11.11 基于层次的聚类算法#
经过前面几节内容的介绍,我们已经清楚了Kmeans、Kmeans++、基于权重的加权Kmeans和DBSCAN这4种聚类算法的原理与实现。总的来说这4种聚类算法各有千秋,分别都能在一些独特的场景中发挥自己的优势。在接下来的这篇文章中,我们将会为大家介绍第5种常见的聚类算法,层次聚类算法(Hierarchical Clustering),如图11-30所示便是整个算法的学习路线图。
11.11.1 HCA算法思想#
现在想象这么一个场景,假如你有大量病人的就医资料,需要通过聚类将其划分为不同的科室,例如消化科、呼吸科和皮肤科等等。但是除此之外,你还想顺便得到每个科室下具体病症的情况,例如呼吸科下面可能有肺炎病人、普通感冒病人等等。如果是通过前面介绍的4种聚类算法来进行建模,那么显然只能得到以科室为颗粒度的聚类结果[1]。
不过此时有读者可能会说,直接以病症为颗粒度进行聚类不就解决了吗?虽然理论上可以这么做,但是这种做法的弊端在于K值太大聚类结果可能不会太理想。同时,在其它我们不知道样本的层次结构中(假如在上面例子中不知道肺炎和感冒属于呼吸科),还能够通过层次聚类算法来发现这种潜在的结构。
在数据挖掘和统计分析中,层次聚类也叫做层次聚类分析(Hierarchical Cluster Analysis, HCA),旨在得到样本簇结构的同时发现样本分布的层次结构[2]。同时,层次聚类算法一般来说可以分为两种,一种是自下而上(Bottom-up)的凝聚层次聚类(Agglomerative Clustering)和自上而下的分裂层次聚类(Divisive Clustering)。
凝聚层次聚类算法在聚类伊始会将数据中的每个样本点均看作是一个独立的簇结构,然后迭代将当前状态下最相似的两个簇进行合并,直到最后只剩下一个簇时聚类结束。对于分裂层次聚类算法来说则恰恰相反,分裂层次聚类算法在聚类伊始将所有的样本点都看成是一个簇,然后迭代将当前状态下最大的簇划分为两部分,直到最后将整个数据集划分成$n$个簇结束[2]。
由于在实际应用中基于自上而下的分裂层次聚类使用较少,所以后续将只介绍采用不同策略下的凝聚层次聚类算法。
11.11.2 HCA示例代码#
在介绍完层次聚类算法的基本思想以后,再来看如何借助sklearn来完成整个层次聚类的建模过程,以下完整示例代码可参见 AllBooKCode/Chapter11/C19_hca_train.py 文件,示例代码如下:
1 from sklearn.cluster import AgglomerativeClustering
2
3 if __name__ == '__main__':
4 n_clusters = 3
5 X, y = load_iris(return_X_y=True)
6 X = StandardScaler().fit_transform(X)
7 model = AgglomerativeClustering(n_clusters=n_clusters, linkage="ward")
8 model.fit(X)
9 print(f"兰德系数为: {adjusted_rand_score(y, model.labels_)}")在上述代码中,第1行代码便是导入sklearn中的凝聚层次聚类算法模块。第4~6行是导入数据集并进行标准化处理。第7行是实例化一个类对象,其中linkage参数表示指定一种层次聚类的算法,取值有'ward'、 'complete'和 'single'这3种,后续也将分别详细进行介绍。第8~9行是先完成整个聚类过程,然后对聚类结果进行评估。
11.11.3 HCA算法原理#
在知道了层次聚类算法的基本思想后再来看聚类过程的具体步骤。根据上面的介绍,可以将整个聚类过程归结为如下3步:
(1)将每个样本点均初始化为一个单独的簇;
(2)如果当前只存在一个簇则进入第(3)步,否则寻找当前状态下最相似的两个簇进行合并;
(3)返回整个聚类合并结果[1]。
如图11-31所示从$a$到$j$一共有10个样本点,下面将按照上述3个步骤来对凝聚层次聚类算法的聚类过程进行示例。
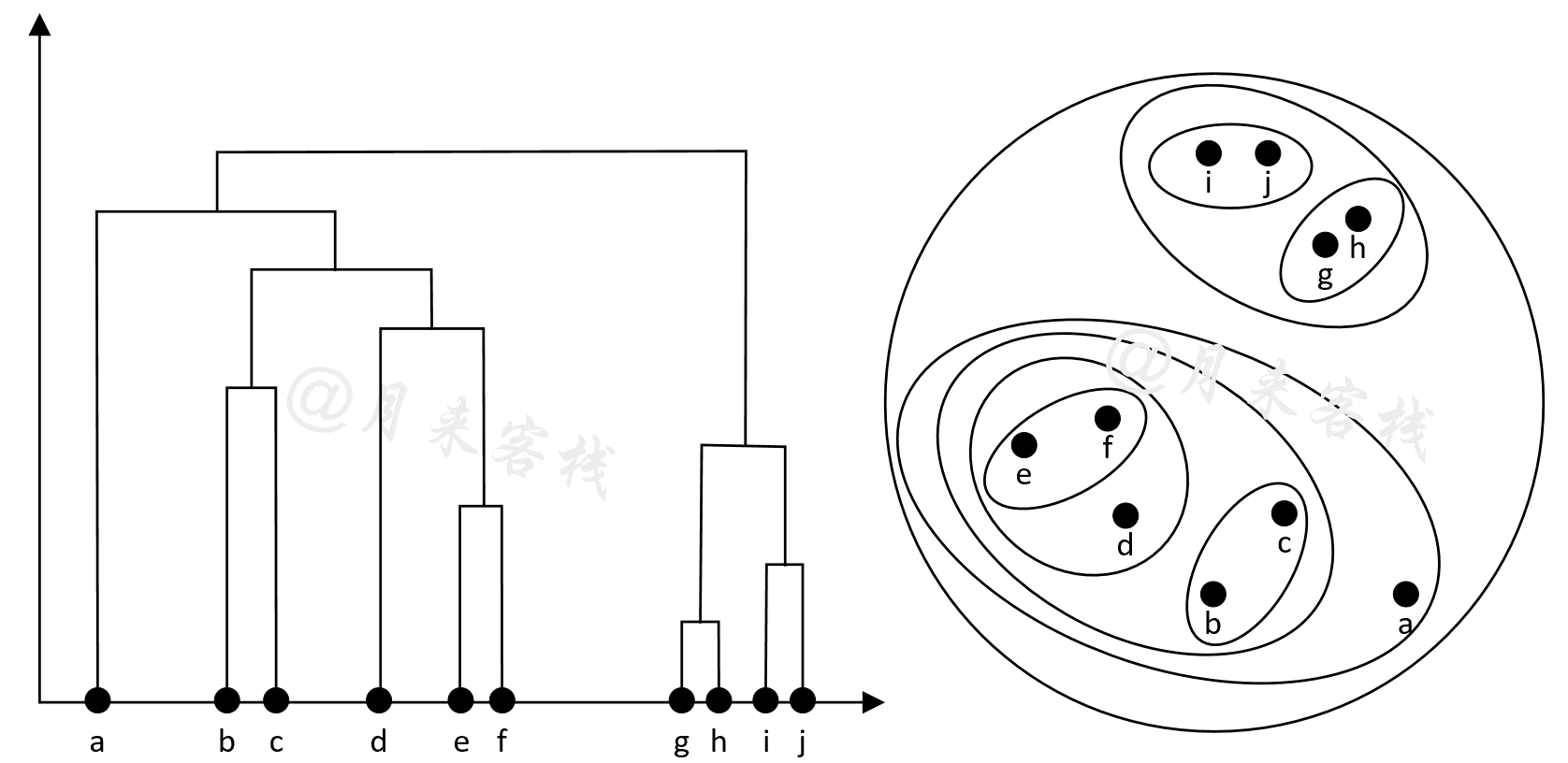
