10.19 百川大模型实现#
在「第10.18节 百川大模型使用教程:调用、体验与应用场景」内容中我们详细介绍了Baichuan2模型的推理使用方法以及如何根据我们自己的需要来对基座模型进行微调。在本节内容中我们将进一步详细介绍Baichuan2模型的内部实现细节。由于百川大模型是基于Transformers框架所实现,因此在正式介绍百川大模型的实现原理之前我们先来看一下Transformers中对于基于Transformer解码器的模型在解码时的Key-Value缓存机制。
10.19.1 解码缓存原理#
根据「第10.3节 Transformer结构:编码器解码器整体架构解析」内容可知,解码器在解码预测每个时刻时都涉及计算Query与Key之间的注意力权重,并通过对Value的加权求和来生成输出。为了避免在生成序列时的重复计算,特别是在处理长序列时,缓存机制允许解码器存储并复用先前计算的Key和Value。这样一来,相同的查询Query在不同时间步中便能够直接使用之前计算得到的结果,在减少了计算复杂度同时也提高了序列生成过程的速度。
现在假定我们已经训练得到了一个基于Transformer解码器的生成式模型,且模型的原始输入为一个长度为3的序列,那么它在第4个时刻的解码输出过程便可以通过图10-64来进行表示。
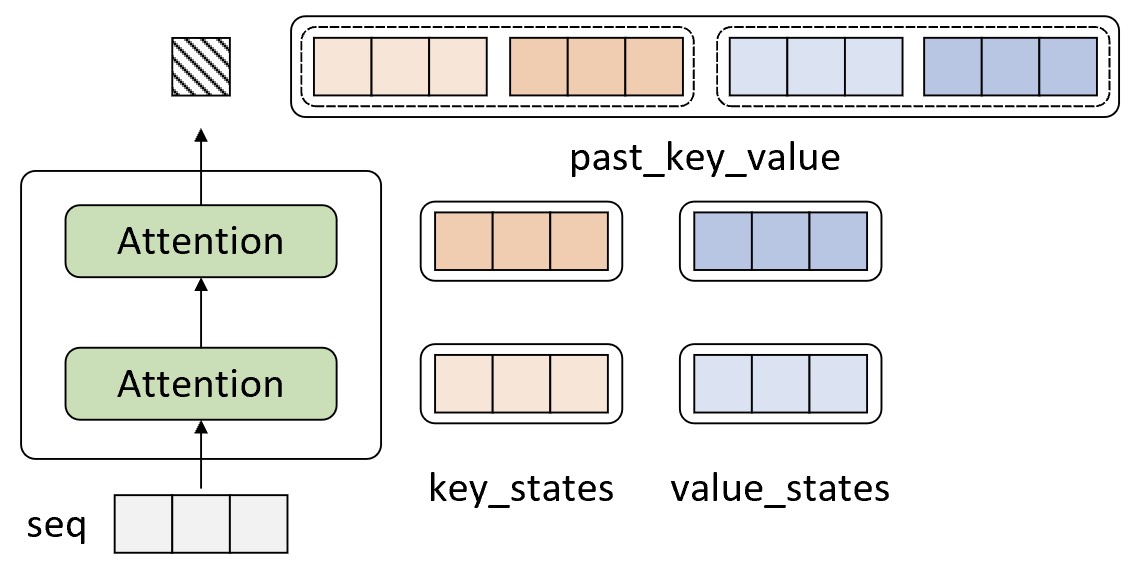
在图10-64中,输入序列在经过两个注意力层以后预测得到了第4个时刻的输出。如果是传统的解码方式,那么在解码第5个时刻时将会把原始的输入序列同第4个时刻的输出拼接在一起作为新的输入进行解码预测,后续过程以此类推。可以发现,在这种解码方式中对第$t$个时刻进行解码输出时,前面第$t-1$个时刻的输入都是重复的,而这就导致在自注意力的计算过程中前面第$t-1$个时刻的计算是重复的。
因此,在基于缓存机制的解码过程中,解码器在对第$t$个时刻进行解码时会直接使用前$t-1$个时刻缓存得到的key_states和value_states来计算第$t$时刻的输出。例如在图10-64所示的过程中,当解码器对第4个时刻进行解码时将会缓存此时计算得到的key_states和values_states并通过一个元组past_key_value进行表示。进一步,解码器在对第5个时刻进行解码时可以通过图10-65所示的过程表示。
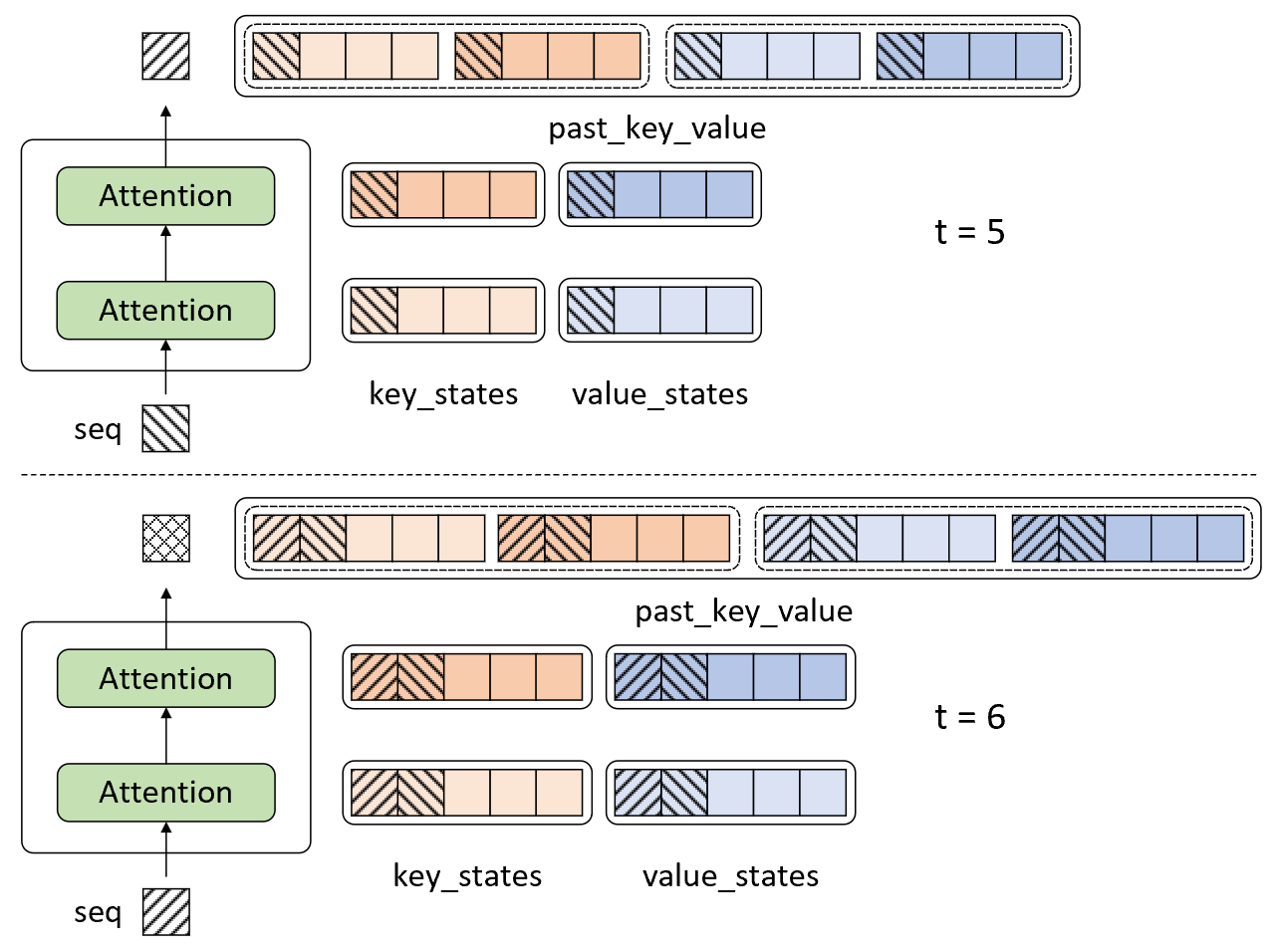
如图10-65所示,解码器在对第5个时刻解码时其输入只有第4个时刻的输出,并且会将当前时刻输入经过线性变换计算得到的key_states和values_states同之前缓存的状态拼接起来得到新的key_states和values_states,以此同query_states计算得到第5个时刻的注意力输出。最后,对于第6个时刻的解码输出过程各位读者可以根据图示自行理解,这里就不再赘述。
在这里,我们还可以通过如下示例代码来验证Baichuan2模型中解码器的输出结果:
1 def test_BaichuanModel():
2 config = BaichuanConfig.from_pretrained('./Baichuan2_7B_Chat')
3 model = BaichuanModel(config)
4 past_key_values = None
5 inp = torch.randint(0, 100, [1, 3])
6 for i in range(4,7):
7 print(f"第{i}个时刻输出: ")
8 result = model(inp, past_key_values=past_key_values)
9 print(f"last_hidden_state的形状: {result.last_hidden_state.shape}")
10 past_key_values = result.past_key_values
11 print(f"len(past_key_values): {len(past_key_values)}")
12 print(f"len(past_key_values[0]: {len(past_key_values[0])}")
13 print(f"past_key_values[0][0].shape: {past_key_values[0][0].shape}")
14 inp = torch.randint(0, 100, [1, 1])在上述代码中,第2~3行是根据本地配置文件实例化一个BaichuanModel类对象。第7~14行便是模拟解码器的解码输出过程。上述代码运行结束以后便会得到如下输出内容。
1 第4个时刻输出:
2 last_hidden_state的形状: torch.Size([1, 3, 4096])
3 len(past_key_values): 32
4 len(past_key_values[0]: 2
5 past_key_values[0][0].shape: torch.Size([1, 32, 3, 4096])
6 第5个时刻输出:
7 last_hidden_state的形状: torch.Size([1, 1, 4096])
8 len(past_key_values): 32
9 len(past_key_values[0]: 2
10 past_key_values[0][0].shape: torch.Size([1, 32, 4, 4096])
11 第6个时刻输出:
12 last_hidden_state的形状: torch.Size([1, 1, 4096])
13 len(past_key_values): 32
14 len(past_key_values[0]: 2
15 past_key_values[0][0].shape: torch.Size([1, 32, 5, 4096])在上述输出结果中,第2行表示对原始输入编码结果的输出,形状为[batch_size, seq_len, hidden_size],后面再通过一个分类层便可以得到第4个时刻的预测输出。第3~5行分别表示past_key_values缓存了32个注意力层中每一层的键值对,且形状为[batch_size, num_heads, seq_len, hidden_size]。第7~10行分别是第5个时刻的输出,以及past_key_values缓存结果,可以发现对于每一层中的键值序列其长度已经由3增加到了4,因为多了本层键值对的缓存。上述完整示例代码可参见Code/Chapter10/C07_BaiChuan2/main.py文件。这里需要提醒各位读者的是,当你们在学习运行上述示例代码时,可以把配置文件中的维度、层数、多头个数等设置小一点,这样就能快速验证结果。
10.19.2 解码层实现#
在介绍完Key-Value缓存机制以后我们再来看如何一步一步实现Baichuan2中的解码层。根据图10-62所示,整个解码层主要由自注意力模块和门控多层感知机所构成,下面分别进行介绍。这里需要提醒各位读者的是,以下各模块的类名对应的便是图10-62中的粗体字,阅读代码的时候结合图10-62的结构会更清晰。同时,为了内容排版的整洁性,我们去掉部分无关紧要的代码,但这并不影响我们对于Baichuan2模型整体实现的把握。更加详细的逐行注释内容可以参见本书所维护的Baichuan2模型代码[1],详见Code/Chapter10/C07_BaiChuan2/Baichuan2_7B_Chat目录。
1. 自注意力实现
Baichuan2模型中自注意力机制的实现过程同第10.3.3节中Transformer里的注意力机制实现过程类似,区别在于此处考虑了Key-Value缓存和旋转位置编码。首先,我们需要定一个Attention类来完成相关成员变量的初始化工作,示例代码如下所示:
