13.2 Label Propagation算法#
在上一节内容中,我们详细地介绍了半监督学习算法中一种用于分类问题的Self-Training算法,其核心思想是先通过少量的标注数据来训练一个弱分类器,其次再通过这个弱分类器来对无标签样本进行标注并选择其中的有效部分作为样本的真实标签,然后再次以当前已有的标注数据来训练模型并对无标签的样本进行标注并反复迭代,最后直到达到停止条件时结束。在本节内容中,将会介绍另外一种基于图结构的半监督学习模型——标签传播算法(Label Propagation)。
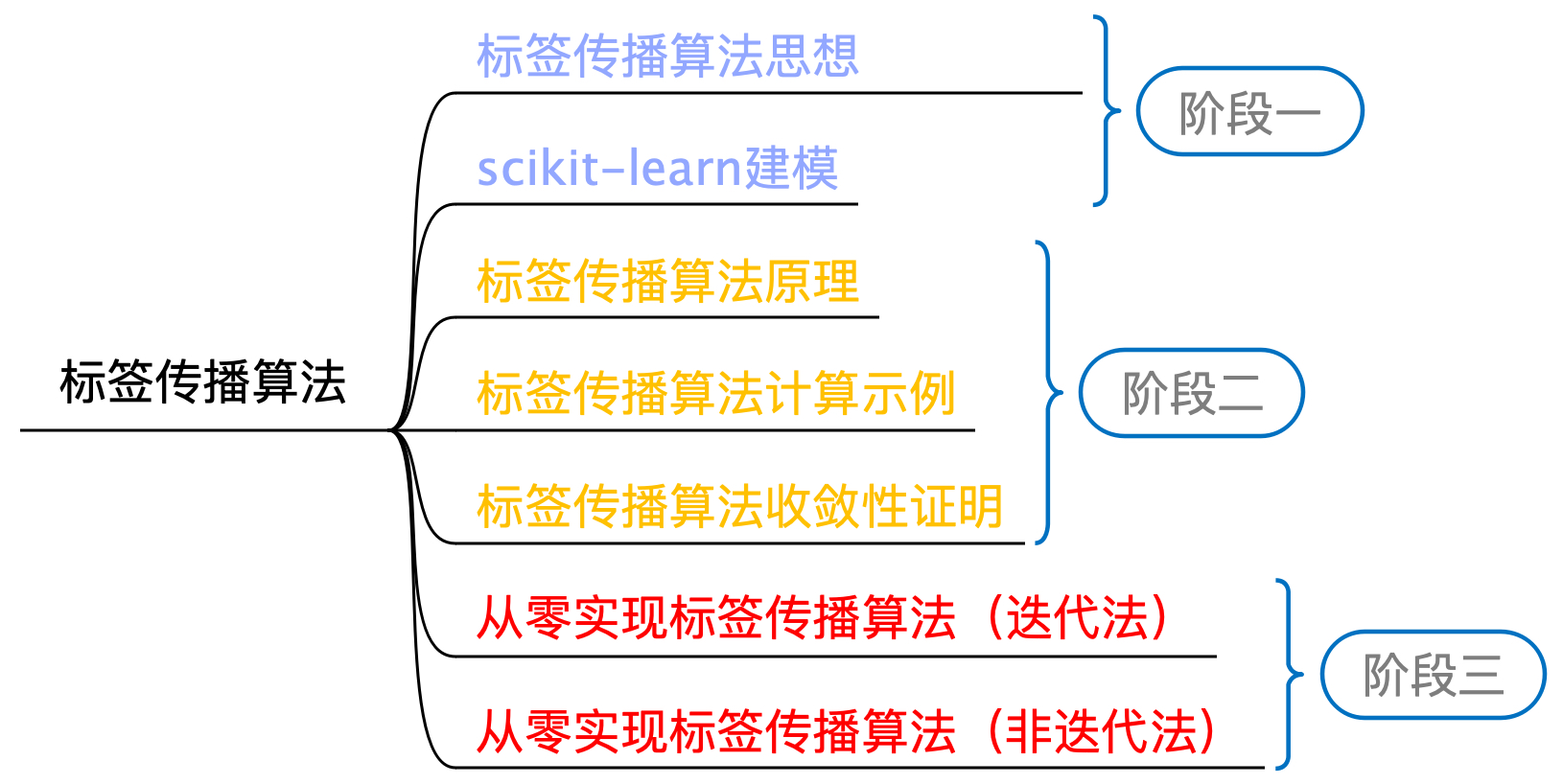
如图13-3所示便是标签传播算法的学习路线图,我们将先介绍其对应的思想以及sklearn的建模过程,然后再来介绍其背后的原理、计算示例和收敛性证明等过程,最后再一步步来从零实现整个算法。
13.2.1 Label Propagation算法思想#
标签传播算法的基本思想认为,在样本空间中距离越是相近的样本点越有可能具有相同的样本标签[1],而这一点也非常符合现实直觉。因此,在这样的假设条件下可以通过构建一个有向完全图来表示样本点之间的位置关系,其中图上的结点表示样本点,边表示两个结点之间的权重(样本点相距越近,则其对应的权重值便越大)。进一步,根据该权重图可以构造得到一个概率迁移矩阵$T$,其中$T_{ij}$表示样本点$j$转移到样本点$i$的概率。如果结点$i$是一个无标签的样本点,结点$j$是一个有标签的样本点,那么此时便可以根据$T_{ij}$的大小来判断样本点$i$是否与$j$具有相同的样本标签。
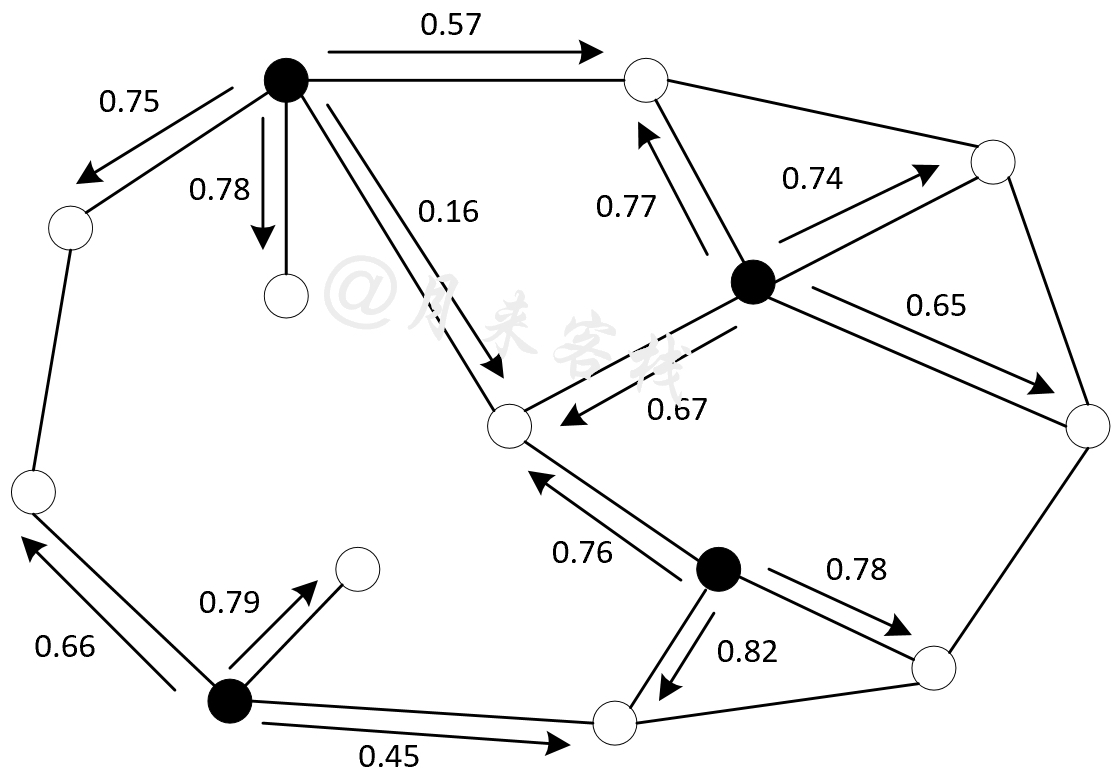
如图13-4所示,黑色圆点和白色圆点分别表示已知标签和未知标签的样本点,箭头表示传播方向,数值表示转移概率。根据标签传播算法的思想,白色样本点的所属类别可以通过黑色样本点到白色样本点的转移概率来进行确定。例如对于图13-4中间的白色样本点来说,其所属类别最有可能便是由右下角的黑色样本点所确定,因为此时对应的转移概率0.76在所有可能的转移情况中最大。
可以看出,标签传播算法的关键在于建立任意两个样本点之间转移的概率,然后通过已知标签的样本点来推断未知标签的样本点。
13.2.2 Label Propagation示例代码#
在sklearn中,我们可以从sklearn.semi_supervised中来导入标签传播算法LabelPropagation模块,以下完整示例代码可参见 AllBooKCode/Chapter13/C03_label_propagation.py 文件。同时,需要构造半监督学习所需要使用到的训练集,即将部分样本的标签置为-1,这是由模型在实现时所确定,示例代码如下:
1 def load_data():
2 x, y = load_iris(return_X_y=True)
3 x_train, x_test, y_train, y_test = \
4 train_test_split(x, y, test_size=0.3, random_state=2022)
5 rng = np.random.RandomState(20)
6 random_unlabeled_points = rng.rand(y_train.shape[0]) < 0.8
7 y_mixed = deepcopy(y_train)
8 y_mixed[random_unlabeled_points] = -1
9 return x_train, x_test, y_train, y_test, y_mixed在上述代码中,第2~4行是导入原始数据集并进行训练集和测试集的划分。第5~8行则是将训练集中$80\%$样本的标签重置为-1,同时也保留了原始重置之前的标签便于后续在训练集上测试模型的效果。第9行是返回最后各个部分的结果。
进一步,可以导入LabelPropagation进行模型训练和测试,示例代码如下:
1 from sklearn.semi_supervised import LabelPropagation
2 def test_label_propagation():
3 x_train, x_test, y_train, y_test, y_mixed = load_data()
4 model = LabelPropagation(gamma=20,max_iter=1000)
5 model.fit(x_train, y_mixed)
6 y_pred = model.predict(x_train)
7 print(f"模型在训练集上的准确率为: {accuracy_score(y_pred, y_train)}")
8 y_pred = model.predict(x_test)
9 print(f"模型在测试集上的准确率为: {accuracy_score(y_pred, y_test)}")
10
11 if __name__ == '__main__':
12 test_label_propagation()在上述代码中,第1行是导入标签传播算法模块。第4行是实例化LabelPropagation模型,其中gamma便是式(13-1)中的$\sigma$,max_iter指的是模型(第13.3.3节中计算标签矩阵$Y$)的迭代次数。第5行是模型的拟合过程。第6~9行是分别在训练集和测试集上的预测结果。
