10.9 BERT问题选择模型#
经过「第10.8节 BERT文本分类:下游任务微调实战」内容介绍之后,我们对于如何在下游任务中使用BERT预训练模型已经有了一定的认识。在本节内容中我们将会介绍如何利用BERT模型来完成推理问答选择任务,同时给模型输入一个问题和若干选项的答案,最后需要模型从给定的选项中选择一个最符合问题逻辑的答案。
通常来说,在NLP领域的大多数场景中模型最后本质上完成的都是一个分类任务。例如文本蕴含任务本质就是将两个序列拼接 在一起,然后预测其所属的类别;基于神经网络的序列生成模型(翻译、文本 生成等)本质就是预测词表中下一个最有可能出现的词,此时的分类类别就是词表的大小。因此,从本质上来看本节内容将要介绍的问答选择任务以及在后面将要介绍的问题回答任务其实都是一个分类任务,而关键的地方就在于如何构建模型的输入和输出。
10.9.1 任务构造原理#
正如上面所说,对于问答选择这个任务场景来说其本质上依旧可以归结为分类任务,只是关键在于如何构建这一任务以及整个数据集。对于问答选择这 个场景来说,其整体原理如图10-30所示。
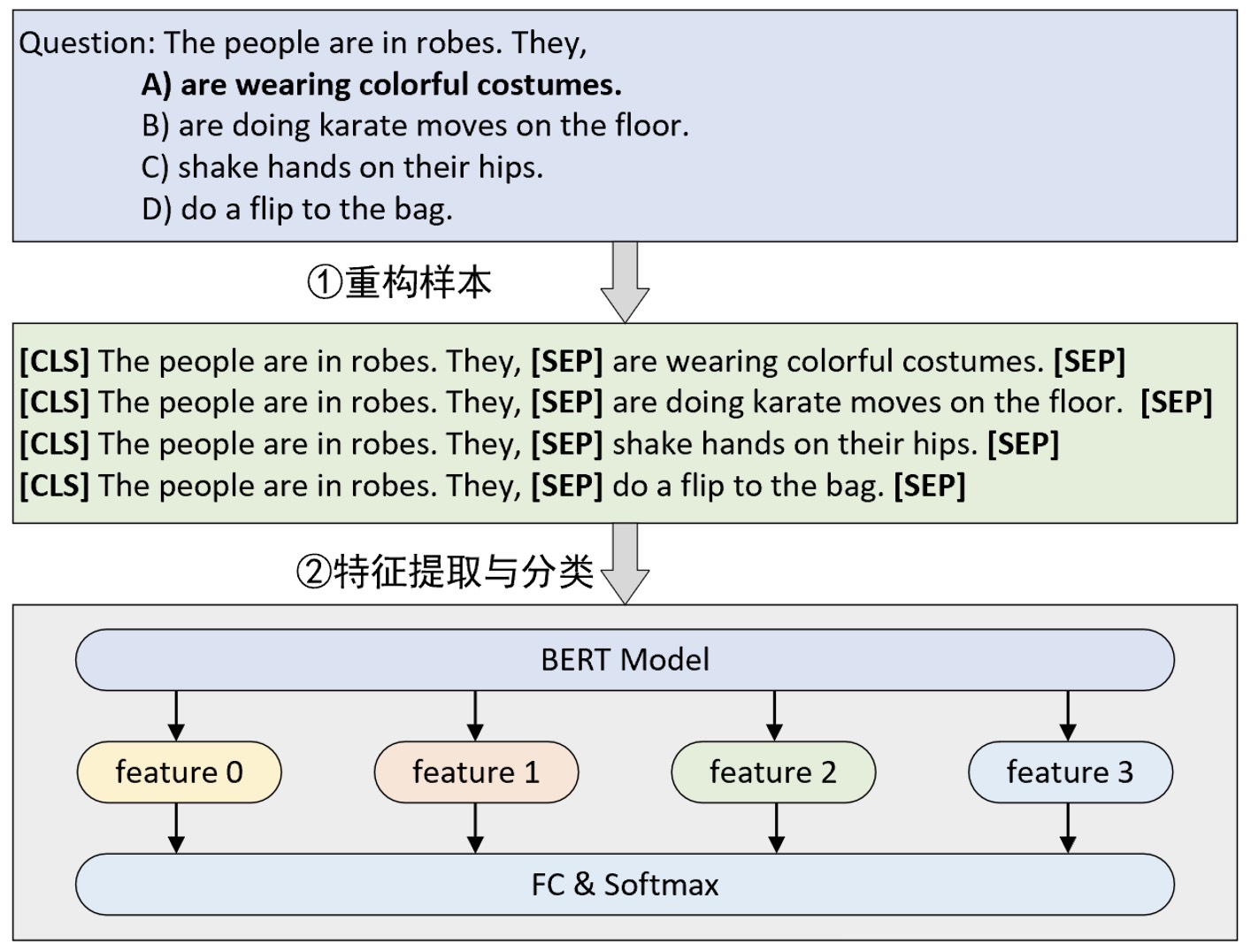
如图10-30所示是一个基于BERT预训练模型的4选1问答选择模型的原理图。从图中可以看出原始数据的形式是1个问题和4个选项,模型需要做的是从4个选项中给出一个最合理的答案,于是本质上也就变成了一个4分类任务。同时,构建模型输入的方式就是将原始问题和每一个答案拼接起来构成一个序列并且中间用[SEP]符号隔开;然后再分别输入到BERT模型中进行特征提取得到4个特征向量,此时输出形状为[4,hidden_size];最后再经过一个分类层进行分类处理得到预测选项。通常情况下这里的4个特征都是直接取每个序列经BERT编码后的[CLS]向量。
10.9.2 数据预处理#
根据上面的内容可知,对于问答任务来说其接受的输入也分为两个部分:一是由问题和每个选项这两个句子所组成的索引序列,并且需要在两个句子的开始位置加上一个[CLS]符号,以及两个句子之间和结尾分别加上一个[SEP]符号;二是句子编码部分的输入用于确定两个句子的所属部分。最后将两者均作为模型的输入即可。以下完整示例代码可参见Code/Chapter10/C04_BERT文件。
