4.6 VGG网络#
经过「第4.4节 LeNet5网络:经典卷积神经网络结构入门」和「第4.5节 AlexNet网络:结构原理、参数量与 PyTorch 实现」内容的介绍我们已经了解了LeNet5和AlexNet这两种卷积网络模型,但是总体上来说两者的网络结构几乎并没有太大的差别。在接下来的这节内容中,我们将会介绍卷积网络中的第3个经典模型VGG[1]。
4.6.1 VGG动机#
随着卷积网络在计算机视觉领域的快速发展,越来越多的研究人员开始通过改变模型的网络结构在提高在图像识别任务中的精度,例如使用更小的卷积核和步长[2]。基于类似的想法,论文作者提出可以尝试通过改变卷积网络深度来提高模型的分类精度。VGG模型于2014年诞生于Visual Geometry Group 实验室,而这3个单词的首字母也代表了VGG的含义。VGG网络总体上一共有5种网络架构,但是从本质上来说这5种网络架构都是一样的,仅仅只是在卷积的深度上有所差别,因此VGG也可以看作是不同卷积深度对模型效果影响的一次探索。
在论文中,作者对卷积网络卷积深度的设计进行了探索,并且通过尝试逐步加深网络的深度来提高模型的整体性能,这使得VGG在当年的ILSVRC任务中以稳定的优势分别取得了两项比赛的第1名和第2名。下面,我们将开始一步一步地来介绍VGG模型的网络结构。
4.6.2 VGG结构#
如图4-36所示一共有6列,其中第2列是在第1列的基础上加入了LRN标准化操作,网络最少有11层,最多有19层。在整个网络的训练过中,VGG会固定输入图片的大小为$224\times224$的RGB图像,并且在预处理中仅仅只是做了去均值化,即在训练集中每个像素值都会减去整体像素的一个平均值。接着,预处理后的图片将会被输入到一系列仅仅只由窗口大小为$3\times3$的卷积核堆叠而成的卷积网络中。并且从图4-36中的模型C可以看出,其还使用了窗口大小为$1\times1$的卷积核,这是因为$1\times1$的卷积既可以增加模型的非线性拟合能力,同时还不会改变卷积层的可视野。
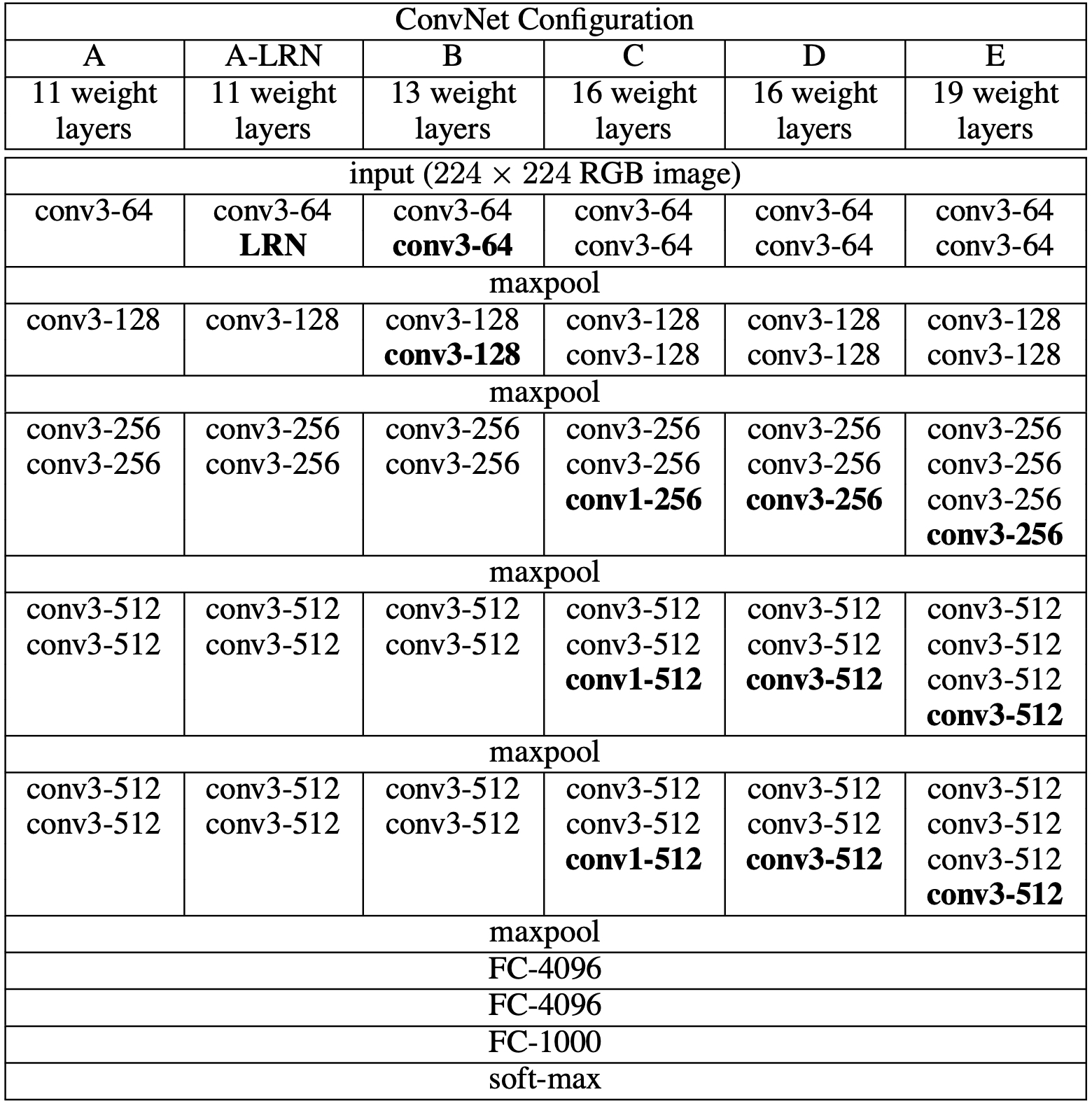
同时,在这5种网络架构中,所有卷积运算的步长都被设置成了固定的$1$,并且为了使得卷积后特征图的大小同输入时保持一致,网络在每次卷积之前均做了对应的填充处理,即特征图的大小只会在池化后产生变化。在池化方面,5种网络模型均使用了5次最大池化操作,其窗口大小均为$2\times2$,移动步长均为$2$。从图4-36可以看出,VGG-19网络结构的参数量大约在1亿1千4百万左右,假如每个权重参数均使用32位浮点数进行表示,则每个权重参数将占用4个字节,则VGG-19模型的大小约为550MB。
在完成一系列的卷积处理后,VGG会将卷积得到的特征图再输入到全连接网络中,其中前两个全连接层均包含有$4096$个神经元,而最后一个全连接层神经元的个数则是对应的分类数$1000$,紧接着再是一个Softmax的分类层。对于所有的5种网络结构来说,这部分都采用了相同的配置。最后,在VGG中所有的隐藏层(所有卷积层和前两个全连接层)都使用了ReLU非线性变换。
从图4-36所示的网络结构可以看出,在整个过程中VGG都仅仅只使用了$3\times3$大小的卷积核,而摒弃了诸如$5\times5$或者是$7\times7$这类更大的卷积核。因为论文作者研究发现,连续2次(中间没有池化)使用窗口为$3$的卷积核卷积后的可视野等同于一次窗口大小为$5$的卷积过程;而连续3次(中间同样没有池化)使用$3\times3$卷积,其效果等价于1次窗口大小为$7$的卷积过程。
