10.10 BERT问题回答模型#
经过前面几节内容的介绍,我们已经清楚了BERT模型的基本原理以及如何基于BERT预训练模型来完成文本分类和问答选择这些下游微调任务。在接下来的这节内容中,我们将会继续介绍基于BERT预训练模型的第3个下游任务微调场景,问题回答任务。所谓问题回答是指同时给模型输入一个问题和一段描述,最后需要模型从给定的描述中预测出答案所在的位置。
例如:
描述:苏轼是北宋著名的文学家与政治家,眉州眉山人。
问题:苏轼是哪里人?
标签:眉州眉山人
在完成这个任务之前首先需要明白的是:①最终问题的答案一定存在于给定的文本描述中;②问题的答案一定是给定描述中的一段连续的字符,即不能有间隔。例如对于上面的描述内容来说,如果给出的问题是“苏轼生活在什么年代以及他是哪里人?”,那么模型最终并不能给出类似“北宋”和“眉州眉山人”这两个分离的答案,最好的情况下便是给出“北宋著名的文学家与政治家,眉州眉山 人”这一段连续的文本序列。
在有了这两个限制条件以后,对于这类问答任务其本质也就变成了需要让模型预测得到答案在文本描述中的起始位置(Start Position)和结束位置(End Position),而这也叫做文本片段(Text Span)预测。因此,问题最终就变成了如何在BERT模型的基础之上再构建一个分类器来对BERT最后一层输出的每个位置进行分类,依次判断它们是否属于开始位置或结束位置。
10.10.1 任务构造原理#
正如上面所说,尽管问题回答任务看似复杂但其本质依旧可以归结为一个普通的分类任务,只是解决这个问题的关键在于如何构建整个数据集。如图10-32所示便是一个基于BERT预训练模型的问题回答模型的原理图。
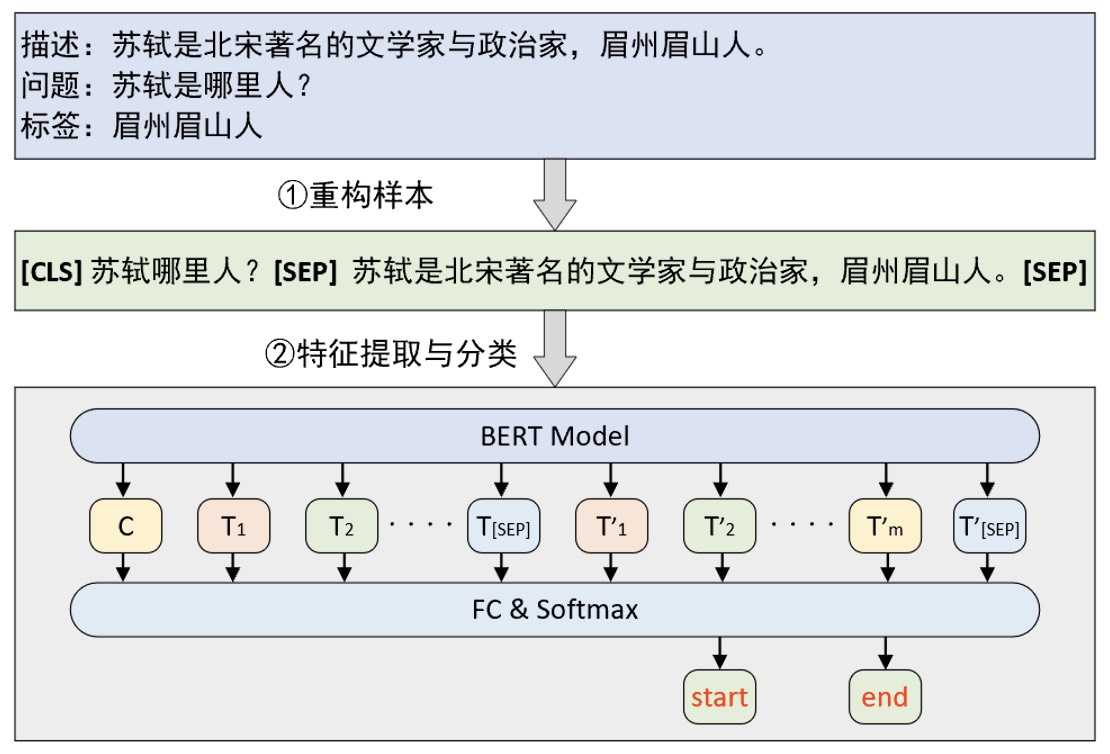
从图10-32可以看出,构建模型输入的方式就是将原始问题和上下文描述拼接成一个序列中间用[SEP]符号隔开,然后再分别输入到BERT模型中进行特征提取。在BERT编码完成后再取最后一层的输出对每个位置上的向量进行分类即可得到开始位置和结束位置的预测输出。
10.10.2 样本构造与结果筛选#
1. 输入介绍
在正式介绍如何构建数据集之前我们先来看对于上下文过长时的情况该怎么处理。在问题回答这个任务场景中,当原始上下文的长度超过给定长度或者是512个字符时,可以采取滑动窗口的方法来构造整个模型的输入序列,如图10-33所示。
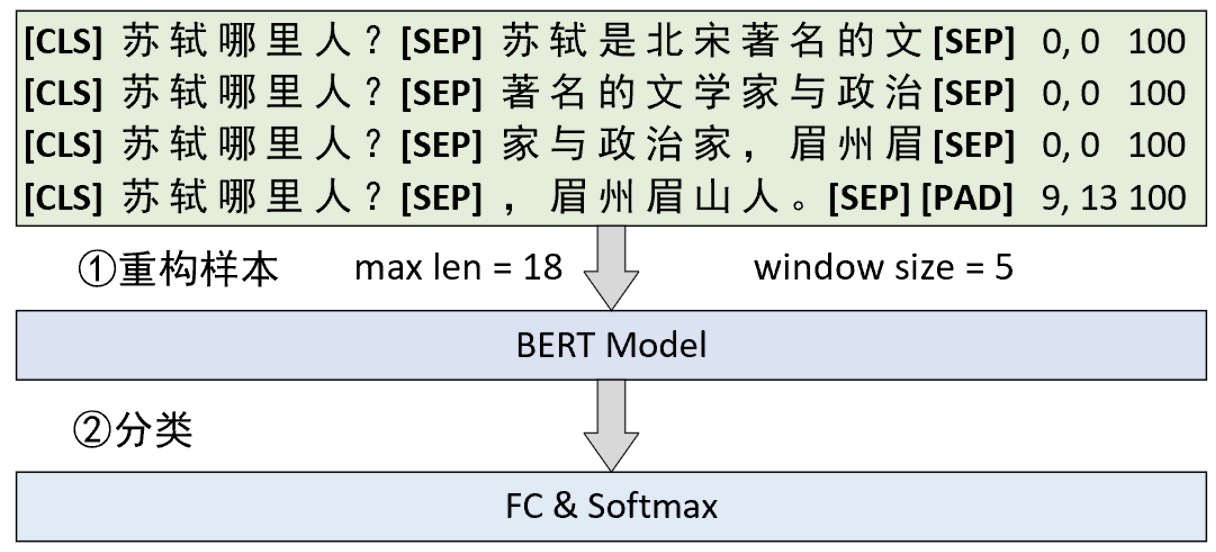
如图10-33所示,第①步需要是根据指定的最大长度和滑动窗口将原始样本进行滑动窗口处理并得到多个子样本。这里需要注意的是,句子A也就是问题部分不参与滑动处理。同时,图10-33中样本右边的3列数字分别表示在每个子样本中答案的起始位置、结束位置和原始样本对应的编号。紧接着第②步便是将所有原始样本滑动处理后的结果作为训练集来训练模型。
总的来说,在这一场景中模型的训练程并不复杂,因为每个子样本也都有其对应的标签值和普通的训练过程并没有什么本质上的差异。因此, 最关键的地方在于如何在推理过程中也使用滑动窗口。
2. 结果筛选
一种最直观的做法是直接取起始位置预测概率值加结束位置预测概率值最大的子样本对应的结果,作为整个原始样本对应的预测结果。虽然这样的做法虽然简单但最终模型的准确率并不高,而下面介绍的筛选法就会得到更好的预测结果。
如图10-34所示,在推理过程中第①步仍旧需要根据指定最大长度和滑动窗口大小将原始样本进行滑动窗口处理。接着第②步是根据模型分类的输出取前K个概率值最大的结果。在图10-34中K=4,因此对于每个子样本来说其开始位置和结束位置分别都有4个候选结果。例如,第②步中第1行的 7:0.41、10:02、9:0.12和2:01分别表示对于第1个子样本来说,开始位置为索引7的概率值为 0.41,其它同理。
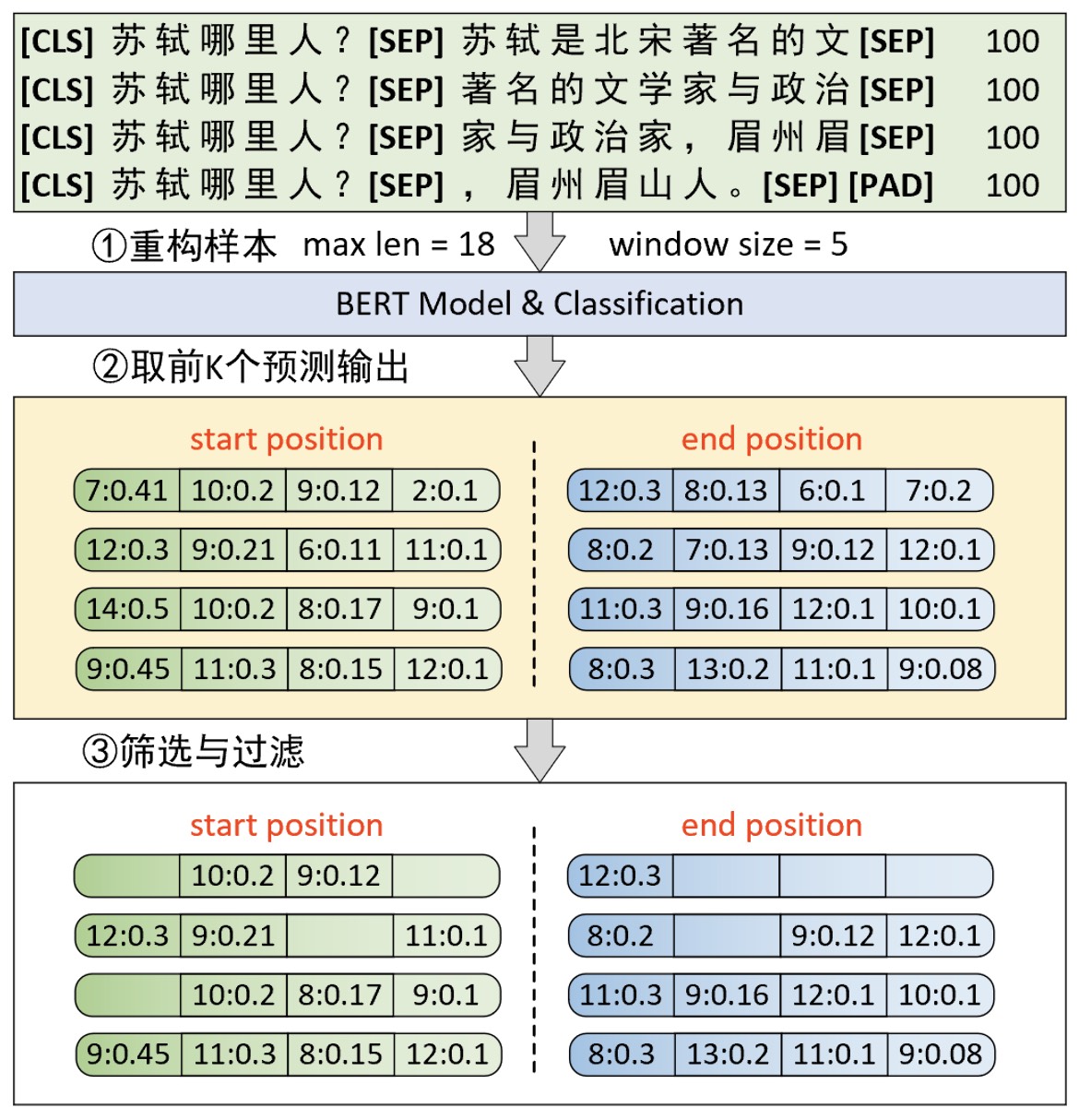
此时对于每一个子样本来说,在分别得到开始位置和结束位置的前K个候选值后便可以通过组合来得到更多的候选预测结果,然后再根据一些规则来选择最终原始样本对应的预测输出。根据图10-34中样本重构后的结果可以看出:(1)最终的索引预测结果需要大于8,因为句子A的长度已经是7,而答案只可能在上下文中出现;(2)在结果组合中,起始索引必定小于等于结束索引。因此,根据这两个条件在经过步骤③的处理后,便可得到进一步筛选后的结果。例如:对于第1个子样本来说,开始位置中7和2不满足条件(1)所以可以直接去掉,同时为了满足第(2)个条件所以在结束位置中8、6和7均需要去掉。
