3.4 目标函数推导#
在前面3节的内容中,我们详细地介绍了什么是逻辑回归、如何进行多分类及分类任务对应的评价指标等,即完成了前面阶段一的学习,但是到目前为止仍旧有一些问题没有解决,映射函数$g(z)$ 是什么样的?逻辑回归的目标函数是怎么来的?如何自己求解并实现逻辑回归?只有在这3个问题得到解决后,整个逻辑回归算法的主要内容才算学习完了。
3.4.1 映射函数#
前面我们只是介绍了通过一个函数$g(z)$将特征的线性组合$z=Wx+b$映射到区间$[0,1]$,那么这个$g(z)$是什么样的呢?如图3-11所示,这便是$g(z)$的函数图形,其也被称为Sigmoid()函数。
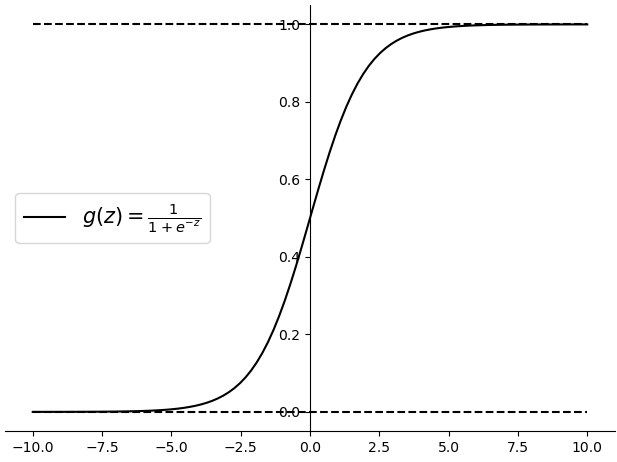
Sigmoid()函数的数学定义如下
$$ g(z)=\frac{1}{1+{{e}^{-z}}}\tag{3-28} $$其中$z\in (-\infty ,+\infty )$,而之所以选择Sigmoid()的原因在于: ①其连续光滑且处处可导; ②Sigmoid()函数关于点(0,0.5)中心对称;③Sigmoid()函数的求导过程简单,其最后的求导结果为$g^{\prime}(z)=g(z)(1-g(z))$。
根据式(3-28)可以得出其实现代码如下:
1 def g(z):
2 return 1 / (1 + np.exp(-z))可以看到对于Sigmoid()的实现也非常简单,1行代码就能完成。
3.4.2 概率表示#
在介绍完Sigmoid()函数后就需要弄清楚逻辑回归中的目标函数到底是怎么得来的。此时,可以设
$$ \begin{aligned} &P(y=1|x;W,b)=h(x) \\[2ex] & P(y=0|x;W,b)=1-h(x) \\[2ex] & h(x)=g(z)=g({{W}^{T}}x+b) \end{aligned}\tag{3-29} $$其中$W$和$x$均为一个列向量,$P(y=1|x; W,b)=h(x)$的含义为当给定参数$W$和$b$时,样本$x$属于$y=1$这个类别的概率为$h(x)$。此时可以发现,对于每个样本来讲都需要前面两个等式来衡量每个样本所属类别的概率,为了更加方便地表示每个样本所属类别的概率,可以改写为如下形式:
$$ p(y|x;W,b)={{(h(x))}^{y}}{{(1-h(x))}^{1-y}}\tag{3-30} $$这样一来,不管样本$x$属于哪个类别,都可以通过式(3-30)进行概率计算。
进一步,我们知道在机器学习中是通过给定训练集,即$({{x}^{(i)}},{{y}^{(i)}})$来求得其中的未知参数$W$和$b$。换句话说,对于每个给定的${{x}^{(i)}}$,我们已经知道了其所属的类别${{y}^{(i)}}$,即${{y}^{(i)}}$的这样一个分布结果我们是知道的。那么什么样的参数$W$和$b$能够使已知的${{y}^{(1)}},{{y}^{(2)}},\cdots ,{{y}^{(m)}}$这样一个结果(分布)最容易出现呢?也就是说给定什么样的参数$W$和$b$,使当输入${{x}^{(1)}},{{x}^{(2)}},\cdots ,{{x}^{(m)}}$这$m$个样本时,最能够产生已知类别标签${{y}^{(1)}},{{y}^{(2)}},\cdots ,{{y}^{(m)}}$这一结果呢?
