2.4 千问大模型接入与使用#
上一节介绍了阿里云百炼、DashScope 与通义千问之间的关系。本节将进一步说明如何在阿里云百炼平台中准备模型调用环境,并分别通过 DashScope 原生 SDK、OpenAI 兼容模式以及 LangChain 相关组件调用千问系列模型。
2.4.1 阿里云百炼模型服务#
首先进入阿里云百炼官网(https://bailian.console.aliyun.com/ ),可以通过支付宝或淘宝扫码登录。登录成功后,在页面左上角选择“模型服务”,即可进入如图 2-4 所示的模型服务页面。
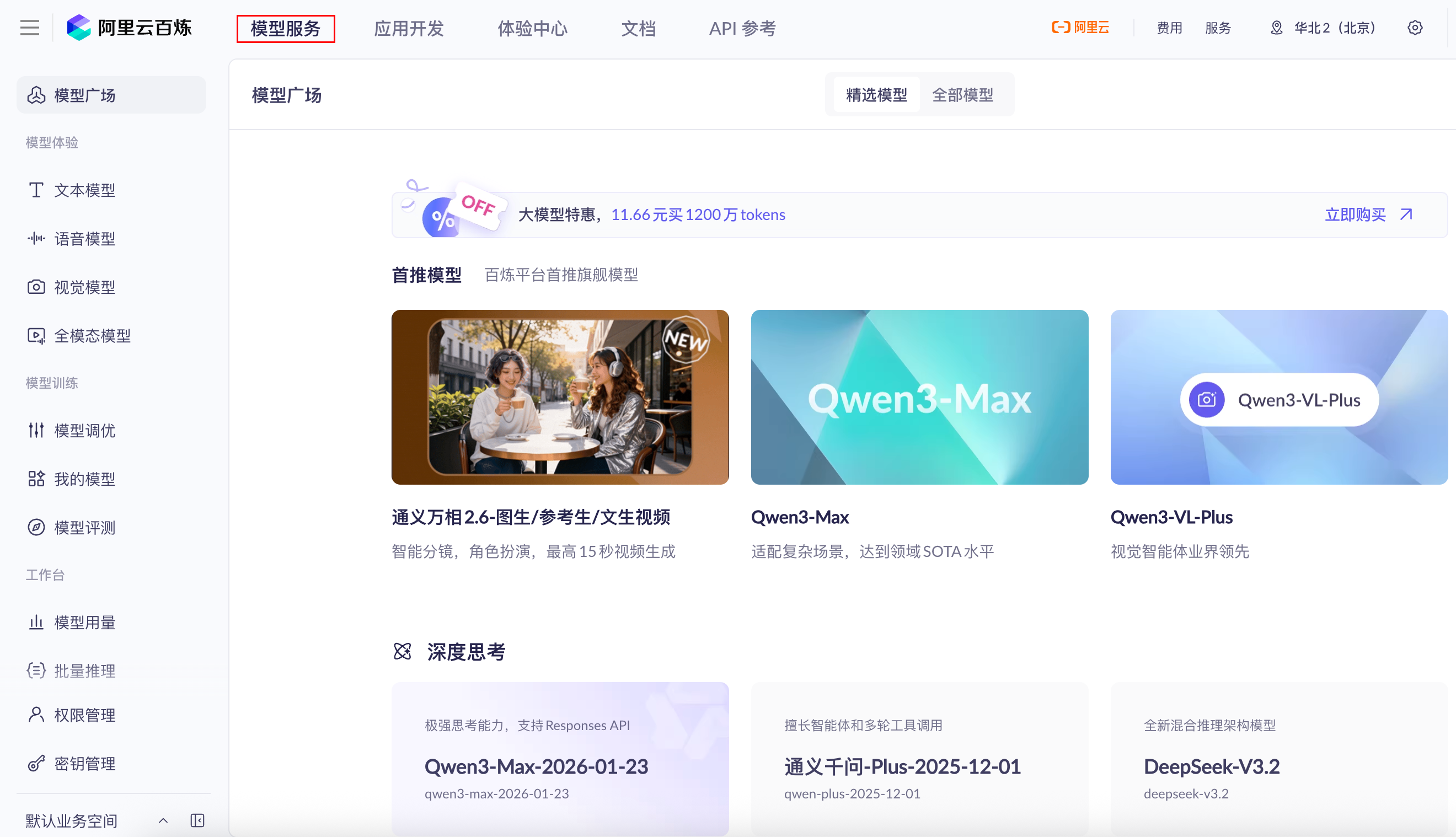
进一步点击左侧的“模型用量”菜单,可以查看当前账号下可用的模型及其用量信息,包括大语言模型、视觉模型、全模态模型等。对于每个模型的具体能力,可以在左侧“模型体验”入口中进行试用和了解。
如图 2-5 所示,部分模型会提供测试额度。后续示例主要用于学习和开发验证,建议优先使用带有免费测试额度的模型,并在控制台中开启“免费额度用完即停”或类似的用量控制选项,以降低误调用带来的计费风险。
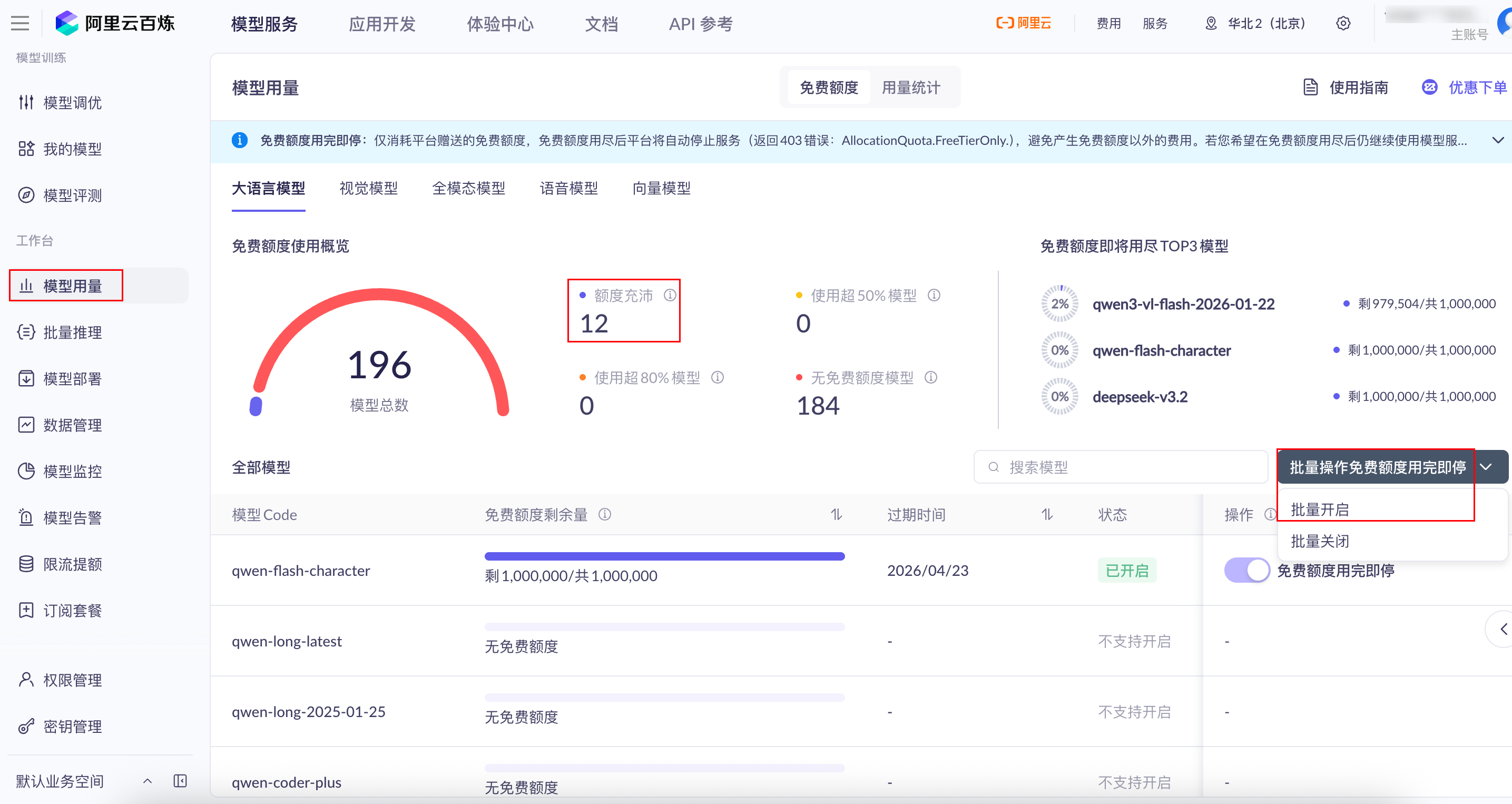
在实际开发中,还应定期通过控制台中的用量统计功能查看模型调用量、Token 消耗和资源包使用情况。对于生产环境,应结合业务规模设置更严格的预算、告警和权限管理策略。
2.4.2 创建并配置 API Key#
为了在代码中调用阿里云百炼平台中的模型,需要先创建 API Key。进入百炼控制台后,可以按照图 2-6 所示路径进入 API Key 管理页面。
点击“创建 API Key”后,将进入如图 2-7 所示页面。
确认创建后,即可在列表中看到如图 2-8 所示的 API Key。该密钥将作为后续代码访问百炼平台的身份凭证。
在示例代码中,可以通过如下方式将 API Key 写入环境变量:
1 os.environ['DASHSCOPE_API_KEY'] = "YOUR_DASHSCOPE_API_KEY"不过,在真实项目中不建议将密钥明文写入代码文件。更常见的做法是将密钥配置到操作系统环境变量、.env 文件或专门的密钥管理服务中,再由程序运行时读取。例如,在 Linux 或 macOS 终端中,可以将环境变量追加到 ~/.bashrc 或 ~/.zshrc 文件中:
1 # 用实际的百炼 API Key 替换 YOUR_DASHSCOPE_API_KEY
2 echo "export DASHSCOPE_API_KEY='YOUR_DASHSCOPE_API_KEY'" >> ~/.bashrc然后执行以下命令使配置生效:
1 source ~/.bashrc重新打开终端窗口后,可以通过如下命令检查环境变量是否已经生效:
1 echo $DASHSCOPE_API_KEY如果输出结果为前面创建的 API Key,则说明环境变量配置成功。后续示例代码将默认通过 os.getenv('DASHSCOPE_API_KEY') 读取该密钥。
2.4.3 调用 Chat 模型#
完成 API Key 配置后,即可在 Python 中调用千问系列 Chat 模型。本节分别介绍3种常见方式:DashScope 原生 SDK、OpenAI SDK 兼容模式以及 LangChain 中的 OpenAI 适配组件。完整示例代码可参见 Code/Chapter02/C01_LLM_usage.py 文件。
(1)使用 DashScope 原生 SDK
使用 DashScope 原生 SDK 调用 Chat 模型时,可以通过 dashscope.Generation.call() 发起请求:
1 os.environ['DASHSCOPE_API_KEY'] = "YOUR_DASHSCOPE_API_KEY"
