8.7 CART生成与剪枝算法#
在8.4节中,我们分别介绍了利用ID3和C4.5这两种算法来生成决策树的过程,其中ID3算法每次用信息增益最大的特征来划分数据样本,而C4.5算法则每次用信息增益比最大的特征来划分数据样本。接下来,再来看另外一种采用基尼不纯度(Gini Impurity)为标准的划分方法,CART算法。
8.7.1 CART算法#
分类与回归树(Classification And Regression Tree, CART),是一种既可以用于分类也可以用于回归的决策树,同时它也是应用最为广泛的决策树学习方法之一。CART假设决策树是一棵二叉树,内部节点的特征取值均为“是”或“否”,即左分支取值为“是”,右分支取值为“否”。这样,决策树在构建过程中就等价于递归地二分每个特征,将整个特征空间划分为有限个单元[2]。
在本书中,我们暂时只对其中的分类树进行介绍。总体来讲,利用CART算法来构造一棵分类树需要完成两步: ①基于训练数据集生成决策树,并且生成的决策树要尽可能大。②用验证集对已生成的树进行剪枝并选择最优子树。
8.7.2 分类树生成算法#
在介绍分类树的生成算法前先来介绍新引入的划分标准——基尼不纯度。在分类问题中,假设某数据集包含$K$个类别,样本点属于第$k$类的概率为$p_k$,则此时的基尼不纯度定义为
$$ \text{Gini}(p)=\sum\limits_{k=1}^{K}{{{p}_{k}}(1-{{p}_{k}})}=1-\sum\limits_{k=1}^{K}{p_{k}^{2}}\tag{8-34} $$因此,对于给定的样本集合$D$,其基尼不纯度为
$$ \text{Gini}(D)=1-\sum\limits_{k=1}^{K}{{{\left( \frac{|{{C}_{k}}|}{|D|} \right)}^{2}}}\tag{8-35} $$其中,$C_k$是$D$中属于第k类的样本子集,$C_k$表示类别$k$中的样本数,$K$是类别的个数。
从基尼不纯度的定义可以看出,若集合$D$中存在样本数的类别越多,则其对应的“不纯度”也会越大,直观地说也就是该集合“不纯”,这也很类似于信息熵的性质。相反,若该集合中只存在一个类别,则其对应的基尼不纯度就会是0,因此,在通过CART算法构造决策树时,会选择使基尼不纯度达到最小值时的特征取值进行样本划分。
同时,在决策树的生成过程中,如果样本集合$D$根据特征$A$是否取某一可能值$a$被分割成$D_1$和$D_2$两部分,即
$$ {{D}_{1}}=\{(x,y)\in D|A(x)=a\},{{D}_{2}}=D-{{D}_{1}}\tag{8-36} $$则在特征$A$的条件下,集合$D$的基尼不纯度定义为
$$ \text{Gini}(D,A)=\frac{|{{D}_{1}}|}{|D|}\text{Gini}({{D}_{1}})+\frac{|{{D}_{2}}|}{|D|}\text{Gini}({{D}_{2}})\tag{8-37} $$其中$\text{Gini}(D,A)$ 表示经$A=a$分割后集合$D$的不确定性。可以看出这类似于条件熵,$\text{Gini}(D,A)$越小则表示特征$A$越能降低集合$D$的不确定性。
在介绍完成基尼不纯度后,就能够列出CART分类树的生成步骤。
输入: 训练数据集$D$,停止计算条件。
输出: CART分类决策树。
