10.9 SMO算法求解SVM#
在10.7节内容中,我们分别就SVM中硬间隔与软间隔目标函数的求解过程进行了介绍,但是在实际应用过程中,从效率的角度来讲那样的做法显然是不可取的,尤其是在大规模数据样本和稀疏数据中[6]。在接下来的这节内容中,我们将介绍一种新的求解算法,即序列最小化优化算法来解决这一问题。
序列最小优化算法(Sequential Minimal Optimization,SMO)于1998年由John Platt所提出,并且SMO算法初次提出的目的就是为了解决SVM的优化问题[7]。SMO算法是一种启发式的算法,它在求解过程中通过以分析的方式来定位最优解可能存在的位置,从而避免了传统方法在求解中所遭遇的大量数值计算问题,并且最终以迭代的方式来求得最优解。在正式介绍SMO算法之前,我们将先介绍SMO算法的基本原理——坐标上升算法(Coordinate Ascent)。
10.9.1 坐标上升算法#
在2.5节内容中,我们详细地介绍了什么是梯度下降算法及梯度下降算法的作用。对于一个待优化的目标函数来讲,在初始化一个起始位置后,便可以以该点为基础每次沿着该点梯度的反方向向前移动一小步,以此来迭代求解,以便得到目标函数的全局(局部)最优解,而所谓的坐标上升(下降)算法可以看作初始位置只沿着其中的一个(或几个)方向移动来求解得到目标函数的全局(局部)最优解[8],如图10-15所示。
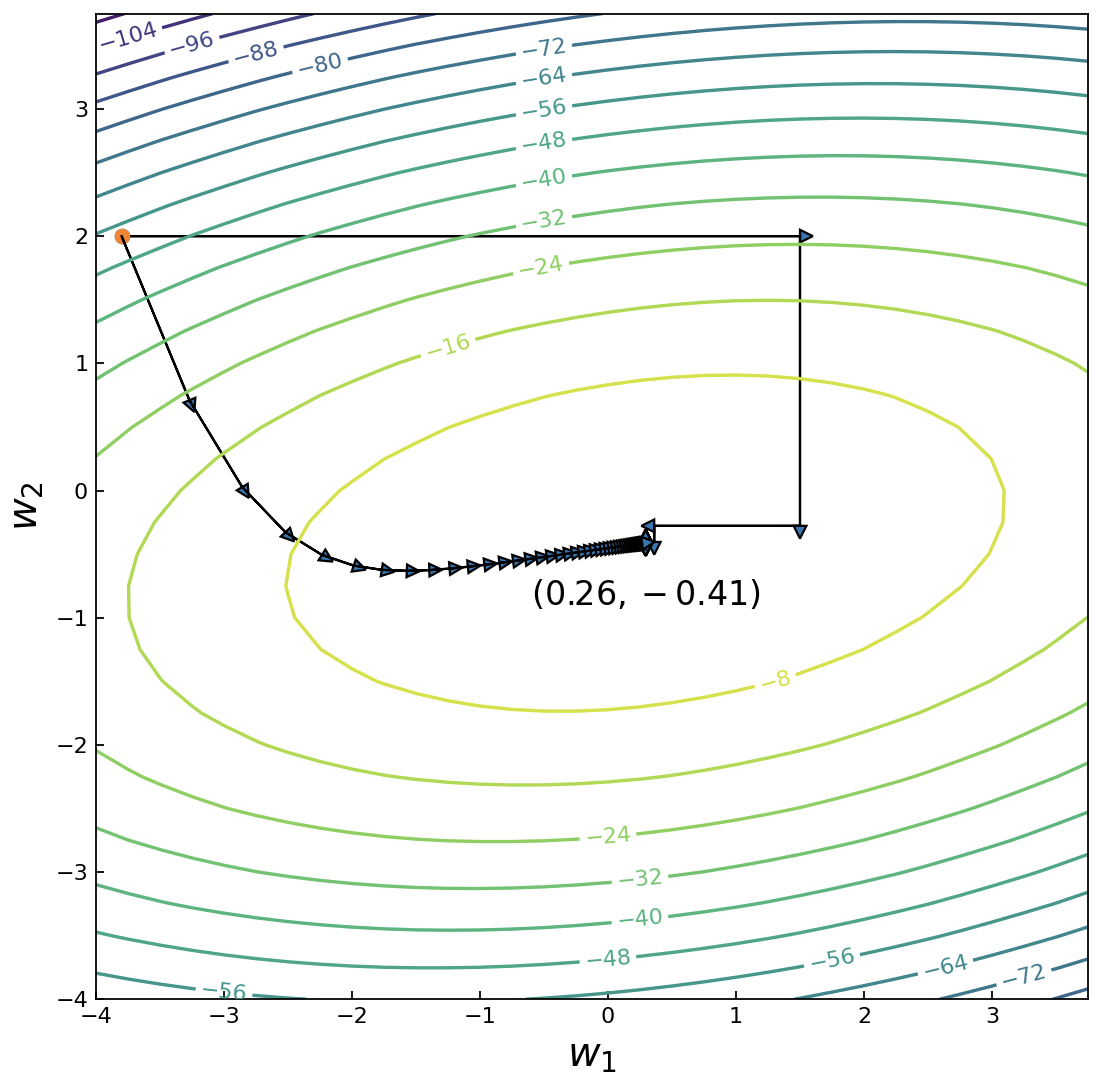
在图10-15中,曲线为目标函数$J({{w}_{1}},{{w}_{2}})=-0.5{{({{w}_{1}}-1)}^{2}}-{{(2{{w}_{2}}+1)}^{2}}-0.5{{({{w}_{1}}-{{w}_{2}})}^{2}}$的等高线,黑色箭头曲线为梯度上升算法最大化目标函数$J(w_1,w_2)$的求解过程,而黑色箭头折线为坐标上升算法最大化目标函数的求解过程。
具体地,对于待求解目标函数$J({{w}_{1}},{{w}_{2}},...,{{w}_{n}})$来讲可以通过如下步骤进行求解。
(1) 随机将向量$w=({{w}_{1}},{{w}_{2}},...,{{w}_{n}})$初始化为初始参数值。
(2) 在${{w}_{1}},{{w}_{2}},...,{{w}_{n}}$中依次将${{w}_{i}},i=1,2,...,n$选择为变量并将其他参数固定为常量,然后求目标函数关于$w_i$的导数并令其为0求得$w_i$。
(3) 重复执行步骤(2)直到目标函数收敛或者误差小于某一阈值结束。
例如在上面这个示例中$w_1$和$w_2$的求解表达式分别为
$$ \begin{aligned} & w_{1}^{\text{new}}=-2w_{1}^{\text{old}}+w_2^{\text{old}}+1 \\[1ex] & w_{2}^{\text{new}}=-9w_{2}^{\text{old}}+w_1^{\text{new}}-4 \end{aligned}\tag{10-131} $$那么在初始化一组$w_{1}^{\text{old}}$和$w_{2}^{\text{old}}$后,便可以通过式(10-131)来迭代以便求解得到$w_1$和$w_2$的解。
同时,上述步骤(2)对于$w_i$顺序的选择这里采用了最为简单的按顺序依次进行,一种更优的做法便是每次选择余下常量中能够使目标函数产生最大增量的参数作为优化对象。
10.9.2 SMO算法原理#
根据10.7.3节中式(10-106)可知,SVM软间隔最终需要求解的目标函数为