进一步,将第③步处理后的结果在每个子样本内部进行组合,并按照开始位置加结束位置概率值的大小进行排序,便可以得到如图10-35所示的结果。
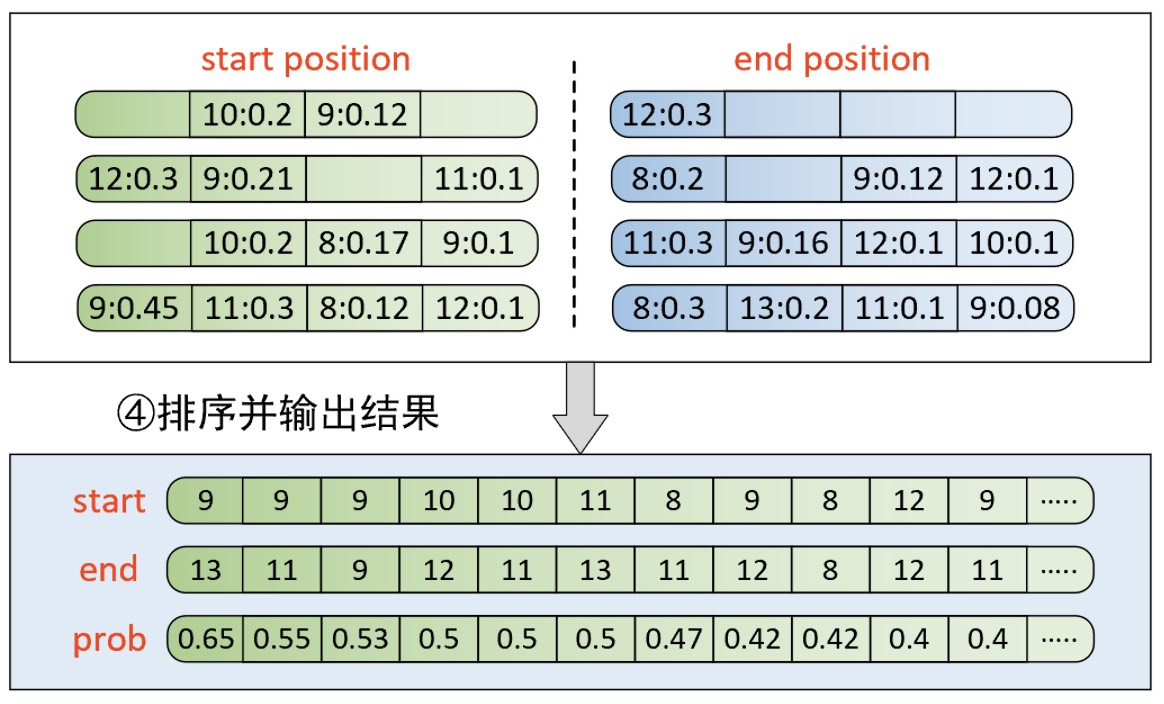
如图10-35所示表示根据概率和排序后的结果。例如第1列 9、13和0.65 的含义便是最终原始样本预测结果为开始位置是9和结束位置是13的概率值为0.65。因此,最终该原始样本对应的预测值便可以取9和13。
10.10.3 数据预处理#
1. 数据集介绍
在这里我们所使用到的是斯坦福问答数据集(The Stanford Question Answering Dataset 1.1, SQuAD)[1], 它是斯坦福大学于2016年推出的一个阅读理解数据集,即给定一个问题和描述需要模型从描述中找出答案的起止位置。SQuAD数据集包含了数千篇文章,每篇文章都伴随着一系列问题。这些问题是基于文章内容提出的,每个问题都要求模型从文章中找到正确的答案。
SQuAD原始数据整体由json格式构成成,其中数据部分在字段“data”中为一个列表,而列表中的每个元素则是对应的一篇文章,并以字典进行的存储。对于每一篇文章来说,由“title”和“paragraphs” 这两个字段构成。同时,“paragraphs”中也是一个列表,其中的每一个元素为一个字典,由“context”和“qas”两个字段构成,分别表示上下文描述和问题答案集合。最后,“qas”字段中也是一个列表,其中每个元素为一个字典,由“question”、“answer”和“id”组成,即“qas”是一段文本描述下多个问题和答案的列表集合。我们在后续构建数据集时需要完成的便是从数据集中提取出对应的上下文描述、问题、开始位置、结束位置以及问题ID这些信息。
2. 数据集预览
由于SQuAD数据集的构建流程稍显复杂,所以在正式介绍数据集的构建之前我们先通过一张图来了解一下整体的构建流程。假如现在有两个样本构成了一个小批量,那么整个数据的处理过程则如图10-36所示。
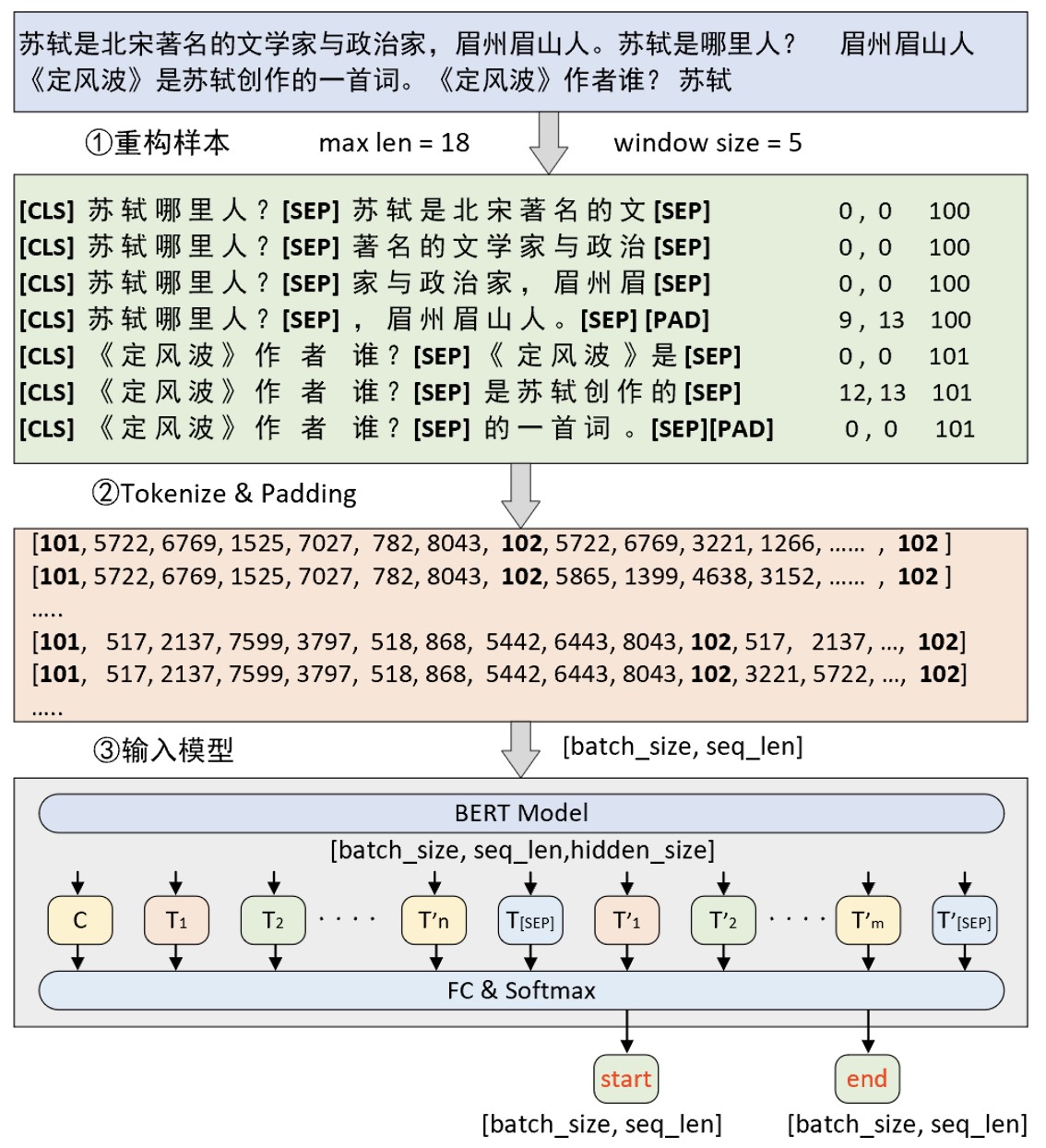
注:由于英文样例普遍较长作图不便,故这里以中文进行了示例。
如图10-36所示,首先对于原始数据中的上下文按照指定最大长度和滑动窗口大小进行滑动处理;然后再将问题同上下文拼接在一起构造成为一个序列并添加上对应的分类符[CLS]和分隔符[SEP],即图10-36中的第①步重构样本。紧接着需要将第①步构造得到的序列转换为词表索引并进行填充处理,此时便得到了一个形状为[batch_size,seq_len]的结构,即图10-36中第②步处理完成后形状为 [7,18]的结果。同时,在第②步中还要根据每个序列构造得到相应的掩码向量和句子编码向量(图中未画出),并且两者的形状也是[batch_size,seq_len]。最后,将第②步处理后的结果输入到BERT模型中,在经过BERT特征提取后将会得到一个形状为[batch_size,seq_len,hidden_size]的结果,最后再乘上一个形状为[hidden_size,2]的矩阵并变形成[batch_size,seq_len,2]的形状,即是对BERT输出层的每个位置进行分类。
3. 读取数据
对于数据预处理部分我们可以继续继承「第10.8节 BERT文本分类:下游任务微调实战」内容中文本分类处理的这个类LoadSingleSentenceClassificationDataset,然后再稍微修改其中的部分方法即可。同时,由于处理SQuAD原始数据将会涉及到多个类方法对数据进行清洗的过程,但是这并不是本节内容的核心所以这部分将只会稍微提及,各位读者可直接阅读项目源码。以下完整示例代码可参见Code/Chapter10/C04_BERT文件。
首先下面我们需要定义一个函数来对原始数据进行读取得到每个样本原始的字符串形式,示例代码如下所示:
1 def preprocessing(self, filepath, is_training=True):