如图11-31右侧所示,首先将这10个样本点均看作是一个单独的簇结构$(\cdot )$;其次假定此时在所有簇的两两组合中,$(g)$和$(h)$这两个簇最相似,那么则将其合并为一个簇$(g,h)$;由于此时不止一个簇所以继续迭代,将$(i)$和$(j)$这两个簇进行合并得到簇$(i,j)$;进一步,根据同样的方式将会得到簇$(e,f)$;同理,再次将$(g,h)$与$(i,j)$合并得到簇$((g,h),(i,j))$;将$(b)$和$(c)$合并得到簇$(b,c)$;将$(d)$和$(e,f)$合并得到簇$(d,(e,f))$;将$(b,c)$和$(d,(e,f))$合并得到$((b,c),(d,(e,f)))$;将$(a)$与$((b,c),(d,(e,f)))$合并得到簇$(a,((b,c),(d,(e,f))))$;最后,将$((g,h),(i,j))$和$(a,((b,c),(d,(e,f))))$合并得到簇$(((g,h),(i,j)),(a,((b,c),(d,(e,f)))))$。由于此时只剩下一个簇,所以层次聚类过程结束。与此同时,我们还可以通过图11-31左侧所示的树状图(Dendrogram)来观察每个簇内部层次结构。
介绍到这里肯定有读者会问,既然凝聚层次聚类算法的终止条件是只剩下一个簇,那么聚类结束后的簇结构到是怎么样的呢?如图11-31左侧所示,在整个聚类过程中,如果不进行最后1次合并那么将会得到两个簇结构;如果在倒数第2次停止合并那么将会得到3个簇结构,以此类推。同时,在每个簇的内部还能看到剩余样本的层次结构。因此实际情况中,如果我们知道真实的簇数量K,那么完全可以在只剩下K个簇的时候停止合并,后续的代码实现也将遵循这一准则。
经过上面的介绍我们发现,凝聚层次聚类算法有两个关键的要素:距离的计算方式和相似性的计算方式(Linkage Criteria)。这一点就类似于K近邻算法一样,也需要两个关键的要素(距离度量方式和决策规则)。因为采用不同的距离计算方式,在后续进行相似性计算时将会得到不同的划分结果。通常在凝聚层次聚类中,距离的度量方式有欧式距离、曼哈顿距离等。对于相似性的度量方式来说常用的有Single-Link、Complete-Link和Ward等[2]。在接下来的内容,我们将分别介绍这3种相似性度量方式的原理及实现过程。
11.11.4 Single-Link算法原理#
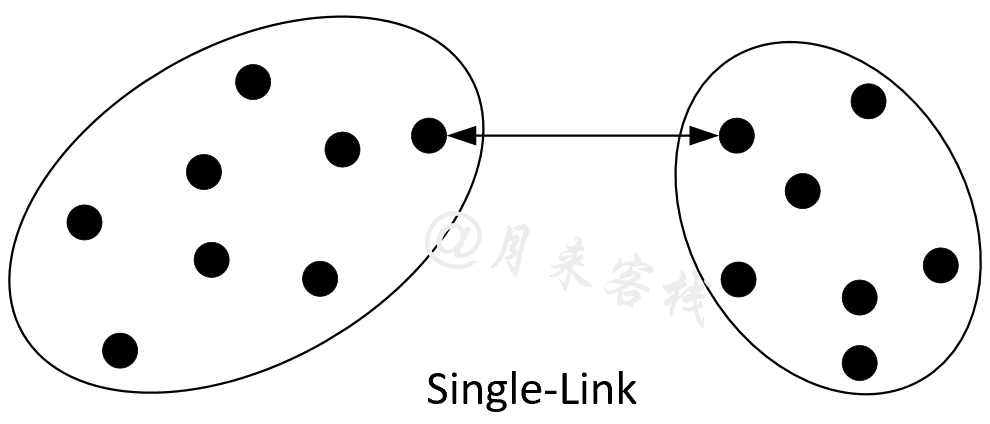
使用Single-Link作为相似性衡量标准的凝聚层次聚类算法也被称之为最近邻聚类(Nearest Neighbour Clustering),其核心思想是根据两个簇之间相邻最近两个样本点的距离来作为相似性评判标准,距离越近则表示这两个簇越相似,即这两个簇越有可能被合并。
如图11-32所示,在聚类过程中对于任意两个簇结构来说,我们需要计算得到相邻两个簇最近样本点之间的距离作为这两个簇相似性的度量值;然后在所有结果中选择相似度最大的值(距离最小)对应的两个簇进行合并;最后按照同样的方法继续进行迭代直到剩余簇数量为1或到达指定值时结束[1]。
假如现在某数据集一共有$a$到$e$这6个样本点,则聚类伊始将这6个样本点均视为6个不同的簇[3]。同时,任意两个簇之间的距离如表11-7所示。
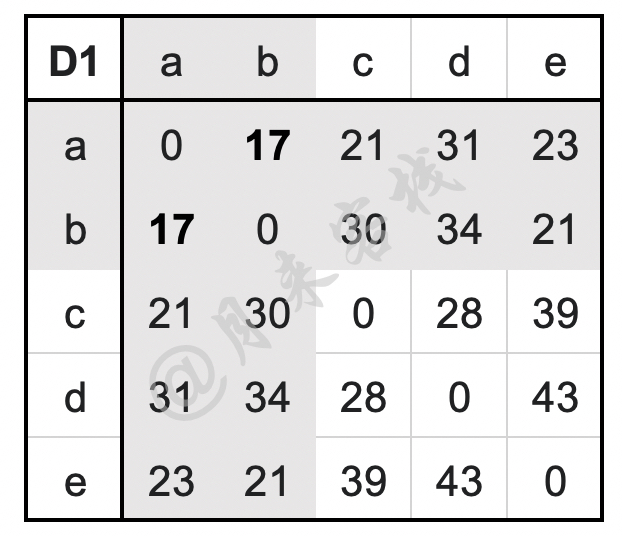
如表11-7所示,D1为一个距离矩阵,用来记录所有簇两两之间的距离。从表中可以看出,此时簇$a$与簇$b$之间的距离最短为17,即最相似,因此将这两个簇进行合并。在合并结束后$a,b$两个簇便合并成了一簇,因此需要删除矩阵D1中簇$a$和簇$b$所在的行与列。同时,由于其它簇两两之间的距离并没有发生改变因此只需要更新簇$(a,b)$与其它3个簇之间的最近距离即可,计算过程如下:
$$ \begin{aligned} \text{D}2((a,b),c)=\min(\text{D}1(a,c),\text{D}1(b,c))=\min(21,30)=21\\[1ex] \text{D}2((a,b),d)=\min(\text{D}1(a,d),\text{D}1(b,d))=\min(31,34)=31\\[1ex] \text{D}2((a,b),e)=\min(\text{D}1(a,e),\text{D}1(b,e))=\min(23,21)=21\\[1ex] \end{aligned}\tag{11-47} $$更新后的距离矩阵D2如表11-8所示。
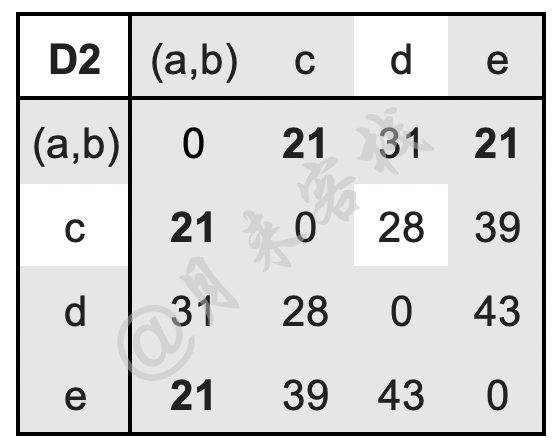
如表11-8所示,此时簇$(a,b)$与簇$c$和簇$d$之间的距离均为21,因此需要将这3个簇进行合并。此时尤其需要注意的一点是,由于D2中是其中一个簇分别与另外两个簇的距离相等(且该距离是簇与簇之间的最短距离),因此可以同时将这3个簇合并到一起。假如此时是簇$(a,b)$与$c$的距离为17,簇$d$和簇$e$之间的距离也是17,那么本次只能是将$(a,b)$与$c$进行合并,或者是将$d$与$e$进行合并,而不能简单地直接将这4个簇进行合并。在簇$(a,b)$与$c$和$e$进行合并后,只需要更新D2中簇$((a,b),c,e)$与剩余其它簇(即仅剩$d$)之间的最近距离即可,计算过程如下:
$$ \begin{aligned} \text{D}3(((a,b),c,e),d)=\min(\text{D}2((a,b),d),\text{D}2(c,d),\text{D}2(e,d))=\min(31,28,43)=28\\[1ex] \end{aligned}\tag{11-48} $$更新后的距离矩阵D3如表11-9所示。
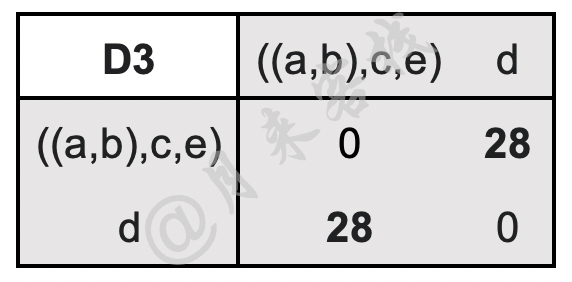
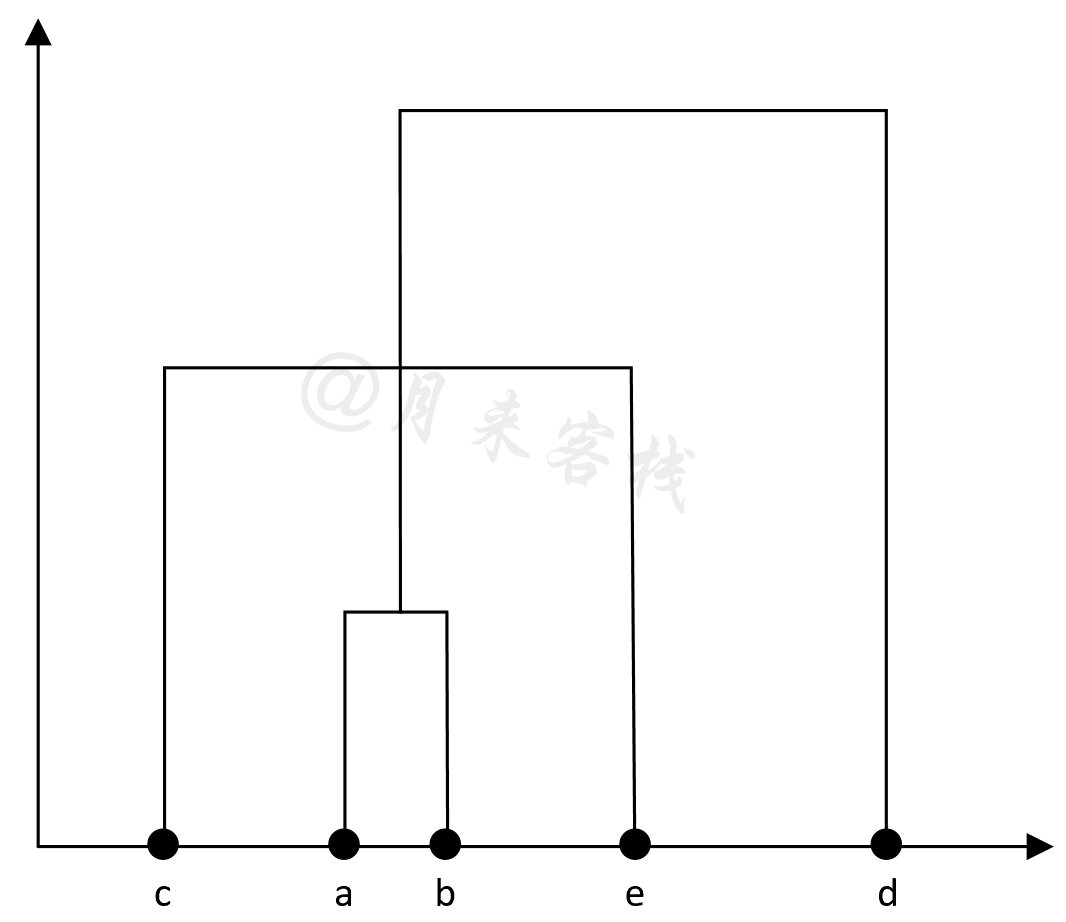
如表11-9所示,此时只剩下$((a,b),c,e)$和$d$这两个簇,因此最后将这两个簇进行合并。最终,根据上述合并过程,我们可以得到如图11-33所示的树状图。
到此,对于基于Single-Link的凝聚层次聚类算法的原理就介绍完了,下面再来介绍如何一步一步实现整个算法。
11.11.5 从零实现Single-Link算法#
在正式介绍Single-Link实现之前,需要先定义节点类来保存每次合并后的簇结构信息,示例代码如下:
1 class ClusterNode(object):
2 def __init__(self, idx=None, centroid=None):
3 samples = []
4 if idx is not None:
5 samples = [idx]
6 self.samples = samples
7 self.n_samples = len(self.samples)
8 self.children = {}
9 self.centroid = centroid在上述代码中,第2行 idx 表示初始化时指定每个每个样本点对应的索引;centroid 表示每个簇对应的簇中心。第6行用来保存当前簇结构中所有样本在原始数据集中的索引。第7行用来保存当前节点对应的样本数量。第8行是保存当前节点对应的孩子节点,即对应的层次信息,如果仅仅只是为了完成聚类任务那么这个参数也可以不用。第9行用来保存当前簇结构对应的簇中心,这个参数只用于 Ward 算法中。
进一步,定义一个类方法来完成簇与簇之间的合并过程,示例代码如下:
1 def merge(self, node):
2 self.samples += node.samples
3 self.children[id(node)] = node
4 self.n_samples = len(self.samples)在定义完簇节点的相关信息后,下面便可以通过一个函数来实现Single-Link算法的逻辑功能,示例代码如下:
1 def single_linkage(X, n_clusters, metric="euclidean"):
2 cluster_nodes = [ClusterNode(i) for i in range(len(X))]
3 old_d = pairwise_distances(X, metric=metric)
4 n_merge = 0
5 while len(cluster_nodes) > n_clusters:
6 n_merge += 1
7 merge_dims = None
8 all_locations = np.where(np.abs(old_d - np.sort(old_d.ravel())
9 [len(old_d)]) < 1e-6)
10 for (row, col) in zip(*all_locations):
11 if row == col:
12 continue
13 merge_dims = [row, col]
14 break
15 merge_node = ClusterNode()
16 del_nodes = [cluster_nodes.pop(dim) for dim in sorted(
17 merge_dims, reverse=True)]
18 for node in del_nodes:
19 merge_node.merge(node)
20 cluster_nodes.insert(0, merge_node)
21 new_d = deepcopy(old_d)
22 new_d = np.delete(new_d, merge_dims, axis=0)
