第10章 现代神经网络#
在「第5.4节 迁移学习教程:预训练模型微调与迁移训练」内容中,我们初次接触到了预训练(Pre-trained)模型这个概念。预训练模型的主要思想是模型通过在大规模数据集上学习得到通用特征的抽取能力,然后再将其迁移到其他任务中以加速新任务的学习和提高模型性能。预训练模型最早大规模应用于图像处理领域,而其中最具代表性的便是深度卷积神经网络预训练模型,例如AlexNet、VGG和ResNet等[1]。这些模型首先在大规模图像数据集(如ImageNet)上进行预训练以捕获图像的低级或中级特征(如边缘、纹理和形状等),然后再将其迁移到其他图像处理任务,如目标检测、图像生成和分割等。预训练模型的优点在于它们能够从大规模数据中学习到通用的特征表示并在多个下游任务上共享,这种方法既减少了对大量标注数据的需求也加速了模型的训练和收敛过程。
虽然在「第9.2节 Word2Vec原理:词向量训练与语义表示方法」和「第9.4节 GloVe词向量:全局统计词向量建模方法」内容中介绍到的词向量从某种程度上来讲也可以看作是一种简单的预训练模型,但是它并没有掀起自然语言处理领域中迁移学习的浪潮,因为它并没有给下游任务带来实质上的提升。直到2018年ELMo模型的出现才使得研究人员又开始将迁移学习聚焦到自然语言处理领域中[2]。紧接着,自然语言处理领域便先后出现了一系列有着重要影响的预训练模型,例如BERT和GPT系列。从某种程度上来说这两个技术流派正在引领者当前自然语言处理研究的主要方向。在本章内容中,我们将会逐一对这些模型的思想原理及其实战案例进行详细的介绍,包括ELMo、Transformer、BERET和GPT系列模型等。
10.1 ELMo网络#
在「第9章 Word2Vec、GloVe、Seq2Seq 与注意力机制」内容中我们谈到自然语言处理的本质是理解并生成语言,而理解自然语言的前提就是如何有效对其进行表示。在第9.2节和第9.4节内容中,我们分别介绍了两种传统的静态词向量表示方法,即Word2Vec和Glove模型。在本节内容中我们将介绍另外一种新的动态词向量模型ELMo。
10.1.1 ELMo动机#
在传统的静态词向量中每个词都将被映射为一个固定的向量表示,词向量在构建过程中也只使用了局部的上下文信息,因此难以准确地表示词语在复杂语境中的依赖关系。同时,静态词向量并没有考虑词义随上下文语境变化所产生的不同含义,即无法解决一词多义的问题。例如文章中出现了“苹果”一词,它到底是指代科技公司“苹果”还是水果中的“苹果”静态词向量无法解决,因为这需要根据上下文来确定。在这样的背景下有学者开始研究基于上下文环境的词向量表示方法[3] [4]。在这类方法中,词向量的表示通常都不再只是一个固定的权重向量而是整个网络模型根据输入的上下文计算得到的词向量表示,即对于同一个词来说上下文语境的变化也会导致词向量表示的变化。
基于这样的动机, 马修(Matthew)等人[2]于2018年提出了一种基于LSTM的深度双向语言模型(Embeddings from Language Models, ELMo)来学习词向量的动态表示。ELMo模型通过将每个词表示为其在不同层次上下文中隐含状态的线性组合,使得每个词的向量表示不仅能够包含更为丰富的语义信息同时也能够捕捉到不同语境下的语义信息。最终,基于ELMo动态词向量的下游模型在6个流行的NLP任务中都取得了显著的效果提升。
10.1.2 ELMo结构#
在以往的研究中研究者们发现,将每个单词拆分成子词(Subword)的形式[5] [6]以及通过将不同网络深度输入的向量表示组合起来[7]均能够在一定程度上提高词向量的表达能力。受此启发,ELMo模型首先利用基于字符级的卷积神经网络CharCNN来学习得到每个词与上下文无关(Context-Independent)的向量表示;然后再通过一个带有残差连接的两层双向循环神经网络(相关内容可参见「第7.1.5节 RNN原理:循环神经网络的结构与序列建模」内容)来学习得到不同网络深度中每个词与上下文相关(Context-Dependent )的向量表示;最后再将三部分的输出以线性组合的方式得到每个词的向量表示。如图10-1所示便是ELMo模型的整体网络结构图。
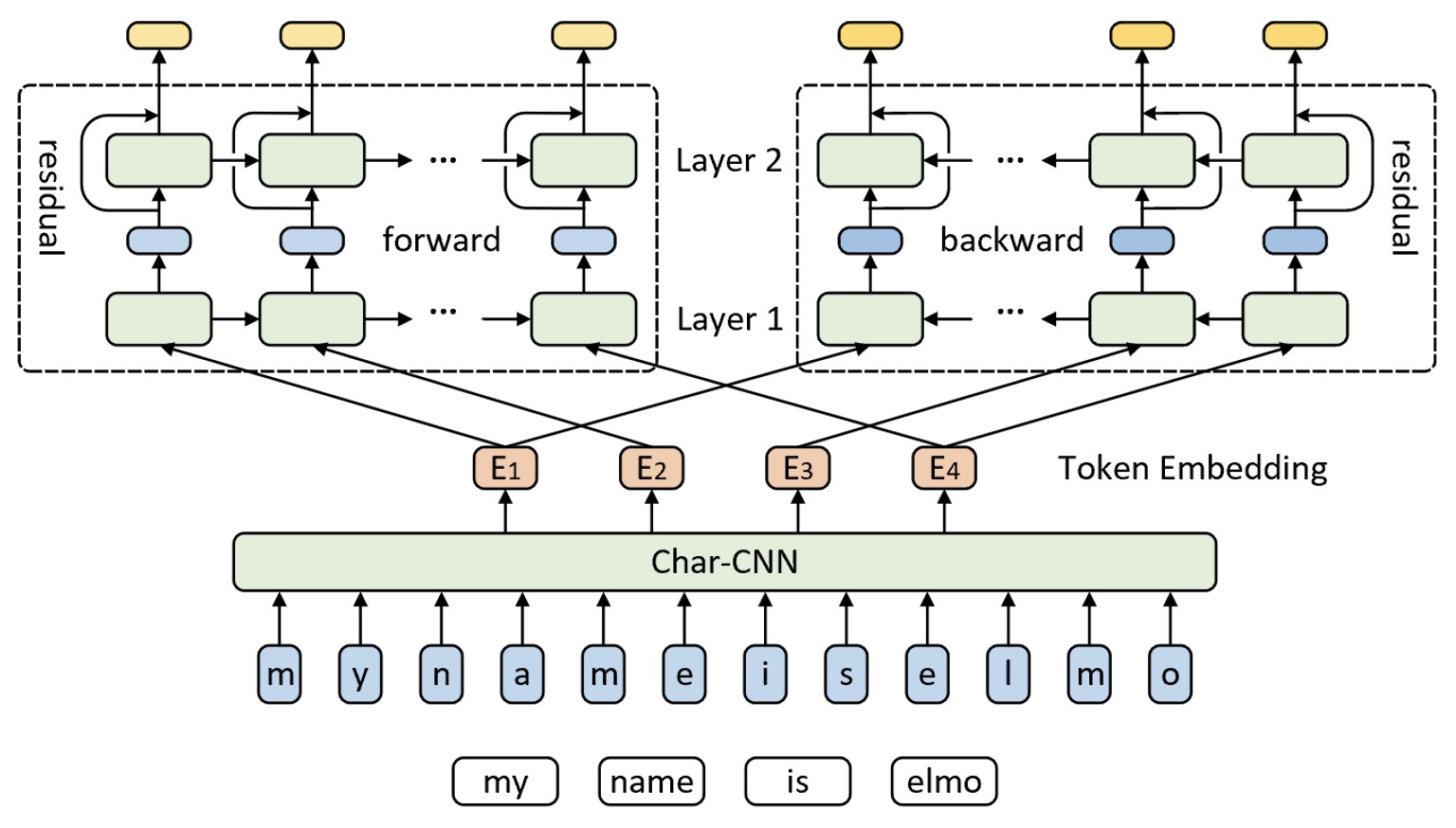
如图10-1所示便是ELMo模型的整体网络结构。ELMo模型整体上包括字符级的卷积神经网络和带残差连接的双向循环神经网络两大部分,分别用于学习得到不同粒度的词向量表示。接下来分别就各部分进行介绍。
1. 字符级卷积网络
在字符级卷积神经网络中,每个单词首先将会被切分成字符形式,并且对于每个单词来说其最大长度为50,不足部分需进行填充;然后再将其以不同窗口大小的一维卷积操作进行特征提取;最后经过最大池化操作并将池化后的结果进行拼接得到整个单词的词嵌入表示。
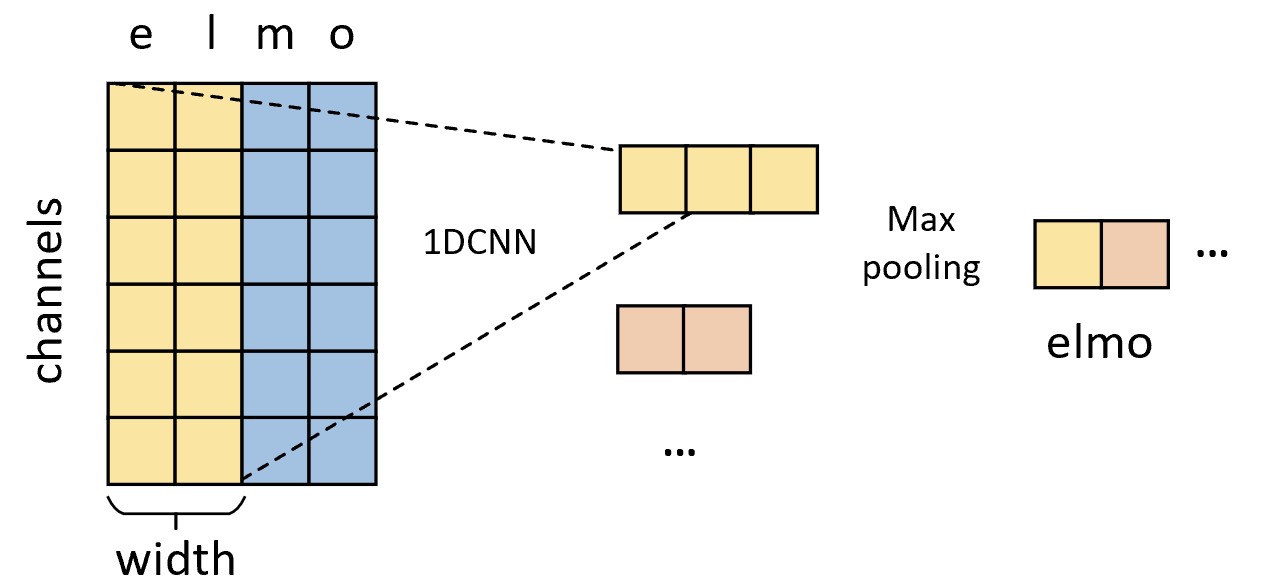