1 class Attention(nn.Module):
2 def __init__(self, config: BaichuanConfig):
3 super().__init__()
4 self.config = config
5 self.hidden_size = config.hidden_size
6 self.num_heads = config.num_attention_heads
7 self.head_dim = self.hidden_size // self.num_heads
8 self.max_position_embeddings = config.max_position_embeddings
9 if (self.head_dim * self.num_heads) != self.hidden_size:
10 raise ValueError(f"hidden_size must be divisible by num_heads")
11 self.W_pack = nn.Linear(self.hidden_size, 3 * self.hidden_size)
12 self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size)
13 self.rotary_emb = RotaryEmbedding(self.head_dim,
14 max_position_embeddings=self.max_position_embeddings)在上述代码中,第2行config是传入的实例化模型配置类对象。第4~10行是初始化多头注意力中的相关模型参数,并判断模型维度是否能被多头个数整除。第11行是同时初始化自注意力机制中Query、Key和Value对应的3个线性变换。第12行是将多头注意力输出进行线性变换,原理示意可参见图10-10部分的内容。第13~14行是实例化一个旋转编码实例化对象。
进一步,整个注意力机制的前向传播实现过程如下所示:
1 def forward(self, hidden_states, attention_mask = None, position_ids = None,
2 past_key_value = None,output_attentions = False, use_cache = False):
3 bsz, q_len, _ = hidden_states.size()
4 proj = self.W_pack(hidden_states)
5 proj = proj.unflatten(-1,(3,self.hidden_size)).unsqueeze(0).transpose(0,-2).squeeze(-2)
6 query_states = proj[0].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
7 key_states = proj[1].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
8 value_states = proj[2].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
9 kv_seq_len = key_states.shape[-2]
10 if past_key_value is not None:
11 kv_seq_len += past_key_value[0].shape[-2]
12 cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
13 query_states, key_states = apply_rotary_pos_emb(query_states,
14 key_states, cos, sin, position_ids)
15 if past_key_value is not None:
16 key_states = torch.cat([past_key_value[0], key_states], dim=2)
17 value_states = torch.cat([past_key_value[1], value_states], dim=2)
18 past_key_value = (key_states, value_states) if use_cache else None
19 attn_output = F.scaled_dot_product_attention(query_states, key_states, value_states,
20 attn_mask=attention_mask)
21 attn_output = attn_output.transpose(1, 2)
22 attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
23 attn_output = self.o_proj(attn_output)
24 if not output_attentions:
25 attn_weights = None
26 return attn_output, attn_weights, past_key_value在上述代码中,第1行hidden_states为解码层对应的输入,形状为[batch_size, seq_len, hidden_size];attention_mask是注意力矩阵,用于在训练时掩盖当前时刻之后的信息,形状为[batch_size, 1, query_len, key_len];position_ids是输入序列的位置编号,形状为[batch_size, seq_len]。第2行中past_key_value仅在推理时会用到,用来传入截止上一个时刻所有缓存的key_states和value_states状态,如图10-65所示;output_attentions为是否返回注意力权重默认为False,不过事实上这里也不支持返回注意力权重矩阵,因为模型中使用到的两种注意力计算函数返回结果都不包含注意力权重矩阵;use_cache表示是否使用Key-Value缓存机制,在整个Baichuan2模型中默认使用。第3~8行是根据解码层对应的输入整体计算得到3个线性变换后的结果,然后再分别得到query_states、key_states和value_states,且形状均为[batch_size, num_heads, seq_len, head_dim]。第10~11是计算得到使用Key-Value缓存机制时,拼接后key_states的序列长度。第12~14行是旋转编码的前向传播计算过程。第15~18行则是使用缓存机制时将历史状态和当前状态拼接的过程,并且同时将拼接后的结果继续缓存以在下一个时刻解码时进行使用。第19~23行则是计算得到多头注意力的输出结果,线性变换后attn_output的形状为 [batch_size, seq_len, hidden_size]。第24~6行是返回最后计算得到的结果。
2. 门控感知机实现
根据图10-62可知,基于门控单元的多层感知机类似于通过一个遗忘门来对输入信息进行筛选过滤,具体地其实现过程如下所示:
1 class MLP(nn.Module):
2 def __init__(self, hidden_size, intermediate_size, hidden_act):
3 super().__init__()
4 self.gate_proj = nn.Linear(hidden_size, intermediate_size)
5 self.down_proj = nn.Linear(intermediate_size, hidden_size)
6 self.up_proj = nn.Linear(hidden_size, intermediate_size)
7 self.act_fn = ACT2FN[hidden_act]
8
9 def forward(self, x):
10 f_gate = self.act_fn(self.gate_proj(x))
11 return self.down_proj(f_gate * self.up_proj(x))在上述代码中,第2行intermediate_size是多层感知机中间层对应的维度,Baichuan2-7B中为11008;hidden_act表示指定遗忘门中所使用的激活函数。第4~6行便是实例化3个线性变换类对象。第7行是实化遗忘门所使用的激活函数,Baichuan2中默认使用的是$\text{silu}$激活函数,如式(10-17)所示。
第10~11行是分别计算得到遗忘门和返回多层感知机的输出,形状同hidden_size一致,为[batch_size, seq_len, hidden_size]。
3. 解码层实现
根据图10-62可知,在完成注意力层和多层感知机实现以后便可以构造得到整个解码层。首先,定义解码层对应的初始化方法,示例代码如下所示:
1 class DecoderLayer(nn.Module):
2 def __init__(self, config: BaichuanConfig):
3 super().__init__()
4 self.hidden_size = config.hidden_size
5 self.self_attn = Attention(config=config)
6 self.mlp = MLP(hidden_size=self.hidden_size, hidden_act=config.hidden_act,
7 intermediate_size=config.intermediate_size)
8 self.input_layernorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
9 self.post_attn_layernorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)在上述代码中,第5~6行分别是实例化得到一个多头注意力层和多层感知机层。第8~9行是分别初始化一个均方根归一化层用于对注意力层的输入和多层感知机层的输入进行归一化。
进一步,解码层的前向传播计算过程如下所示:
1 def forward(self,hidden_states, attention_mask, position_ids,
2 past_key_value, output_attentions, use_cache):
3 residual = hidden_states
4 hidden_states = self.input_layernorm(hidden_states)
5 hidden_states, self_attn_weights, present_key_value = self.self_attn(
6 hidden_states=hidden_states, attention_mask=attention_mask,
7 position_ids=position_ids, past_key_value=past_key_value,
8 output_attentions=output_attentions, use_cache=use_cache)
9 hidden_states = residual + hidden_states
10 residual = hidden_states
11 hidden_states = self.post_attn_layernorm(hidden_states)
12 hidden_states = self.mlp(hidden_states)
13 hidden_states = residual + hidden_states
14 outputs = (hidden_states,)
15 if output_attentions:
16 outputs += (self_attn_weights,)
17 if use_cache:
18 outputs += (present_key_value,)
19 return outputs在上述代码中,第4~9行是先对输入进行归一化处理,然后计算得到多头注意力的输出结果,并进行残差连接计算。第11~13行则是对多层感知机的输入进行归一化并计算得到多层感知机的输出并同时完成残差连接的计算,输出结果的形状为[batch_size, seq_len, hidden_size]。第14~19行是根据条件返回对应的输出结果。
10.19.3 语言模型实现#
根据图10-62可知,在完成解码层的实现以后我们进一步便可以实现解码器和整个Baichuan2语言模型。
1. 解码器实现
对于解码器来说,它是由多个解码层堆叠所构成,同时也对position_ids、attention_mask和output_attentions等参数的默认值进行了初始化。首先,定义解码器对应的初始化方法,示例代码如下所示:
1 class BaichuanModel(BaichuanPreTrainedModel):
2 def __init__(self, config: BaichuanConfig):
3 super().__init__(config)
4 self.padding_idx = config.pad_token_id
5 self.vocab_size = config.vocab_size
6 self.embed_tokens = nn.Embedding(config.vocab_size,
7 config.hidden_size, self.padding_idx)
8 layers = [DecoderLayer(config) for _ in range(config.num_hidden_layers)]
9 self.layers = nn.ModuleList(layers)
10 self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)在上述代码中,第6~7行是实例化一个嵌入层对象,同时还指定了填充值对应的索引。第8~9行是根据超参数num_hidden_layers实例化得到多层解码层对象并存放到ModuleList中。
进一步,解码器的前向传播计算过程如下所示:
1 def forward(self, input_ids = None, attention_mask = None, position_ids = None,
2 past_key_values = None, inputs_embeds = None, use_cache = None,
3 output_attentions = None, output_hidden_states = None, return_dict = None):
4 batch_size, seq_length = input_ids.shape
5 seq_length_with_past, past_key_values_length = seq_length, 0
6 if past_key_values is not None:
7 past_key_values_length = past_key_values[0][0].shape[2]