2 with open(filepath, 'r') as f:
3 raw_data = json.loads(f.read())
4 data = raw_data['data']
5 examples = []
6 for i in tqdm(range(len(data)), ncols=80, desc="正在遍历每一个段落"):
7 paragraphs = data[i]['paragraphs']
8 for j in range(len(paragraphs)):
9 context = paragraphs[j]['context']
10 c_tokens, word_offset = self.get_format_text_and_word_offset(context)
11 qas = paragraphs[j]['qas']
12 for k in range(len(qas)):
13 q_text, qas_id = qas[k]['question'],qas[k]['id']
14 if is_training:
15 answer_offset = qas[k]['answers'][0]['answer_start']
16 orig_answer_text = qas[k]['answers'][0]['text']
17 answer_length = len(orig_answer_text)
18 start_pos = word_offset[answer_offset]
19 end_pos = word_offset[answer_offset + answer_length - 1]
20 actual_text = " ".join(
21 c_tokens[start_pos:(end_pos + 1)])
22 cleaned_answer_text = " ".join(orig_answer_text.strip().split())
23 if actual_text.find(cleaned_answer_text) == -1:
24 continue
25 else:
26 start_pos, end_pos, orig_answer_text = None,None,None
27 examples.append([qas_id, q_text, orig_answer_text,
28 " ".join(c_tokens), start_pos, end_pos])
29 return examples在上述代码中,第6~7行用来遍历原始数据中的每一篇文章。第8~11行用来遍历每一篇文章中的每个paragraph,并取相应的上下文context和问题答案对。 第12~13行是用来遍历取每个paragraph中对应的多个问题和问题编号。第14~24行是判断如果当前处理的是训练集,那么再取问题对应答案的偏移量和原始答案描述,并以此获取原始答案对应的起始位置和结束位置。第20~22行是判断真实答案和根据起止位置从上下文描述中截取的答案是否相同,不同则跳过该条样本。第 25~28行是用来处理验证集或测试集。
最后,该函数将会返回一个2维列表,内层列表中的各个元素分别为:
1 ['问题 ID','原始问题文本','答案文本','context 文本','答案在 context 中的开始位置', '答案在 context 中的结束位置']例如:
1 [['5733be284776f41900661182', 'To whom did the Virgin Mary allegedly appear in .... France?', 'Saint Bernadette Soubirous', 'Architecturally, the school has a Catholic character......', 90, 92],
2 ['5733be284776f4190066117f', ....]]4. 重构输入样本
在经过预处理函数preprocessing()处理后,我们便可以进一步采用滑动窗口来构造模型的输入,示例代码如下所示:
1 def data_process(self, file_path, is_training=False):
