8.5 3DCNN网络#
在「第8.4节 ConvLSTM原理:时空序列预测与卷积循环模型」内容中,我们详细介绍了一种用于对时空数据进行特征提取的ConvLSTM模型,其有效地结合了RNN和CNN各自的优点对输入数据在时间和空间两个维度进行建模。在接下来的这节内容中将会介绍另外一种拓展自传统卷积网络的3D卷积模型来对时空数据进行特征提取。
8.5.1 3DCNN动机#
在传统的卷积神经网络中,卷积操作可以直接用于对二维图像数据进行特征提取,但是对于类似视频这样的时空数据却不能对其时间维度上的信息进行建模。在时空数据中,原始数据是由一系列连续的帧(二维图像)组成,每一帧内部包含了空间信息,而帧与帧之间还存在时间关系,因此传统的二维CNN只能对单独的帧进行处理而无法捕捉到帧与帧之间的时序特征。
基于这样的动机,姬水旺[1]等人在2014年提出了一种同时能够考虑时序信息的卷积模型(3D Convolutional Neural Network, 3DCNN)。3DCNN的基本结构与传统的CNN类似,由多个卷积层、池化层和全连接层组成,但是3DCNN在卷积操作中使用了3D卷积核,同时在池化操作中同时考虑了时间和空间维度,这使得3DCNN能够捕捉数据中的时空特征并在处理时间序列或空间序列数据时更加有效。
8.5.2 3DCNN结构#
1. 卷积层
在3DCNN中,其核心部分便是其中的三维卷积操作。根据第8.4.2节内容可知,时空数据一共包含有4个维度,即长度、宽度、通道数和时序长度。因此,在3DCNN中卷积层对输入数据进行卷积操作时除了像二维卷积一样需要在长度和宽上进行滑动,还需要以固定深度在时序长度这个维度上进行滑动,并在每个位置上与输入数据进行逐元素相乘求和,从而生成输出特征图。
如图8-7所示,从上到下依次为2D卷积对单帧数据、2D卷积对多帧数据和3D卷积对多帧数据的特征提取过程。
![图 8-7 2D卷积与3D卷积对比图[2]](https://mlwithme.oss-cn-shanghai.aliyuncs.com/images/dl/230618160432.jpg)
在图8-7(a)中,使用卷积核通道数为单个数据帧帧通道数的2D维卷积对单帧数据进行特征提取后得到的仍旧只是一个数据帧;在图8-7(b)中,使用卷积核通道数为单帧通道数乘以数据帧数的2D卷积后得到的也只是一个数据帧;在图8-7(c)中,使用卷积核通道数为$d(d < L)$,且同时在数据帧这个维度上进行滑动的3D卷积对多帧数据进行特征提取后得到的还是一个多帧数据。具体地,对于图8-7(c)中的卷积过程进一步还可以细化为图8-8中的形式。