23 new_d = np.pad(np.delete(new_d,merge_dims, axis=1), [1, 0])
24 old_d_dims = [i for i in range(len(old_d)) if i not in merge_dims]
25 new_d_dims = [i for i in range(1, len(new_d))]
26 for i, j in zip(new_d_dims, old_d_dims):
27 value = np.inf
28 for k in merge_dims:
29 value = np.min([old_d[k][j], value]) # 寻找最小距离
30 new_d[0][i] = new_d[i][0] = value # 更新 new_d
31 old_d = new_d
32 return cluster_nodes在上述代码中,第1行X表示数据集形状为 [n_samples, n_features],n_clusters表示簇的数量,metric表示样本间距离的计算方式,常见的有'cosine'、 'euclidean'、'l1'、'l2'、'manhattan'等。第2行是初始化每个样本为一个簇节点。第3行用于计算簇与簇之间的距离(初始时就是样本点两两之间的距离),是一个形状为 [n_samples,n_samples]的对称矩阵,old_d[i][j] 表示第i个簇到第j个簇之间的距离。第5行开始递归合并满足条件的簇结构。第7行用来记录需要合并的维度。
第8~9行用来寻找簇与簇之间最短距离的索引, 由于距离是浮点型数据所以这里通过作差来判断是否相等。同时np.sort(old_d.ravel())[len(old_d)]的目的是将矩阵中的所有值进行顺序排序,并取第len(old_d)个元素为所有距离中的最小值,因为前len(old_d)个元素均为对角线上的0值需要过滤掉。同时,np.where返回的是所有满足条件的元素所在的行索引和列索引。第10~14行用来过滤掉当最小值为0时的情况,因为如果有两个簇之间的距离为0(初始时有重复样本点)时,簇与簇之间的最小距离便是0,此时all_locations中就会包含有距离矩阵old_d对角线上元素的位置,只有当row不等于col时才表示此时的最小值0不是对角线上的元素。
第15行是定义一个新的簇节点,用来保存所有需要合并到一起的簇结构。第16~17行是根据需要合并的维度将原始簇列表中对应的簇节点取出并删除,这里需要注意的是需要先删除列表中靠后的元素所以对索引进行逆序处理,因为如果乱序删除列表中的元素会出现索引值大于当前列表长度的情况,例如需要删除第2、3行,如果先删除第2行那么3行的索引就会变成2,再删除第3行是则会出错。第18~19行是将需要合并的两个列表合并到新的簇中。第20行是将合并后新的簇结构放入到簇列表的首位。第21~23分别是复制原始的距离矩阵old_d,然后删除已经合并簇结构对应的行和列,并在new_d的首行和首列填充0用来记录合并后的簇结构到其它簇的距离。第24~25行是得到old_d中去掉合并维度后剩下的维度,以及new_d中需要更新距离的索引。第26~30行则是更新簇合并后两两之间的距离矩阵new_d(即第11.11.3节中表11-7到表11-9所示的过程),用于后续的迭代过程。最后,cluster_nodes中存放的就是n_clusters个簇对应的根节点。
到此,对于Single-Link部分的代码就实现完成了,下面再通过一个类来完成整个聚类算法的封装即可。
首先,定义一个类和初始化方法,示例代码如下:
1 class HierarchicalClustering(object):
2 def __init__(self, n_clusters=3, linkage="single", metric='euclidean'):
3 self.linkage = linkage
4 self.metric = metric
5 self.n_clusters = n_clusters最后定义一个fit方法来调用上面的single_linkage函数即可,示例代码如下:
1 def fit(self, X):
2 if self.linkage == "single":
3 cluster_nodes = single_linkage(X, self.n_clusters, self.metric)
4 else:
5 raise ValueError(f"self.linkage == {self.linkage} 不存在该方法!")