2 import dashscope
3 def test_dashscope_chat(messages):
4 response = dashscope.Generation.call(
5 api_key=os.getenv('DASHSCOPE_API_KEY'),
6 model="qwen-flash-character",
7 messages=messages,
8 result_format='message')
9 print(response)在上述代码中,第 5 行通过环境变量读取百炼 API Key,第 6 行指定需要调用的模型名称,第 7 行传入符合对话格式的 messages 参数,第 8 行指定返回结果采用消息格式。由于示例使用的是 DashScope 原生 SDK,因此通常不需要显式指定模型调用地址;如果需要访问特定区域或特定部署地址,可以根据平台文档在请求参数中配置相应的访问地址。
可以通过如下方式构造输入并运行示例:
1 if __name__ == '__main__':
2 messages = [
3 {"role": "system", "content": "You are a helpful assistant."},
4 {"role": "user", "content": "上海在哪儿?"}]
5 test_dashscope_chat(messages)代码执行后,会得到类似如下返回结果:
{"status_code": 200, "request_id": "4c5d7a66-fd79-484f-ba29-d70a59a51437", "code": "", "message": "","output": {"text": null, "finish_reason": null, "choices": [{"finish_reason": "stop", "message": {"role": "assistant", "content": "位于中国东部,是直辖市之一,也是中国的经济、金融中心。你有什么具体想了解的方面吗?"}, "index": 0}]}, "usage": {"input_tokens": 23, "output_tokens": 24, "prompt_tokens_details": {"cached_tokens": 0}, "total_tokens": 47}}该结果中包含请求状态、请求 ID、模型输出内容以及词元用量等信息。其中,usage 字段对后续成本统计、性能分析和调用监控都非常重要。
需要注意的是,词元数量并不等同于字符数或汉字数。模型在处理输入和输出时会先进行分词,系统提示词、用户问题、角色标记以及消息结构都可能被计入输入词元。因此,即使用户问题看起来很短,最终统计出的 input_tokens 也可能明显大于表面字符数量。
(2) 使用 OpenAI SDK 兼容模式
如果希望通过 OpenAI SDK 访问千问模型,可以使用 DashScope 提供的 OpenAI 兼容模式。示例代码如下:
1 from openai import OpenAI
2 def test_OpenAI_chat(messages):
3 client = OpenAI(api_key=os.getenv('DASHSCOPE_API_KEY'),
4 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
5 completion = client.chat.completions.create(
6 model="qwen-flash-character",
