5.4 模型的迁移学习#
在前面几节内容中,我们详细介绍了PyTorch中模型的保存及载入推理和复用等过程。在有了前期这些基础知识后,接下来我们再来介绍关于模型迁移学习(Transfer Learning)部分的内容。
5.4.1 迁移学习#
在深度神经网络中由于模型通常都含有大量的可学习参数,所以在训练数据不充分的情况下模型极易出现过拟合或者泛化能力差的情况。而另一方面,数据样本的标注又是一项既耗费时间又耗费财力的工作[6],尤其是在一些需要业务专家介入的复杂任务标注中。因此,如何利用有限的数据来训练模型便成为了热门的研究方向。受到人类学习的启发——人类在学习并解决一个新问题的时候,总是可以依赖于先前所拥有的经验并迅速迁移到当前的场景中——研究人员开始提出一种两段式的学习框架,即先在一个通用的大规模数据集上训练得到一个预训练模型(Pre-trained Model),然后针对于特定的任务场景再根据少量的标注数据对整个模型进行微调(Fine-tuning),而这也被称为迁移学习。
在深度学习中迁移学习主要起源于图像处理领域,其背后的理念是如果一个模型是基于足够大且通用的数据集所训练得到,那么该模型将可以有效地充当视觉领域的通用模型,随后便可以直接将这些学习到的模型参数迁移到下游任务中而不必再从头开始训练整个模型[1]。
在图像处理领域中ImageNet是一个非常著名的大型通用数据集,它是由李飞飞团队于2007年所发起构建的一个项目,包含有超过1400万张手动标注的图片,旨在为世界各地的研究人员提供用于训练大规模物体识别模型的图像数据。[2]。自2010年以来,ImageNet项目每年都举办了一次大规模视觉识别挑战赛(ILSVRC),挑战赛使用了1000个类别的图片用于正确分类和检测目标及场景[3]。如图5-20所示便是ImageNet数据集中的部分图像。

根据「第4.2.3节 卷积计算过程:卷积核、多卷积、步长、可视野与特征提取原理」内容可知,越是靠近输出层特征越抽象,越是靠近输入层的特征越具体。因此假如现在有一个开源的图片分类模型A是基于ImageNet数据集训练而来,如果在某任务场景中需要训练另外一个10分类模型B用于汽车型号的分类,那么便可以直接取模型A中的前若干层(靠近输入层)网络作为特征提取器,然后在此基础上再加入一个新的全连接分类层来构造得到模型B完成整个10分类任务,此时称模型A为预训练(Pre-trained)模型。同时,通常来说还可以根据是否让预训练模型中的参数参与整个模型的训练这两种方式来完成模型的迁移学习任务[4]。
在接下来的内容中,我们将会通过一个实际的示例来对模型的迁移学习过程进行介绍。以下完整示例代码可参见Code/Chapter05/C05_ModelTrans/文件夹。
5.4.2 模型定义与比较#
在「第4.4节 LeNet5网络:经典卷积神经网络结构入门」内容中,我们详细介绍了LeNet5网络模型的原理及现实过程,并且同时根据「第5.3节 PyTorch模型保存与加载:模型复用与权重管理」的介绍我们也清楚了模型的保存与复用。现在假设有一个LeNet6网络模型,它是在LeNet5的基础上多增加了一个全连接层,此时便可以通过迁移学习将LeNet5模型中的部分参数用于LeNet6模型中。具体地,LeNet6模型结构的实现代码如下所示:
1 class LeNet6(nn.Module):
2 def __init__(self, ):
3 super(LeNet6, self).__init__()
4 self.conv = nn.Sequential(
5 nn.Conv2d(in_channels=1, out_channels=6,
6 kernel_size=5, padding=2),
7 nn.ReLU(), nn.MaxPool2d(2, 2), nn.Conv2d(6, 16, 5),
8 nn.ReLU(),nn.MaxPool2d(2, 2))
9 self.fc = nn.Sequential(
