9.10 注意力机制#
在「第9.9节 神经机器翻译 NMT:Seq2Seq 在翻译任务中的应用」内容中,解码器在解码时我们直接取了编码器最后一个时刻的输出进行循环解码,然而随着输入序列长度的增加这样的处理方式将会成为一种信息瓶颈( Information Bottleneck)[1] [2] [3],即使得解码器无法记住和区分源序列中各个时刻的编码信息。在本节内容中,我们将会学习到一种新的深度学习技术——注意力机制(Attention Mechanism)——来解决类似问题。
9.10.1 注意力的起源#
关于对人类注意力机制的研究最早大致可以追溯至19世纪下半叶。有着世纪之交最有影响力心理学家之称的威廉·詹姆斯在他的主要作品《心理学原理》中说到[4]:每个人都知道什么是注意力,注意力其实就是大脑以一种清晰生动的方式在多个同时存在的对象中选择占据其中一个的过程,即意识的集中和聚焦。所以,注意力也被形象的描述为根据有限认知处理和分配大脑资源的过程[5]。
例如在视觉注意力( Visual Attention )中,人类的视觉系统在处理视觉信息时会根据特定任务或环境选择性地集中关注某些区域,从而提高对这些区域的感知,使得我们能够在复杂的视觉场景中更有效地捕获重要信息[6]。
![图 9-23 视觉注意力示意图[7]](https://mlwithme.oss-cn-shanghai.aliyuncs.com/images/dl/230817211900.jpg)
如图9-23所示,当我们注视于湖边的这只白鹭时,我们的大脑便会将更多的注意力分配到这只白鹭身上而减少对其周边环境的注意力。
正是受到人类注意力机制的启发,研究人员开始将这一思想运用于深度学习领域中。2014年姆尼赫等人[8]开始将注意力机制运用在基于循环神经网络的图像和视频分类模型中;2014年巴赫达瑙等人[1]第一次将注意力运用于机器翻译模型中;进一步,注意力机制的应用也开始出现在语音识别、图像描述、图像描述、摘要总结和文本分类等领域[9]。
9.10.2 注意力机制思想#
在Seq2Seq任务中,源输入序列的不同部分通常都具有不同的重要性,然而传统Encoder-Decoder模型在处理这一过程时并没有考虑到这种情况,因为它仅仅只是依靠上一个时刻的解码输出来对当前时刻进行解码。所以通过将源序列编码压缩得到一个固定维度的中间向量并直接进行解码的做法并不能有效地区分源序列中每个时刻的重要性,进而准确地预测每个时刻的输出结果。理想情况下,解码器在对不同时刻的输出进行解码时都应该将关注点放在编码器对应的不同时刻上。
例如在图9-22中,当解码器对第3个时刻“是”进行解码时,理论上模型应该更加专注于编码器中第2个时刻“am”对应的位置。同时,实验结果也表明当推理过程中输入序列的长度远大于训练集中的序列长度时,这种影响将会更加明显[1] [2]。
基于这样的动机,巴赫达瑙(Bahdanau)等人[1]在2014年首次提出了一种基于Seq2Seq架构的加法形式(Additive Style)注意力学习机制,其核心思想是对于解码器每个时刻的输出,模型可以对源输入序列的不同部分动态地分配注意力权重,使得模型可以更聚焦于编码序列中与当前输出时间步最相关的部分[3]。进一步,基于巴赫达瑙所提出的注意力框架,卢翁(Luong)等人[10]2015年又提出了一种乘法形式(Multiplicative Style)的注意力机制。
通过引入注意力机制,模型可以根据输入的上下文动态地将注意力权重分配到序列的不同位置上,而这也意味着模型可以更加灵活地关注重要位置上的信息,从而提高模型的预测能力。
9.10.3 注意力计算框架#
