10.10 BERT问题回答模型#
经过前面几节内容的介绍,我们已经清楚了BERT模型的基本原理以及如何基于BERT预训练模型来完成文本分类和问答选择这些下游微调任务。在接下来的这节内容中,我们将会继续介绍基于BERT预训练模型的第3个下游任务微调场景,问题回答任务。所谓问题回答是指同时给模型输入一个问题和一段描述,最后需要模型从给定的描述中预测出答案所在的位置。
例如:
描述:苏轼是北宋著名的文学家与政治家,眉州眉山人。
问题:苏轼是哪里人?
标签:眉州眉山人
在完成这个任务之前首先需要明白的是:①最终问题的答案一定存在于给定的文本描述中;②问题的答案一定是给定描述中的一段连续的字符,即不能有间隔。例如对于上面的描述内容来说,如果给出的问题是“苏轼生活在什么年代以及他是哪里人?”,那么模型最终并不能给出类似“北宋”和“眉州眉山人”这两个分离的答案,最好的情况下便是给出“北宋著名的文学家与政治家,眉州眉山 人”这一段连续的文本序列。
在有了这两个限制条件以后,对于这类问答任务其本质也就变成了需要让模型预测得到答案在文本描述中的起始位置(Start Position)和结束位置(End Position),而这也叫做文本片段(Text Span)预测。因此,问题最终就变成了如何在BERT模型的基础之上再构建一个分类器来对BERT最后一层输出的每个位置进行分类,依次判断它们是否属于开始位置或结束位置。
10.10.1 任务构造原理#