上述代码运行结束后可以得到类似如下所示的输出结果:
1 模型在训练集上的准确率为: 0.9619
2 模型在测试集上的准确率为: 113.3.3 Label Propagation算法原理#
在介绍完标签传播算法的思想及使用示例后我们再来详细介绍其背后的数学原理。设 $(x_1,y_1),(x_2,y_2),...,(x_l,y_l)$ 为已知标签的数据样本,其中$Y_L=\{y_1,y_2,...,y_l\}$ 是样本点对应的标签;同时样本的类别数为$C$,并且假定所有的类别均出现在 $Y_L$ 中。继续,设$(x_{l+1},y_{l+1}),(x_{l+2},y_{l+2}),...,(x_{l+u},y_{l+u})$ 为不含标签的样本点,其中 $Y_U=\{y_{l+1},y_{l+2},...,y_{l+u}\}$ 未知,且通常情况下$l\ll u$,即未知标签的样本远多于已知标签的样本。此时有 $X=\{x_1,...,x_{l+u}\}$,且$x_i\in R^D$。
根据标签传播算的思想可知,首先需要构建一个有向完全图,并完成任意两个样本点之间的权重计算,计算公式如式(13-1)所示
$$ w_{ij}=\exp\left(-\frac{d^2_{ij}}{\sigma^2}\right)=\exp\left(-\frac{\sum_{d=1}^D(x^d_i-x^d_j)^2}{\sigma^2}\right)\tag{13-1} $$其中$\sigma$为控制权重的超参数,$w_{ij}$表示样本点$x_i$和$x_j$之间的距离权重。
通过式(13-1)计算任意两个样本点之间的距离权重后便可以得到一个结点与边之间的权重矩阵 $W$ ,并且还可以知道 $W$ 是一个对称矩阵,其形状为$(l+u,l+u)$。同时,值得一提的是这里还可以用其它距离来计算两个结点之间的距离权重。
进一步,定义形状为 $(l+u,l+u)$ 的概率迁移矩阵 $T$,且任意两个节点之间的转移概率计算公式为
$$ \begin{aligned} T_{ij}=P(j \to i)=\frac{w_{ij}}{\sum_{k=1}^{l+u}w_{kj}} \end{aligned}\tag{13-2} $$其中 $T_{ij}$ 表示结点 $j$ 转移到结点 $i$ 的概率,同时需要注意的是 $T$ 并不是一个对称矩阵。可以看出,此时是对矩阵 $w$ 在列上进行归一化,即每一列的和为1。
接着,再定义一个形状为 $(l+u,C)$ 的标签矩阵 $\overline{Y}$,其每一行用于表示每个样本属于各个类别的概率分布。初始化时的结果如图13-8中第2个矩阵所示。
最后,只需要迭代如下3个步骤便可以求解得到未知标签样本的预测结果:
第1步:计算更新后的 $Y$
$$ Y=T\overline{Y}\tag{13-3} $$第2步: 在行上对 $Y$ 进行标准化
$$ \overline{Y}_{ij}=\frac{Y_{ij}}{\sum_{c=1}^CY_{ic}}\tag{13-4} $$第3步:将 $\overline{Y}$ 中已知标签位置上的结果替换为原始的正确标签,然后重复前面两步直到收敛。
13.2.4 Label Propagation 计算示例#
在介绍完标签传播算法的基本原理之后,下面再通过一个实际的计算示例来展示其中的计算细节,同时也好再次从感官上来认识什么是标签传播算法。假设现在一共有a,b,c,d,e这5个样本点,类别标签分别为[0,1,1,-1,-1],其中-1表示无标签,如图13-5所示。
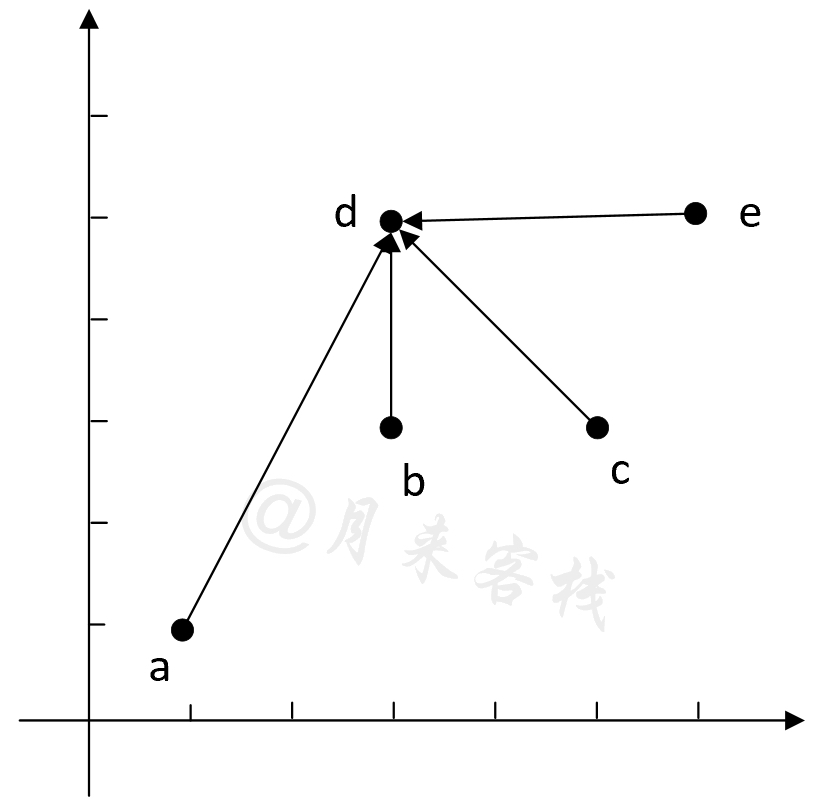
如图13-5所示,5个样本点分别为[[0.5, 0.5], [1.5, 1.5], [2.5, 1.5], [1.5, 2.5], [3.5, 2.5]]。此时,根据式(13-1)可以计算得到权重矩阵$W$,如图13-6所示。
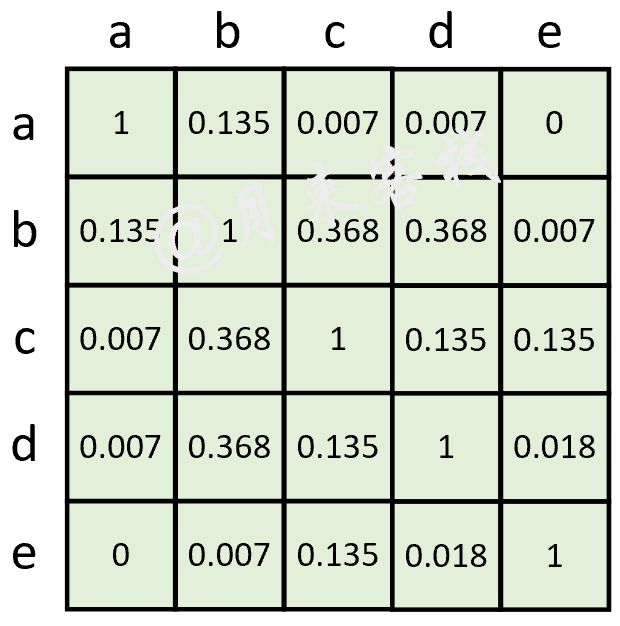
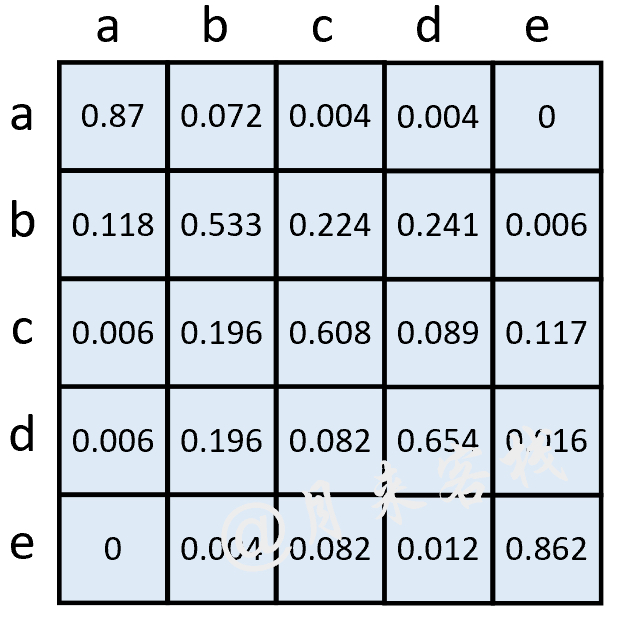
从图13-5中可以看出,样本b与样本d和样本c之间的距离最近,因此图13-6中对应的权重也是所有权重中最大的,为0.368。进一步,根据式(13-2)可以计算得到概率迁移矩阵如图13-7所示。
接着,初始化标签矩阵 $Y$ 并根据式(13-3)和式(13-4)可以计算得到更新后的标签矩阵,如图13-8所示。
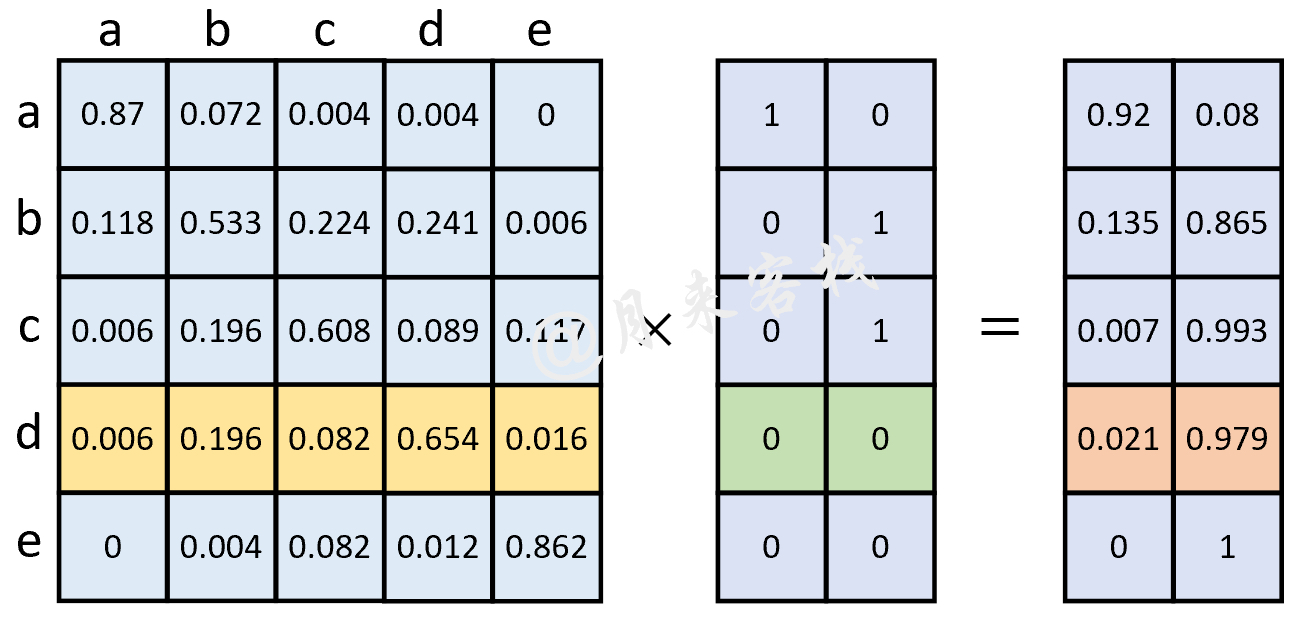
如图13-8所示便是标签矩阵的计算过程,其中最右边的矩阵便是更新后的标签矩阵(已归一化),不过这两个矩阵相乘的意义在哪里呢?
以样本点d为例,根据概率迁移矩阵可知,样本a转移到d的概率为0.006,其含义便是样本d的标签有0.6%的可能性和样本a的标签相同。同理,b转移到d的概率为0.196,c到d的概率为0.082,d到d的概率为0.654,e到d的概率为0.016。从图13-5也可以看出,b是所有样本点中距离d最近的样本点,因此样本d的标签最有可能和样本b的相同,计算过程如图13-9所示。