10 nn.Flatten(),nn.Linear(16 * 5 * 5, 120),
11 nn.ReLU(),nn.Linear(120, 84),nn.ReLU(),
12 nn.Linear(84, 64),nn.ReLU(),nn.Linear(64, 10))在上述代码中,第1~11行是LeNet5模型的前4层。第12行便是LeNet6模型中新加入的一个网络层。
在模型定义结束后,便可以输出模型中对应的参数信息。同时,为了完成后续模型的迁移过程这里也将LeNet5保存在本地权重参数载入输出以便两者进行对比,示例代码如下所示:
1 if __name__ == '__main__':
2 print("\n=====Model paras in LeNet6:")
3 model = LeNet6()
4 for (name, param) in model.state_dict().items():
5 print(name, param.size())
6
7 model_save_path = os.path.join('../C04_ModelSaving', 'lenet5.pt')
8 print("\n=====Model paras in LeNet5:")
9 loaded_paras = torch.load(model_save_path)
10 for (name, param) in loaded_paras.items():
11 print(name, param.size())在上述代码中,第2~5行是输出LeNet6模型中各个权重参数的名称和形状信息。第7~11行则是载入上一节中持久化保存到本地的LeNet5权重参数,并同时也输出每个参数的名称和形状。
在上述代码运行结束后便可以得到如下所示结果:
1 =====Model paras in LeNet6:
2 conv.0.weight torch.Size([6, 1, 5, 5])
3 conv.0.bias torch.Size([6])
4 conv.3.weight torch.Size([16, 6, 5, 5])
5 conv.3.bias torch.Size([16])
6 fc.1.weight torch.Size([120, 400])
7 fc.1.bias torch.Size([120])
8 fc.3.weight torch.Size([84, 120])
9 fc.3.bias torch.Size([84])
10 fc.5.weight torch.Size([64, 84])
11 fc.5.bias torch.Size([64])
12 fc.7.weight torch.Size([10, 64])
13 fc.7.bias torch.Size([10])
14 =====Model paras in LeNet5:
15 conv.0.weight torch.Size([6, 1, 5, 5])
16 conv.0.bias torch.Size([6])
17 conv.3.weight torch.Size([16, 6, 5, 5])
18 conv.3.bias torch.Size([16])
19 fc.1.weight torch.Size([120, 400])
20 fc.1.bias torch.Size([120])
21 fc.3.weight torch.Size([84, 120])
22 fc.3.bias torch.Size([84])
23 fc.5.weight torch.Size([10, 84])
24 fc.5.bias torch.Size([10])在上述结果中,第1~13行和第14~24行分别的两个模型的参数输出信息,其中第2~9行与第15~22行则是两这对应的相同部分(即可以复用),区别在于前者是随机初始化的权重参数而后者是训练得到的权重参数。第10~13行便是LeNet6模型中所改动的部分。