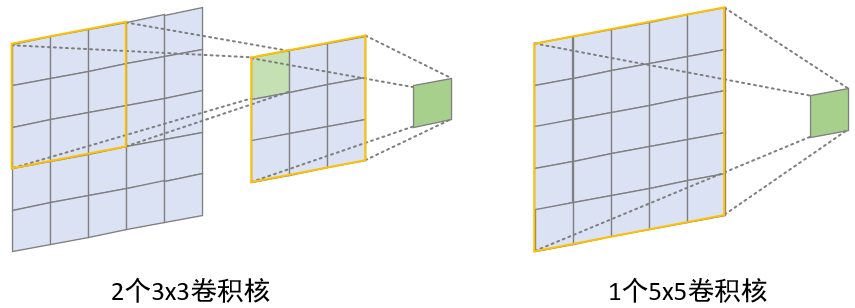
如图4-37所示,左右两边均是大小为$5\times5$的输入,左边通过连续两次$3\times3$大小的卷积核进行卷积后能够实现$5\times5$的可视野;而右边仅用一次$5\times5$大小的卷积核进行卷积后同样也能够实现$5\times5$的可视野。那这样做的好处是什么呢?以窗口大小为$7$和连续3个窗口大小为$3$的卷积过程为例,作者认为:①连续3次卷积的同时也进行非线性变化得到的模型,比仅仅只进行一次卷积和非线性变换得到的模型要更具有泛化能力,尽管两者能够获得同样大小的可视野,而这也可以看作是对$7\times7$的卷积核施加了一次正则化的结果;②可以有效减少参数量,假设卷积时输入输出的通道数均为$C$,则一次$7\times7$的卷积需要的参数量为$7^2C^2=49C^2$,而3次$3\times3$的卷积需要的参数量为$(3^2C^2)3=27C^2$,前者比后者多了$81\%$的参数量。
4.6.3 VGG实现#
从图4-36可以看出VGG有多种不同类型的网络配置,如果是按照之前的实现思路那么就得写多份代码,但显然这里面有很多代码是可以复用。所以首先需要实现一个通用模块,然后只需要传入对应的配置参数就能够实现对应的网络结构。以下完整示例代码可以参见Code/Chapter04/C05_VGG/文件。
1. 辅助模块
如下代码所示就是A、B、D和E这4种网络结构的配置参数,其中'M'表示该层为最大池化层,而其它的数字则表示对应的卷积核个数。至于网络结构C这里就不进行示例了,有兴趣的读者可以自己修改。
1 vgg_config={'A':[64,'M',128,'M',256,256,'M',512,512,'M',512,512,'M'],
2 'B':[64,64,'M',128,128,'M',256,256,'M',512,512,'M',512,512,'M'],
3 'D':[64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M',512,512,512,'M'],
4 'E'[64,64,'M',128,128,'M',256,256,256,256,'M',512,512,512,512,'M',512,512,512,512,'M']}进一步,在定义完这个配置字典后便可以实现构造网络结构的辅助函数,示例代码如下所示:
1 def make_layers(config):
2 layers = []
3 in_channels = config.in_channels
4 cfg = vgg_config[config.vgg_type]
5 for v in cfg:
6 if v == 'M':
7 layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
8 else:
9 conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
10 layers += [conv2d, nn.ReLU(inplace=True)]
11 in_channels = v
12 return nn.Sequential(*layers) # *号的作用解包这个list在上述代码中,第1行是传入的模型配置信息。第2行用来保存所有的网络层。第4行用于根据传入的参数返回VGG中对应的网络结构。第5~11行是依次遍历每个配置参数来构建对应的VGG网络结构。第12行则是将列表中的所有网络层放入到nn.Sequential()中。