7 messages=messages)与直接访问 OpenAI 服务不同,代码第 4 行显式指定了 DashScope 的兼容模式地址,第 3 行使用的是百炼平台的 DASHSCOPE_API_KEY。因此,虽然代码形式是 OpenAI SDK,但实际调用目标仍然是阿里云百炼中的千问模型。
使用与上一小节相同的 messages 输入时,返回结果可能类似如下形式:
{"id":"chatcmpl-2837a513-6c0d-991a-9e39-9360c1a5e9af","choices":[{"finish_reason":"stop","index":0,"logprobs":null,"message":{"content":"上海,别称申城、魔都,是中华人民共和国直辖市,国家中心城市,超大城市,位于中国东部、长江口下游、江海交汇之地。东与上海市毗邻,南临杭州湾,北、西与江苏省接壤。面积为 6340.5 平方千米,是一座经济发达、魅力独具的现代化国际大都市。您想了解上海哪些方面的信息呢?","refusal":null, "role":"assistant", "annotations":null,"audio":null,"function_call":null,"tool_calls":null}}],"created":1770945046,"model":"qwen-flash-character","object":"chat.completion","service_tier":null,"system_fingerprint":null,"usage":{"completion_tokens":87,"prompt_tokens":23,"total_tokens":110,"completion_tokens_details":null,"prompt_tokens_details":{"audio_tokens":null,"cached_tokens":0}}}可以看到,兼容模式下的返回结构更接近 OpenAI Chat Completions API 的返回格式。这对于已经基于 OpenAI SDK 开发的项目非常有利,因为上层代码通常只需要替换密钥、接口地址和模型名称,即可完成模型平台切换。
(3)使用 LangChain OpenAI 适配组件
在 LangChain 项目中,常见做法是使用 langchain_openai 包中的 ChatOpenAI 组件,并将接口地址指向 DashScope 兼容模式:
1 def test_LangChain_OpenAI_chat(messages):
2 from langchain_openai import ChatOpenAI
3 chatLLM = ChatOpenAI(
4 api_key=os.getenv('DASHSCOPE_API_KEY'),
5 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
6 model="qwen-flash-character")
7 response = chatLLM.invoke(messages)
8 print(response.model_dump_json())该方式适合已经使用 LangChain 组织提示词、链式调用或 Agent 流程的项目。ChatOpenAI 负责与 LangChain 的统一模型抽象对接,而 base_url 和 api_key 则使实际请求转向 DashScope 兼容接口。后续在构建 RAG 应用时,本书会多次使用类似方式完成模型调用。
2.4.4 调用 Embedding 模型#
在 RAG 系统中,Embedding 模型用于将文本转换为向量表示。文档入库时,需要将文档片段转换为向量并写入向量数据库;用户提问时,也需要将问题转换为向量,再与文档向量进行相似度检索。因此,Embedding 模型是 RAG 检索阶段的基础能力。