2 examples = self.preprocessing(file_path, is_training)
3 all_data, example_id, feature_id =[], 0, 1000000000
4 for example in tqdm(examples, ncols=80, desc="正在遍历每个问题(样本)"):
5 q_tokens = self.tokenizer(example[1])
6 if len(q_tokens) > self.max_query_length: # 问题过长进行截取
7 q_tokens = q_tokens[:self.max_query_length]
8 q_ids = [self.vocab[token] for token in q_tokens]
9 q_ids = [self.CLS_IDX] + q_ids + [self.SEP_IDX]
10 c_tokens = self.tokenizer(example[3])
11 c_ids = [self.vocab[token] for token in c_tokens]
12 start_pos, end_pos, answer_text = -1, -1, None
13 if is_training:
14 start_pos, end_pos = example[4], example[5]
15 answer_text,answer_tokens = example[2],self.tokenizer(answer_text)
16 rest_lenc_ids_len, = self.max_sen_len - len(q_ids) - 1, len(c_ids)在上述代码中,第4行是开始遍历preprocessing()函数返回的每一条原始数据。第5~11行是构造模型后续对应所需要的各个部分。第13~15行是用来获取得到训练集中答案的起始位置、结束位置以及答案原始文本。第16行是用来计算上下文描述的长度判断是否需要进行滑动窗口处理,如果需要则按以下逻辑进行处理:
1 if c_ids_len > rest_len:
2 s_idx, e_idx = 0, rest_len
3 while True:
4 tmp_c_ids = c_ids[s_idx:e_idx]
5 tmp_c_tokens = [self.vocab.itos[item] for item in tmp_c_ids]
6 input_ids = torch.tensor(q_ids + tmp_c_ids + [self.SEP_IDX])
7 input_tokens = ['[CLS]'] + q_tokens + ['[SEP]'] + tmp_c_tokens + ['[SEP]']
8 seg = [0] * len(q_ids) + [1] * (len(input_ids) - len(q_ids))
9 seg = torch.tensor(seg)
10 if is_training:
11 new_start_pos, new_end_pos = 0, 0
12 if start_pos >= s_idx and end_pos <= e_idx:
13 new_start_pos = start_pos - s_idx
14 new_end_pos = new_start_pos + (end_pos - start_pos)
15 new_start_pos += len(q_ids)
16 new_end_pos += len(q_ids)
17 all_data.append([example_id, feature_id, input_ids, seg, new_start_pos,
18 new_end_pos, answer_text, example[0], input_tokens])
19 else:
20 all_data.append([example_id, feature_id, input_ids, seg, start_pos,
21 end_pos, answer_text, example[0], input_tokens])