6 labels_ = [-1] * len(X)
7 for cluster_id, node in enumerate(cluster_nodes):
8 for sample in node.samples:
9 labels_[sample] = cluster_id
10 self.labels_ = labels_
11 self.cluster_nodes_ = cluster_nodes在上述代码中,第6行是初始化一个全为-1的簇标签。第7~9行是根据层次聚类后的合并结果来遍历得到每个样本对应的簇标签。
11.11.6 Single-Link使用示例#
在完成整个Single-Link算法的实现过程后,便可以通过类似如下的方式来进行使用,示例代码如下:
1 def test_single():
2 n_clusters = 3
3 X, y = load_iris(return_X_y=True)
4 X = StandardScaler().fit_transform(X)
5 my_single = HierarchicalClustering(n_clusters=n_clusters)
6 my_single.fit(X)
7 logging.info(f"HierarchicalClustering(Single)"
8 f"调整兰德系数: {adjusted_rand_score(y, my_single.labels_)}")
9 model = AgglomerativeClustering(n_clusters=n_clusters, linkage="single")
10 model.fit(X)
11 logging.info(f"AgglomerativeClustering(Single)"
12 f"调整兰德系数: {adjusted_rand_score(y, model.labels_)}")
13
14 if __name__ == '__main__':
15 test_single()上述代码运行结束后便可得到类似如下所示的结果:
1 HierarchicalClustering(Single) 调整兰德系数: 0.5584
2 AgglomerativeClustering(Single) 调整兰德系数: 0.5584其中AgglomerativeClustering为sklearn中对层次聚类算法的实现,上述完整示例可参见 AllBooKCode/Chapter11/C20_hierarchical_clustering.py 文件。
11.11.7 Complete-Link算法原理#
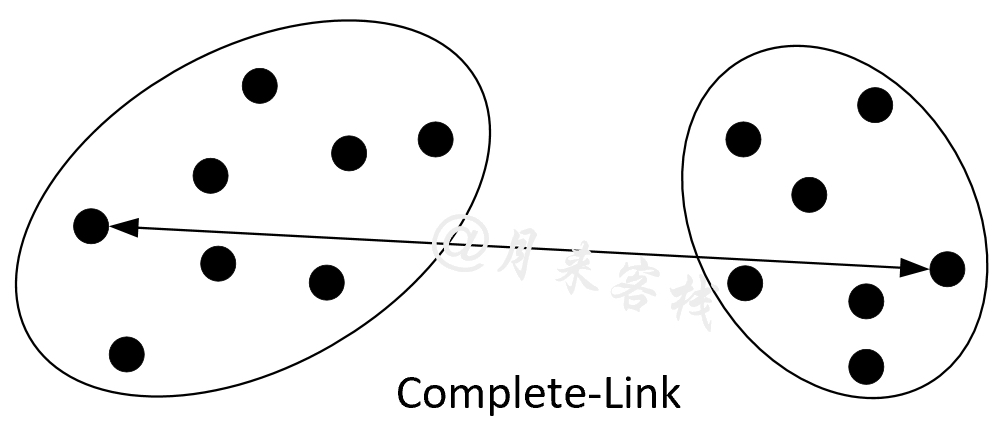
在介绍完Single-Link相似性衡量指标后,我们再来看一个与之类似的Complete-Link方法。与Single-Link相反,Complete-Link的核心思想是根据两个簇之间相邻最远两个样本点的距离来作为相似性评判标准,距离越近则表示这两个簇越相似,即这两个簇越有可能被合并,因此Complete-Link也被称为最远邻聚类(Farthest Neighbour Clustering)。
此时可以看出,Single-Link是根据相邻两个簇最近样本点之间的距离来衡量两个簇的相似性,而Complete-Link则是根据相邻两个簇最远样本点之间的距离来衡量两个簇的相似性,但两者都是距离越小表示两个簇越相似。前者可以看作是求解最近距离之间的最小值,而后者则是求解最远距离之间的最小值。
如图11-34所示,在聚类过程中对于任意两个簇结构来说,我们需要计算得到相邻两个簇最远样本点之间的距离作为这两个簇相似性的度量值;然后在所有结果中选择相似度最高的值(距离最小)对应的两个簇进行合并;最后按照同样的方法继续进行迭代直到剩余簇数量为1或到达指定值时结束[1] [4]。
这里,继续以第11.11.3节中的数据集为例,在聚类伊始任意两个簇之间的距离如表11-10所示。
如表11-10所示,此时簇$a$与簇$b$之间的距离最短为17,因此将这两个簇进行合并。在合并结束后$a,b$两个簇便合并成了一簇,因此需要删除矩阵D1中簇$a$和簇$b$所在的行与列。同时,由于其它簇两两之间的距离并没有发生改变因此只需要更新簇$(a,b)$与其它3个簇之间的最远距离即可,计算过程如下:
$$ \begin{aligned} \text{D2}((a,b),c)=\max(\text{D1}(a,c),\text{D1}(b,c))=\max(21,30)=30\\[1ex] \text{D2}((a,b),d)=\max(\text{D1}(a,d),\text{D1}(b,d))=\max(31,34)=34\\[1ex] \text{D2}((a,b),e)=\max(\text{D1}(a,e),\text{D1}(b,e))=\max(23,21)=23\\[1ex] \end{aligned}\tag{11-49} $$更新后的距离矩阵D2如表11-11所示。
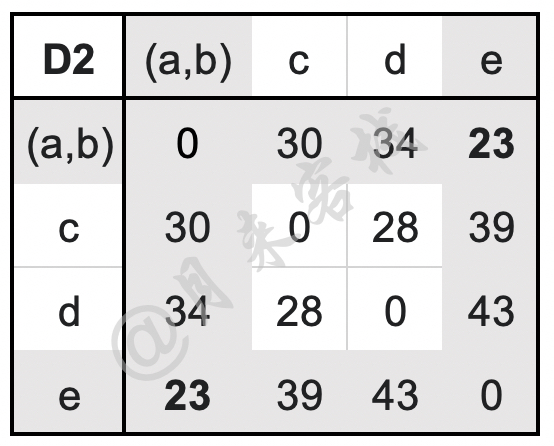
如表11-11所示,此时簇$(a,b)$与簇$e$的距离23为最小值,因此需要将簇$(a,b)$与$e$进行合并。在簇$(a,b)$与$e$进行合并后,只需要更新D2中簇$((a,b),e)$与剩余其它簇之间的最远距离即可,计算过程如下:
$$ \begin{aligned} \text{D}3(((a,b),e),c)=\max(\text{D}2((a,b),c),\text{D}2(e,c))=\max(30,39)=39\\[1ex] \text{D}3(((a,b),e),d)=\max(\text{D}2((a,b),d),\text{D}2(e,d))=\max(34,43)=43\\[1ex] \end{aligned}\tag{11-50} $$更新后的距离矩阵D3如表11-12所示。
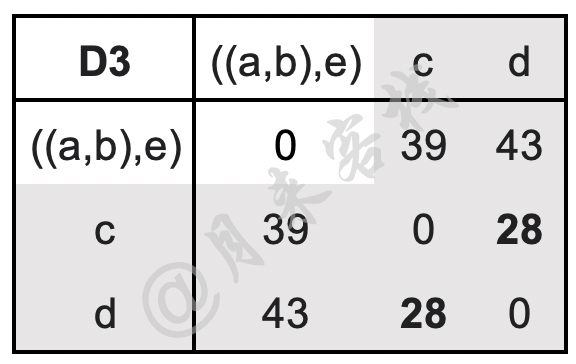
如表11-12所示,此时簇$c$与簇$d$之间的距离28为最小值,因此需要将簇$c$与$d$进行合并。在簇$c$与$d$进行合并后,只需要更新D3中簇$(c,d)$与剩余其它簇之间的最远距离即可,计算过程如下:
$$ \begin{aligned} \text{D}4(((a,b),e),(c,d))=\max(\text{D}3(((a,b),e),c),\text{D}3(((a,b),e),d))=\max(39,43)=43\\[1ex] \end{aligned}\tag{11-51} $$更新后的距离矩阵D4如表11-13所示。
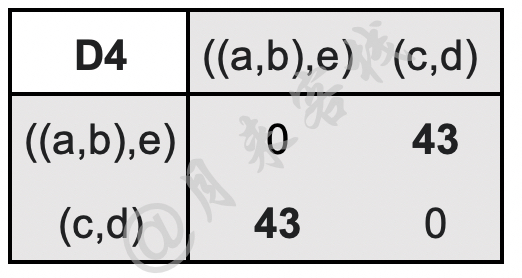
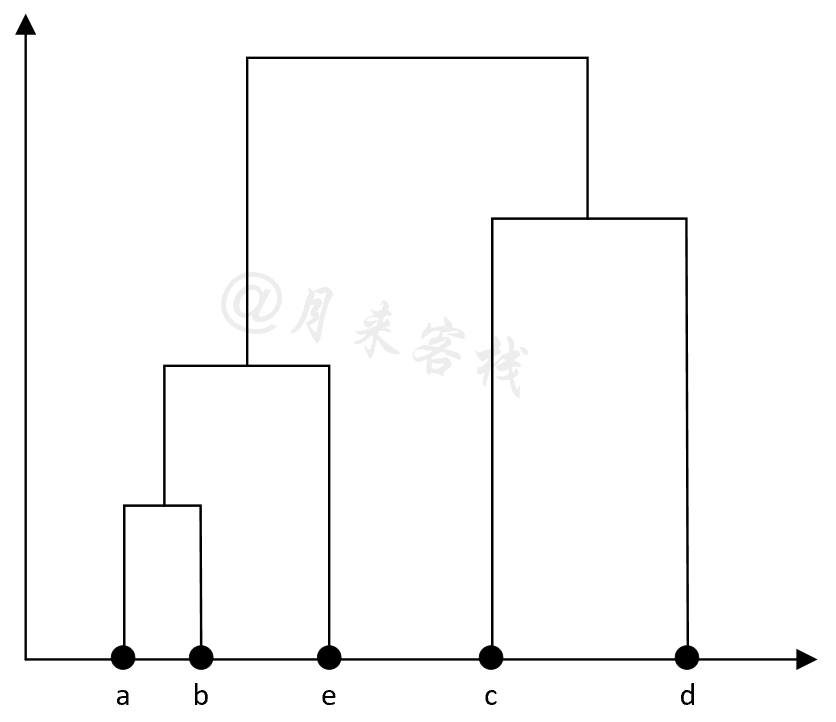
如表11-13所示,此时只剩下$((a,b),e)$和$(c,d)$这两个簇,因此最后将这两个簇进行合并。最终,根据上述合并过程,我们可以得到如图11-35所示的树状图。
到此,对于基于Complete-Link原理的凝聚层次聚类算法的原理就介绍完了,下面再来介绍如何实现整个算法。
11.11.8 从零实现Complete-Link算法#
经过第11.11.5节内容的介绍,我们已经对Single-Link算法的实现有了清晰的认识。由于Complete-Link仅仅只是在簇与簇之间相似性的度量上从最小值换成了最大值,因此在实现Complete-Link算法时只需要在Single-Link实现代码的基础上修改其中几行便可完成。进一步,可以把Single-Link和Complete-Link这两个算法的实现放到一个函数中,通过一个参数来进行选择,示例代码如下:
1 def single_complete_linkage(X, n_clusters, metric="euclidean", link_type='single'):
2 # 此处同3.2节中的single_linkage()
3 for i, j in zip(new_d_dims, old_d_dims):
4 value = np.inf
5 if link_type == "complete":
6 value *= -1
7 for k in merge_dims:
8 if link_type == "single":
9 value = np.min([old_d[k][j], value]) # 寻找最近距离
10 elif link_type == "complete":
11 value = np.max([old_d[k][j], value]) # 寻找最远距离
12 else:
13 raise ValueError(f"link_type 类型错误")
14 new_d[0][i] = new_d[i][0] = value # 更新 new_d
15 old_d = new_d
16 return cluster_nodes在上述代码中,第1行link_type参数用来指定使用Single-Link方法还是使用Complete-Link方法。第2行表示复用11.11.5节中single_linkage()函数第2~25行的代码。第5~6行和10~11行则是对Complete-Link方法的实现。
最后,只需要在类HierarchicalClustering的fit方法中新引入single_complete_linkage这个函数调用即可,示例代码如下:
1 def fit(self, X):
2 if self.linkage == "single":
3 cluster_nodes = single_complete_linkage(X,
4 self.n_clusters, self.metric, 'single')
5 elif self.linkage == "complete":
6 cluster_nodes = single_complete_linkage(X,
7 self.n_clusters, self.metric, 'complete')
8 else:
9 raise ValueError(f"link_type 类型错误")
10 labels_ = [-1] * len(X)
11 for cluster_id, node in enumerate(cluster_nodes):
12 for sample in node.samples:
13 labels_[sample] = cluster_id
14 self.labels_ = labels_
15 self.cluster_nodes_ = cluster_nodes在上述代码中,第5~7行便是新加入的Complete-Link方法。同时可以看到在第2~4行中也对Single-Link方法的调用进行了统一。
11.11.9 Complete-Link使用示例#
在完成整个Complete-Link算法的实现过程后,便可以通过类似如下的方式来进行使用,示例代码如下:
1 def test_complete():
2 n_clusters = 2
3 X, y = make_moons(n_samples=500, noise=0.05, random_state=2020)
4
5 n_clusters = 3
6 X, y = load_iris(return_X_y=True)
7 X = StandardScaler().fit_transform(X)
8 my_single = HierarchicalClustering(n_clusters=n_clusters, linkage="complete")
9 my_single.fit(X)
10 logging.info(f"HierarchicalClustering(Complete) "
11 f"调整兰德系数: {adjusted_rand_score(y, my_single.labels_)}")
12 model = AgglomerativeClustering(n_clusters=n_clusters, linkage="complete")
13 model.fit(X)
14 logging.info(f"AgglomerativeClustering(Complete) "
15 f"调整兰德系数: {adjusted_rand_score(y, model.labels_)}")
16
17 if __name__ == '__main__':
18 test_complete()上述代码运行结束后便可得到类似如下所示的结果:
1 HierarchicalClustering(Complete) 调整兰德系数: 0.5726
2 AgglomerativeClustering(Complete) 调整兰德系数: 0.5726其中AgglomerativeClustering为sklearn中对层次聚类算法的实现,完整代码可参见 AllBooKCode/Chapter11/C20_hierarchical_clustering.py 文件。
