4.5 复杂问题拆解与ReAct框架#
在上一小节的内容中,我们直接使用了 LangChain 中的 create_agent() 来创建智能体,并让它能够在一次请求中多次调用工具,所以即便是一个用户请求中包含有多个子问题,它也能够持续迭代,直到得到最终的答案。站在使用者的角度来看,这一切似乎合情合理也应该如此,但如果继续追问其内部机制就会发现,这背后对应的正是 Agent 领域中最重要的一类思想。
4.5.1 ReAct 出现的动机#
在不借助工具的情况下,大模型处理问题的方式通常可以概括为“一次输入,一次输出”。用户给出问题后,模型基于参数中已经学到的知识直接生成答案,其流程如图4-6所示。
根据图4-6可知,虽然这种方式在简单问答中已经足够有效,但它有两个明显的局限:
第一,模型无法主动接触外部世界。如果问题依赖最新信息、私有知识库或运行时环境,模型即使具备较强的语言能力,也只能依赖训练阶段形成的内部记忆进行猜测。当然,这一点我们已经可以通过外部工具来解决。
第二,模型虽然可以在一次回答中表现出一定的推理能力,但这种推理是“封闭的”。一旦中间某一步判断错误,后续答案往往会沿着错误方向继续展开,从而产生事实性幻觉或不可靠的结论。
例如,在上一节内容的示例中,当用户提出“本书主角是谁?找到主角后,再继续说明他的出生背景”这类问题时,模型实际上需要完成多个连续动作:先判断是否需要检索,再提炼一个更适合搜索的查询词,然后读取检索结果,最后根据新得到的信息决定下一步还要不要继续查找。显然,这已经不是一次性生成答案能够稳定完成的任务,而是一个需要多轮中间决策的过程。
为了解决这一问题,研究员姚顺雨[1] 在2022年10月提出了推理与行动(Reasoning and Acting, ReAct)决策框架,它的核心出发点是不要强迫模型一次性给出最终答案,而是允许模型在推理过程中主动采取行动,并根据行动得到的观察结果继续推进后续推理,直到得到最终答案。
4.5.2 ReAct 决策原理#
在推理与行动中,“推理”表示模型围绕当前任务形成的中间思考,“行动”则表示模型基于当前判断采取的动作,例如搜索、查询数据库、调用函数或访问工具。如果只看定义,ReAct 很容易被误解为让模型先想一想再调工具,但它真正重要的地方不在于“先想后做”这4个字,而在于它把复杂任务拆成了一个可以反复循环的过程,如图4-7所示。
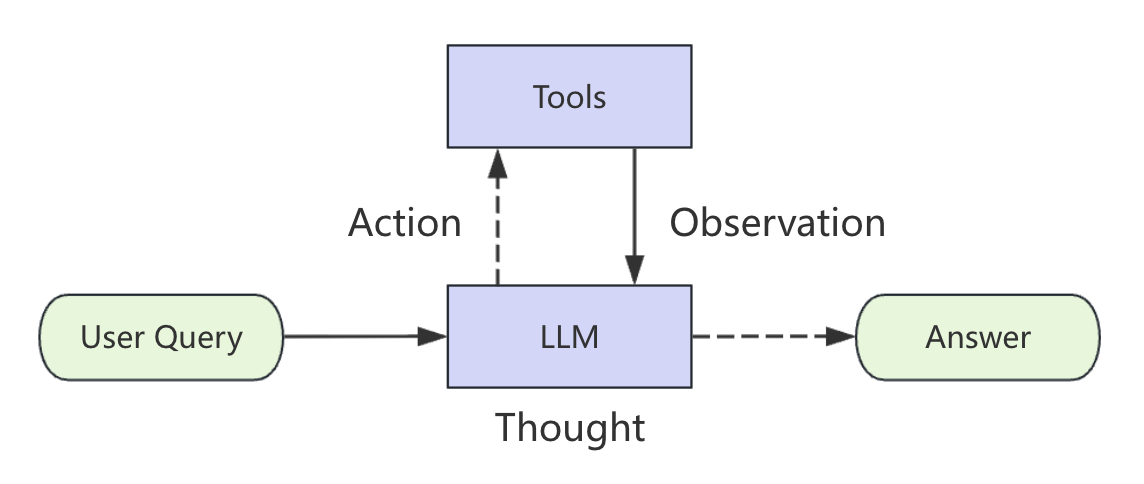
在图4-7中,思考(Thought)表示模型的中间推理,它的作用是分解目标、规划下一步或解释为什么要调用某个工具;行动(Action)表示模型决定执行的动作,通常对应一次工具调用;观察(Observation)表示工具执行后的结果,它会重新进入上下文,成为下一轮推理的依据。
