10.13 GPT-1模型#
经过「第10.2节 Transformer原理:自注意力、多头注意力与位置编码」和「第10.6节 BERT原理:双向编码器预训练模型解析」内容的介绍,我们对基于多头注意力机制的网络模型已经有了深刻的认识。根据第10.6节内容可知,BERT模型本质上只是一个基于Transformer编码器的网络结构,它通过多层多头注意力机制来对输入序列进行编码并完成后续下游任务。这种通过对整个文本序列同时进行编码理解并完成后续下游任务的过程我们称之为自然语言理解。在接下来几节内容中,我们将会介绍另外一种以自然语言生成方式来进行建模的网络模型。
10.13.1 GPT-1动机#
在第9章内容开始我们介绍到自然语言处理可以分为自然语言理解和自然语言生成两大部分。对于自然语言理解来说它包括的场景有文本蕴含、问题回答和文本分类等,并且对于这类任务来说它们都有两个共同的地方——特定任务下的网络结构和高质量的标注数据。在传统的判别式模型训练过程中——例如RNN、CNN这类分类模型——标注数据总是一件成本高昂的事情,但与此同时却又存在着海量的非标注数据却无法有效利用。从BERT模型的预训练过程我们知道,如果能通过合理的预训练任务使用无标签数据来训练一个通用的预训练模型,然后分别在每个特定的下游任务中进行有监督微调将会有效改善标注数据不足的问题。
基于这样的动机,2018年6月OpenAI团队拉德福德(Radford)[1]等人以Transformer中解码器为基础提出了一种通过自然语言生成方式来进行建模的预训练语言模型(Generative Pretrained Transformer, GPT),而这也是第1代GPT模型,下称GPT-1。GPT-1模型的核心思想在于它首先使用生成式任务在大规模未标记的文本语料上进行预训练,使模型学习到通用的结构、语法、语义等信息;然后在下游任务上通过有监督的方式进行参数微调以实现模型的迁移运用,并且通过特定的输入方式实现了模型结构调整的最小化。这里需要注意的一点是,GPT-1模型的提出时间要早于BERT模型。最后,实验表明GPT-1在12个任务场景中有9个任务的结果超越了传统完全以有监督方式训练的网络模型。
10.13.2 GPT-1结构#
1. 预训练阶段
类似于BERT网络模型,GPT-1模型也分为预训练和微调两个部分,不同的地方在于GPT-1模型是以Transformer中的解码器为基础构建得到的标准语言模型,即在模型预训练过程中通过以前$k$个字符来预测第$k+1$个字符的方式来训练模型。具体地,假设给定语料$\mathcal{U}=\{u_1,...,u_n\}$,则模型将最大化如下目标函数
$$ L_1(\mathcal{U})=\sum_{i=k+1}^n\log P(u_i|u_{i-k},u_{i-k+1},...,u_{i-1};\Theta) \tag{10-12} $$其中$k$表示预训练任务中构建样本时的窗口大小,$\Theta$表示模型参数,这里相加是因为取$\log$后的缘故。
同时,整个模型的前向传播计算过程为
$$ \begin{aligned} h_0&=UW_e+W_p\\[1ex] h_l&=\text{transformer\_block}(h_{l-1}), \forall\;l\in[1,L]\\[1ex] P(u)&=\text{softmax}(h_L,W^T_e) \end{aligned}\tag{10-13} $$其中$U$为输入文本序列对应的词表索引形状为[src_len, batch_size],$W_e$为字符嵌入层对应的权重参数形状为[vocab_size, hidden_size],$W_p$为位置编码层对应的权重参数形状为[max_position_embeddings, hidden_size],$L$表示解码器的层数,$h_l$为解码器第$l$层的输出结果形状为[tgt_len, batch_size, hidden_size],$h_L$为最后一层的输出结果,而$P(u)$则是对应每个时刻预测结果的概率分布。这里需要注意的是此处的位置编码同样是可训练的模型参数,而非原始Transformer中的公式变换。
最后,在大规模语料上根据上述过程利用梯度下降算法便可以训练得到对应的预训练模型。
2. 微调阶段
在预训练阶段结束以后,我们便可以通过如下过程来针对特定任务场景进行模型参数的微调。现假设某下游任务的输入序列为$x^1,x^2,...,x^m$,对应标签为集合$\mathcal{C}$,则需最大化如下目标函数