22 orig_map = self.get_orig_map(input_tokens, example[3], self.tokenizer)在上述代码中,第3行开始便是进入滑动窗口循环处理中。第4~9行同样是构造得到模型输入的所需部分。第10~21行是分别取训练和推理时输入序列对应答案所在的索引位置,并同其余部分形成一个原始样本进行保存。第22行是返回得模型输入序列中每 个字符在原始单词中所对应的位置索引,这一结果将会在最后推理过程中得到最后预测结果时用到。
例如现在有如下字符序列:
1 input_tokens = ['[CLS]', 'to', 'whom', 'did', 'the', 'virgin', '[SEP]',
2 'architectural', '##ly', ',', 'the', 'school', 'has', 'a', 'catholic',
3 'character', '.', '[SEP']那么上下文字符在原始上下文中的索引映射表则为:
1 origin_context = "Architecturally, the Architecturally, test, Architecturally, the school has a Catholic character. Welcome moon hotel"
2 orig_map = {7: 4, 8: 4, 9: 4, 10: 5, 11: 6, 12: 7, 13: 8, 14: 9,15:10,16: 10}其含义表示,input_tokens[7]为origin_context中的第4个单词Architecturally, 同理input_tokens[10]为origin_context中的第5个单词the。
如果不需要进行活动窗口处理则按以下逻辑进行:
1 else:
2 input_ids = torch.tensor(q_ids + c_ids + [self.SEP_IDX])
3 input_tokens = ['[CLS]'] + q_tokens + ['[SEP]'] + c_tokens + ['[SEP]']
4 seg = [0] * len(q_ids) + [1] * (len(input_ids) - len(q_ids))
5 seg = torch.tensor(seg)
6 if is_training:
7 start_position += (len(q_ids))
8 end_position += (len(q_ids))
9 orig_map = self.get_orig_map(input_tokens, example[3], self.tokenizer)
10 all_data.append([example_id, feature_id, input_ids, seg, start_position,
11 end_position, answer_text, example[0], input_tokens, orig_map])
12 feature_id += 1
13 example_id += 1
14 data = {'all_data': all_data, 'max_len': self.max_sen_len, 'examples': examples}
15 return data在上述代码中,all_data中的每个元素分别为原始样本ID、训练特征ID、input_ids、seg、开始位置、结束位置、答案文本、问题ID、input_tokens和ori_map。
5. 构建迭代器
在完成前面各部分内容后,只需要在构造每个小批量样本时对输入序列进行填充并返回的相应的迭代器整个数据集就算是构造完成了。为此,同样需要重写对应的generate_batch方法,示例代码如下所示:
1 def generate_batch(self, data_batch):
2 batch_input, batch_seg, batch_label, batch_qid = [], [], [], []
3 batch_example_id, batch_feature_id, batch_map = [], [], []