如图10-2所示便是一维卷积操作的示意图,其中左侧矩阵中:每一列表示每个字符对应的向量表示,在一维卷积中称其为通道数;每一行表示同一个特征通道中不同字符对应的特征。同时,在一维卷积中卷积核有3个参数,分别是输入通道数in_hannels、宽度width和输出通道数out_channels。在ELMo模型中,每个单词的最大长度max_characters_per_token为50;字符嵌入维度char_embed_dim为16,即图10-2中的channels为16;并且采用了宽度分别为1、2、3、4、5、6、7的卷积核,其中卷积核的数量分别为32、32、64、128、256、512、1024,即卷积操作结束后每个词向量的维度为2048。最后,再通过一个两层的高速连接(Highway )[8]和全连接层将每个词向量映射到了512维,即图10-1中的$E_i$。
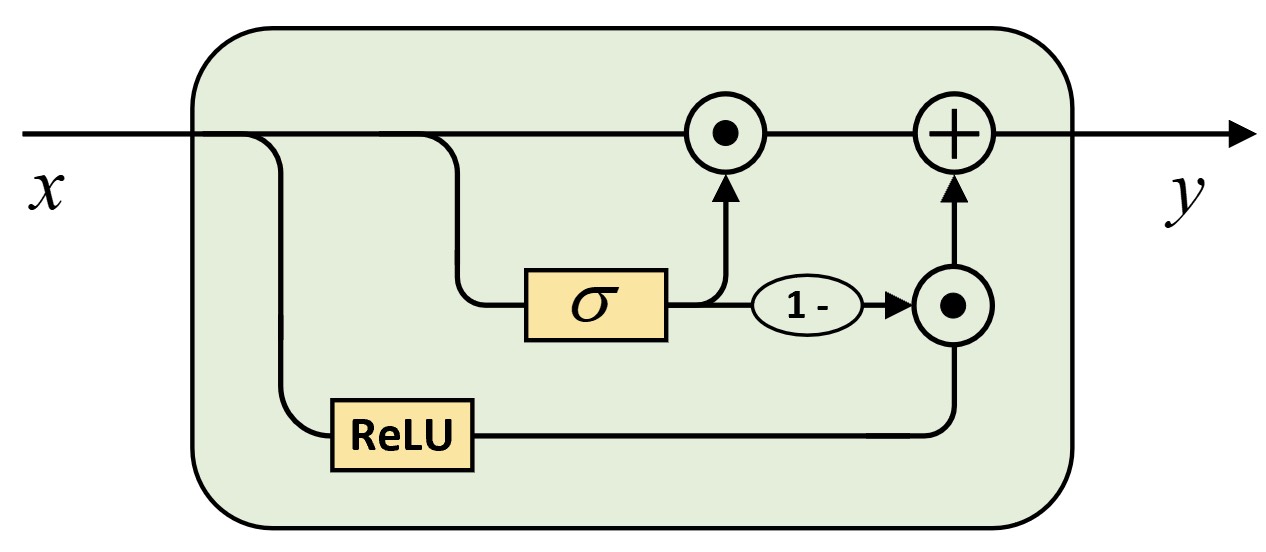
如图10-3所示便是高速连接层的结构示意图,其主要思想也是借鉴于LSTM中的单元记忆状态,使得网络每加深一层都能够同时融合当前层和上一层的历史信息。可以看出,此处的门控单元同时充当了遗忘门和输入门的角色。具体地,其计算过程为
$$ y=\sigma(xW_f)\odot x\oplus(1-\sigma(xW_f))\odot g(xW_i)\tag{10-1} $$2. 双向循环神经网络
在循环神经网络中不同网络深度的输出结果能够分别从上下文依赖、语法信息等角度来丰富词语的向量化表示,因而对于不同的下游任务有着不同的性能提升。例如在一个基于两层LSTM的编码器-解码器翻译模型中,编码器第1层的输出向量相比于第2层来说更加有利于进行词性标记(Part-Of-Speech Tags)任务。因此ELMo模型同样采用了两层的双向循环神经网络来获取得到不同粒度的词向量表示,并且在循环神经网络之间还采用了残差连接。如图10-1上半部分所示表示整个双向LSTM部分。
在ELMo模型中,对于给定序列$t_1,t_2,...,t_N$正向LSTM需要根据给定的前$k-1$个词来预测第$k$词,即建模
$$ p(t_1,t_2,...,t_N)=\prod_{k=1}^Np(t_k|t_1,t_2,...,t_{k-1})\tag{10-2} $$并且用$\overrightarrow{h}_{k,j}^{\text{LM}}, j=1,...,L$表示正向LSTM第$j$层第$k$个时刻的输出结果。
反向LSTM则恰好相反,需要根据给定的后$N-k$个词来预测第$k$个词,即建模
$$ p(t_1,t_2,...,t_N)=\prod_{k=1}^Np(t_k|t_{k+1},t_{k+2},...,t_{N})\tag{10-3} $$并且用$\overleftarrow{h}^{\text{LM}}_{k,j}, j=1,...,L$表示反向LSTM第$j$层第$k$个时刻的输出结果。
最终,通过最大化式(10-4)来求解整个模型参数
$$ \sum_{k=1}^N\left(\log p(t_k|t_1,...,t_{k-1};\Theta_x,\overrightarrow{\Theta}_{\text{LSTM}},\Theta_s)+\log p(t_k|t_{k+1},...,t_{N};\Theta_x,\overleftarrow{\Theta}_{\text{LSTM}},\Theta_s)\right)\tag{10-4} $$其中$\Theta_x$表示CharCNN中的所有权重参数,$\overrightarrow{\Theta}_{\text{LSTM}}$和$\overleftarrow{\Theta}_{\text{LSTM}}$分别表示正向反向LSTM中的权重参数,$\Theta_s$表示每个时刻$\text{Softmax}$分类层的权重参数,且对于正反两个LSTM来说共享一个分类器。
3. ELMo词向量表示
当整个ELMo模型在大规模语料上完成预训练之后,便可以取各部分对应的输出经过线性组合得到每个词最终的向量表示,如图10-4所示。
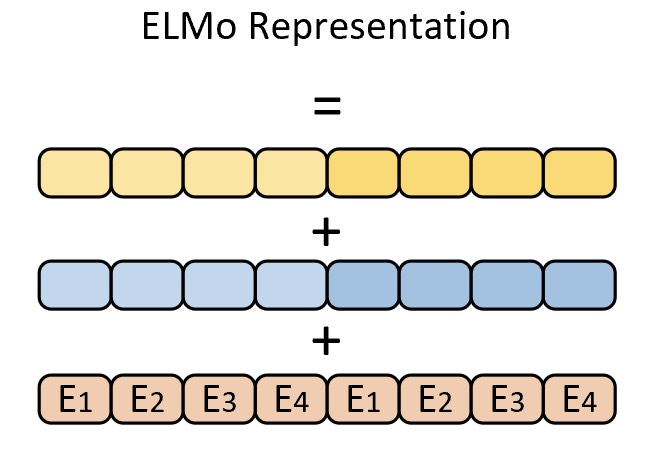
在图10-4中,最下面是CharCNN部分的输出,且同时为对齐LSTM的输出进行的复制拼接;上面两个部分则分别是两层双向LSTM每一层的输出结果。
具体地,在一个包含有$L$层的双向语言模型来中,对于任意词$t_k$来说将会得到$2L+1$个向量表示,即
$$ R_k=\{x^{\text{LM}}_k,\overrightarrow{h}_{k,j}^{\text{LM}},\overleftarrow{h}_{k,j}^{\text{LM}}|j=1,...,L\}=\{h^{\text{LM}}_{k,j}|j=0,1,...,L\}\tag{10-5} $$其中$h^{\text{LM}}_{k,0}$表示CharCNN模块第$k$个时刻的输出,$h^{\text{LM}}_{k,j}=[\overrightarrow{h}_{k,j}^{\text{LM}};\overleftarrow{h}_{k,j}^{\text{LM}}]$表示双向LSTM第$j$层第$k$个时刻的输出。
最终,在每个具体的下游任务中,我们可以通过如下线性组合方式得到每个词的向量表示
$$ \text{ELMo}_k=E(R_k;\Theta)=\gamma\sum_{j=0}^Ls_jh^{\text{LM}}_{k,j}\tag{10-6} $$其中$\gamma$可以看做是用于缩放ELMo向量的超参数,$s_i$为线性组合中每一层对应的权重参数,在实际情况中可以手动指定也可以随机初始化同下游模型一同训练得到[9]。