$$ \begin{aligned} &P(y|x^1,x^2,...,x^m)=\text{softmax}(h^m_L,W_y)\\[1ex] &L_2(\mathcal{C})=\sum_{(x,y)}\log P(y|x^1,x^2,...,x^m)\\[1ex] &L_3(\mathcal{C})=L_2(\mathcal{C})+\lambda*L_1(\mathcal{C}) \end{aligned}\tag{10-14} $$其中$h^m_L$表示第$L$层最后一个位置的输出结果,$W_y$为最后分类层对应的权重参数,$\lambda$为平衡目标函数$L_1$和$L_2$的一个超参数。之所以这样构造目标函数一是为了提高模型的泛化性,二是为了加速模型的收敛速度。
同时,在传统的深度学习模型中对于不同的下游任务场景均需要修改网络结构以满足不同形式的输入。GPT-1为了解决这一问题采用了一种统一的输入形式,即将所有待输入部分以特殊字符进行分割构造成一个序列作为模型的输入,并且整个序列的首尾以<s>和<e>进行标识
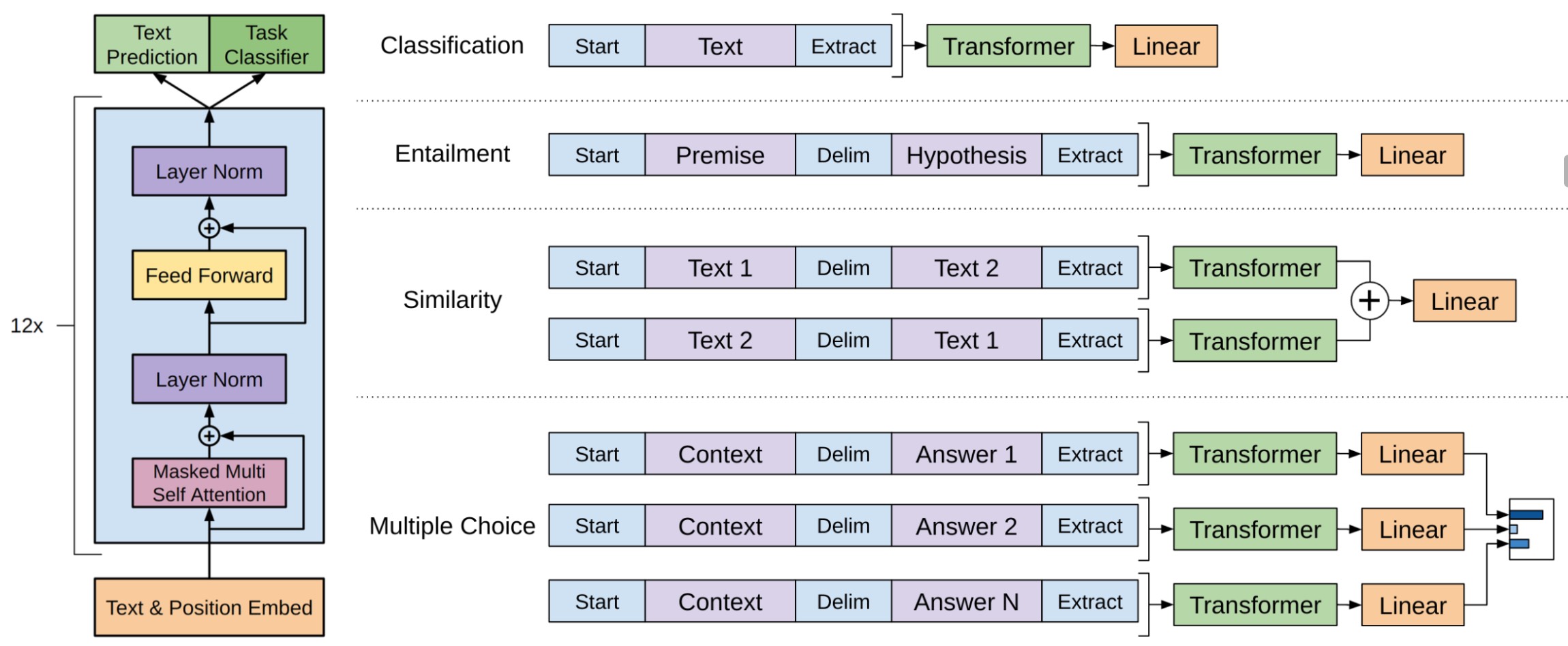
如图10-41所示为4种常见下游任务场景的输入构建方式。对于文本分类任务来说可以直接取最后一个时刻的生成结果进行分类即可;对于文本蕴含任务来说可以将描述和假设拼接成一个序列,并且两者之间用特殊分隔符标识,然后再将其输入到GPT-1模型中进行特征提取并取最后一个时刻的生成结果进行分类;对于相似性比较任务来说可以分别以不同的顺序将两个序列拼接到一起,且两者中间同样用分隔符标识,然后分别将两者经GPT-1特征提取后的向量按位相加进行分类即可;对于问题选择任务来说分别将上下文与不同的选项构造形成一个序列,并且上下文与选项之间同样以特殊分隔符标识,然后分别通过GPT-1进行特征提取完成分类即可,细节可以参考「第10.10节 BERT问答模型:阅读理解任务建模方法」内容。可以看出BERT模型中在构造不同下游任务的输入时也参考借鉴了GPT-1的处理方式。
同时,对于问题回答和阅读理解这类任务来说,给定上下文$z$,问题$q$以及一系列答案选项$\{a_k\}$,我们只需要将它们拼接在一起中间用特殊分隔符标识,即$[z;q;a_k]$,然后输入到模型中进行分类。
10.13.3 GPT-1实现#
在介绍完GPT-1的相关原理后我们再来看如何借助PyTorch从零实现一个简单版GPT-1模型。从整体上来看GPT-1模型是基于Transformer解码器的多层网络结构,同时由于没有了与编码器交互的部所以此时解码器中将只有一个带掩码的多头注意力机制模块。基于「第10.3节 Transformer结构:编码器解码器整体架构解析」内容中已经实现的多头注意力机制,我们下面先实现GPT-1中的解码器。本节内容完整示例代码可参见Code/Chapter10/C05_ToyGPT文件。
1. 解码器实现
同「第10.4节 Transformer实现:从模块到代码的搭建过程」内容中实现Transformer解码器逻辑一样,此处解码器我们同样通过MyTransformerDecoder和MyTransformerDecoderLayer这两个模块来构建。首先,对于MyTransformerDecoderLayer模块来说其实现过程如下所示:
1 class MyTransformerDecoderLayer(nn.Module):
2 def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
3 super(MyTransformerDecoderLayer, self).__init__()
4 self.self_attn = MyMultiheadAttention(d_model, nhead, dropout)
5 self.linear1 = nn.Linear(d_model, dim_feedforward)
6 self.linear2 = nn.Linear(dim_feedforward, d_model)
7 self.norm1 = nn.LayerNorm(d_model)
8 self.norm2 = nn.LayerNorm(d_model)
9 self.dropout1 = nn.Dropout(dropout)
10 self.dropout2 = nn.Dropout(dropout)
11 self.dropout3 = nn.Dropout(dropout)
12 self.activation = nn.ReLU()
13
14 def forward(self, tgt, tgt_mask=None, key_padding_mask=None):
15 tgt2 = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask,