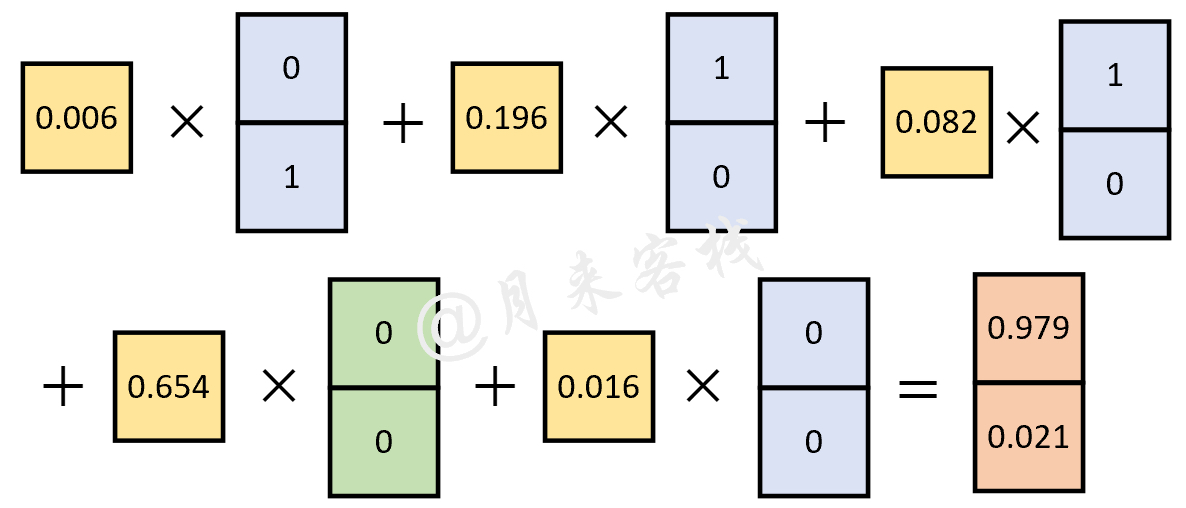
从图13-9可以看出,对于样本d来说,其最终的类别概率分布就等于每种情况下的转移概率乘以对应样本类别的概率分布并进行求和。所以,图13-8中的计算过程本质上就是将各个转移概率分配到每个样本标签上的过程,而这也类似于深度学习中的注意力机制,相关内容可以参见《跟我一起学深度学习》一书。
同时,这里值得一提的是由式(13-2)可知, $T$ 是 $w$ 在列上归一化后的结果,而式(13-3)中是 $T$ 的每一行作用于 $\overline{Y}$ ,并不是 $T$ 的每一列作用于 $\overline{Y}$ ,即 $T^T\overline{Y}$ ,因此在式(13-4)中对 $Y$ 在行上进行了归一化。因为从逻辑上来讲,每个样本点属于剩余所有样本点(包括自身)类别的概率和应该为1,所以作者在式(13-5)中换了一种表达形式。
13.2.5 Label Propagation 算法收敛性证明#
在13.2.3节内容中,我们直接给出了多次迭代后模型便会收敛的结论,下面就来介绍其中缘由并给出不通过迭代计算方式来获得标签矩阵的方法。
根据式(13-3)和式(13-4)可知,这两步本质上等价于
$$ Y=\overline{T}Y,\;\;\overline{T}_{ij}=\frac{T_{ij}}{\sum_{k=1}^{l+u}T_{ik}} \tag{13-5} $$即先对概率迁移矩阵在行上进行标准化,然后再乘以标签矩阵得到新的标签矩阵。
进一步,令
$$ Y=\begin{bmatrix} \;Y_{L} \\ \;Y_{U} \\ \end{bmatrix}\tag{13-6} $$其中$Y_L$表示已知标签部分,形状为$l\times C$;$Y_U$表示未知标签的部分,形状为$u\times C$。
同时,可以将$\overline{T}$拆解成4个子矩阵
$$ \overline{T}=\begin{bmatrix} \;\overline{T}_{ll} & \overline{T}_{lu} \\ \;\overline{T}_{ul} & \overline{T}_{uu} \\ \end{bmatrix}\tag{13-7} $$将式(13-6)和式(13-7)带入式(13-5)可得
$$ Y=\begin{bmatrix} \;\overline{T}_{ll} & \overline{T}_{lu} \\ \;\overline{T}_{ul} & \overline{T}_{uu} \\ \end{bmatrix}\times\begin{bmatrix} \;Y_{L} \\ \;Y_{U} \\ \end{bmatrix}=\begin{bmatrix} \;\overline{T}_{ll} Y_{L}+\overline{T}_{lu} Y_U \\ \;\overline{T}_{ul} Y_{L}+\overline{T}_{uu} Y_U\\ \end{bmatrix}\tag{13-8} $$由于 $Y_L$ 是已知的,因此在整个计算过程中 $Y_L$ 都会保持不变,故式(13-8)可以简写为(即只考虑更新后 $Y$ 中的 $Y_U$ 部分)
$$ Y_U=\;\overline{T}_{ul} Y_{L}+\overline{T}_{uu} Y_U \tag{13-9} $$根据式(13-9)可知,在迭代求解过程中有
$$ \begin{aligned} Y_U^1&=\overline{T}_{ul} Y_{L}+\overline{T}_{uu}Y_U^0\\[1ex] Y_U^2&=\overline{T}_{ul} Y_{L}+\overline{T}_{uu}Y_U^1\\[1ex] \vdots\\ Y_U^n&=\overline{T}_{ul} Y_{L}+\overline{T}_{uu}Y_U^{n-1} \end{aligned}\tag{13-10} $$其中 $Y^0_U$ 表示 $Y_U$ 的随机初始化结果,因为根据后面式(13-15)的证明过程可知 $Y^0_U$ 这一项不会对最后结果产生影响。同时,化简式(13-10)后有
$$ \begin{aligned} Y^n_U&=\overline{T}_{uu}^nY^0_U+\left(\overline{T}^0_{uu}\overline{T}_{ul}Y_L+\overline{T}^1_{uu}\overline{T}_{ul}Y_L+...,+\overline{T}^{n-1}_{uu}\overline{T}_{ul}Y_L\right)\\[2ex] &=\overline{T}_{uu}^nY^0_U+\overline{T}_{ul}Y_L\sum_{i=1}^n\overline{T}_{uu}^{(i-1)} \end{aligned}\tag{13-11} $$其中式(13-11)中, $Y_U^i$ 表示第 $i$ 次迭代后的结果,$\overline{T}_{uu}^k$ 表示取 $k$ 次幂。
进一步,当 $n$ 趋于无穷(迭代无限次)时有
