9.5 词向量的微调使用#
在前面几节内容中,我们分别介绍了两种词向量模型的原理和使用方法,不过这些方法也仅仅是停留在单一词向量计算和推理方面,而它更常见的一种用法是作为网络中的词嵌入层进行使用。在本节内容中,我们将会详细介绍如何将预训练的词向量作为网络模型的词嵌入层进行使用。
9.5.1 词嵌入层介绍#
词嵌入层(Word Embedding Layer)是自然语言处理任务中常用的组件之一,它的作用是将离散的词转换为连续的向量表示以便计算机可以更好地理解和处理自然语言。本书中首次提及词嵌入这个概念是在7.6节内容中,我们通过一个词嵌入层将原始的词转换为了一个稠密的向量表示,其原理如图9-13所示。
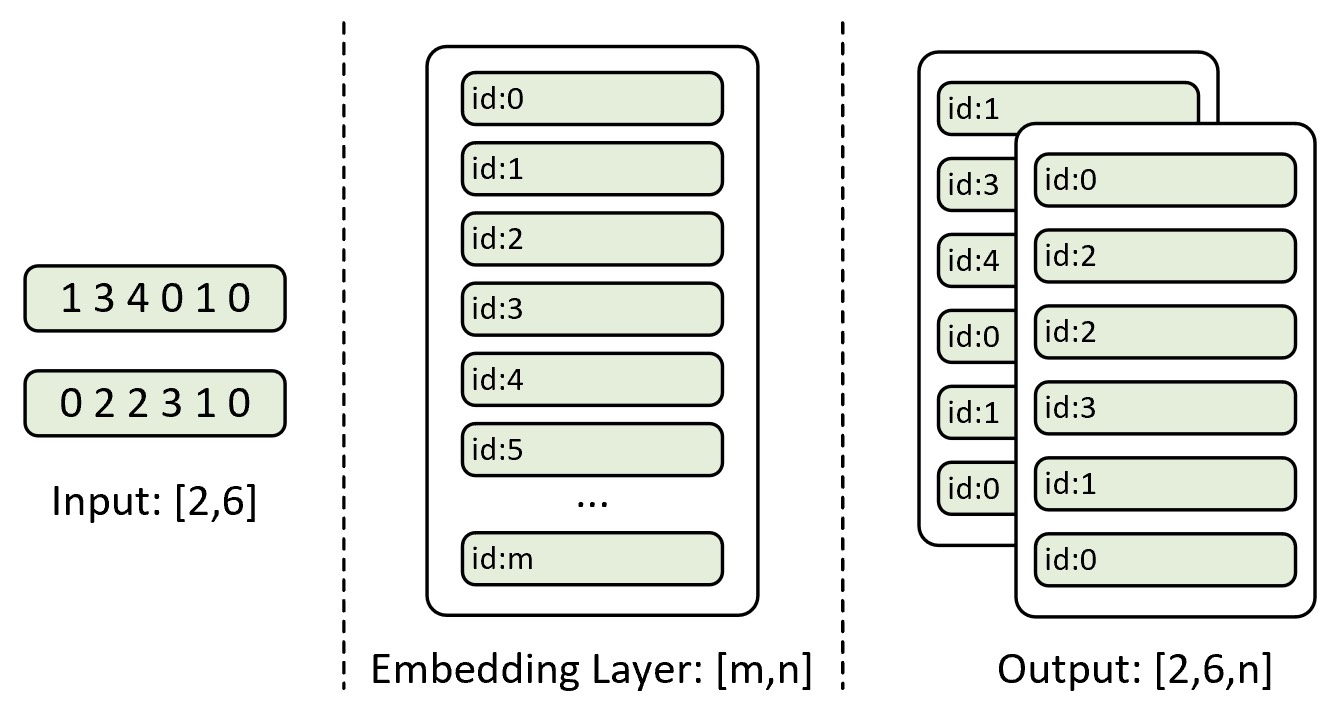
如图9-13所示,最左侧为该任务词表中每个词对应的索引,此时一共有2个样本,每个样本由6个词构成;中间部分为一个词嵌入层,其权重为一个$m\times n$的矩阵,其中$m$表示词表的长度,第$i$行表示词表中第$i$个词的词向量表示,$n$表示词向量的维度;最左侧则是输入的索引在词嵌入层中索引得到的结果。例如对于第1个样本来说它是有词表中第1、3、4、0、1和0个词构成,而词嵌入层则会取权重矩阵的对应行来得到该样本的稠密向量表示。
在自然语言处理中对于原始的文本输入通常都会经过这样一个词嵌入层将其转换为稠密向量表示,其中不同的策略在于词嵌入层中的权重矩阵是随机初始化的还是第三方预训练模型,例如GloVe词向量。
9.5.2 词嵌入层使用#
不管是哪种策略下的词嵌入层都可以通过PyTorch中的nn.Embedding()模块进行实现,下面分别就这两种方式进行介绍。
1. 随机初始化词嵌入层
对于初始化的词嵌入层来说只需要一行代码便可以完成该词嵌入层的初始化并进行使用,示例代码如下所示:
1 if __name__ == '__main__':
2 embedding = nn.Embedding(num_embeddings=20, embedding_dim=3)
3 x = torch.LongTensor([[1, 3, 4, 0, 1, 0], [0, 2, 2, 3, 1, 0]])
4 embedded_input = embedding(x)
5 print("词嵌入层权重: ", embedding.weight[:5])
6 print("词嵌入后输入的形状: ", embedded_input.shape)
7 print("词嵌入后输入的结果: ", embedded_input[0])在上述代码中,第2行是初始化一个词嵌入层,其中num_embeddings和embedding_dim分别表示词表长度和词向量维度。第3行是样本中每个词在词表中的索引。第4行便是经过词嵌入后的结果。
上述代码运行结束后便会得到类似如下结果:
1 词嵌入层权重: tensor([[ 0.9658, -0.4774, 1.7705],
2 [-1.3563, 1.8367, -0.6297],
3 [ 0.0833, -0.6767, -0.2838],
4 [ 0.2031, -0.0171, 0.7267],
5 [ 0.7138, -0.3275, 0.8566]])
6 词嵌入后输入的形状: torch.Size([2, 6, 3])
7 词嵌入后输入的结果: tensor([[-1.3563, 1.8367, -0.6297],
8 [ 0.2031, -0.0171, 0.7267],
9 [ 0.7138, -0.3275, 0.8566],
10 [ 0.9658, -0.4774, 1.7705],
11 [-1.3563, 1.8367, -0.6297],