与 Chat 模型类似,Embedding 模型也可以通过 DashScope 原生 SDK、OpenAI SDK 兼容模式以及 LangChain 组件调用。
(1)使用 DashScope 原生 SDK
使用 DashScope 原生 SDK 调用 Embedding 模型的示例如下:
1 def test_dashscope_embedding(input_text):
2 from dashscope import TextEmbedding
3 resp = TextEmbedding.call(
4 model="text-embedding-v4",
5 dimensions=1024, input=input_text)
6 print("test_dashscope_embedding")
7 print(resp)
8 input_text = ["跟我学机器学习", "RAG大模型开发"]
9 test_dashscope_embedding(input_text)在上述代码中,第 4 行指定 Embedding 模型名称,第 5 行通过 dimensions 指定输出向量维度,并通过 input 传入待向量化文本。示例中的 input_text 是一个字符串列表,因此模型会分别为列表中的每段文本生成对应向量。
输出结果示例如下:
test_dashscope_embedding
{"status_code": 200, "request_id": "be6eec5c-b212-48aa-b2a5-cd02bbb5f138", "code": "", "message": "", "output": {"embeddings": [{"embedding": [-0.0863448828458786, 0.0336710587143898, 0.030886666849255562, ...], "text_index": 0}, {"embedding": [-0.08091967552900314, -0.012189434841275215, -0.0039899577386677265, ...], "text_index": 1}]}, "usage": {"total_tokens": 11}}返回结果中的 embedding 字段即为文本对应的向量,text_index 表示该向量对应输入列表中的位置,usage 字段则记录了本次向量化消耗的词元数量。
(2)使用 OpenAI SDK 兼容模式
通过 OpenAI SDK 兼容模式调用 Embedding 模型的示例如下:
1 def test_OpenAI_embedding(input_text):
2 from openai import OpenAI
3 client = OpenAI(
4 api_key=os.getenv("DASHSCOPE_API_KEY"),
5 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
6
7 completion = client.embeddings.create(
8 model="text-embedding-v4",
9 input=input_text,
10 dimensions=1024,
11 encoding_format="float")
12 data = completion.model_dump_json()
13 print("test_OpenAI_embedding")该方式同样需要在第 5 行显式指定 DashScope 兼容模式地址。第 7 行调用 OpenAI SDK 中的 embeddings.create() 方法,但实际请求会被发送到百炼平台。第 10 行指定输出向量维度,第 11 行指定向量编码格式。