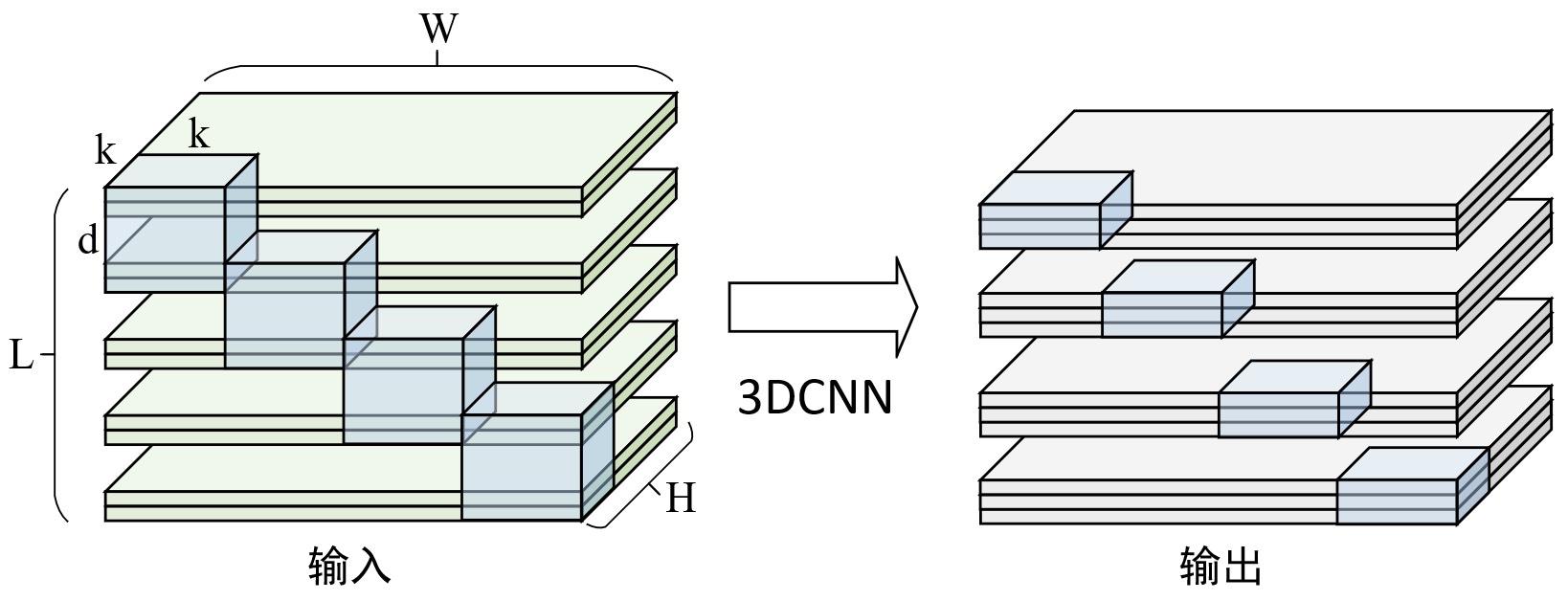
如图8-8所示,左侧为原始的输入数据和卷积核,对于输入数据来说一共包含有5帧,其中每一帧中有2个特征通道;右侧为3D卷积计算结果后的结果,一共包含有4帧,每一帧有3个特征通道。由此可知,对于3D卷积来说卷积核可通过长度、宽度、通道数、深度和卷积核个数这个5个维度来进行表示。例如对于图8-8中的示例来说,该卷积核的长度和宽度均为$k$、通道数和深度均为2、卷积核的个数为3(对应的便是输出的3个通道)。
2. 计算示例
在清楚3D卷积的计算原理后我们再通过一个实际的计算示例来体会整个计算过程。现在假定原始输入数据有3帧,其中每一帧有2个特征通道,长宽均为5,即形状为[in_channels, frame_len, height, width];卷积核个数为2,长宽均为3,深度为2,即形状为[out_channels, in_channels, depth, height, width]。整体相关信息如图8-9所示。
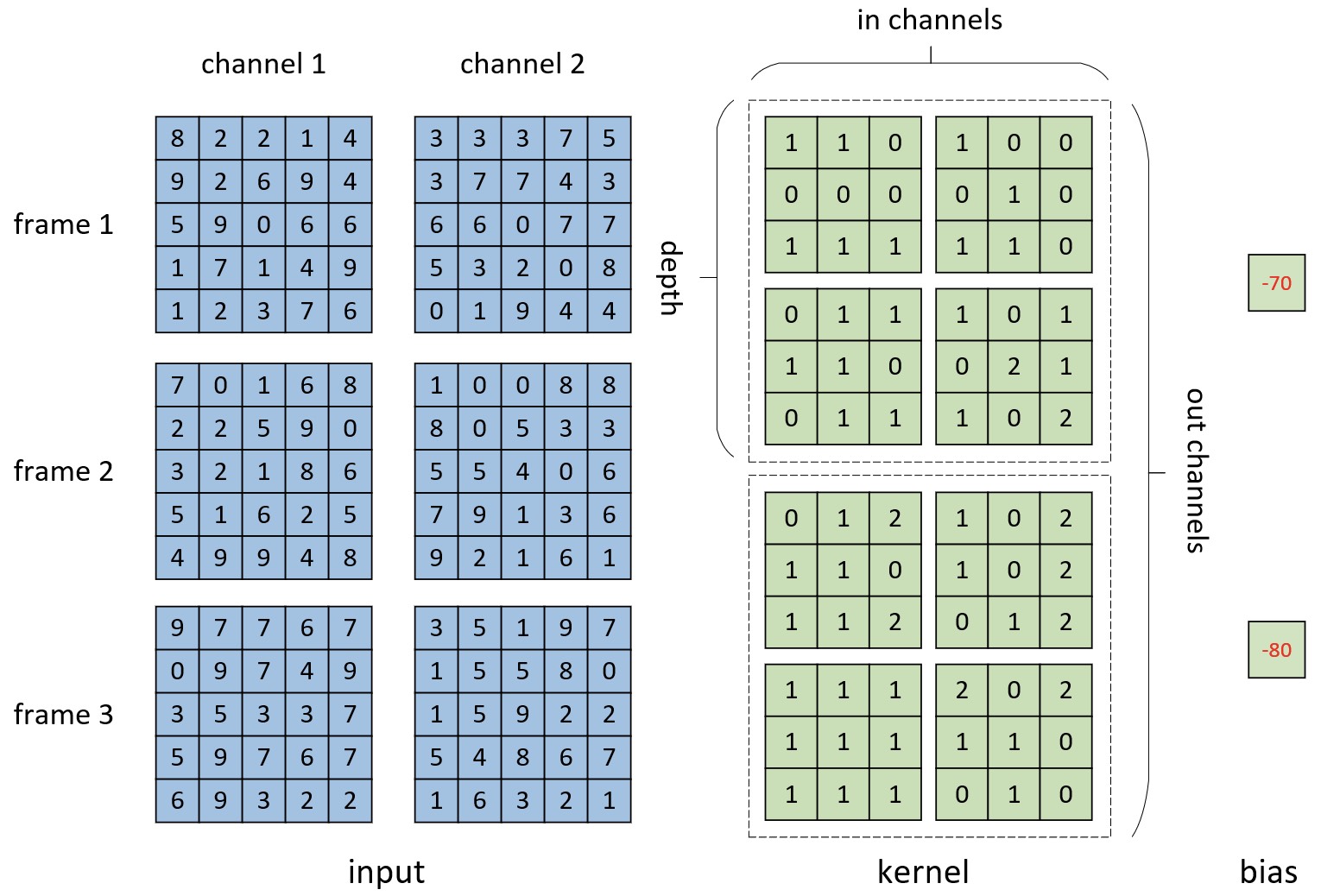
如图8-9所示,左侧便是原始的输入数据帧,其形状为[2,3,5,5];右侧有为卷积核与偏置,其中卷积核的形状为[2,2,2,3,3]。由此可知,在不进行填充的情况下,3D卷积最终计算完成后特征图一共包含有2帧,每一帧的长宽均为3,特征通道数为2。
进一步,3D卷积的计算过程可以通过图8-10来进行表示。
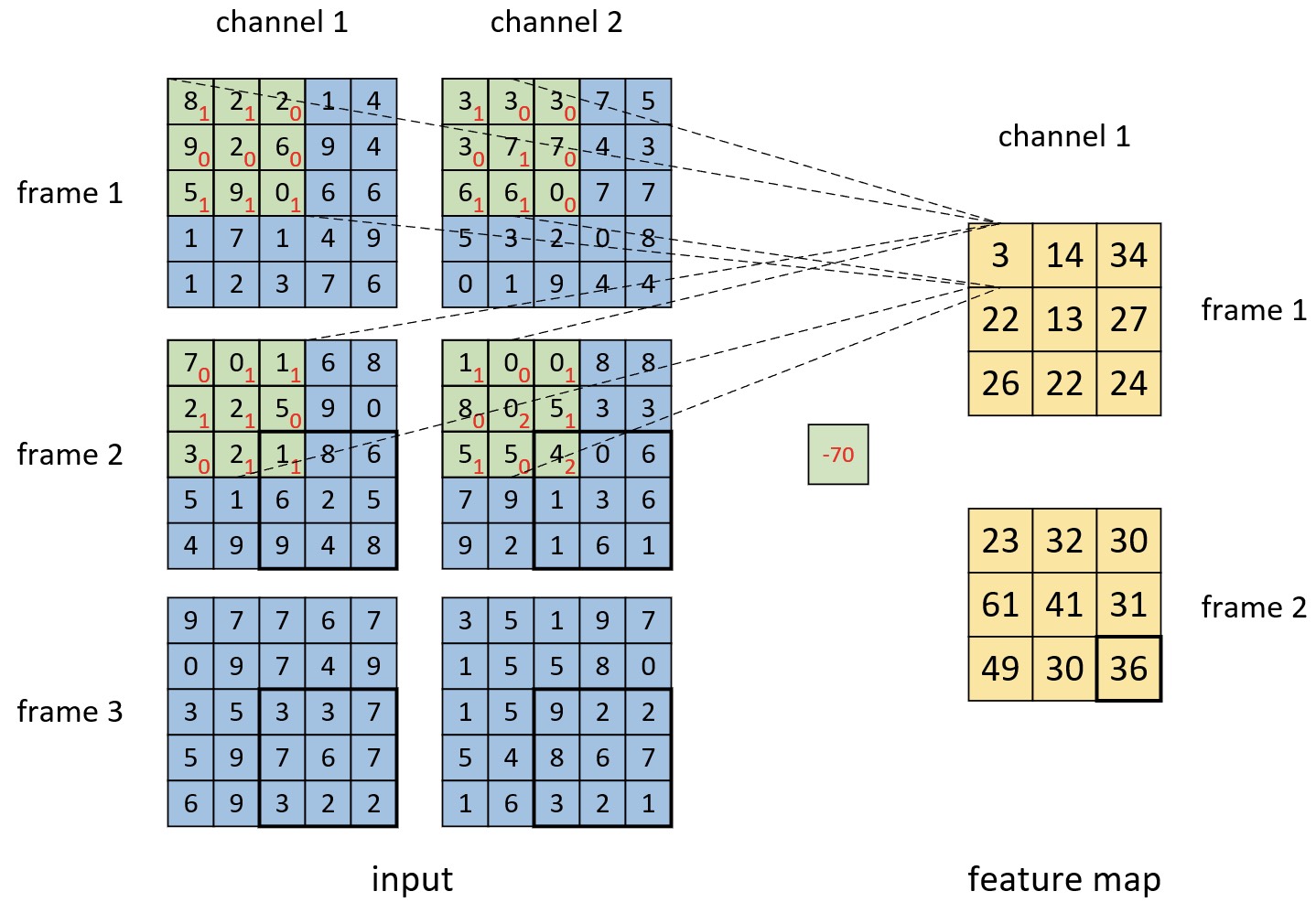
如图8-10所示,对于第1个卷积核来说,第1帧的第1个值3的计算过程如式(8-2)所示。
$$ \begin{aligned} &(8\cdot1+2\cdot1+5\cdot1+9\cdot1)+(3\cdot1+7\cdot1+6\cdot1+6\cdot1)+\\[2ex]&(1\cdot1+2\cdot1+2\cdot1+2\cdot1+1\cdot1)+(1\cdot1+5\cdot1+5\cdot1+4\cdot2)-70=3 \end{aligned}\tag{8-2} $$可以发现,其计算过程同2D卷积类似,即卷积核每个位置上与输入数据进行逐元素相乘求和。
同理,第2帧的最后一个值36的计算过程如式(8-3)所示。
