8.4 ConvLSTM网络#
在「第8.3节 CNN-RNN模型:卷积与循环网络融合方法」内容中,我们介绍了几种将CNN和RNN进行结合的时序模型,包括串行的方式将CNN和RNN进行结合、以并行的方式将CNN和RNN进行结合。同时,在这些任务场景中序列样本所拥有的一个共同特点便是对于每个序列中的每个时刻来说,其特征表示均为一个向量。但是在现实情况中,还有一类时序数据是以数据帧的形式而存在,即每一时刻均为一个三维(或二维)矩阵。这样的数据也被称为时空(Spatiotemporal)数据,例如最常见的视频数据。因此,在本节内容中,我们将会介绍另外一种结合CNN和RNN的深度学习模型ConvLSTM来解决这一问题[1]。
8.4.1 ConvLSTM动机#
在气象学领域中,对于如何能够准确地预测未来短时间(如0~6小时)内的降雨情况一直以来就是一个热门的研究方向。通常,研究者会根据实时拍摄得到的雷达回波数据(Radar Echo Data)作为输入序列来预测接下来一段时间内的降雨情况。得益于深度学习的发展,有研究者提出了基于循环神经网络和卷积神经网络的预测模型。尽管通过这样的结合方式也能够建模完成这一预测任务,但是模型并没有充分考虑到时空数据中的空间依赖关系(Spatial Correlation)。
基于这样的动机,施行健等人[1]在2015年提出了一种融合CNN和LSTM的时序预测模型ConvLSTM。ConvLSTM模型的动机是通过将CNN和LSTM结合起来克服传统RNN和CNN各自的局限性。ConvLSTM引入了空间上的卷积操作和时间上的循环操作,同时保留了LSTM中的记忆单元和门控机制,能够捕捉到时间和空间上的特征,考虑到时序数据的长期依赖性和空间结构的局部相关性。因此,ConvLSTM可以有效地用于处理时空数据,例如视频数据、雷达数据等。
8.4.2 ConvLSTM结构#
从整体上看,ConvLSTM的模型结构主要分为两部分:在时序结构上遵循典型的RNN网络结构;在空间结构上遵循CNN的特征提取方式。简单来说,ConvLSTM模型就等价于将LSTM中的所有全连接结构替换为卷积结构,同时采用了基于窥视连接的结构(详见「第7.4.5节 GRU原理:门控循环单元与 RNN 改进方法」内容)。如图8-5所示便是ConvLSTM的循环记忆单元。
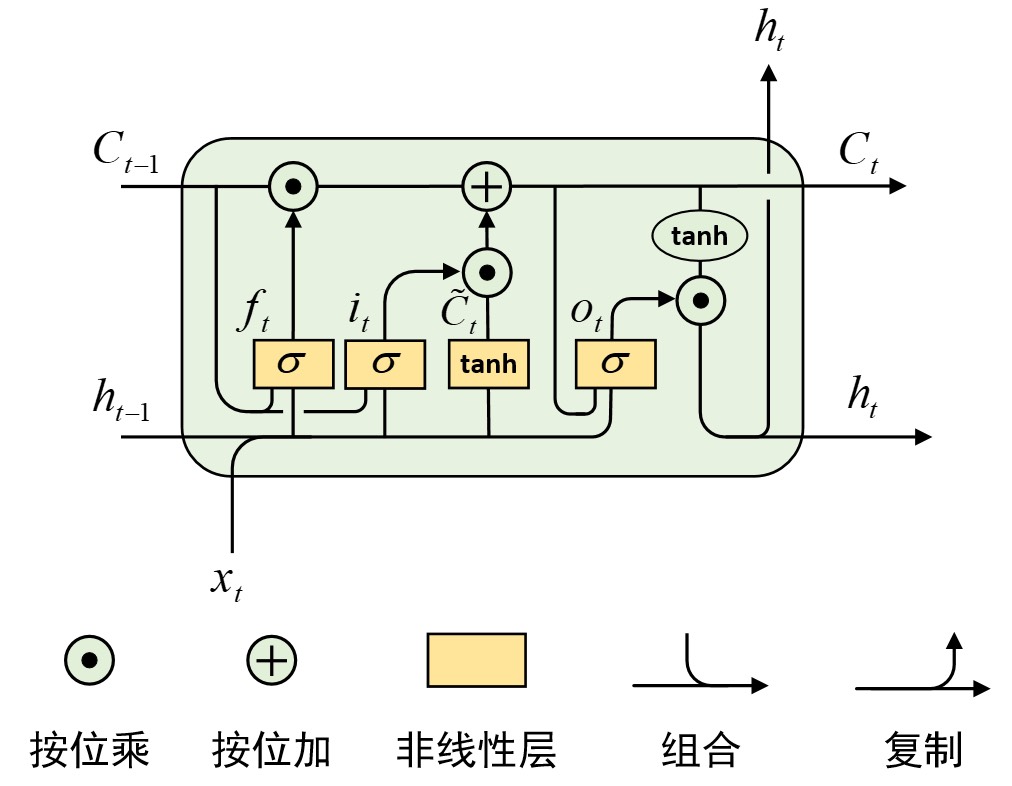
如图8-5所示便是ConvLSTM的记忆单元结构图,总体上同LSTM类似包含有4个门结构,因此这部分内容不在赘述参考「第7.3节 LSTM原理:长短期记忆网络如何解决长依赖」内容即可。对于ConvLSTM来说,其唯一变化的地方在于各个门控单元的计算方式,具体计算过程如式(8-1)所示。
$$ \begin{aligned} f_t&=\sigma([h_{t-1},x_t,C_{t-1}]\ast W_f+b_f)\\[2ex] i_t&=\sigma([h_{t-1},x_t,C_{t-1}]\ast W_i+b_i)\\[2ex] \tilde{C_t}&=\tanh([h_{t-1},x_t]\ast W_c+b_c)\\[2ex] C_t&=f_t\odot C_{t-1}\oplus i_t\odot\tilde{C_t}\\[2ex] o_t&=\sigma([h_{t-1},x_t,C_{t}]\ast W_o+b_o)\\[2ex] h_t&=o_t\odot\tanh(C_t) \end{aligned}\tag{8-1} $$在式(8-1)中,$\ast$ 表示卷积操作,$W_f$、$W_i$、$W_c$和$W_o$均为卷积核,因此ConvLSTM模型的输入将是一个5维张量,即[batch_size,time_step,in_channels,height,width]。由此可知,$x_t$的形状为[batch_size,in_channels,height,width];$h_t$和$C_t$的形状均为[batch_size,out_channels,height,width];$[h_{t-1},x_t]$的形状为[batch_size,in_channels+out_channels,height,width];$[h_{t-1},x_t,C_{t-1}]$的形状为[batch_size,in_channels+out_channels*2,height,width]。
同时,由于循环神经网络可以在时间维度和网络层数两个方向展开,因此在ConvLSTM记忆单元中每次卷积之前都会进行填充,以保证每次卷积后特征图的长和宽不发生改变,所以$f_t$、$i_t$和$o_t$的形状均为[batch_size, out_channels, height, width]。对于ConvLSTM来说,其同样类似于RNN模型,因此也可以根据「第7.1.4节 RNN原理:循环神经网络的结构与序列建模」中的结构来构造网络模型并完成相关下游任务。
8.4.3 ConvLSTM实现#