$$ \begin{aligned}& \underset{\alpha }{\mathop{\max }}\sum_{i=1}^m{{\alpha }_{i}}-\frac{1}{2}\sum\limits_{i,j=1}^{m}{{{y}^{(i)}}{{y}^{(j)}}{{\alpha }_{i}}{{\alpha }_{j}}}{{({{x}^{(i)}})}^{T}}{{x}^{(j)}} \\[1ex]\text{s}.\text{t}.\ \ &0\le {{\alpha }_{i}}\le C,\ i=1,2,...,m\\[2ex]&\sum\limits_{i=1}^{m}{{{\alpha }_{i}}}{{y}^{(i)}}=0 \\\end{aligned}\tag{10-132} $$假设随机初始化后的$\alpha_i$均满足式(10-132)中的约束条件,现在通过坐标上升算法来求解$\alpha$。如果此时将${{\alpha }_{2}},...,{{\alpha }_{m}}$固定为常量,将$\alpha_1$ 固定为变量来求解$\alpha_1$ ,则能求解得到$\alpha_1$吗?答案是不能[2]。因为根据式(10-132)中第2个约束条件有
$$ \alpha_1y^{(1)}=-\sum_{i=2}^m\alpha_iy^{(i)}\tag{10-133} $$进一步,在式(10-133)两边同时乘上${{y}^{(1)}}$有
$$ \alpha_1=-y^{(1)}\sum_{i=2}^m\alpha_iy^{(i)}\tag{10-134} $$根据式(10-134)可知,${{\alpha }_{1}}$完全取决于${{\alpha }_{2}},...,{{\alpha }_{m}}$,如果${{\alpha }_{2}},...,{{\alpha }_{m}}$固定,也就意味着${{\alpha }_{1}}$也是固定的,因此,在这样的情况下每次至少需要同时选择两个参数为变量,同时再固定其他参数为常量,才能够最终求得所有参数。
此时,假设固定${{\alpha }_{3}},...,{{\alpha }_{m}}$不变来求解参数${{\alpha }_{1}}$和${{\alpha }_{2}}$。根据式(10-132)中的约束条件有
$$ {{\alpha }_{1}}{{y}^{(1)}}+{{\alpha }_{2}}{{y}^{(2)}}=-\sum\limits_{i=3}^{m}{{{\alpha }_{i}}}{{y}^{(i)}}\tag{10-135} $$由于此时式(10-135)右边是固定的,因此可以用一个常数$\zeta$来表示
$$ {{\alpha }_{1}}{{y}^{(1)}}+{{\alpha }_{2}}{{y}^{(2)}}=\zeta \tag{10-136} $$进一步,可以将${{\alpha }_{1}}$表示为
$$ {{\alpha }_{1}}=(\zeta -{{\alpha }_{2}}{{y}^{(2)}}){{y}^{(1)}}\tag{10-137} $$此时,式(10-132)中的目标函数便可以改写为
$$ W({{\alpha }_{1}},{{\alpha }_{2}},...,{{\alpha }_{m}})=W((\zeta -{{\alpha }_{2}}{{y}^{(2)}}){{y}^{(1)}},{{\alpha }_{2}},...,{{\alpha }_{m}})\tag{10-138} $$在式(10-138)中,由于此时将${{\alpha }_{3}},...,{{\alpha }_{m}}$固定为常数,因此其可以简单地表示为一个关于$\alpha_2$的一元二次 多项式,这一点也可以从式(10-84)中看出。
$$ a\alpha _{2}^{2}+b{{\alpha }_{2}}+c\tag{10-139} $$接着,对于多项式(10-139)来讲通过令${{\alpha }_{2}}$的导数为0便可以轻易求得${{\alpha }_{2}}$的取值,然后将${{\alpha }_{2}}$代入式(10-136)即可得到${{\alpha }_{1}}$的值。进一步,按照相同的过程便可求得${{\alpha }_{3}},...,{{\alpha }_{m}}$的值,最后重复执行上述整个过程便可以迭代求解得到$\alpha_1,\alpha_2,...,\alpha_m$的值。