12 [ 0.9658, -0.4774, 1.7705]])在上述结果中,第2~5行是随机初始化的词嵌入层权重的前5行。第7~12行便是第1个样本经过词嵌入层后的输出结果。
2. 预训练词嵌入层
在使用预训练词向量作为词嵌入层时首先需要根据词表中词的顺序依次从预训练模型中取出,然后再将其作为词嵌入层的权重参数来重新初始化词嵌入层,示例代码如下所示:
1 def load_embedding():
2 pretrained_emb = {'a': torch.randn(3), 'b': torch.randn(3), 'c': torch.randn(3),
3 'd': torch.randn(3), 'e': torch.randn(3), 'f': torch.randn(3), }
4 vocab = {'a': 0, 'b': 1, 'c': 2, 'd': 3,'k':4}
5 embedding_weight = []
6 for word, _ in vocab.items():
7 if word in pretrained_emb:
8 embedding_weight.append(pretrained_emb[word])
9 else:
10 embedding_weight.append(torch.randn(3))
11 embedding_weight = torch.stack(embedding_weight)
12 return nn.Embedding(len(vocab), 3, _weight=embedding_weight,_freeze=False)在上述代码中,第2~3行是模拟构造了一个预训练词向量模型,一共包含有6个词,每个词用一个3维的向量表示。第4行是任务实际对应的词表。第6~10行是遍历词表中的每一个词判断其是否存在于预训练模型中,如果存在则取该词对应的词向量,如果不存在则随机初始化一个向量。第11行是构造得到词向量矩阵。第12行则是用新构造的词向量矩阵来实例化一个词嵌入层,其中_freeze用于指定是否让词嵌入层的权重参数冻结,即词向量是否参与模型训练。
9.5.3 多通道TextCNN网络#
在清楚词嵌入层的使用方法之后下面再通过一个实际的任务进行示例。在8.1节内容中,我们介绍了基于CNN的文本分类模型TextCNN,该模型通过以随机初始化的方式实例化了一个词嵌入层来对文本序列进行向量化表示。接下来,我们将以此为基础再通过GloVe词向量来构建一个词嵌入层,即最终通过两个特征通道来表示输入文本并进行分类。
1. 数据格式化
这里我们使用到的是影评(Movie Reviews, MR)数据集[1],它包含了一系列的电影评论,每个评论都有一个情感标签表示评论是正面还是负面情感,其中政府样本各有5331各样本。下载完成后将会得到rt-polarity.neg和rt-polarity.pos这两个文件,前者为负样本后者为正样本。
为了复用在7.2.4节中实现的今日头条数据集构建模块,我们需要将MR数据集格式化成类似格式。首先实现一个函数来读取每个文件中的样本,示例代码如下所示:
1 def read_data(path):
2 samples = []
3 with open(path, encoding='iso-8859-1') as f:
4 for line in f:
5 samples.append(line.strip('\n'))
6 if 'pos' in path:
7 labels = [1] * len(samples)
8 else:
9 labels = [0] * len(samples) #
10 return samples, labels进一步,格式化数据,示例代码如下:
1 def format_data():
2 file_paths = ['rt-polarity.neg', 'rt-polarity.pos']
3 all_samples, all_labels = [], []
4 for path in file_paths:
5 result = read_data(path)
6 all_samples += result[0]
7 all_labels += result[1]
8 x_train, x_test, y_train, y_test = \
9 train_test_split(all_samples, all_labels, test_size=0.3)
10 with open('./rt_train.txt', 'w', encoding='utf-8') as f:
11 for item in zip(x_train, y_train):
12 f.write(item[0] + '_!_' + str(item[1]) + '\n')在上述代码中,第4~7行是依次读取两个原始文件。第8~9行是将其划分成训练集和测试集两个部分。第10~12行是划分好的数据集保存到本地,其中_!_符号用于分割样本和标签。
最后格式化到本地的数据格式如下:
1 really does feel like a short stretched out to feature length . _!_0
2 has a customarily jovial air but a deficit of flim-flam inventiveness . _!_0
2 as teen movies go , " orange county " is a refreshing change_!_1以上完整示例代码可参见[Code/data/MR/format.py`文件。
2. 数据集构建
由于是复用模块TouTiaoNews的代码,所以只需要继承该类,并实现一个方法来返回词表即可,示例代码如下所示:
1 class MR(TouTiaoNews):
2 DATA_DIR = os.path.join(DATA_HOME, 'MR')
3 FILE_PATH = [os.path.join(DATA_DIR, 'rt_train.txt'),
4 os.path.join(DATA_DIR, 'rt_val.txt'),
5 os.path.join(DATA_DIR, 'rt_test.txt')]
6 def get_vocab(self):
7 return self.vocab.stoi在上述代码中,第2~5行是指定相应路径。第6~7行是返回构造完成的词表,类型为字典。
在使用MR模块构建数据集的过程中将会输出类似如下信息:
1 ## 载入原始文本 rt_train.txt
2 ## 正在根据训练集构建词表……
3 ## 词表构建完毕,前100个词为: [('[UNK]', 0), ('[PAD]', 1), ('.', 2), (',', 3), ('the', 4),...
4 ## 索引预处理缓存文件的参数为:['top_k', 'cut_words', 'max_sen_len', 'is_sample_shuffle']
5 ## 处理原始文本 rt_train.txt
6 ## 原始输入样本为: with rabbit-proof fence , noyce has tailored an epic ...
7 ## 分割后的样本为: ['with', 'rabbit-proof', 'fence', ',', 'noyce', 'has', 'tailored', 'an', ...]