8 seq_length_with_past += past_key_values_length
9 if position_ids is None:
10 device = input_ids.device if input_ids is not None else inputs_embeds.device
11 position_ids = torch.arange(past_key_values_length,
12 seq_length + past_key_values_length, dtype=torch.long, device=device)
13 position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
14 else:
15 position_ids = position_ids.view(-1, seq_length).long()
16 if inputs_embeds is None:
17 inputs_embeds = self.embed_tokens(input_ids)
18 if attention_mask is None:
19 attention_mask = torch.ones((batch_size, seq_length_with_past),
20 dtype=torch.bool, device=inputs_embeds.device)
21 attention_mask = self._prepare_decoder_attention_mask(attention_mask,
22 (batch_size, seq_length), inputs_embeds, past_key_values_length)在上述代码中,第1行input_ids为原始的序列索引编号,形状为[batch_size, seq_len];attention_mask和position_ids分别为注意力掩码和序列的位置索引编号,默认为None。第2行past_key_values为一个元组,用于保存所有注意力层对应的key_states和value_states,初始时为None;inputs_embeds为输入序列的嵌入编码形式,形状为[batch_size, seq_len, hidden_size],如果该值不为None那么input_ids将被忽略;use_cache表示是否使用缓存机制,在推理中默认使用。第4~8行是取上一时刻中key_states的长度以及计算与当前时刻key_states拼接后的长度。第9~15行是构造当前序列对应的位置顺序,需要注意的是position_ids的起始位置为 past_key_values_length,也就是说如果传入past_key_values,那么past_key_values_length的起始值为上一个时刻key_states序列的长度。例如,如果past_key_values_length = 5且seq_length = 4, 则position_ids是[[5,6,7,8]]。第16~17行是输入序列进行嵌入处理。第18~21行构造注意力掩码,当训练时形状为[batch_size, 1, seq_len, seq_len],推理时为[1, 1, 1, seq_length_with_past]。
1 hidden_states = inputs_embeds
2 all_hidden_states = () if output_hidden_states else None
3 all_self_attns = () if output_attentions else None
4 next_decoder_cache = () if use_cache else None
5 for idx, decoder_layer in enumerate(self.layers):
6 if output_hidden_states:
7 all_hidden_states += (hidden_states,)
8 past_key_value = past_key_values[idx] if past_key_values is not None else None
9 layer_outputs = decoder_layer(hidden_states, attention_mask=attention_mask,
10 position_ids=position_ids,past_key_value=past_key_value,
11 output_attentions=output_attentions, use_cache=use_cache)
12 hidden_states = layer_outputs[0]
13 if use_cache:
14 next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
15 if output_attentions:
16 all_self_attns += (layer_outputs[1],)
17 hidden_states = self.norm(hidden_states)
18 if output_hidden_states:
19 all_hidden_states += (hidden_states,)
20 next_cache = next_decoder_cache if use_cache else None
21 if not return_dict:
22 return tuple(v for v in [hidden_states, next_cache,
23 all_hidden_states, all_self_attns] if v is not None)
24 return BaseModelOutputWithPast(last_hidden_state=hidden_states,attentions=all_self_attns,
25 hidden_states=all_hidden_states, past_key_values=next_cache)在上述代码中,第2~4行是根据条件初始化返回值。第5~16行则是多层注意力机制的前向传播计算过程,其中第8行是取对应层的缓存key_states和value_states,第9~11行计算每一层多头注意力的输出,第12行是取每一层注意力的输出结果形状为[batch_size, seq_len, hidden_size],第13~14行是缓存每一层多头注意力计算得到的key_states和value_states。第17行是对多层注意力的输出结果进行归一化,输出结果形状为[batch_size, seq_len, hidden_size]。第21~25行是根据条件返回对应形式的结果,默认情况下返回的是BaseModelOutputWithPast形式的结果。
2. 语言模型实现
在完成解码器的实现过程以后,我们只需要在解码器的输出之上再添加一个分类数等于词表大小的分类层即可实现语言模型,示例代码如下所示:
1 class BaichuanForCausalLM(BaichuanPreTrainedModel):
2 def __init__(self, config, *model_args, **model_kwargs):
3 super().__init__(config, *model_args, **model_kwargs)
4 self.model = BaichuanModel(config)
5 self.lm_head = NormHead(config.hidden_size, config.vocab_size, bias=False)
