13.3 Label Spreading 算法#
在上一节内容中,我们介绍了一种基于图结构的标签传播算法。标签传播算法的核心思想认为,在样本空间中距离越相近的样本点越有可能具有相同的标签。因此,对于样本空间中的所有样本点,可以通过构建一个有向完全图来表示样本点之间的位置关系,并以此为基础构建一个概率迁移矩阵来确定未知标签的所属类别。在本节内容中,我们将继续学习另外一种同样也是基于图结构的标签扩散算法(Label Spreading)[1]。
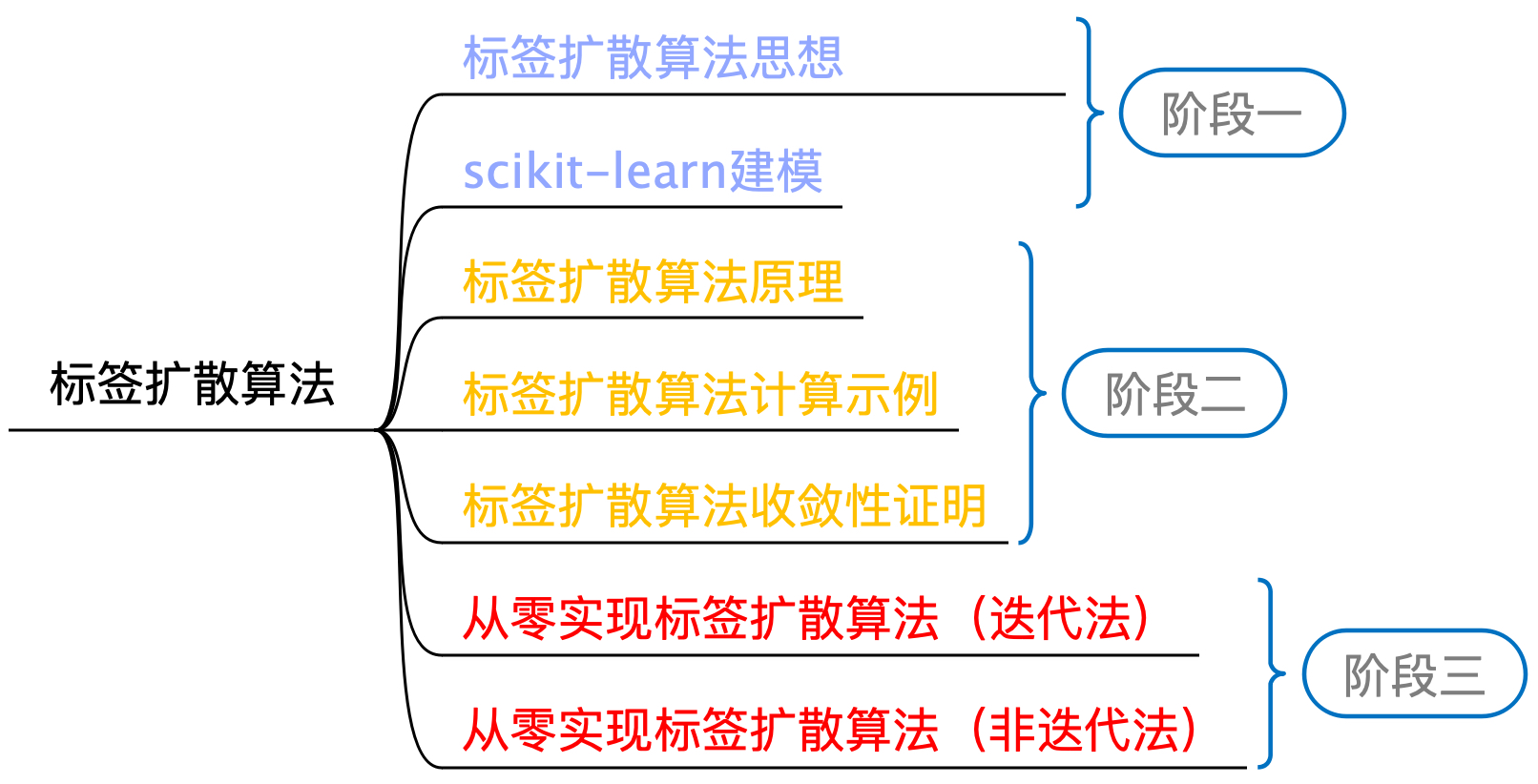
如图13-10所示便是标签扩散算法的学习路线图,我们将先介绍其对应的思想以及sklearn的建模过程,然后再来介绍其背后的原理、计算示例和收敛性证明等过程,最后再一步步来从零实现整个算法。
13.3.1 Label Spreading算法思想#
从本质上来讲,标签传播和标签扩散这两种算法在思想上并没有太大的差别,都是基于样本点的空间位置来构造得到概率迁移矩阵,然后通过概率迁移矩阵用已知标签的样本点来确定未知标签样本点的类别。相比较于标签传播算法来说,标签扩散算法的改进点表现在两个方面:①使用了标准化的拉普拉斯矩阵(Laplace Matrix )来作为概率迁移矩阵,其目的是能够使得在迭代过程中标签的传播更加平滑;②加入了类似于正则化策略的惩罚参数来增加模型的泛化能力。由于标签扩散算法在思想上与标签传播算法并没有什么本质区别,下面首先直接来看标签扩散算法的示例用法。
13.3.2 Label Spreading 示例代码#
在sklearn中,可以从sklearn.semi_supervised中来导入标签传播算法LabelSpreading模块。接下来,需要构造半监督学习所需要使用到的训练集,即将部分样本的标签置为-1,示例代码如下:
1 def load_data():
2 x, y = load_iris(return_X_y=True)
3 x_train, x_test, y_train, y_test = \
4 train_test_split(x, y, test_size=0.3, random_state=2022)
5 rng = np.random.RandomState(20)
6 random_unlabeled_points = rng.rand(y_train.shape[0]) < 0.8
7 y_mixed = deepcopy(y_train)
8 y_mixed[random_unlabeled_points] = -1
9 return x_train, x_test, y_train, y_test, y_mixed在上述代码中,第2~4行是导入原始并进行训练集和测试集的划分。第5~8行则是将训练集中$80\%$样本的标签重置为-1,同时也保留了原始重置之前的标签便于后续在训练集上测试模型的效果。第9行是返回最后各个部分的结果。
进一步,便可以导入LabelSpreading进行模型训练和测试,示例代码如下:
1 def test_label_spreding():
2 x_train, x_test, y_train, y_test, y_mixed = load_data()
3 ls = LabelSpreading(alpha=0.2)
4 ls.fit(x_train, y_mixed)
5 print("Label Spreading")
6 print(f"训练集上的准确率为:{ls.score(x_train, y_train)}")
7 print(f"测试集上的准确率为:{ls.score(x_test, y_test)}")上述代码运行结束后便会得到类似如下所示的结果:
1 训练集上的准确率为:0.9714
2 测试集上的准确率为:1.0上述完整示例代码可参见 AllBooKCode/Chapter13/C06_label_spreading.py 文件。
在学会LabelSpreading模块的使用后,再来对比一下标签扩散和标签传播算法各自在包含噪音数据上的表现。下面以sklearn中的手写体数据集为例来构造相应的训练和测试样本,示例代码如下:
1 from sklearn.datasets import load_digits
2 from sklearn.preprocessing import StandardScaler
3
4 def load_data(noise_rate=0.1):
5 n_class = 10
6 x, y = load_digits(n_class=n_class, return_X_y=True)