3.4.3 极大似然估计#
上面绕来绕去说了这么多,其目的只有一个,即为什么要用似然函数进行下一步计算。由3.4.2节内容分析可知,为了能够使${{y}^{(1)}},{{y}^{(2)}},\cdots ,{{y}^{(m)}}$这样一个结果最容易出现,应该最大化如下似然函数 [3]
$$ L(W,b)=\frac{1}{m}\prod\limits_{i=1}^{m}{p}({{y}^{(i)}}|{{x}^{(i)}};W,b)=\frac{1}{m}\prod\limits_{i=1}^{m}{(h(}{{x}^{(i)}}){{)}^{{{y}^{(i)}}}}{{(1-h(x^{(i)}))}^{1-{{y}^{(i)}}}}\tag{3-31} $$对式(3-31)两边同时取自然对数有
$$ \ell (W,b)\text{ }=\frac{1}{m}\log L(W,b)=\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}\log h({{x}^{(i)}})+(1-{{y}^{(i)}})\log (1-h({{x}^{(i)}})) \right]}\tag{3-32} $$注意:$\log {{a}^{b}}{{c}^{d}}=\log {{a}^{b}}+\log {{c}^{d}}=b\log a+d\log c$
由于我们的目标是最大化式(3-31),也就等价于最大化式(3-32),因此当式(3-32)取得最大值时,其所对应的参数$W$和$b$就是逻辑回归模型所需要求解的参数。由此便得到了逻辑回归算法的目标函数
$$ J(W,b)=-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}\log h({{x}^{(i)}})+(1-{{y}^{(i)}})\log (1-h({{x}^{(i)}})) \right]}\tag{3-33} $$从式(3-33)可以发现我们在前面加了一个负号,因此求解逻辑回归的最终目的就变成了最小化式(3-33)。
3.4.4 求解梯度#
在求解线性回归中,我们首次引入并讲解了梯度下降算法,知道可以通过梯度下降算法来最小化某个目标函数。当目标函数取得(或接近)其函数最小值时,我们便得到了目标函数中对应的未知参数。由此可知,欲通过梯度下降算法来最小化函数式(3-33),则必须先计算并得到其关于各个参数的梯度,所以接下来就需要求解并得到目标函数关于各个参数的梯度。
目标函数$J(W,b)$对$W_j$的梯度为
$$ \begin{aligned} & \frac{\partial J}{\partial {{W}_{j}}}=-\frac{\partial }{\partial {{W}_{j}}}\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}\log h({{x}^{(i)}})+(1-{{y}^{(i)}})\log (1-h({{x}^{(i)}})) \right]} \\[2ex] & =-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}\frac{{{h}^{\prime }}({{x}^{(i)}})}{h({{x}^{(i)}})}+(1-{{y}^{(i)}})\frac{-{{h}^{\prime }}({{x}^{(i)}})}{1-h({{x}^{(i)}})} \right]} \\[2ex] & =-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}\frac{g({{z}^{(i)}})(1-g({{z}^{(i)}}))}{g({{z}^{(i)}})}x_{j}^{(i)}-(1-{{y}^{(i)}})\frac{g({{z}^{(i)}})(1-g({{z}^{(i)}}))}{1-g({{z}^{(i)}})}x_{j}^{(i)} \right]} \\[2ex] & =-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}(1-g({{z}^{(i)}}))-(1-{{y}^{(i)}})g({{z}^{(i)}}) \right]}x_{j}^{(i)} \\[2ex] & =-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}-h({{x}^{(i)}}) \right]}x_{j}^{(i)} \end{aligned}\tag{3-34} $$目标函数$J(W,b)$对$b$的梯度为