6
7 def forward(self, input_ids = None, attention_mask = None, position_ids = None,
8 past_key_values = None, inputs_embeds = None, labels = None, use_cache = None,
9 output_attentions = None, output_hidden_states = None, return_dict = None):
10 outputs = self.model(input_ids, attention_mask, position_ids, past_key_values,
11 inputs_embeds, use_cache, output_attentions, output_hidden_states, return_dict)
12 hidden_states = outputs[0]
13 logits, loss = self.lm_head(hidden_states), None
14 if labels is not None:
15 shift_logits = logits[..., :-1, :].contiguous()
16 shift_labels = labels[..., 1:].contiguous()
17 loss_fct = CrossEntropyLoss()
18 shift_logits = shift_logits.view(-1, self.config.vocab_size)
19 shift_labels = shift_labels.view(-1)
20 softmax_normalizer = shift_logits.max(-1).values ** 2
21 z_loss = self.config.z_loss_weight * softmax_normalizer.mean()
22 loss = loss_fct(shift_logits, shift_labels) + z_loss
23 if not return_dict:
24 output = (logits,) + outputs[1:]
25 return (loss,) + output if loss is not None else output
26 return CausalLMOutputWithPast(loss=loss, logits=logits, attentions=outputs.attentions,
27 past_key_values=outputs.past_key_values, hidden_states=outputs.hidden_states)在上述代码中,第4~5行是分别是实例化一个解码器和一个分类层,其输出维度便是词表的大小。第7~9行便是语言模型前向传播所需要的输入值,同类BaichuanModel中的一致,这里就不再赘述。第10~12行是解码器返回的结果,其中hidden_states的形状为[batch_size, seq_len, hidden_size]。第13行最后一个分类层的输出结果,形状为[batch_size, seq_len, vocab_size]。第14~22行是模型预训练时的损失计算过程,与10.13.3节中的过程类似这里就不再赘述。第23~27行是根据条件返回对应形式的输出结果,默认返回的是CausalLMOutputWithPast的形式。这里需要注意的事,返回的BaseModelOutputWithPast类对象既可以通过以成员变量的形式访问,也可以通过索引的形式访问,见下面的使用示例。
3. 使用示例
在完成上述代码实现之后,我们便可以通过如下方式来进行使用:
1 def test_BaichuanForCausalLM():
2 config = BaichuanConfig.from_pretrained('./Baichuan2_7B_Chat')
3 model = BaichuanForCausalLM(config)
4 seq = torch.randint(0,100,[2,32])
5 result = model(input_ids=seq, labels=seq,return_dict=True)
6 print(result.loss) # tensor(12.2164, grad_fn=<AddBackward0>)
7 print(result[0]) # tensor(12.2164, grad_fn=<AddBackward0>)在上述代码中,第2~3行是分别实例化一个配置类和一个语言模型类对象。第4~5行是先制作两条模拟样本,然后计算其前向传播后的损失值。第6~7行是以不同的方式来取得样本计算后的损失值。
10.19.4 模型微调实现#
在10.18.5节内容中我们大致介绍了如何利用自定义的数据来对Baichuan2模型进行微调,下面我们对其中的关键原理进行一个详细的介绍。当然,模型微调的原理本质上也就是模型训练的原理,所以这也算是对模型训练过程的一个介绍。本部分的代码可参见Code/Chapter10/C08_Baichuan2FineTune/fine_tune.py文件。
1. 数据集构建
根据上面内容中语言模型的实现过程来看,Baichuan2仍旧是一个标准的语言模型,即通过前$k$个词来预测第$k+1$个词。因此,整个模型训练中最重要的就是如何根据多轮对话数据在构建模型的输入和标签。如图10-66所示便是Baichuan2模型在微调对话模型时模型输入和标签的原理示意图。
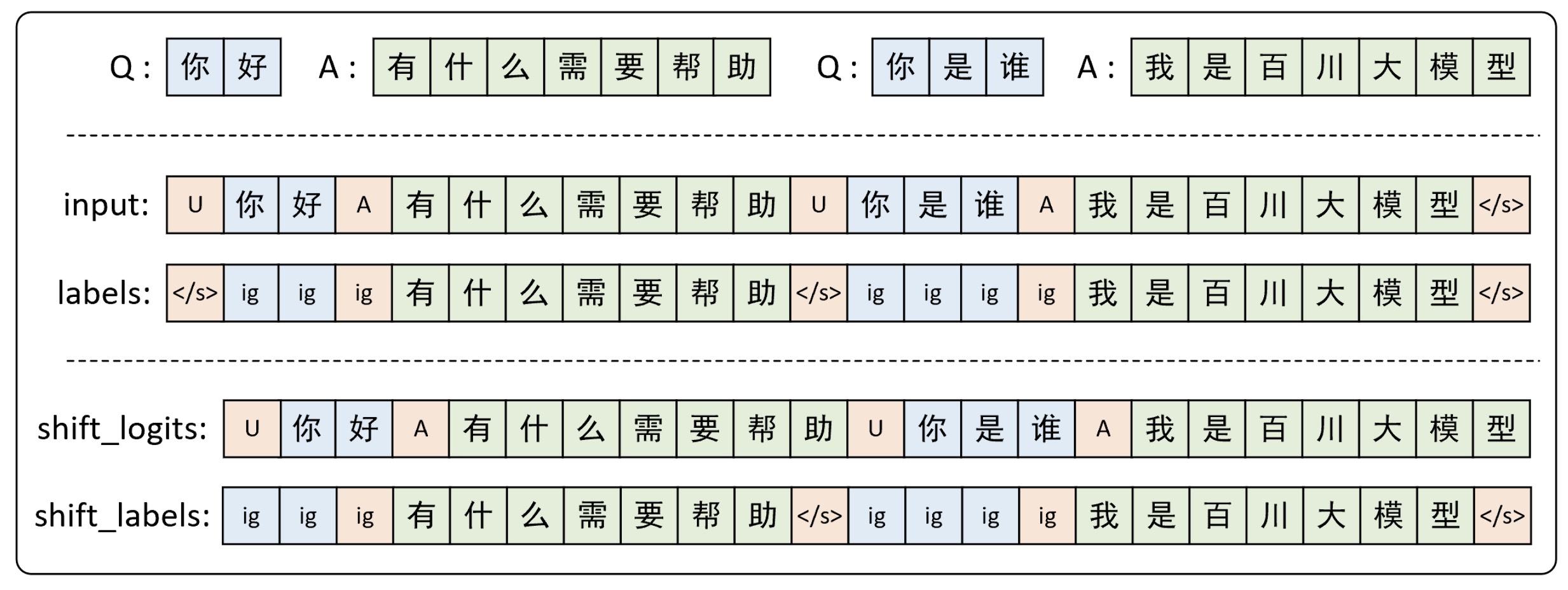
在图10-66中,最上面部分是一条包含有两轮对话的语料,也即为一个原始样本,其中Q表示问题,A表示标注的回答内容。首先,对于模型的输入部分来说在构造时我们需要依次将问题和回答按序拼接在一起,并且在问题部分的文本前面需要拼接user_tokens即图10-66中的U,在回答部分的文本前面需要拼接assistant_tokens即图10-66中的A,用于让模型区分哪部分是用户的提问哪部分是作为问题的回答。对于模型的标签部分来说,我们需要在输入的基础之上将问题部分的文本替换为ignore_index,即图示中的ig,同时需要在每个回答内容后加上结束符</s>。也就是说模型在微调时这部分对应的预测结果不进行损失的计算,因为这是用户的输入部分。在模型计算损失时,对于输出部分来说只会取前$n-1$个位置的结果,即类BaichuanForCausalLM前向传播中的shift_logits = logits[..., :-1, :]部分;对于标签来说只会取后$n-1$个结果,即shift_labels = labels[..., 1:]部分。最后,通过交叉熵来计算预测值与真实值之间的损失。
从图10-66中最下面部分可以看出,对于用户输入部分文本的预测值并不需要模型进行学习,我们需要的是让模型根据上下文来预测回答部分的文本,并且到遇到</s>时表示本轮问答内容结束。同时,这里需要注意的是Baichuan2模型中所使用的词元分割器并不是按字而是按词进行分割的,图示只是为了进行原理说明,具体细节可以参见官方文档 [2]。
2. 数据集构建实现
进一步,我们根据图10-66中的原理来实现数据集的构建过程。首先,我们定义类SupervisedDataset并完成类的初始化方法,示例代码如下所示:
1 class SupervisedDataset(Dataset):
2 def __init__(self, data_path, tokenizer, model_max_length,