$$ \begin{aligned} &(1\cdot1+8\cdot1+9\cdot1+4\cdot1+8\cdot1)+(4\cdot1+3\cdot1+1\cdot1+6\cdot1)+\\[2ex] &(3\cdot1+7\cdot1+7\cdot1+6\cdot1+2\cdot1+2\cdot1)+(9\cdot1+2\cdot1+6\cdot2+7\cdot1+3\cdot1+1\cdot2)-70=36 \end{aligned}\tag{8-3} $$在完成第1个卷积核的计算过程后,可以根据同样的做法再次完成第2个卷积核的计算过程,最终得到的计算结果如图8-11所示。
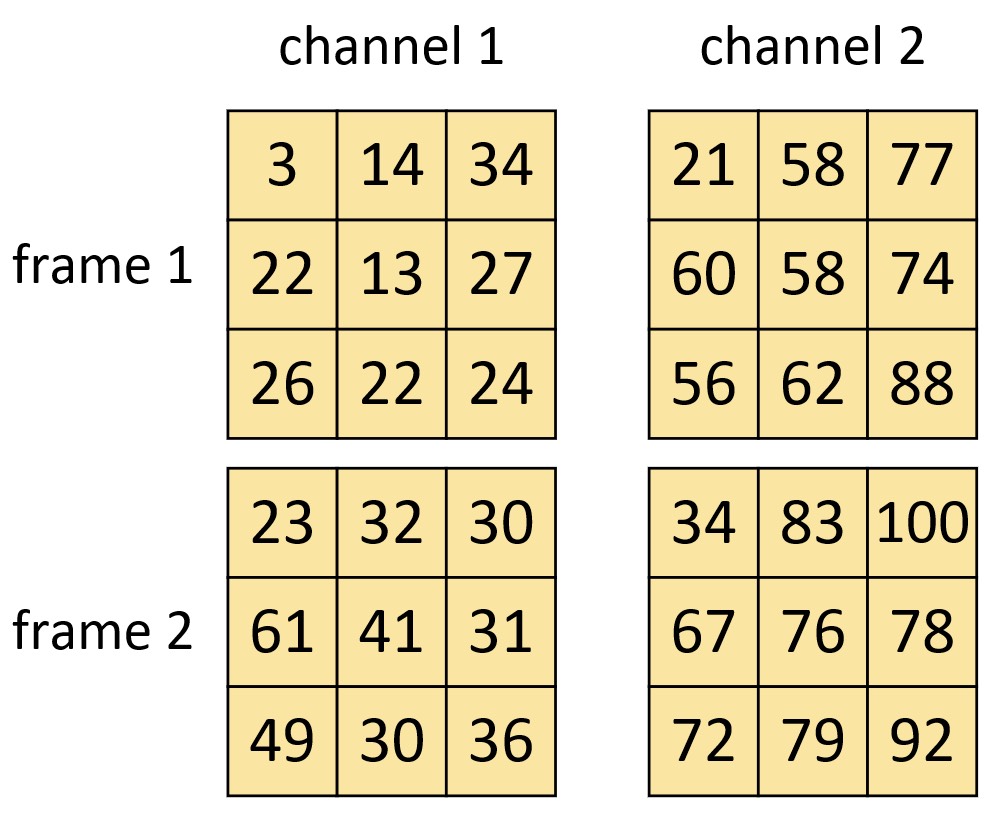
如图8-11所示便是最后计算得到的结果,其形状为[out_channels, frame_len_out, h_out, w_out],即[2,2,3,3]。以上完成计算示例代码可参见Code/Chapter08/C06_3DCNN/main.py文件。
3. 使用示例
在PyTorch中,我们可以借助nn.Conv3d()模块来完成3D卷积的计算过程。对于nn.Conv3d()模块来说,实例化需要传入5个参数,分别是in_channels、 out_channels、kernel_size和stride, padding。其中in_channels表示输入数据每一帧中特征的通道数,为整型;out_channels表示输出结果每一帧中特征的通道数,即卷积核的个数,为整型;kernel_size便是卷积核的形状,可以为元组(depth,height,width)或者整型,为整型时表示3个维度取同一个值;stride和padding分别表示移动和填充的参数,可以是3元组此时分别表示在深度、高度和宽度上的移动和填充,也可以是整型即每个维度的取值一样。
具体地,使用示例代码如下所示:
1 def OP_3DCNNC():
2 batch_size = 1
3 in_channels = 3
4 frame_len = 5
5 height = 32
6 width = 32
7 kernel_size = (2, 3, 3)
8 stride = (1, 1, 1)
9 padding = (0, 1, 1)
10 out_channels = 3
11 m = nn.Conv3d(in_channels, out_channels, kernel_size, stride, padding)