以上就是SMO算法求解的主要思想。虽然看起来不太复杂,但是里面仍旧有很多值得深究的内容,下面开始正式介绍SMO算法的原理。
10.9.3 SMO算法求解SVM原理#
为了更加广义地表示SVM软间隔中的优化问题,可以通过如下形式来表示待求解的优化问题
$$ \begin{aligned}& \underset{\alpha }{\mathop{\max }}\sum_{i=1}^m{{\alpha }_{i}}-\frac{1}{2}\sum\limits_{i,j=1}^{m}{{{y}^{(i)}}{{y}^{(j)}}{{\alpha }_{i}}{{\alpha }_{j}}}K({{x}^{(i)}},{{x}^{(j)}}) \\[1ex]\text{s}.\text{t}.\ \ &0\le {{\alpha }_{i}}\le C,\ i=1,2,...,m \\[2ex]& \sum\limits_{i=1}^{m}{{{\alpha }_{i}}}{{y}^{(i)}}=0 \\\end{aligned}\tag{10-140} $$其中$K(\cdot)$为任意核函数。
进一步,不失一般性,这里假设首先将参数${{\alpha }_{1}}$和${{\alpha }_{2}}$选择为变量,将其他参数固定为常量。于是式(10-140)便可以改写成如下形式[6]
$$ \begin{aligned}& \underset{{\alpha_1},{\alpha_2}}{\mathop{\max }}\,{{\alpha}_{1}}+{{\alpha}_{2}}-\frac{1}{2}\alpha _{1}^{2}{{K}_{11}}-{{\alpha }_{1}}{{\alpha }_{2}}{{y}^{(1)}}{{y}^{(2)}}{{K}_{12}}-{{\alpha }_{1}}{{y}^{(1)}}\sum_{i=3}^m{{\alpha }_{i}}{{y}^{(i)}}{{K}_{1i}} \\[1ex]&\;\;\;\;\;\;\;\; -\frac{1}{2}\alpha _{2}^{2}{{K}_{22}}-{{\alpha }_{2}}{{y}^{(2)}}\sum_{i=3}^m{{\alpha }_{i}}{{y}^{(i)}}{{K}_{2i}}+{{\Psi }_{\text{constant}}} \\[1ex]& \text{s}.\text{t}.\ \ 0\le {{\alpha }_{i}}\le C,\ i=1,2 \\[1ex]& {{\alpha }_{1}}{{y}^{(1)}}+{{\alpha }_{2}}{{y}^{(2)}}=-\sum\limits_{i=3}^{m}{{{\alpha }_{i}}}{{y}^{(i)}}=\zeta\end{aligned}\tag{10-141} $$其中${{K}_{ij}}=K({{x}^{(i)}},{{x}^{(j)}})$,${{\Psi }_{\text{constant}}}$表示与$\alpha_1$和$\alpha_2$无关的常量。
同时,记
$$ \begin{aligned}& g(x)=\sum\limits_{i=1}^{m}{{{\alpha }_{i}}}{{y}^{(i)}}K(x,{{x}^{(i)}})+b \\& {{v}_{i}}=\sum\limits_{j=3}^{m}{{{\alpha }_{j}}}{{y}^{(j)}}K({{x}^{(i)}},{{x}^{(j)}})=g({{x}^{(i)}})-\sum_{j=1}^2{{\alpha }_{j}}{{y}^{(j)}}K({{x}^{(i)}},{{x}^{(j)}})-b,\ \ i=1,2 \\\end{aligned}\tag{10-142} $$则目标函数(10-141)可以改写为