根据上面两个小节内容的介绍我们从直观上了解了什么是注意力机制以及注意力机制的主要作用,因此接下来我们需要知道在深度学习中如何表示注意力以及如何设计一个通用的注意力计算框架。由于注意力的本质就是对有限资源的一个分配过程,自然而然我们可以通过一个权重向量来表示注意力的分配情况,权重越大的位置便给予更高的注意力。所以,如何设计一个有效的框架来计算注意力权重向量便成了我们接下来需要解决的问题。
1. 计算框架
在信息检索系统中,通常我们可以根据关键字在数据库中检索得到离我们期望结果最相似的输出结果,而这样一个过程便可以作为注意力计算框架的灵感来源。例如对于一个视频网站来说,用户可以通过关键字(Query)在标题表(Keys)中检索得到与之最为匹配的标题,然后再通过标题从视频库(Values)中检索得到对应视频并返回给用户,整个结构如图9-24所示。
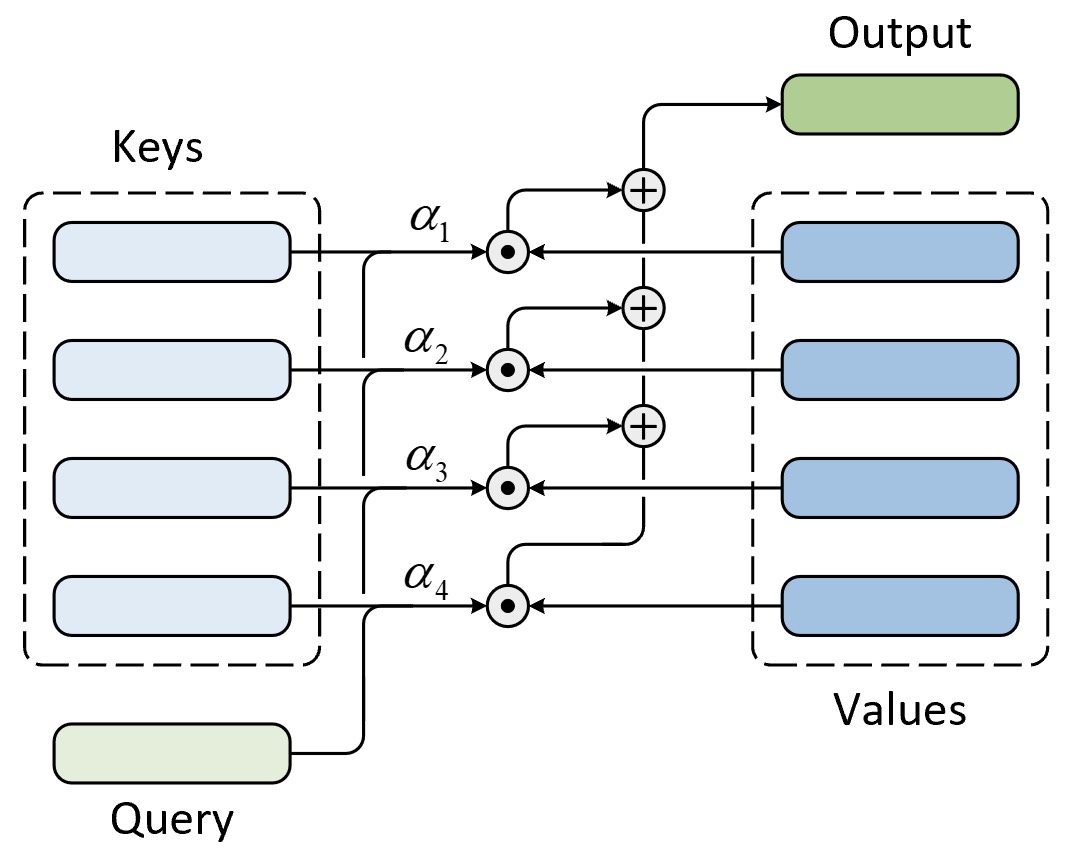
在图9-24中,视频检索系统首先根据用户输入的关键词Query同视频标题Keys中的每个标题进行相似性计算并得到一个权重向量$\alpha$ ,其中$\alpha_i$表示Query与第$i$个标题的相似程度;最后根据$\alpha$便可以从Values中返回相应的视频内容。此时,权重向量$\alpha$便可以理解为当输入关键词为Query时检索系统应该如何将注意力分配到各个视频内容上的度量。进一步,如果将$\alpha$限制为One-hot编码形式则被称之为硬注意力(Hard Attention),此时将只会返回Values中的一个值;通常情况下$\alpha$将会被归一化成一个概率分布称之为软注意力(Soft Attention),此时将会返回所有Values的加权结果。
同时,对于不同的模型来说Query、Keys和Values都不尽相同,并且需要注意的是Keys和Values一一对应出现。例如在Seq2Seq架构中Query通常取自目标序列编码后的隐含状态,Keys和Values则都取自源序列编码后的隐含状态。
2. 计算流程
根据上述注意力计算框架,含有注意力机制的NMT模型在对每个时刻进行解码时,其注意力计算过程可以通过图9-25进行表示 [2] [3] [11]。
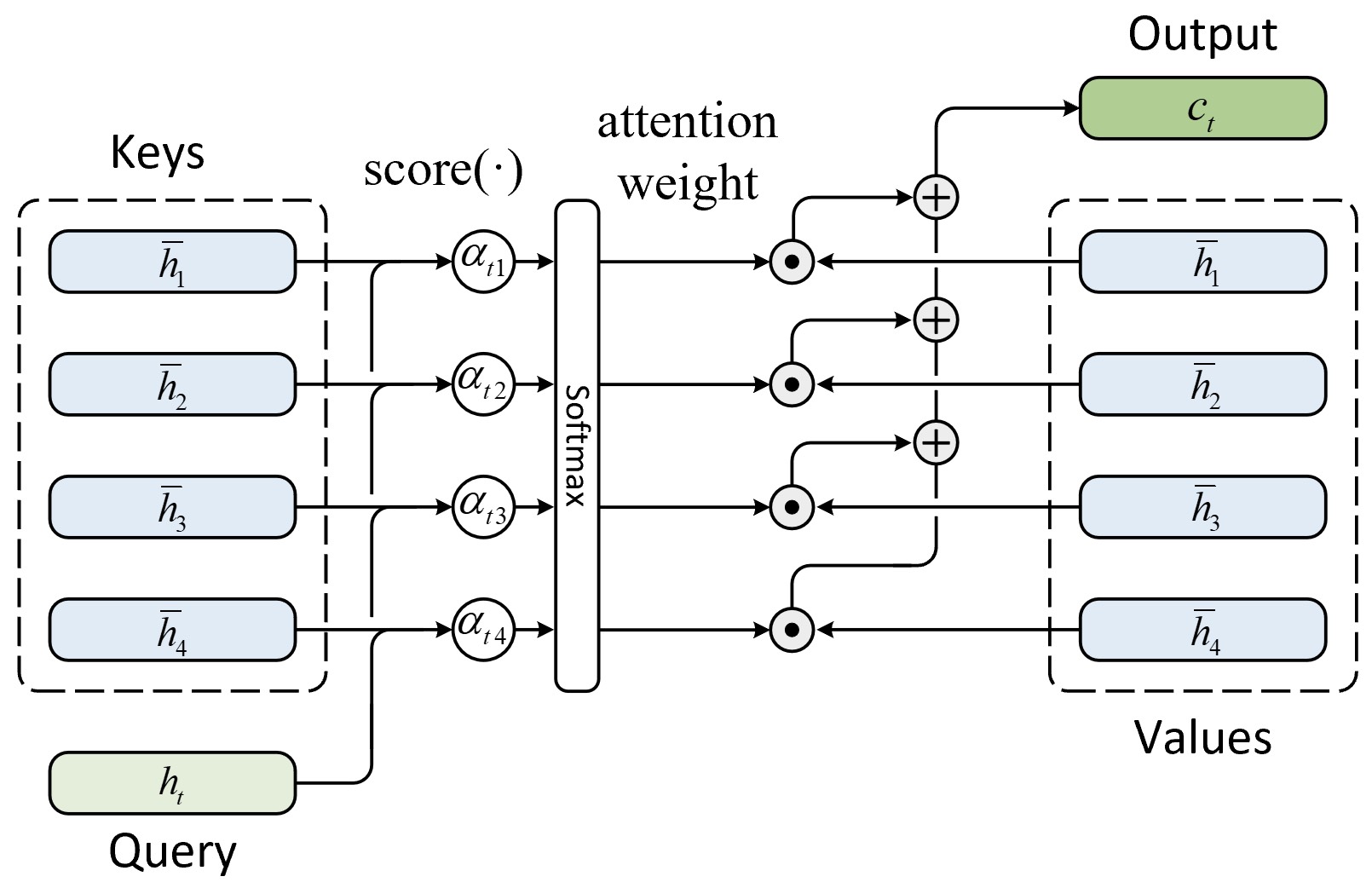
如图9-25所示便是解码器解码时注意力机制的计算原理图,其中Query表示第$t$时刻解码器的隐含状态$h_t$,Keys表示编码器中所有时刻的隐含状态$\overline{h}_1,\overline{h}_2,..\overline{h}_S$,此时Values与Keys相同。进一步,整个含注意力的解码过程可以表示为如下4步。
①将第$t$时刻的隐含状态同编码器中所有时刻的隐含状态进行比较,根据式(9-37)计算得到注意力权重(Attention Weights)。
$$ \alpha_{ts}=\frac{\exp\left(\text{score}(h_t,\overline{h}_s)\right)}{\sum_{s^{\prime}=1}^S\exp\left(\text{score}(h_t,\overline{h}_{s^{\prime}})\right)}\in\mathbb{R}\tag{9-37} $$其中$\alpha_{ts}$表示解码器第$t$个时刻的隐含状态需要将注意力分配到编码器中第$s$时刻的大小,即解码器第$t$个时刻隐含状态的与编码器第$s$时刻隐含状态的相关性越高,则对应的注意力值便越大;$\text{score}(\cdot)$为注意力评分函数,将在接下来的两个小节中进行介绍。可以看出,注意力权重向量$\alpha_t$的含义是对于第$t$时刻来说应该如何把注意力分配到编码器中的各个时空。
