经过前面两章内容的学习,我们已经完成了对线性回归和逻辑回归核心内容的学习,但是机器学习的一些基础概念、模型改善(Optimization)与泛化(Generalization)等内容并没有进行介绍。在第4章中,我们将以线性回归和逻辑回归为例(同样可以运用到后续介绍的其他算法模型中),来介绍机器学习中常见的几个概念和一些模型及数据的处理技巧,并尽可能地说清楚为什么要这么做的原因。由于这部分的内容略微有点杂乱,所以我们将按照如图4-1所示的顺序来递进地进行介绍,同时再辅以示例进行说明。在正式开始继续介绍后续内容之前,我们先来看一看机器学习中的几个基本概念。
4.1 基本概念#
在经过前面两章内容的介绍后,相信大家对于机器学习这个概念已经有了一定感官上的认识。不过到底什么是机器学习呢?机器学习又有哪些类别呢?他和传统的程序设计有什么区别呢?
4.1.1 机器学习概念#
关于到底什么是机器学习(Machine Learning),可能不同的人会有不同的理解,自然也就产生了不同的定义。下面我们主要介绍一下计算领域内两位大师对于什么是机器学习所给出的定义。
第一位是人工智能先驱亚瑟·塞缪尔(Arthur Samuel),他在1959年创造了“机器学习”一词 [1]。塞缪尔认为,所谓机器学习是指: 计算机能够具备根据现有数据构建一套不需要进行显式编程的算法模型来对新数据进行预测的能力。这里所谓不需要进行显式编程便是区别于传统程序算法需要人为指定程序执行步骤的过程。
Field of study that gives computers the ability to learn without being explicitly programmed
第二位是卡内基梅隆大学的计算机科学家汤姆·迈克尔·米切尔(Tom Michael Mitchell),他给出了一个相较于塞缪尔更加正式与学术的定义。米切尔认为,如果计算机程序能够在任务T中学得经验E,并且可以通过指标P进行评价,同时根据经验E还能够提升程序在任务T中的评价指标P,这就是机器学习[2]。这段话对于初学者来讲稍微有点拗口,其实际想要表达的就是,如果一个计算机程序能够自己根据数据样本学习,以此获得经验并通过迭代逐步提高最终的表现结果,则这个过程就被称为机器学习。
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
可以看出,两位大师虽然在对机器学习进行定义时用了不同的语言进行描述,但是从本质上来讲他们说的都是一回事,即能让计算机根据现有的数据样本自己“学”出一套潜在规则的过程。
4.1.2 机器学习分类#
在整个机器学习算法中,按照学习方式的不同主要可以分为有监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)、半监督学习(Semi-supervised Learning )和强化学习(Reinforcement Learning)四类,如图4-2所示。
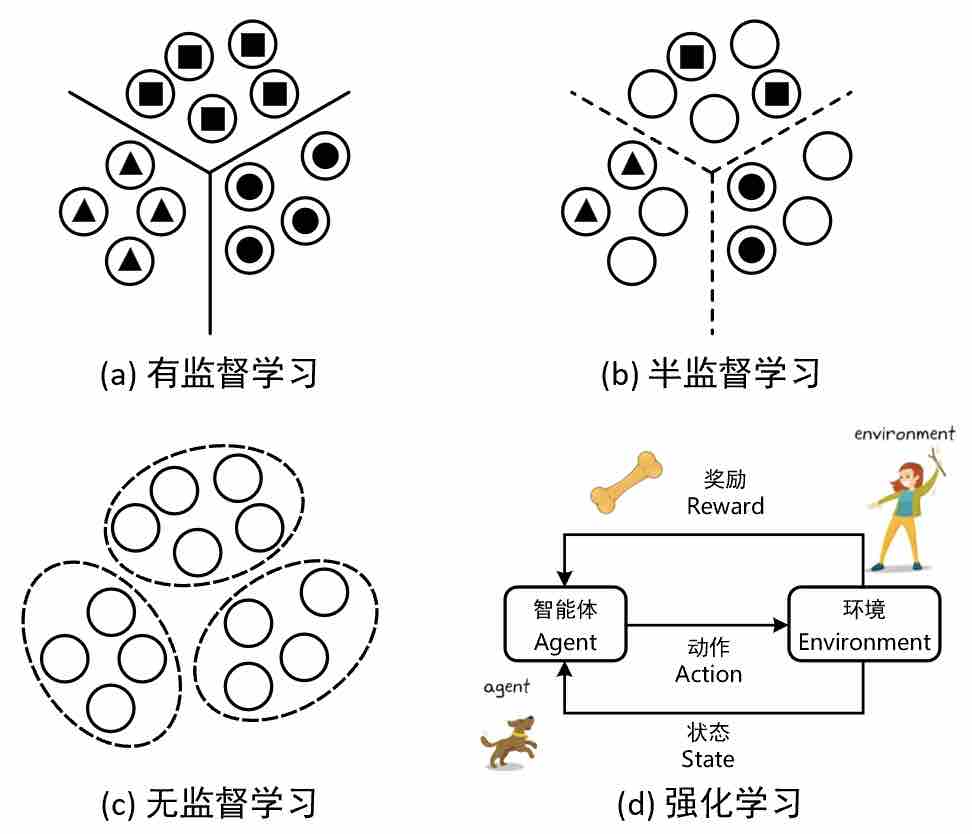
在本书中我们将主要就前面3种类型的算法进行介绍,下面我们依次对这4个概念进行一个简单的介绍。
1. 有监督学习
有监督学习也叫做有指导学习,它是指模型在训练过程中需要通过真实值来对训练过程进行指导的学习过程。在有监督模型的训练过程中,每次输入模型的数据都是形如$(x,y)$这样的样本对,而模型最终学到的就是从输入$x$到输出$y$这样的映射关系。例如在前面两章中介绍的线性回归和逻辑回归,以及后面会陆续介绍的K近邻、朴素贝叶斯、决策树和支持向量机等都是典型的有监督学习模型,因为这些模型在训练过程中都需要通过真实值来指导模型进行学习。