在清楚ConvLSTM模型的相关原理之后,我们再来看如何借助PyTorch快速实现ConvLSTM模型。由于PyTorch框架中的nn模块并没有实现ConvLSTM模型,因此需要我们自己动手进行实现。以下完整示例代码可以参见Code/Chapter08/C05_ConvLSTM/ConvLSTM.py文件。
1. ConvLSTMCell实现
为了便于实现这里以不带窥视连接的结构进行介绍。首先,需要实现一个单独的ConvLSTM记忆单元的前向传播过程,示例代码如下所示:
1 class ConvLSTMCell(nn.Module):
2 def __init__(self, in_channels, out_channels, kernel_size, bias):
3 super(ConvLSTMCell, self).__init__()
4 self.in_channels = in_channels
5 self.out_channels = out_channels
6 self.kernel_size = kernel_size
7 self.padding = kernel_size[0] // 2, kernel_size[1] // 2
8 self.bias = bias
9 self.conv = nn.Conv2d(in_channels=self.in_channels + self.out_channels,
10 out_channels=4 * self.out_channels,kernel_size=self.kernel_size,
11 padding=self.padding,bias=self.bias)在上述代码中,第1行中in_channels表示输入特征图的通道数,out_channels表示输出特征图的通道数,kernel_size表示卷积核的窗口大小为一个元组。第7行用于计算填充的数量,以保证每次卷积后特征图的大小不发生变化,其计算规则可见「第4.3.2节 卷积和池化:CNN 中 padding 与 pooling 的作用」内容;同时,为了提高计算效率,对于ConvLSTM中所有卷积操作可以在一个Conv2d实例中完成,第9~10行中in_channels和out_channels两个参数的传入值便是这一点的体现。
进一步,整个前向传播计算过程的示例代码如下所示:
1 def forward(self, input_tensor, last_state):
2 h_last, c_last = last_state
3 combined_input = torch.cat([input_tensor, h_last], dim=1)
4 combined_conv = self.conv(combined_input)
5 cc_i, cc_f, cc_o, cc_g = torch.split(combined_conv, self.out_channels, dim=1)
6 i = torch.sigmoid(cc_i)
7 f = torch.sigmoid(cc_f)
8 o = torch.sigmoid(cc_o)
9 g = torch.tanh(cc_g)
10 c_next = f * c_last + i * g
11 h_next = o * torch.tanh(c_next)
12 return h_next, c_next
13
14 def init_hidden(self, batch_size, image_size):
15 height, width = image_size
16 return (torch.zeros(batch_size, self.out_channels,
17 height, width, device=self.conv.weight.device),
18 torch.zeros(batch_size, self.out_channels,
19 height, width, device=self.conv.weight.device))在上述代码中,第1行input_tensor表示当前时刻的输入形状为[batch_size, in_channels, height, width]。第2行last_state表示上一个时刻的输出,包含$h_{t-1}$和$C_{t-1}$两个部分形状均为[batch_size, out_channels, height, width]。第3行表示将$h_{t-1}$和$x_t$进行拼接,形状为[batch_size, in_channels+out_channels, height, width]。第4行为同时计算4个部分的卷积运算。第5行是将卷积运算后的整体结果在dim=1这个维度上按照self.out_channels的大小分割,即分割成4个部分,因为卷积运算后的通道数为4 * self.out_channels。第6~12行则是进行相关状态的计算输出。第14~19行是定义一个方法来实现初始时刻的初始化过程。