10.1.3 ELMo实现#
在介绍完ELMo模型的基本原理后我们再来看如何借助PyTorch来实现这一模型。由于论文开源代码较为复杂、考虑细节较多,例如为了提升效果作者重新实现了LSTM等模块[9],因此接下来的实现仅仅只是一个简单版的ELMo模型,不过这并不影响我们对于ELMo模型的整体理解。
1. 加载预训练模型
首先我们需要实现一个类来完成对后续已经持久化的模型进行载入,示例代码如如下所示:
1 class PretrainedModel(nn.Module):
2 def __init__(self, ):
3 super(PretrainedModel, self).__init__()
4 pass
5
6 @classmethod
7 def from_pretrained(cls, config, pretrained_model_path=None):
8 model = cls(config)
9 loaded_paras = torch.load(pretrained_model_path)
10 model.load_state_dict(loaded_paras)
11 if config.freeze:
12 for (name, param) in model.named_parameters():
13 param.requires_grad = False
14 return model在上述代码中,第8行是根据传入的配置参数实例化一个类对象。第9~10行是载入本地持久化参数并重新赋值给已经实例化的模型。第11~13行是判断是否冻结预训练模型。后续实现的各个类模块只需要继承类PretrainedModel便可以直接使用from_pretrained()方法来载入预训练模型。
2. HighWay实现
接着对高速连接层进行实现。根据式(10-1)可知,实现过程如下所示:
1 class HighWay(nn.Module):
2 def __init__(self, config=None):
3 super().__init__()
4 self.highway = nn.Linear(config.n_filters, config.n_filters * 2)
5 self.relu = nn.ReLU()
6 self.sigmoid = nn.Sigmoid()
7
8 def forward(self, hidden_state):
9 highway = self.highway(hidden_state)
10 nonlinear_part, gate = highway.chunk(2, dim=-1)
11 nonlinear_part = self.relu(nonlinear_part)
12 gate = self.sigmoid(gate)
13 hidden_state = gate * hidden_state + (1 - gate) * nonlinear_part
14 return hidden_state在上述代码中,第4行为实例化一个线性层,其中乘以2是一次性完成后续非线性变换和门控单元的计算。第5~6行是分别实例化一个非线性变换层和一个门控计算层。第9~12行是分别计算得到非线性变换部分和门控单元的结果。第13行则是根据式(10-1)计算得到高速连接层的输出。可以看出,经过高速连接层处理后,输出结果的形状并没有发生改变。
3. ELMoCharacterCNN实现
然后实现基于一维卷积操作的字符级嵌入模块,并最终得到维度为512维的上文无关的词向量表示,实现代码如下所示:
1 class ELMoCharacterCNN(PretrainedModel):
2 def __init__(self, config=None):
3 super(ELMoCharacterCNN, self).__init__()
4 self.config = config
5 self.char_embedding = nn.Embedding(config.embed_num,config.embed_dim)
6 conv = []
7 for i, (width, num) in enumerate(config.char_cnn_filters):
8 conv.append(nn.Conv1d(in_channels=config.char_embed_dim,
9 out_channels=num, kernel_size=width, bias=True))
10 self.char_conv = nn.ModuleList(conv)
11 self.relu = nn.ReLU()
12 self.highway = nn.ModuleList([HighWay(config) for _ in range(config.n_highway)])
13 self.projection = nn.Linear(config.n_filters, config.projection_dim)在上述代码中,第5行是实例化一个字符嵌入层对象。第7~9行是根据传入的参数实例化多个不同宽度的一维卷积对象,其中每个参数的含义同图10-2处介绍一致。第12~13行分别是实例化多个高速连接层和一个全连接投影层。