②基于注意力权重同编码器所有时刻的隐含状态,根据式(9-38)计算得到加权上下文向量(Context Vector)。
$$ c_t=\sum_{s=1}^S\alpha_{ts}\overline{h}_s\tag{9-38} $$可以看出,此时$c_t$便是编码器中所有时刻隐含向量的加权和。
③将上下文环境向量$c_t$与解码器第$t$时刻的隐含状态$h_t$进行组合,根据式(9-39)计算得到注意力向量(Attention Vector)。
$$ a_{t+1}=f(c_t,h_t,\hat{y}_t)=\tanh(W_c[c_t;h_t;\hat{y}_{t}])\tag{9-39} $$④将$a_{t+1}$进行预测分类便得到了第$t+1$时刻的输出结果。
以上4步便是Bahdanau等人所提出的注意力计算框架。从式(9-37)可以看出,选择不同的评分函数$\text{score}(\cdot)$也将会得到不同的计算结果,而这也是本节内容中将会介绍到的两种不同类型的注意力机制。同时,根据第②步可知此时计算得到的上下文向量$c_t$是根据第$t$时刻的状态计算而来,并且同第$t$时刻的隐含向量$h_t$和预测输出$\hat{y}_t$经RNN解码后得到第$t+1$时刻的预测输出$y_{t+1}$;而另外一种做法也可以是直接取第$t+1$时候的状态来计算第$t+1$时刻的上下文向量$c_{t+1}$最后得到第$t+1$时刻的预测结果$y_{t+1}$。因此,采用不同的评分函数或解码策略都能得到不同的注意力机制扩展模型。
9.10.4 填充注意力掩码#
由于在模型训练过程中是一个小批量的样本同时进行计算,且对于长度不同的样本我们都进行了填充处理,因此在计算上下文向量$c_t$时便应该忽略掉编码器中填充部分的隐含状态。一种常见的做法便是将填充部分对应的注意力权重$\alpha_{ts}$重置为0,这样在计算上下文向量时便可以忽略填充部分的影响。
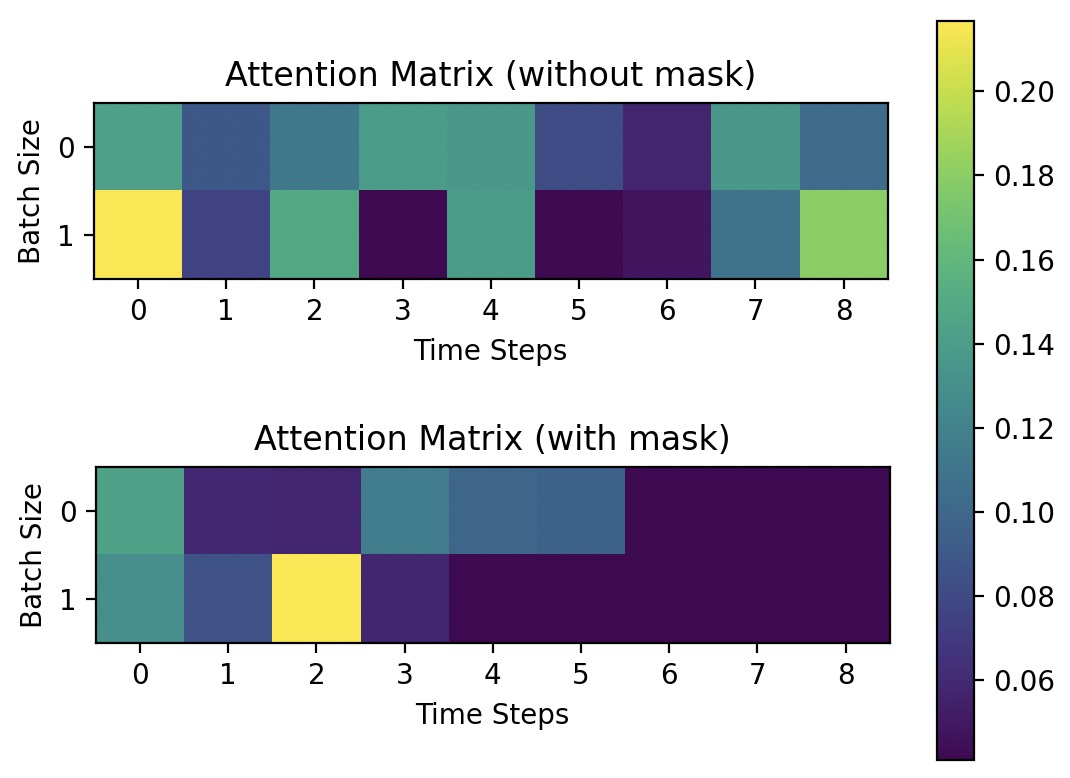
如图9-26所示,上面部分为不进行掩码操作的可视化结果;下面部分则为掩码操作后的结果,其中第0个样本中的后3个时刻和第1个样本的后5个时刻为填充部分的注意力权重,即为0。
对于这部分内容可以通过如下方式进行实现:
1 src_key_padding_mask = torch.tensor([[False, False, True, True],
2 [False, False, False, True]])
3 scores = torch.tensor([[0.2, 0.3, 0.5, 0.7], [0.3, 0.1, 0.5, 0.6]])
4 scores = scores.masked_fill(src_key_padding_mask, float('-inf'))
5 attention_weights = torch.softmax(scores, dim=-1) # [batch_size, src_len]
6 print(attention_weights)在上述代码中,第1/~2行用来表示表示原始序列中的填充位置,其中True 表示该位置填充值。第4行是将score中src_key_padding_mask为True 的地方填充为负无穷,例如对于第1个样本来说最后两个值0.5和0.7将被填充为负无穷。第5行是对注意力权重进行归一化处理,其中score中为负无穷的值将会为0。