2. ConvLSTM实现
在完成ConvLSTMCell模块的实现之后我们便可以基于此来完成ConvLSTM模块的实现,即完成在时间和网络层数两个维度的计算过程。在这之前需要实现两个辅助方法来完成相关参数的扩展与合法性检验,示例代码如下所示:
1 @staticmethod
2 def _check_kernel_size_consistency(kernel_size):
3 if not (isinstance(kernel_size, tuple) or
4 (isinstance(kernel_size, list) and
5 all([isinstance(elem, tuple) for elem in kernel_size]))):
6 raise ValueError('kernel_size must be tuple or list of tuples')
7
8 @staticmethod
9 def _extend_for_multilayer(param, num_layers):
10 if not isinstance(param, list):
11 param = [param] * num_layers
12 return param在上述代码中,第2~6行_check_kernel_size_consistency()方法用来检验参数kernel_size的合法性,即对于多层的ConvLSTM来,传入的kernel_size要么是一个元组如(3,3),要么是一个包含有多个元组的列表如[(3,3),(5,5)],前者表示所有层的卷积核窗口大小均为(3,3),后者表示在两层的ConvLSTM中卷积核的窗口大小分别为(3,3)和(5,5)。第9~12行则是对相关参数进行延展,例如kernel_size=(3,3)且num_layers=2,那么将会返回[(3,3),(3,3)]这样一个结果。
进一步,可以开始实现ConvLSTM模块,示例代码如下所示:
1 class ConvLSTM(nn.Module):
2 def __init__(self, in_channels, out_channels, kernel_size, num_layers,
3 batch_first=False, bias=True, return_all_layers=False):
4 super(ConvLSTM, self).__init__()
5 self._check_kernel_size_consistency(kernel_size)
6 kernel_size = self._extend_for_multilayer(kernel_size, num_layers)
7 out_channels = self._extend_for_multilayer(out_channels, num_layers)
8 if not len(kernel_size) == len(out_channels) == num_layers:
9 raise ValueError('参数不合法')
10 self.in_channels = in_channels
11 self.out_channels = out_channels
12 self.kernel_size = kernel_size
13 self.num_layers = num_layers
14 self.batch_first = batch_first
15 self.bias = bias
16 self.return_all_layers = return_all_layers
17 cell_list = []
18 for i in range(0, self.num_layers):
19 cur_in_channels = self.in_channels if i == 0 else self.out_channels[i - 1]
20 cell_list.append(ConvLSTMCell(in_channels=cur_in_channels,bias=self.bias,
21 out_channels=self.out_channels[i],kernel_size=self.kernel_size[i]))
22 self.cell_list = nn.ModuleList(cell_list)在上述代码中,第2行in_channels为输出样本的通道数为整型,out_channels为每一层的输出通道数可以是整型或者列表,kernel_size为每一层的卷积核窗口大小可以是元组或者为包含元组的列表,num_layers表示网络的层数。第2行return_all_layers表示是否返回每一层的计算结果。第5~9行是分别检验相关参数的合法性以及进行扩展。第18~22行则是开始实例化每一层对应的ConvLSTM记忆单元。
紧接着,整个前向传播的计算过程示例代码如下所示:
1 def forward(self, input_tensor, hidden_state=None):
2 if not self.batch_first:
3 input_tensor = input_tensor.permute(1, 0, 2, 3, 4)
4 batch_size, time_step, _, height, width = input_tensor.size()
5 if hidden_state is not None:
6 raise NotImplementedError()
7 else:
8 hidden_state = self._init_hidden(batch_size,(height, width))
9 layer_output_list, last_state_list = [], []
10 cur_layer_input = input_tensor
11 for layer_idx in range(self.num_layers):
12 h, c = hidden_state[layer_idx]
13 output_inner = []
14 cur_layer_cell = self.cell_list[layer_idx]
15 for t in range(time_step):
16 h, c = cur_layer_cell(cur_layer_input[:, t, :, :, :], [h, c])
17 output_inner.append(h)
18 layer_output = torch.stack(output_inner, dim=1)
19 cur_layer_input = layer_output
20 layer_output_list.append(layer_output)
21 last_state_list.append([h, c])
22 if not self.return_all_layers:
23 layer_output_list = layer_output_list[-1:]
24 last_state_list = last_state_list[-1:]
25 return layer_output_list, last_state_list在上述代码中,第2~3行用于判断批大小是否为第1个维度,不是则进行维度交互。第4行是获取输出张量各个维度的数值。第5~8行是对初始状态进行初始化。第9行中,layer_output_list用于保存每一层的所有输出$h$,每个元素的形状均为[batch_size, time_step, out_channels, height, width],last_state_list用于保存每一层最后一个时刻的输出$h$和$c$,即形容[(h,c),(h,c)...]。第11~12行开始遍历每一层的记忆单元并取对应的初始值。第14行当前层对应的ConvLSTMCell实例化对象。第15~17行开始在时间维度对当前层进行展开计算,其中output_inner用于报错当前时刻计算的得到的$h$值。第18行表示将当前层所有时刻的输出$h$进行堆叠以便作为下一层每个时刻的输入,形状为[batch_size, time_step, out_channels, height, width]。第20~21行则是分别保存对应的输出结果。第22~25行为按照条件返回部分或全部的计算结果,其中last_states[-1][0]表示最后一层最后一个时刻的输出$h$,形状为[batch_size, out_channels, height, width]。
最后,可以通过如下方式进行使用:
1 def example1():
2 out_channels = [5, 6, 7]
3 kernel_size = [(3, 3), (5, 5), (7, 7)]
4 in_channels, num_layers = 3, 3
5 batch_size, time_step = 1, 4
6 height, width = 16, 16
7 x = torch.rand((batch_size, time_step, in_channels, height, height))
8 model = ConvLSTM(in_channels=in_channels,out_channels=out_channels,
9 kernel_size=kernel_size,num_layers=num_layers,
10 batch_first=True,bias=True,return_all_layers=True)
11 layer_output_list, last_states = model(x)
12 print(last_states[-1][0])
13 print(layer_output_list[-1][:, -1])上述代码运行结束后,将会输出类似如下结果:
1 tensor([[[[-0.0171, -0.0154, -0.0130, ..., -0.0129, -0.0135, -0.0143],
2 [-0.0158, -0.0149, -0.0130, ..., -0.0157, -0.0164, -0.0172],
3 [-0.0129, -0.0133, -0.0091, ..., -0.0123, -0.0132, -0.0146],
4 ...,]]]])
5
6 tensor([[[[-0.0171, -0.0154, -0.0130, ..., -0.0129, -0.0135, -0.0143],
7 [-0.0158, -0.0149, -0.0130, ..., -0.0157, -0.0164, -0.0172],
8 [-0.0129, -0.0133, -0.0091, ..., -0.0123, -0.0132, -0.0146],
9 ...,]]]])8.4.4 KTH数据集构建#
在完成ConvLSTM模型的实现之后,我们再来看如何基于ConvLSTM网络模型完成KTH数据集这一视频分类任务。以下完整示例代码可以参见Code/utils/data_helper.py文件。
1. 数据集介绍
KTH数据集是一个广泛应用于动作识别和行为分析的计算机视觉数据集,它是由瑞典皇家工学院(KTH Royal Institute of Technology)收集和发布的,旨在提供用于动作识别和行为分析的标准测试数据[2]。KTH数据集包含有6个不同的动作类别,包括Boxing(拳击)、Handclapping(鼓掌)、Handwaving(挥手)、Jogging(慢跑)、Running(快跑)和Walking(行走),由 25 名受试者在4种不同的场景中进行多次拍摄得到,即一共包含有$25\times6\times4=600$个视频文件。
对于每个视频来说,分辨率均为$120\times 160$像素,其长度从最短230帧到最长1120帧不等,并以AVI格式进行存储。如图8-6所示便是部分视频帧的可视化结果。

后续,模型需要根据输入的连续多帧视频来识别其属于对应的分类。
2. 读取原始数据
在清楚数据集的相关信息后进一步便可以编码读取并进行相关的预处理工作。KTH下载完成后一共包含有6个压缩包,分别解压之后即可。首先我们需要先定义一个类并完成其初始化函数的构造,示例代码如下所示:
1 class KTHData(object):
2 DATA_DIR = os.path.join(DATA_HOME, 'kth')
3 CATEGORIES = ["boxing", "handclapping", "handwaving", "jogging", "running", "walking"]
4 TRAIN_PEOPLE_ID = [1, 2, 4, 5, 6, 7, 9, 11, 12, 15, 17, 18, 20, 21, 22, 23, 24]
5 VAL_PEOPLE_ID = [3, 8, 10, 19, 25]
6 TEST_PEOPLE_ID = [13, 14, 16]
7 FILE_PATH = os.path.join(DATA_DIR, 'kth.pt')
8
9 def __init__(self, frame_len=15,batch_size=4,is_gray=True,
10 is_sample_shuffle=True,transforms=None):
11 self.frame_len = frame_len
12 self.batch_size = batch_size
13 self.is_sample_shuffle = is_sample_shuffle
14 self.is_gray = is_gray
15 self.transforms = transforms在上述代码中,第2~3行用于定义数据集的目录和文件名。第4~6行为根据人物编号随机划分的训练集、验证集和测试集。第9~12行则是定义相关超参数,其中frame_len表示以该长度对视频进行分割构造样本,is_gray表示是否转换为灰度图,transforms表示进行图像增强操作。
接着,定义一个函数来载入原始的视频文件并转换成对应的数据帧。在这之前,需要先通过如下命令完成opencv库的安装:
1 pip install opencv-python在安装完成后,便可以根据如下方式来载入数据:
1 @staticmethod
2 def load_avi_frames(path=None, is_gray=False):
3 video = cv2.VideoCapture(path)
4 frames = []
5 while video.isOpened():
6 ret, frame = video.read()
7 if not ret:
8 break
9 if is_gray:
10 frame = Image.fromarray(frame)
11 frame = frame.convert("L")
12 frame = np.array(frame.getdata()).reshape((120, 160, 1))
13 frames.append(frame)
14 return np.array(frames, dtype=np.uint8)在上述代码中,第2行用于创建一个视频捕获对象,用于读取视频文件。第5~6行用于循环读取视频帧,直到视频结束。第7~8行检查是否成功读取到帧图像数据。第9~12行用于将原始图片转换为灰度图,因为后续数据集用作分类所以转换为单通道的灰度图可以降低计算量。第14行将返回得到一个4维数组,即[n,120,160,channel],其中n表示视频的帧数。
3. 构建样本
在原始样本读取完成后下一步便可以开始构造样本。由于每个视频的长度并不一致,所以下面的示例中将粗略地以15帧为长度对原始视频进行采样,例如150帧的数据将可以采样得到10个样本。样本相关构建过程示例代码如下所示:
1 @process_cache(unique_key=["frame_len", "is_gray"])
2 def data_process(self, file_path=None):
3 train_data, val_data, test_data = [], [], []
4 for label, dir_name in enumerate(self.CATEGORIES):
5 video_dir = os.path.join(self.DATA_DIR, dir_name)
6 video_names = os.listdir(video_dir)
7 for name in video_names:
8 people_id = int(name[6:8])
9 video_path = os.path.join(video_dir, name)
10 frames = self.load_avi_frames(video_path, self.is_gray)
11 s_idx, e_idx = 0, self.frame_len
12 while e_idx <= len(frames):
13 sub_frames = frames[s_idx:e_idx]
14 if people_id in self.TRAIN_PEOPLE_ID:
15 train_data.append((sub_frames, label))
16 elif people_id in self.VAL_PEOPLE_ID:
17 val_data.append((sub_frames, label))
18 elif people_id in self.TEST_PEOPLE_ID:
19 test_data.append((sub_frames, label))
20 else:
21 raise ValueError(f"people id {people_id} 有误")
22 s_idx, e_idx = e_idx, e_idx + self.frame_len
23 data = {"train_data": train_data, "val_data": val_data, "test_data": test_data}
24 return data在上述代码中,第1行是用于缓存预处理结果的修饰器,详见「第5.7节 训练数据预处理与缓存:提升深度学习训练效率」内容。第4~6行是循环遍历每个目录下的视频文件,并得到该目录下所有视频文件的名称。第7行是开始遍历当前文件夹中的每个视频文件。第8行是根据文件名获取对应的人物编号。第9~10行读取得到原始的视频数据。第12~22行则是根据每个视频以固定长度进行采样构造样本,其中第13行中sub_frames的形状为[frame_len,120,160,channels]。第23~24行则是返回最后构造完成的样本数据。
4. 构建迭代器
在完成原始样本构建后进一步可以构造得到迭代器。首先需要实现一个辅助函数来处理每个小批量样本的数据,示例代码如下所示:
1 def generate_batch(self, data_batch):
2 batch_frames, batch_label = [], []
3 for (frames, label) in data_batch:
4 if self.transforms is not None:
5 frames = torch.stack([self.transforms(frame) for frame in frames], dim=0)
6 else:
7 frames = torch.tensor(frames.transpose(0, 3, 1, 2))
8 batch_frames.append(frames)
9 batch_label.append(label)
10 batch_frames = torch.stack(batch_frames, dim=0)
