8.6 连续型特征变量下决策树实现#
在上一节内容中,我们详细介绍了如何基于ID3与C4.5的原理来一步一步从零开始实现决策树模型,不过由于原始的决策树模型均是针对离散型的特征变量,因此并不能对连续型的特征变量进行建模处理。在这节内容中将采用sklearn库中的做法来对连续型特征进行离散化处理,并以此来实现ID3与C4.5的建模过程。值得一提的是,在sklearn中不管输入的是离散型变量还是连续型变量,都会先对其以同样的方式来进行离散化处理,下面我们也将采用同样的做法来进行处理。
8.6.1 特征离散化实现#
由于在8.5节内容中我们已经详细介绍了对于离散型特征输入的ID3与C4.5的决策树实现过程,因此接下来只需要以之前的代码框架为基础,对其中部分判断逻辑进行修改即可。在实现这部分内容之前,先来介绍如何对特征进行离散化。本节所有实现代码可参见AllBooKCode/Chapter08/C04_id3_continuous.py 文件。
根据8.3.5节内容可知,连续型特征变量的离散化过程可以先对原始特征进行排序处理,然后取所有连续两个值的均值来离散化整个连续型特征变量。在清楚上述特征离散化的原理后,便可以来进一步对其编码实现,示例代码如下:
1 def _get_feature_values(self, data):
2 n_features = data.shape[1]
3 feature_values = {}
4 for i in range(n_features):
5 x_feature = sorted(set(data[:, i])) # 去重与排序
6 tmp_values = [x_feature[0]] # 左边插入最小值
7 for j in range(1, len(x_feature)):
8 tmp_values.append(round((x_feature[j - 1] + x_feature[j]) / 2, 4))
9 tmp_values.append(x_feature[-1]) # 右边插入最大值
10 feature_values[i] = tmp_values
11 return feature_values在上述代码中,第2行是得到特征的维度数量。第4~5行是遍历每一列特征维度并进行排序以及去重处理。第7~8行是计算得到两两相邻的特征值之间的平均值作为离散特征。第6、9行是为了方便后续决策树的实现,所以在离散化特征的两个端点分别加入了原始特征中的最小值和最大值。
最终,通过上述方法便可以得到离散化后的数据特征。例如对于如下测试数据来说
1 x = np.array([[3, 4, 5, 6, 7],
2 [2, 2, 3, 5, 8],
3 [3, 3, 8, 8, 9.]])
4 x = _get_feature_values(x)
5 print(x)
6 {0: [2.0, 2.5, 3.0], 1: [2.0, 2.5, 3.5, 4.0], 2: [3.0, 4.0, 6.5, 8.0],
7 3: [5.0, 5.5, 7.0, 8.0], 4: [7.0, 7.5, 8.5, 9.0]}在上述结果中,第6~7行便是原始输入特征离散化后的结果,其中key表示特征维度的ID,value表示该特征维度对应的离散化特征取值。
8.6.2 信息熵与条件熵实现#
在完成特征离散化的编码工作后,下一步便可以开始对第8.5.2中实现的代码进行修改以满足离散化特征的需求,信息熵计算代码的修改部分如下:
1 def _compute_entropy(self, y_class):
2 y_unique = np.unique(y_class)
3 if y_unique.shape[0] == 1: # 只有一个类别
4 return 0. # 熵为0
5 ety = 0.
6 for i in range(len(y_unique)): # 取每个类别
7 p = np.sum(np.abs(y_class - y_unique[i]) < 0.0001) / len(y_class)
8 ety += p * np.log2(p)
9 return -ety在上述代码中,第1行是定义一个方法来计算信息熵,主要用于ID3和C4.5中计算样本的信息熵,以及C4.5中特征的信息熵。第2行是计算得到当前输入有多少种类别(或特征取值)。第3~4行则是判断如果只有一个类别则信息熵为0。第6~8行是分别遍历每一个类别,然后计算信息熵。值得注意的是,因为同时要计算特征维度的信息熵,而特征是浮点型所以一般不会用==来判断两者是否相等。
进一步,可以编码完成条件熵的计算过程,示例代码如下:
1 def _compute_condition_entropy(self, X_feature, id, y_class):
2 f_unique = self.feature_values[id]
3 result = 0.