$$ \begin{aligned} & W({{\alpha }_{1}},{{\alpha }_{2}})={{\alpha }_{1}}+{{\alpha }_{2}}-\frac{1}{2}\alpha _{1}^{2}{{K}_{11}}-{{\alpha }_{1}}{{\alpha }_{2}}{{y}^{(1)}}{{y}^{(2)}}{{K}_{12}}-{{\alpha }_{1}}{{y}^{(1)}}{{v}_{1}} \\ & \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\; -\frac{1}{2}\alpha _{2}^{2}{{K}_{22}}-{{\alpha }_{2}}{{y}^{(2)}}{{v}_{2}}+{{\Psi }_{\text{constant}}} \\[1ex] \end{aligned}\tag{10-143} $$将${{\alpha }_{1}}=(\zeta -{{\alpha }_{2}}{{y}^{(2)}}){{y}^{(1)}}$代入式(10-143)便可以得到一个只含有变量$\alpha_2$的目标函数
$$ \begin{aligned} W({{\alpha }_{2}}) & =(\zeta -{{\alpha }_{2}}{{y}^{(2)}}){{y}^{(1)}}+{{\alpha }_{2}}-\frac{1}{2}{{(\zeta -{{\alpha }_{2}}{{y}^{(2)}})}^{2}}{{K}_{11}} \\[1ex] & -(\zeta -{{\alpha }_{2}}{{y}^{(2)}}){{\alpha }_{2}}{{y}^{(2)}}{{K}_{12}}-(\zeta -{{\alpha }_{2}}{{y}^{(2)}}){{v}_{1}}-\frac{1}{2}\alpha _{2}^{2}{{K}_{22}}-{{\alpha }_{2}}{{y}^{(2)}}{{v}_{2}} \end{aligned}\tag{10-144} $$进一步,式(10-144)关于$\alpha_2$的导数为
$$ \begin{aligned} \frac{\partial W}{\partial {{\alpha }_{2}}} & =-{{y}^{(1)}}{{y}^{(2)}}+1+\zeta {{y}^{(2)}}{{K}_{11}}-{{\alpha }_{2}}{{K}_{11}}+2{{\alpha }_{2}}{{K}_{12}} \\[1ex] & -\zeta {{y}^{(2)}}{{K}_{12}}+{{v}_{1}}{{y}^{(2)}}-{{\alpha }_{2}}{{K}_{22}}-{{y}^{(2)}}{{v}_{2}} \end{aligned}\tag{10-145} $$令式(10-145)为0,可以得到
$$ {{\alpha }_{2}}=\frac{{{y}^{(2)}}\left( {{y}^{(2)}}-{{y}^{(1)}}+\zeta {{\text{K}}_{11}}-\zeta {{\text{K}}_{12}}+{{v}_{1}}-{{v}_{2}} \right)}{{{K}_{11}}-2{{K}_{12}}+{{K}_{22}}}\tag{10-146} $$此时,记
$$ \begin{aligned} & \eta ={{K}_{11}}-2{{K}_{12}}+{{K}_{22}} \\[1ex] & {{E}_{i}}=g({{x}^{(i)}})-{{y}^{(i)}}=\left( \sum\limits_{j=1}^{m}{{{\alpha }_{j}}}{{y}^{(j)}}K({{x}^{(i)}},{{x}^{(j)}})+b \right)-{{y}^{(i)}},\ \ i=1,2 \\ \end{aligned}\tag{10-147} $$那么在初始化一组$\alpha _{1}^{\text{old}}$和$\alpha _{2}^{\text{old}}$后,将式(10-147)和$\zeta =\alpha _{1}^{\text{old}}{{y}^{(1)}}+\alpha _{2}^{\text{old}}{{y}^{(2)}}$代入式(10-146)有
