder_state = model.decoder(tgt_in, decoder_state, encoder_out)
8 logits = model.classifier(decoder_out)
9 pred = logits.argmax()
10 if pred.item() == end_symbol:
11 break
12 results.append(pred.detach().cpu().item())
13 tgt_in = torch.LongTensor([[pred]]).to(device)
14 return results 在上述代码中,第1行model表示训练完成的翻译模型,src_in表示输入序列形状为[1,src_len]且已经根据词表转换为了索引序列,start_symbol和end_symbol分别表示目标序列词表中开始和结束符对应的索引。第2行是得到编码器对应的编码输出。第3行是设定最大的生成长度为源序列的两倍。第4行是根据开始符构造解码器第1个时刻的输入,形状为[1,1]。第7行是根据解码器的状态和编码器的输出来对当前时刻进行解码输出。第8~9行是对当前时刻的输出进行预测并按照最大概率选择预测值,其中logits的形状为[1,1, tgt_vocab_size]。第10~11行是判断当前时刻的预测结果是否为结束标志,如果是则直接跳出循序。第12行是保存每一个时刻预测得到的结果。第13行是将上一个时刻的输出构造成为下一个时刻的输入。最后第14行返回的则是每个时刻预测结果对应的词表索引。
进一步,需要实现一个函数来将源序列输入转换为词表索引并将上面解码后的结果根据目标序列词表转换为真是的预测结果,实现过程如下所示:
1 def translation(model=None, text=None, config=None, data_loader=None):
2 src_tokens = data_loader.tokenizer['src'](text)
3 src_tokens = [[data_loader.src_vocab[token] for token in src_tokens]]
4 src_tokens = torch.LongTensor(src_tokens).to(config.devices[0]) # [1,src_len]
5 trans_tokens = greedy_decode(model, src_tokens, data_loader.TGT_BOS_IDX,
6 data_loader.TGT_EOS_IDX, config.devices[0])
7 trans = [data_loader.tgt_vocab.itos[idx] for idx in trans_tokens]
8 return " ".join(trans)在上述代码中,第1行中text是输入的原始文本序列,为1个字符串。第2~4行是将输入文本进行切分处理变成单个字符,然后再转换成词表所以,最后构造成一个张量并放到主设备上,此时src_tokens的形状为[1,src_len]。第5~6行则是开始按照贪婪搜索策略进行解码,后续还可以实现其它搜索策略在这里进行替换即可。第7~8行则是将解码后的索引根据词表转换为真是的文本内容并返回。
最后,将两者整合并加入模型载入部分的代码,整个模型推理过程实现如下:
1 def inference(texts=None):
2 config = TranslationModelConfig()
3 data_loader = LoadEnglishGermanDataset(batch_size=config.batch_size,
4 min_freq=config.min_freq,src_top_k=config.src_v_size,
5 tgt_top_k=config.tgt_v_size,src_inverse=config.src_inverse)
6 config.src_v_size = len(data_loader.src_vocab)
7 config.tgt_v_size = len(data_loader.tgt_vocab)
8 model = TranslationModel(config)
9 if not os.path.exists(config.model_save_path):
10 raise ValueError(f"模型不存在:{config.model_save_path}")
11 loaded_paras = torch.load(config.model_save_path)
12 model.load_state_dict(loaded_paras)
13 model = model.to(config.devices[0])
14 for text in texts:
15 logging.info(f"原文: {text}")
16 logging.info(f"翻译: {translation(model, text, config, data_loader)}")在上述代码中,第1行texts为输入需要进行翻译的文本为一个列表,每个元素是一句文本。第2~8行是根据超参数实例化相关类对象。第9~13行是载入本地模型参数并赋值到现有翻译模型。第14~16行则是开始逐句对待翻译文本进行翻译。
9.9.7 NMT模型训练#
在模型训练这部分主要包含3个部分,评价指标BLEU计算的实现、模型评估的实现以及模型训练部分的实现,下面开始分别进行介绍。
1. BLEU计算实现
虽然在「第9.8.2节 序列模型评价指标:BLEU 等 NLP 任务评估方法」内容中已经介绍过了BLEU的使用方法,但这里还需要考虑的一点就是模型在训练过程中计算BLEU值时需要忽略掉填充部分的信息,具体实现如下所示:
1 def compute_bleu(y_pred, y_true, inference=False, pad_index=0):
2 y_pred = [[str(item) for item in x] for x in y_pred]
3 y_true_truncated = []
4 for i, y in enumerate(y_true):
5 tmp = []
6 for item in y:
7 if item != pad_index:
8 tmp.append(str(item))
9 else:
10 break
11 y_true_truncated.append([tmp])
12 if not inference:
13 y_pred[i] = y_pred[i][:len(tmp)]
14 return bleu_score(y_pred, y_true_truncated, max_n=4)在上述代码中,第1行y_pred和y_true均为一个二维列表。第2行是将索引转换成字符型,以便后续看做一个字符计算BLEU值。第4~10行是开始遍历每一样本中的每个索引序号,如果当前索引为填充值则退出循环。第11行便得到了真实的目标输出值。第12~13行是判断如果是训练阶段,在计算BLEU时则需要去掉解码器中填充值和<EOS>作为输入时预测得到的这部分结果,如果是在推理阶段则不需要对预测结果做任何操作,因为此时解码器的输入均为上一个时刻的预测值。
例如对于如下序列来说:
1 y_pred = [[1, 2, 3, 4, 5, 6, 6, 7], [2, 2, 2, 3, 5, 6, 3, 4]]
2 y_true = [[1, 2, 3, 4, 5, 6, 0, 0], [2, 2, 2, 3, 5, 7, 0, 0]]其在训练和推理情况下的BLEU值分别为0.881和0.599。可以看出,在训练情况下由于忽略掉了0所在位置的结果,所以BLEU值会高于推理时的情况。
2. 模型评估实现
在模型评估阶段,需要逐样本根据对应的搜索策略来完成预测结果的生成,并同时根据预测结果和标签值进行BLEU计算,实现代码如下所示:
1 def evaluate(config, valid_iter, model, data_loader):
2 y_preds, y_trues = [], []
3 with torch.no_grad():
4 for src_input, tgt_input in valid_iter:
5 for src_in, tgt_in in zip(src_input, tgt_input):
6 src_in = src_in.to(config.devices[0])
7 tgt_out = tgt_in[1:]
8 y_trues.append(tgt_out.tolist())
9 y_pred = greedy_decode(model, src_in.reshape(1, -1),
10 data_loader.TGT_BOS_IDX,data_loader.TGT_EOS_IDX, config.devices[0])
11 y_preds.append(y_pred)
12 return compute_bleu(y_preds, y_trues, True, data_loader.TGT_PAD_IDX)在上述代码中,第4行是开始遍历每个小批量中的样本。第5行开始遍历每一个样本,因为在推理过程中需要逐时刻将上一时刻的预测结果作为当期时刻的输入进行解码,所有不能多样本并行。第6行是将样本放到主设备上,第7~8行是得到对应的真实预测结果。第9~10行是完成每个样本解码预测过程。第11行是保存每个样本的预测结果。第12行则是计算所有预测结果的BLEU评价指标。
3. 模型训练实现
在完成上述两个步骤之后便可以整合实现整个模型的训练过程,关键代码如下所示:
1 def train(config=None):
2 data_loader = LoadEnglishGermanDataset(batch_size=config.batch_size,
3 config.min_freq,config.src_v_size,config.tgt_v_size,config.src_inverse)
4 train_iter, valid_iter = data_loader.load_train_val_test_data(is_train=True)
5 config.src_v_size = len(data_loader.src_vocab)
6 config.tgt_v_size = len(data_loader.tgt_vocab)
7 model = TranslationModel(config).to(config.devices[0])
8 loss_fn = torch.nn.CrossEntropyLoss('sum', data_loader.TGT_PAD_IDX)
9 for epoch in range(config.epochs):
10 for i, (src_input, tgt_input) in enumerate(train_iter):
11 tgt_in, tgt_out= tgt_input[:, :-1],tgt_input[:, 1:]
12 logits = model(src_input, tgt_in)
13 loss = loss_fn(logits.reshape(-1, logits.shape[-1]),
14 tgt_out.reshape(-1)) / config.batch_size
15 ......