4 for item in data_batch:
5 batch_example_id.append(item[0])
6 batch_feature_id.append(item[1])
7 batch_input.append(item[2])
8 batch_seg.append(item[3])
9 batch_label.append([item[4], item[5]])
10 batch_qid.append(item[7])
11 batch_map.append(item[9])
12 batch_input = pad_sequence(batch_input, False, self.max_sen_len,self.PAD_IDX)
13 batch_seg = pad_sequence(batch_seg, False, self.max_sen_len,self.PAD_IDX)
14 batch_label = torch.tensor(batch_label, dtype=torch.long)
15 return batch_input, batch_seg, batch_label, batch_qid,
16 batch_example_id, batch_feature_id, batch_map在上述代码中,第1行中的data_batch便是data_process()处理后返回的all_data结果。第4~11行是构造每个小批量中所包含的向量。第 12~13行是根据指定的参数max_len来进行填充处理。第15~16行是用来返回每个小批量处理后的结果。
在完成迭代器的构建之后,便可以通过如下方式来载入构建完成的SQuAD数据集,示例代码如下所示:
1 if __name__ == '__main__':
2 model_config = ModelConfig()
3 data_loader = LoadSQuADQuestionAnsweringDataset(...)
4 train_iter, test_iter, val_iter = data_loader. \
5 load_train_val_test_data(model_config.test_file_path,
6 model_config.train_file_path,only_test=False)
7 for input, seg, label, qid, example_id, feature_id, map in train_iter:
8 pass10.10.4 问提回答#
1. 前向传播
正如第10.10.1节内容所介绍,我们只需要在原始BERT模型的基础上取最后一层的输出结果,然后再加一个分类层即可。因此这部分代码相对来说也比较容易理解。我们在BertForQuestionAnswering.py模块中首先需要定义一个类以及相应的初始化函数,示例代码如下所示:
1 class BertForQuestionAnswering(nn.Module):
2 def __init__(self, config, bert_model_dir=None):
3 super(BertForQuestionAnswering, self).__init__()
4 if bert_model_dir is not None:
5 self.bert = BertModel.from_pretrained(config, bert_model_dir)
6 else:
7 self.bert = BertModel(config)
8 self.qa_outputs = nn.Linear(config.hidden_size, 2)在上述代码中,第4~7行便是根据相应的条件返回一个BERT模型,第8行是定义了一个分类层。最后定义完成整个前向传播过程,示例代码如下所示:
1 def forward(self, input_ids, attn_mask=None, token_type_ids=None,
2 pos_ids=None, start_pos=None, end_pos=None):
3 _, all_outputs = self.bert(input_ids,attn_mask, token_type_ids, pos_ids)