12 input = torch.randn(batch_size, in_channels, frame_len, height, width)
13 output = m(input)
14 print(output.shape) # torch.Size([1, 3, 4, 32, 32])在上述代码中,第2~6行是定义输入数据的相关维度信息。第7~10行是定义3D卷积的操作的相关超参数。第11行是实例化一个3D卷积类对象。第12行是构造输入数据。第13~14便是最后的输出结果。
4. 池化层
由于原始输入数据的形式产生了改变,所以3D池化层与2D池化层同样也有着不同之处,但是池化窗口的滑动过程同3DCNN一样,因此其详细计算过程这里不再赘述。例如对于图8-9中的输入数据来说,其采用同样大小的窗口进行最大池化操作后的结果如图8-12所示。
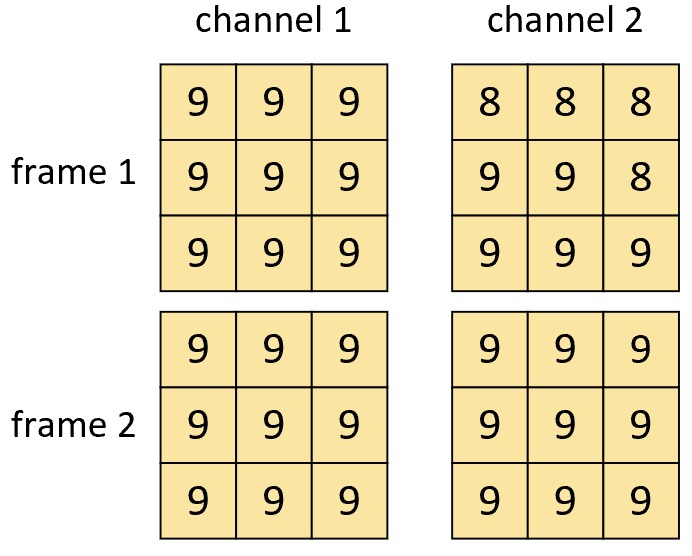
在3D池化层中,池化操作的对象为同一通道中连续多帧(深度)数据在一个池化窗口中的元素,即池化操作后通道数依旧保持不变。例如图8-12中第1个通道第1帧左上角的值9其计算过程如式(8-4)所示。
$$ \max(8, 2, 2, 9, 2, 6, 5, 9, 0, 7, 0, 1, 2, 2, 5, 3, 2, 1)=9\tag{8-4} $$同时,其对应的示例代码如下所示:
1 def max_pool():
2 pool = nn.MaxPool3d(kernel_size=(2, 3, 3), stride=1)
3 print(pool(input))在上述代码中,第2行便是实例化池化层的方法,其中kernel_size、stride和padding这3个参数的用法同nn.Conv3d中的一致,但需要注意的一点是这里必须指定stride的取值,否则默认会取与kernel_size同样的值。
8.5.3 3DCNN实现#
在介绍完3DCNN的基本原理后,下面依旧以第8.4节中介绍的KTH数据集为例来构建一个基于3DCNN的视频动作识别模型,其总体思路同之前的卷积神经网络类似,取多次卷积后的结果作为整个视频序列的特征表示,然后通过一个分类层完成分类任务。以下完整示例代码可以参见Code/Chapter08/C06_3DCNN/KTH3DCNN.py文件。
1. 前向传播
根据上述建模思路,基于3DCNN的KTH动作识别任务模型的前向传播过程示例代码如下所示:
1 class KTH3DCNN(nn.Module):
2 def __init__(self, config):