上述代码如运行结束后将会得到如下所示结果:
1 tensor([[0.4750, 0.5250, 0.0000, 0.0000],
2 [0.3289, 0.2693, 0.4018, 0.0000]])9.10.5 Bahdanau注意力#
在Bahdanau注意力机制中[1],评分函数$\text{score}(\cdot)$采用的是基于加法形式的做法,且同时NMT的编码器使用了双向RNN进行编码。具体地,对于加法形式的评分函数来说,其计算过程为
$$ \text{score}(h_t,\overline{h}_s)=v^T\tanh(W_Qh_t+W_K\overline{h}_s)\tag{9-40} $$其中$h_t$和$\overline{h}_s$的形状均为[hidden_size,1],$v$的形状为[1,hidden_size],$W_Q$和$W_K$的形状均为[hidden_size,hidden_size]。
根据式(9-37)、式(9-38)和式(9-40)可得,Bahdanau注意力机制的实现过程如下所示:
1 class BahdanauAttention(nn.Module):
2 def __init__(self, hidden_size, dropout=0.):
3 super(BahdanauAttention, self).__init__()
4 self.dropout = dropout
5 self.l_query = nn.Linear(hidden_size, hidden_size)
6 self.l_key = nn.Linear(hidden_size, hidden_size)
7 self.linear = nn.Linear(hidden_size, 1)
8 self.drop = nn.Dropout(dropout)
9
10 def forward(self, query, key, value, src_key_padding_mask=None):
11 query = self.l_query(query).unsqueeze(1)
12 key = self.l_key(key)
13 feature = torch.tanh(query + key)
14 scores = self.linear(feature).squeeze(2)
15 if src_key_padding_mask is not None:
16 scores = scores.masked_fill(src_key_padding_mask, float('-inf'))
17 attention_weights = torch.softmax(scores, dim=-1)
18 context_vec = torch.bmm(self.drop(attention_weights).unsqueeze(1), value)
19 return context_vec, attention_weights在上述代码中,第5/~7行是实例化式(9-40)中对应的3个线性变换的类对象。第10行中query的形状为[batch_size, hidden_size],key和value的形状均为[batch_size, src_len, hidden_size],src_key_padding_mask的形状为[batch_size, src_len]。第11/~14行是式(9-40)的整个计算过程。第15/~16行是判断是否进行掩码操作,在推理时不需要。第17/~18行分别计算得到注意力权重矩阵和上下文权重向量,形状分别为[batch_size, src_len]和[batch_size, 1, hidden_size]。