此时,上述代码对应的前向传播实现过程为:
1 def forward(self, x):
2 seq_len = x.shape[1]
3 x = self.char_embedding(x)
4 x = x.reshape(-1, x.shape[2], x.shape[3])
5 x = x.transpose(1, 2)
6 convs = []
7 for conv in self.char_conv:
8 convolved = conv(x)
9 convolved, _ = torch.max(convolved, dim=-1)
10 convolved = self.relu(convolved)
11 convs.append(convolved)
12 token_embedding = torch.cat(convs, dim=-1)
13 for highway in self.highway:
14 token_embedding = highway(token_embedding)
15 token_embedding = self.projection(token_embedding)
16 token_embedding = token_embedding.reshape(-1, seq_len, self.config.proj_dim)
17 return token_embedding在上述代码中,第1行传入的x是原始文本经过字符切分填充且转换为索引ID后的结果,其形状为[batch_size, seq_len, max_chars_per_token],其中max_chars_per_token表示每个单词所允许的最大长度。
例如对于如下两个样本来说
1 ['language model', 'ELMo is very powerful']其首先将被处理成
1 [['language', 'model'], ['ELMo', 'is', 'very', 'powerful']]然后再将每个单词进行分割,不足max_chars_per_token长度的进行填充,并转换成对应的索引ID。最后,处理完成后部分结果如下所示
1 tensor([[[259, 109, 98, 111, 104, 118, 98, 104, 102, 260, 261, ... , 261],
2 [259, 110, 112, 101, 102, 109, 260, 261, 261, 261, 261, ... , 261],
3 [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... , 0],
4 [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... , 0]],
5 [[259, 70, 77, 78, 112, 260, 261, 261, 261, 261, 261, ... , 261],
6 [259, 106, 116, 260, 261, 261, 261, 261, 261, 261, 261, ... , 261],
7 [259, 119, 102, 115, 122, 260, 261, 261, 261, 261, 261, ... , 261],
8 [259, 113, 112, 120, 102, 115, 103, 118, 109, 260, 261, ... , 261]]])在上述结果中,第1~4行和5~8行分别是上面两个样本的输出结果,其中第3~4行表示从单词数量角度进行的填充,因为两个样本中最长的有4个单词。同时,第1~8行每一行均表示一个单词分割后的字符索引ID,其中索引261表示对长度不足50(论文中max_chars_per_token为50)的部分进行的填充。此时,输出结果的形状为[batch_size, seq_len, max_chars_per_token]。
在上述代码中,第3~5行是字符嵌入后的输出结果并将形状处理成nn.Conv1d()所接受的形式,即[batch_size*seq_len, char_embed_dim, max_chars_per_token]。第7~11行是根据不同宽度的卷积核对字符嵌入进行特征提取并进行最大池化。第12行是将卷积后的结果进行拼接,形状为[batch_size*seq_len, n_filters],默认配置中n_filters为2048。第13~14行为高速连接层的前向传播计算过程,输出形状仍为[batch_size*seq_len, n_filters]。第15~16行为将其进行一次线性投影并变形为标准的文本序列表示形式,即形状为[batch_size, seq_len, projection_dim]。
此时,CharCNN模块输出的便是与上下文无关的词向量表示。
4. ELMoBiLSTM实现
进一步,实现带残差连接双向LSTM。由于层与层之间进行了跳层连接,所以并不能直接使用PyTorch中实现的双向LSTM,因此需要单向双向分开逐层实现,示例代码如下所示:
1 class ELMoBiLSTM(PretrainedModel):
2 def __init__(self, config=None):
3 super().__init__()