16 key_padding_mask=key_padding_mask)[0]
17 tgt = self.norm1(tgt + self.dropout1(tgt2))
18 tgt2 = self.activation(self.linear1(tgt))
19 tgt2 = self.linear2(self.dropout2(tgt2))
20 return self.norm2(tgt + self.dropout3(tgt2))在上述代码中,第4行是实例化一个多头注意力机制对象,详细介绍可参见第10.3节内容。第5~12行是实例化相关的全连接层和归一化类对象。第14行中tgt是多头注意力模块的序列输入形状为[tgt_len,batch_size, embed_dim];tgt_mask为注意力掩码矩阵用于掩盖当前时刻之后的信息形状为[tgt_len, tgt_len];key_padding_mask为填充掩码向量用于掩盖每个序列填充部分的信息形状为[batch_size, tgt_len]。第15~20行则是对应各部分的前向传播过程。
进一步,对于多层解码器的实现如下所示:
1 class MyTransformerDecoder(nn.Module):
2 def __init__(self, decoder_layer, num_layers, norm=None):
3 super(MyTransformerDecoder, self).__init__()
4 self.layers = _get_clones(decoder_layer, num_layers)
5 self.num_layers = num_layers
6 self.norm = norm
7
8 def forward(self, tgt, tgt_mask=None, key_padding_mask=None):
9 output = tgt
10 for layer in self.layers:
11 output = layer(output, tgt_mask, key_padding_mask)
12 if self.norm is not None:
13 output = self.norm(output)
14 return output 在上述代码中,第4行是根据参数实例化多个解码层,即多个MyTransformerDecoderLayer类对象。第10~11行是多个解码层的前向传播计算过程。第14行则是对应解码器的输出结果形状为[tgt_len, batch_size, d_model]。
可以看出,对于上面两部分的实现过程同第10.4节内容中Transformer解码器的逻辑一致,仅仅只是去掉了编码器与解码器交互部分的多头注意力机制。最后,只需要整合这两部分便可得到GPT-1解码器的实现,示例代码如下所示:
1 class GPTDecoder(nn.Module):
2 def __init__(self, d_model=512, nhead=8, num_layers=6, dim_feedforward=2048, dropout=0.1):
3 super(GPTDecoder, self).__init__()
4 decoder_layer = MyTransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout)
5 decoder_norm = nn.LayerNorm(d_model)
6 self.decoder = MyTransformerDecoder(decoder_layer, num_layers, decoder_norm)
7 self.d_model = d_model
8 self.nhead = nhead
9
10 def forward(self, tgt, tgt_mask=None, key_padding_mask=None):
11 output = self.decoder(tgt, tgt_mask, key_padding_mask)
12 return output 在上述代码中,第2行d_model表示解码器中多头的维度也是词嵌入和解码器输出结果的维度;nhead为多头的数量;num_layers为解码层的示例;dim_feedforward为每个解码层中全连接层的维度。第4~6行是分别实例化一个解码层并克隆得到所有解码层。第11行则是返回整个解码器的输出结果形状为[tgt_len, batch_size, d_model]。
2. GPT-1模型实现