最后,通过如下方式便可使用Bahdanau注意力机制并对注意力权重进行可视化:
1 def test_attention():
2 src_key_padding_mask = torch.tensor(
3 [[False, False, False, False, False, False, True, True, True],
4 [False, False, False, False, True, True, True, True, True]])
5 bahdanau = BahdanauAttention(64)
6 query = torch.rand((2, 64))
7 key = value = torch.rand((2, 9, 64))
8 con_vec, atten_weights = bahdanau(query, key, value, src_key_padding_mask)
9 plt.imshow(attention_weights, cmap='viridis', interpolation='nearest')
10 plt.colorbar()
11 plt.title('Attention Matrix (with mask)')
12 plt.xlabel('Time Steps')
13 plt.ylabel('Batch Size')
14 plt.show()上述代码运行结束后输出结果类似图9-26所示。
9.10.6 Luong注意力#
在Luong注意力机制中[10],评分函数$\text{score}(\cdot)$采用的是基于乘法形式的做法。具体地,对于加法形式的评分函数来说,其计算过程为
$$ \text{score}(h_t,\overline{h}_s)=h_t^TW\overline{h}_s\tag{9-41} $$
其中$h_t$和$\overline{h}_s$的形状均为[hidden_size,1],$W$的形状均为[hidden_size,hidden_size]。
根据式(9-37)、式(9-38)和式(9-41)可得,Luong注意力机制的实现过程如下所示:
1 class LuongAttention(nn.Module):
2 def __init__(self, hidden_size, dropout=0.):
3 super(LuongAttention, self).__init__()
4 self.linear = nn.Linear(hidden_size, hidden_size)
5 self.drop = nn.Dropout(dropout)
6
7 def forward(self, query, key, value, src_key_padding_mask=None):
8 scores = torch.bmm(self.linear(query).unsqueeze(1), key.transpose(1, 2))
9 scores = scores.squeeze(1)
10 if src_key_padding_mask is not None:
11 scores = scores.masked_fill(src_key_padding_mask, float('-inf'))
12 attention_weights = torch.softmax(scores, dim=-1)