进一步,根据图4-7可知,在整个循环中模型并不会立即产生最终答案,而是首先会根据当前任务形成一个中间判断,决定是否需要调用某个工具,即思考过程;然后调用工具并返回结果,即行动过程;其次根据工具返回的结果修正后续判断,即观察过程;最后在条件满足时再输出最终答案。也正因为如此,我们在第4.4节看到的 RAG Agent 才能够先拆问题、再检索、再继续检索,最后组合出完整答案。
从这个角度看,ReAct 并不是一个单独的工具调用技巧,而是一种围绕推理驱动行动、行动反哺推理而组织起来的任务求解范式。
4.5.3 ReAct 的基本执行流程#
为了更直观地理解这一点,我们来看一个简单的例子。假设用户的问题是:“《哈利波特》的作者出生在哪个国家?” 此时模型如果直接回答,完全可能因为模型能力或记忆偏差或知识不完整而出错,但是在 ReAct 框架下,更合理的过程应当是:
Question: 《哈利波特》的作者出生在哪个国家?
Thought: 我需要先确认《哈利波特》的作者是谁。
Action: Search("哈利波特 作者")
Observation: J.K. Rowling
Thought: 现在我已经知道作者,需要继续查询她的出生国家。
Action: Search("J.K. Rowling 出生国家")
Observation: United Kingdom
Final Answer: 《哈利波特》的作者是 J.K. Rowling,出生于英国。从上述过程可以看出,ReAct 并不要求模型一开始就具备完整答案,而是允许它在中途通过行动补充信息。这样模型的推理不再完全依赖内部记忆,而是可以在关键节点引入外部证据;其次,整个求解过程具有更强的可解释性,我们不仅看到最终答案,也能看到模型为何进行了某一步操作,以及这一步操作返回了什么信息。
进一步,需要注意的是 ReAct 与只强调连续思考的思维链(Chain of Thought, CoT) 存在明显差别。思维链的核心是把复杂问题拆解为多个推理步骤,但它依然停留在模型内部;而 ReAct 在推理链中加入了“行动”和“观察”,使得模型能够真正与外部环境交互。因此,前者更像是“在脑中推演”,后者则更像是“边推演边查证”。
4.5.4 ReAct 的实现方法#
从方法发展的角度看,最初的 ReAct 并不是一个复杂框架,而是一种提示词组织方式。也就是说并不用修改大模型本身,而是告诉模型遇到复杂任务时不要直接给答案,而要按照图4-7中的节奏输出。
如下所示便是一个典型的 ReAct 提示词组织方式:
请尽可能好地回答以下问题。同时,你可以使用以下工具:
{tools}
请使用以下格式:
问题:用户输入的问题你必须回答
思考:你始终需要思考接下来应该做什么
行动:要采取的动作,但应当是 [{tool_names}] 中的一个
行动输入:该动作对应的输入
观察:该动作返回的结果
……(上述“思考/行动/行动输入/观察”可以重复 N 次)
思考:我现在知道最终答案了
最终答案:对原始输入问题的最终回答
开始!