16 if i % 50 == 0:
17 bleu = compute_bleu(logits.argmax(dim=-1).detach().cpu().tolist(),
18 tgt_out.detach().cpu().tolist(), False, data_loader.TGT_PAD_IDX)
19 bleu = evaluate(config, valid_iter, model, data_loader)在上述代码中,第2~4行是根据模型超参数返回训练集和验证集对应的迭代器。第5~6行是根据制作完成的数据集来获取得到源序列词表和目标序列词表各自对应的长度。第7行是实例化翻译模型,并将其放到主设备上。第8行是实例化交叉熵计算类对象,注意这里指定返回损失和以及需要忽略的标签值,这样便可以在计算损失时不考虑填充位置所产生的损失值。第11行是得到训练时解码器的输入和标签,即图9-20的地⑤步。第12行是模型的前向传播过程。第13~14行是计算预测值对应的损失并在批大小这个维度上计算均值,详见「第7.6.3节 CharRNN教程:基于字符级序列的生成模型」内容。第17~19行是分别计算每个小批量数据的BLEU评估值和在整个验证集上的评估值。
最后,模型训练时将会得到类似如下输出结果:
1 Epochs[1/200]--batch[0/454]--loss: 128.9809--bleu: 0.0
2 Epochs[1/200]--batch[50/454]--loss: 82.4742--bleu: 0.0
3 Epochs[1/200]--batch[100/454]--loss: 69.7093--bleu: 0.0361
4 Epochs[1/200]--batch[150/454]--loss: 66.4129--bleu: 0.0264
5 Epochs[1/200]--batch[200/454]--loss: 66.0655--bleu: 0.0491
6 Epochs[1/200]--batch[250/454]--loss: 57.8919--bleu: 0.0341
7 Epochs[1/200]--batch[300/454]--loss: 55.7165--bleu: 0.0411
8 Epochs[1/200]--batch[350/454]--loss: 53.9611--bleu: 0.0609
9 Epochs[16/200]--batch[450/454]--loss: 16.2022--bleu: 0.402
10 bleu on valid set: 0.19199.9.8 小结#
在本节内容中,我们首先介绍了谷歌翻译的发展历史以及传统的基于统计方法翻译模型的弊端;然后详细介绍了基于NMT模型的数据集构建流程原理和代码实现;最后一步一步介绍了整个NMT模型的详细实现过程,包括Seq2Seq模型实现、NMT模型实现、NMT推理实现和NMT训练实现等等。在接下来的一节内容中,我们将会开始学习一种全新的深度学习技术注意力机制。
引用#
[1] https://en.wikipedia.org/wiki/Google_Translate
[2] Sutskever I, Vinyals O, Quoc V Le. Sequence to sequence learning with neural networks[J]. Advances in neural information processing systems, 2014, 27.
[3] https://ai.googleblog.com/2016/09/a-neural-network-for-machine.html
[4] Wu Y, Schuster M, Chen Z, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation[J]. arXiv preprint, 2016, arXiv:1609.08144.
[5] https://ai.googleblog.com/2020/06/recent-advances-in-google-translate.html
[6] Luong M T, Brevdo E, Zhao R, Neural Machine Translation (seq2seq) Tutorial, https://github.com/tensorflow/nmt, 2017.
[7] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint, 2014, arXiv:1409.0473.