2. 无监督学习
无监督学习也叫做无指导学习,它是指模型在训练过程中不需要通过真实值来对训练过程进行指导的学习过程。在无监督模型的训练过程中,模型仅仅需要输入特征变量便可以进行学习,而模型最终学到的就是输入特征中所潜在的某种模式(Pattern)。例如在第10章中将要介绍的聚类算法就是一类典型的无监督学习模型。
3. 半监督学习
所谓半监督学习它是指介于有监督学习和无监督学习之间的一种机器学习方法。在半监督学习中,模型首先会通过少量的有标签数据来训练一个简单的模型并对无标签的数据进行预测;然后再通过某种策略来对预测出的样本进行筛选并将置信度较高的样本扩充到有标签的数据集中;接着再以整个扩充后的有标签数据来训练新的模型,并以同样的方式进行迭代;最后在满足某种条件下停止并得到训练好的模型。例如在第12章中将要介绍的自训练算法(Self-training)和标签传播算法(Label-Propagation)等都属于这类半监督学习方法。
4. 强化学习
强化学习是另外一种不同于上述三种机器学习算法的范式,其目标是通过代理智能体(Agent)与环境(Environment)的交互学习来达成某种目标或最大化累积奖励。在强化学习中,代理智能体根据环境的状态采取行动,并根据环境的反馈(奖励信号)来调整其行为策略,以使得代理智能体未来获得的奖励最大化。强化学习在许多领域都有广泛的应用,包括机器人控制、自动驾驶、游戏玩法、金融交易等。典型的强化学习算法包括Q学习(Q-Learning)、深度Q网络(Deep Q-Learning Network, DQN)等[3]。
4.1.3 机器学习与人工智能#
经过上面两个小节内容的介绍,我们大致清楚了什么是机器学习。虽然机器学习与人工智能(Artificial Intelligence, AI)并不完全相同,但它们之间却存在着密切的关系。总体来讲,人工智能是一个更加宽泛的概念,它是指由人制造出来的机器所表现出来的智能形式,并且通常是指通过普通计算机程序来呈现人类智能的一类技术[4];而机器学习则是人工智能中的一种应用,可以让机器从数据中提取知识并进行自主学习[5]。同时,在机器学习领域中还能按照建模方式划分得到深度学习,如图4-3所示。
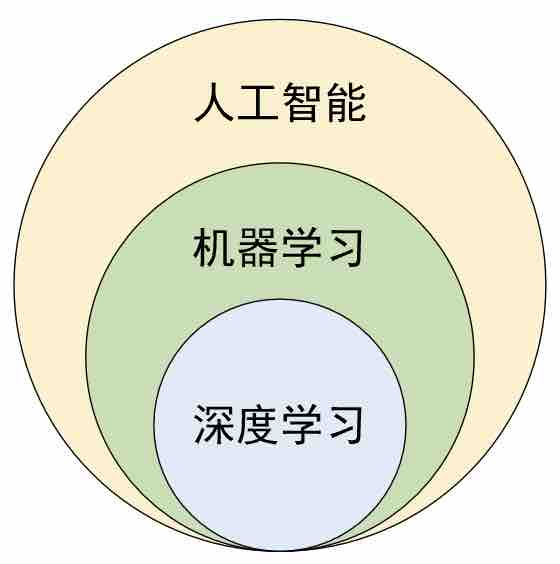
如图4-3所示表示人工智能与机器学习(包括深度学习)之间的关系,从集合的角度来看机器学习是人工智能的一个子集,而深度学习又是机器学习的一个子集。机器学习是一种通过数据和算法来训练计算机程序执行特定任务的一种方法,而人工智能则是一种计算机程序和机器的智能能力,这种能力使得机器可以执行类似于人类的智能行为,因此它涉及到许多不同的技术和方法,包括机器学习、自然语言处理、计算机视觉、语音识别等等。总的来讲,机器学习是实现人工智能的一个重要手段,而人工智能是机器学习的应用之一。
4.1.4 小结#
在本节中,我们首先介绍了什么是机器学习这一基本概念,并引述了计算机领域中两位大师分别对机器学习一词的定义;然后介绍了机器学习算法中的四种基本分类,即有监督学习、无监督学习、半监督学习和强化学习,并同时介绍了它们之间的区别;最后介绍了机器学习和人工智能这两个基本概念的联系与区别。在介绍完这几个基本概念后,下面将正式开始介绍模型改善与泛化的常用方法。