4 sequence_output = all_outputs[-1]
5 logits = self.qa_outputs(sequence_output)
6 start_logits, end_logits = logits.split(1, dim=-1)
7 start_logits = start_logits.squeeze(-1).transpose(0, 1)
8 end_logits = end_logits.squeeze(-1).transpose(0, 1)
9 if start_pos is not None and end_pos is not None:
10 ignored_index = start_logits.size(1)
11 start_pos.clamp_(0, ignored_index)
12 end_pos.clamp_(0, ignored_index)
13 loss_fct = nn.CrossEntropyLoss(ignore_index=ignored_index)
14 start_loss = loss_fct(start_logits, start_pos)
15 end_loss = loss_fct(end_logits, end_pos)
16 return (start_loss + end_loss) / 2, start_logits, end_logits
17 else:
18 return start_logits, end_logits 在上述代码中,第1~2行分别是模型所接受的输入,其中input_ids的形状为[src_len,batch_size],attn_mask的形状为[batch_size,src_len],token_type_ids的形状为[src_len,batch_size],start_pos和end_pos的形状均为[batch_size]。第3~4行是根据输入返回原始BERT模型的输出结果,需要注意的是这里要取BERT输出整个最后1层的输出结果,而不是像之前一样 只取最后1层第1个位置[CLS]对应的向量。第5行是分类层的输出结果,形状为[src_len, batch_size,2]。第6~8行是得到对应的start_logits和end_logits,两者的形状均是[batch_size,src_len]。第9~18行是根据是否有标签返回对应的损失或者预测值。第10~12行是用来处理当给定的start_pos和end_pos在[0,max_len]这个范围之外时,强制将其改为0或max_len。例如某个样本的起始位置为520,而序列最大长度为 512,即此时ignore_index=512,那么clamp_()方法便会将520改变成512,当然根据前面数据处理流程来最后生成的数 据集并不存在这样的情况,这里只是一种程序健壮性的体现。在第13行中之所以要将ignored_index作为损失计算时的忽略值,是因为这些位置并不能算是模型预测错误的而只能看做是没有预测,是答案超出了范围所以需要忽略掉这些情况。第14~16行是分别计算两部分的损失值并返回。
2. 模型训练
我们在Tasks目录下新建一个名为TaskForSQuADQuestionAnswering.py的模块,然后定义函数train()来完成模型的训练,核心示例代码如下所示:
1 def train(config):
2 model = BertForQuestionAnswering(config, config.model_dir)
3 data_loader = LoadSQuADQuestionAnsweringDataset(...)
4 train_iter, test_iter, val_iter = \
5 data_loader.load_train_val_test_data(config.train_file_path,
6 config.test_file_path,only_test=False)
7 for epoch in range(config.epochs):
8 for idx, (b_input, b_seg, b_label, _, _, _, _) in enumerate(train_iter):