11 batch_label = torch.tensor(batch_label, dtype=torch.long)
12 return batch_frames, batch_label在上述代码中,第3行用于遍历小批量样本中的每个样本。第4~5行是循环对视频里的每一帧进行图像增强,其中frame的形状为[height, width, channels],在进行图像增强经过ToTensor()变换后形状会变成[channels,height,width]且每个像素值的范围会被缩放至0到1。第10行是将所有样本堆叠构造得到一个小批量标准数据,其形状为[batch_size, frame_len, channels, height, width]。
进一步,编码实现迭代器的构建,示例代码如下所示:
1 def load_train_val_test_data(self, is_train=False):
2 data = self.data_process(file_path=self.FILE_PATH)
3 if not is_train:
4 test_data = data['test_data']
5 test_iter = DataLoader(test_data, batch_size=self.batch_size,
6 shuffle=True, collate_fn=self.generate_batch)
7 return test_iter
8 train_data, val_data = data['train_data'], data['val_data']
9 train_iter = DataLoader(train_data, batch_size=self.batch_size,
10 shuffle=self.is_sample_shuffle,collate_fn=self.generate_batch)
11 val_iter = DataLoader(val_data, batch_size=self.batch_size,
12 shuffle=False, collate_fn=self.generate_batch)
13 return train_iter, val_iter在上述代码中,第2行用于返回data_process方法采样得到的原始样本数据。第3~7行是构建得到测试集对应的迭代器,其中generate_batch方法将作为参数传入到类DataLoader中进行使用。第8~13行则是构建得到训练集和验证集对应的迭代器。
8.4.5 KTH动作识别任务#
在完成数据集构建之后便可以以ConvLSTM为基础构建得到视频分类模型,其总体思路依旧是取最后一层最后一个时刻的输出作为整个视频序列的特征表示,然后通过一个分类层完成分类任务。以下完整示例代码可以参见Code/Chapter08/C05_ConvLSTM/ConvLSTM.py文件。
1. 前向传播
根据上述建模思路,基于ConvLSTM的KTH动作识别任务模型的前向传播过程示例代码如下所示:
1 class ConvLSTMKTH(nn.Module):
2 def __init__(self, config=None):
3 super().__init__()
4 self.conv_lstm = ConvLSTM(config.in_channels, config.out_channels,
5 config.kernel_size, config.num_layers, config.batch_first)
6 self.max_pool = nn.MaxPool2d(kernel_size=(5, 5), stride=2, padding=2)
7 self.hidden_dim = (config.width * config.height) // 4 *
8 self.conv_lstm.out_channels[-1]
9 self.classifier = nn.Sequential(nn.Flatten(),
10 nn.Linear(self.hidden_dim, config.num_classes))在上述代码中,第4~5行用于实例化一个多层的ConvLSTM循环单元。第6行则是实例化一个最大池化层,其中池化窗口大小为5的并且为了保持形状不变进行了填充。第7~8行是计算池化层后特征图拉伸后的维度,其中4表示长宽均缩小了2倍所以总的数量会缩小4倍。第9~10行则是实例化最后的分类层。
进一步,前向传播的的计算过程实现代码如下所示:
1 def forward(self, x, labels=None):
2 _, layer_output = self.conv_lstm(x)
3 pool_output = self.max_pool(layer_output[-1][0])
4 logits = self.classifier(pool_output)