$$ \begin{aligned} \alpha _{2}^{\text{new}}=&\frac{{{y}^{(2)}}}{\eta }[{{y}^{(2)}}-{{y}^{(1)}}+\left( \alpha _{1}^{\text{old}}{{y}^{(1)}}+\alpha _{2}^{\text{old}}{{y}^{(2)}} \right){{K}_{11}}-\\[1ex] &( \alpha _{1}^{\text{old}}{{y}^{(1)}}+\alpha _{2}^{\text{old}}{{y}^{(2)}} ){{K}_{12}}+g({{x}_{1}})-\sum\limits_{j=1}^{2}{\alpha _{j}^{\text{old}}}{{y}^{(j)}}{{K}_{1j}}-\\[1ex] &b-g({{x}_{2}})+\sum\limits_{j=1}^{2}{\alpha _{j}^{\text{old}}}{{y}^{(j)}}{{K}_{2j}}+b ] \end{aligned}\tag{10-148} $$将式(10-148)进一步化简后可得
$$ \alpha_2^{\text{new}}=\alpha_2^{\text{old}}+\frac{y^{(2)}(E_1-E_2)}{\eta}\tag{10-149} $$至此,便初步求得了$\alpha_2$的求解表达式。为什么是初步呢?因为此时求得的$\alpha_2$还没有经过约束条件裁剪。
由式(10-141)中的第1个约束条件可知,$\alpha_1$和$\alpha_2$的解只能位于$[0,C]\times[0,C]$这个正方形盒子中。进一步,由式(10-141)中的第2个约束条件可知,$\alpha_1$和$\alpha_2$还必须位于平行于盒子对角线的线段上,如图10-16所示。
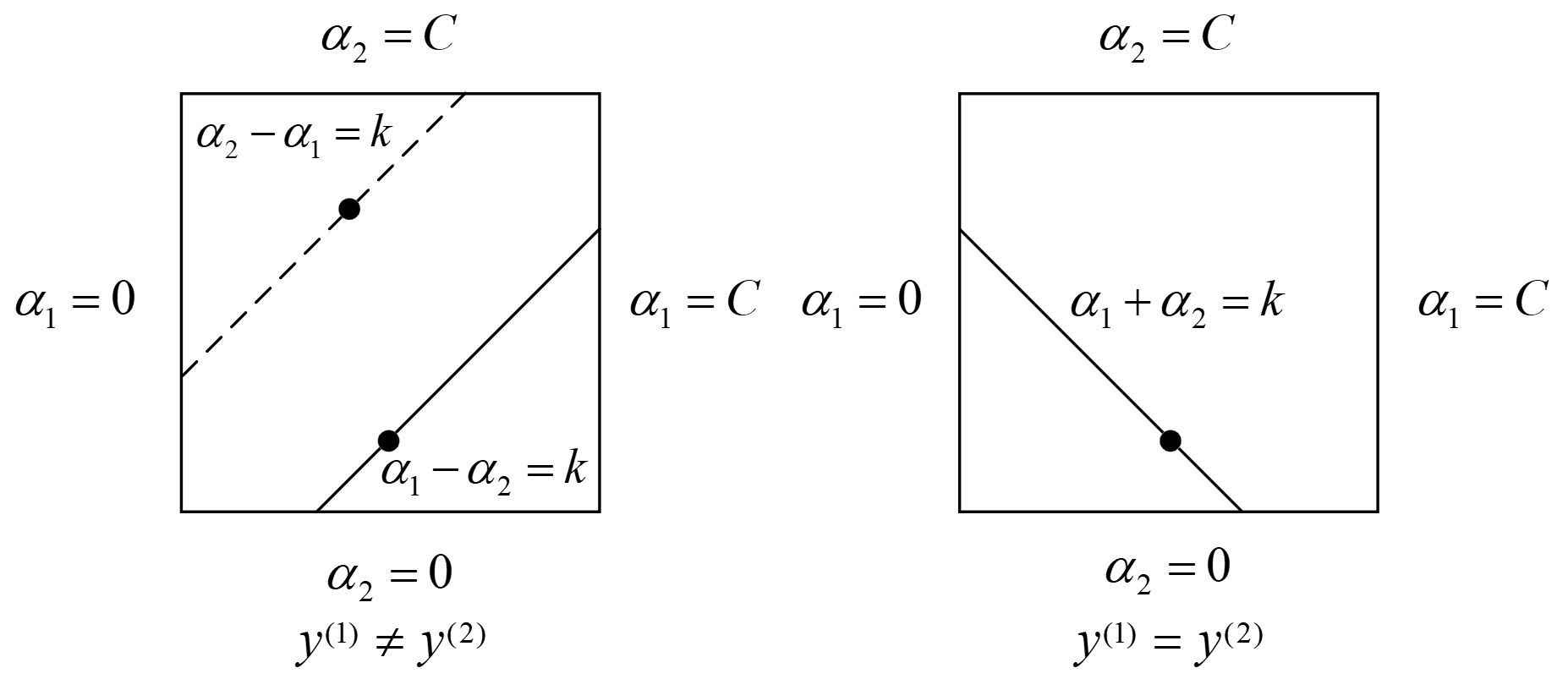
如图10-16所示,$\alpha_1$和$\alpha_2$的解只能位于盒子内部的线段上,因此还需要使$\alpha _{2}^{\text{new}}$满足
$$ L\le \alpha _{2}^{\text{new}}\le H\tag{10-150} $$其中,$L$与$H$是图10-16中线段的两个端点,即下界和上界。
从图10-16可以看出,如果${{y}^{(1)}}\ne {{y}^{(2)}}$时两种情况:
① 当 $y^{(1)}=1,y^{(2)}=-1$时有 $\alpha_1-\alpha_2=k$,此时线段与 $\alpha_2=0$ 相交处为 $L=0$ ,与 $\alpha_1=C$ 相交处为 $H=C+\alpha _{2}^{\text{old}}-\alpha _{1}^{\text{old}}$ ;
② 当 $y^{(1)}= -1,y^{(2)}=1$时有 $\alpha_2-\alpha_1=k$,此时线段与 $\alpha_1=0$ 相交处为 $L=\alpha _{2}^{\text{old}}-\alpha _{1}^{\text{old}}$ , 与 $\alpha_2=C$ 相交处为 $H=C$ 。
因为 $L$ 和 $H$ 分别为线段的下界和上界,所以有
$$ L=\max (0,\alpha _{2}^{\text{old}}-\alpha _{1}^{\text{old}}),\;\;\;\;H=\min (C,C+\alpha _{2}^{\text{old}}-\alpha _{1}^{\text{old}})\tag{10-151} $$同理可得,如果${{y}^{(1)}}= {{y}^{(2)}}$则有