4 for i in range(len(f_unique) - 1): # 取每个特征类别
5 index_x = (f_unique[i] <= X_feature) & (X_feature <= f_unique[i + 1])
6 # 离散化后的特征则判断当前特征值是否存在于某个区间
7 p = np.sum(index_x) / len(y_class) # 取索引对应的标签
8 ety = self._compute_entropy(y_class[index_x]) # 计算标签对应的信息熵
9 result += p * ety # 计算条件熵
10 return result在上述代码中,第1行X_feature表示数据集中的某一列特征,id表示当前特征列对应的索引,y_class表示样本的类别标签。第2行是根据特征维度的id作为key从8.6.1节中离散化的结果中取到相应特征维度的取值情况。第4行开始是遍历每一个特征取值。第5行是根据取值区间判断结果来得到满足条件的特征值对应的索引。第7~9行是先计算样本对应的信息熵,然后再计算条件熵。
值得一提的是,因为特征被离散化后便形成了一个个的区间范围, 因此决策树在进行特征分裂时判断的其实是当前特征值属于哪个取值区间,然后再选择对应的节点。例如对于第8.3.5节中的示例来说,离散化结果便是将原始特征划分成了[0.35,0.65],[0.65,0.85],[0.85,1.05][1.05,1.65],[1.65,2.65],[2.65,3.85]这6个区间。此后对于任意新输入的特征$x$,决策树在预测时都是先判断其属于哪个区间,然后再进入到区间所对应的子节点中。
8.6.3 决策树构建实现#
在实现完信息熵和条件熵的计算过程后,下面再来封装一个方法来根据指定参数返回信息增益或者是信息增益比的结果来作为节点划分时的标准,示例代码如下:
1 def _split_criterion(self, ety, X_feature, id, y_class):
2 c_ety = self._compute_condition_entropy(X_feature, id, y_class) # 计算每个特征下的条件熵
3 info_gains = ety - c_ety # 计算信息增益
4 if self.criterion == "id3":
5 return info_gains
6 elif self.criterion == "c45":
7 f_ety = self._compute_entropy(X_feature)
8 return info_gains / f_ety
9 else:
10 raise ValueError(f"划分标准 self.criterion = {self.criterion}只能是 id3 和 c45 其中之一!")在上述代码中,第1行的4个参数分别是传入的信息熵、对应的特征列、特征ID和样本标签。第2行是计算每个特征下的条件熵。第3行是计算对应特征下的信息增益。第4~8行是根据参数来返回对应的划分指标,其中第7行是计算特征对应的信息熵;第10行则是进行错误提示。
在做完前面的整个铺垫过程后,下面就可以正式的来递归构建生成决策树了。由于这部分代码整体上同第8.5.3节中对应部分的内容差别不大,因此我们下面就只介绍两者的差异之处,示例代码如下:
1 def _build_tree(self, data, f_ids):
2 # 此处省略 ......
3 node.feature_id = best_feature_id
4 feature_values = self.feature_values[best_feature_id] # 得到当前特征离散化后特征的取值情况
5 candidate_ids = copy.copy(f_ids)
6 candidate_ids.remove(best_feature_id) # 当前节点划分后的剩余特征集
7 for i in range(len(feature_values) - 1): # 依次遍历特征离散化后的每个取值情况
8 v = data[:, best_feature_id]
9 c = (feature_values[i] <= v) & (v <= feature_values[i + 1])
10 index = np.array([i for i in range(len(c)) if c[i] == True]) # 获取对应的索引
11 if len(index) == 0: # 如果当前特征取值范围没有样本,则继续
12 continue
13 node.children[str(feature_values[i + 1])] = self._build_tree(data[index], candidate_ids)
14 return node在上述代码中,第4行是取最佳划分特征中特征的取值情况。第5~6行是从一开始传入的特征列表f_ids中去除此时选中的最佳特征,而之所以要先复制是因为后续要依次遍历最佳特征中的每个特征取值并递归的构建决策树(第13行),而f_ids是一个列表,传入函数_build_tree时本质上是传入的地址,这就会导致每次递归操作都会改变其中的值,因此需要先进行复制。第7~13行是依次遍历特征离散化后的每个取值情况,然后根据当前特征维度的取值,来取对应的样本索引,并递归的进行节点划分;同时,由于离散化的特征值是浮点型,所以第13行将key转换成字符串来进行保存。
到此,对于整个决策树的递归构建过程就介绍完了,进一步可以通过如下方式来进行决策树的拟合,示例代码如下:
1 def fit(self, X, y):
2 self._y = np.array(y).reshape(-1)
3 self.n_classes = len(np.bincount(y)) # 得到当前数据集的类别数量
4 feature_ids = [i for i in range(X.shape[1])] # 得到特征的序号
5 self.feature_values = self._get_feature_values(X)
6 self._X = np.hstack(([X, np.arange(len(X)).reshape(-1, 1)]))
7 self._build_tree(self._X, feature_ids) # 递归构建决策树
8 self._pruning_leaf()在上述代码中,第1行X,y便是训练时所用到的数据和标签,需要注意的是X的形状必须为[n_samples, n_features],y的形状必须为[n_samples,]。第3行是得到当前数据集的类别数量。第4行是得到特征的序号。第5行是获取得到每一列特征离散化后的结果。第6行是在X的右侧追加一列作为每个样本的索引。第7行是开始递归构建决策树。第8行是进行剪枝步骤,同第8.5.8节内容一样不再赘述。
在完成决策树构建的编码过程后,便可以通过一个测试数据来查看拟合后的结果。例如对于表8-1中的示例数据来说,首先需要将其中最后一个特征也转换成数值型,并且0、1和2分别表示学历等级中的D、S和T,如表8-6所示。
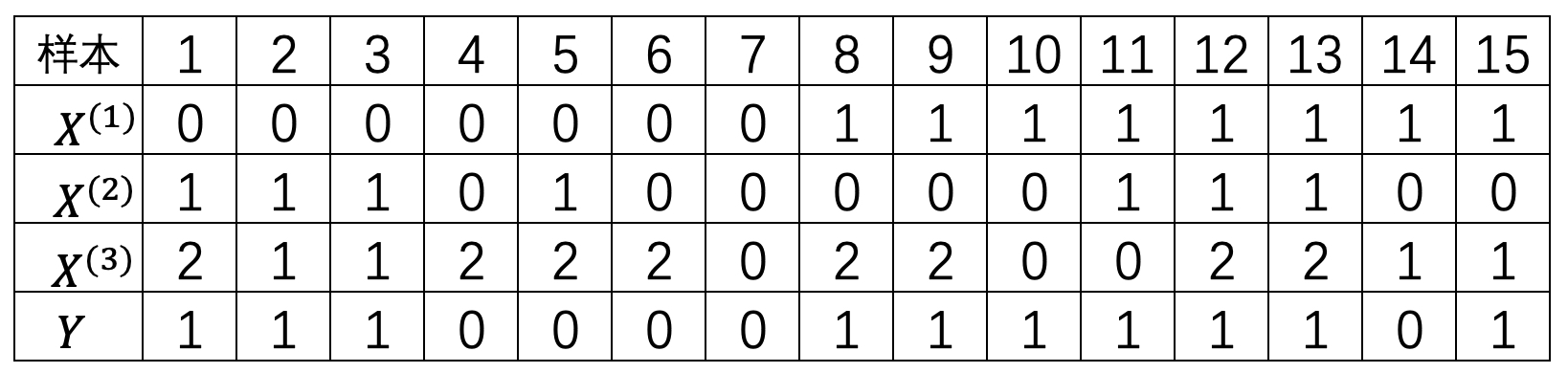
进一步,可以通过如下代码来进行模型拟合:
1 def load_simple_data():
2 x = np.array([[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1],
3 [1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0],
4 [2, 1, 1, 2, 2, 2, 0, 2, 2, 0, 0, 2, 2, 1, 1]]).transpose()
5 y = np.array([1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1])
6 return x, y
7
8 def test_decision_tree():
9 x, y = load_simple_data()
10 dt = DecisionTree(criterion='c45')
11 dt.fit(x, y)
12 dt.level_order()其拟合后决策树的部分打印信息为
1 feature_values = {0: [0, 0.5, 1], 1: [0, 0.5, 1], 2: [0, 0.5, 1.5, 2]}
2
3 ======层次遍历结果为=======
4 <==========第1层的节点为==========>
5 当前节点所有样本的索引([ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14])
6 当前节点每个类别的样本数([ 5 10])
7 当前节点状态时划分特征ID(0)
8 当前节点对应的孩子为(dict_keys(['0.5', '1']))
9
10 <==========第2层的节点为==========>
11 当前节点所有样本的索引([0 1 2 3 4 5 6])
12 当前节点每个类别的样本数([4 3])
13 当前节点状态时划分特征ID(1)
14 当前节点对应的孩子为(dict_keys(['0.5', '1']))
15
16 当前节点所有样本的索引([ 7 8 9 10 11 12 13 14])
17 当前节点每个类别的样本数([1 7])
18 当前节点状态时划分特征ID(2)
19 当前节点对应的孩子为(dict_keys(['0.5', '1.5', '2']))
21 ......根据打印出来的信息,便可以得到如图8-12所示的决策树。
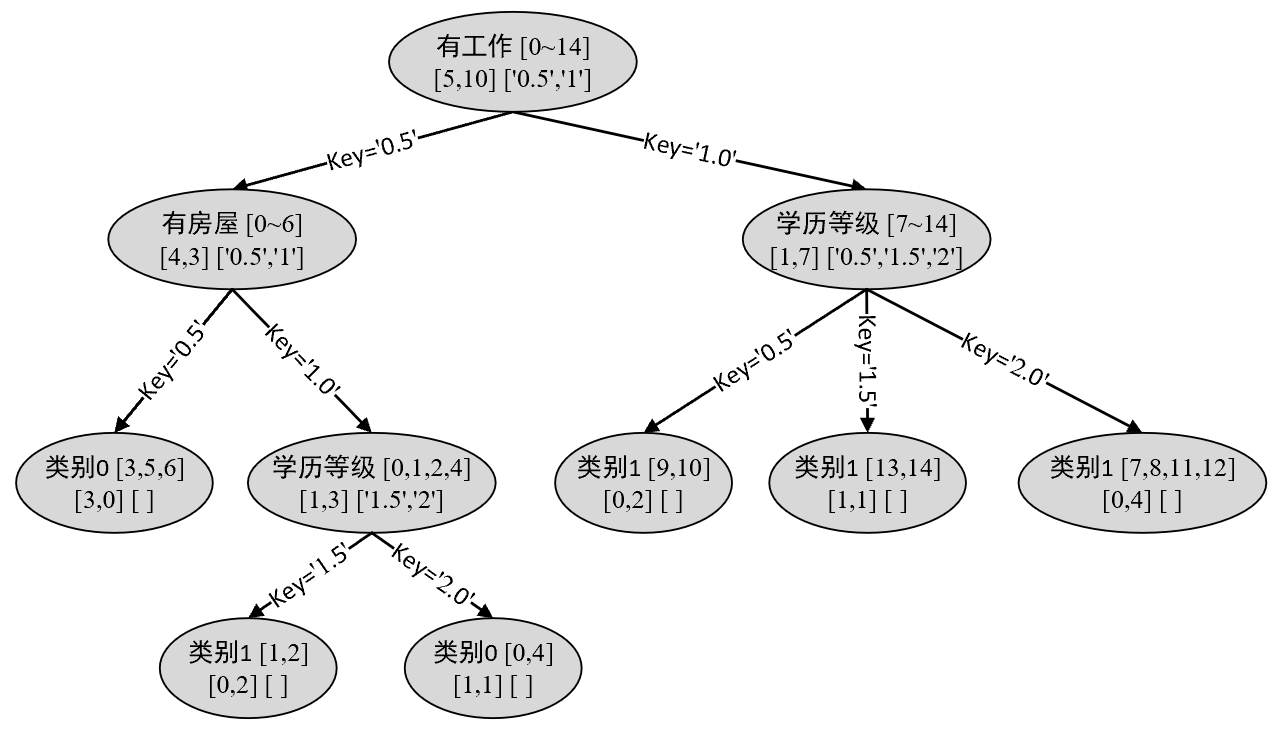
在图8-12中,对于任意节点来说第1行右边的数字表示当前节点中的样本索引;第2行左边的数字表示当前节点中每个类别样本的数量,右边表示离散化后的特征取值。
8.6.4 样本预测实现#
在完成决策树的拟合过程后,下一步便是实现决策树的预测过程。总的来讲,新样本的预测思路为:从根节点开始,根据当前节点的划分维度取测试样本中对应的特征维度,然后再根据特征维度的取值来判断其属于哪个离散化的特征区间,并进入到当前节点的孩子节点中;然后再迭代进行这一步骤,直到进入到叶子节点或当前节点的孩子节点中不存在满足特征取值的节点时停止,此时取当前节点对应的类别作为该测试样本的类别即可。
例如对于图8-12中的决策树来说,现在需要预测新样本x=[0,1,1]的类别,那么首先需要根据训练集得到每个特征维度离散化的取值情况:
feature_values = {0: [0, 0.5, 1], 1: [0, 0.5, 1], 2: [0, 0.5, 1.5, 2]}根据图8-12中的决策树可知,对于根节点来说其特征划分ID为0,由于x[0] < 0.5因此进入到根节点key='0.5'对应的孩子节点;此时当前节点的特征划分ID为1,且0.5 < x[1] <=1,因此进入到当前节点key='1.0'对应的孩子节点;此时当前节点的划分ID为2,且0.5 < x[2] <= 1.5,因此进入到当前节点key='1.5'对应的孩子节点中;此时当前节点为叶子节点,因此返回该节点对应的类别1作为预测样本x=[0,1,1]的类别。
具体地,我们先来实现一个样本的预测过程,实现代码如下:
1 def _predict_one_sample(self, x):
2 current_node = self.root
3 while True:
4 if len(current_node.children) < 1: # 当前节点为叶子节点
5 return current_node.values
6 current_feature_id = current_node.feature_id
7 current_feature = x[current_feature_id]
8 current_feature_values = self.feature_values[current_feature_id]
9 exist_child = False
10 for i in range(len(current_feature_values) - 1):