7 x_train, x_test, y_train, y_test = \
8 train_test_split(x, y, test_size=0.3, random_state=2022)
9 rng = np.random.RandomState(20)
10 random_unlabeled_points = rng.rand(y_train.shape[0]) < 0.8
11 y_mixed = deepcopy(y_train)
12 y_mixed[random_unlabeled_points] = -1
13 for i in range(len(y_mixed)):
14 if y_mixed[i] == -1:
15 continue
16 if rng.random() < noise_rate: # 在训练集中,将有标签的样本中的noise_rate替换为随机标签
17 candidate_ids = np.random.permutation(n_class).tolist()
18 candidate_ids.remove(y_mixed[i])
19 y_mixed[i] = candidate_ids[0]
20 ss = StandardScaler()
21 x_train = ss.fit_transform(x_train)
22 x_test = ss.transform(x_test)
23 return x_train, x_test, y_train, y_test, y_mixed在上述代码中,第1~2行是导入手写体数据集和特征标准化模块。第5~8行是导入10个类别的数据集,并将其中$70\%$用作训练集。第9~12行是将训练集中$80\%$的样本重置为无标签样本。第13~19行则是将训练样本中,有真实标签样本中的noise_rate替换为随机标签(即制造噪音样本)。第20~22行是对训练集和测试集进行标准化处理;第23行是返回最后处理完成的结果。
进一步,可以定义一个函数来对两个模型的结果进行对比,示例代码如下:
1 def comp(p=0.1):
2 x_train, x_test, y_train, y_test, y_mixed = load_data(noise_rate=p)
3 lp = LabelPropagation(max_iter=200)
4 lp.fit(x_train, y_mixed)
5 print("LabelPropagation")
6 print(f"训练集上的准确率为:{lp.score(x_train, y_train)}")
7 print(f"测试集上的准确率为:{lp.score(x_test, y_test)}")
8
9 ls = LabelSpreading(max_iter=200)
10 paras = {'alpha': np.arange(0.01, 1, 0.02)}
11 gs = GridSearchCV(ls, paras, verbose=1, cv=3)
12 gs.fit(x_train, y_mixed)
13 print("LabelSpreading")
14 print('最佳模型:', gs.best_params_ )
15 print(f"训练集上的准确率为:{gs.score(x_train, y_train)}")
16 print(f"测试集上的准确率为:{gs.score(x_test, y_test)}")
17
18 if __name__ == '__main__':
19 comp()在上述代码中,第2行是载入手写体数据集,并将训练集中有标签样本的$10\%$设定为随机标签。第3~7行是标签传播算法分别在训练集和测试集上的表现结果。第9~16行分别是标签扩散算法在训练集和测试集上的结果,同时这里使用了网格搜索与交叉验证来寻找超参数$\alpha$,这部分内容可以参考5.3.2节内容。
在上述代码中运行结束后便会得到类似如下结果:
1 LabelPropagation
2 训练集上的准确率为:0.8409
3 测试集上的准确率为:0.8241
4 Fitting 3 folds for each of 50 candidates, totalling 150 fits
5 LabelSpreading
6 最佳模型: {'alpha': 0.9899}
7 训练集上的准确率为:0.85759