$$ \begin{aligned} & \frac{\partial J}{\partial b}=-\frac{\partial }{\partial b}\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}\log h({{x}^{(i)}})+(1-{{y}^{(i)}})\log (1-h({{x}^{(i)}})) \right]} \\[2ex] & =-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}\frac{{{h}^{\prime }}({{x}^{(i)}})}{h({{x}^{(i)}})}+(1-{{y}^{(i)}})\frac{-{{h}^{\prime }}({{x}^{(i)}})}{1-h({{x}^{(i)}})} \right]} \\[2ex] & =-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}\frac{g({{z}^{(i)}})(1-g({{z}^{(i)}}))}{g({{z}^{(i)}})}-(1-{{y}^{(i)}})\frac{g({{z}^{(i)}})(1-g({{z}^{(i)}}))}{1-g({{z}^{(i)}})} \right]} \\[2ex] & =-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}(1-g({{z}^{(i)}}))-(1-{{y}^{(i)}})g({{z}^{(i)}}) \right]} \\[2ex] & =-\frac{1}{m}\sum\limits_{i=1}^{m}{\left[ {{y}^{(i)}}-h({{x}^{(i)}}) \right]} \end{aligned}\tag{3-35} $$进一步,对式(3-33)、式(3-34)、式(3-35)矢量化可得
1 J(W,b)=-1/m * np.sum(y * np.log(h_x) + (1 - y) * np.log(1 - h_x))
2 grad_w = (1 / m) * np.matmul(X.T, (h_x - y)) # [n,m] @ [m,1]
3 grad_b = (1 / m) * np.sum(h_x - y)在求得各个参数的梯度计算公式后,便可以通过Python自己实现整个逻辑回归的建模与求解过程。
3.4.5 从零实现二分类逻辑回归#
这里以breast_cancer这个二分类数据集为例来建立逻辑回归模型,完整代码见 AllBookCode/Chapter03/C07_implementation.py 文件。
1. 载入数据集
breast_cancer数据集一共包含有2个类别(正样本与负样本),其中负样本212个,正样本357个,并且每个样本的有30个特征维度。进一步,我们可以通过如下方式进行载入:
1 from sklearn.datasets import load_breast_cancer
2 def load_data():
3 data = load_breast_cancer()
4 x, y = data.data, data.target.reshape(-1, 1)
5 x = feature_scalling(x)
6 return x, y在上述代码中,第1行是载入load_breast_cancer模块。第3~4行是载入该二分类数据集。第5行是对特征进行标准,详细内容见4.2节内容。
2. 预测函数
在实现整个逻辑回归的建模与求解过程前,首先需要完成假设函数和预测函数的编码,代码如下:
1 def hypothesis(X, W, bias):
2 z = np.matmul(X, W) + bias
3 h_x = sigmoid(z)
4 return h_x如上代码便是假设函数的实现,其中第2行代码是样本和权重的线性组合,第3行代码通过映射函数将线性组合后的结果映射到$[0,1]$的概率值。接着便是根据一个阈值(这里默认设置为0.5,也可以设置为其他值)将概率值转化为具体对应的类别,代码如下:
1 def prediction(X, W, bias, thre=0.5):