在理清楚了新旧模型的参数信息后,下面便可以将LeNet5模型中需要的参数取出来并迁移到LeNet6模型中。
5.4.3 参数微调#
在迁移学习中,最直观的一种方式就是让所有迁移过来的参数一同参与到整个模型的训练过程,即参数的微调(Fine Tuning),然后再将训练完成的整个参数保存到本地用于后续的推理过程。在进行模型参数微调前,首先需要在类LeNet6中实现一个方法来对LeNet5中的权重参数进行解析并将其用于LeNet6模型部分参数的初始化,实现代码如下所示:
1 @classmethod
2 def from_pretrained(cls, pretrained_model_dir=None):
3 model = cls()
4 pretrained_model_path = os.path.join(pretrained_model_dir, "lenet5.pt")
5 if not os.path.exists(pretrained_model_path):
6 raise ValueError(f"<路径:{pretrained_model_path} 中的模型不存在,请仔细检查!>")
7 loaded_paras = torch.load(pretrained_model_path)
8 state_dict = deepcopy(model.state_dict())
9 for key in state_dict:
10 if key in loaded_paras and
11 state_dict[key].size() == loaded_paras[key].size():
12 logging.info(f"成功初始化参数: {key}")
13 state_dict[key] = loaded_paras[key]
14 model.load_state_dict(state_dict)
15 return model在上述代码中,第2行pretrained_model_dir用来指定预训练模型所在的目录。第3行是实例化LeNet6这个模型。第4~6行是构造得到预训练模型的路径并判断是否存在。第7~8行是分别载入预训练模型和深度拷贝一份LeNet6模型中的参数,之所以深度拷贝是因为model.state_dict()返回的是一个引用,无法直接修改里面的权重参数。第9~13行是在LeNet6网络模型中遍历每个参数,并根据参数名和参数形状来判断LeNet5模型中是否有相同的参数,如有则对LeNet6网络模型中的参数进行替换。第14~15行则是对LeNet6中的部分权重参数进行重新初始化并返回。
这里值得一提的是,对于不同的迁移场景,第10~11行的判断条件并不一致,需要根据第5.4.2节中的介绍进行分析确定。
在完成上述代码之后,便可以通过如下方式进行载入,并输出部分结果进行对比,示例代码如下所示:
1 if __name__ == '__main__':
2 model_save_path = os.path.join('../C04_ModelSaving', 'lenet5.pt')
3 print("\n=====Model paras in LeNet5:")
4 loaded_paras = torch.load(model_save_path)
5 print(f"LeNet5模型中第一层权重参数(部分)为:
6 {loaded_paras['conv.0.weight'][0, 0]}")
7 print("\n=====Load model from pretrained ")
8 model = LeNet6.from_pretrained('../C04_ModelSaving')
9 print(f"LeNet6模型中第一层权重参数(部分)为:
10 {model.state_dict()['conv.0.weight'][0, 0]}")在上述代码中,第2~6用于载入本地的LeNet5模型对应的参数并输出第1个卷积层对应的部分参数。第7~10行则是根据上面所实现的from_pretrained方法来完成权重参数的迁移过程。