3 user_tokens=[195], assistant_tokens=[196]):
4 super(SupervisedDataset, self).__init__()
5 self.data = json.load(open(data_path))
6 self.tokenizer = tokenizer
7 self.model_max_length = model_max_length
8 self.user_tokens = user_tokens
9 self.assistant_tokens = assistant_tokens
10 self.ignore_index = -100在上述代码中,第1行data_path用于指定原始语料的路径,数据样例可见10.18.5节内容;model_max_length用于指定序列的最大长度,即对话时上下文窗口的长度。第2行user_tokens和assistant_tokens分别是图10-66中的U和A,对应的词元为<reserved_106>和<reserved_107>。第5行是载入原始对话语料,如果有多个文件的话可分别载入再合并到一个字典中。第10行是指定在计算损失时需要忽略的索引,因为nn.CrossEntropyLoss()中默认的参数ignore_index = -100。
接着,我们可以实现训练样本的构建部分,示例代码如下所示:
1 def preprocessing(self, example):
2 input_ids, labels = [], []
3 for message in example["conversations"]:
4 from_, value = message["from"],message["value"]
5 value_ids = self.tokenizer.encode(value)
6 if from_ == "human":
7 input_ids += self.user_tokens + value_ids
8 labels += [self.tokenizer.eos_token_id] + [self.ignore_index] * len(value_ids)
9 else:
10 input_ids += self.assistant_tokens + value_ids
11 labels += [self.ignore_index] + value_ids
12 input_ids.append(self.tokenizer.eos_token_id)
13 labels.append(self.tokenizer.eos_token_id)
14 input_ids = input_ids[: self.model_max_length]
15 labels = labels[: self.model_max_length]
16 input_ids += [self.tokenizer.pad_token_id] * (self.model_max_length - len(input_ids))
17 labels += [self.ignore_index] * (self.model_max_length - len(labels))
18 input_ids = torch.LongTensor(input_ids)
19 labels = torch.LongTensor(labels)
20 attention_mask = input_ids.ne(self.tokenizer.pad_token_id)
21 return {"input_ids": input_ids,"labels": labels,"attention_mask": attention_mask}在上述代码中,第1行example为原始的一条数据,包含有多轮对话内容,格式为一个字典。第2行是初始化两个列表用于后续保存输入和标签。第3~5行分别是开始遍历当前多轮对话中的每一条对话文本,并取其中的标识问题和回答的from字段以及文本内容的value字段,最后将文本内容进行索引向量化处理。第6~11行则是用来判断当前这一条对话内容是问题还是回答,并按照图10-66中的原理进行拼接处理。
例如对于如下样本来说:
1 { "id": "77771","conversations": [
2 {"from": "human", "value": "请给出两句苏轼词中主题是中秋的句子\n"},
3 {"from": "gpt","value": "好的,以下是你要求的内容:明月几时有?把酒问青天。\n不止天上宫阙,今夕是何年。"},
4 {"from": "human", "value": "这首词是苏轼什么时候写的?\n"},
5 {"from": "gpt","value": "这首词作于宋神宗熙宁九年(1076)年,即丙辰年的,中秋佳节。"}]}经过第6~11行代码处理后的结果为:
1 input_ids: [195, 92676, 19278, 48278, 26702, 93319, 92364, 73791, 10430, 82831,
2 5, 196, 2015, 65, 2835, 11024, 1853, 8736, 70, 23387, 92855, 23656, 68, 89446,
3 92614, 79107, 66, 5, 5380, 24616, 93660, 96261, 65, 92731, 94404, 84465, 92381,
4 66, 195, 17759, 93319, 92347, 26702, 11090, 15473, 68, 5, 196, 17759, 93319,
5 92400, 92441, 93849, 92786, 93676, 94859, 93151, 31506, 97923, 92336, 92335,
6 92383, 92373, 97905, 92381, 65, 92813, 94893, 94459, 2537, 65, 10430, 26231, 66]
7 ['<reserved_106>', '请', '给出', '两句', '苏轼', '词', '中', '主题是', '中秋',
8 '的句子', '\n', '<reserved_107>','好的', ',', '以下', '是你', '要求', '的内容',
9 ':', '明月', '几', '时有', '?', '把酒', '问', '青天', '。', '\n', '不知', '天上',
10 '宫', '阙', ',', '今', '夕', '是何', '年', '。', '<reserved_106>', '这首', '词',
11 '是', '苏轼', '什么时候', '写的', '?', '\n', '<reserved_107>', '这首', '词', '作',
12 '于', '宋', '神', '宗', '熙', '宁', '九年', '(', '1', '0', '7', '6', ')', '年',
13 ',', '即', '丙', '辰', '年的', ',', '中秋', '佳节', '。']
14
15 labels: [2, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
16 2015, 65, 2835, 11024, 1853, 8736, 70, 23387, 92855, 23656, 68, 89446, 92614,
17 79107, 66, 5, 5380, 24616, 93660, 96261, 65, 92731, 94404, 84465, 92381, 66,
18 2, -100, -100, -100, -100, -100, -100, -100, -100, -100, 17759, 93319, 92400,
19 92441, 93849, 92786, 93676, 94859, 93151, 31506, 97923, 92336, 92335, 92383,
20 92373, 97905, 92381, 65, 92813, 94893, 94459, 2537, 65, 10430, 26231, 66]
21 ['</s>', '<->', '<->', '<->', '<->', '<->', '<->', '<->', '<->', '<->', '<->',
22 '<->', '好的', ',','以下', '是你', '要求', '的内容', ':','明月', '几', '时有', '?',
23 '把酒', '问', '青天', '。', '\n', '不知', '天上', '宫', '阙', ',', '今', '夕','是何',
24 '年', '。', '</s>', '<->', '<->', '<->', '<->', '<->', '<->', '<->', '<->', '<->',
25 '这首', '词', '作', '于', '宋', '神', '宗', '熙', '宁', '九年', '(', '1', '0', '7',
26 '6', ')', '年', ',', '即', '丙', '辰', '年的', ',', '中秋', '佳节', '。']在上述输出结果中,切分后的词元结果为我们自行转换后的结果为便于理解,同时<->是将-100随意指定的一个符号。
上述第12~19行代码则是进行一系列的后处理,比较简单就不再赘述。第20行是计算得到输入序列是否填充的掩码向量。第21行则是返回每个原始包含有多轮对话的样本处理结束后的结果。
3. 模型训练实现
在完成数据的构建以后,我们可以借助transformers框架中的Trainer模块来完成模型的训练过程,示例代码如下所示:
1 def train():
2 parser = transformers.HfArgumentParser((ModelArguments, DataArguments, TrainingArguments))
3 model_args, data_args, training_args = parser.parse_args_into_dataclasses()
4 model = BaichuanForCausalLM.from_pretrained(model_args.model_name_or_path,
5 trust_remote_code=True, cache_dir=training_args.cache_dir)
6 tokenizer = BaichuanTokenizer.from_pretrained( model_args.model_name_or_path,
7 use_fast=False, trust_remote_code=True, cache_dir=training_args.cache_dir,
8 model_max_length=training_args.model_max_length)
9 dataset = SupervisedDataset(data_args.data_path, tokenizer,
10 training_args.model_max_length)
11 trainer = transformers.Trainer(model=model, args=training_args,
12 train_dataset=dataset, tokenizer=tokenizer)
13 trainer.train()
14 trainer.save_state()
15 trainer.save_model(output_dir=training_args.output_dir)在上述代码中,第2~3行是解析命令行中所输出的相关参数,并分离得到model_args、 data_args和 training_args。第4~5行则是根据模型路径通过from_pretrained方法实例化预训练模型,如果预训练模型不存在将会在线下载并缓存到cache_dir目录中。第6~8行是实例化得到词元切分器。第9~10行是返回得到模型训练用的数据集迭代器。第11~12行是实例化得到模型训练器。第13~15行则是开始训练模型并保存,其中第14行是保存整个模型训练器的状态参数,第15行是仅保存模型权重参数。
在完成上述编码以后,我们便可以通过10.18.5节中的命令开始模型的微调过程。到此,对于Baichuan2模型的微调方法就介绍完了,更多详细信息可参见官方教程 [2]。
10.19.5 模型推理实现#
为了实现交互式的对话流程,我们需要在类BaichuanForCausalLM中实现一个chat()方法来完成每一轮响应内容的生成,示例代码如下所示:
1 def chat(self, tokenizer, messages , stream=False, generation_config = None):
2 generation_config = generation_config or self.generation_config
3 input_ids = build_chat_input(self, tokenizer, messages,
4 generation_config.max_new_tokens)
5 outputs = self.generate(input_ids, generation_config=generation_config)
6 response = tokenizer.decode(outputs[0][len(input_ids[0]):],
7 skip_special_tokens=True)
8 return response在上述代码中,第1行tokenizer是传入的词元切分器,messages是用户输入的原始文本,generation_config为传入的模型在推理时用到的参数,不过默认是通过model.generation_config=GenerationConfig.from_pretrained()方法得到,即generation_config为下面第2行的后者。第3~4行是根据用户输入构造得到模型对应的序列输出,即input_ids。第5行则是根据用户输入生成对应的响应内容。第6行是将模型生成的内容解码成对应的文字。
这里我们在简单介绍一下第5行中的generate()方法。这个方法是类GenerationMixin中的成员方法,因为类BaichuanForCausalLM是继承自该类,所以这里直接使用该类来解码生成内容,具体可见Python环境中的site-packages/transformers/generation/utils.py文件(transformers版本为4.29.2)。为了支持不同策略下的解码过程,例如采样、束搜索和贪婪搜索等,所以GenerationMixin中实现了各种不同的解码策略,而Baichuan2中使用的是基于采样的策略,因此最后Baichuan2中使用的是GenerationMixin中的sample()成员方法。
由于篇幅有限,所以我们这里只对sample()方法中的核心逻辑进行介绍,示例代码如如下所示:
1 def sample(self, input_ids, max_length = None, stopping_criteria = None,
2 logits_processor = None, logits_warper = None, ... ):
3 ......