2 h_x = hypothesis(X, W, bias)
3 y_pre = (h_x > thre) * 1#将大于阈值的True和False结果转换为1和0的标签结果
4 return y_pre3. 目标函数
为了更好地观察目标函数的收敛,同样需要计算每次参数更新后的损失值,具体实现代码如下:
1 def cost_function(X, y, W, bias):
2 m, n = X.shape
3 h_x = hypothesis(X, W, bias)
4 cost = np.sum(y * np.log(h_x) + (1 - y) * np.log(1 - h_x))
5 return -cost / m4. 梯度下降
为了对整个模型进行求解,因此需要编程实现整个梯度下降的计算过程,代码如下:
1 def gradient_descent(X, y, W, bias, alpha):
2 m, n = X.shape
3 h_x = hypothesis(X, W, bias)
4 grad_w = (1 / m) * np.matmul(X.T, (h_x - y)) # [n,m] @ [m,1]
5 grad_b = (1 / m) * np.sum(h_x - y)
6 W = W - alpha * grad_w # 梯度下降
7 bias = bias - alpha * grad_b # 梯度下降
8 return W, bias在上述代码中,第6~7行用来执行梯度下降的过程。
5. 训练模型
在完成上述各部分函数的实现后便可以实现整个模型的训练过程,代码如下:
1 def train(X, y, ite=200):
2 m, n = X.shape # 506,13
3 W = np.random.uniform(-0.1, 0.1, n).reshape(n, 1)
4 b, alpha, costs = 0.1, 0.08, []
5 for i in range(ite):
6 costs.append(cost_function(X, y, W, b))
7 W, b = gradient_descent(X, y, W, b, alpha)
8 y_pre = prediction(X, W, b)
9 return costs在上述代码中,第2行用来随机初始化权重参数,然后通过梯度下降进行迭代更新,第6行用来保存参数在每一次迭代更新后计算出来的损失值,并进行了返回。最后,该模型经过200次迭代后,准确率能够达到0.98左右。
根据返回后的损失值,还能画出整个训练过程中模型的收敛情况,如图3-12所示。
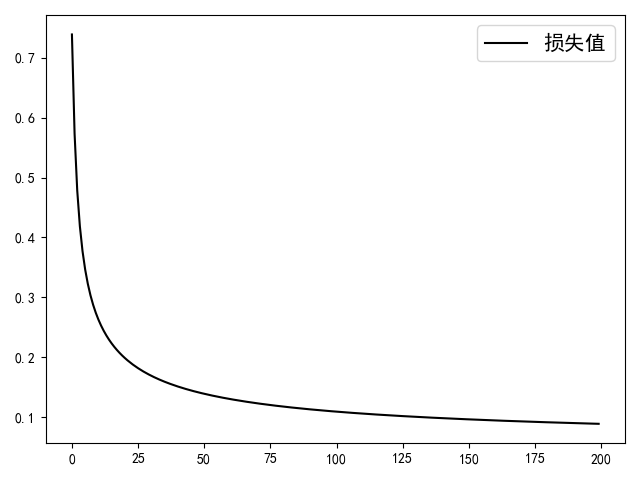
从图3-12可以看出,模型大概大约在第100次迭代后就慢慢进入了收敛阶段。
3.4.6 从零实现多分类逻辑回归#
在3.4.5节内容中,我们从零开始实现了整个二分类逻辑回归的建模与求解过程。在接下来的这一小节中,我们将继续介绍如何从零开始实现一个多分类的逻辑回归模型。完整代码见 AllBookCode/Chapter03/C08_implementation_multi_class.py 文件。
1. 载入数据集 由于是多分类任务,所以这里使用的是sklearn中的一个3分类数据集iris,具体信息在3.2.2节中已经介绍过,这里就不再赘述了,载入的代码如下:
1 from sklearn.datasets import load_iris
2 def load_data():
3 data = load_iris()
4 x, y = data.data, data.targe
5 return x, y2. 定义二分类器
根据3.2.2节的内容可知,One-vs-all的本质就是训练多个二分类器,然后用每个二分类器来对样本进行分类,因此这里需要定义一个函数来完成二分类器的训练,最后通过多次调用这个函数实现多个二分类模型的训练,代码如下:
1 def train_binary(X, y, iter=200):
2 m, n = X.shape # 506,13
3 W = np.random.randn(n, 1)
4 b,alpha,costs = 0.3,0.5,[]
5 for i in range(iter):
6 costs.append(cost_function(X, y, W, b))
7 W, b = gradient_descent(X, y, W, b, alpha)