3 super(KTH3DCNN, self).__init__()
4 self.features = nn.Sequential(
5 nn.Conv3d(config.in_channels, 32, 3, stride=1, padding=(0, 1, 1)),
6 nn.BatchNorm3d(32),nn.ReLU(),
7 nn.Conv3d(32, 64, 3, stride=1, padding=(0, 1, 1)),
8 nn.BatchNorm3d(64),nn.ReLU(),
9 nn.MaxPool3d(3, stride=(1, 2, 2), padding=(0, 1, 1)),
10 nn.Conv3d(64, 128, 3, stride=1, padding=(0, 1, 1)),
11 nn.BatchNorm3d(128),nn.ReLU(),
12 nn.AdaptiveAvgPool3d((1, 1, 1)))
13 self.classifier = nn.Sequential(nn.Flatten(),nn.Linear(128, config.num_classes))在上述代码中,第5、7、10行分别是实例化3个3D卷积模块,且均使用了窗口大小为3的卷积核并仅在长宽两个维度上进行了填充,即每次卷积之后视频序列的帧数会减2但长宽不变。第6、8、11行分别是实例化一个批归一化和分线性变换对象。第9行则是一个最大池化层,将使得特征图的长宽均减半。第12行是全局自适应平均池化,会使得视频帧数、长和宽均为1。第13行则是最后一层分类器。
进一步,整个前向传播计算过程的示例代码如下所示:
1 def forward(self, x, labels=None):
2 x = self.features(x)
3 logits = self.classifier(x)
4 if labels is not None:
5 loss_fct = nn.CrossEntropyLoss(reduction='mean')
6 loss = loss_fct(logits, labels)
7 return loss, logits
8 else:
9 return logits在上述代码中,第1行x为模型输入,形状为[batch_size, in_channels, frames, height, width]。第2行为特征提取过程,输出结果形状为[batch_size,128,1,1,1]。第3行是分类层的输出结果,形状为[batch_size, num_classes]。
