第10章 现代神经网络#
在5.4节内容中,我们初次接触到了预训练(Pre-trained)模型这个概念。预训练模型的主要思想是模型通过在大规模数据集上学习得到通用特征的抽取能力,然后再将其迁移到其他任务中以加速新任务的学习和提高模型性能。预训练模型最早大规模应用于图像处理领域,而其中最具代表性的便是深度卷积神经网络预训练模型,例如AlexNet、VGG和ResNet等[1]。这些模型首先在大规模图像数据集(如ImageNet)上进行预训练以捕获图像的低级或中级特征(如边缘、纹理和形状等),然后再将其迁移到其他图像处理任务,如目标检测、图像生成和分割等。预训练模型的优点在于它们能够从大规模数据中学习到通用的特征表示并在多个下游任务上共享,这种方法既减少了对大量标注数据的需求也加速了模型的训练和收敛过程。
虽然在9.2节和9.4节内容中介绍到的词向量从某种程度上来讲也可以看作是一种简单的预训练模型,但是它并没有掀起自然语言处理领域中迁移学习的浪潮,因为它并没有给下游任务带来实质上的提升。直到2018年ELMo模型的出现才使得研究人员又开始将迁移学习聚焦到自然语言处理领域中[2]。紧接着,自然语言处理领域便先后出现了一系列有着重要影响的预训练模型,例如BERT和GPT系列。从某种程度上来说这两个技术流派正在引领者当前自然语言处理研究的主要方向。在本章内容中,我们将会逐一对这些模型的思想原理及其实战案例进行详细的介绍,包括ELMo、Transformer、BERET和GPT系列模型等。
10.1 ELMo网络#
在第9章内容中我们谈到自然语言处理的本质是理解并生成语言,而理解自然语言的前提就是如何有效对其进行表示。在9.2节和9.4节内容中,我们分别介绍了两种传统的静态词向量表示方法,即Word2Vec和Glove模型。在本节内容中我们将介绍另外一种新的动态词向量模型ELMo。
10.1.1 ELMo动机#
