6.6 动量法#
在「第3.3节 反向传播原理:梯度下降与神经网络参数更新」内容中,我们详细介绍了如何通过梯度下降算法来最小化目标函数并以此求解得到模型对应的权重参数。进一步,我们在「第3.6节 Softmax回归简洁实现:PyTorch 多分类建模示例」内容中还介绍了什么是随机梯度下降算法和小批量梯度下降算法。在本节内容中我们将会介绍另外一种基于梯度下降改进的动量法(Momentum )[1]。
6.6.1 动量法动机#
在使用基于小批量样本的梯度下降算法最小化模型的过程中,我们可以通过调整学习率的大小来加快模型的收敛速速,但是通常情况下我们很难找到一个合适的学习率。过小会使得模型收敛速度慢,而过大则会可能使得目标函数发散,如图6-21所示。
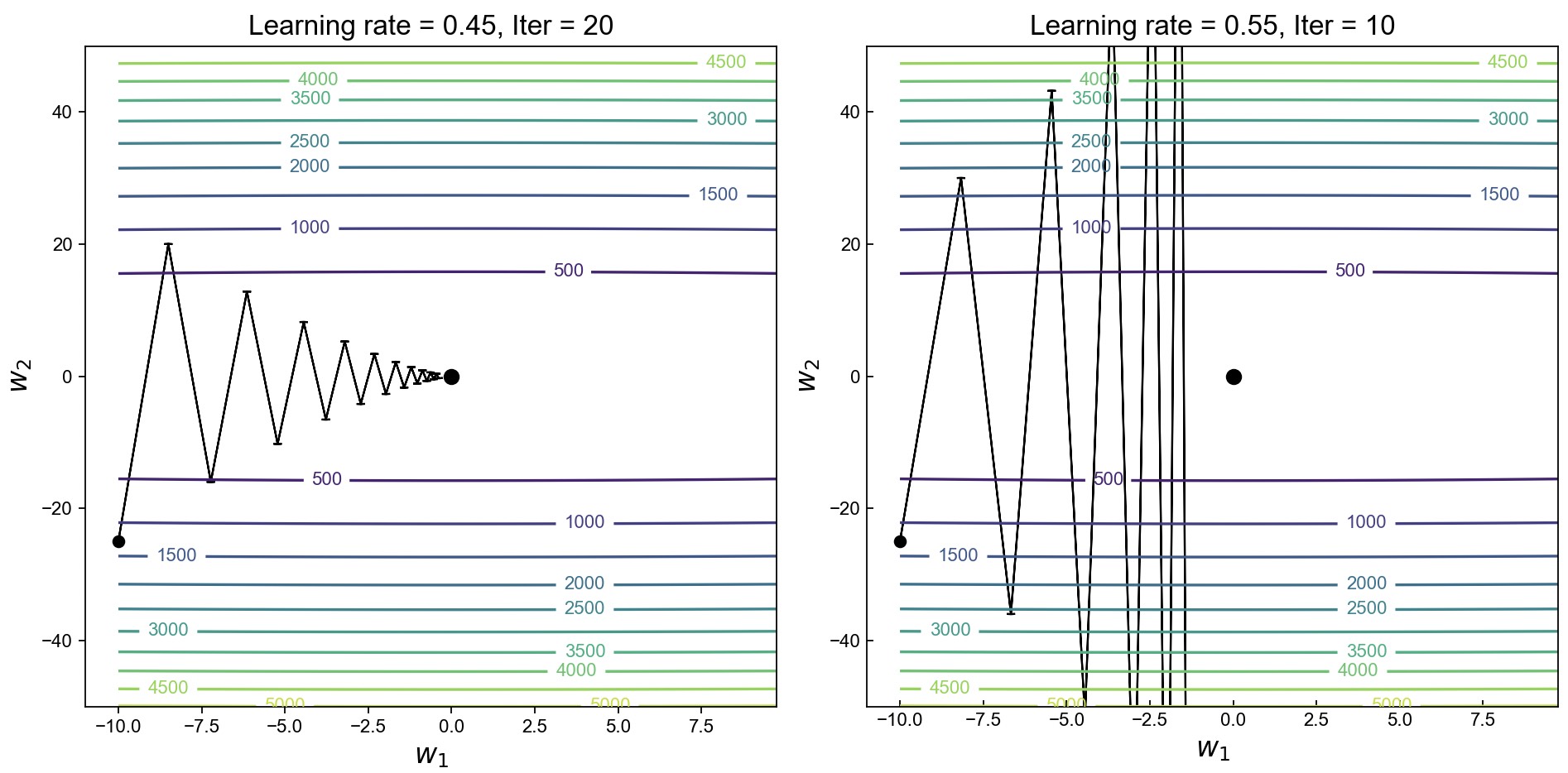
在图6-21中对于该目标函数来说,当学习率设置为0.45时(左)目标函数大约在20次迭代后收敛;当学习率增大至0.55时(右)目标函数则在大约10次迭代便进入了发散状态。同时可以看出,在这两种情况下目标函数在$w_2$上的偏移量都要远大于在$w_1$上的偏移量,这是因为该目标函数在竖直方向上的斜率要远大于水平方向上的斜率。正是因为这些原因使得目标函数在优化过程中梯度来回震荡,导致模型难以收敛或发散。一种有效的做法便是权重参数在当前位置计算梯度时,同时也考虑到在上一次位置时的梯度,而这也被称之为动量法。
6.6.2 动量法原理#
动量法是梯度下降算法的一种改进,它引入了动量的概念以加速目标函数收敛过程并减小震荡。动量法的基本思想是在更新参数的过程中,不仅考虑当前的梯度方向,同时也考虑历史累积的梯度信息。具体地,设目标函数在第$t$时刻关于所有权重参数的梯度为$g_t$,速度变量为$v_t$且$v_0=0$,权重参数为$\theta_t$,则第$t+1$时刻结果过$\theta_{t+1}$可通过如下过程计算