2. 前向传播
在实现完上述辅助模块后,便可以进一步实现VGG模型的整个前向传播过程,示例代码如下所示:
1 class VGGNet(nn.Module):
2 def __init__(self, features, config):
3 super(VGGNet, self).__init__()
4 self.features = features
5 self.classifier = nn.Sequential(
6 nn.Flatten(), nn.Linear(512 * 7 * 7, 4096),
7 nn.ReLU(True), nn.Dropout(),
8 nn.Linear(4096, 4096), nn.ReLU(True),
9 nn.Dropout(), nn.Linear(4096, config.num_classes))
10 if config.init_weights:
11 self._initialize_weights()
12
13 def forward(self, x, labels=None):
14 x = self.features(x)
15 logits = self.classifier(x)
16 if labels is not None:
17 loss_fct = nn.CrossEntropyLoss(reduction='mean')
18 loss = loss_fct(logits, labels)
19 return loss, logits
20 else:
21 return logits在上述代码中,第2行中features便是上面make_layers函数所返回的结果。第5~9行是完成后面3个全连接层构造。第10~11行则是根据传入参数判断模型中的所有权重参数是否重新进行初始化。第13~21行是对应的整个前向传播计算过程。其中_initialize_weights方法实现带入如下所示:
1 def _initialize_weights(self):
2 for m in self.modules():
3 if isinstance(m, nn.Conv2d):
4 nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
5 if m.bias is not None:
6 nn.init.constant_(m.bias, 0)
7 elif isinstance(m, nn.Linear):
8 nn.init.normal_(m.weight, 0, 0.01)
9 nn.init.constant_(m.bias, 0)在上述代码中,第2行表示开始遍历每一层网络。第3~6行判断如果当前层是卷积层,则权重使用kaiming_normal_方法进行重新初始化,偏置则直接赋值为0。第7~9行用于判断如果当前层是全连接层,则权重使用正态分布进行重新初始化,偏置重置为0。之所以需要重新对模型中的参数进行初始化,是因为在利用梯度下降算法求解参数时,参数的初始化状态非常重要,这点可以参见「第3.3节 反向传播原理:梯度下降与神经网络参数更新」内容。一个好的初始化参数在少数几次迭代后目标函数便可能达到达全局最优解,而一个糟糕的初始化参数往往可能使得目标函数发散。
在实现完前向传播的整个编码过程后,便可以通过如下方式进行使用:
1 def vgg(config=None):
2 cnn_features = make_layers(config)