4 while True:
5 model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
6 outputs = self(**model_inputs, output_attentions = output_attentions,
7 return_dict = True, output_hidden_states = output_hidden_states)
8 next_token_logits = outputs.logits[:, -1, :]
9 next_token_scores = logits_processor(input_ids, next_token_logits)
10 next_token_scores = logits_warper(input_ids, next_token_scores)
11 probs = nn.functional.softmax(next_token_scores, dim=-1)
12 next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
13 input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
14 model_kwargs = self._update_model_kwargs_for_generation(outputs,
15 model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder)
16 if stopping_criteria(input_ids, scores):
17 this_peer_finished = True在上述代码中,第1行input_ids为输入序列的索引,max_length为生成序列允许的最大长度,stopping_criteria为传入停止解码的策略方法。第2行logits_processor和logits_warper为传入的两个类方法,均用于为对后续logits的过滤处理,即通过参数temperature、top_k、top_p和repetition_penalty来控制生成结果,相关原理可以参见「第10.15节 基于GPT-2的中文预训练模型:中文生成模型实践」内容。第4行开始则是循环生成结果内容。第5行便是构造得到模型的整体输入,包括position_ids、past_key_values、use_cache和attention_mask,该方法对应的便是modeling_baichuan.py模块中的prepare_inputs_for_generation方法。第6~7行便是语言模型的前向传播计算过程,对应的是类BaichuanForCausalLM中的forward方法。第8行取原始输出的 logits 值。第9行是对模型输出的原始 logits 做约束和过滤,例如禁止某些词元生成,不过这里 logits_processor 内部默认没有进行任何处理。第10行是对 logits 做概率调整,它会影响生成的随机性,本质上就是第10.15.2节中的 top_k_top_p_filtering 函数。第11~12行则是根据采样的策略来得到当前时刻的解码输出。第13~15行则是重新构造得到下一个解码时刻的输入。这里需要注意一点的是,尽管在第13行中是将之前的所有输入同当前时刻的解码输出拼接到一起的,但是在prepare_inputs_for_generation方法中,当使用缓存机制时会通过input_ids = input_ids[:, -1:] 来只取当前时刻的输出作为下一个解码时刻的输入。第16~17行则是判断是否停止解码。
10.19.6 模型解码过程#
经过上面的介绍,我们对于Baichuan2模型应该已经有了比较清晰地认识。不过为了让各位读者能够更加形象化地理解模型在推理时的细节,下面我们再通过一个简单的示例来展示推理时模型的输入输出形式。当我们询问Baichuan2模型问题“金庸是谁?”时,将会得到类似“金庸(原名查良镛,1924年3月10日—2018年10月30日),生于浙江省嘉兴市海宁市……”的回复。对于模型的整个推理过程来说,我们可以通过如图10-67所示的形式来进行表示。
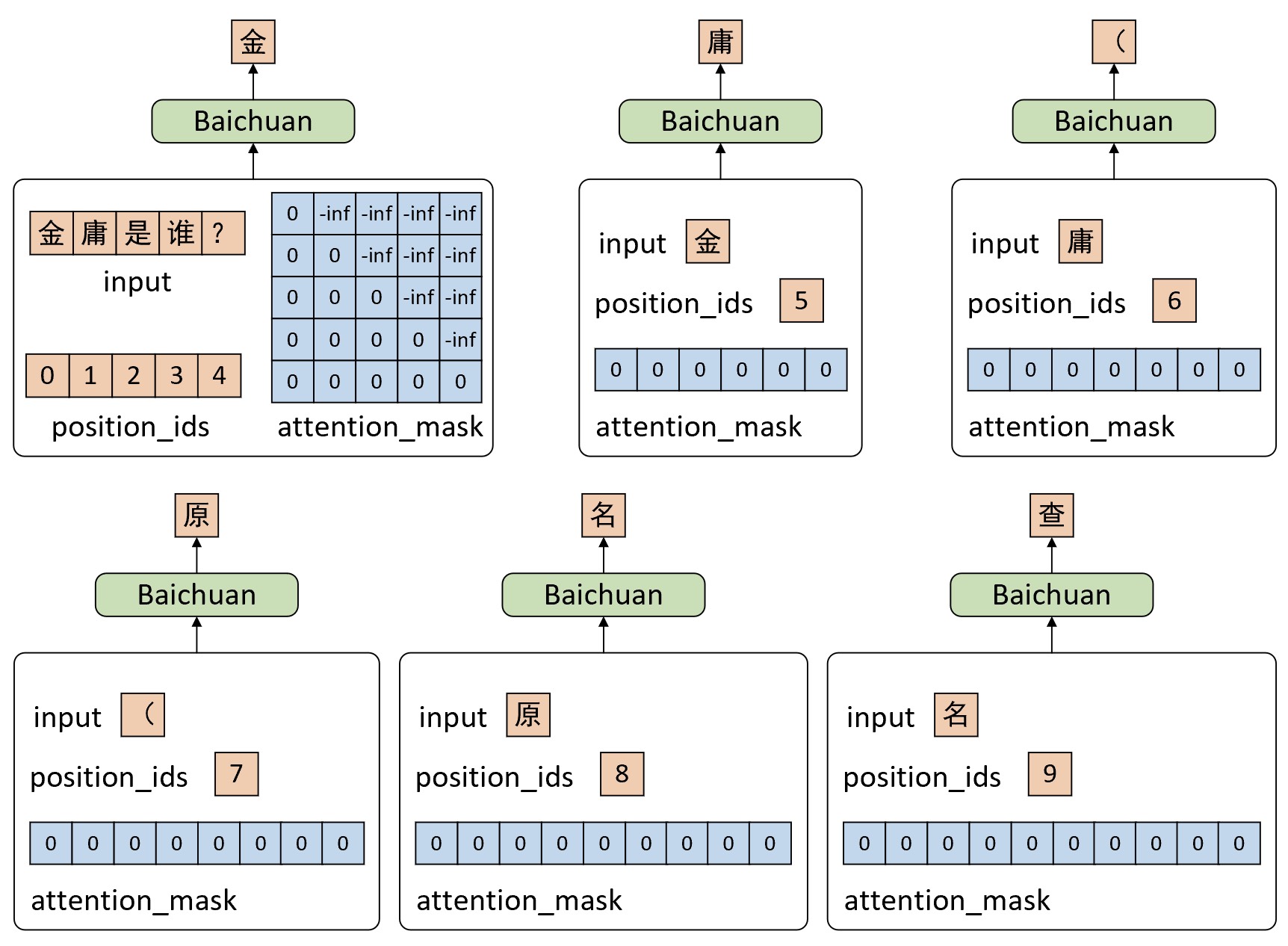
如图10-67所示,当我们询问Baichuan2问题“金庸是谁?”模型首先会对输入进行编码并解码得到当前时刻的输出“金”,此时由于输入是包含多个时刻的序列,所以对应注意力掩码attention_mask的形状为[1,1,5,5],位置序列索引position_ids的形状为[1,5],计算多头注意力时query_states、key_states和value_states的形状均为[1,num_heads,5,head_dim]。进一步,模型以当前时刻的输出“金”作为下一个时刻的输入预测得到输出“庸”,此时由于模型的输入只有一个词元,所以对应注意力掩码attention_mask的形状为[1,1,1,5+1],位置序列索引position_ids的形状为[1,1],计算多头注意力时query_states的形状为[1,num_heads,1,head_dim],key_states和value_states的形状均为[1,num_heads,5+1,head_dim]。后续过程以此类推,直到完成整个推理过程。
10.19.7 小结#
在本节内容中,我们首先介绍了大模型中模型解码时Key-Value缓存机制的详细原理;然后分别注意介绍了Baichuan2模型中的注意力机制、解码器和语言模型的实现过程;接着介绍了Baichun2模型的微调和推理解码过程;最后,我们再次通过图示来详细介绍了模型在解码过程中的输入输出形式。到这里,对于整个Baichuan2模型的介绍就结束了。在下一节内容中我们将会介绍GPT-4系列模型及其使用方法。
引用#
[1] https://github.com/moon-hotel/DeepLearningWithMe/
[2] https://github.com/baichuan-inc/Baichuan2