$$ \begin{aligned} v_{t+1} & = \mu * v_{t} + g_{t+1}, \\[1ex] \theta_{t+1} & = \theta_{t} - \gamma * v_{t+1}, \end{aligned}\tag{6-29} $$其中$\mu$表示动量系数,$\gamma$表示学习率。为了方便各位读者阅读内容时能够同实践相结合,因此本节及后续几节内容中相关计算公式的符号标记均遵循了PyTorch框架中相应接口描述文档中类似的标记方式。
从式(6-29)可以看出,在通过梯度下降算法计算第$t+1$时刻的结果时所依赖的速度$v_{t+1}$便同时考虑了第$t$时刻的速度$v_t$,并通过超参数$\mu$来控制依赖程度,这与「第6.3节 BatchNorm原理:批归一化为什么能加速训练」内容中式(6-19)通过移动平均来计算均值和方差类似。此时可以看出,当$\mu=0$时式(6-29)便等价于原始的梯度下降算法。
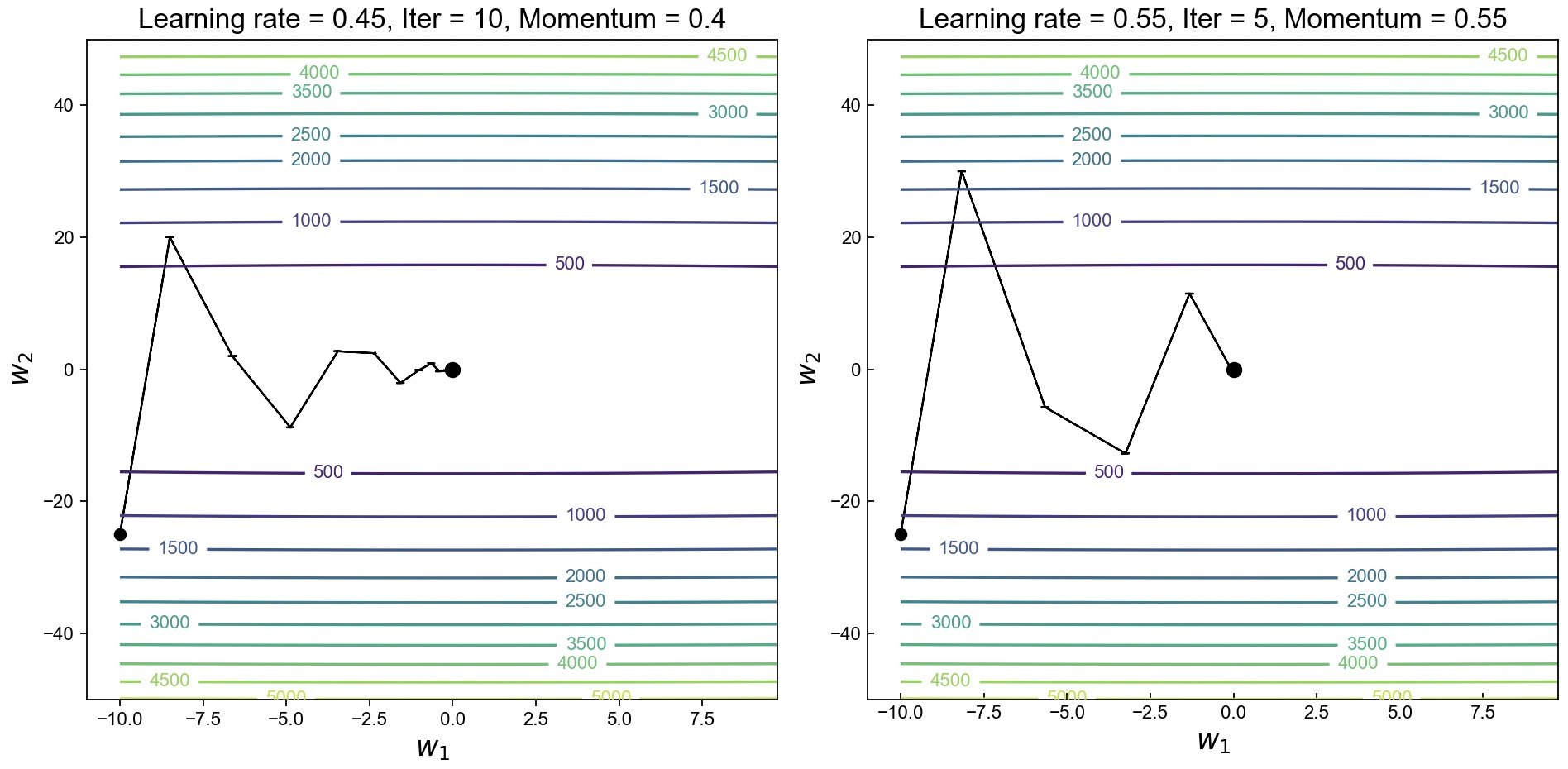
如图6-22所示,左右两边分别为图6-21中的两种情况加入动量后的迭代过程。对比图6-21和图6-22左侧的结果可以看出,当学习率不变且动量系数$\mu=0.4$时,目标函数在10次迭代后便收敛了,并且每次迭代的震荡幅度也有了明显减小。对比图6-21和图6-22右侧的结果可以看出,当学习率从0.4增大到0.55且动量系数增大至$\mu=0.55$后,目标函数在5次迭代后便进入了收敛状态。
此时可以看出,通过引入动量项可以使得权重参数的更新方向同时受到当前和之前梯度的影响,而这也更有助于在梯度方向不断变化的情况下更快地使目标函数收敛。
6.6.3 使用示例#
在介绍完动量法的基本原理以后,我们再来看如何使用这一优化算法。在PyTorch框架中,我们可以通过torch.optim.SGD() 模块来使用基于动量的梯度下降算法。下面对其中的几个关键参数进行介绍。
1 class SGD(Optimizer):
2 def __init__(self, params, lr=required, momentum=0,
3 dampening=0,weight_decay=0):
