10.3 Transformer结构#
在「第10.2节 Transformer原理:自注意力、多头注意力与位置编码」内容中我们详细介绍了自注意力机制的动机和原理,在介绍下来的这节内容中我们将继续介绍Transformer的整个网络结构,以及多头注意力机制的实现。
10.3.1 单层Transformer结构#
整体来看Tansformer模型同样是基于多层的编码器-解码器构造而来,而编码器和解码器又都是基于多头注意力机制构建而来,如图10-18所示便是Transformer网络结构的示意图。
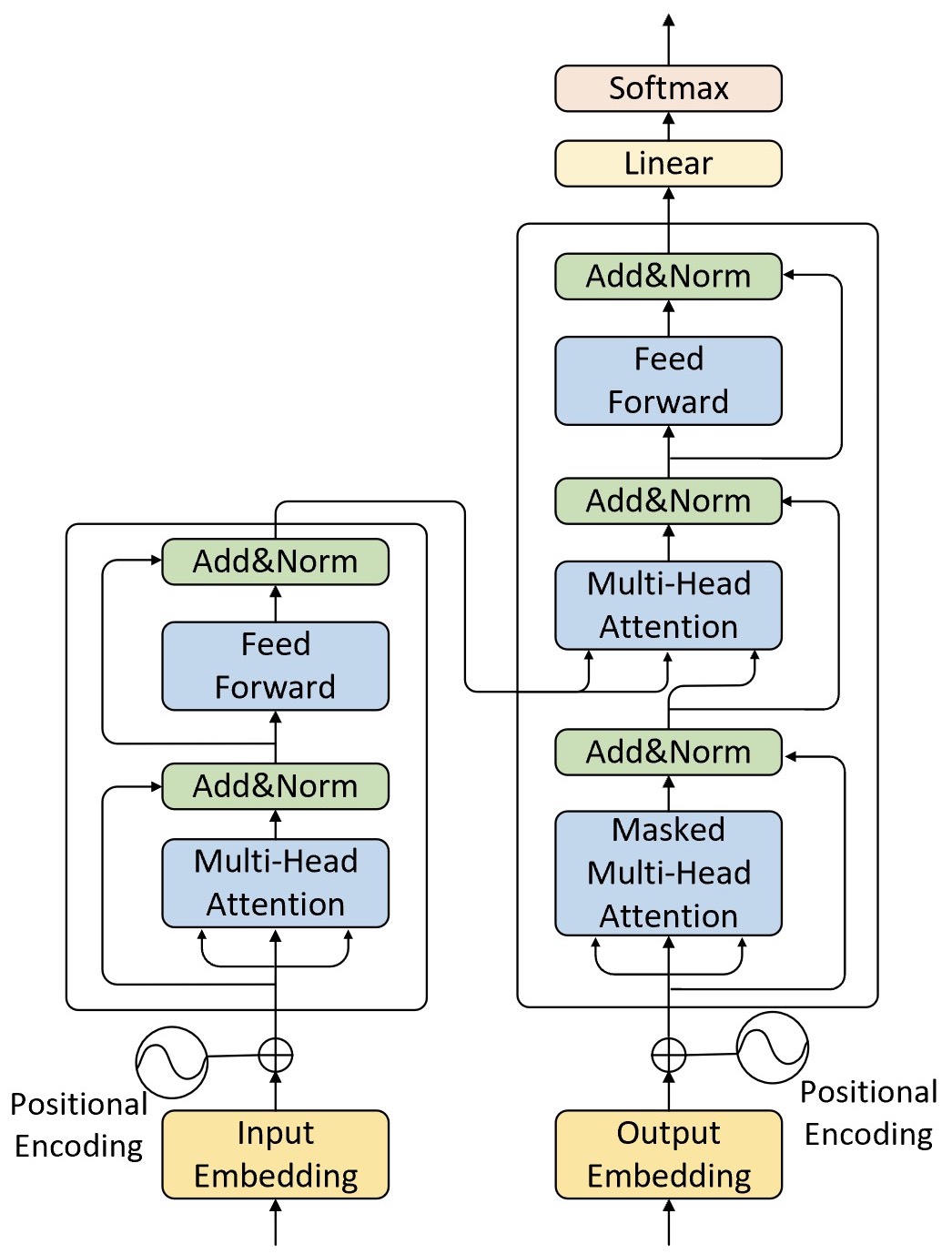
在图10-18中,左侧为编码器,右侧为解码器。下面,我们分别对其中的各个部分进行介绍。
1. 编码器
对于编码器来说其网络结构如图10-18(左)侧所示。尽管论文中的编码器是由6个相同的编码层结构堆叠而成,但这里我们还是先以堆叠一层时的情况来进行介绍。在每一个编码层中,其内部主要由两部分网络所构成:多头注意力机制和两层前馈神经网络。同时,对于这两部分网络来说都加入了残差连接,并且在残差连接后还进行了层归一化操作。这样,对于每个部分来说其输出均为$\text{LayerNorm}(x+\text{SubLayer}(x))$,并且在都加入了Dropout操作。
进一步,为了便于在这些地方使用残差连接,这两部分网络输出向量的维度均相同,默认为$d_{\text{model}}=512$,并且对于第2部分的两层全连接网络来说,其具体计算过程为
$$ \text{FFN}(x)=\text{ReLU}(xW_1+b_1)W_2+b_2\tag{10-10} $$其中输入$x$的维度为$d_{\text{model}}=512$,第1个全连接层的输出维度为$d_{ff}=2048$;第2个全连接层的输出为$d_{\text{model}}=512$。
2. 解码层
同编码器一样,解码器也采用了6个完全相同的网络层堆叠而成,不过这里我们依旧只是先看1层时的情况。对于解码器部分来说整体上与编码器类似,只是多了一个用于与编码器输出进行交互的多头注意力机制, 如图10-18(右)侧所示。
不同于编码器部分,在解码器中一共包含有3个部分的网络结构。最上面的前馈神经网络和最下面的掩码多头注意力机制(暂时忽略掩码)与 编码器相同,只是多了中间与编码器输出(Memory)进行交互的部分,称之为“Encoder-Decoder attention”。 对于这一多头注意力机制,Q来自于下方的掩码多头注意力机制的输出,而K和V均是编码器部分的输出经过线性变换后所得到。当然这样设计也是在模仿传统编码器-解码器网络模型的解码过程,即在对当前时刻的状态解码时需要同编码器中每个时刻的隐含状态计算得到对应的注意力权重完成注意力的分配过程,更多具体细节可以参见「第9.3节 Word2Vec训练与使用:CBOW、Skip-gram 与词向量应用」内容。
例如对于编码器输入为”我 是 谁“编码结束后,编码器-解码器交互注意力机制的整个过程便可以通过如图10-19和图10-20所示的过程来进行表示。
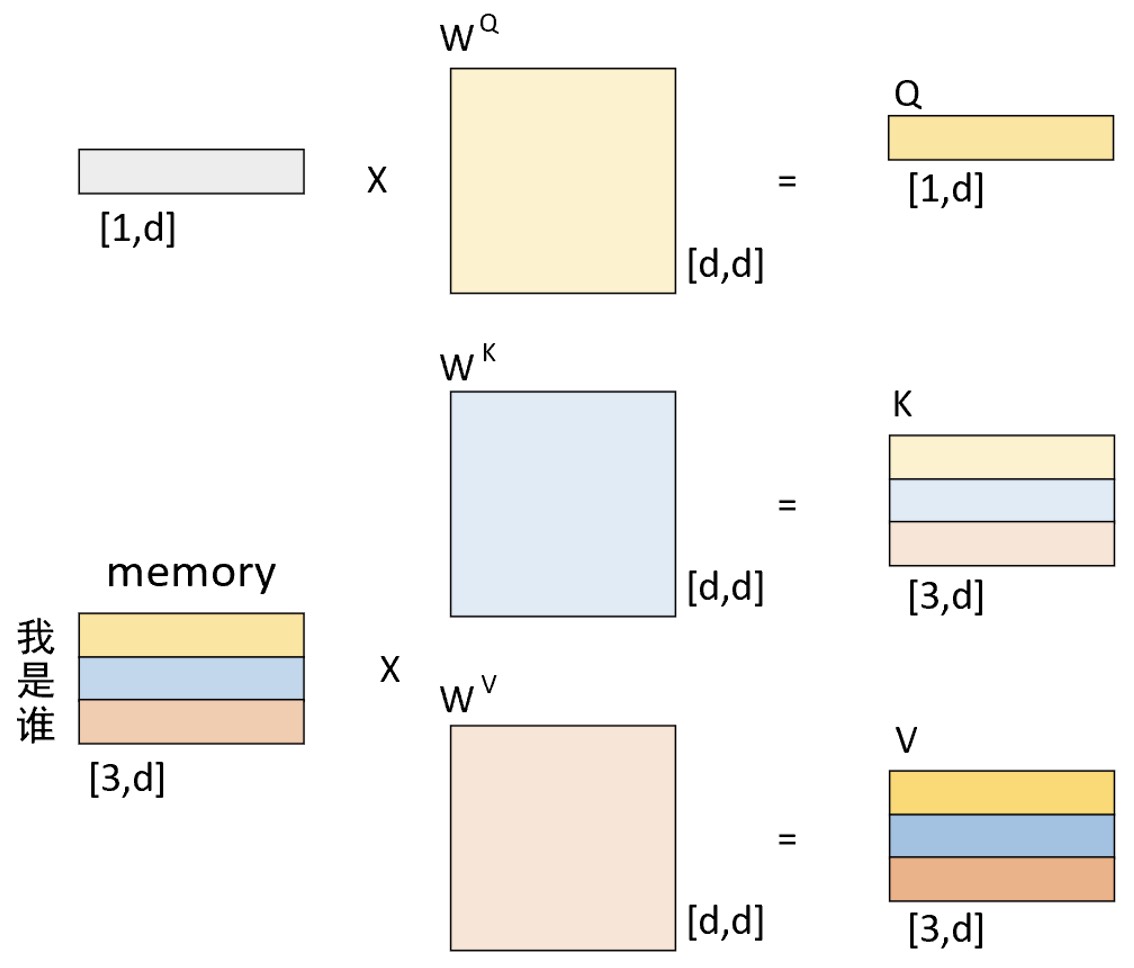
如图10-19所示,对于左上角待解码向量和编码器的输出结果来说,分别进行对应的线性变换得到$Q$、$K$和$V$。
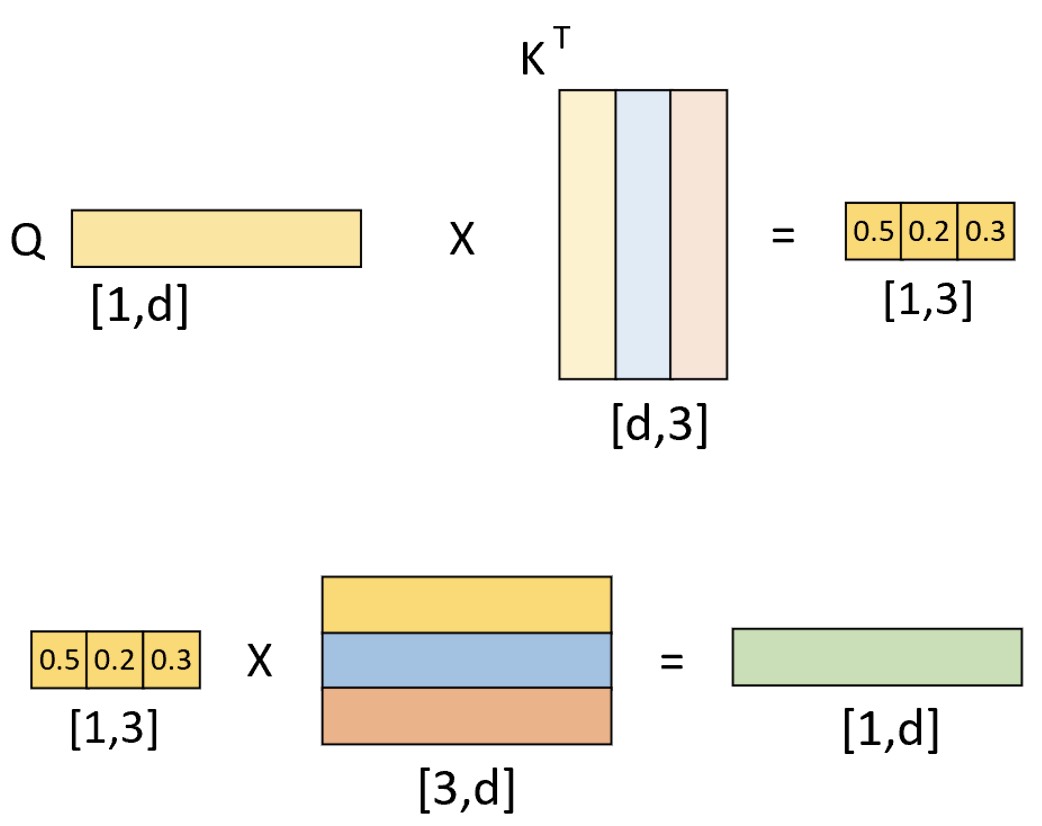
如图10-20所示,首先$Q$通过与$K$进行交互得到权重向量,此时可以看做是$Q$在 $K$中查询各个位置与$Q$有关的信息;然后将权重向量与$V$进行运算得到解码向量,此时这个解码向量便可以看作是考虑了memory中各个位置编码信息的输出结果。进一步,在得到这个解码向量并经过图10-18(右)中最上面的两层全连接层后,便将其输入到分类层中进行分类得到当前时刻的解码预测输出。
3. 推理解码过程
如同我们在「第9.7.2节 Seq2Seq教程:编码器解码器结构与序列生成」内容中介绍的编码器-解码器结构一样,在Transformer解码器的推理过程中,当第1个时刻的解码过程完成之后,解码器便会将解码器第1个时刻的输入,以及解码第1个时刻后的输出均作为解码器的输入来解码预测第2个时刻的输出,后续过程以此类推直到达到指定长度或某个时刻的预测输出为结束符时停止。
假设现在需要将" 我 是 谁"翻译成英语"who am i",且解码预测后前两个时刻的结果为"who am", 接下来需要对下一时刻的输出"i"进行预测,那么整个过程就可以通过图 10-21来进行表示。
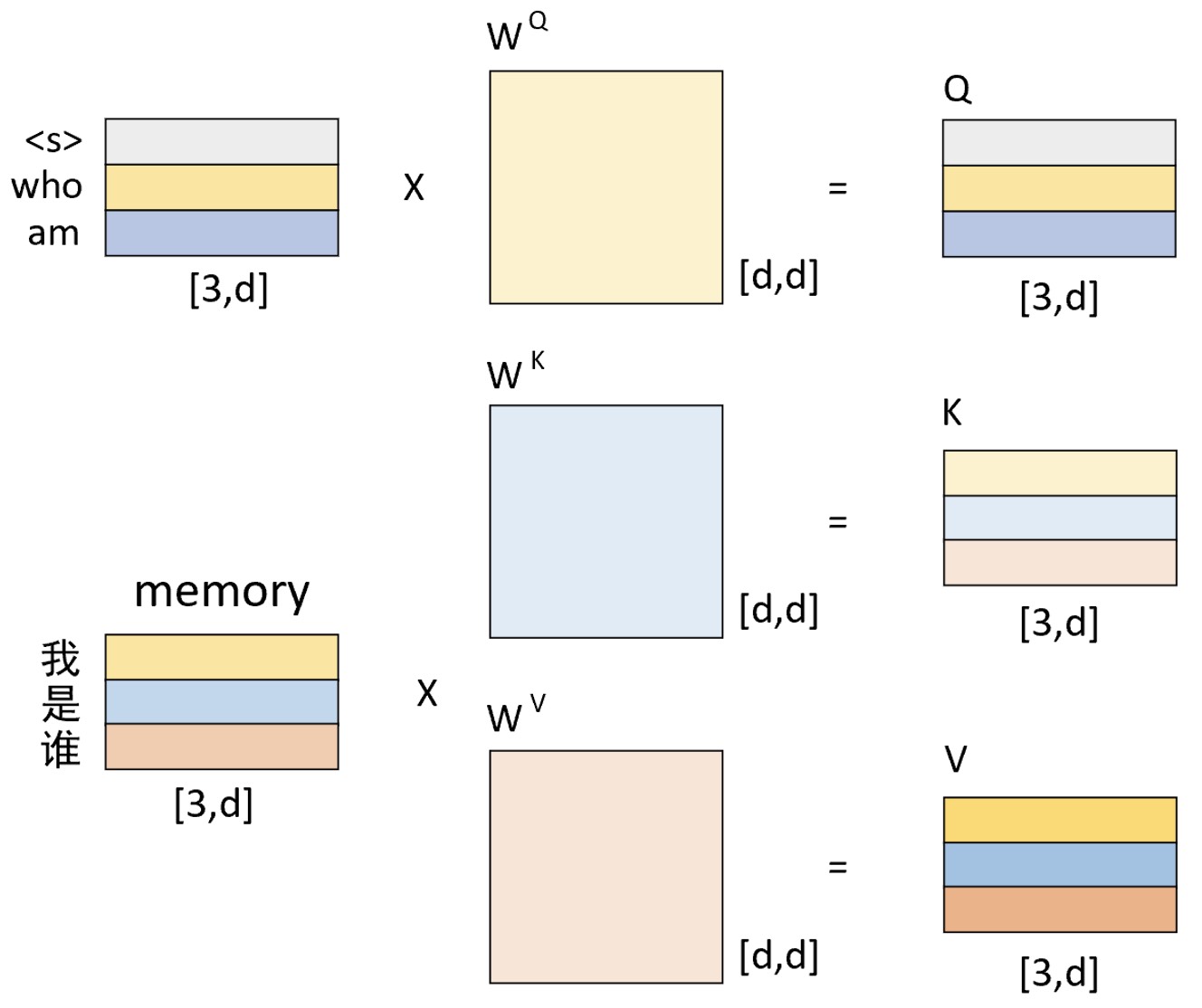
如图10-21 所示,左上角的矩阵是解码器对输入 "<s> who am"这 3 个字经过解码器中自注意力机制编码后的结果;左下角是编码器对输入"我 是 谁"这 3 个字编码后的结果;两者分别经过线性变换后便得到了$Q$、$K$和$V$这3个矩阵。此时值得注意的是,左上角矩阵中的每一个向量在经过自注意力机制编码后,每个向量同样也包含了其它位置上的编码信息。
进一步,$Q$与$K$作用后便得到了一个权重矩阵;再将其与$V$进行线性组合便得到了编码器-解码器多头注意力机制部分的输出。最后在经过解码器中的两个全连接层后,便得到了解码器最终的输出结果。同时,这里需要注意的是模型在进行实际的预测时,只会取解码器输出的其中一个向量进行分类,然后作为当前时刻的解码输出。例如上述示例中解码器最终会输出一个形状为[3,vocab_len]的矩阵,那么只用取其最后一行向量输入到分类器中进行分类得到当前时刻的解码输出,具体细节可见后续代码实现。
4. 训练解码过程
从上面介绍的内容可以看出,在推理过程中解码器需要将上一个时刻的输出作为下一个时刻解码的输入,然后逐时刻地进行解码操作。显然,训练时也采用同样的方法将十分耗时。因此,在训练过程中解码器也同编码器一样,一次接收解码时所有时刻的输入进行计算。 这样做的好处,一是通过多样本并行计算能够加快网络的训练速度;二是在训练过程中直接输入解码器正确的结果而不是上一时刻的预测值能够更好的训练网络,这一点我们在「第9.9.5节 神经机器翻译 NMT:Seq2Seq 在翻译任务中的应用」内容中也介绍过。
例如在用平行预料"我 是 谁"与"who am i"对网络进行训练时,编码器的输入便是"我 是 谁",而解码器的输入则是"<s> who am i",对应的正确标签则 是"who am i <e>"。假设现在解码器的输入"<s> who am i"分别进行线性变换后得到了$Q$、$K$和$V$,且$Q$与$K$作用后得到了注意力权重矩阵(此时还未进行$\text{softmax}$操作),如图10-22所示。
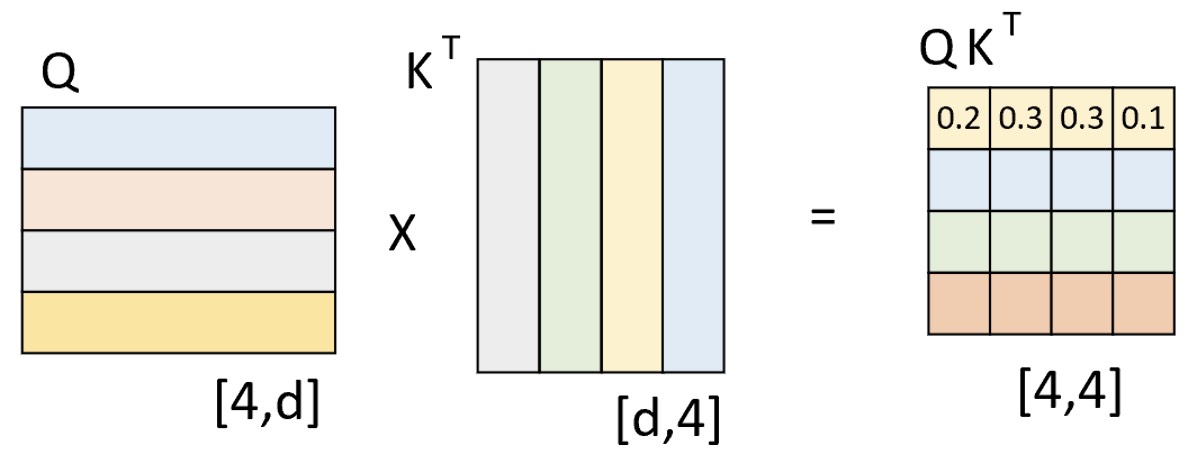
从图10-22可以看出,此时已经计算得到了注意力权重矩阵。不过现在有一个问题就是,模型在实际推理过程中只能看到(包括)当前时刻之前的信息来预测下一时刻,而图10-22所示的情况则是在对任意时刻进行解码时都能看到解码器输入所有时刻位置上的信息。因此,Transformer中的 解码器通过加入注意力掩码机制来解决了这一问题。
如图10-23所示,左侧是通过$Q$和$K$计算得到的注意力权重矩阵(此时还未进行$\text{Softmax}$操作),而中间便是所谓的注意力掩码(Attention Mask)矩阵。两者在相加并进行$\text{Softmax}$操作之后再乘上矩阵$V$便得到了整个自注意力机制的输出,这也就是图10-18中的掩码多头注意力(Masked Multi-Head Attention)。
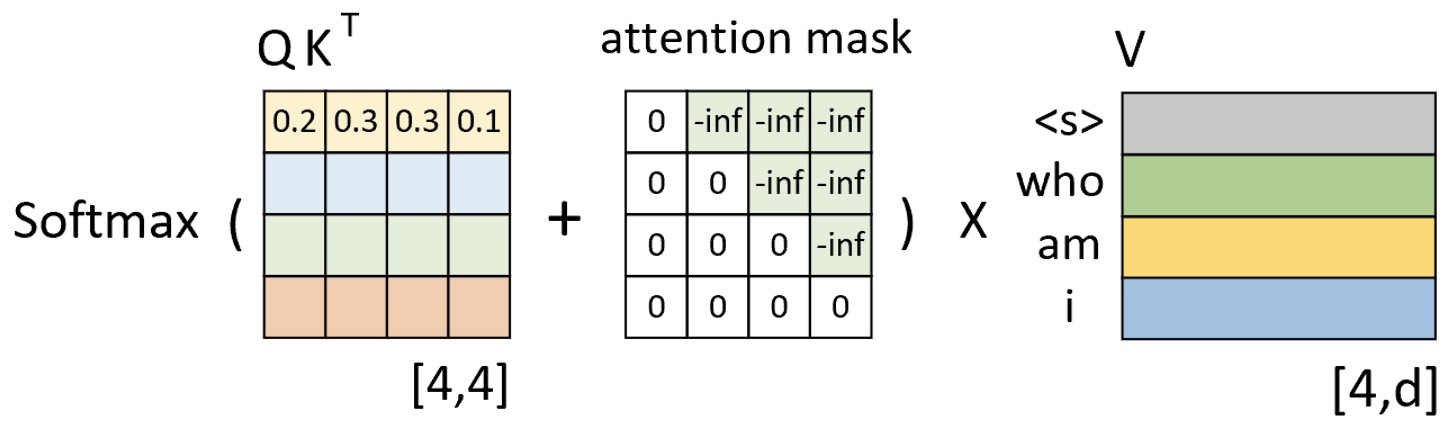
我们接着看注意力掩码矩阵是如何来解决这一问题的。以图10-23中第1行权重为例,当解码器对第1个时刻进行解码时其对应的真实输入应该只有"<s>",而这就意味着此时应该将所有的注意力放在第1个位置上(尽管在训练时解码器一次喂入了所有的输入)。换句话说也就是第1个位置上的权 重应该是 1,而其它位置则是 0。从图10-23中可以看出,第1行注意力向量在加上第1行注意力掩码,再经过$\text{Softmax}$操作后便得到了一个类似[1,0,0,0,0]的向量。 那么,通过这个向量就能够保证在解码第1个时刻时只能将注意力放在第1个位 置上的特性。同理,在解码后续的时刻也是类似的过程。
10.3.2 多层Transformer结构#
经过第10.3.1节内容的介绍我们已经清楚了单层Transformer网络结构的详细原理,并且尽管多层 Transformer就是在此基础上堆叠而来,但依旧有必要在这里稍微提及一下。
如图10-24所示便是一个多层Transformer网络结构图,左边是编码器右边是解码器,其中的Transformer EncoderLayer和Transformer DecoderLayer分别是指图10-18中的左右两个部分。在原论文中作者分别采用了6个编码器层和6个解码器层来构建整个Tranformer网络模型。同时,在后续代码实现过程中各个模块的命名也会延续图10-24中的名称,以便各位读者能够更好的理解。
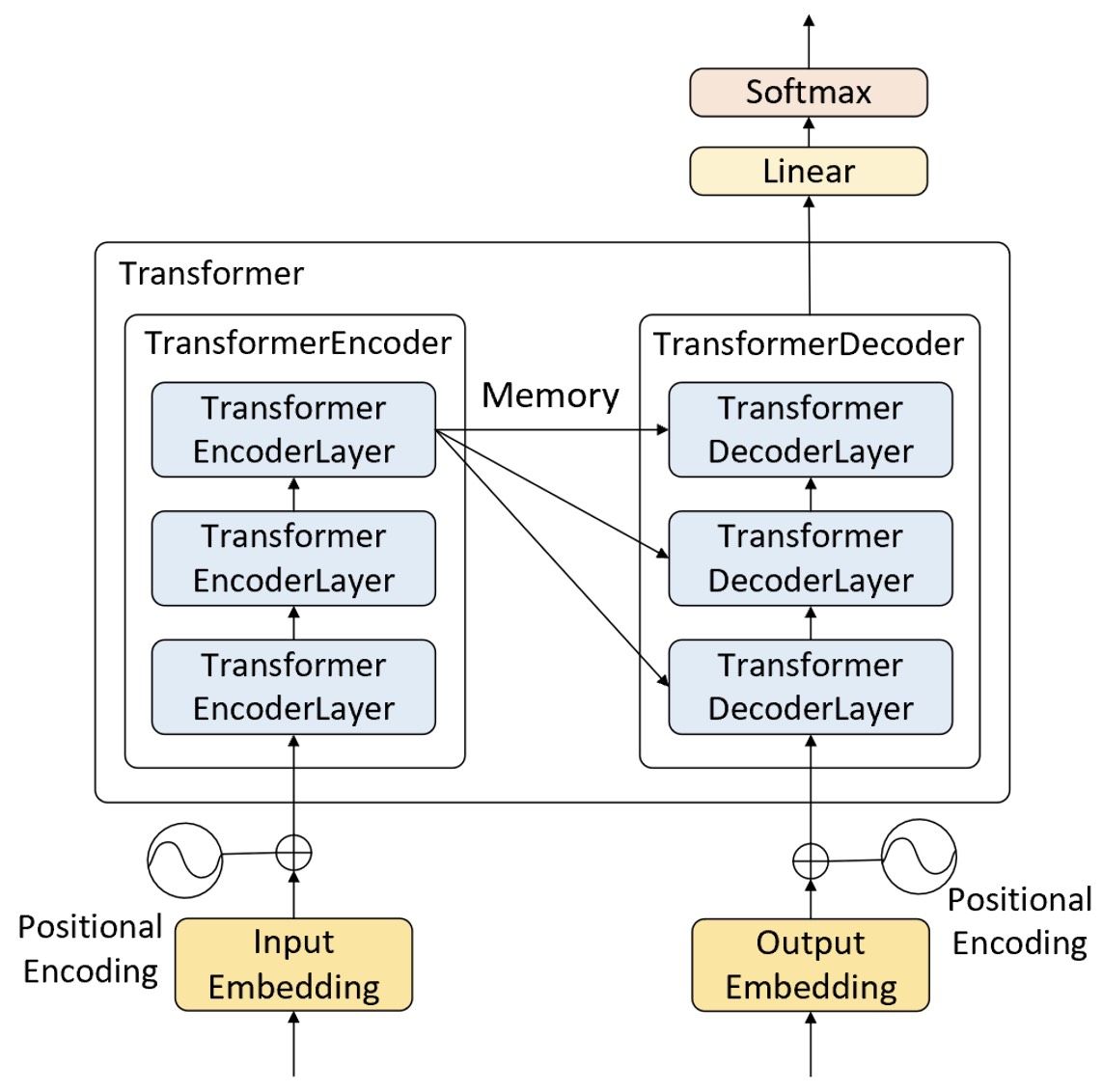
在多层 Transformer 中,多层编码器先对输入序列进行编码,然后得到最后一个编码层的输出。解码器先通过掩码注意力机制对解码器输入序列进行编码,然后将输出结果同编码器输出通过编码器-解码器注意力计算得到解码器第1层的输出结果;接着再将该结果继续输入到下一个解码层中进行编码,并将编码后的结果继续同编码器的输出通过编码器-解码器注意力计算后得到解码器的第2层输出结果。以此类推便得到了最后一个解码层的输出,然后再进行后续分类处理。
10.3.3 多头注意力实现#
根据前面的介绍可以知道,多头注意力机制中最为重要的就是自注意力机制,也就是需要前计算得到$Q$、$K$和$V$。同时,为了避免单个自注意力机制计算得到的注意力权重过度集中于当前编码位置自己所在的位置,所以作者采用了多头注意力机制来解决这一问题。下面我们开始介绍如何从零实现整个多头注意力机制。以下完整示例代码可参见Code/Chapter10/C03_Transformer文件。
1. 类MyMultiHeadAttentiond初始化方法
根据10.2.2节内容可知,我们可以给出类MyMultiHeadAttentiond的定义,示例代码如下所示:
1 class MyMultiheadAttention(nn.Module):
2 def __init__(self, embed_dim, num_heads, dropout=0., bias=True):
3 super(MyMultiheadAttention, self).__init__()
4 self.embed_dim = embed_dim
5 self.head_dim = embed_dim // num_heads
6 self.kdim = self.head_dim
7 self.vdim = self.head_dim
8 self.num_heads = num_heads
9 self.dropout = dropout
10 assert self.head_dim * num_heads == self.embed_dim, "embed_dim 除以 num_heads必须为整数"
11 self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
12 self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
13 self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
14 self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)在上述代码中,第1行embed_dim表示模型的维度,即前面各个图示中的d;num_heads表示多头的个数;bias表示是否在多头线性组合时使用偏置。第5行是计算得到每个头的维度head_dim。第10行是用于判断模型维度是否能够被多头个数整除,即论文中的限制条件$d_k=d_v=d/h$。第11~13行是为了使得实现代码更加高效,所以采取了将多个头注意力机制并行进行计算的方式,即图10-10所示的过程。当多头注意力机制计算完成后,将会得到一个形状为[seq_len,embed_dim]的矩阵,也就是图10-10中多个$z_i$水平堆叠后的结果。因此,第14行代码将会初始化一个线性层来对这一结果进行线性变换。
2. 前向传播过程
在定义完初始化函数后,便可以定义如下所示的多头注意力前向传播的过程,示例代码如下所示:
1 def forward(self, query, key, value, attn_mask=None, key_padding_mask=None):
2 return multi_head_attention_forward(query, key, value, self.num_heads,
3 self.dropout,out_proj=self.out_proj,training=self.training,
4 key_padding_mask=key_padding_mask,q_proj=self.q_proj,
5 k_proj=self.k_proj,v_proj=self.v_proj,attn_mask=attn_mask)由于在编码器和解码器的不同部分均会用到多头注意力机制,所以query、key和value均有不同的代指,相关变量在不同地方表示形状的指代也会不同,所以下面将以一种通用的形式来进行介绍。在上述代码中,第1行query、key和value指的并不是图10-6中的Q、K和V,而是指没有经过线性变换前的输入,此时三者的形状分别是[tgt_len, batch_size, embedd_dim]、[src_len, batch_size, embedd_dim]和[src_len, batch_size, embedd_dim]。atten_mask表示注意力掩码,形状为[tgt_len, src_len],但由于Transformer中只有图10-23中的情景会用到,所以此处上它的形状实际为[tgt_len, tgt_len]。key_padding_mask表示填充注意力掩码,相关介绍可参见9.10.4节内容,在编码器和解码器中对应的形状分别为[batch_size, src_len]和[batch_size, tgt_len]。
3. 多头注意力计算过程
在定义完类MyMultiHeadAttentiond后再来定义出多头注意力的实际计算过程。由于这部分代码较长所以下面分两部分进行介绍。
1 def multi_head_attention_forward(query, key, value, num_heads, dropout_p, out_proj,
2 training=True, key_padding_mask=None, q_proj=None, k_proj=None,v_proj=None,attn_mask=None):
3 q, k, v = q_proj(query), k_proj(key), v_proj(value)
4 tgt_len, bsz, embed_dim = query.size()
5 src_len, head_dim = key.size(0), embed_dim // num_heads
6 scaling, q = float(head_dim) ** -0.5, q * scaling
7 if attn_mask is not None:
8 if attn_mask.dim() == 2:
9 attn_mask = attn_mask.unsqueeze(0)
10 q = q.contiguous().view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
11 k = k.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
12 v = v.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
13 attn_output_weights = torch.bmm(q, k.transpose(1, 2))在上述代码中,第3行是分别对原始输入进行线性变换得到q、k和v,即式(10-7)中的$Q$、$K$和$V$,形状分别为[tgt_len, batch_size, kdim*num_heads]、[src_len, batch_size, kdim*num_heads]和[src_len, batch_size, kdim*num_heads]。第4~5行用于得到相关输入变量的信息。第6行是根据式(10-7)计算得到系数部分的结果。第7~9行是将atten_mask的形状从[tgt_len, tgt_len]扩维成[1, tgt_len, tgt_len]。第10~12行是分别将三者变形且同时交换了前面两个维度以便于后面计算,因为前面是num_heads个头一起参与线性变化。 第13行便是根据式(10-7)计算得到注意力权重矩阵,其中bmm的作用是用来计算 两个三维矩阵的乘法操作。
这里需要提醒的是,各位读者在阅读工程代码的时候建议仔细观察一下各个变量维度的变化过程,以便更好地理解整个计算过程。
进一步,多头注意力的输出结果过程实现为如下:
1 if attn_mask is not None:
2 attn_output_weights += attn_mask
3 if key_padding_mask is not None:
4 attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
5 attn_output_weights = attn_output_weights.masked_fill(
6 key_padding_mask.unsqueeze(1).unsqueeze(2),float('-inf'))
7 attn_output_weights = attn_output_weights.view(bsz * num_heads, tgt_len,src_len)
8 attn_output_weights = F.softmax(attn_output_weights, dim=-1)
9 attn_output_weights = F.dropout(attn_output_weights, p=dropout_p, training=training)
10 attn_output = torch.bmm(attn_output_weights, v)
11 attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
12 attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
13 Z = out_proj(attn_output)
14 return Z, attn_output_weights.sum(dim=1) / num_heads 在上述代码中,第1~2行是判断如果注意力矩阵不为空,则执行图10-23中的操作。第3~7行是用来对填充部分位置的注意力权重进行掩码处理,其中第6行当作用是将key_padding_mask从[batch_size,src_len]变成[batch_size,1,1,src_len]的形状。第8~10行便是用来对权重矩阵进行归一化操作,以及计算得到多头注意力机制的输出,此时attn_output的形状为[batch_size* num_heads, tgt_len, src_len]。第11行代码是将attn_output的形状先变成[tgt_len, batch_size* num_heads ,kdim],然变成[tgt_len,batch_size,num_heads * kdim]。第 13 行代码便是用来对多个头的注意力输出结果进行线性组合,输出形状为[tgt_len,batch_size,embed_dim]。第14行代码用来返回线性组合后的结果,以及多个注意力权重矩阵的平均值。
4. 使用示例
在完成上述实现过程之后,我们便可以通过如下方法来进行使用,示例代码如下所示:
1 if __name__ == '__main__':
2 src_len, batch_size = 5, 2
3 dmodel, tgt_len = 32, 6
4 src,num_head = torch.rand((src_len, batch_size, dmodel)),8
5 src_key_padding_mask = torch.tensor([[False, False, False, True, True],
6 [False, False, False, False, True]])
7 tgt = torch.rand((tgt_len, batch_size, dmodel))
8 tgt_key_padding_mask = torch.tensor([[False, False, False, True, True, True],
9 [False, False, False, False, True, True]])
10 my_mh = MyMultiheadAttention(embed_dim=dmodel, num_heads=num_head)
11 r = my_mh(src, src, src, key_padding_mask=src_key_padding_mask)
12 print(r[0].shape) # torch.Size([5, 2, 32])在上述代码中,第4行是随机初始化了一个嵌入结果。第5~6行是指定填充位置的掩码情况,其中True表示该位置为填充值。第10行是实例化一个多头注意力机制对象。第11是最后计算得到的结果。当然,我们也可以借助PyTorch中的torch.nn.MultiheadAttention模块来完成上述计算过程,其使用方法同本文实现的MyMultiheadAttention一致。
10.3.4 小结#
在本节内容中,我们首先分别从单层和多层的角度Transformer模型的整体网络结构,从整体上认识了Transformer的构成部分;然后详细介绍了Transformer中的编码层、解码层、推理解码过程和训练解码过程等细节内容;最后一步一步介绍了如何利用PyTorch框架来从零实现整个多头注意力机制的计算过程,并且对其使用方法进行了示例。