$$ Y_U=\lim_{n \to \infty}\left[\overline{T}_{uu}^nY_U^0+\left(\sum_{i=1}^n\overline{T}_{uu}^{(i-1)}\right) \overline{T}_{ul} Y_{L}\right]\tag{13-12} $$最终,便可以得到如下计算公式
$$ Y_U=(I-\overline{T}_{uu})^{-1}\overline{T}_{ul}Y_L\tag{13-13} $$其中 $I$ 为单位矩阵。
根据式(13-13)便可以直接一步计算得到 $Y_U$,而不需要通过式(13-3)和式(13-4)多次迭代。对于式(13-13)的证明过程如下。
根据式(13-5)可知,由于$\overline{T}$是行标准化后的结果(即$\sum_j^{l+u}\overline{T}_{ij}=1$),所以有
$$ \exists\;\gamma < 1, \sum_{j=1}^u(\overline{T}_{uu})_{ij}\leq \gamma, \forall\;i=1,2,...,u\tag{13-14} $$即 $\exists\; \gamma < 1$ 使得 $\overline{T}_{uu}$ 中任意一行的和小于 $\gamma$ 。 显然这是成立的,因为 $\overline{T}$ 中的每一行和为1,而 $\overline{T}_{uu}$ 只是 $\overline{T}$ 的子矩阵。
进一步
$$ \begin{aligned} \sum_{j=1}^u(\overline{T}^n_{uu})_{ij}&=\sum_{j=1}^u\left[(\overline{T}^{n-1}_{uu})_{i1}\cdot (\overline{T}_{uu})_{1j} + (\overline{T}^{n-1}_{uu})_{i2}\cdot (\overline{T}_{uu})_{2j}+...+(\overline{T}^{n-1}_{uu})_{iu}\cdot (\overline{T}_{uu})_{uj}\right]\\[2ex] &=\sum_{j=1}^u\sum_{k=1}^u(\overline{T}^{n-1}_{uu})_{ik}(\overline{T}_{uu})_{kj}\\[2ex] &=\sum_{k=1}^u(\overline{T}^{n-1}_{uu})_{ik}\sum_{j=1}^u(\overline{T}_{uu})_{kj}\\[2ex] &\leq \sum_{k=1}^u(\overline{T}^{n-1}_{uu})_{ik}\cdot\gamma = \sum_{k=1}^u(\overline{T}^{n-2}_{uu})_{ik}\sum_{j=1}^u(\overline{T}_{uu})_{kj} \cdot \gamma\\[2ex] &\leq \gamma^n \end{aligned}\tag{13-15} $$所以当 $n$ 趋于无穷时有 $\sum_j(\overline{T}^n_{uu})_{ij}=0$ 。 又因为 $\overline{T}_{ij} >0$,这意味着当 $n$ 趋于无穷时 $(\overline{T}^n_{uu})_{ij}=0$ ,故式(13-12)中 $\overline{T}^n_{uu}Y^0_U=0$,此时有
$$ Y_U=\lim_{n \to \infty}\left(\sum_{i=1}^n\overline{T}_{uu}^{(i-1)}\right) \overline{T}_{ul} Y_{L}\tag{13-16} $$接下来,只需要证明式(13-16)中括号里的部分等于$(I-\overline{T}_{uu})^{-1}$即可。根据式(13-16)有
$$ \begin{aligned} \lim_{n \to \infty}\sum_{i=1}^{n}\overline{T}_{uu}^{i-1}&=\lim_{n \to \infty}\left(I+\overline{T}_{uu}+\overline{T}_{uu}^2+...+\overline{T}_{uu}^{n-1}\right)\\[2ex] &=\lim_{n \to \infty}\left[I+\left(I+\overline{T}_{uu}+\overline{T}_{uu}^2+...+\overline{T}_{uu}^{n-2}+\overline{T}_{uu}^{n-1}-\overline{T}_{uu}^{n-1}\right)\overline{T}_{uu}\right]\\[2ex] &=\lim_{n \to \infty}\left[I+\left(I+\overline{T}_{uu}+\overline{T}_{uu}^2+...+\overline{T}_{uu}^{n-1}\right)\overline{T}_{uu}-\overline{T}_{uu}^n\right]\\[2ex] \end{aligned}\tag{13-17} $$此时,令
$$ \lim_{n \to \infty}\sum_{i=1}^{n}\overline{T}_{uu}^{i-1}=A\tag{13-18} $$将式(13-18)带入式(13-17)可得