11.11.10 Ward算法原理#
在介绍完前面两种簇结构合并方法后我们再来看另外一种基于方差(簇内距离)的簇合并方式Ward算法。原始的Ward算法由J. H. Ward [6]在1963年所提出,该方法的核心思想是每次选择方差增量最小的两个簇进行合并。
由于凝聚层次聚类算法在聚类伊始将每个样本点均视为一个单独的簇结构,因此在这个状态下每个簇的簇内距离(方差)均是0。当簇与簇逐步开始两两进行合并时,簇内部的方差便会逐渐增大。Ward算法的思想则是选择在合并后与合并前方差变化量最小的两个簇进行合并,以此保证整体方差最小,也称之为合并损失(Merging Cost)[7]。
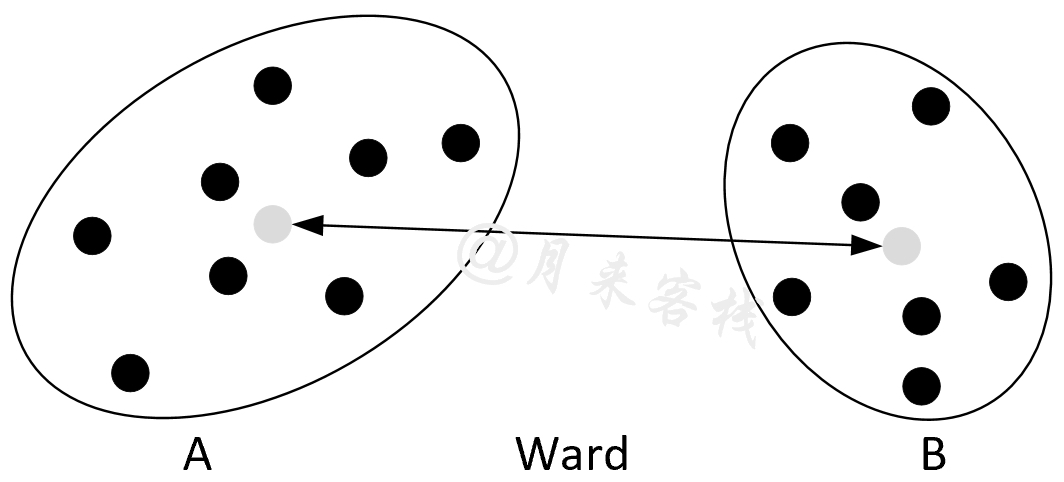
如图11-36所示,左右两边分别为两个簇结果,中间灰色样本为两个簇各自的簇中心,则两个合并后的方差增量为[1] [8]:
$$ \begin{aligned} \Delta(A,B)=&\sum_{i\in A \cup B}\|x_i-m_{A\cup B}\|^2-\sum_{i\in A}\|x_i-m_A\|^2-\sum_{i\in B}\|x_i-m_{B}\|^2\\[2ex] =&\sum_{i\in A\cup B}\left(x^2_i+m_{A\cup B}^2-2x_im_{A\cup B}\right)-\sum_{i\in A}\left(x^2_i+m_A^2-2x_im_A\right)-\sum_{i \in B}\left(x^2_i+m_B^2-2x_im_B\right) \\[2ex] =&\sum_{i\in A\cup B}m_{A\cup B}^2-2m_{A\cup B}\sum_{i\in A\cup B}x_i-n_Am^2_A+2m_A\sum_{i\in A}x_i-n_Bm_B^2+2m_B\sum_{i\in B}x_i\\[2ex] =&(n_A+n_B)m^2_{A\cup B}-2m_{A\cup B}n_{A\cup B}\frac{1}{n_{A\cup B}}\sum_{i\in A\cup B}x_i-n_Am^2_A+2m_An_A\frac{1}{n_A}\sum_{i\in A}x_i-n_Bm^2_B+2m_Bn_B\frac{1}{n_B}\sum_{i\in B}x_i\\[2ex] =&(n_A+n_B)m^2_{A\cup B}-2n_{A\cup B}m_{A\cup B}^2-n_Am^2_A+2n_Am^2_A-n_Bm^2_B+2n_Bm^2_B\\[2ex] =&n_Am^2_A+n_Bm^2_B-(n_A+n_B)m^2_{A\cup B}\\[2ex] =&n_Am^2_A+n_Bm^2_B-(n_A+n_B)\left[\frac{1}{n_A+n_B}(n_Am_A+n_Bm_B)\right]^2\\[2ex] =&n_Am^2_A+n_Bm^2_B-\frac{1}{n_A+n_B}\left(n_A^2m_A^2+n^2_Bm^2_B+2n_An_Bm_Am_B\right)\\[2ex] =&\left(n_A-\frac{n_A^2}{n_A+n_B}\right)m^2_A+\left(n_B-\frac{n_B^2}{n_A+n_B}\right)m^2_B-\left(\frac{2n_An_B}{n_A+n_B}\right)m_Am_B\\[2ex] =&\frac{n_An_B}{n_A+n_B}\|m_A-m_B\|^2 \end{aligned}\tag{11-52} $$其中$m_A$表示簇$A$的簇中心,$n_A$表示簇$A$中样本的总数。
从式(11-52)可以发现,方差增量计算的是两个簇合并后的方差减去两个簇各自内部的方差。在聚类过程中,只需要计算任意两个簇之间的方差增量,然后选择增量最小的两个簇进行合并。同时,从最后化简得到的结果来看,方差增量也等价于两个簇簇中心之间的加权距离。
11.11.11 从零实现Ward算法#
根据Ward算法的原理可知,整个聚类的实现过程整体上和前面两种方法类似,主要区别体现在方差增量计算这一步。因此,我们只需要在第11.11.5节中的代码基础上进行修改即可。这里定义一个名为ward_linkage的函数,示例代码如下:
1 def ward_linkage(X, n_clusters, metric="euclidean"):
2 cluster_nodes = [ClusterNode(i, X[i]) for i in range(len(X))]
3 n_merge = 0
4 while len(cluster_nodes) > n_clusters:
5 centroids, n_samples = [], []
6 for node in cluster_nodes:
7 centroids.append(node.centroid)
8 n_samples.append(node.n_samples)
9 n_samples = np.array(n_samples)
10 weight = (n_samples[:, None] * n_samples) /
11 (n_samples[:, None] + n_samples) # 计算权重
12 d = weight * pairwise_distances(centroids, metric=metric)
13 n_merge += 1
14 merge_dims = None
15 all_locations = np.where(np.abs(d - np.sort(d.ravel())[len(d)]) < 1e-6) # 顺序
16 for (row, col) in zip(*all_locations):
17 if row == col: # 当最小值出现在对角线上时,继续
18 continue
19 merge_dims = [row, col] # 否则得到最小距离对应的索引
20 break
21 merge_node = ClusterNode()
22 del_nodes = [cluster_nodes.pop(dim) for dim in
23 sorted(merge_dims, reverse=True)]
24 for node in del_nodes:
25 merge_node.merge(node)
26 merge_node.centroid = np.mean(X[merge_node.samples], axis=0)
