9.11 含注意力的NMT网络#
在9.9节和9.10节内容中我们分别介绍了NMT模型和注意力机制的原理和实现。在本节内容中,我们将会结合NMT和注意力机制来实现一个完整的含注意力的神经网络翻译模型。
9.11.1 含注意力的NMT结构#
在Seq2Seq任务中,源输入序列的不同部分通常都具有不同的重要性,然而传统Encoder-Decoder模型在处理这一过程时并没有考虑到这种情况。然而在理想情况下,解码器在对不同时刻的输出进行解码时都应该将注意力聚焦在编码器对应的不同时刻上。
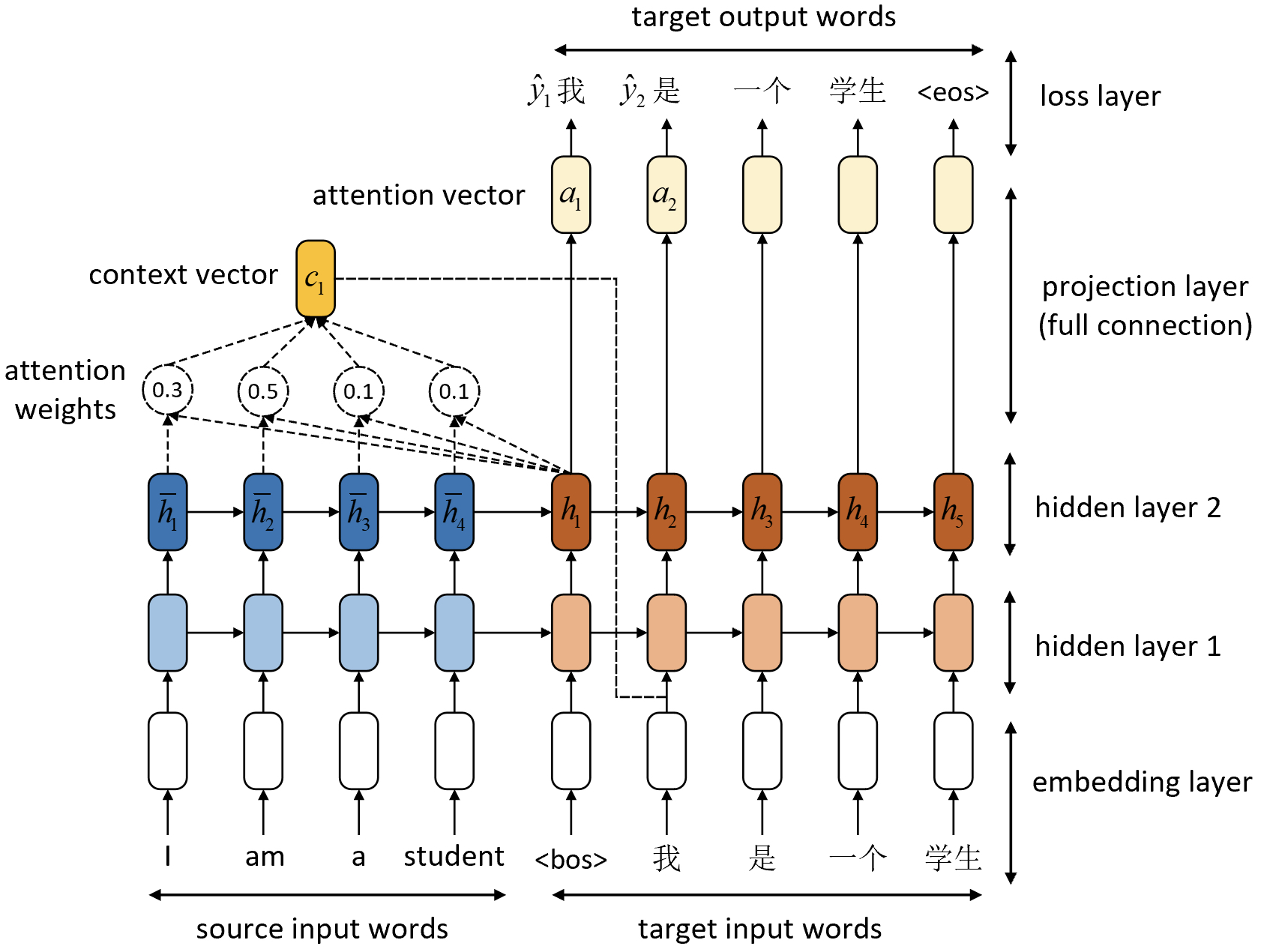
如图9-27所示便是含注意力机制的NMT模型网络结构图。从图中可以看出,解码器在解码第2个时刻时,其输入除了上一个时刻的预测结果“我”之外,还有根据第1个时刻计算得到的上下文向量$c_1$。根据图9-27可知,在解码第2个时刻时应该将更多的注意力集中到编码器’am’对应的隐含向量上,因此理想状态下应该给予该时刻更多的注意力关注。此时,模型将首先取解码器第2层第1个时刻对应的隐含向量$h_1$同编码器第2层所有的隐含向量$\overline{h}_1,...\overline{h}_4$来计算得到对应的上下文向量$c_1$;然后再将$[c_1;\hat{y}_1]$一同作为第2个时刻的输入计算得到$a_2$;最后根据$a_2$分类得到第2个时刻的预测结果$\hat{y}_2$。
9.11.2 含注意力的NMT实现#
在清楚NMT及注意力机制的相关原理后,接下来我们再来看如何实现整个基于注意力机制的解码过程。下面我们基于9.9节所实现的NMT模型进行改进。由于注意力机制只是作用于解码过程,因此我们只需要对解码器部分的代码进行改造即可,其余部分不需要进行任何改动。具体地,我们只需要修改类DecoderWrapper中的逻辑即可完成改造。
1. 改造初始化方法
首先我们需要在初始化方法中加入注意力机制的实例化逻辑,其中关键代码如下所示:
1 class DecoderWrapper(nn.Module):
2 def __init__(self, embedding_size, hidden_size, num_layers, vocab_size,
3 cell_type='LSTM', attention_type='standard', batch_first=True, dropout=0.):
4 super(DecoderWrapper, self).__init__()
5 self.embedding_size = embedding_size
6 ...
7 input_size = self.embedding_size + self.hidden_size
8 if self.attention_type == 'standard':
9 self.attention, input_size = None, self.embedding_size
10 elif self.attention_type == 'luong':
11 self.attention = LuongAttention(hidden_size, dropout)
12 elif self.attention_type == 'bahdanau':
