11.11 基于层次的聚类算法#
经过前面几节内容的介绍,我们已经清楚了Kmeans、Kmeans++、基于权重的加权Kmeans和DBSCAN这4种聚类算法的原理与实现。总的来说这4种聚类算法各有千秋,分别都能在一些独特的场景中发挥自己的优势。在接下来的这篇文章中,我们将会为大家介绍第5种常见的聚类算法,层次聚类算法(Hierarchical Clustering),如图11-30所示便是整个算法的学习路线图。
11.11.1 HCA算法思想#
现在想象这么一个场景,假如你有大量病人的就医资料,需要通过聚类将其划分为不同的科室,例如消化科、呼吸科和皮肤科等等。但是除此之外,你还想顺便得到每个科室下具体病症的情况,例如呼吸科下面可能有肺炎病人、普通感冒病人等等。如果是通过前面介绍的4种聚类算法来进行建模,那么显然只能得到以科室为颗粒度的聚类结果[1]。
不过此时有读者可能会说,直接以病症为颗粒度进行聚类不就解决了吗?虽然理论上可以这么做,但是这种做法的弊端在于K值太大聚类结果可能不会太理想。同时,在其它我们不知道样本的层次结构中(假如在上面例子中不知道肺炎和感冒属于呼吸科),还能够通过层次聚类算法来发现这种潜在的结构。
在数据挖掘和统计分析中,层次聚类也叫做层次聚类分析(Hierarchical Cluster Analysis, HCA),旨在得到样本簇结构的同时发现样本分布的层次结构[2]。同时,层次聚类算法一般来说可以分为两种,一种是自下而上(Bottom-up)的凝聚层次聚类(Agglomerative Clustering)和自上而下的分裂层次聚类(Divisive Clustering)。
凝聚层次聚类算法在聚类伊始会将数据中的每个样本点均看作是一个独立的簇结构,然后迭代将当前状态下最相似的两个簇进行合并,直到最后只剩下一个簇时聚类结束。对于分裂层次聚类算法来说则恰恰相反,分裂层次聚类算法在聚类伊始将所有的样本点都看成是一个簇,然后迭代将当前状态下最大的簇划分为两部分,直到最后将整个数据集划分成$n$个簇结束[2]。
由于在实际应用中基于自上而下的分裂层次聚类使用较少,所以后续将只介绍采用不同策略下的凝聚层次聚类算法。
11.11.2 HCA示例代码#
在介绍完层次聚类算法的基本思想以后,再来看如何借助sklearn来完成整个层次聚类的建模过程,以下完整示例代码可参见 AllBooKCode/Chapter11/C19_hca_train.py 文件,示例代码如下:
1 from sklearn.cluster import AgglomerativeClustering
2
3 if __name__ == '__main__':