4 self.config = config
5 forward_layers, back_layers = [], []
6 for _ in range(config.n_layers):
7 lstm_forward = nn.LSTM(input_size=config.projection_dim,
8 hidden_size=config.projection_dim,num_layers=1, batch_first=True)
9 lstm_backward = nn.LSTM(input_size=config.projection_dim,
10 hidden_size=config.projection_dim,num_layers=1, batch_first=True)
11 forward_layers.append(lstm_forward)
12 back_layers.append(lstm_backward)
13 self.forward_layers = nn.ModuleList(forward_layers)
14 self.back_layers = nn.ModuleList(back_layers)在上述代码中,第6~12行是根据参数实例化多层的前向和反向LSTM,并将其分别保存到两个列表中。第13~14则是将两者分别存放至PyTorch的模型列表中,否则在GPU上运行时会提示模型与变量不在同一设备的错误。
接着,双向LSTM的前向传播过程实现如下:
1 def forward(self, x):
2 forward_cache, backward_cache = x, x.flip(1)
3 outputs = [torch.cat([forward_cache, backward_cache], dim=-1)]
4 for layer_id in range(self.config.n_layers):
5 forward_output = self.forward_layers[layer_id](forward_cache)[0]
6 backward_output = self.back_layers[layer_id](backward_cache)[0]
7 if layer_id != 0:
8 forward_output += forward_cache
9 backward_output += backward_cache
10 outputs.append(torch.cat([forward_output, backward_output], dim=-1))
11 forward_cache = forward_output
12 backward_cache = backward_output
13 return outputs在上述代码中,第1行x为文本序列的词嵌入表示结果,形状为[batch_size, seq_len, projection_dim]。第2行是分别得到正向和反向LSTM的输入,其中x.flip(1) 表示将序列按seq_len这个维度进行逆序处理。第3行是保存CharCNN的输出结果,即式(10-5)中的$x^{\text{LM}}_k$。第4~6行是分别计算每一层的正向LSTM和反向LSTM,并取每个LSTM所有时刻的输出结果,形状为[batch_size, seq_len, projection_dim]。第7~9行是残差连接的计算过程,并且从第2层开始才使用残差连接。第10行是保存ELMoBiLSTM中每一层的输出结果,形状为[batch_size, seq_len, projection_dim*2]。第13行则是返回所有层的输出结果。
5. ELMoLM实现
然后,基于ELMoBiLSTM来实现ELMo模型的预训练部分。整体思路为对于正向和反向LSTM两部分输出,各自根据式(10-4)来完成整个语言模型的构建过程,示例代码如下所示:
1 class ELMoLM(PretrainedModel):
2 def __init__(self, config=None):
3 super().__init__()
4 self.config = config
5 self.char_cnn = ELMoCharacterCNN(config)
6 self.lstm = ELMoBiLSTM(config)
7 self.classifier = nn.Linear(config.projection_dim, config.vocab_size)在上述代码中,第5~6行分别实例化一个字符级卷积类对象和双向LSTM类对象。第7行是实例化一个分类器,用于对正向和反向LSTM输出结果进行分类。
进一步,ELMo语言模型的的前向传播计算过程为:
1 def forward(self, x, labels=None):
2 char_embedding = self.char_cnn(x)
3 outputs = self.lstm(char_embedding)[-1]
4 f_logits = outputs[:, :, :self.config.projection_dim]
5 f_logits = self.classifier(f_logits)