在完成GPT-1解码器的实现之后我们需要进一步将嵌入层也封装实现到一个模块中以构建整个模型。具体地,GPT-1中包含有字符嵌入和位置编码两个嵌入层,最后将两者的结果相加作为解码器的输入,示例代码如下所示:
1 class GPTModel(nn.Module):
2 def __init__(self, config=None):
3 super().__init__()
4 self.token_embed = nn.Embedding(config.n_positions, config.n_embd)
5 self.position_embed = nn.Embedding(config.vocab_size, config.n_embd)
6 self.register_buffer("position_ids",
7 torch.arange(config.n_positions).expand((1, -1)))
8 self.drop = nn.Dropout(config.dropout)
9 self.gpt_decoder = GPTDecoder(config.n_embd, config.n_head, config.n_layer,
10 config.dim_feedforward, config.dropout)
11
12 def forward(self, input_ids=None, position_ids=None, key_padding_mask=None):
13 tgt_len = input_ids.size(0)
14 token_embedding = self.token_embed(input_ids)
15 if position_ids is None:
16 position_ids = self.position_ids[:, :tgt_len]
17 position_embedding = self.position_embed(position_ids).transpose(0, 1)
18 embeddings = token_embedding + position_embedding
19 hidden_states = self.drop(embeddings)
20 tgt_mask = self.gpt_decoder.generate_square_subsequent_mask(tgt_len)
21 output = self.gpt_decoder(tgt=hidden_states, tgt_mask=tgt_mask,
22 key_padding_mask=key_padding_mask)
23 return output 在上述代码中,第4~5行是实例化两个嵌入层对象,分别为字符嵌入和位置编码。第6~7行是申明一个不可训练参数以便后续作为默认的位置编码输入值。第9~10行是实例化一个GPT-1解码器对象。第12行是GPT-1模型的输入,其中input_ids为原始输入的索引序列形状为[tgt_len, batch_size];position_ids为序列的位置编码输入,本质就是[0,1,2,3,...,tgt_len-1],形状为[1,tgt_len],key_padding_mask为序列填充的掩码向量,True表示该位置为填充值,False表示该位置为非填充值,形状为[batch_size, tgt_len],实际建模时也可以不用传入。第14~19行是得到嵌入后的输出表示结果。第20行构造得到注意力掩码矩阵形状为[tgt_len, tgt_len]。第21~23行是返回模型最终的输出结果,形状为[tgt_len, batch_size, d_model]。
在完成GPTModel部分的实现之后便可以通过如下方式进行使用:
1 if __name__ == '__main__':
2 config = Config()
3 model = GPTModel(config)
4 tgt = torch.randint(0, 100, [5, 2])
5 key_padding_mask = torch.tensor([[False, False, False, False, True],
6 [False, False, False, True, True]])
7 output = model(tgt, key_padding_mask=key_padding_mask)
8 print(output.shape) # torch.Size([5, 2, 768])3. 预训练模型