$$ L=\max (0,\alpha _{2}^{\text{old}}+\alpha _{1}^{\text{old}}-C),\;\;\;\;H=\min (C,\alpha _{2}^{\text{old}}+\alpha _{1}^{\text{old}})\tag{10-152} $$因此,$\alpha _{2}^{\text{new}}$裁剪后的值应该为
$$ \alpha _{2}^{\text{new},\text{clipped}}= \begin{cases} H,\; \alpha _{2}^{\text{new}}\ge H \\[1ex] \alpha _{2}^{\text{new}},\; L < \alpha _{2}^{\text{new}} < H \\[1ex] L,\; \alpha _{2}^{\text{new}}\le L \end{cases} \tag{10-153} $$进一步,由${{\alpha }_{1}}=(\zeta -{{\alpha }_{2}}{{y}^{(2)}}){{y}^{(1)}}$和$\zeta =\alpha _{1}^{\text{old}}{{y}^{(1)}}+\alpha _{2}^{\text{old}}{{y}^{(2)}}$可得
$$ \begin{aligned} \alpha _{1}^{\text{new}}&=(\alpha _{1}^{\text{old}}{{y}^{(1)}}+\alpha _{2}^{\text{old}}{{y}^{(2)}}-\alpha _{2}^{\text{new},\text{clipped}}{{y}^{(2)}}){{y}^{(1)}} \\[1ex] & =\alpha _{1}^{\text{old}}+{{y}^{(1)}}{{y}^{(2)}}(\alpha _{2}^{\text{old}}-\alpha _{2}^{\text{new},\text{clipped}}) \end{aligned}\tag{10-154} $$至此就介绍完了${{\alpha }_{1}}$和$\alpha_2$的求解步骤。进一步,可以按照类似的方法求解得到${{\alpha }_{3}},...,{{\alpha }_{m}}$,最后迭代整个过程便可以求解得到${{\alpha }_{1}},{{\alpha }_{2}},...,{{\alpha }_{m}}$的最优解。
10.9.4 偏置$b$求解#
在每次计算得到${{\alpha}_{i}}$和$\alpha_j$两个变量后,都需要同步地更新偏置$b$的值。例如当求得$0 < \alpha _{1}^{\text{new}} < C$时,根据式(10-118)中的第3个条件可知
$$ {{y}^{(1)}}({{w}^{T}}{{x}^{(1)}}+b)={{y}^{(1)}}g({{x}^{(1)}})={{y}^{(1)}}\left( \sum\limits_{i=1}^{m}{{{\alpha }_{i}}}{{y}^{(i)}}{{K}_{1i}}+b \right)=1\tag{10-155} $$进一步,可得
$$ \sum_{i=1}^m\alpha_iy^{(i)}K_{1i}+b=y^{(1)}\tag{10-156} $$于是根据式(10-156)有
$$ b_{1}^{\text{new}}={{y}^{(1)}}-\sum_{i=3}^m{{\alpha }_{i}}{{y}^{(i)}}{{K}_{1i}}-\alpha _{1}^{\text{new}}{{y}^{(1)}}{{K}_{11}}-\alpha _{2}^{\text{new},\text{clipped}}{{y}^{(2)}}{{K}_{12}}\tag{10-157} $$由式(10-147)中$E_i$的定义可知