返回结果示例如下:
{"data":[{"embedding":[-0.0863448828458786,0.0336710587143898,0.030886666849255562,...],"index":0,"object": "embedding"},{"embedding":[-0.08091967552900314,-0.012189434841275215,-0.0039899577386677265,...],"index":1, "object":"embedding"}],"model":"text-embedding-v4","object":"list","usage":{"prompt_tokens":11, "total_tokens":11},"id":"09c9b47c-52a8-9805-b052-557285f41cb5"}该结构与 OpenAI Embeddings API 的返回格式一致,适合已有 OpenAI 风格代码迁移到 DashScope 兼容模式时使用。
(3)使用 LangChain DashScope 组件
LangChain 也提供了面向 DashScope 的 Embedding 封装。示例代码如下:
1 def test_LangChain_dashscope_embedding(input_text):
2 from langchain_community.embeddings import DashScopeEmbeddings
3 embeddings = DashScopeEmbeddings(model="text-embedding-v4")
4 print("test_LangChain_dashscope_embedding")
5 query_result = embeddings.embed_query(input_text[0])
6 print(query_result)
7 doc_results = embeddings.embed_documents(input_text)
8 print(doc_results)其中,embed_query() 通常用于对用户查询进行向量化,embed_documents() 则用于对文档片段列表进行批量向量化。这一区分与 RAG 系统中的检索流程高度对应:查询向量用于检索,文档向量用于构建可检索的知识库。
输出结果示例如下:
[-0.0863448828458786, 0.0336710587143898, 0.030886666849255562, ...]
[[-0.0863448828458786, 0.0336710587143898, 0.030886666849255562, ...],
[-0.08091967552900314, -0.012189434841275215, -0.0039899577386677265, ...]]至此,本节完成了 Chat 模型与 Embedding 模型的基本接入说明。掌握这两类模型的调用方式后,后续即可进一步将模型能力接入文档切分、向量检索、提示词组装和回答生成等 RAG 核心流程。
参考#
[1] https://docs.langchain.com/oss/python/langchain/rag
[2] https://bailian.console.aliyun.com/cn-beijing/?tab=api#/api
[3] https://bailian.console.aliyun.com/cn-beijing/?tab=api#/api/?type=model&url=3016807