4 n_clusters = 3
5 X, y = load_iris(return_X_y=True)
6 X = StandardScaler().fit_transform(X)
7 model = AgglomerativeClustering(n_clusters=n_clusters, linkage="ward")
8 model.fit(X)
9 print(f"兰德系数为: {adjusted_rand_score(y, model.labels_)}")在上述代码中,第1行代码便是导入sklearn中的凝聚层次聚类算法模块。第4~6行是导入数据集并进行标准化处理。第7行是实例化一个类对象,其中linkage参数表示指定一种层次聚类的算法,取值有'ward'、 'complete'和 'single'这3种,后续也将分别详细进行介绍。第8~9行是先完成整个聚类过程,然后对聚类结果进行评估。
11.11.3 HCA算法原理#
在知道了层次聚类算法的基本思想后再来看聚类过程的具体步骤。根据上面的介绍,可以将整个聚类过程归结为如下3步:
(1)将每个样本点均初始化为一个单独的簇;
(2)如果当前只存在一个簇则进入第(3)步,否则寻找当前状态下最相似的两个簇进行合并;
(3)返回整个聚类合并结果[1]。
如图11-31所示从$a$到$j$一共有10个样本点,下面将按照上述3个步骤来对凝聚层次聚类算法的聚类过程进行示例。
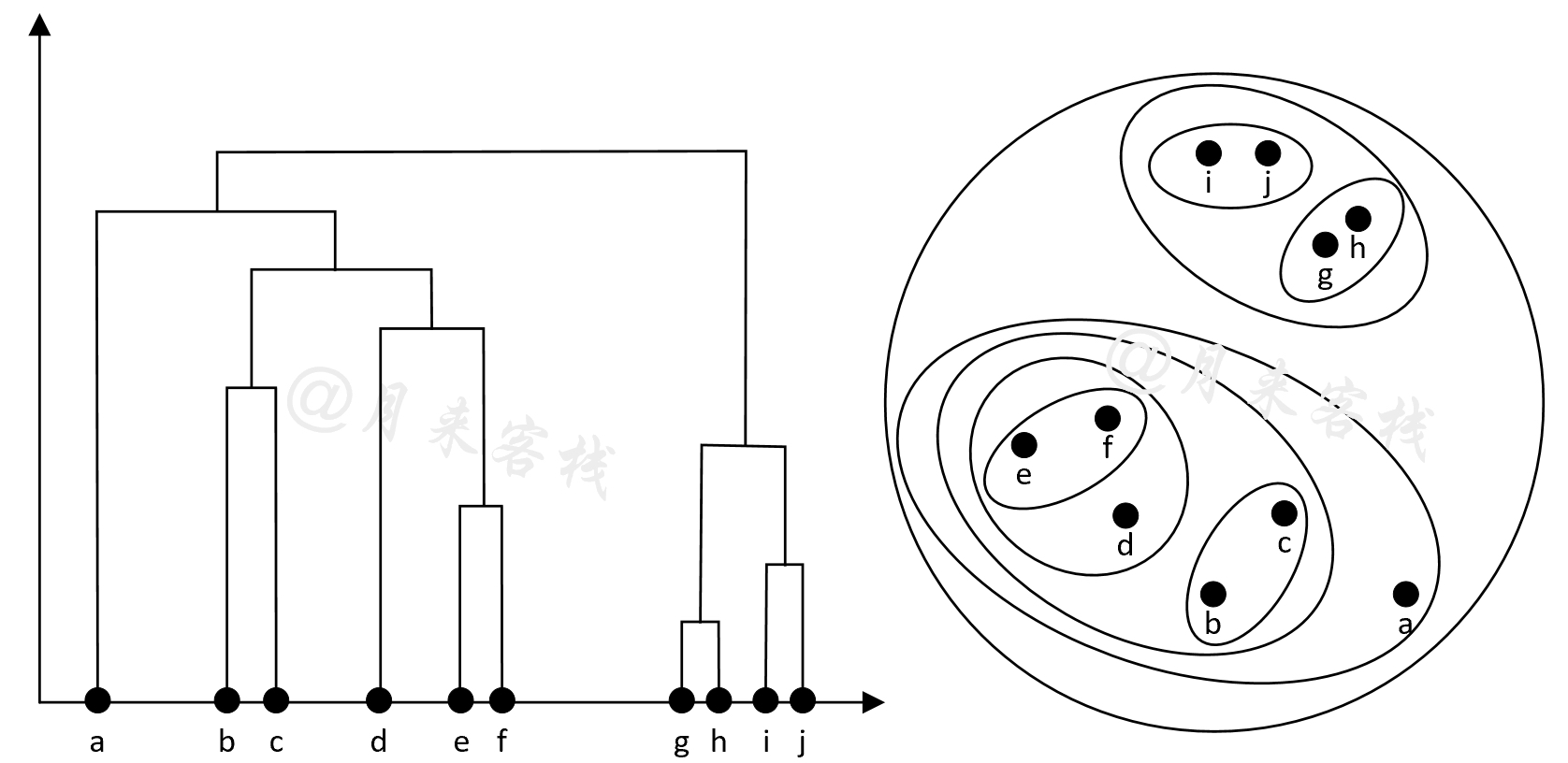
如图11-31右侧所示,首先将这10个样本点均看作是一个单独的簇结构$(\cdot )$;其次假定此时在所有簇的两两组合中,$(g)$和$(h)$这两个簇最相似,那么则将其合并为一个簇$(g,h)$;由于此时不止一个簇所以继续迭代,将$(i)$和$(j)$这两个簇进行合并得到簇$(i,j)$;进一步,根据同样的方式将会得到簇$(e,f)$;同理,再次将$(g,h)$与$(i,j)$合并得到簇$((g,h),(i,j))$;将$(b)$和$(c)$合并得到簇$(b,c)$;将$(d)$和$(e,f)$合并得到簇$(d,(e,f))$;将$(b,c)$和$(d,(e,f))$合并得到$((b,c),(d,(e,f)))$;将$(a)$与$((b,c),(d,(e,f)))$合并得到簇$(a,((b,c),(d,(e,f))))$;最后,将$((g,h),(i,j))$和$(a,((b,c),(d,(e,f))))$合并得到簇$(((g,h),(i,j)),(a,((b,c),(d,(e,f)))))$。由于此时只剩下一个簇,所以层次聚类过程结束。与此同时,我们还可以通过图11-31左侧所示的树状图(Dendrogram)来观察每个簇内部层次结构。