3 model = VGGNet(cnn_features, config)
4 return model
5
6 class Config(object):
7 def __init__(self):
8 self.vgg_type = 'B'
9 self.num_classes = 10
10 self.init_weights = True
11 self.in_channels = 3
12
13 if __name__ == '__main__':
14 config = Config()
15 vgg13 = vgg(config)
16 x = torch.rand(1, 3, 224, 224)
17 y = vgg13(x)
18 print(y.shape)在上述代码中,第1~4行便是根据配置信息返回一个VGG网络模型。第6~11行则是定义相关的配置信息,这里我们定义的是一个13层的VGG网络,分类数量为10。第14~18行是根据相应的输入返回最后前向传播的计算结果,如下所示:
1 torch.Size([1, 10])3. 构造数据集
在完成模型的前向传播过程后便可以根据需要来完成数据集的构建。在这里,我们使用到的是图像处理领域中另外一个场景的图片分类数据集CIFAR10。CIFAR10数据集一共包含有训练样本50000个和测试样本10000个,每个样本的大小均为3通道$32\times32$,分类类别数为10。

如图4-38所示便是CIFAR10数据集的可视化结果。进一步,我们可以通过如下方式来构造该数据集对应的迭代器,示例代码如下所示:
1 def load_dataset(config, is_train=True):
2 trans = [transforms.ToTensor()]
3 if config.resize:
4 trans.append(transforms.Resize(size=config.resize,
5 interpolation=InterpolationMode.BILINEAR))
6 if config.augment and is_train:
7 trans += [transforms.RandomHorizontalFlip(0.5),
8 transforms.CenterCrop(config.resize),]
9 trans = transforms.Compose(trans)
10 dataset = CIFAR10(root='~/Datasets/CIFAR10', train=is_train,
11 download=True, transform=trans)
12 iter = DataLoader(dataset, batch_size=config.batch_size, shuffle=True,
13 num_workers=1, pin_memory=False)
14 return iter在上述代码中,第2~9行是相应的数据增强操作。第10~11行是载入新的CIFAR10数据集,其余部分的代码同之前一样,所以这里就不再赘述。
4. 模型训练
在前面各项工作都准备完毕之后便可以进一步实现模型的训练过程,部分核心代码如下所示:
1 def train(config):
2 train_iter = load_dataset(config, is_train=True)
3 test_iter = load_dataset(config, is_train=False)
4 model = vgg(config)
5 ......