在实现完GPT-1模型后我们再来基于此实现对应的预训练模型。GPT-1中的预训练任务是一个标准的语言模型训练过程,整体来看我们只需要将GPTModel模型部分的输出结果通过一个分类层对每个位置上的向量进行分类预测即可,示例代码如下所示:
1 class GPTLMHeadModel(nn.Module):
2 def __init__(self, config=None):
3 super().__init__()
4 self.transformer = GPTModel(config)
5 self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
6
7 def forward(self, input_ids=None, position_ids=None, key_padding_mask=None, labels=None):
8 last_state = self.transformer(input_ids=input_ids, position_ids=position_ids,
9 key_padding_mask=key_padding_mask)
10 lm_logits = self.lm_head(last_state).transpose(0, 1)
11 shift_logits = lm_logits[:, :-1].contiguous()
12 shift_labels = labels.transpose(0, 1)[:, 1:].contiguous()
13 loss_fct = nn.CrossEntropyLoss()
14 loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
15 return loss,last_state在上述代码中,第4~5行便是分别实例化一个GPTModel模型类对象和分类层类对象。第7行是预训练模型的输入部分,其中input_ids为输入索引序列形状为[tgt_len, batch_size],其中这里的tgt_len便是式(10-12)中窗口的大小;key_padding_mask为填充掩码在预训练任务中由于序列长度都一致,所以保持默认为None即可;labels为预测标签,传入值和input_ids保持一致。第8~9行便是GPT-1模型的输出结果,形状为[tgt_len, batch_size, n_embd]。第10行是分类层的预测结果形状为[batch_size, tgt_len, vocab_size]。第11~14行是将预测值与标签进行对齐,然后进行损失值计算。第15行是返回损失值和解码器最后一层的输出结果。
在完成GPTLMHeadModel部分的实现后便可以通过如下方式进行使用:
1 if __name__ == '__main__':
2 config = Config()
3 model = GPTLMHeadModel(config)
4 tgt = torch.randint(0, 100, [5, 2]) # [tgt_len, batch_size]
5 output,last_state = model(tgt, labels=tgt)
6 print(output) # tensor(9.4449, grad_fn=<NllLossBackward0>)
7 print(last_state.shape) # torch.Size([5, 2, 768])4. 文本分类模型
在介绍完GPT-1模型的实现过程后,下面我们再以文本分类这个任务为例来介绍如何使用GPTModel进行建模。根据第10.13.2节内容可知,我们只需要取解码器输出最后一个位置上的结果进行分类即可。不过此时需要注意的一点是由于序列填充的存在,所以不能直接取输出结果的最后一个位置,而是要按照实际情况获取。具体地,我们首先定义对应的初始化方法,示例代码如下所示:
1 class GPTForSequenceClassification(nn.Module):
2 def __init__(self, config):
3 super().__init__()
4 self.num_labels = config.num_labels
5 self.lm_model = GPTLMHeadModel(config)
6 self.classifier = torch.nn.Linear(config.n_embd, config.num_labels)
7 self.config = config
8
9 def forward(self, input_ids=None, key_padding_mask=None, position_ids=None, labels=None):