5 if labels is not None:
6 loss_fct = nn.CrossEntropyLoss(reduction='mean')
7 loss = loss_fct(logits, labels)
8 return loss, logits
9 else:
10 return logits在上述代码中,第2行是多层ConvLSTM展开后的计算结果,输出形状信息见上面「第8.4.3节 ConvLSTM原理:时空序列预测与卷积循环模型」内容。第3行则是最大池化计算后的结果,形状为[batch_size, out_channels, 0.5*height, 0.5*width]。第4行则是最后的分类层,输出形状为[batch_size, num_classes]。
最后,可以通过如下方式来进行使用:
1 class ModelConfig(object):
2 def __init__(self):
3 self.num_classes = 6
4 self.in_channels = 3
5 self.out_channels = [32, 16, 8]
6 self.kernel_size = [(3, 3), (5, 5), (7, 7)]
7 self.num_layers = len(self.out_channels)
8 self.batch_size = 8
9 self.height = 120
10 self.width = 160
11 self.batch_first = True
12 self.time_step = 15
13
14 if __name__ == '__main__':
15 config = ModelConfig()
16 model = ConvLSTMKTH(config)
17 x = torch.randn([config.batch_size, config.time_step,
18 config.in_channels, config.height,config.width])
19 label = torch.randint(0, config.num_classes, [config.batch_size], dtype=torch.long)
20 loss, logits = model(x, label)
21 print(logits.shape) # torch.Size([8, 6])在上述代码中,第1~12行是参数配置定义类。第15~16行是分别实例化参数配置类和模型。第17~19行是构造输入和标签。第20~21便是模型的输出结果。
2. 模型训练
这部分代码依旧同先前的类似这里就不再赘述,各位读者直接参考源码即可。最后,在对网络模型进行训练时将会得到类似如下的输出结果:
1 Epochs[1/50]--batch[0/402]--Acc: 0.1562--loss: 1.7924
2 Epochs[1/50]--batch[50/402]--Acc: 0.4375--loss: 1.6179
3 Epochs[1/50]--batch[100/402]--Acc: 0.375--loss: 1.3734
4 Epochs[1/50]--batch[150/402]--Acc: 0.3438--loss: 1.2532
5 Epochs[1/50]--batch[200/402]--Acc: 0.4375--loss: 1.2269
6 Epochs[1/50]--batch[250/402]--Acc: 0.5625--loss: 0.925
7 Epochs[1/50]--batch[300/402]--Acc: 0.5938--loss: 0.8918
8 Epochs[1/50]--batch[350/402]--Acc: 0.5--loss: 1.085
9 Epochs[1/50]--Acc on val 0.5182
10 Epochs[30/50]--Acc on val 0.65518.4.6 小结#
在本节内容中,我们首先介绍了ConvLSTM模型的动机,并进一步详细介绍了ConvLSTM的基本原理,其整体结构类似于LSTM模型仅仅只是将其中的全连接替换成了卷积操作;然后一步一步介绍了ConvLSTM模型的实现过程及其示例用法;接着介绍了KTH数据集,并从零构建了用于人物动作识别的分类数据集;最后介绍了基于ConvLSTM的KTH动作识别模型。
引用#
[1] Shi X, Chen Z, Wang H, et al. Convolutional LSTM network: A machine learning approach for precipitation nowcasting [J]. Advances in neural information processing systems, 2015, 28.
[2] https://www.csc.kth.se/cvap/actions/