介绍到这里肯定有读者会问,既然凝聚层次聚类算法的终止条件是只剩下一个簇,那么聚类结束后的簇结构到是怎么样的呢?如图11-31左侧所示,在整个聚类过程中,如果不进行最后1次合并那么将会得到两个簇结构;如果在倒数第2次停止合并那么将会得到3个簇结构,以此类推。同时,在每个簇的内部还能看到剩余样本的层次结构。因此实际情况中,如果我们知道真实的簇数量K,那么完全可以在只剩下K个簇的时候停止合并,后续的代码实现也将遵循这一准则。
经过上面的介绍我们发现,凝聚层次聚类算法有两个关键的要素:距离的计算方式和相似性的计算方式(Linkage Criteria)。这一点就类似于K近邻算法一样,也需要两个关键的要素(距离度量方式和决策规则)。因为采用不同的距离计算方式,在后续进行相似性计算时将会得到不同的划分结果。通常在凝聚层次聚类中,距离的度量方式有欧式距离、曼哈顿距离等。对于相似性的度量方式来说常用的有Single-Link、Complete-Link和Ward等[2]。在接下来的内容,我们将分别介绍这3种相似性度量方式的原理及实现过程。
11.11.4 Single-Link算法原理#
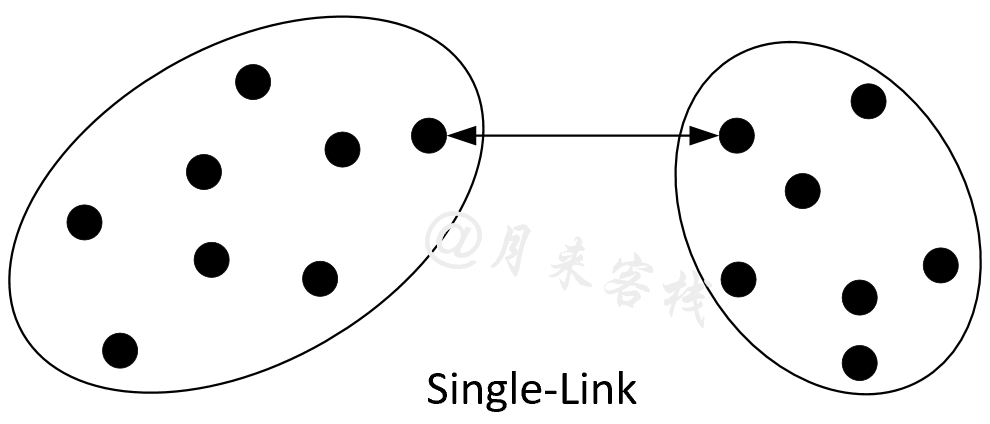
使用Single-Link作为相似性衡量标准的凝聚层次聚类算法也被称之为最近邻聚类(Nearest Neighbour Clustering),其核心思想是根据两个簇之间相邻最近两个样本点的距离来作为相似性评判标准,距离越近则表示这两个簇越相似,即这两个簇越有可能被合并。
如图11-32所示,在聚类过程中对于任意两个簇结构来说,我们需要计算得到相邻两个簇最近样本点之间的距离作为这两个簇相似性的度量值;然后在所有结果中选择相似度最大的值(距离最小)对应的两个簇进行合并;最后按照同样的方法继续进行迭代直到剩余簇数量为1或到达指定值时结束[1]。
假如现在某数据集一共有$a$到$e$这6个样本点,则聚类伊始将这6个样本点均视为6个不同的簇[3]。同时,任意两个簇之间的距离如表11-7所示。
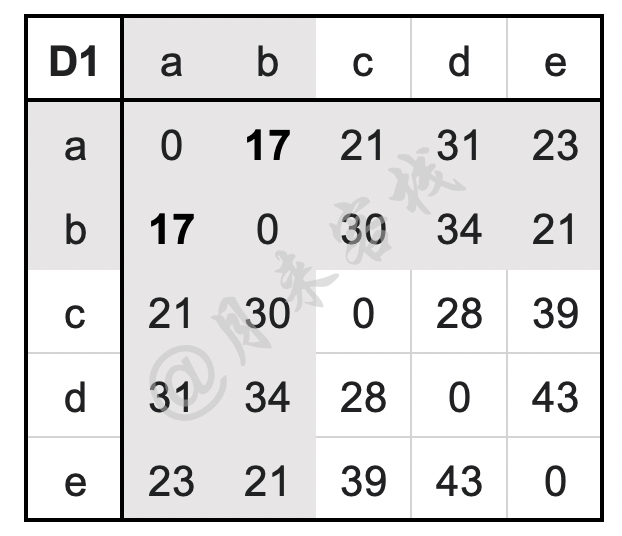
如表11-7所示,D1为一个距离矩阵,用来记录所有簇两两之间的距离。从表中可以看出,此时簇$a$与簇$b$之间的距离最短为17,即最相似,因此将这两个簇进行合并。在合并结束后$a,b$两个簇便合并成了一簇,因此需要删除矩阵D1中簇$a$和簇$b$所在的行与列。同时,由于其它簇两两之间的距离并没有发生改变因此只需要更新簇$(a,b)$与其它3个簇之间的最近距离即可,计算过程如下:
$$ \begin{aligned} \text{D}2((a,b),c)=\min(\text{D}1(a,c),\text{D}1(b,c))=\min(21,30)=21\\[1ex] \text{D}2((a,b),d)=\min(\text{D}1(a,d),\text{D}1(b,d))=\min(31,34)=31\\[1ex] \text{D}2((a,b),e)=\min(\text{D}1(a,e),\text{D}1(b,e))=\min(23,21)=21\\[1ex] \end{aligned}\tag{11-47} $$更新后的距离矩阵D2如表11-8所示。
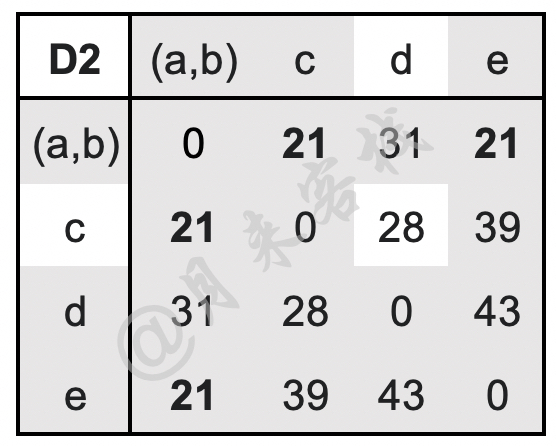
如表11-8所示,此时簇$(a,b)$与簇$c$和簇$d$之间的距离均为21,因此需要将这3个簇进行合并。此时尤其需要注意的一点是,由于D2中是其中一个簇分别与另外两个簇的距离相等(且该距离是簇与簇之间的最短距离),因此可以同时将这3个簇合并到一起。假如此时是簇$(a,b)$与$c$的距离为17,簇$d$和簇$e$之间的距离也是17,那么本次只能是将$(a,b)$与$c$进行合并,或者是将$d$与$e$进行合并,而不能简单地直接将这4个簇进行合并。在簇$(a,b)$与$c$和$e$进行合并后,只需要更新D2中簇$((a,b),c,e)$与剩余其它簇(即仅剩$d$)之间的最近距离即可,计算过程如下:
$$ \begin{aligned} \text{D}3(((a,b),c,e),d)=\min(\text{D}2((a,b),d),\text{D}2(c,d),\text{D}2(e,d))=\min(31,28,43)=28\\[1ex] \end{aligned}\tag{11-48} $$更新后的距离矩阵D3如表11-9所示。
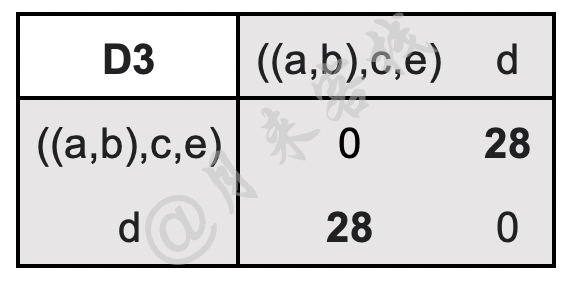
如表11-9所示,此时只剩下$((a,b),c,e)$和$d$这两个簇,因此最后将这两个簇进行合并。最终,根据上述合并过程,我们可以得到如图11-33所示的树状图。
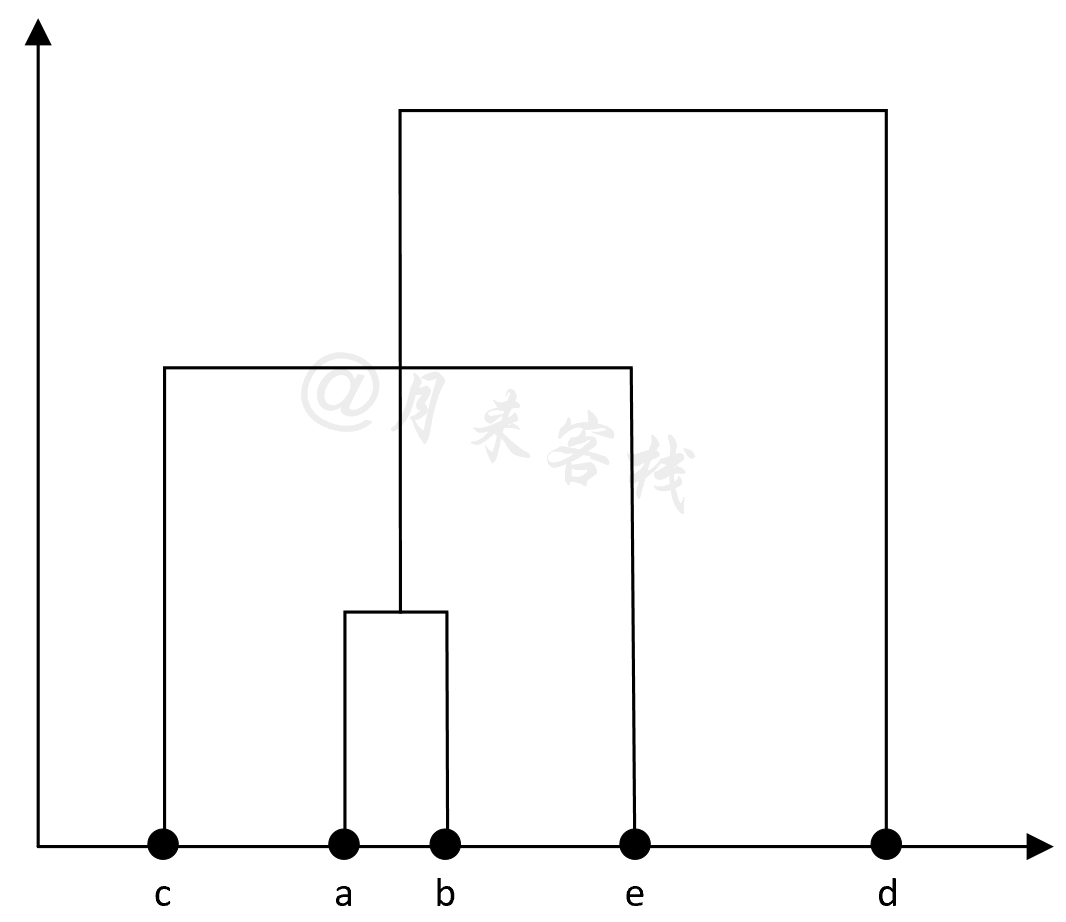
到此,对于基于Single-Link的凝聚层次聚类算法的原理就介绍完了,下面再来介绍如何一步一步实现整个算法。
11.11.5 从零实现Single-Link算法#
在正式介绍Single-Link实现之前,需要先定义节点类来保存每次合并后的簇结构信息,示例代码如下:
1 class ClusterNode(object):