最后,可以通过如下方式来进行使用:
1 if __name__ == '__main__':
2 config = ModelConfig()
3 x = torch.randn([8, 3, 15,60, 80])
4 label = torch.randint(0, 6, [8], dtype=torch.long)
5 model = KTH3DCNN(config)
6 loss, logits = model(x, label)
7 print(f"输入形状:{x.shape}")
8 for seq in model.children():
9 for layer in seq:
10 x = layer(x)
11 print(f"网络层: {layer.__class__.__name__}, 输出形状: {x.shape}")上述代码运行结束后输出结果如下所示:
1 输入形状:torch.Size([8, 3, 15, 60, 80])
2 网络层: Conv3d, 输出形状: torch.Size([8, 32, 13, 60, 80])
3 网络层: BatchNorm3d, 输出形状: torch.Size([8, 32, 13, 60, 80])
4 网络层: ReLU, 输出形状: torch.Size([8, 32, 13, 60, 80])
5 网络层: Conv3d, 输出形状: torch.Size([8, 64, 11, 60, 80])
6 网络层: BatchNorm3d, 输出形状: torch.Size([8, 64, 11, 60, 80])
7 网络层: ReLU, 输出形状: torch.Size([8, 64, 11, 60, 80])
8 网络层: MaxPool3d, 输出形状: torch.Size([8, 64, 9, 30, 40])
9 网络层: Conv3d, 输出形状: torch.Size([8, 128, 7, 30, 40])
10 网络层: BatchNorm3d, 输出形状: torch.Size([8, 128, 7, 30, 40])
11 网络层: ReLU, 输出形状: torch.Size([8, 128, 7, 30, 40])
12 网络层: AdaptiveAvgPool3d, 输出形状: torch.Size([8, 128, 1, 1, 1])