8 return costs, W, b从上述代码可以看出,其整体上同3.4.5节中训练模型部分的代码一致,只是这里还额外地返回了训练好的参数。
3. 预测函数
由于这里变成了多分类的预测过程,按照One-vs-all的策略,对于每个样本我们需要预测得到它属于每个类别的概率,然后选择概率值最大的分类器对应的类别即可,实现代码如下所示:
1 def prediction(X, W, bias, thre=0.5):
2 class_type = len(W)
3 prob = []
4 for c in range(class_type):
5 w, b = W[c], bias[c]
6 h_x = hypothesis(X, w, b)
7 prob.append(h_x)
8 prob = np.hstack(prob)
9 y_pre = np.argmax(prob, axis=1)
10 return y_pre在上述代码中,第2行是根据传入的参数得到二分类器的个数。第4~7行是使用每一个二分类器来对样本进行预测,并保存每个样本属于每个类别的概率。第8行是将所有样本的概率预测结果堆叠成一个矩阵,形状为m行c列,即prob[i] [j]表示第i个样本属于第j个类别的概率。第9行是取每个样本最大概率对应的索引作为该样本的所属类别。
4. 模型训练
在完成上述两部分的代码后就可以进行整个多分类模型的训练了,代码如下:
1 def train(x, y, iter=1000):
2 class_type = np.unique(y)
3 costs, W, b = [], [], []
4 for c in class_type:
5 label = (y == c) * 1
6 tmp = train_binary(x, label, iter=iter)
7 costs.append(tmp[0])
8 W.append(tmp[1])
9 b.append(tmp[2])
10 y_pre = prediction(x, W, b)
11 print(classification_report(y, y_pre))
12 return costs在上述代码中,第2行用来判断数据集中一共有多少个类别,即需要训练多少个二分类器,第4行用来循环训练多个二分类器,第7~9行用来记录每个模型训练后的损失值和对应的权重参数。待整个模型训练完成后,便能够得到如图3-13所示的模型收敛图形。
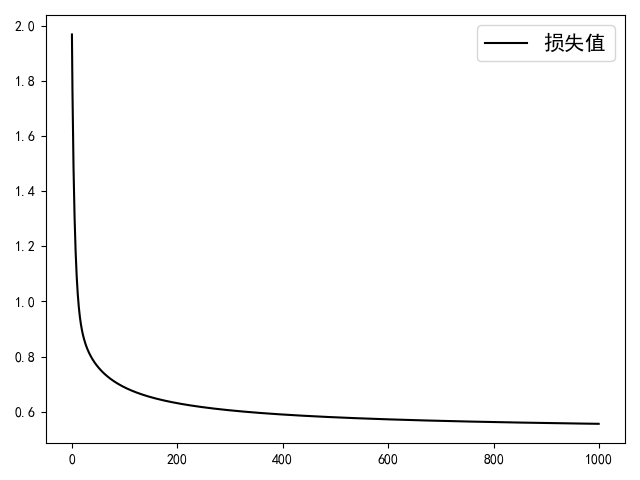
从图3-13可以看出,整个模型大约在第400次迭代后就进入了收敛状态,最终也得到了大约0.96的准确率。
3.4.7 小结#
在本节中,我们首先介绍了逻辑回归中的映射函数(Sigmoid()函数)和样本分类时的概率表示,接着介绍了如何通过极大似然估计来推导并得到逻辑回归模型的目标函数,然后介绍了如何根据得到的目标函数来推导各个参数关于目标函数的梯度,最后,分别从零开始介绍了如何实现二分类模型和多分类逻辑回归模型。
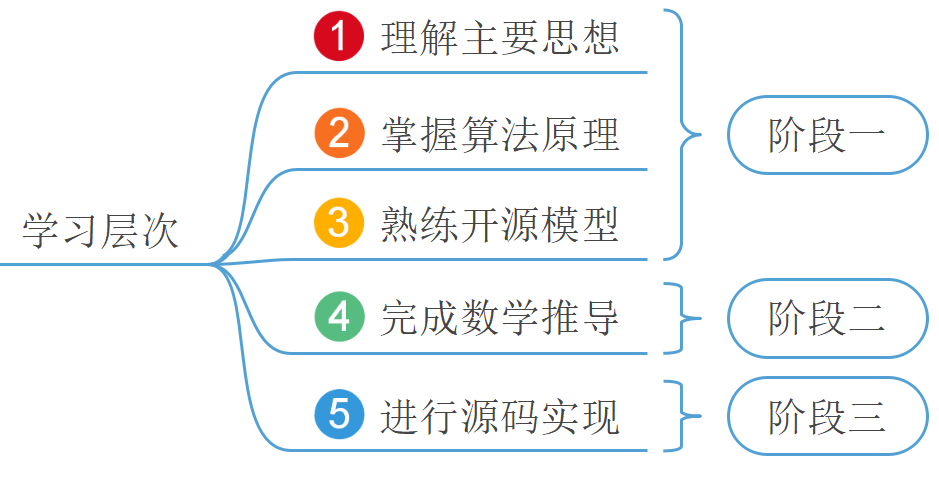
总结一下,如图3-14所示,在本章中我们首先通过一个示例引入了什么是分类模型,并通过在线性回归的基础上一步步地引出了什么是逻辑回归模型,然后我们介绍了逻辑回归从建模到利用开源库进行求解的整个过程,接着介绍了如何通过逻辑回归来完成多分类任务及分类任务中常见的4种评价指标,并完成了阶段一的学习。最后,我们通过本节的内容详细介绍了逻辑回归算法目标函数的推导及梯度的迭代公式等,还动手从0开始实现了逻辑回归的分类代码,进一步完成了后面两个阶段的学习。
到此,对于逻辑回归的主要内容也就介绍完毕了。不过尽管如此,仍然还有一些提升模型性能的方法(例如数据集划分、正则化等)没有阐述,这些内容我们将在第4章中进行详细介绍。
引用#
[1] https://scikitlearn.org/stable
[2] Pedregosa F, Varoquaux G, Gramfort A, et al. Scikit-learn: Machine learning in Python[J]. the Journal of machine Learning research, 2011, 12: 2825-2830.
[3] Andrew Ng,Machine Learning,Stanford University,CS229,Spring 2019.