同时,这里需要注意的是虽然对于BERT模型来说“问题 + 1个选项”构成的序列就是一个样本,但是我们在构造数据集的时候还是需要将“问题 + 4个选项”看成一个整体,然后在输入模型之前再变形为对应的形状。
1. 语料介绍
在这里我们使用到的是生成对抗场景数据集(The Situations With Adversarial Generations, SWAG)[1] [2],即给定一个情景(一个问题或一句描述),任务是模型从给定的4个选项中预测最有可能的一个。
如下所示便是部分原始示例数据:
1 ,video-id,fold-ind,startphrase,sent1,sent2,gold-source, ending0,ending1, ending2,ending3,label
2 0,anetv_NttjvRpSdsI,19391,The people are in robes. They,The people are in robes.,They,gold,are wearing colorful costumes.,are doing karate moves on the floor.,shake hands on their hips.,do a flip to the bag.,0
3 1,lsmdc3057_ROBIN_HOOD-27684,16344,She smirks at someone and rides off. He,She smirks at someone and rides off.,He,gold,smiles and falls heavily.,wears a bashful smile.,kneels down behind her.,gives him a playful glance.,1在上述示例中一共有12个字段(第1行)包含两个样本(第2~3行),这里需要用到的是sent1, ending0, ending1, ending2, ending3和label这6个字段。例如对于第1个样本来说,其形式如下:
1 The people are in robes. They
2 A) wearing colorful costumes. # 正确选项
3 B) are doing karate moves on the floor.
4 C) shake hands on their hips.
5 D) do a flip to the bag.同时,由于该数据集已经做了训练集、验证集和测试集的划分,所以后续也就不需要我们手动划分。
2. 数据集预览
在正式介绍如何构建数据集之前我们先通过一张图来了解整个大致的构建流程。假如我们现在有两个样本构成了一个小批量,那么其整个数据的处理流程将如图10-31所示。
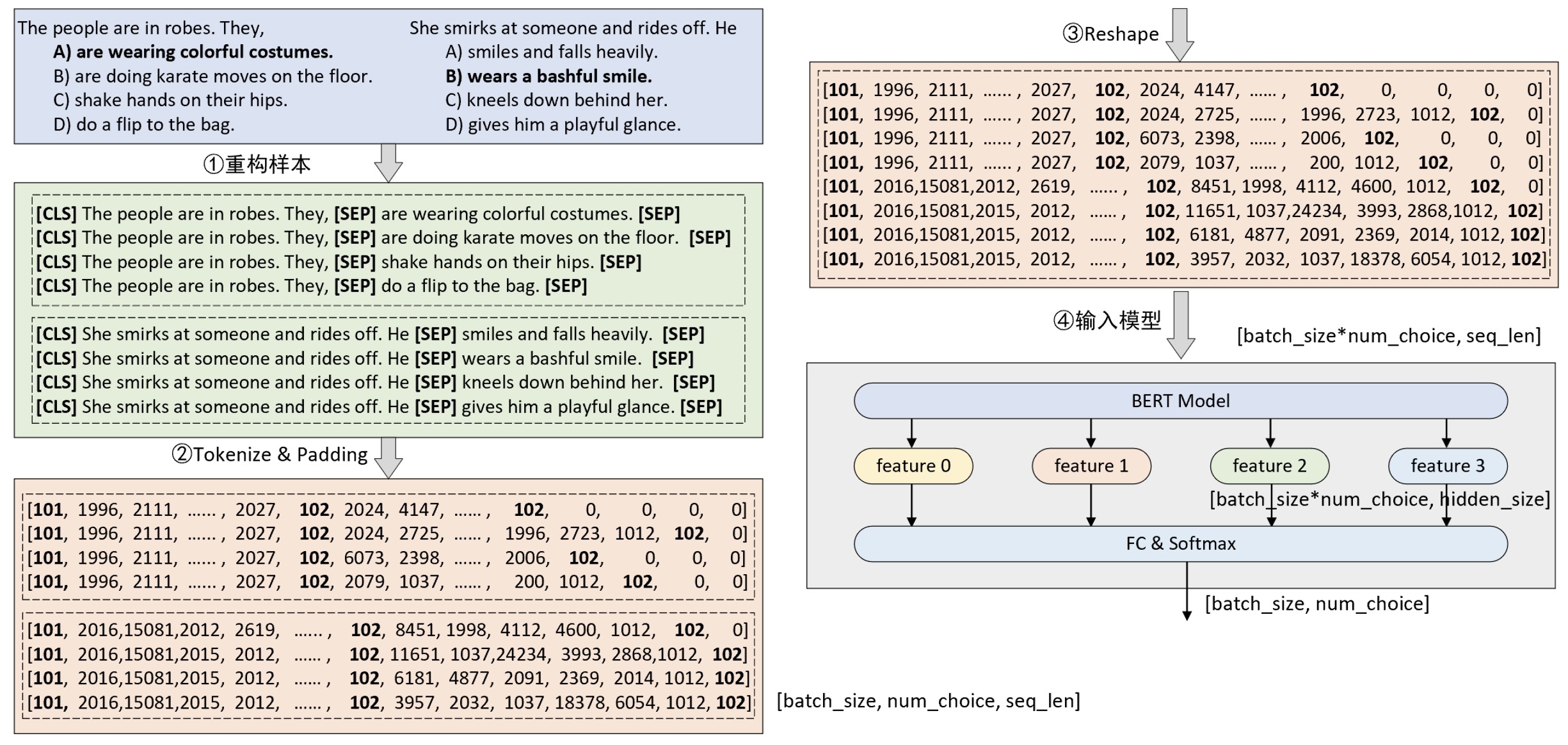
如图10-31所示,首先对于原始数据的每个样本,即1个问题和4个选项,需要将问题同每个选项拼接在一起构造成为4个序列并添加上对应的分类符[CLS] 和分隔符[SEP],即图中的第①步重构样本。接着将第①步构造得到的序列转换得到索引并进行填充处理,此时便得到了一个形状为[batch_size, num_choice, seq_len]的3维矩阵,即图10-31中第②步处理完成后的结果,形状为[2,4,19]。同时,在第②步中还要根据每个序列构造得到相应的掩码向量和句子编码输入(图中未画出),并且两者的形状也是[batch_size, num_choice, seq_len]。
进一步,将第②步处理后的结果变形成[batch_size * num_choice, seq_len]的2维 形式,因为BERT模型接收的输入形式便是一个二维矩阵。在经过BERT模型特征提取后将会得到一个形状为[batch_size * num_choice, hidden_size]的二维矩阵,最后再乘上一个形状为[hidden_size,1]的矩阵并变形成[batch_size, num_choice]即可完成整个分类任务。
3. 重构样本
对于数据预处理部分我们可以继承上一节文本分类中的LoadSingleSentenceClassificationDataset类,然后再稍微修改其中的部分方法即可。同时,由于在上一节内容中已经就词表构建等内容做了详细的介绍所以后续将不再赘述。如图10-31所示,需要对原始样本进行重构以及转换得到每个序列对应的索引,下面首先是在data_process()方法中来定义如何读取原始数据:
1 def data_process(self, file_path):
2 data = pd.read_csv(file_path)
3 questions = data['startphrase']
4 answers0, answers1 = data['ending0'], data['ending1']
5 answers2, answers3 = data['ending2'], data['ending3']
6 labels = [-1] * len(questions)
7 if 'label' in data: # 测试集中没有标签
8 labels = data['label']
9 all_data, max_len = [], 0
10 for i in tqdm(range(len(questions)), ncols=80):
11 t_q = [self.vocab[token] for token in self.tokenizer(questions[i])]
12 t_q = [self.CLS_IDX] + t_q + [self.SEP_IDX]
13 t_a0 = [self.vocab[token] for token in self.tokenizer(answers0[i])]
14 t_a1 = [self.vocab[token] for token in self.tokenizer(answers1[i])]
15 t_a2 = [self.vocab[token] for token in self.tokenizer(answers2[i])]
16 t_a3 = [self.vocab[token] for token in self.tokenizer(answers3[i])]
17 max_len = max(max_len,len(t_q)+ max(len(t_a0),len(t_a1),len(t_a2),len(t_a3)))
18 seg_q = [0] * len(t_q)
19 seg_a0, seg_a1 = [1] * (len(t_a0) + 1), [1] * (len(t_a1) + 1)
20 seg_a2, seg_a3 = [1] * (len(t_a2) + 1), [1] * (len(t_a3) + 1)
21 all_data.append((t_q, t_a0, t_a1, t_a2, t_a3, seg_q,
22 seg_a0, seg_a1, seg_a2, seg_a3, labels[i]))