13 context_vec = torch.bmm(self.drop(attention_weights).unsqueeze(1), value)
14 return context_vec, attention_weights9.10.7 小结#
在本节内容中,我们首先介绍了注意力的起源和定义,从宏观层面直观解释了什么是注意力;然后介绍了注意力机制的思想,即为什么在Seq2Seq模型中需要引入注意力机制;进一步详细介绍了深度学习中注意力机制的整体框架设计和计算流程,并从查询和键值对的角度来介绍了深度学习中注意力机制的本质;最后一步一步介绍了Bahdanau和Luong这两种在Seq2Seq模型中比较常见的注意力机制模型及其实现过程。在「第10.2节 Transformer原理:自注意力、多头注意力与位置编码」内容中,我们还将介绍一种目前更为广泛使用的自注意力机制。
引用#
[1] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint, 2014, arXiv:1409.0473.
[2] Cho K, Van Merriënboer B, Bahdanau D, et al. On the properties of neural machine translation: Encoder-decoder approaches[J]. arXiv preprint, 2014, arXiv:1409.1259.
[3] Luong M T, Brevdo E, Zhao R. Neural Machine Translation (seq2seq) Tutorial, https://github.com/tensorflow/nmt, 2017.
[4] Attention | Definition, Theories, Aspects, & Facts | Britannica". www.britannica.com.
[5] https://en.wikipedia.org/wiki/Attention
[6] https://en.wikipedia.org/wiki/Visual_spatial_attention
[7] Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]. Proceedings of the European conference on computer vision (ECCV). 3-19, 2018.
[8] Mnih V, Heess N, Graves A. Recurrent models of visual attention[J]. Advances in neural information processing systems, 27, 2014.
[9] Niu Z, Zhong G, Yu H. A review on the attention mechanism of deep learning[J]. Neurocomputing, 2021, 452: 48-62.
[10] Luong M T, Pham H, Manning C D. Effective approaches to attention-based neural machine translation[J]. arXiv preprint, 2015, arXiv:1508.04025.
[11] 阿斯顿·张、李沐、扎卡里 C. 立顿等,动手学深度学习[M],2版. 北京:人民邮电出版社, 2019.