$$ {{E}_{1}}=\sum_{i=3}^m{{\alpha }_{i}}{{y}^{(i)}}{{K}_{1i}}+\alpha _{1}^{\text{old}}{{y}^{(1)}}{{K}_{11}}+\alpha _{2}^{\text{old}}{{y}^{(2)}}{{K}_{12}}+{{b}^{\text{old}}}-{{y}^{(1)}}\tag{10-158} $$根据式(10-158)可知,式(10-157)的前两项可以改写为
$$ {{y}^{(1)}}-\sum_{i=3}^{m}{{{\alpha }_{i}}}{{y}^{(i)}}{{K}_{1i}}={{b}^{\text{old}}}-{{E}_{i}}+\alpha _{1}^{\text{old}}{{y}^{(1)}}{{K}_{11}}+\alpha _{2}^{\text{old}}{{y}^{(2)}}{{K}_{12}}\tag{10-159} $$最后,将式(10-159)代入式(10-157)可得
$$ b_{1}^{\text{new}}={{b}^{\text{old}}}-{{E}_{1}}-{{y}^{(1)}}{{K}_{11}}(\alpha _{1}^{\text{new}}-\alpha _{1}^{\text{old}})-{{y}^{(2)}}{{K}_{12}}(\alpha _{2}^{\text{new},\text{clipped}}-\alpha _{2}^{\text{old}})\tag{10-160} $$同理可得,当$0 < \alpha _{2}^{\text{new},\text{clipped}} < C$时有
$$ b_{2}^{\text{new}}={{b}^{\text{old}}}-{{E}_{2}}-{{y}^{(1)}}{{K}_{12}}(\alpha _{1}^{\text{new}}-\alpha _{1}^{\text{old}})-{{y}^{(2)}}{{K}_{22}}(\alpha _{2}^{\text{new},\text{clipped}}-\alpha _{2}^{\text{old}})\tag{10-161} $$同时,当$\alpha _{1}^{\text{new}}$和$\alpha _{2}^{\text{new},\text{clipped}}$同时满足条件时,$b_{1}^{\text{new}}$和$b_{2}^{\text{new}}$均是有效的,并且两者相等。如果$\alpha _{1}^{\text{new}}$和$\alpha _{2}^{\text{new},\text{clipped}}$为0或者$C$,则所有在$b_{1}^{\text{new}}$和$b_{2}^{\text{new}}$之间的值均为满足KKT条件的值,此时选择两者的均值作为$b^{\text{new}}$。因此偏置$b$的计算公式为
$$ {{b}^{\text{new}}}= \begin{cases} b_{1}^{\text{new}},\ 0 < \alpha _{1}^{\text{new}} < C\\[1ex] b_{2}^{\text{new}},\ 0 < \alpha _{2}^{\text{new},\text{clipped}} < C\\[1ex] (b_{1}^{\text{new}}+b_{2}^{\text{new}})/2,\ \text{其它} \end{cases}\tag{10-162} $$最后,需要注意的是在上述求解过程中,最终得到$w$的解是唯一的,而偏置$b$的解却可能不唯一(它存在于一个区间中),详细证明过程可以参见《数据挖掘中的新方法——支持向量机》第5.3节中的介绍[9]。当然,除了理论上的证明还可从另外一个更直观的角度来理解。如果$w$唯一而$b$不唯一,也就意味着决策面并不唯一,而这在SVM软间隔中显然是成立的。因为此时允许个别样本被分类错误,但是这些被错分的样本是不确定的。也就是说,在这样的情况下可以存在不同的分类决策面,而它们的分类间隔却相同。
10.9.5 SVM算法求解示例#