4 pass在上述代码中,第2行params表示指定模型的权重参数。lr表示指定学习率;momentum便是需要指定的动量系数,默认为0,即不使用动量法;dampening为PyTorch中加入的另外一个控制参数,即式(6-29)中$g_{t+1}$将变形为$(1-\tau)g_{t+1}$,默认情况下$\tau=0$,即此时等价于$g_{t+1}$;weight_decay表示$l_2$权重衰减项,详情可参见「第3.10节 过拟合与正则化:深度学习模型怎么防过拟合」内容。
最后,我们只需要在初始化SGD优化器的时候指定相应的动量系数便可以在模型训练时使用基于动量的梯度下降算法来最小化目标函数。
6.6.4 小结#
在本节内容中,我们首先介绍了动量法出现的动机,即使得目标函数在使用较大学习率的情况下能够时候模型更快收敛;然后详细介绍了动量法的基本原理,并通过实验来直观解释了动量法的作用;最后介绍了如何在PyTorch中使用基于动量的梯度下降算法来优化目标函数。在下一节内容中,我们将会介绍另外一种基于梯度下降算法改进的优化算法AdaGrad。
引用#
[1] Polyak B T. Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics, 1964, 4(5):1–17.
[2] Sutskever I, Martens J, Dahl G, et al. On the importance of initialization and momentum in deep learning[C]//International conference on machine learning. PMLR, 2013: 1139-1147.
[3] 阿斯顿·张、李沐、扎卡里 C. 立顿等,动手学深度学习[M],2版. 北京:人民邮电出版社, 2019.
[4] Paszke A, Gross S, Massa F, et al. Pytorch: An imperative style, high-performance deep learning library[J]. Advances in neural information processing systems, 2019, 32.