根据训练集,从根节点开始,递归地对每个节点进行如下操作,并构建二叉决策树。
(1) 设训练集为$D$,根据式(8-35)计算现有特征对该数据集的基尼不纯度。接着,对于每个特征$A$,对其可能的每个值$a$,根据样本点对$A=a$是否成立将$D$划分成$D_1$和$D_2$两部分,然后利用式(8-37)计算$A=a$时的基尼不纯度。
(2) 在所有可能的特征$A$及它们所有可能的切分点$a$中,选择基尼不纯度最小的特征取值作为划分标准将原有数据集划分为两部分,并分配到两个子节点中去。
(3) 对两个子节点递归的调用步骤(1)和(2),直到满足停止条件。
(4) 生成CART决策树。
其中,算法停止计算的条件通常是节点中的样本点个数小于设定阈值,或样本集合的基尼不纯度小于设定阈值,抑或没有更多的特征,这一点同8.3节中ID3和C4.5算法的停止条件类似。
8.7.3 分类树生成示例#
在介绍完上述理论性的内容后,这里同样还是采用之前的信用卡审批数据集来对具体的生成过程进行详细示例。由表8-1中的数据可知,此时整个数据集对应的基尼不纯度为
$$ \text{Gini}(D)=1-\sum\limits_{k=1}^{K}{{{\left( \frac{|{{C}_{k}}|}{|D|} \right)}^{2}}}=1-{{\left( \frac{5}{15} \right)}^{2}}-{{\left( \frac{10}{15} \right)}^{2}}\approx 0.444\tag{8-38} $$进一步,对于特征$A_1$来讲,根据其取值是否为1,可以将原始样本划分为$D_1$和$D_2$两部分。由式(8-37)得
$$ \text{Gini}(D,{{A}_{1}}=1)=\frac{7}{15}\text{Gini}({{D}_{1}})+\frac{8}{15}\text{Gini}({{D}_{2}})=\frac{7}{15}\times \frac{24}{49}+\frac{8}{15}\times \frac{14}{64}\approx 0.345\tag{8-39} $$同理,对于特征$A_2$来讲,根据其取值是否为1,也可以将原始样本划分为$D_1$和$D_2$两部分。此时有
$$ \text{Gini}(D,{{A}_{2}}=1)=\frac{8}{15}\text{Gini}({{D}_{1}})+\frac{7}{15}\text{Gini}({{D}_{2}})=\frac{8}{15}\times \frac{1}{2}+\frac{7}{15}\times \frac{12}{49}\approx 0.381\tag{8-40} $$进一步,对于特征$A_3$来讲,根据其分别取值是否为D、S和T,每一次也可将原始样本划分为$D_1$和$D_2$两部分。此时有
$$ \text{Gini}(D,{{A}_{3}}=D)=\frac{12}{15}\text{Gini}({{D}_{1}})+\frac{3}{15}\text{Gini}({{D}_{2}})=\frac{12}{15}\times \frac{4}{9}+\frac{3}{15}\times \frac{4}{9}\approx 0.444\tag{8-41} $$$$ \text{Gini}(D,{{A}_{3}}=S)=\frac{11}{15}\text{Gini}({{D}_{1}})+\frac{4}{15}\text{Gini}({{D}_{2}})=\frac{11}{15}\times \frac{56}{121}+\frac{4}{15}\times \frac{3}{8}\approx 0.439\tag{8-42} $$$$ \text{Gini}(D,{{A}_{3}}=T)=\frac{7}{15}\text{Gini}({{D}_{1}})+\frac{8}{15}\text{Gini}({{D}_{2}})=\frac{7}{15}\times \frac{20}{49}+\frac{8}{15}\times \frac{30}{64}\approx 0.440\tag{8-43} $$注意: 每次划分时都将样本集合划分为两部分,即$A_i=a$和$A_i\neq a$
由以上计算结果可知,使用$A_1=1$对样本集合进行划分所得到的基尼不纯度最小。故根节点应该以$A_1=1$是否成立进行分割,如图8-13所示。
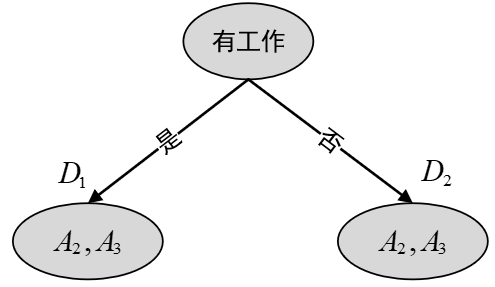
经过这次划分后,原始的样本集合就被特征“有工作”分割成了左右两部分。接下来,再对左右两个集合递归地执行上述步骤,最终便可以得到通过CART算法生成的分类决 策树,如图8-14所示。
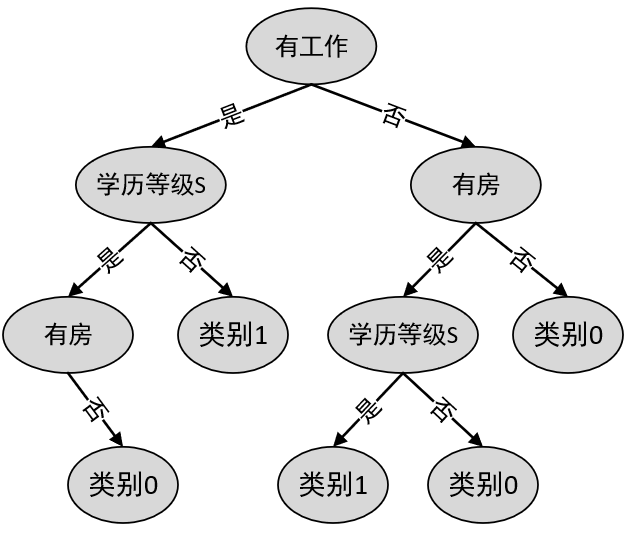
8.7.4 分类树剪枝步骤#
在8.7.3节中,我们介绍了CART中决策树的生成算法,接下来再来看一看在CART中如何对生成后的决策树进行剪枝。根据第4章内容的介绍可知,总体上来讲模型(决策树)越复杂,越容易产生过拟合现象,此时对应的代价函数值也相对较小。在决策树中,遇到这种情况时也就需要进行剪枝处理。CART剪枝算法由两部组成:
(1) 首先从之前生成的决策树$T_0$底端开始不断剪枝,直到$T_0$的根节点,这样便形成了一个子序列$\{T_0,T_1,...,T_n\}$。
(2) 然后通过交叉验证对这一子序列进行测试,从中选择最优的子树。
从上面的两个步骤可以看出,第(2)步并没有什么难点,关键就在于如何通过剪枝来生成这样一个决策树子序列。
1). 剪枝,形成一个子序列
在剪枝过程中,计算子树的损失函数
$$ C_{\alpha}(T)=C(T)+\alpha|T|\tag{8-44} $$其中,$T$为任意子树,$C(T)$为对训练集的预测误差,$|T|$ 为子树的叶节点个数,$\alpha\geq 0$ 为参数。需要指出的是,不同于之前ID3和C4.5中剪枝算法的$\alpha$,前者是人为设定的,而此处则是通过计算得到的。
具体地,从整体树$T_0$开始剪枝,如图8-15所示。
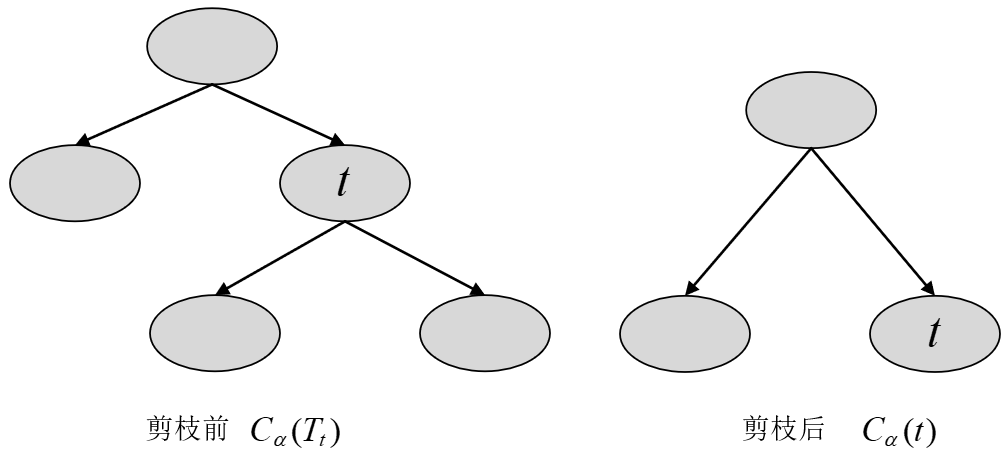
对于$T_0$的任意内部节点$t$,以$t$为根节点的子树$T_t$(可以看作剪枝前)的损失函数为
$$ {{C}_{\alpha }}({{T}_{t}})=C({{T}_{t}})+\alpha |{{T}_{t}}|\tag{8-45} $$同时,以$t$为单节点的子树(可以看作剪枝后)的损失函数为
$$ {{C}_{\alpha }}(t)=C(t)+\alpha \cdot 1\tag{8-46} $$(1)当$\alpha=0$或者极小的时候,有不等式
$$ {{C}_{\alpha }}({{T}_{t}})<{{C}_{\alpha }}(t)\tag{8-47} $$