问题:{input}
思考:{intermediate_state}其中 tools 表示当前所有可用工具的定义信息,tool_names 表示每个工具对应的名称, intermediate_state 表示中间状态,记录模型已经思考过什么、调用过什么工具、工具返回了什么结果。
在这种实现中,大模型真正输出的仍然只是文本。例如用户提问“上海今天的冷吗?”,模型根据上面的提示词先生成:
Thought: 我需要查询天气
Action: get_weather("上海")随后,外部程序解析 Action 这一段文本,识别出要调用哪个工具,再由程序实际执行工具,拿到结果后补上一段新的上下文:
Observation: 上海今天晴天,25 度然后把这段 Observation 连同之前的上下文拼接好再次送回模型,让模型继续生成下一步,即
请尽可能好地回答以下问题。同时,你可以使用以下工具:
{tools}
请使用以下格式:
问题:用户输入的问题你必须回答
思考:你始终需要思考接下来应该做什么
行动:要采取的动作,但应当是 [{tool_names}] 中的一个
行动输入:该动作对应的输入
观察:该动作返回的结果
……(上述“思考/行动/行动输入/观察”可以重复 N 次)
思考:我现在知道最终答案了
最终答案:对原始输入问题的最终回答
开始!
问题:上海今天的冷吗?
思考:
Question: 上海今天的冷吗?
Thought: 我需要查询天气
Action: get_weather("上海")
Observation: 上海今天晴天,25 度这种方式的意义在于,它第1次系统性地证明了即便不改动模型参数,只要设计好提示词与循环体也能让大模型表现出较稳定的多步推理与工具使用能力。
当然,它也有明显的缺点,最突出的问题是格式脆弱。因为程序依赖对模型输出文本的解析,只要模型把 Action: 少写一个冒号,或者把参数格式写乱,整个执行流程就可能失败。也正因如此,后来的 Agent 框架开始逐步转向结构化的函数调用(Function Calling)机制。这里需要注意的一点是,ReAct 的提出早于函数调用,而函数调用的出现也正是为了解决上面这一问题。
4.5.5 LangChain 中的 Agent 与 ReAct#
理解了经典的 ReAct 之后,再回头来看我们前面已经使用过的 create_agent(),很多现象就会变得清晰起来。在今天的 LangChain 体系中通常不会再手工编写完整的"思考-行动-观察"提示词流程,然后再手动解析字符串并调用工具,更常见的做法是先把工具与模型绑定,再把它们交给 Agent 运行时统一调度。例如:
1 from langchain.agents import create_agent
2 tools = [retrieve_context]
3 agent = create_agent(model=model, tools=tools, system_prompt=prompt)表面上看,这段代码只是创建了一个可以调用工具的智能体,但从执行机制上看它延续的仍然是 ReAct 的核心循环,只不过现代框架把行动和观察的表达形式做了工程化改造。因此如果去看 LangGraph 的运行图,会发现它和上面的 ReAct 流程图几乎是一一对应,只是思考过程被隐藏在模型内部推理中,行动被结构化函调调用替代了。这部分内容将在第4.10节内容中进行介绍,同时在第5.10节内容中我们也将基于 create_agent 来构建一个迷你版的 ChatGPT 个人助手。
同时,这里需要注意的一点是,由于 create_agent 遵循了 ReAct 的求解范式,所以理论上整个过程可能会无限循环下去。如果提示词约束不够明确、模型能力不够稳定,或者工具定义不够清晰就可能出现反复调用、错误拆解或过度检索等问题,从而导致算力成本激增。因此我们在定义的时候可以显示指定最大循环步数,即
1 create_agent(model).with_config(recursion_limit=100)在上述代码中,recursion_limit=100 表示最大循环步数为100次,如果不指定则默认允许的最大循环步数是 9999 步。
4.5.6 小结#
本节中,我们从前面已经使用过的 create_agent() 出发,回过头解释了它背后的方法论基础。可以看到,ReAct 的核心并不只是一个论文中的术语,而是一种非常具体的任务求解方式——让模型在推理过程中主动采取行动,再根据行动结果继续推理,直到得到最终答案。
从发展历程上看,最初的 ReAct 主要依赖显式提示词和文本解析来完成循环,而在现代 LangChain 等框架中这一思想则被进一步工程化,表现为结构化函数调用、消息状态管理以及自动迭代执行。理解这一点以后,后续再去阅读后续更复杂的 LangGraph 流程编排、节点控制与自定义 Agent 设计,就会更加自然。
引用#
[1] Yao S, Zhao J, Yu D, et al. ReAct: Synergizing Reasoning and Acting in Language Models. 2022.
[2] https://reference.langchain.com/python/langchain-classic/agents/react/agent/create_react_agent