9 padding_mask = (b_input == data_loader.PAD_IDX).transpose(0, 1)
10 loss, start_logits, end_logits = model(input_ids, attention_mask,
11 b_seg, None, b_label[:, 0], b_label[:, 1])
12 acc_start = (start_logits.argmax(1) == b_label[:, 0]).float().mean()
13 acc_end = (end_logits.argmax(1) == b_label[:, 1]).float().mean()
14 acc = (acc_start + acc_end) / 2
15 if idx % 10 == 0:
16 logging.info(f"Epoch: {epoch}, Batch[{idx}/{len(train_iter)}], "
17 f"Train loss :{loss.item():.3f}, Train acc: {acc:.3f}")
18 y_pred = [start_logits.argmax(1), end_logits.argmax(1)]
19 y_true = [b_label[:, 0], b_label[:, 1]]
20 show_result(b_input, data_loader.vocab.itos, y_pred, y_true)在上述代码中,第2行是根据参数返回一个实例化的问答模型。第3~6行是根据对应参数返回训练集、验证集和测试集。第7~20行是正式进入模型的训练过程中,其中第12~14行是计算模型在训练集上的准确率,第20行show_result()函数是用来展示训练时的预测结果。
最后,模型训练过程中将会输出类似如下信息:
1 Epoch:0, Batch[810/7387] Train loss: 0.998, Train acc: 0.708
2 Epoch:0, Batch[820/7387] Train loss: 1.130, Train acc: 0.708
3 Epoch:0, Batch[830/7387] Train loss: 1.960, Train acc: 0.375
4 Epoch:0, Batch[840/7387] Train loss: 1.933, Train acc: 0.542
5 ### Quesiotn:[CLS] when was the first university in switzerland founded..
6 ## Predicted answer: 1460
7 ## True answer: 1460
8 ## True answer idx: (tensor(46, tensor(47))
9 ### Quesiotn:[CLS] how many wards in plymouth elect two councillors?
10 ## Predicted answer: 17 of which elect three .....
11 ## True answer: three
12 ## True answer idx: (tensor(25, tensor(25))在上述结果中,第5~12行便是模型在训练过程中实时输出的预测结果。
到此,对于基于BERT的问答模型构建过程就介绍完了,后续只需要按照第10.10.2节内容中的逻辑实现推理过程即可,这部分内容各位读者可以直接阅读源码进行学习。
10.10.5 小结#
在本节内容中,我们首先通过一个示例说明了什么是问题回答模型,也即是阅读理解任务;然后整体介绍了基于BERT该模型的构建思路和原理并详细介绍了在推理过程中如何对候选结果进行筛选和排除;进一步介绍了基于SQuAD问答数据的数据集构建原理与过程;最后介绍了如何一步一步实现整个问答模型的前向传播和训练过程。在下一节内容中,我们将会开始介绍如何从零实现基于BERT预训练模型的命名体识别任务。
引用#
[1] https://rajpurkar.github.io/SQuAD-explorer/