8 测试集上的准确率为:0.8444从上述结果可以看出,无论是在训练集上还是测试集上标签扩散算法的表现结果都要明显好于标签传播算法。同时,经过网格搜索后可知,当$\alpha\approx0.99$时模型的效果最优。上述代码可参见 AllBooKCode/Chapter13/C07_label_spreading_comp.py 文件。
13.3.3 Label Spreading算法原理#
在介绍完标签扩散算法的使用示例及与标签传播算法的对比以后,再来详细介绍其背后的数学原理。设$(x_1,y_1),(x_2,y_2),...,(x_l,y_l)$为已知标签的数据样本,其中$Y_L=\{y_1,y_2,...,y_l\}$是样本点对应的标签;同时样本的类别数为$C$,并且假定所有的类别均出现在$Y_L$中。继续,设$(x_{l+1},y_{l+1}),(x_{l+2},y_{l+2}),...,(x_{l+u},y_{l+u})$为不含标签的样本点,其中$Y_U=\{y_{l+1},y_{l+2},...,y_{l+u}\}$未知,且通常情况下$l\ll u$。此时有$X=\{x_1,...,x_{l+u}\}$,且$x_i\in R^D$。
首先,我们同样需要先计算任意两个样本点之间的权重距离,如式(13-20)所示
$$ W_{ij}= \begin{cases} \exp\frac{-\|x_i-x_j\|^2}{2\sigma^2}, & \text{if } i \neq j \\[2ex] 0, & \text{if } i=j \\ \end{cases}\tag{13-20} $$从式(13-20)中可以看出,当 $i=j$ 时,即同一个样本点之间的权重距离为0,这样处理是为了避免样本点自身权重过大的问题。同时可以知道,$W$是一个形状为$(l+u,l+u)$的对称矩阵。
进一步,根据式(13-21)来构造样本点之间概率迁移矩阵
$$ S=D^{-\frac{1}{2}}WD^{-\frac{1}{2}}\tag{13-21} $$其中 $D$ 为一个对角矩阵,对角线上每个值为权重 $W$ 中对应行所有所有元素的和,即$D_{ii}=\sum_{j=1}W_{ij}$。同时,$S$ 是标准化后的拉普拉斯矩阵,形状与权重矩阵$W$相同。
接着,再定义一个形状为$(l+u,C)$的标签矩阵$Y$,其每一行用于表示每个样本属于各个类别的概率分布。
最后,只需要迭代式(13-22)便可以求解得到未知标签样本的预测结果:
$$ F(t+1)=\alpha SF(t)+(1-\alpha)Y\tag{13-22} $$其中$F(0)=Y$,$\alpha\in(0,1)$ 用来平衡模型在迭代过程中对于初始标签矩阵的依赖程度,$\alpha$ 越大则表示模型更加依赖于样本的分布情况,即式(13-22) 中等式右边的第一项,这样可以一定程度上增强模型的泛化能力。
13.3.4 Label Spreading 收敛性证明#
在介绍完标签扩散算法的原理后,再来简单看一下为什么算法多次迭代后便会收敛结论。根据式(13-22)可知,此时有
$$ \begin{aligned} F(1)&=\alpha SF(0)+(1-\alpha)Y\\[1ex] F(2)&=\alpha SF(1)+(1-\alpha)Y\\[1ex] \vdots\\[1ex] F(t)&=\alpha SF(t-1)+(1-\alpha)Y\\[1ex] \end{aligned}\tag{13-23} $$进一步可得
$$ \begin{aligned} F(t)=(\alpha S)^tY+(1-\alpha)\sum_{i=0}^{t-1}(\alpha S)^iY \end{aligned}\tag{13-24} $$又因为$0<\alpha < 1$所以有
$$ \lim_{t \to \infty}(\alpha S)^t=0;\;\;\lim_{t \to \infty}\sum_{i=0}^{t-1}(\alpha S)^i=(I-\alpha S)^{-1}\tag{13-25} $$因此
$$ F^{\ast}=\lim_{t \to \infty}F(t)=(1-\alpha)(I-\alpha S)^{-1}Y\tag{13-26} $$由于对于分类任务来说,$F$表示样本所属类别的概率分布,所以式(13-26)还可以等价写为
$$ F^{\ast}=(I-\alpha S)^{-1}Y\tag{13-27} $$也就是说,式(13-22)的整个迭代过程将会等价地收敛于式(13-27)中的结果,因此在实现标签扩散算法时还可以通过式(13-27)来直接计算得到标签概率矩阵。
接着再来看式(13-25)中极限结果的证明,此时有