6.10 初始化方法#
在前面几节内容中我们陆续介绍了不同的模型优化方法来加快模型在训练过程中的收敛速度,包括学习率调度器、梯度裁剪、归一化方法和模型优化算法等。在本节内容中,我们将介绍另外一种角度的模型优化算法,即初始化方法。
6.10.1 初始化动机#
根据3.3节内容中梯度下降算法的原理可知,不同的初始化位置对于目标函数最终的收敛速度或收敛情况有着至关重要的影响。神经网络的初始权重决定了网络对输入数据的初始响应。如果初始权重设置得不合理,网络可能会陷入局部最优解或者无法收敛的情况。
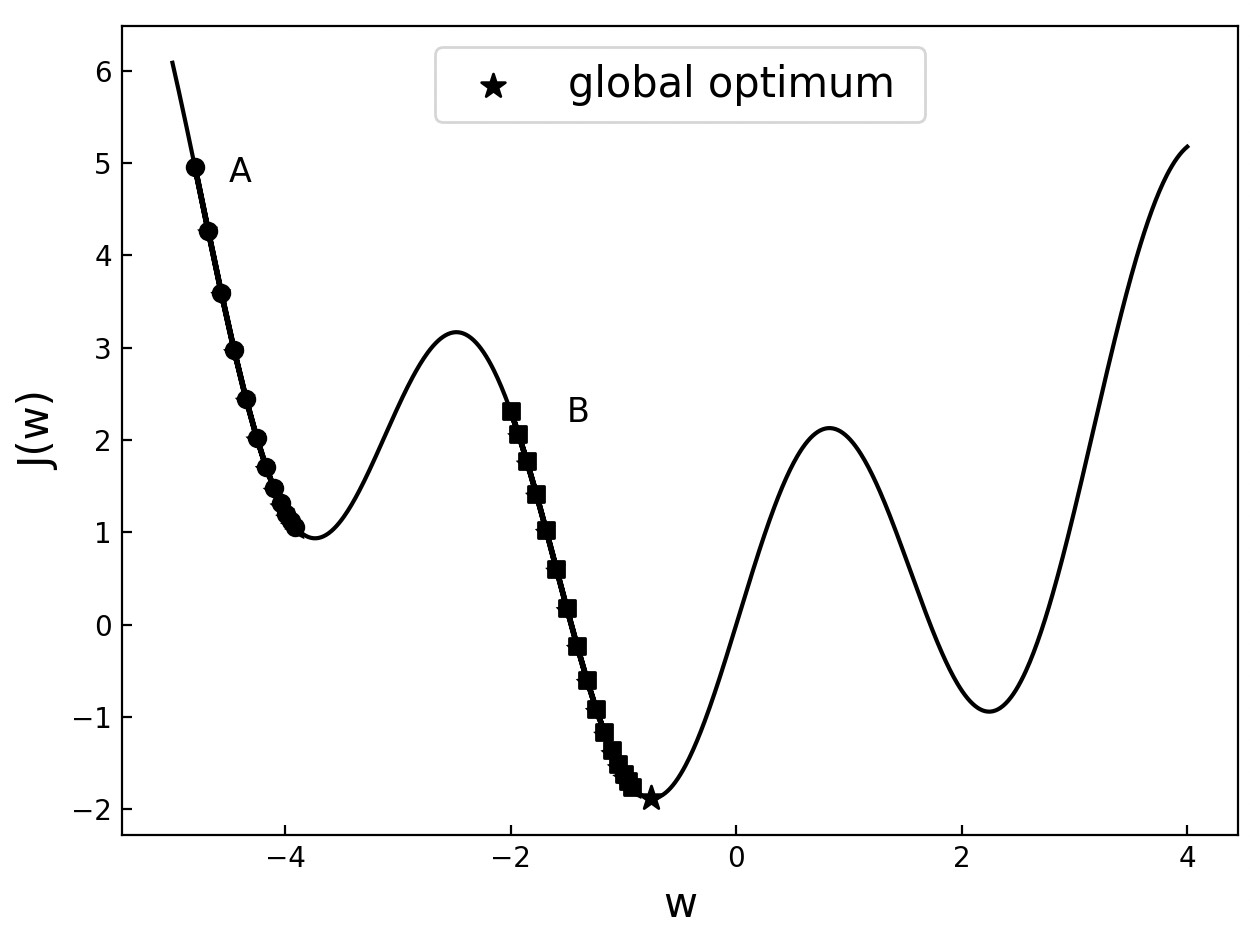
如图6-23所示,对于同一个目标函数来说权重的初始值选在不同的地方最终将会得到不同的优化结果。从图中可以看出,当参数初始值选在A点时,目标函数最终将会收敛于局部最优解;而当权重初始值选在B点时,目标函数最终则会收敛于全局最优解。如果是更为极端的情况,不合理的初始位置还将会导致目标函数发散的情况。图示代码参见Code/Chapter06/C07_Init/visual.py文件。
鉴于传统的初始化方法,如随机初始化方法,可能会导致深层网络中梯度消失或爆炸的问题从而使得模型训练变得更加困难,因此,便出现了一系列不同的初始化方法,例如 kaiming 初始化、xavier 初始化等。
6.10.2 初始化原理#
在深度学习中,目前最常用的初始化方法是 kaiming 初始化和 xavier 初始化。不过从本质上来讲,两种初始化方法类似,仅仅只是使用了不同的方式来计算方差。初始化的原理都是根据当前层权重参数的数量信息来计算整体方差,然后再对权重参数重新进行采样以保证正向传播中激活值的方差和反向传播中梯度的方差尽可能一致来使得网络的训练更加稳定。具体来说,梯度方差是梯度的离散程度,即每个梯度值相对于梯度均值的偏离程度,梯度的方差较小意味着梯度值相对一致没有过大的波动,而方差较大则意味着梯度值的波动大。在前向传播中激活值的方差影响着网络的表达能力;在反向传播中梯度的方差影响着学习的速度和方向,而保持激活值方差和梯度方差一致可以帮助网络保持前向传播和反向传播之间的平衡,使得信息能够稳定地传递和更新。
因此,当采用不同的方式计算得到方差以后,我们便可以使用正态分布或均匀分布来对网络权重进行初始化,所以 kaiming 初始xavier 初始化分别对应了两种不同的初始化方法,即 PyTorch 中的 kaiming_normal_()、kaiming_uniform_()、xavier_normal_()和xavier_uniform_()。下面我们分别来进行介绍。
1. kaiming 初始化
kaiming 初始化方法是一种针对激活函数为ReLU时的神经网络权重初始化方法 [1] [2]。它的目标是将网络层的激活输出的方差保持在一个相对稳定的范围内,以促进网络的稳定训练和收敛。假设我们有一个全连接层(或卷积层),其权重矩阵为$W$,该层的输入特征数为$n_{\text{in}}$,输出特征数为$n_{\text{out}}$。如果使用ReLU作为激活函数,则权重矩阵$W$的每一个元素都将从正态分布$\mathcal{N}(0,\sigma^2)$或均匀分布$\mathcal{U}(0,\sigma^2)$采样而来,其中在两种模式下标准差$\sigma$的计算方式分别为:
$$ \sigma=\sqrt{\frac{2}{n_{\text{in}}}}\tag{6-34} $$或
$$ \sigma=\sqrt{\frac{2}{n_{\text{out}}}}\tag{6-35} $$其中,当$W$为全连接层参数时,$n_{\text{in}}$和$n_{\text{out}}$分别为该层对应的输入输出神经元个数;当$W$为卷积层参数时,$n_{\text{in}}$和$n_{\text{out}}$分别为$k\times k\times \text{in_channels}$和$k\times k\times \text{out_channels}$,$\text{in_channels}$和$\text{out_channels}$分别表示特征图的输入输出通道数,$k$表示卷积核的窗口大小。
在计算得到标准差以后,我们便可以将其作为参数使用torch.normal_(0,std)方法来对权重参数进行采样初始化。下面,我们以PyTorch中的实现代码为例来详细介绍其中的细节。
1 def kaiming_normal_(tensor, a = 0, mode = 'fan_in', nonlinearity = 'leaky_relu'):
2 fan = _calculate_correct_fan(tensor, mode)
