11.3 Kmeans算法求解#
到目前为止,相信各位读者已经对Kmeans聚类算法的过程有了一个清楚的了解,但是我们应该如何从数学的角度来对其进行描述呢?正如我们在介绍线性回归时所讲解的那样,对于聚类算法来讲我们同样应该找到一个目标函数来对聚类结果的好坏进行刻画。在前面我们介绍过,聚类的本质可被看成不同样本间相似度比较的过程,把相似度较高的样本点放到一个簇中,而把相似度较低的样本点放到不同的簇中。既然如此,应该怎么来衡量样本间的相似度呢?
一种最常见的做法当然是计算两个样本间的欧氏距离,即两个样本点离得越近就代表着两者间的相似度越高,并且这也是Kmeans聚类算法中的衡量标准。因此,根据这样的准则就可以将Kmeans聚类算法的目标函数定义为所有样本点到其对应簇中心距离的总和,以此来刻画聚类结果的好坏程度。
11.3.1 Kmeans算法目标函数#
如图11-5所示,图(a)和图(b)分别为同一数据集的两种不同聚类结果,其中同种颜色表示聚类后被划分到同一个簇中,黑色圆点为聚类后的簇中心。从可视化结果来看,图(a)中的聚类结果肯定好于图(b)中的聚类结果。也就是说,可以通过最小化目标函数$d=d_1+d_2,+\cdots,+d_{10}$来得到最优解。
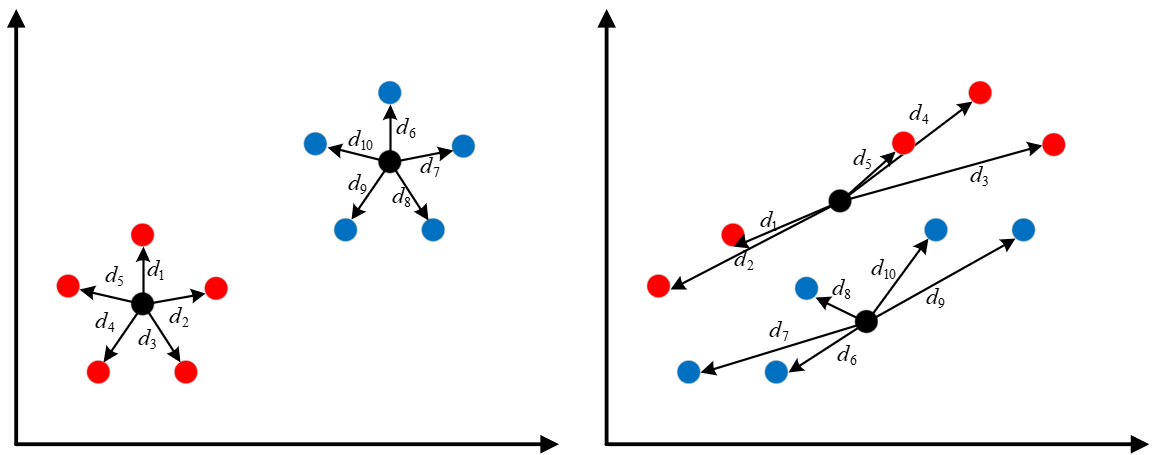
设$X=\{X_1,X_2,.\cdots,X_n\}$为一个含有$n$个样本的数据集,其中第$i$个样本表示为$X_i=\{x_{i1},x_{i2},\cdots,x_{im}\}$,$m$为样本特征的数量。样本分配矩阵$U$是一个$n\times k$的0-1矩阵(只含有0和1),$u_{ip}$表示第$i$个样本被分到第$p$个簇中。$Z=\{{{Z}_{1}},{{Z}_{2}},\cdots ,{{Z}_{k}}\}$为$k$个簇中心向量,其中$Z_p=\{z_{p1},z_{p2},\cdots,z_{pm}\}$为第$p$个簇中心,则Kmeans聚类算法的目标函数可以写为
$$ \begin{aligned} &P(U,Z)=\sum\limits_{p=1}^{k}{\sum\limits_{i=1}^{n}{{{u}_{ip}}}}\sum\limits_{j=1}^{m}{{{({{x}_{ij}}-{{z}_{pj}})}^{2}}}\\[1ex] &\text{s.t.} \;\sum\limits_{p=1}^{k}{{{u}_{ip}}}=1 \end{aligned} \tag{11-1} $$虽然式(11-1)看起来稍微有点复杂,但是其表示的含义就是求各个样本点到其对应簇中心的距离和。由于一个数据集有多个簇,每个簇中有多个样本,每个样本又有多个维度,因此式(11-1)中就出现了3个求和符号。其次,我们再以图11-5为例来简单介绍一下分配矩阵$U$。由图11-5(a)可知,数据集中一共有两个簇,并且假设前5个样本为一个簇,后5个样本为一个簇,则其对应的分配矩阵为
$$ {{U}_{[10\times 2]}}={{\left[ \begin{matrix} 1 & 1 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 & 1 \\ \end{matrix} \right]}^{T}}\tag{11-2} $$11.3.2 求解簇中心矩阵$Z$#
同SVM求解过程一样,对于目标函数式(11-1)的求解依旧需要借助于拉格朗日乘数法。由目标函数式(11-1)可知,这里一共需要求解的未知参数包括两个,簇中心矩阵$Z$和簇分配矩阵$U$。
针对目标函数式(11-1),关于变量$z_{pj}$求导可得
$$ \frac{\partial P(U,Z)}{\partial {{z}_{pj}}}=-2\sum\limits_{i=1}^{n}{{{u}_{ip}}}({{x}_{ij}}-{{z}_{pj}})\tag{11-3} $$进一步,令式(11-3)为0,有
$$ \begin{aligned} & \sum\limits_{i=1}^{n}{{{u}_{ip}}}({{x}_{ij}}-{{z}_{pj}})=0 \\ & \Rightarrow \sum\limits_{i=1}^{n}{{{u}_{ip}}}{{x}_{ij}}=\sum\limits_{i=1}^{n}{{{u}_{ip}}}{{z}_{pj}} \\ & \Rightarrow {{z}_{pj}}=\frac{\sum\limits_{i=1}^{n}{{{u}_{ip}}}{{x}_{ij}}}{\sum\limits_{i=1}^{n}{{{u}_{ip}}}} \\ \end{aligned}\tag{11-4} $$由此便得到了簇中心的计算公式(11-4)。这个公式有什么含义呢?其实就是求每个簇中样本点对应维度的平均值。例如某个簇中有3个样本点[1,2]、[2,3]、[4,6],则其簇中心为$\frac{1}{3}[1+2+4,2+3+6]$。
11.3.3 求解簇分配矩阵$U$#
在求解得到簇中心矩阵Z后,该怎样求解分配矩阵呢?11.2节我们在介绍Kmeans聚类的思想时说过,聚类的本质可被看成不同样本间相似度比较的一个过程,把相似度较高的样本点放到一个簇,而把相似度较低的样本点放到不同的簇中,因此,对于每个样本点来讲,只需分别计算其与K个簇中心的距离(相似度),然后将其划分到与之相似度最高(距离最近)的簇中即可。也就是说,求解分配矩阵其实就是一个比较的过程,通过式(11-5)即可完成。
$$ {{u}_{ip}}=\begin{cases} 1, & \sum\limits_{j=1}^{m}{{{({{x}_{ij}}-{{z}_{pj}})}^{2}}}\le \sum\limits_{j=1}^{m}{{{({{x}_{ij}}-{{z}_{tj}})}^{2}}},\text{for }1\le t\le k \\[4ex] 0, & \text{其它} \\ \end{cases} \tag{11-5} $$式(11-5)的含义是,计算每个样本点到所有簇中心的距离,然后将其划分到离它最近的簇中。例如,若某个样本点到3个簇中心的距离分别是5、2、8,则簇分配矩阵对应行为[0,1,0]。
11.3.4 小结#
在本节中,我们首先介绍了Kmeans聚类算法中目标函数的由来,并且以图示的形式解释了该目标函数背后的含义,最后介绍了如何通过拉格朗日乘数法来求解Kmeans聚类算法中的未知参数$Z$和$U$。