13 self.attention = BahdanauAttention(hidden_size, dropout)
14 self.rnn = rnn_cell(input_size, self.hidden_size, self.num_layers,
15 batch_first=self.batch_first, dropout=self.dropout)在上述代码中,第7行是初始化RNN的输入维度,因为如果使用到注意力机制的话,RNN的输入还包含有上下文向量$c_t$。第8~13行是根据不同的超参数选择使用不同的注意力机制进行解码。
2. 改造前向传播方法
进一步需要改造原有解码器的前向传播过程,示例代码如下所示:
1 def forward(self, tgt_input=None, decoder_state=None,
2 encoder_output=None, src_key_padding_mask=None):
3 tgt_input = self.token_embedding(tgt_input)
4 if self.attention_type == 'standard':
5 outputs, decoder_state = self.rnn(tgt_input, decoder_state)
6 else:
7 tgt_input = tgt_input.permute(1, 0, 2)
8 outputs, self._attention_weights = [], []
9 for tgt_in in tgt_input:
10 tgt_in = tgt_in.unsqueeze(1)
11 if isinstance(self.rnn, nn.LSTM):
12 query = decoder_state[0][-1]
13 else:
14 query = decoder_state[-1]
15 con_vect, attn_weights = self.attention(query, encoder_output,
16 encoder_output, src_key_padding_mask)
17 tgt_in = torch.cat((tgt_in, con_vect), dim=-1)
18 attn_vector, decoder_state = self.rnn(tgt_in, decoder_state)
19 outputs.append(attn_vector)
20 self._attention_weights.append(attn_weights)
21 outputs = torch.cat(outputs, dim=1)
22 return outputs, decoder_state在上述代码中,第1~2行tgt_input是每个时刻解码器的输入形状为[batch_size, tgt_len],decoder_state为解码器上一个时刻的状态,如果是解码第1个时刻则其为编码器最后一个时刻的状态,encoder_output为编码器所有时刻的输出形状为[batch_size, src_len, hidden_size],src_key_padding_mask为注意力掩码用于忽略编码器中填充部分的输出结果形状为[batch_size, src_len]。