在上述代码运行结束后,便可以看到类似如下所示的验证结果:
1 LeNet5模型中第一层权重参数(部分)为:
2 tensor([[-0.0538, -0.4352, 0.2128, -0.0808, 0.0599],
3 [ 0.1359, -0.4566, 0.0987, 0.1395, -0.0719],
4 [-0.1107, -0.2895, 0.3242, 0.3209, 0.1349],
5 [ 0.2209, -0.2949, 0.2101, 0.0179, 0.0596],
6 [-0.0431, -0.2913, -0.0029, 0.1416, 0.0864]])
7 LeNet6模型中第一层权重参数(部分)为:
8 tensor([[-0.0538, -0.4352, 0.2128, -0.0808, 0.0599],
9 [ 0.1359, -0.4566, 0.0987, 0.1395, -0.0719],
10 [-0.1107, -0.2895, 0.3242, 0.3209, 0.1349],
11 [ 0.2209, -0.2949, 0.2101, 0.0179, 0.0596],
12 [-0.0431, -0.2913, -0.0029, 0.1416, 0.0864]])从上述输出结果可以看出,LeNet6模型中第1个卷积层的权重参数已经变成了LeNet5中对应部分的参数。
最后,在训练初始化 LeNet6模型时,只需要像上面一样用from_pretrained方法来完成参数的迁移即可,其它部分的代码并没有发生任何改变。
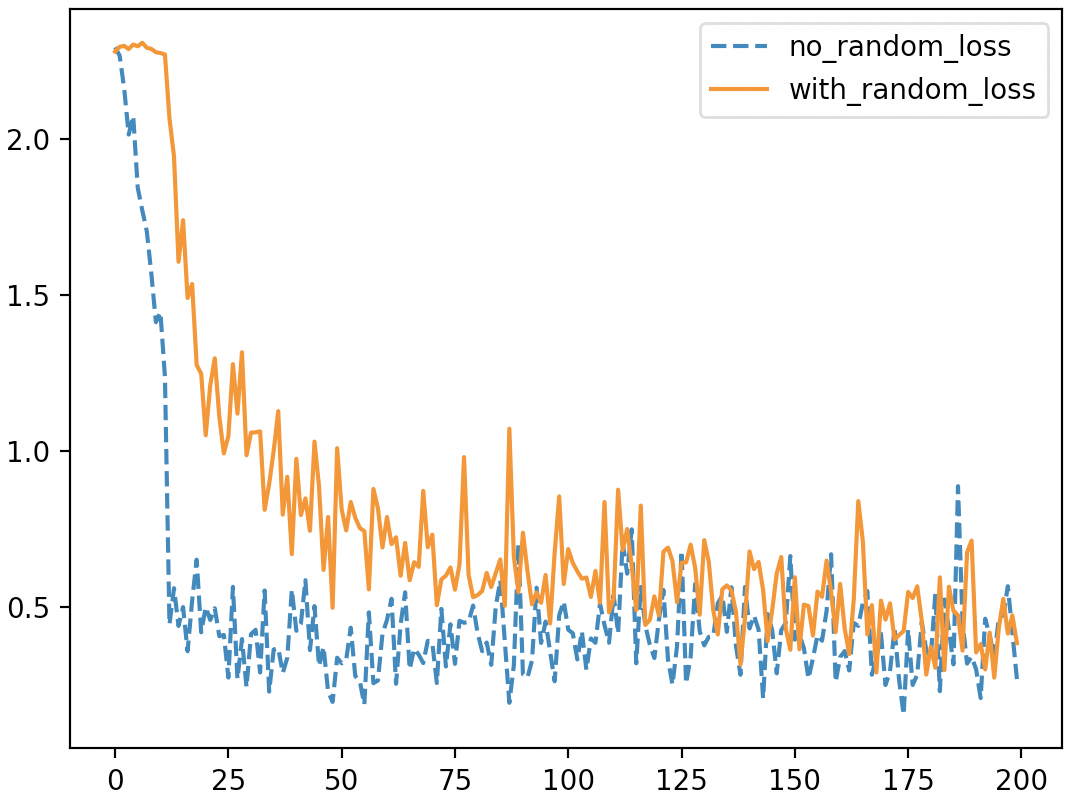
如图5-21所示,虚线和实线分别表示是否将LeNet5模型中的参数迁移到LeNet6中。从图中可以发现,在大约前50次小批量样本迭代过程中进行参数迁移的模型损失减小速度要明显快于没有进行迁移的模型,不过由于整个LeNet6模型也比较小,所以大约在100次迭代后两者的损失变换便趋同了。
5.4.4 参数冻结#
除了将其它模型迁移过来参数一同加入到新模型中进行训练微调之外,还有一种做法就是将迁移部分的参数进行冻结(固定不变),即不参与整个模型的训练过程,而仅仅只是将它作为一个固定的特征提取器。之所以选择这样做的一个主要原因是当被迁移过来的权重参数规模过大时,将会十分耗费整个模型的训练时间以及可能陷入过拟合的状态。
为了使得迁移过来的权重参数不参与整个模型的训练,只需要在重新初始化模型参数时将需要冻结参数的requires_grad属性设置为False,即在训练过程中不再更新梯度,具体新增部分代码如下所示:
1 @classmethod
2 def from_pretrained(cls, pretrained_model_dir=None, freeze=False):
3 model = cls()
4 frozen_list = []
5 # ... 载入本地参数等
6 for key in state_dict:
7 if key in loaded_paras and
8 state_dict[key].size() == loaded_paras[key].size():
9 logging.info(f"成功初始化参数: {key}")
10 state_dict[key] = loaded_paras[key]
11 if freeze:
12 frozen_list.append(key)
13 if len(frozen_list) > 0:
14 for (name, param) in model.named_parameters():
15 if name in frozen_list:
16 logging.info(f"冻结参数{name}")
17 param.requires_grad = False