6 b_logits = outputs[:, :, -self.config.projection_dim:]
7 b_logits = self.classifier(b_logits)
8 fn_loss = nn.CrossEntropyLoss(reduction='sum', ignore_index=-1)
9 f_loss = fn_loss(f_logits.reshape(-1, self.config.vocab_size),
10 labels.reshape(-1)) / x.shape[0]
11 b_loss = fn_loss(b_logits.reshape(-1, self.config.vocab_size),
12 labels.flip(1).reshape(-1)) / x.shape[0]
13 total_loss = f_loss + b_loss
14 return total_loss在上述代码中,第3行是双向LSTM的输出结果,其中取最后一层的向量表示,形状为[batch_size, seq_len, projection_dim*2]。第4~7行表示分别取正向和反向LSTM各自的输出结果,并使用同一个分类器进行分类。第8~13行是分别对正向和反向LSTM的预测结果进行损失计算,并将两部分的损失求和作为模型的整体损失。
6. ELMoRepresentation实现
在语言模型训练完毕以后,我们便可以用它来对输入序列进行表示,示例代码如下所示:
1 class ELMoRepresentation(nn.Module):
2 def __init__(self, config=None, rep_weights=None):
3 super().__init__()
4 self.config = config
5 self.char_cnn = ELMoCharacterCNN.from_pretrained(config, config.charcnn_model)
6 self.lstm = ELMoBiLSTM.from_pretrained(config, config.elmo_bilstm_model)
7 rep_weights_shape = [config.n_layers + 1, 1, 1, 1]
8 if rep_weights is None or len(rep_weights) != config.n_layers + 1:
9 if rep_weights is not None and len(rep_weights) != config.n_layers + 1:
10 logging.warning(f"rep_weights指定无效,其长度必须为{config.n_layers + 1}")
11 self.rep_weights = nn.Parameter(torch.randn(rep_weights_shape))
12 else:
13 self.rep_weights = torch.tensor(rep_weights).reshape(rep_weights_shape)在上述代码中,第2行rep_weights为指定每一层词向量的权重值,为一个列表。第5~6行是分别载入已经持久化的预训练模型。第8~11行是判断如果没有指定权重或指定错误则随机初始化权重。
进一步,双向LSTM的前向传播过程实现如下:
1 def forward(self, x):
2 char_embedding = self.char_cnn(x)
3 outputs = self.lstm(char_embedding)
4 outputs = torch.stack(outputs, dim=0)
5 elmo_rep = (outputs * self.rep_weights).sum(0)
6 return outputs, elmo_rep在上述代码中,第4行是得到每一层的向量表示,形状为[n_layers+1, batch_size, seq_len, projection_dim*2]。第5行是对每一层的向量表示进行线性组合,形状为[batch_size, seq_len, projection_dim*2]。
到此,对于ELMo模型的实现及使用就介绍完了,以上完整示例代码可参见Code/Chapter10/C01_ELMo/ELMo.py文件。
10.1.4 ELMo迁移#
下面,我们开始介绍如何使用官方开源的预训练模型[9]来获得ELMo对应的词向量表示,并且基于此来完成影评数据的分类任务。首先需要通过命令pip install allennlp-models来完成相关Python包的安装,同时由于其依赖于PyTorch==1.12.1版本,所以各位读者可以重新按照「第2.2节 深度学习环境安装:CUDA、PyTorch 与依赖配置教程」中的步骤重新创建一个虚拟环境来进行使用。
以下完整示例代码可参见Code/Chapter10/C02_AllenELMo/ELMoClassification.py文件。
1. 构建数据集
虽然在「第9.5.3节 词向量微调使用:预训练词向量在下游任务中的应用」内容中我们已经介绍 了影评数据集MR(Movie Reviews)的构建流程,但是由于ELMo模型需要从基于字符级别的输入进行特征提取,所以我们需要重新再改造一下之前的模块。具体地,我们需要重写其中的data_process()和generate_batch()方法,示例代码如下所示:
1 class MR4ELMo(TouTiaoNews):
2 DATA_DIR = os.path.join(DATA_HOME, 'MR')
3 FILE_PATH = [os.path.join(DATA_DIR, 'rt_train.txt'),
4 os.path.join(DATA_DIR, 'rt_val.txt'),
5 os.path.join(DATA_DIR, 'rt_test.txt')]
6
7 def __init__(self, batch_size=32, is_sample_shuffle=True):
8 self.batch_size = batch_size
9 self.is_sample_shuffle = is_sample_shuffle
10
11 def data_process(self, file_path=None):
12 samples, labels, data = self.load_raw_data(file_path), []
13 for i in tqdm(range(len(samples)), ncols=80):
14 data.append((samples[i].split(), labels[i]))
15 return data在上述代码中,第2~5行代码是初始化原始数据的相关路径。第7~9行是初始化方法,由于这里我们不需要构建词表所哟不需要用调用父类TouTiaoNews的初始化方法,所以就不需要使用super().__init__()语句。第11~15行则是把原始文本分割成安单词进行表示,即samples返回的是一个列表,其中的每个元素为一条文本,而第14行则将其切分成单词粒度。
1 def generate_batch(self, data_batch):
2 from allennlp.modules.elmo import batch_to_ids
3 batch_sentence, batch_label = [], []
4 for (sen, label) in data_batch:
5 batch_sentence.append(sen)
6 l = torch.tensor(int(label), dtype=torch.long)
7 batch_label.append(l)
8 batch_sentence = batch_to_ids(batch_sentence)
9 batch_label = torch.tensor(batch_label, dtype=torch.long)
10 return batch_sentence, batch_label在上述代码中,第2行是导入batch_to_ids模块来将原始文本转换成索引序列。第4~7行是遍历小批量数据中的每个样本并构建输入和标签。
接着我们可以通过如下方式进行来进行测试:
1 if __name__ == '__main__':
2 dataloader = MR4ELMo(batch_size=4)
3 train_iter, val_iter = dataloader.load_train_val_test_data(is_train=True)
4 for x, y in train_iter:
5 print(x.shape, y.shape)2. 前向传播
进一步,我们需要ELMo预训练模型来实现文本分类的前向传播过程,示例代码如下所示:
1 from allennlp.modules.token_embedders import ElmoTokenEmbedder
2 class ELMoClassification(nn.Module):
3 def __init__(self, num_classes=10, freeze=True, rep_weights=None):
4 super().__init__()
5 self.elmo_rep = ElmoTokenEmbedder(requires_grad=not freeze,
6 scalar_mix_parameters=rep_weights)
7 self.classifier = nn.Linear(1024, num_classes)
8
9 def forward(self, x, labels=None):
10 features = torch.mean(self.elmo_rep(x), dim=1)
11 logits = self.classifier(features) # [batch_size, num_classes]
12 if labels is not None:
13 loss_fct = nn.CrossEntropyLoss(reduction='mean')
14 loss = loss_fct(logits, labels)
15 return loss, logits
16 else:
17 return logits在上述代码中,第1行是导入ELMo模型中对应的词嵌入表示模型ElmoTokenEmbedder。第5~6行是实例化词嵌入模型,并指定是否冻结预训练模型参数与式(10-6)中的权重值$s_i$,为一个列表包含3个元素,如[0.3,0.4,0.2]。第7行则是实例化一个线性层。第10行是取所有时刻词向量的均值来作为样本的特征表示,输入形状为[batch_size, 1024]。第11~17行则是计算预测值或计算损失值。
进一步,我们可以通过如下方式来进行测试:
1 if __name__ == '__main__':
2 token_ids = torch.randint(0, 100, [2, 6, 50])
3 labels = torch.tensor([0, 1], dtype=torch.long)
4 model = ELMoClassification(num_classes=2, freeze=False)
5 loss, logits = model(token_ids, labels)
6 print(logits.shape)3. 模型训练
整体上模型训练这部分内容在前面已经多次介绍过,各位读者可以直接参见源码,这里就不再赘述。最后模型训练时将会输出类似如下结果:
1 Epochs[1/5]--batch[0/234]--Acc: 0.3438--loss: 0.7039
2 Epochs[1/5]--batch[50/234]--Acc: 0.6562--loss: 0.6665
3 Epochs[1/5]--batch[100/234]--Acc: 0.5938--loss: 0.588
4 Epochs[1/5]--batch[150/234]--Acc: 0.7812--loss: 0.4728
5 Epochs[1/5]--batch[200/234]--Acc: 0.6562--loss: 0.5369
6 Epochs[1/5]--Acc on val 0.781806814629571710.1.5 小结#
在本节内容中,我们首先再次简单回顾了模型迁移的基本概念;然后详细介绍了ELMo模型的基本思想和原理,包括基于字符级的卷积网络和带有残差连接的双向LSTM;然后进一步详细介绍了如何从零实现ELMo模型;最后还介绍了如何使用开源的预训练模型来通过ELMo词向量进行文本分类。在下一节内容中我们将开始接受另外一种全新的网络结构多头注意力机制。
引用#
[1] Han X, Zhang Z, Ding N, et al. Pre-trained models: Past, present and future[J]. AI Open, 2021, 2: 225-250.
[2] Matthew E. Peters, Neumann M, et al. Deep Contextualized Word Representations[C]. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2018, 1:2227–2237.
[3] Melamud O, Goldberger J, Dagan I. context2vec: Learning generic context embedding with bidirectional lstm[C] Proceedings of the 20th SIGNLL conference on computational natural language learning. 2016: 51-61.
[4] McCann B, Bradbury J, Xiong C, et al. Learned in translation: Contextualized word vectors[J]. Advances in neural information processing systems, 2017, 30.
[5] Wieting J, Bansal M, Gimpel K, et al. Charagram: Embedding words and sentences via character n-grams[J]. arXiv preprint, 2016, arXiv:1607.02789.
[6] Bojanowski P, Grave E, Joulin A, et al. Enriching word vectors with subword information[J]. Transactions of the association for computational linguistics, 2017, 5: 135-146.
[7] Neelakantan A, Shankar J, Passos A, et al. Efficient non-parametric estimation of multiple embeddings per word in vector space[J]. arXiv preprint, 2015, arXiv:1504.06654.
[8] Srivastava R K, Greff K, Schmidhuber J. Training very deep networks[J]. Advances in neural information processing systems, 2015, 28.
[9] https://allenai.org/allennlp