正如上面所说,尽管问题回答任务看似复杂但其本质依旧可以归结为一个普通的分类任务,只是解决这个问题的关键在于如何构建整个数据集。如图10-32所示便是一个基于BERT预训练模型的问题回答模型的原理图。
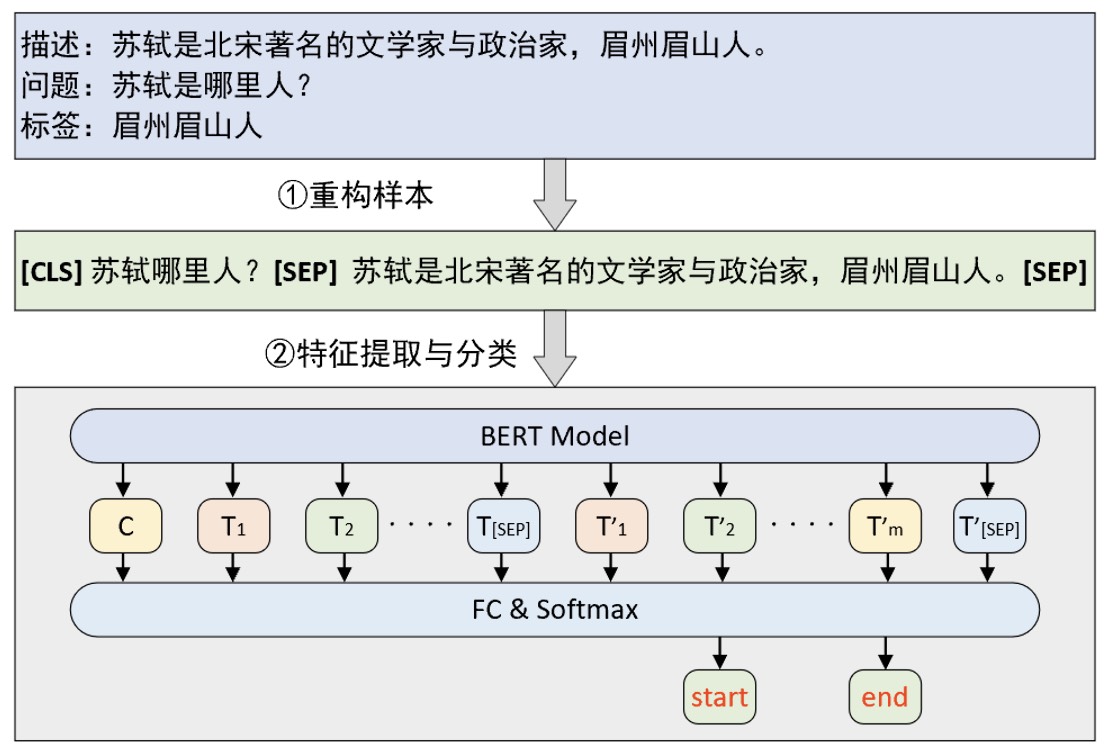
从图10-32可以看出,构建模型输入的方式就是将原始问题和上下文描述拼接成一个序列中间用[SEP]符号隔开,然后再分别输入到BERT模型中进行特征提取。在BERT编码完成后再取最后一层的输出对每个位置上的向量进行分类即可得到开始位置和结束位置的预测输出。
10.10.2 样本构造与结果筛选#
1. 输入介绍
在正式介绍如何构建数据集之前我们先来看对于上下文过长时的情况该怎么处理。在问题回答这个任务场景中,当原始上下文的长度超过给定长度或者是512个字符时,可以采取滑动窗口的方法来构造整个模型的输入序列,如图10-33所示。
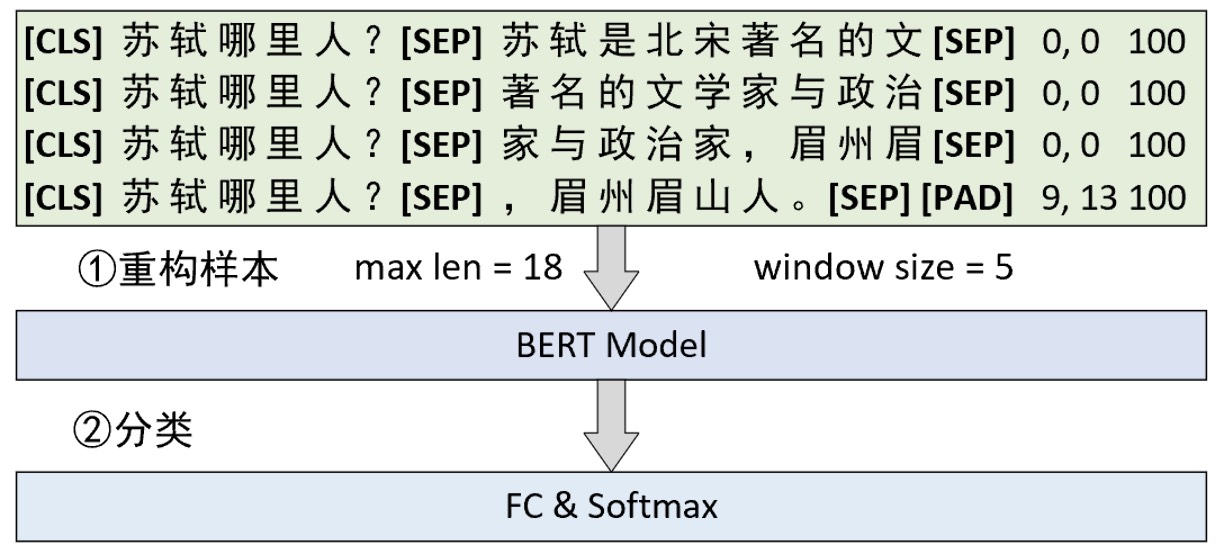
如图10-33所示,第①步需要是根据指定的最大长度和滑动窗口将原始样本进行滑动窗口处理并得到多个子样本。这里需要注意的是,句子A也就是问题部分不参与滑动处理。同时,图10-33中样本右边的3列数字分别表示在每个子样本中答案的起始位置、结束位置和原始样本对应的编号。紧接着第②步便是将所有原始样本滑动处理后的结果作为训练集来训练模型。
总的来说,在这一场景中模型的训练程并不复杂,因为每个子样本也都有其对应的标签值和普通的训练过程并没有什么本质上的差异。因此, 最关键的地方在于如何在推理过程中也使用滑动窗口。
2. 结果筛选