6 optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
7 for epoch in range(config.epochs):
8 for i, (x, y) in enumerate(train_iter):
9 x, y = x.to(config.device), y.to(config.device)
10 loss, logits = model(x, y)
11 loss.backward()
12 optimizer.step() # 执行梯度下降
13 global_steps += 1
14 if i % 50 == 0:
15 acc = (logits.argmax(1) == y).float().mean()
16 writer.add_scalar('Training/Accuracy', acc, global_steps)
17 writer.add_scalar('Training/Loss', loss.item(), global_steps)
18 test_acc = evaluate(test_iter, model, config.device)
19 logging.info(f"Epochs[{epoch + 1}/{config.epochs}]--Acc on test {test_acc}")
20 writer.add_scalar('Testing/Accuracy', test_acc, global_steps)
21 if test_acc > max_test_acc:
22 max_test_acc = test_acc
23 state_dict = deepcopy(model.state_dict())
24 torch.save(state_dict, config.model_save_path)在上述代码中,第2~3行是根据条件载入训练集和测试集对应的迭代器。第4行是根据配置信息实例化一个VGG模型。第9~13行则是分别进行前向传播、反向传播和梯度下降等过程。第14~20行则是根据对应的判断条件对损失、准确率等通过Tensorboard进行可视化。第21~24行则是根据条件对当前的模型权重参数进行持久化保存。
在运行上述代码中之后,便可看到如下所示输出结果:
1 Epochs[1/15]--batch[0/782]--Acc: 0.0781--loss: 2.3034
2 Epochs[1/15]--batch[50/782]--Acc: 0.2188--loss: 2.2064
3 Epochs[1/15]--batch[100/782]--Acc: 0.2656--loss: 1.9216
4 ...
5 Epochs[13/15]--Acc on test 0.8398
6 Epochs[14/15]--Acc on test 0.8416
7 Epochs[15/15]--Acc on test 0.84395. 模型推理
最后,在完成模型训练以后便可以载入训练时持久化到本地的模型对新样本进行推理预测,实现代码类似上一节中的对应内容直接查看源码即可,这里我们不再进行赘述。
到此为止,对于VGG网络模型的原理以及如何通过PyTorch来进行实现我们就介绍完了。这里顺便提一句,以上前向传播代码我们是直接取自于PyTorch的官方实现,并且我们还可以直接通过下面这一行代码来完成对于VGG模型的调用:
1 from torchvision.models import vgg19当然,PyTorch官方实现的模型还包括了AlexNet、ResNet和GoogleNet等比较经典的网络模型,同时还能直接使用对应已经训练好的预训练模型,各位读者可以自行尝试使用。
4.6.4 小结#
在本节内容中,我们首先VGG网络的动机及其需要解决的问题;然后详细介绍了VGG模型的原理和参数设置,并介绍了如何一步一步的来实现VGG中的各个网络模型;最后还以CIFAR10数据集为例对VGG16模型进行了测试。在下一节内容中,我们将开始介绍卷积网络中的第4个经典模型NIN。
引用#
[1] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]. International Conference on Learning Representations, 2015.
[2] Sermanet P, Eigen D, Zhang X, et al. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks[C]. International Conference on Learning Representations, 2014.