在传统的静态词向量中每个词都将被映射为一个固定的向量表示,词向量在构建过程中也只使用了局部的上下文信息,因此难以准确地表示词语在复杂语境中的依赖关系。同时,静态词向量并没有考虑词义随上下文语境变化所产生的不同含义,即无法解决一词多义的问题。例如文章中出现了“苹果”一词,它到底是指代科技公司“苹果”还是水果中的“苹果”静态词向量无法解决,因为这需要根据上下文来确定。在这样的背景下有学者开始研究基于上下文环境的词向量表示方法[3] [4]。在这类方法中,词向量的表示通常都不再只是一个固定的权重向量而是整个网络模型根据输入的上下文计算得到的词向量表示,即对于同一个词来说上下文语境的变化也会导致词向量表示的变化。
基于这样的动机, 马修(Matthew)等人[2]于2018年提出了一种基于LSTM的深度双向语言模型(Embeddings from Language Models, ELMo)来学习词向量的动态表示。ELMo模型通过将每个词表示为其在不同层次上下文中隐含状态的线性组合,使得每个词的向量表示不仅能够包含更为丰富的语义信息同时也能够捕捉到不同语境下的语义信息。最终,基于ELMo动态词向量的下游模型在6个流行的NLP任务中都取得了显著的效果提升。
10.1.2 ELMo结构#
在以往的研究中研究者们发现,将每个单词拆分成子词(Subword)的形式[5] [6]以及通过将不同网络深度输入的向量表示组合起来[7]均能够在一定程度上提高词向量的表达能力。受此启发,ELMo模型首先利用基于字符级的卷积神经网络CharCNN来学习得到每个词与上下文无关(Context-Independent)的向量表示;然后再通过一个带有残差连接的两层双向循环神经网络(相关内容可参见7.1.5节内容)来学习得到不同网络深度中每个词与上下文相关(Context-Dependent )的向量表示;最后再将三部分的输出以线性组合的方式得到每个词的向量表示。如图10-1所示便是ELMo模型的整体网络结构图。
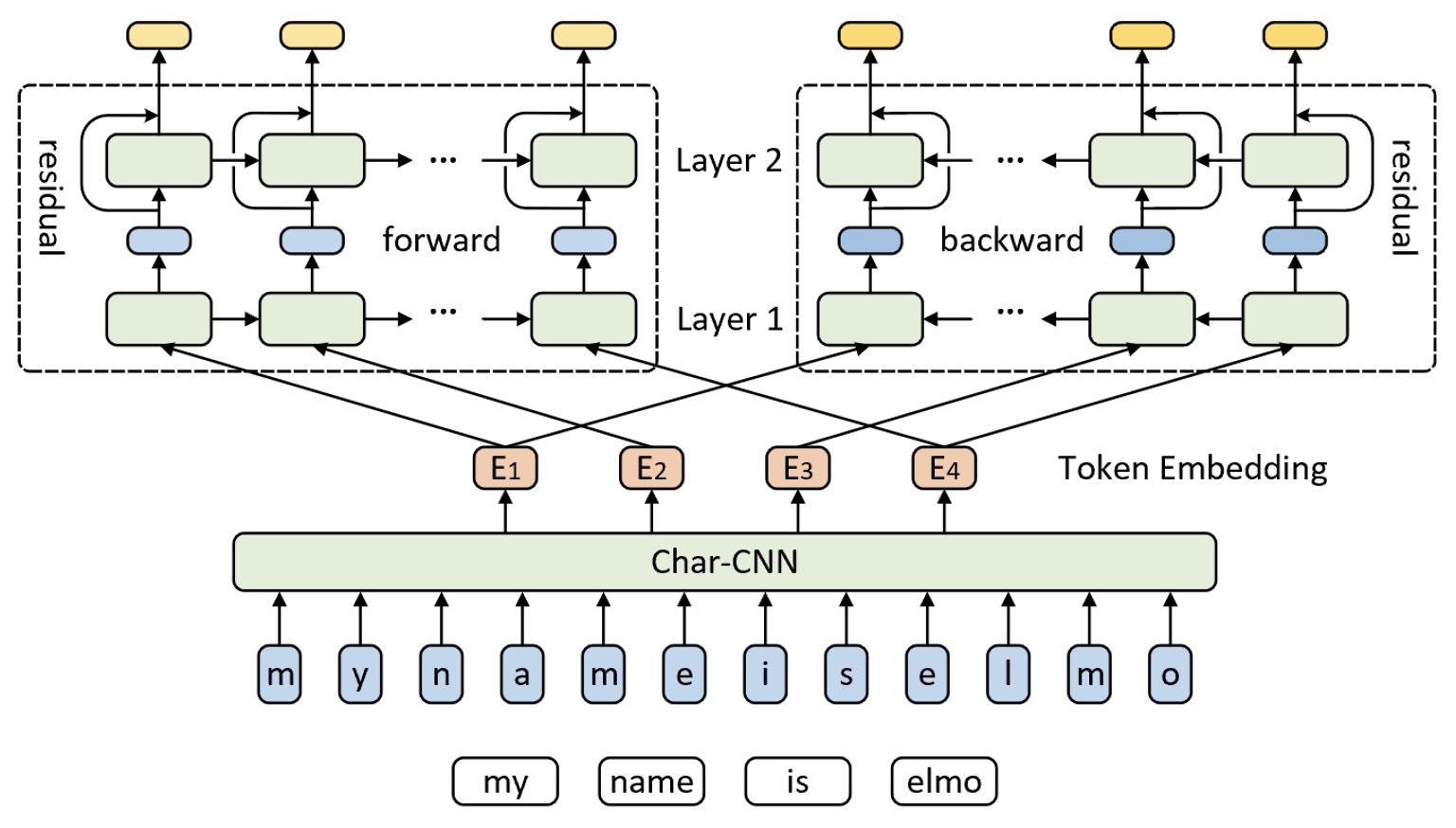
如图10-1所示便是ELMo模型的整体网络结构。ELMo模型整体上包括字符级的卷积神经网络和带残差连接的双向循环神经网络两大部分,分别用于学习得到不同粒度的词向量表示。接下来分别就各部分进行介绍。
1. 字符级卷积网络
在字符级卷积神经网络中,每个单词首先将会被切分成字符形式,并且对于每个单词来说其最大长度为50,不足部分需进行填充;然后再将其以不同窗口大小的一维卷积操作进行特征提取;最后经过最大池化操作并将池化后的结果进行拼接得到整个单词的词嵌入表示。