3 gain = calculate_gain(nonlinearity, a)
4 std = gain / math.sqrt(fan)
5 with torch.no_grad():
6 return tensor.normal_(0, std)
7
8 def _calculate_correct_fan(tensor, mode):
9 mode = mode.lower()
10 valid_modes = ['fan_in', 'fan_out']
11 if mode not in valid_modes:
12 raise ValueError("Mode {} not supported, please use one of ")
13 fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
14 return fan_in if mode == 'fan_in' else fan_out
15
16 def _calculate_fan_in_and_fan_out(tensor):
17 dimensions = tensor.dim()
18 if dimensions < 2:
19 raise ValueError("tensor with fewer than 2 dimensions")
20 num_input_fmaps = tensor.size(1)
21 num_output_fmaps = tensor.size(0)
22 receptive_field_size = 1
23 if tensor.dim() > 2:
24 for s in tensor.shape[2:]:
25 receptive_field_size *= s
26 fan_in = num_input_fmaps * receptive_field_size
27 fan_out = num_output_fmaps * receptive_field_size
28 return fan_in, fan_out在上述代码中,第16~28行是根据输入的权重参数来计算输入或输出特征的个数。第20~21行是分别获得全连接层或卷积层输入输出神经元个数或输入输出特征图个数。当对全连接层进行初始化时,此时tensor.dim() = 2,则 fan_in, fan_out分别为该层对应的输入输出神经元个数;当对卷积层进行初始化时,此时tensor.dim() = 3,则 fan_in, fan_out分别为输入输出特征通道可视野内的神经元个数;例如某个卷积层权重的形状为[32,16,3,3],则fan_in = 16*3*3,fan_out = 32*3*3。第8~14行则是根据参数mode来返回$n_{\text{in}}$或者$n_{\text{out}}$的个数。第3行则是根据指定激活函数的类型来返回对应的缩放尺度值,当nonlinearity = 'relu'时返回$\sqrt{2}$,各个激活函数的建议值可参见函数calculate_gain()的实现部分。第6行则是使用均值0,标准差为std对权重参数进行采样初始化。
这里需要注意的是,fan_in和fan_out是两种不同的倾向选择。当使用fan_in模式时更侧重于保持前向传播过程中激活值的方差稳定,从而提高网络的稳定性;当使用fan_out模式时则更侧重于确保在反向传播时梯度的方差稳定,避免梯度消失或梯度爆炸的问题。通常来说这会根据使用的激活函数来确定,例如对于ReLU激活函数,通常推荐使用fan_in模式进行初始化。
进一步,kaiming_uniform_初始化方法的计算过程为:
1 def kaiming_uniform_(tensor, a = 0, mode = 'fan_in', nonlinearity = 'leaky_relu'):
2 fan = _calculate_correct_fan(tensor, mode)
3 gain = calculate_gain(nonlinearity, a)
4 std = gain / math.sqrt(fan)
5 bound = math.sqrt(3.0) * std
6 with torch.no_grad():
7 return tensor.uniform_(-bound, bound)2. xavier 初始化
在清楚 kaiming 初始化的相关计算过程以后,对于 xavier 初始化方法的计算过程就比较清晰了[1]。具体地,对于xavier_normal_初始化方法来说,其实现过程为: