3.6 Milvus 模块解析#
在上一节内容中,我们详细介绍了如何从零来构建一个语义检索系统,包括读取文档、文档切块、文本向量化和存储与检索这四步。不过细心的读者可能会发现,我们在使用 LangChain 中的 Milvus 创建向量数据库的时候,除了指定集合名称(其实这个也可以不用指定)外,其它例如 Schema 创建、索引创建、集合创建等操作我们都没执行,但最终看到的结果却是一切都能正常使用。
虽然说起来我们可以用一句话——因为框架都帮我们做了——来解释,但是为了能够更加清晰地掌握 LangChain 框架的使用,这篇文章我们带着大家来简单看一下整个内部的处理流程。
3.6.1 Milvus 类初始化#
首先,我们先通过 LangChain 中 Milvus 类初始化方法中的常见参数来一窥整个全貌,代码如下:
1 class Milvus(VectorStore):
2 def __init__(
3 self,
4 embedding_function: Optional[Union[EmbeddingType, List[EmbeddingType]]],
5 collection_name: str = "LangChainCollection",
6 collection_description: str = "",
7 text_field: str = TEXT_FIELD,
8 vector_field: Union[str, List[str]] = VECTOR_FIELD,
9 primary_field: str = PRIMARY_FIELD,
10 auto_id: bool = False,
11 drop_old: Optional[bool] = False,
12 enable_dynamic_field: bool = False,
13 index_params: Optional[Union[dict, List[dict]]] = None,在上述代码中,第4行指定使用的词嵌入模型,例如 DashScopeEmbeddings() 对应的实例化对象。第5~6行分别指定集合的名称和对应集合的描述信息,其中 collection_name 的默认值便是 "LangChainCollection"。第7行指定指定原始文本的字段名,默认为 "text"。第8行 vector_field 表示指定向量字段的名称,默认值为 "vector";同时可以指定为一个列表是 LangChain 为多字段 Embedding 场景预留的接口。