27 cluster_nodes.insert(0, merge_node) # 将合并后的节点插入到最前面的位置
28 return cluster_nodes在上述代码中,第2行是初始化每个样本点为一个簇,并同时初始化该簇对应的簇中心.第6~8是遍历得到簇列表中所有簇对应的簇中心,以及每个簇对应的样本数量。第9~11行是计算式(11-52)中簇间距离前面的权重。第12行是计算各个簇之间的距离并乘上权重值,最后将会得到一个形状为[n_cluster,n_cluster]的矩阵,d[i][j]表示第i个簇到底j个簇之间的加权距离;第24行则是计算得到合并后当前簇对应的簇中心;最后,第27行则是返回聚类结束后的簇列表。
最后,只需要在类HierarchicalClustering的fit方法中新引入ward_linkage这个函数调用即可,示例代码如下:
1 def fit(self, X):
2 if self.linkage == "single":
3 cluster_nodes = single_complete_...
4 elif self.linkage == "complete":
5 cluster_nodes = single_complete_...
6 elif self.linkage == "ward":
7 cluster_nodes = ward_linkage(X, self.n_clusters, self.metric)
8 else:
9 raise ValueError(f"link_type 类型错误")
10 labels_ = [-1] * len(X)
11 for cluster_id, node in enumerate(cluster_nodes):
12 for sample in node.samples:
13 labels_[sample] = cluster_id
14 self.labels_ = labels_
15 self.cluster_nodes_ = cluster_nodes11.11.12 Ward使用示例#
在完成整个Ward算法的实现过程后,便可以通过类似如下的方式来进行使用,代码如下:
1 def test_ward():
2 n_clusters = 3
3 X, y = load_iris(return_X_y=True)
4 X = StandardScaler().fit_transform(X)
5 my_ward = HierarchicalClustering(n_clusters=n_clusters, linkage="ward")
6 my_ward.fit(X)
7 logging.info(f"HierarchicalClustering(Ward) "
8 f"调整兰德系数: {adjusted_rand_score(y, my_ward.labels_)}")
9 model = AgglomerativeClustering(n_clusters=n_clusters, linkage="ward")
10 model.fit(X)
11 logging.info(f"AgglomerativeClustering(Ward) "
12 f"调整兰德系数: {adjusted_rand_score(y, model.labels_)}")
13 if __name__ == '__main__':
14 test_ward()上述代码运行结束后便可得到类似如下所示的结果:
1 HierarchicalClustering(Ward) 聚类结果兰德系数为: 0.6969
2 AgglomerativeClustering(Ward) 聚类结果兰德系数为: 0.6153其中AgglomerativeClustering为sklearn中对层次聚类算法的实现,完整示例代码可参见AllBooKCode/Chapter11/C20_hierarchical_clustering.py文件。
11.11.13 小结#
在本节内容中,我们首先介绍了层次聚类的种类包括自下而上的凝聚层次聚类和自上而下的分裂层次聚类;然后介绍了凝聚层次聚类算法的思想与原理,并通过一个简单的示例进行了讲解;最后分别详细的介绍了凝聚层次聚类算法中常见的3种簇结构合并算法,并逐一对其原理和实现过程进行了介绍和示例。
总结一下,在本章中,我们首先介绍了什么是聚类及聚类算法的基本思想,接着介绍了使用最为广泛的Kmeans聚类算法,包括如何通过sklearn进行建模、具体的参数求解过程和详细的代码实现;然后介绍了Kmeans算法的改进版Kmeans++算法,包括其具体原理和实现过程并进一步介绍了聚类场景中常见的4种外部评价指标和3种内部评价指标;接着介绍了如何通过肘部法和轮廓系数法来对K值的选取进行分析;最后分别介绍了另外两种非Kmeans框架下基于密度和基于层次结构的聚类算法的原理及实现过程。
引用#
[1] Ryan Tibshirani, Statistics 36-350: Data Mining, Carnegie Mellon University, Fall 2009
[2] https://en.wikipedia.org/wiki/Hierarchical_clustering
[3] https://en.wikipedia.org/wiki/Single-linkage_clustering
[4] https://en.wikipedia.org/wiki/Complete-linkage_clustering
[6] Ward, Joe H.. “Hierarchical Grouping to Optimize an Objective Function.” Journal of the American Statistical Association 58 (1963): 236-244.
[7] https://en.wikipedia.org/wiki/Ward%27s_method
[8] Kaufman, L. and Rousseeuw, P. J. (1990), Finding Groups in Data: An Introduction to Cluster Analysis, New York: Wiley.
[9] https://scikit-learn.org/stable/modules/clustering.html#hierarchical-clustering