2 def __init__(self, idx=None, centroid=None):
3 samples = []
4 if idx is not None:
5 samples = [idx]
6 self.samples = samples
7 self.n_samples = len(self.samples)
8 self.children = {}
9 self.centroid = centroid在上述代码中,第2行 idx 表示初始化时指定每个每个样本点对应的索引;centroid 表示每个簇对应的簇中心。第6行用来保存当前簇结构中所有样本在原始数据集中的索引。第7行用来保存当前节点对应的样本数量。第8行是保存当前节点对应的孩子节点,即对应的层次信息,如果仅仅只是为了完成聚类任务那么这个参数也可以不用。第9行用来保存当前簇结构对应的簇中心,这个参数只用于 Ward 算法中。
进一步,定义一个类方法来完成簇与簇之间的合并过程,示例代码如下:
1 def merge(self, node):
2 self.samples += node.samples
3 self.children[id(node)] = node
4 self.n_samples = len(self.samples)在定义完簇节点的相关信息后,下面便可以通过一个函数来实现Single-Link算法的逻辑功能,示例代码如下:
1 def single_linkage(X, n_clusters, metric="euclidean"):
2 cluster_nodes = [ClusterNode(i) for i in range(len(X))]
3 old_d = pairwise_distances(X, metric=metric)
4 n_merge = 0
5 while len(cluster_nodes) > n_clusters:
6 n_merge += 1
7 merge_dims = None
8 all_locations = np.where(np.abs(old_d - np.sort(old_d.ravel())
9 [len(old_d)]) < 1e-6)
10 for (row, col) in zip(*all_locations):
11 if row == col:
12 continue
13 merge_dims = [row, col]
14 break
15 merge_node = ClusterNode()
16 del_nodes = [cluster_nodes.pop(dim) for dim in sorted(