23 return all_data, max_len在上述代码中,第2~5行是根据文件路径来读取原始数据并按对应字段取得问题和答案。第6~8行是用来判断是否存在正确标签,因为测试集中不含有标签。第10行用来遍历每一个问题以及对应的答案。第11~12行是将原始问题转换为对应的索引,同时在起止位 置分别加上[CLS]和[SEP]符号。第13~17行是分别将每个问题对应的4个选项转换为索引,以及保存最大序列的长度。第18~10行是用来构造对应的句子编码输入向量。第21~23行是分别将每一个问题以及对应的4个选项处理后的结果保存和返回最后的结果。
4. 样本拼接与填充
在处理得到每个问题及对应选项的索引和句子编码输入后,需要再定义一个generate_batch()方法对每个小批量中的数据拼接和填充处理,示例代码如下所示:
1 def generate_batch(self, data_batch):
2 batch_qa, batch_seg, batch_label = [], [], []
3 def get_seq(q, a):
4 seq = q + a
5 if len(seq) > self.max_position_embeddings - 1:
6 seq = seq[:self.max_position_embeddings - 1]
7 return torch.tensor(seq + [self.SEP_IDX], dtype=torch.long)
8
9 for item in data_batch:
10 tmp_qa = [get_seq(item[0], item[1]),get_seq(item[0], item[2]),
11 get_seq(item[0], item[3]),get_seq(item[0], item[4])]
12 seg0 = (item[5] + item[6])[:self.max_position_embeddings]
13 seg1 = (item[5] + item[7])[:self.max_position_embeddings]
14 seg2 = (item[5] + item[8])[:self.max_position_embeddings]
15 seg3 = (item[5] + item[9])[:self.max_position_embeddings]
16 tmp_seg = [torch.tensor(seg0, dtype=torch.long),
17 torch.tensor(seg1, dtype=torch.long),
18 torch.tensor(seg2, dtype=torch.long),
19 torch.tensor(seg3, dtype=torch.long)]
20 batch_qa.extend(tmp_qa)
21 batch_seg.extend(tmp_seg)
22 batch_label.append(item[-1])
23 batch_qa = pad_sequence(batch_qa,True,self.max_sen_len,self.PAD_IDX)
24 batch_mask = (batch_qa == self.PAD_IDX)
25 batch_mask = batch_mask.view([-1, self.num_choice,batch_qa.size(-1)])
26 batch_qa = batch_qa.view([-1, self.num_choice, batch_qa.size(-1)])
27 batch_seg = pad_sequence(batch_seg,True, self.max_sen_len,self.PAD_IDX)
28 batch_seg = batch_seg.view([-1, self.num_choice, batch_seg.size(-1)])
29 batch_label = torch.tensor(batch_label, dtype=torch.long)
30 return batch_qa, batch_seg, batch_mask, batch_label在上述代码中,第3~7行get_seq()方法是用于根据传入的问题索引和答案索引序列拼接得到一个完整的模型输入序列,并将超过长度的部分进行截断处理。第10~11行是将每个问题分别与其对应的4个选项进行拼接。第12~15 行分别构造得到每个问题与其对应的4个选项所形成的句子编码输入向量。第20~22行是保存每个小批量中所有样本处理好的结果。第23~29行是对各个输入进行填充或者变形等以得到对应形状的输入,最后处理结束后batch_qa、batch_seq和batch_mask的维度均为[batch_size, num_choice, src_len],batch_label 的形状为[batch_size,]。
4. 使用示例
在完成上述两个步骤之后,整个数据集的构建就算是已经基本完成了,可以通过如下代码进行数据集的载入:
1 if __name__ == '__main__':
2 model_config = ModelConfig()
3 load_dataset = LoadMultipleChoiceDataset(...)
4 train_iter, test_iter, val_iter = \
5 load_dataset.load_train_val_test_data(model_config.train_file_path,
6 model_config.val_file_path, model_config.test_file_path)