$$ \begin{aligned} A&=I+A\overline{T}_{uu}-0\\[1ex] A&=\left(I-\overline{T}_{uu}\right)^{-1} \end{aligned}\tag{13-19} $$因此,由式(13-16)~式(13-19)便可得到式(13-13)中的结果。同时,从上述整个证明过程可以得到两个结论:①当迭代次数足够大时,式(13-3)~式(13-4)一定会收敛;②除了以迭代的方式来求解得到未知标签 $Y_U$ 外,还可以根据式(13-13)来一次计算得到。
13.2.6 从零实现Label Propagation算法迭代法#
在清楚了标签传播算法的基本原理之后再来看看如何从零开始实现这一算法。之所以这里叫做迭代法实现,即迭代13.2.3节中求解标签矩阵的3个步骤,是因为标签传播算法的求解过程其实只需要一步就可以完成,这部分内容将在稍后进行介绍。下面,开始对迭代法的实现过程进行介绍。以下完整示例代码可参见 AllBooKCode/Chapter13/C04_label_propagation_imp.py 文件。
1. 核函数实现
首先,根据式(13-1)可知需要先定义一个函数来求解样本点之间的权重值,在sklearn实现中称之为核函数,示例代码如下:
1 from sklearn.metrics.pairwise import euclidean_distances
2 def kernel(X, y=None, gamma=None):
3 if gamma is None:
4 gamma = 1.0 / X.shape[1]
5 K = euclidean_distances(X, y, squared=True)
6 K *= -gamma
7 np.exp(K, K)
8 return K在上述代码中,第1行是导入euclidean_distances模块来快速实现样本点之间距离的计算。第3~4行判断gamma是否为空,如果为空则取特征维度数的倒数。第5~7行是根据式(13-1)来计算权重矩阵,其中np.exp(K, K)等价于 K = np.exp(K)。
例如对于图13-6中的结果,可以通过如下方式根据kernel进行计算,示例代码如下:
1 x = np.array([[0.5, 0.5], [1.5, 1.5], [2.5, 1.5], [1.5, 2.5], [3.5, 2.5]])
2 W = kernel(x, gamma=1.0)
3 print(W)
4
5 [[1. 0.135 0.007 0.007 0. ]
6 [0.135 1. 0.368 0.368 0.007]
7 [0.007 0.368 1. 0.135 0.135]
8 [0.007 0.368 0.135 1. 0.018]
9 [0. 0.007 0.135 0.018 1. ]]这里需要注意的是,对于euclidean_distances函数来说,如果y=None则它计算的便是X中两两样本点之间的距离,如果y!=None则它计算的是X中每个样本点与y中每个样本点之间的距离,即euclidean_distances(X,X)等价于euclidean_distances(X)。同时,在实现标签传播算法时,还可以使用其它的权重计算方法。
2. 概率迁移矩阵实现
在实现权重矩阵的计算之后便可以定义一个LabelPropagation类来构建完整的算法模型。首先需要实现概率迁移矩阵的计算过程,示例代码如下:
1 class LabelPropagation(object):
2 def __init__(self, gamma=20., max_iter=1000, tol=1e-3):
3 self.gamma = gamma
4 self.max_iter = max_iter
5 self.tol = tol
6
7 def _get_kernel(self, X, y=None):
8 return kernel(X, y, gamma=self.gamma)
9
10 def _build_graph(self):
11 affinity_matrix = self._get_kernel(self.X_)
12 normalizer = affinity_matrix.sum(axis=0, keepdims=True) # [1, n_samples]
13 affinity_matrix /= normalizer # [n_samples,n_samples] 归一化得到矩阵 T
14 return affinity_matrix在上述代码中,第2~5行是定义模型的3个基本参数,max_iter表示最大迭代次数,tol表示误差容忍度。第7~8行是返回构造完成的权重矩阵,需要注意的是这里的y不是指的训练标签而是另外一个矩阵,当y为None时(即模型训练时)计算的是训练样本X中各个样本点两两之间的权重距离,当y不为None时(即模型预测时)计算的是训练X中各个样本与测试样本y中各个样本之间的权重距离。第10~14行是根据返回的权重矩阵计算得到概率迁移矩阵,其中affinity_matrix的形状为[n_samples,n_samples]。
3. 模型拟合实现
在构建完成概率迁移矩阵后,便可以根据式(13-3)和式(13-4)来迭代完成标签矩阵的计算过程,示例代码如下:
1 def fit(self, X, y):
2 self.X_ = X
3 self.graph_matrix = self._build_graph() # 得到矩阵T,[n_samples,n_samples]
4 classes = np.unique(y) # 得到分类类别,例如三分类可能是 [-1,0,1,2],其中-1表示对应样本无标签
5 self.classes_ = (classes[classes != -1])
6 n_samples, n_classes = len(y), len(self.classes_) # 得到样本数和类别数
7 unlabeled = y == -1 # 得到没有标签的样本对应的索引
8 unlabeled = np.reshape(unlabeled, (-1, 1))
9 self.label_distributions_ = np.zeros((n_samples, n_classes))
10 for label in self.classes_: # 遍历每个类别
11 self.label_distributions_[y == label, self.classes_ == label] = 1
12 y_static = np.copy(self.label_distributions_)
13 l_previous = np.zeros((n_samples, n_classes))
14 for self.n_iter_ in range(self.max_iter):
15 if np.abs(self.label_distributions_ - l_previous).sum() < self.tol:
16 break
17 l_previous = self.label_distributions_
18 self.label_distributions_ = np.matmul(self.graph_matrix, self.label_distributions_)
19 normalizer = np.sum(self.label_distributions_, axis=1, keepdims=True)
20 self.label_distributions_ /= normalizer # 进行标准化
21 self.label_distributions_ = np.where(unlabeled, self.label_distributions_, y_static)
22 else:
23 logging.warning('max_iter=%d was reached without convergence.' % self.max_iter)
24 normalizer = np.sum(self.label_distributions_, axis=1, keepdims=True)
25 normalizer[normalizer == 0] = 1
26 self.label_distributions_ /= normalizer # 进行标准化
27 self.transduction_ = self.classes_[np.argmax(self.label_distributions_, axis=1)]
28 return self在上述代码中,第1行X表示训练样本形状为[n_samples,n_features],y表示训练标签形状为[n_samples,],同时未知标签样本的标签需要用-1进行标识。第2~3行是得到概率迁移矩阵,形状为[n_samples,n_samples]。第4行得到分类类别,例如三分类可能是 [-1,0,1,2],其中-1表示对应样本无标签。第5~6行用于得到标签类别的取值情况以及样本数。第7~8行是得到未知标签样本在训练集中的索引,其中True表示对应的样本没有标签。第9~11行是初始化标签矩阵用来记录训练集中每个样本的类别所属概率,然后再在已知的标签中把对应类别置为1,最后会得到类似下面这样一个矩阵:
1 [[0,0,1],
2 [0,0,0],
3 [1,0,0],
4 [0,0,0]] 其中全0表示该样本没有标签。
第14行开始进行迭代计算。第15~16行判断误差是否小于阈值,满足条件则退出迭代。第18~20行是根据公式$Y=TY$计算得到更新后标签矩阵,并进行了标准化。第21行是将self.label_distributions_中unlabel为False(即有标签)的位置用y_static中对应位置上的结果去替换,也就是保持训练集中有标签的样本对应的真实标签在迭代过程中不发生改变,其中np.where的用法如下:
1 label_distributions_ = np.array([1, 2, 3, 5, 6])
2 unlabeled = np.array([True, True, False, False, True])
3 y_static = np.array([1, 1, 99, 99, 1])
4 label_distributions_ = np.where(unlabeled, label_distributions_, y_static)