第3行是词嵌入操作。第4~5行不使用注意力机制。第7行是交互tgt_input的维度,因为后续是逐时刻进行解码,其形状为[tgt_len, batch_size, embedding_size]。第8行用于保存每个时刻的解码输出和注意力权重矩阵。第9行开始逐时刻进行解码,此时tgt_in的形状为[batch_size, embedding_size]。第10行是扩张维度,将变成[batch_size, 1, embedding_size]。第11~14行是判断RNN的类型,因为LSTM的状态包括$h_t$和$C_t$两部分(详见7.3节内容)而 GUR 中只有 $h_t$,进一步取最后一层,此时query的形状为[batch_size, hidden_size]。第15~16行是计算上下文向量和注意力权重,在推理阶段时src_key_padding_mask的传入值将为None,此时con_vect的形状为[batch_size, 1, hidden_size],attn_weights的形状为[batch_size, src_len]。第17~18行则是先将输入和上下文向量组合,然后输入到RNN中进行解码,此时tgt_in的形状为[batch_size, 1, hidden_size+embedding_size],attn_vector的形状为[batch_size, 1, hidden_size]。第19~20行是分别保存注意力向量和注意力权重矩阵。第21行是堆叠得到所有注意力向量,用于后续分类得到所有时刻的预测结果,其形状为[batch_size, tgt_len, hidden_size]。
3. 获取注意力权重矩阵
为了方便获取解码器计算结束后的注意力矩阵,我们可以定一个方法来获取,示例代码如下所示:
1 @property
2 def attention_weights(self):
3 return self._attention_weights在上述代码中,第1行@property修饰器是将方法attention_weights声明为一个类属性,后续可以直接像访问类成员变量一样来调用方法attention_weights。
9.11.3 模型训练#
经过上述过程后,我们便完成了对于含有注意力机制解码器的改造工作,在使用时我们只需要在配置类中通过attention_type来指定注意力机制的类型即可,其它部分同9.9节内中的一致,这里就不再赘述。完整示例代码可参见Code/Chapter09/C07_NMT文件夹。
同时,值得注意的是这里作为讲解示例在NMT的编码器中我们并没有像原论文中那样使用了双向RNN来进行编码,有兴趣的读者可以自行改造实现,其中每个时刻正向反向的输出结果做简单的拼接即可。
9.11.4 小结#
在本节内容中,我们首先详细介绍了含注意力机制的NMT模型的整体结构;然后一步步介绍了如何在原有解码器的基础上实现包含注意力机制的解码过程。这里值得一提的是NMT模型仅仅只是作为利用深度学习来完成翻译任务的开山之作,其效果并没有达到一个可以产品化的程度。直到2016年,谷歌公司又基于Seq2Seq的NMT模型提出了GNMT模型才实现了真正的产品落地,而其中的一个改进就是GNMT的编码器使用了我们在7.1.5节中所介绍的包含残差连接的RNN模型。有兴趣的读者可以自行阅读相关材料研究。