7 for qa, seg, mask, label in test_iter:
8 print(qa[0], mask[0], seg[0])到此,对于整个数据集的构建过程就介绍完了,下面开始继续介绍问答选择模型的实现内容。
10.9.3 问题选择#
1. 前向传播
正如第10.9.1节内容所介绍,我们只需要在原始BERT模型的基础上再加一个分类层即可,因此这部分代码相对来说也比较容易理解。进一步我们在BertForMultipleChoice.py文件中需要定义一个类以及相应的初始化函数, 示例代码如下所示:
1 class BertForMultipleChoice(nn.Module):
2 def __init__(self, config, bert_model_dir=None):
3 super(BertForMultipleChoice, self).__init__()
4 self.num_choice = config.num_labels
5 if bert_model_dir is not None:
6 self.bert = BertModel.from_pretrained(config, bert_model_dir)
7 else:
8 self.bert = BertModel(config)
9 self.dropout = nn.Dropout(config.hidden_dropout_prob)
10 self.classifier = nn.Linear(config.hidden_size, 1)在上述代码中,第5~8行是根据相应的条件返回一个BERT模型,第10行则是定义了一个分类层。可以看出,这部分代码同10.8.4节内容中的本质上没有任何区别。
进一步,定义模型的整个前向传播计算过程,示例代码如下所示:
1 def forward(self, input_ids, att_mask=None, token_type_ids=None,
2 position_ids=None, labels=None):
3 input_ids = input_ids.view(-1, input_ids.size(-1)).transpose(0, 1)
4 token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1))
5 token_type_ids = token_type_ids.transpose(0, 1)
6 att_mask = att_mask.view(-1, token_type_ids.size(-1))
7 output, _ = self.bert(input_ids,att_mask, token_type_ids,position_ids)
8 output = self.dropout(output)
9 logits = self.classifier(output)
10 shaped_logits = logits.view(-1, self.num_choice)
11 if labels is not None:
12 loss_fct = nn.CrossEntropyLoss()
13 loss = loss_fct(shaped_logits, labels.view(-1))
14 return loss, shaped_logits
15 else:
16 return shaped_logits在上述代码中,第3~6行用于将3维的输入变成2维的输入(也就是图10-31中的第③步),这是因为BERT所接收的输入形式所限。第7行则是通过原始的BERT模型提取得到每个序列(指的是每个问题和其中一个选项所构成的序列)的特征表示,输出形状为[batch_size*num_choice, hidden_size]。 第9~10行是先进行分类处理,然后再变形得到每个问题所对应预测选项的预测值,最后输出形状为[batch_size, num_choice]。第17~22行是根据相应的判断条件返回损失或者预测值。
2. 模型训练
首先在Tasks目录下新建一个名为TaskForMultipleChoice.py的模块,然后定义一个ModelConfig类来对分类模型中的超参数以及其它变量进 行管理。由于这部分内容在10.8.4节内容中已做介绍,各位读者直接参见源码即可。 同时,为了展示训练时的预测结果这里需要写一个函数来进行格式化:
1 def show_result(qas, y_pred, itos=None, num_show=5):
2 num_samples, num_choice, seq_len = qas.size()
3 qas, count = qas.reshape(-1), 0
4 strs = np.array([itos[t] for t in qas]).reshape(-1, seq_len)
5 for i in range(num_samples):
6 s_idx = i * num_choice
7 e_idx = s_idx + num_choice
8 sample = strs[s_idx:e_idx]
9 if count == num_show:
10 return
11 count += 1