第9~10行是指定主键名称字段,默认为"pk",以及是否设定为自增。第11行是判断数据库存在时是否删除。第12行是指定是否启用动态字段,详见本章第3.3节内容。第13行指定构建索引时的参数,例如 {'index_type': 'FLAT', 'metric_type': 'L2', 'dim': '2048', 'field_name': 'vector', 'index_name': 'vector'}。
3.6.2 向量化流程#
在介绍完 Milvus() 类中的几个常用参数以后,我们再来看一下整个向量入库时的流程。根据上一节内容可知,把切块后的文本对象放到 Milvus 数据库我们只进行了两个步骤:实例化类对象 Milvus() 以及使用 vector_store.add_documents(documents=docs) 来进行向量入库。对于整个集合创建、 Schema 创建、索引创建和向量入库等流程,如图1所示。
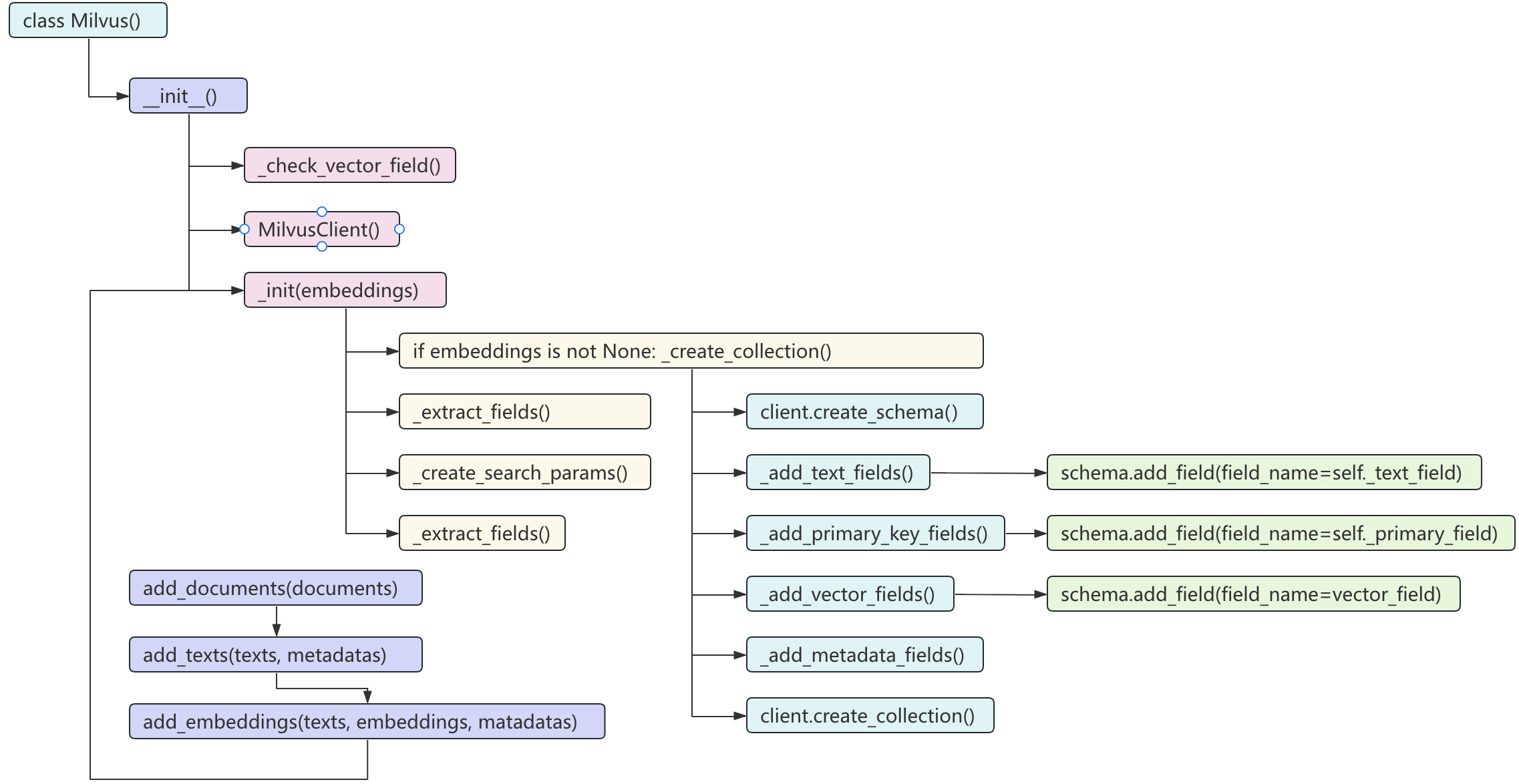
从图3-6可以看出,当实例化Milvus() 类时会调用 _check_vector_field()、MilvusClient() 和 _init(embeddings) 这3个方法或类,其中MilvusClient() 则是 Milvus 原生的客户端实现类,embeddings 指的是原始的文本块。从这里可以看出,在实例化 Milvus() 类对象时, _init() 只会执行 _extract_fields()、_create_search_params() 和 _extract_fields() 这3个方法,因为此时的 embeddings 为 None 。
进一步,在通过调用类方法 add_documents() 时,会依次调用 add_texts(texts, metadatas) 、add_embeddings() 和 _init(embeddings),其中 add_texts() 方法将会把文本转换成向量,而 add_embeddings() 的作用便是将向量及 metadata 放到数据库中。可以发现此时 add_embeddings() 内部会再次调用_init(embeddings)方法,这个时候才会正在的创建 Schema 、集合等,并完成向量入库。
所以,在实例化类 Milvus() 以后仅仅只是完成库的建立,集合并没有创建,这一点大家可以根据上一节中的示例代码进行验证。反过来想,只有在调用 add_documents() 时才能知道完整的 Schema 信息,那么在这之前自然也就不能创建集合了。