经过10.9.3节和10.9.4两节内容的介绍,相信各位读者对于如何通过SMO算法来求解SVM中的参数已经有了一定的了解。同时,对于整个求解过程还可以通过如下一段伪代码进行表示[2]。
输入为
(1) $C$: 惩罚项系数。
(2) $\text{tol}$: 误差容忍度。
(3) $\text{max\_passes}$ : 当$\alpha_i$ 不再发生变化时继续迭代更新的最大次数。
(4) $(({{x}^{(1)}},{{y}^{(1)}}),...,({{x}^{(m)}},{{y}^{(m)}}))$: 训练集。
输出为
(1) $\alpha\in\mathbb{R}^m$: 求解得到的拉格朗日乘子。
(2) $b\in\mathbb{R}$: 求解得到的偏置。
示例伪代码如下:
1 初始化所有 alpha_i = 0, b = 0, passes = 0
2 while (passes < max_passes)
3 num_changed_alphas = 0
4 for i = 1,...,m
5 计算 E_i
6 if ((y_i*E_i < -tol and a_i < C)||(y_i*E_i > tol and alpha_i > 0))
7 随机选择j,且j不等于i
8 计算 E_j
9 保存:alpha_i_old = alpha_i,alpha_j_old = alpha_j
10 计算 L 和 H
11 if (L == H):
12 continue
13 计算 eta
14 if (eta <= 0):
15 continue
16 计算 alpha_j并裁剪
17 if (|alpha_j - alpha_j_old| < 10e-5):
18 continue
19 分别计算alpha_i, b_1, b_2
20 计算b
21 num_changed_alphas += 1
22 if (num_changed_alphas == 0):
23 passes += 1
24 else:
25 passes = 0当然,根据上述伪代码的描述,还可以通过代码将其完整地实现,具体可以参见 AllBooKCode/Chapter10/C14_svm_smo.py 文件。同时,根据实现的代码,如果以10.7.4节中图10-14里的数据样本为输入,并且将惩罚系数设为C=0.2,则最终的求解结果为
1 data_x = np.array([[5, 1], [0, 2], [1, 5], [3.0, 2], [1, 2], [3, 5], [1.5, 6], [4.5, 6], [0, 7]])
2 data_y = np.array([1, 1, 1, 1, 1, -1, -1, -1, -1])
3 alphas, b = smo(C=.2, tol=0.001, max_passes=200, data_x=data_x, data_y=data_y)
4 print(alphas) #[0. 0. 0.2 0.142 0. 0.2 0.142 0. 0.]
5 print(b)#2.66
6 w = compute_w(data_x,data_y,alphas)
7 print(w)#[-0.186, -0.569]根据上述输出结果可知,$\alpha_3=\alpha_6=0.2$,以及$\alpha_4=\alpha_7=0.142$,即对应的支持向量为(1,5)、(3,5)、(3,2)、(1.5,6),并且同时$w=(-0.186,-0.569)$,并且$b=2.66$。需要注意的是,为了作图方便,图10-14中左右两边各自还有两个样本点没有画出,所以在上述代码中有9个样本。
10.9.6 小结#
在本节中,我们首先以坐标上升算法为铺垫,介绍了SMO算法的基本思想,从整体层面上阐述了SMO算法的求解过程,然后详细介绍了SMO算法的具体求解过程及原理,包括参数$\alpha$和偏置$b$的求解方法,最后以伪代码的形式展示了SMO算法的求解过程,并通过一个实例进行了展示。在下一节内容中,我们将开始介绍如何从零实现SVM算法。