5 # label_distributions_= [ 1 2 99 99 6]第24~26行是对最后的标签矩阵进行标准化,其中第25行为平滑处理。第27行则是得到训练集中每个样本对应的标签。
4. 模型预测实现
在完成模型拟合的代码实现后,便可以根据式(13-3)中的公式来预测新样本的所属类别,示例代码如下:
1 def predict_proba(self, X):
2 weight_matrices = self._get_kernel(self.X_, X).T
3 probabilities = np.matmul(weight_matrices, self.label_distributions_)
4 normalizer = np.sum(probabilities, axis=1, keepdims=True)
5 normalizer[normalizer == 0] = 1 # 平滑处理
6 probabilities /= normalizer
7 return probabilities在上述代码中,第1行X是待预测的样本,形状为[n_samples, n_features]。第2行是计算训练样本self._X到预测样本X的权重距离,其形状为[X.shape[0],n_train_sample]。第3-6行则是计算测试数据中每个样本点所属类别的概率值,同时由于第2行中计算的训练样本点到测试样本点的单向权重距离,并不是所有样本点两两之间的权重距离,因此并不需要计算概率迁移矩阵。第7行是返回计算后的概率值。
这里值得一提的是,因为在训练过程中我们是通过训练集中的样本点来构建迁移矩阵的,因此在测试时对于新样本来说同样也需要有训练集构建的图结构。所以在上面第2行代码中我们是过self._get_kernel(self.X_,X)来建立各个样本点(已知标签和未知标签样本点)之间的权重距离。这也类似于前面12.2.6节内容中测试阶段构建核矩阵的过程。
最后,只需要再定义一个预测函数来取probabilities中最大值对应的标签即可,示例代码如下:
1 def predict(self, X):
2 probas = self.predict_proba(X)
3 return self.classes_[np.argmax(probas, axis=1)].ravel()在实现完整个模型之后,可以通过如下方式进行使用:
1 def test_label_propagation():
2 x_train, x_test, y_train, y_test, y_mixed = load_data()
3 model = LabelPropagation()
4 model.fit(x_train, y_mixed)
5
6 y_pred = model.predict(x_train)
7 logging.info(f"模型在训练集上的准确率为: {accuracy_score(y_pred, y_train)}")
8 y_pred = model.predict(x_test)
9 logging.info(f"模型在测试集上的准确率为: {accuracy_score(y_pred, y_test)}")
10
11 if __name__ == '__main__':
12 test_label_propagation()上述代码运行结束可以得到类似如下所示的结果:
1 模型在训练集上的准确率为: 0.9714
2 模型在测试集上的准确率为: 1.013.2.7 从零实现Label Propagation 算法非迭代法#
在第13.2.5节的收敛性证明中,我们已经知道了可以直接通过式(13-13)来直接求得$Y_U$对应的结果。经过分析可知,在基于第13.2.6节代码的基础之上,只需要修改fit()方法中的部分逻辑即可。以下完整示例代码可参见 AllBooKCode/Chapter13/C05_label_propagation_simple.py 文件。
根据式(13-13)可知,分别只需要得到矩阵$\overline{T}$和$Y$的一部分即可,因此在计算之前需要先将已知标签样本和未知标签样本进行分离,这部分实现过程示例代码如下:
1 def fit(self, X, y):
2 unlabeled = y == -1
3 X = np.vstack([X[~unlabeled], X[unlabeled]])
4 y = y.reshape(-1, 1)
5 y = np.vstack([y[~unlabeled], y[unlabeled]]).reshape(-1)
6 self.X_ = X
7 graph_matrix = self._build_graph() # 得到矩阵T,[n_samples,n_samples]
8 norm = np.sum(graph_matrix, axis=1, keepdims=True)
9 self.graph_matrix = graph_matrix / norm
10 classes = np.unique(y) # 得到分类类别,例如三分类可能是 [-1,0,1,2],其中-1表示对应样本无标签
11 classes = (classes[classes != -1])
12 self.classes_ = classes
