2.4 回归模型评估#
在第2.1至第2.3这3节内容中,我们介绍了如何建模线性回归(包括多变量与多项式回归)及如何通过sklearn来搭建模型并求解,但是对于一个创建出来的模型应该怎样来对其进行评估呢?换句话说,这个模型到底怎么样呢?
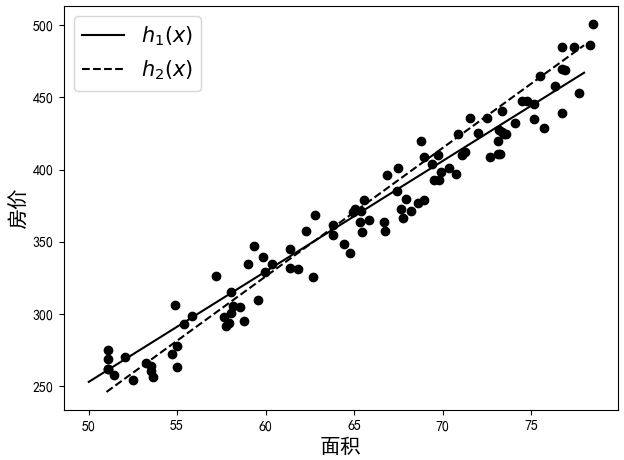
以最开始的房价预测为例,现在假设求解得到了图2-8所示的两个模型$h_1(x)$与$h_2(x)$,那么应该选哪一个呢?抑或在不能可视化的情况下,应该如何评估模型的好与坏呢?
在回归任务(对连续值的预测)中,常见的评估指标(Metric)有平均绝对误差(Mean Absolute Error,MAE)、均方误差(Mean Square Error, MSE)、均方根误差(Root Mean Square Error, RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)和决定系数(Coefficient of Determination)等,其中用得最为广泛的是 MAE 和 MSE。下面我们依次来对这些指标进行一个大致的介绍,同时在所有的计算公式中,$n$均表示样本数量、$y^{(i)}$均表示第$i$个样本的真实值、$\hat{y}^{(i)}$均表示第$i$个样本的预测值。
2.4.1 常见回归评估指标#
1.平均绝对误差(MAE)
MAE用来衡量预测值与真实值之间的平均绝对误差,定义如下:
$$ \text{MAE}=\frac{1}{n}\sum\limits_{i=1}^{n}{|}{{y}^{(i)}}-{{\hat{y}}^{(i)}}|\tag{2-8} $$其中 $\text{MAE}\in [0,+\infty )$,其值越小表示模型越好。
从式(2-8)可以看出,$\text{MAE}$ 的核心思想就是平均上来我们的预测到底差了多少?说的通俗一点 $\text{MAE}$ 给我们的就是一个很直接的平均误差值,不管你是预测高了还是低了它只关心你到底差了多少,最后把所有这些差值取平均,并且它的单位跟原始数据是一模一样。比方说我们预测房价单位是万元,那 $\text{MAE}$ 的单位就是万元。
所以,在 $\text{MAE}$ 眼里,所有错误都是平等的,一个 10 万块的误差严重性就是一个 1 万块误差的10倍,一视同仁。
具体地,$\text{MAE}$ 实现代码如下:
1 def MAE(y, y_pre):
2 return np.mean(np.abs(y - y_pre))2. 均方误差(MSE)
MSE用来衡量预测值与真实值之间的误差平方,定义如下:
$$ \text{MSE}=\frac{1}{n}\sum\limits_{i=1}^{n}{{{({{y}^{(i)}}-{{{\hat{y}}}^{(i)}})}^{2}}}\tag{2-9} $$其中$\text{MSE}\in [0,+\infty )$,其值越小表示模型越好。
从式(2-9)可以看出,$\text{MSE}$ 认为不是所有错误都是平等的,有时候一个天大的错误比 10 个小错误加起来还要命。$\text{MSE}$ 的核心思想是犯小错可以容忍但犯大错绝对不行,所以最关键的变化就是这个平方项。例如一个误差是2一个误差是10,分别平方后则变成了4和100,一下就看出了对大误差的敏感度。
具体地,$\text{MSE}$ 实现代码如下:
1 def MSE(y, y_pre):
2 return np.mean((y - y_pre) ** 2)3. 均方根误差(RMSE)
虽然 $\text{MSE}$ 能够突出对模型大误差的评判,但也有个一小的缺点。因为平方的缘故它的单位也变成了平方,理解起来就没那么直观了,所以这便是 $\text{RMSE}$ 出现的原因。 $\text{RMSE}$ 是在 $\text{MSE}$ 的基础之上取算术平方根而来,其定义如下:
$$ \text{RMSE}=\sqrt{\frac{1}{n}\sum\limits_{i=1}^{n}{{{({{y}^{(i)}}-{{{\hat{y}}}^{(i)}})}^{2}}}}\tag{2-10} $$其中 $\text{RMSE}\in [0,+\infty )$,其值越小表示模型越好,
具体地, $\text{RMSE}$ 实现代码如下:
1 def RMSE(y, y_pre):
2 return np.sqrt(MSE(y, y_pre))4. 平均绝对百分比误差(MAPE)
$\text{MAPE}$ 和 $\text{MAE}$ 类似,只是在MAE的基础上做了一定的标准化处理,其定义如下:
$$ \text{MAPE}=\frac{100\%}{n}\sum\limits_{i=1}^{n}{\left| \frac{y^{(i)}-\hat{y}^{(i)}}{y^{(i)}}\right|}\tag{2-11} $$其中$\text{MAPE}\in [0,+\infty )$,其值越小表示模型越好,
具体地,$\text{MAPE}$ 的实现代码如下:
1 def MAPE(y, y_pre):
2 return np.mean(np.abs((y - y_pre) / y))5. $R^2$ 评价指标
决定系数 $R^2$ 是线性回归模型中sklearn默认采用的评价指标,其定义如下:
$$ {{R}^{2}}=1-\frac{\sum\limits_{i=1}^{n}{{{({{y}^{(i)}}-{{{\hat{y}}}^{(i)}})}^{2}}}}{\sum\limits_{i=1}^{n}{{{({{y}^{(i)}}-\bar{y})}^{2}}}}\tag{2-12} $$其中${{R}^{2}}\in (-\infty ,1]$,其值越大表示模型越好,$\overline{y}$表示真实值的平均值。
根据式(2-12)可以看出,$R^2$ 的核心思想其实是在比较当前模型与输出值都是平均值这个基准模型的差别有多大。换句话说,假如有个模型不管三七二十一永远只输出所有房价的平均值,那么 $R^2$ 衡量的就是你的这个模型比瞎猜平均数这个笨办法到底好了多少。
具体地,$R^2$ 的实现代码如下:
1 def R2(y, y_pre):
2 u = np.sum((y - y_pre) ** 2)
3 v = np.sum((y - np.mean(y)) ** 2)
4 return 1 - (u / v)2.4.2 回归指标示例代码#
有了这些评估指标后,在对模型训练时就可以选择其中的一些指标对模型的精度进行评估了。这里以前面波士顿房价的预测结果为例进行示例,完整代码见AllBook/Chapter02/04_metrics_boston_price.py文件,代码如下:
1 def train(x, y):
2 model = LinearRegression()
3 model.fit(x, y)
4 y_pre = model.predict(x)
5 print("MAE:{},MSE:{}".format(MAE(y, y_pre),MSE(y,y_pre)))
6 #MAE: 3.27, MSE:21.89从上述代码的输出结果可以看到,此时模型对应的MAE和MSE评价指标分别为3.27和21.89。
2.4.3 小结#
在本节中,我们详细地介绍了如何评价一个回归模型的优与劣,以及一些常用的评估指标和实现方法。最后,我们还通过波士顿房价预测示例来展示了评价指标的用法。到此,对于线性回归模型在整个阶段一部分的内容就介绍完了。在2.5节中,我们将介绍如何通过梯度下降算法来求解目标函数,以及这个目标函数的由来。