13 网络层: Flatten, 输出形状: torch.Size([8, 128])
14 网络层: Linear, 输出形状: torch.Size([8, 6])2. 模型训练
由于这部分代码在之前也已经多次介绍过,因此这里也不再赘述,各位读者直接参考源码即可。最后,在对网络模型进行训练时将会得到类似如下的输出结果:
1 Epochs[1/50]--batch[0/201]--Acc: 0.1406--loss: 1.8179
2 Epochs[1/50]--batch[50/201]--Acc: 0.4844--loss: 1.4795
3 Epochs[1/50]--batch[100/201]--Acc: 0.3906--loss: 1.3454
4 Epochs[1/50]--batch[150/201]--Acc: 0.3594--loss: 1.1993
5 Epochs[1/50]--batch[200/201]--Acc: 0.4444--loss: 1.1351
6 Epochs[1/50]--Acc on val 0.3396
7 Epochs[2/50]--batch[0/201]--Acc: 0.4688--loss: 1.1121
8 Epochs[2/50]--batch[50/201]--Acc: 0.5625--loss: 1.0405
9 Epochs[2/50]--Acc on val 0.4899
10 Epochs[30/50]--Acc on val 0.77388.5.4 小结#
在本节内容中,我们首先介绍了3DCNN提出的动机;然后详细介绍了3DCNN的原理,并通过一个实际的计算示例来展示了其中的计算细节;接着介绍了如何在PyTorch中使用3DCNN以及其中各个参数的含义,并进一步介绍了3D池化层的计算原理;最后介绍了如何基于3DCNN来完成KTH动作识别任务。
引用#
[1] Ji S, Xu W, Yang M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2012, 35(1): 221-231.
[2] Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3d convolutional networks[C]. Proceedings of the IEEE international conference on computer vision. 2015, 4489-4497.