10 lm_loss, states = self.lm_model(input_ids, position_ids, key_padding_mask, input_ids)
11 logits = self.classifier(states).transpose(0, 1)
12 real_seq_len = (key_padding_mask == False).sum(-1) - 1
13 pooled_logits = logits[range(input_ids.size(1)), real_seq_len]
14 if labels is not None:
15 loss_fct = nn.CrossEntropyLoss()
16 loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
17 if self.config.use_multi_loss:
18 loss += self.config.lamb * lm_loss
19 return loss, pooled_logits
20 else:
21 return pooled_logits 在上述代码中,第5~6行分别是实例化一个语言模型和一个分类层。第9行中input_ids为原始的文本索引序列,labels是分类标签形状为[batch_size]。第10行分别是预训练模型的损失值和解码器最后一层的输出结果。第11行是对最后一层每个位置上的输出分类后的结果,形状为[batch_size, tgt_len, num_labels]。因为这里要取每个序列最后一个位置上的概率值,而当输入多个样本时会有填充的情况,所以我们需要找到真实的最后一个位置。第12行则是用来计算每个序列对应的真实最后一个位置。第13行便是取真实位置上对应的预测概率。第14~19行是根据标签来计算模型的损失值,其中第17~18行判断是否加入预训练任务对应的损失值。
在完成GPTForSequenceClassification部分的实现后便可以通过如下方式进行使用:
1 if __name__ == '__main__':
2 config = Config()
3 model = GPTForSequenceClassification(config)
4 tgt = torch.randint(0, 100, [5, 2]) # [tgt_len, batch_size]
5 key_padding_mask = torch.tensor([[False, False, False, False, True],
6 [False, False, False, True, True]])
7 labels = torch.tensor([0, 4])
8 output = model(tgt, key_padding_mask=key_padding_mask,labels=labels)
9 print(output) 上述代码运行结束后将会看到类似如下结果:
1 (tensor(3.0855, grad_fn=<AddBackward0>),
2 tensor([[-0.2803, 0.0494, -0.7169, 0.2803, 0.6800, -0.8184, -0.6872, -0.1306,
3 0.6032, -1.0219], [-0.4553, 0.6104, -0.4035, 0.8936, 0.9481, 1.0144,
4 -0.4878, 0.2719, 0.8163, -0.7139]], grad_fn=<IndexBackward0>))10.13.4 小结#
在本节内容中,我们首先介绍了GPT模型出现的动机;然后详细介绍了GPT-1模型的原理,包括预训练阶段和模型微调阶段;最后一步一步介绍了如何基于PyTorch从零实现整个GPT-1模型,包括预训练过程和下游文本分类任务。此时我们可以发现,尽管GPT-1模型使用的是Transformer中的解码器,但是它所遵循的建模思想依旧是需要在每个下游任务中加入新的网络层来进行处理,本质上它还是一个“编码器”的角色,并没有用到模型的生成能力。在下一节内容中,我们将会介绍以GPT-1为基础改进而来的GPT-2模型。
引用#
[1] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[2] https://github.com/openai/gpt-2
[3] https://huggingface.co/docs/transformers/v4.34.1/en/tasks/language_modeling