11 if current_feature_values[i] <= current_feature <= current_feature_values[i + 1]:
12 exist_child = True
13 if str(current_feature_values[i + 1]) not in current_node.children:
14 return current_node.values
15 current_node = current_node.children[str(current_feature_values[i + 1])]
16 if not exist_child:
17 return current_node.values在上述代码中,第2行是初始化根节点为当前节点;第3行开始则是按照上述思路进行遍历。第4~5行是判断如果当前节点为叶子节点则直接返回当前节点。第6~8行是根据当前样本在某个维度的特征取值去取对应维度的离散化特征区间。第10行是开始遍历离散化特征的每个取值区间。第11行是判断当前特征的取值是否存在于其中一个离散化取值区间。第13行是用来解决当训练集不充分时当前节点的孩子节点不存在的问题,例如对于图8-12中的决策树来说,样本[0,1,0]在查找最后一个特征维度时,key='0.5'对应的孩子节点就不存在。第15行则是循环进入到当前节点的孩子节点中进行遍历。第16~17同样是解决当训练集不充分时当前节点的孩子节点不存在的问题。
到此,对于连续型特征变量的ID3和C4.5决策树实现就介绍完了,其中predict()方法和剪枝过程的实现并没有发生改变所以这里就不再赘述。
8.6.5 使用示例#
在实现完整个连续型特征变量的ID3和C4.5决策树的编码过程后,最后再通过一个真实的数据集来对代码的准确率进行测试,示例代码如下:
1 def test_iris_classification():
2 x, y = load_iris(return_X_y=True)
3 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=2022)
4 dt = DecisionTree(criterion='c45')
5 dt.fit(x_train, y_train)
6 y_pred = dt.predict(x_test)
7 logging.info(f"DecisionTree 准确率:{accuracy_score(y_test, y_pred)}")
8
9 model = DecisionTreeClassifier(criterion='entropy')
10 model.fit(x_train, y_train)
11 y_pred = model.predict(x_test)
12 logging.info(f"DecisionTreeClassifier 准确率:{accuracy_score(y_test, y_pred)}")在上述代码中,我们以机器学习中最常见的iris数据集进行了示例,在代码运行结束后将会看到类似如下的训练结果:
1 DecisionTree 准确率:0.9333
2 DecisionTreeClassifier 准确率:0.9333可以发现,此时两者的准确率并没有任何差别。但是我们在设置不同的random_state(上述第3行代码)后,发现有些情况下的结果会远差于sklearn中的DecisionTreeClassifier方法,当然这其实也是预料之中的情况。因为我们在这里只是为了向大家介绍决策树实现的整体思路,所以很多值得优化的地方并没有进行,不过这也并不影响我们对于决策树实现的整体把握。
8.6.6 小结#
在本章内容中,我们首先介绍了决策树中连续型特征离散化的一种常用方法以及实现过程;然后分别介绍了信息熵、条件熵、决策树的构建以及样本预测的实现过程;最后,我们还以iris数据集为例对比了DecisionTree与sklearn中DecisionTreeClassifier模型的测试结果,虽然DecisionTree整体上实现了ID3与C4.5决策树原理,但是仍旧存在一定的优化空间。