13 n_samples, n_classes = len(y), len(classes) # 得到样本数和类别数
14 unlabeled = y == -1 # 得到没有标签的样本对应的索引
15 self.label_distributions_ = np.zeros((n_samples, n_classes))
16 for label in classes: # 遍历每个类别
17 self.label_distributions_[y == label, classes == label] = 1
18 num_unlabeled = np.sum(unlabeled) # 统计无标签样本个数
19 num_labeled = len(y) - num_unlabeled # 统计有标签样本个数
20 Tuu = self.graph_matrix[-num_unlabeled:, -num_unlabeled:] # [num_unlabeled,num_unlabeled]
21 Tul = self.graph_matrix[-num_unlabeled:, :num_labeled] # [num_unlabeled,num_labeled]
22 YL = self.label_distributions_[:num_labeled] # [num_labeled,classes]
23 inv = np.linalg.inv(np.eye(num_unlabeled) - Tuu) # [num_unlabeled,num_nulabeled]
24 YU = np.matmul(np.matmul(inv, Tul), YL) # [num_unlabeled,classes]
25 self.label_distributions_ = np.vstack([YL, YU])
26 return self在上述代码中,第2~5行代码则是分别将训练样本X和y中已知和未知标签的部分放到一起。第7~9行分别是计算得到矩阵$T$和归一化后的结果$\overline{T}$。第10行得到分类类别,例如三分类可能是 [-1,0,1,2],其中-1表示对应样本无标签。第18~22行是分别得到$\overline{T}_{uu},\overline{T}_{ul}$和$Y_L$,其中Tuu的形状为[num_unlabeled,num_unlabeled],Tul的形状为[num_unlabeled,num_labeled],YL的形状为[num_labeled,classes],inv的形状为[num_unlabeled,num_nulabeled],YU的形状为[num_unlabeled,classes]。 第23~24则是根据式(13-13)来直接计算$Y_U$的结果。
最后,可以通过以下方式来进行使用:
1 def test_label_propagation():
2 x_train, x_test, y_train, y_test, y_mixed = load_data()
3 model = LabelPropagation()
4 model.fit(x_train, y_mixed)
5
6 y_pred = model.predict(x_train)
7 logging.info(f"模型在训练集上的准确率为: {accuracy_score(y_pred, y_train)}")
8 y_pred = model.predict(x_test)
9 logging.info(f"模型在测试集上的准确率为: {accuracy_score(y_pred, y_test)}")
10
11 if __name__ == '__main__':
12 test_label_propagation()在上述代码运行结束后可以得到类似如下结果:
1 模型在训练集上的准确率为: 0.9619
2 模型在测试集上的准确率为: 1.013.2.8 小结#
在本节内容中,我们首先介绍了标签传播算法的基本思想和原理,并通过一个实际的计算示例来介绍了标签传播算法的迭代过程同时讲解了如何在sklearn中使用标签传播算法;然后我们进一步详细地介绍了如何从零开始实现标签传播算法;最后,详细介绍了标签算法的收敛性证明以及非迭代方式下的标签传播算法求解过程和实现原理。在下一节内容中,我们将介绍基于标签传播算法改进而来的另外一种半监督学习算法。
引用#
[1] Xiaojin Zhu and Zoubin Ghahramani. Learning from labeled and unlabeled data with label propagation. Technical Report CMU-CALD-02-107, Carnegie Mellon University, 2002
[2] https://en.wikipedia.org/wiki/Semi-supervised_learning
[3] https://scikit-learn.org/stable/modules/semi_supervised.html
[4] Olivier Chapelle, Bernhard Schölkopf, and Alexander Zien, Semi-Supervised Learning, MIT Press.