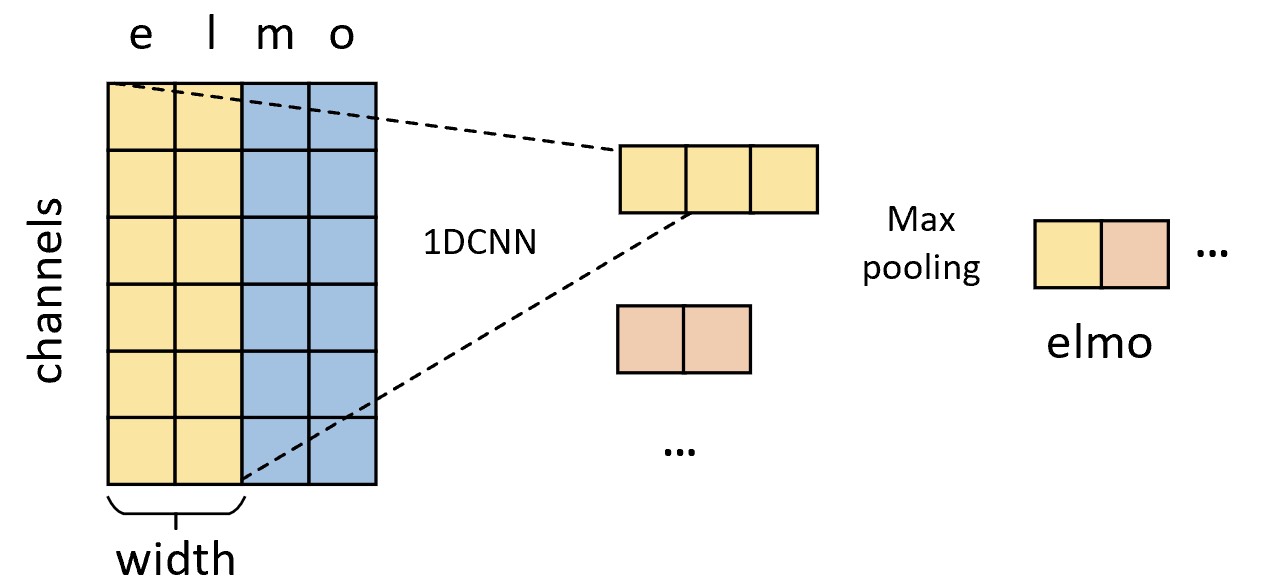
如图10-2所示便是一维卷积操作的示意图,其中左侧矩阵中:每一列表示每个字符对应的向量表示,在一维卷积中称其为通道数;每一行表示同一个特征通道中不同字符对应的特征。同时,在一维卷积中卷积核有3个参数,分别是输入通道数in_hannels、宽度width和输出通道数out_channels。在ELMo模型中,每个单词的最大长度max_characters_per_token为50;字符嵌入维度char_embed_dim为16,即图10-2中的channels为16;并且采用了宽度分别为1、2、3、4、5、6、7的卷积核,其中卷积核的数量分别为32、32、64、128、256、512、1024,即卷积操作结束后每个词向量的维度为2048。最后,再通过一个两层的高速连接(Highway )[8]和全连接层将每个词向量映射到了512维,即图10-1中的$E_i$。
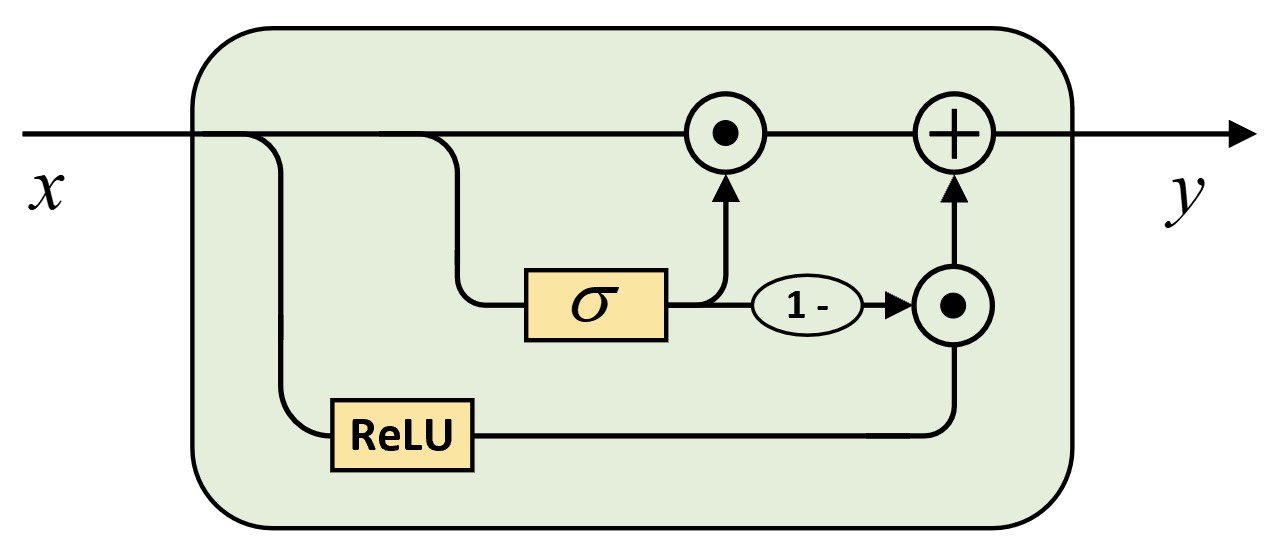
如图10-3所示便是高速连接层的结构示意图,其主要思想也是借鉴于LSTM中的单元记忆状态,使得网络每加深一层都能够同时融合当前层和上一层的历史信息。可以看出,此处的门控单元同时充当了遗忘门和输入门的角色。具体地,其计算过程为
$$ y=\sigma(xW_f)\odot x\oplus(1-\sigma(xW_f))\odot g(xW_i)\tag{10-1} $$2. 双向循环神经网络
在循环神经网络中不同网络深度的输出结果能够分别从上下文依赖、语法信息等角度来丰富词语的向量化表示,因而对于不同的下游任务有着不同的性能提升。例如在一个基于两层LSTM的编码器-解码器翻译模型中,编码器第1层的输出向量相比于第2层来说更加有利于进行词性标记(Part-Of-Speech Tags)任务。因此ELMo模型同样采用了两层的双向循环神经网络来获取得到不同粒度的词向量表示,并且在循环神经网络之间还采用了残差连接。如图10-1上半部分所示表示整个双向LSTM部分。