8 ## 向量化后样本为: [15, 0, 0, 3, 0, 31, 0, 19, 506, 170, 51, 5, 0, 3, 0, 21, 2]3. 预训练词嵌入加载
进一步,需要实现一个函数来完成GloVe词向量的载入并同时根据词表完成词嵌入层的初始化,示例代码如下所示:
1 def get_glove_embedding(vocab=None, embedding_size=50):
2 if embedding_size not in [50, 100, 200, 300]:
3 raise ValueError(f"emb_size must in [50,100,200,300], but got {embedding_size}")
4 glove_path = os.path.join(DATA_HOME, 'Pretrained', 'glove6b',
5 f'glove.6B.{embedding_size}d.txt')
6 glove_word2vec_path = os.path.join(DATA_HOME, 'Pretrained', 'glove6b',
7 f'glove.6B.{embedding_size}d.word2vec.txt')
8 if not os.path.exists(glove_word2vec_path):
9 glove2word2vec(glove_path, glove_word2vec_path)
10 model = KeyedVectors.load_word2vec_format(glove_word2vec_path)
11 vocab_size,embedding_weight = len(vocab),[]
12 for word, _ in vocab.items():
13 if word in model:
14 embedding_weight.append(model[word])
15 else:
16 embedding_weight.append(np.random.uniform(-1, 1, embedding_size))
17 embedding_weight = np.array(embedding_weight) #
18 embedding_weight = torch.tensor(embedding_weight, dtype=torch.float32)
19 return nn.Embedding(vocab_size, embedding_size, _weight=embedding_weight)在上述代码中,第1行中vocab用于指定根据训练语料构造得到的词表,embedding_size表示词向量的维度。第2~3行是判断指定的维度是否正确,因为GloVe词向量只有这4中规格。第4~9行是构造预训练模型的路径,并判断是否存在转换后的GloVe模型,详见9.4.4节内容。第10行是载入本地的词向量模型。第12~16行便是构造新的词向量权重矩阵。第17~19行则是实例化返回利用GloVe词向量实例化得到的词嵌入层。
4. 前向传播
这部分实现整体上同7.8.1节中的TextCNN类似,仅仅只是多加入了一个词嵌入层,关键代码如下所示:
1 class TextCNN(nn.Module):
2 def __init__(self, vocab_size=2000, embedding_size=50,vocab=None):
3 super(TextCNN, self).__init__()
4 self.vocab_size = vocab_size
5 self.random_embedding = nn.Embedding(self.vocab_size, self.embedding_size)
6 self.glove_embedding = get_glove_embedding(vocab, self.embedding_size)
7
8 def forward(self, x, labels=None):
9 x_random = self.random_embedding(x)
10 x_random = torch.unsqueeze(x_random, dim=1)
11 x_glove = self.glove_embedding(x)
12 x_glove = torch.unsqueeze(x_glove, dim=1)
13 embedded_x = torch.cat([x_random, x_glove], dim=1) 在上述代码中,第5~6行分别是实例化的两个词嵌入层,前者为随机初始化,后者为GloVe词向量。第9~11行是随机初始化词嵌入层的前向传播过程,并同时将词嵌入后的结果扩展自4个维度,即从 [batch_size, src_len, embedding_size]变为 [batch_size, 1, src_len, embedding_size]。第11~12行同理,也会得到一个同样形状的文本表示矩阵。第13行则是将两者行拼接得到形状为[batch_size, 2, src_len, embedding_size]的结果以便后续进行卷积操作。
由于训练部分代码没有发生实质性的改变所以这里就不在赘述,以上完整示例代码可参见Code/Chapter09/C04_Word2VecCla文件夹。
9.5.4 小结#
在本节内容中,我们首先详细介绍了词嵌入层的原理和应用场景;然后介绍了如何基于PyTorch框架来完成两种策略下词嵌入层的使用;最后以GloVe词向量为例,介绍了如何在TextCNN模型中构建一个多通道的文本表示矩阵完成对影评数据MR的分类任务。
引用#
[1] https://www.cs.cornell.edu/people/pabo/movie-review-data/