11.2 Kmeans聚类算法#
在11.1节中我们介绍过,聚类的思想是将具有同种特征的样本聚在一起。换句话说,同一个簇中的样本点之间都具有高度的相似性,而不同簇中的样本点则具有较低的相似性,因此,聚类算法的本质又可被看成不同样本点间相似性的度量,聚类的目的就是将相似度较高的样本点放到一个簇中。由于不同类型的聚类算法有着不同的聚类原理,以及相似性评判标准。下面我们首先介绍聚类算法中最常用的Kmeans聚类算法,其对应的学习路线如图11-3所示。
如图11-3所示便是Kmeans聚类算法的学习路线图,在接下来的3节内容中我们将逐一对上述内容进行介绍。
11.2.1 Kmeans算法思想#
在上面我们说到,聚类算法的核心思想就是将具有相似特征的样本点聚在一起,而不同聚类算法之间的差异则表现在对于样本点相似的定义上。对于Kmeans聚类算法来说,它的核心思想在于通过计算样本点之间的欧式距离来衡量样本间的相似性,距离越近的两个样本点则越相似,则越有可能被划分到同一个簇结构中,最终使得同一簇内的样本点尽可能接近,而不同簇之间的样本点尽可能远离。因此,当Kmeans聚类算法完成整个聚类过程以后,将会得到类似图11-2所示的结果。下面,我们来看如何在sklearn中使用Kmeans聚类算法。
11.2.2 Kmeans示例代码#
在sklearn中,可以通过语句from sklearn.cluster import KMeans来完成对Kmeans模型的导入。在这之后,我们仍旧可以通过前面介绍的3步走策略完成整个聚类任务。完整代码可参见 AllBooKCode/Chapter11/C02_kmeans_train.py 文件。
1. 载入数据集
在开始聚类之前,首先同样需要载入相应的数据集。在这个示例中,使用的依旧是iris数据集,示例代码如下:
1 from sklearn.datasets import load_iris
2 def load_data():
3 data = load_iris()
4 x, y = data.data, data.target
5 return x, y2. 训练模型
在完成数据集载入后则需要导入sklearn中的Kmeans聚类模型并进行聚类,示例代码如下:
1 from sklearn.cluster import KMeans
2 from sklearn.metrics.cluster import adjusted_rand_score
3 def train(x, y, K):
4 model = KMeans(n_clusters=K)
5 model.fit(x)
6 y_pred = model.predict(x)
7 ari = adjusted_rand_score(y, y_pred)
8 print("ARI: ", ari)# 0.716在上述代码中,第1行用来导入sklearn中的KMeans聚类模型。第2行用来导入聚类评估指标,其范围为$[-1,1]$,值越大表示结果越好,这部分内容将在第11.6节中进行介绍。第4行代码则用来初始化KMeans模型,参数n_clusters表示指定数据集中的簇数量。第5~8行则用来分别进行聚类、预测和模型评估。
以上代码便是使用sklearn搭建一个聚类模型的全部代码,可以看到其过程其实非常简单,而这一切得益于sklearn的友好的接口设计风格。
11.2.3 Kmeans算法原理#
Kmeans聚类算法也被称为K均值聚类,其主要原理可以总结为以下几点[1]:
(1) 随机选择K个样本点作为K个簇的初始簇中心;
(2) 计算每个样本点与这K个簇中心的相似度,并将该样本点划分到与之相似度最高的簇中心所对应的簇中;
(3) 根据每个簇中现有的样本,重新计算每个簇的簇中心;
(4) 循环迭代步骤(2)和步骤(3),直到目标函数收敛,即簇中心不再发生变化。
如图11-4所示为Kmeans算法的聚类过程,其中iter=0表示聚类过程尚未开始,即正确标签下的样本可视化结果(每种颜色表示一个类别),而3个黑色圆点为随机初始化的3个簇中心。iter=1表示算法第1次迭代后的结果,可以看到此时的算法将左边原本2个簇的样本点都划分到了1个簇中,而右下角原本1个簇的样本点却被聚类成了2个簇。之后,Kmeans聚类算法依次进行反复迭代,当第4次迭代完成后,可以发现3个簇中心基本上已经位于3个簇中了,被错分的样本也在逐渐减少。当进行完第5次迭代后,可以发现基本上已经完成了对整个样本的聚类处理,只需再迭代几次便可收敛。
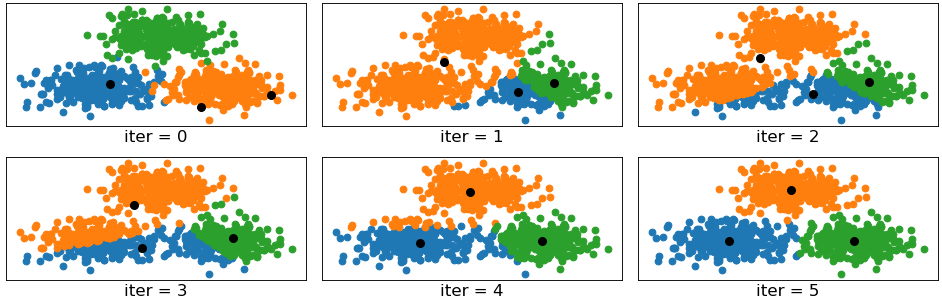
从图11-4所示的聚类结果可以再次印证,聚类算法只会告诉我们哪些样本点属于同一个类别(同一个簇),但是无法告诉我们每个簇到底属于什么类别。以上就是Kmeans聚类算法在整个聚类过程中的变化情况,至于其具体的求解计算过程将在11.3节中进行介绍。
11.2.4 K 值选取#
经过上面的介绍,相信各位读者对于Kmeans聚类算法的基本原理已经有了一定的了解,但现在有一个问题,如何来确定聚类的K值呢?也就是说,我们需要将数据集聚成多少个簇呢?如果已经很明确数据集中存在多少个簇,则直接指定K值即可。如果并不知道数据集中有多少个簇,则需要结合另外一些办法进行选取,例如查看轮廓系数、多次聚类结果的稳定性等,这部分内容将在11.9节内容中进行详细介绍。
11.2.5 小结#
在本节中,我们首先介绍了Kmeans聚类算法的基本思想以及如何使用sklearn来完成整个建模过程;然后介绍了Kmeans聚类算法的原理,即聚类的整个迭代过程,并对整个过程中的样本状态进行了可视化;最后简单介绍了K值的选取原则,这部分内容将在11.9节中进行介绍。
引用#
[1] PEDREGOSA.scikitlearn: Machine Learning in Python[J].JMLR 12,2011: 28252830.