在ELMo模型中,对于给定序列$t_1,t_2,...,t_N$正向LSTM需要根据给定的前$k-1$个词来预测第$k$词,即建模
$$ p(t_1,t_2,...,t_N)=\prod_{k=1}^Np(t_k|t_1,t_2,...,t_{k-1})\tag{10-2} $$并且用$\overrightarrow{h}_{k,j}^{\text{LM}}, j=1,...,L$表示正向LSTM第$j$层第$k$个时刻的输出结果。
反向LSTM则恰好相反,需要根据给定的后$N-k$个词来预测第$k$个词,即建模
$$ p(t_1,t_2,...,t_N)=\prod_{k=1}^Np(t_k|t_{k+1},t_{k+2},...,t_{N})\tag{10-3} $$并且用$\overleftarrow{h}^{\text{LM}}_{k,j}, j=1,...,L$表示反向LSTM第$j$层第$k$个时刻的输出结果。
最终,通过最大化式(10-4)来求解整个模型参数
$$ \sum_{k=1}^N\left(\log p(t_k|t_1,...,t_{k-1};\Theta_x,\overrightarrow{\Theta}_{\text{LSTM}},\Theta_s)+\log p(t_k|t_{k+1},...,t_{N};\Theta_x,\overleftarrow{\Theta}_{\text{LSTM}},\Theta_s)\right)\tag{10-4} $$其中$\Theta_x$表示CharCNN中的所有权重参数,$\overrightarrow{\Theta}_{\text{LSTM}}$和$\overleftarrow{\Theta}_{\text{LSTM}}$分别表示正向反向LSTM中的权重参数,$\Theta_s$表示每个时刻$\text{Softmax}$分类层的权重参数,且对于正反两个LSTM来说共享一个分类器。
3. ELMo词向量表示
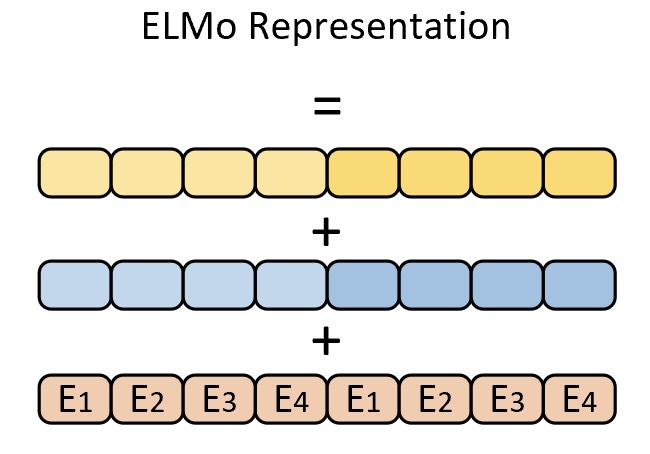
当整个ELMo模型在大规模语料上完成预训练之后,便可以取各部分对应的输出经过线性组合得到每个词最终的向量表示,如图10-4所示。