18 model.load_state_dict(state_dict)
19 return model在上述代码中,第1~10行上面已经介绍过不再赘述。第11~12行用于判断是否需要将参数进行冻结,并将参数名进行保存。第13~17则是遍历模型中的每个参数,然后将需要冻结参数的requires_grad属性设置为False。最后,只需要在通过from_pretrained方法对模型进行初始化时再传入参数freeze=True即可不让迁移部分的参数参与训练。
同时,在模型的训练过程中还可以通过在每个小批量迭代过程中通过以下一行代码来验证参数是否发生改变:
1 print(f"第一层权重参数(部分)为:{model.state_dict()['conv.0.weight'][0, 0]}")当然在实际情况中也可以根据相应的判断条件来对需要的参数进行冻结。
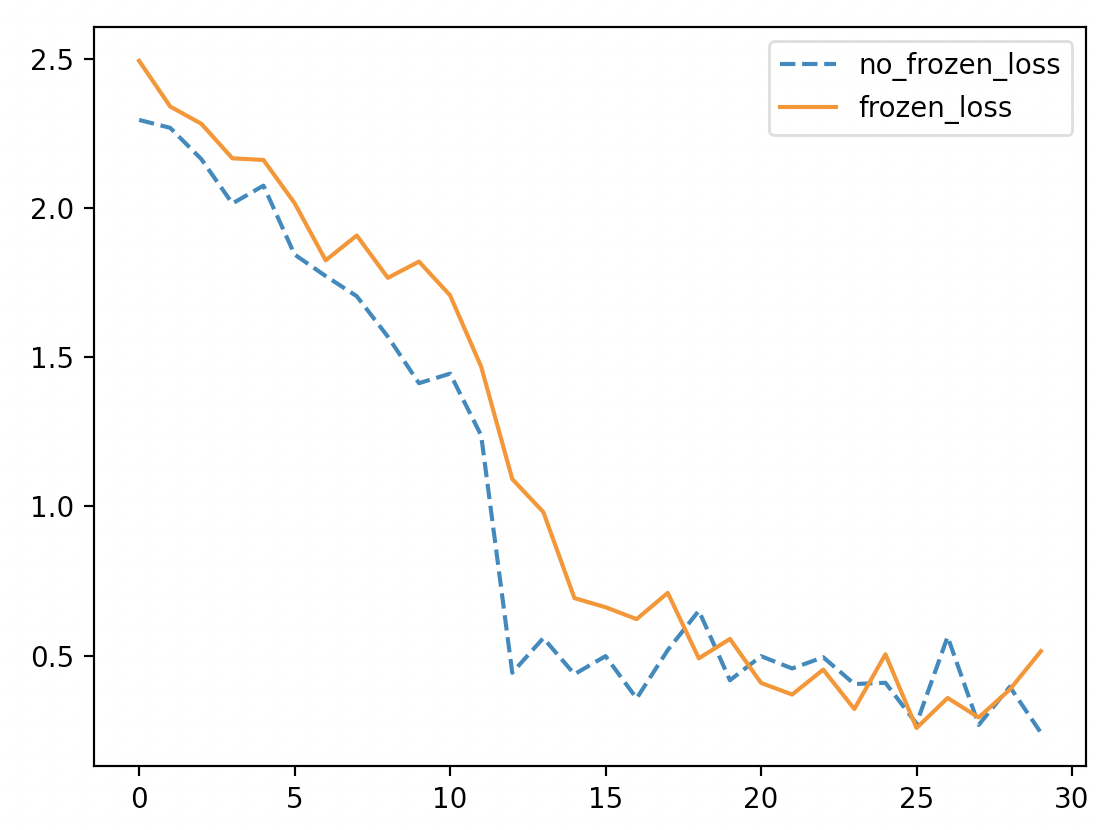
如图5-22所示实现和虚线分别表示是否将迁移参数进行冻结。从图5-22可以看出,在大约前15个小批量的迭代过程中,不进行参数冻结的模型在损失降低速度上会略快于进行参数冻结的模型,并且在大约20个小批量跌到后两则的变化速度趋同。当然,如果是迁移部分的权重规模较大,那么这两者将会有更加明显的区别。
总体来说,对于是否应该让迁移部分的模型参数参与到整个网络的训练过程大致可以分为如下4种情况[4]:
1. 当新场景中的数据集规模小于且类似于预训练模型中的数据集时不建议对迁移部分参数进行微调,因为此时新数据集规模较小微调整个模型会容易出现过拟合现象,所以更好的做法是将迁移部分的网络作为一个初步的特征抽取器,然后直接训练一个线性分类器来完成后续任务。
2. 当新场景中的数据集规模大于且类似于预训练模型中的数据集时可以对迁移部分参数进行微调,因为此时拥有更大规模的相似数据集可以用来调整模型参数,并且也不易出现过拟合的现象。
3. 当新场景中的数据集规模小于且不同于预训练模型中的数据集时不建议对迁移部分参数进行微调,因为新数据不同于源数据集可能包含有该数据特有的特征结构,所以更好的做法是将迁移部分的网络作为一个特征抽取器,然后再构建一个简单的网络来完成后续任务。
4. 当新场景中的数据集规模大于且不同于预训练模型中的数据集时可以对迁移部分参数进行微调,因为此时拥有更大规模的数据集支持微调整个模型,且通过迁移部分的参数来初始化新模型也有利于训练得到一个更好的模型参数。
5.4.5 小结#
在本节内容中,我们首先介绍了迁移学习的基本概念以及其背后的思想;然后介绍了如何通过对比来分析预训练模型中参数结构和新模型中参数结构的差异以此来实现参数的迁移过程;接着进一步介绍了两种常见的模型参数迁移方式,即迁移部分的参数是否参与整个模型的微调过程;最后详细介绍了如何通过代码实现模型的迁移过程,并总结了是否让迁移参数参与模型微调的4种情况。
引用#
[1] https://www.tensorflow.org/tutorials/images/transfer_learning
[2] https://www.image-net.org/index.php
[3] https://zh.wikipedia.org/wiki/ImageNet
[4] CS231n Convolutional Neural Networks for Visual Recognition. https://cs231n.github.io/transfer-learning/
[5] Saving And Loading Models https://pytorch.org/tutorials/beginner/saving_loading_models.html
[6] Han X, Zhang Z, Ding N, et al. Pre-trained models: Past, present and future[J]. AI Open, 2021, 2: 225-250.