12 for j, item in enumerate(sample): # 每个样本的四个答案
13 result = " ".join(item[1:]).replace(" .", ".").replace(" ##", "")
14 q, a, _ = result.split('[SEP]')
15 if y_pred[i] == j:
16 a += " ## True"
17 else:
18 a += " ## False"
19 logging.info(f"[{num_show}/{count}] ### {q + a}")在上述函数调用结束可以输出类似如下所示的结果:
1 - the people are in robes. they are wearing colorful costumes. ## False
2 - the people are in robes. they are doing karate moves on the floor. ## True
3 - the people are in robes. they shake hands on their hips. ## False
4 - the people are in robes. they do a flip to the bag. ## False最后,我们便可以通过如下方法完成整个模型的微调,核心代码如下所示:
1 def train(config):
2 model = BertForMultipleChoice(config,config.pretrained_model_dir)
3 data_loader = LoadMultipleChoiceDataset(...)
4 train_iter, test_iter, val_iter = \
5 data_loader.load_train_val_test_data(config.train_file_path,
6 config.val_file_path, config.test_file_path)
7 for epoch in range(config.epochs):
8 for idx, (qa, seg, mask, label) in enumerate(train_iter):
9 loss, logits = model(qa, mask, seg, None, label)
10 acc = (logits.argmax(1) == label).float().mean()
11 logging.info(f"Epoch: {epoch}, Batch[{idx}/{len(train_iter)}], "
12 f"Train loss :{loss.item():.3f}, Train acc: {acc:.3f}")
13 y_pred = logits.argmax(1).cpu()
14 show_result(qa, y_pred, data_loader.vocab.itos, num_show=1)在上述代码中,第2行是根据指定预训练模型的路径初始化一个基于BERT的问答任务模型。第3~6行是载入相应的数据集。第7~14行则是整个模型的训练过程。
如下便是网络的训练时的输出结果:
1 Epoch: 0, Batch[0/4597], Train loss :1.433, Train acc: 0.250
2 Epoch: 0, Batch[10/4597], Train loss :1.277, Train acc: 0.438
3 ......
4 Epoch: 0, Batch loss :0.786, Epoch time = 1546.173s
5 Epoch: 0, Batch[0/4597], Train loss :1.433, Train acc: 0.250
6 He is throwing darts at a wall. A woman, squats alongside ... ## False
7 He is throwing darts at a wall. A woman, throws a dart at a dartboard. ## False
8 He is throwing darts at a wall. A woman, collapses and falls to the floor. ## False
9 He is throwing darts at a wall. A woman, is standing next to him. ## True
10 Accuracy on val 0.794在完成模型的训练过程后便可以将训练过程中持久化的模型用于任务的推理场景中,各位读者可直接参见源码,这里就不再赘述。
10.9.4 小结#
在本节内容中,我们首先介绍了问题选择模型的任务构建原理,其本质上也是文本分类任务,关键在于任务的构建过程;然后介绍了详细介绍了问题选择模型数据集的构建流程;最后一步一步介绍了如何基于BERT预训练模型搭建整个问题选择模型。总的来讲,对于问答选择这一任务场景来说,只需要将每个问题与其对应的各个选项看成两个拼接在一起的序列,再输入到BERT模型中进行特征提 取最后进行分类即可。在下一节内容中,我们将开始介绍基于BERT预训练模型的问答任务模型。