一种最直观的做法是直接取起始位置预测概率值加结束位置预测概率值最大的子样本对应的结果,作为整个原始样本对应的预测结果。虽然这样的做法虽然简单但最终模型的准确率并不高,而下面介绍的筛选法就会得到更好的预测结果。
如图10-34所示,在推理过程中第①步仍旧需要根据指定最大长度和滑动窗口大小将原始样本进行滑动窗口处理。接着第②步是根据模型分类的输出取前K个概率值最大的结果。在图10-34中K=4,因此对于每个子样本来说其开始位置和结束位置分别都有4个候选结果。例如,第②步中第1行的 7:0.41、10:02、9:0.12和2:01分别表示对于第1个子样本来说,开始位置为索引7的概率值为 0.41,其它同理。
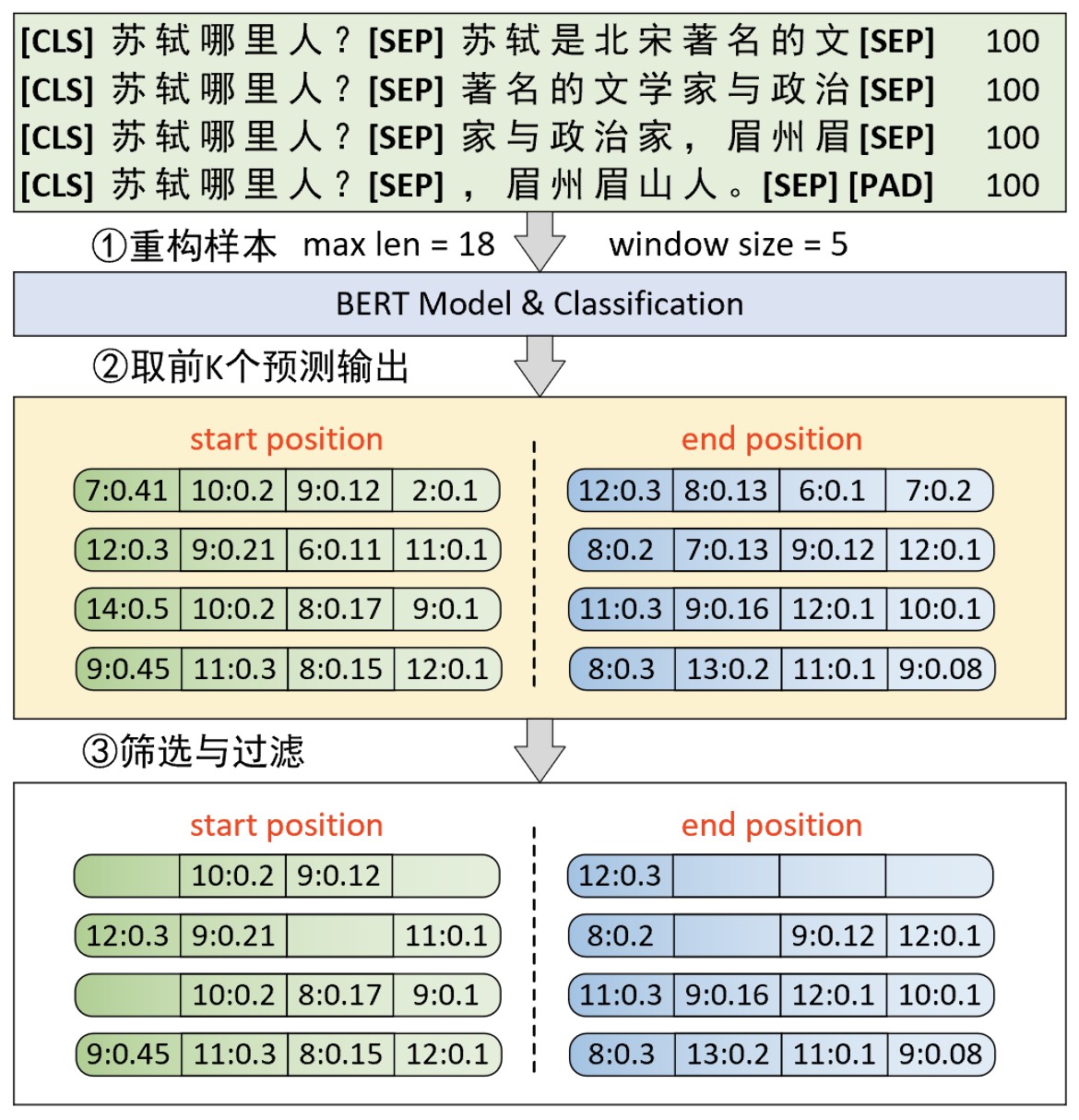
此时对于每一个子样本来说,在分别得到开始位置和结束位置的前K个候选值后便可以通过组合来得到更多的候选预测结果,然后再根据一些规则来选择最终原始样本对应的预测输出。根据图10-34中样本重构后的结果可以看出:(1)最终的索引预测结果需要大于8,因为句子A的长度已经是7,而答案只可能在上下文中出现;(2)在结果组合中,起始索引必定小于等于结束索引。因此,根据这两个条件在经过步骤③的处理后,便可得到进一步筛选后的结果。例如:对于第1个子样本来说,开始位置中7和2不满足条件(1)所以可以直接去掉,同时为了满足第(2)个条件所以在结束位置中8、6和7均需要去掉。
进一步,将第③步处理后的结果在每个子样本内部进行组合,并按照开始位置加结束位置概率值的大小进行排序,便可以得到如图10-35